스케일러블 적대적 분류를 위한 일반 재학습 프레임워크
본 논문은 임의의 학습 알고리즘과 다양한 적대적 공격 모델에 적용 가능한 재학습 프레임워크(RAD)를 제안한다. RAD는 공격자 시뮬레이션을 통해 생성된 적대적 예제를 반복적으로 학습 데이터에 추가함으로써 최적의 적대적 위험의 상한을 최소화한다. 이론적 분석을 통해 RAD가 적대적 위험을 근사적으로 최소화함을 보였으며, 좌표 탐욕(local search) 기반 공격 근사와 무작위 재시작을 결합한 알고리즘을 통해 실용적인 보증을 제공한다. 실험에…
저자: Bo Li, Yevgeniy Vorobeychik, Xinyun Chen
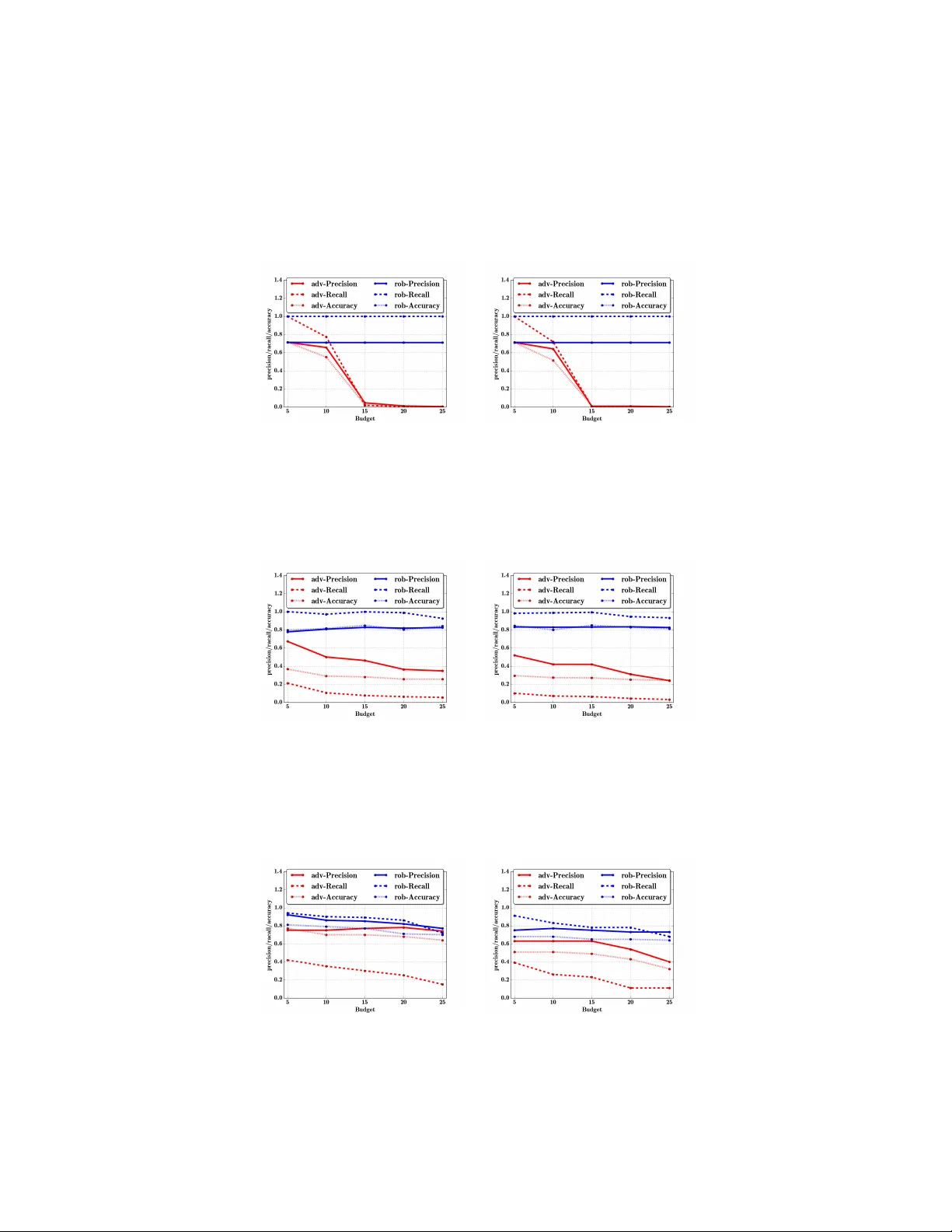
본 논문은 머신러닝 기반 보안 시스템이 직면한 적대적 위협을 다루기 위해, 학습 알고리즘과 공격 모델에 구애받지 않는 일반적인 재학습 프레임워크인 RAD (Retraining with ADversarial examples)를 제안한다. 기존 연구는 특정 모델(예: 선형, 신경망)이나 특정 공격(예: L2 비용 최소화) 에 특화된 방어 기법을 설계했으며, 특히 Li와 Vorobeychik이 제시한 Stackelberg 게임 기반 최적 적대적 위험 최소화는 이론적으로는 포괄적이지만 차원 수가 10‑30 정도로 제한돼 실용성이 낮았다.
논문은 먼저 적대적 위험 함수를 정의한다. 일반적인 학습 목표는 정규화된 경험적 위험 L(β)=∑_i ℓ(g_β(x_i), y_i)+α‖β‖_p^p 이다. 그러나 악성 샘플이 공격자에 의해 변형될 경우, 실제 위험은 L_A(β;O)=∑_{i:y_i=-1}ℓ(g_β(x_i),-1)+∑_{i:y_i=+1}ℓ(g_β(O(β,x_i)),+1)+α‖β‖_p^p 로 표현된다. 여기서 O(β,x) 는 현재 분류기 β 에 대해 최적 회피 변형을 반환하는 공격자 오라클이다.
RAD 알고리즘은 다음 절차로 구성된다. (1) 초기 데이터 X 로 기본 학습기 T rain 을 학습한다. (2) 모든 악성 샘플 x_i 에 대해 O(β, x_i) 를 호출해 회피 가능한 변형 x′ 를 얻는다. (3) x′ 가 아직 데이터에 없으면 N_i 집합에 추가하고 전체 데이터에 삽입한다. (4) 새 데이터가 추가되면 다시 학습기를 재학습한다. (5) 새로운 변형이 더 이상 생성되지 않을 때까지 반복한다. 이 과정은 “오라클이 반환하는 변형을 데이터에 포함시키는” 일종의 데이터 증강이며, 학습 알고리즘 자체를 수정할 필요가 없다는 장점이 있다.
이론적 분석에서는 두 가지 핵심 정리를 제시한다. Proposition 3.1 은 RAD가 최적 적대적 위험 L\*_A(O) 의 상한을 최소화한다는 것을 증명한다. 구체적으로, RAD가 마지막 반복에서 얻은 파라미터 β̂ 에 대해 L_RN(β̂, O) ≥ L\*_A(O) 가 성립한다. 이는 RAD가 최적 위험보다 크게 벗어나지 않는 안전한 해를 제공함을 의미한다. 그러나 O 가 정확한 최적 회피 변형을 제공하지 못하는 경우, 위 정리는 직접 적용되지 않는다.
이를 보완하기 위해 논문은 두 가지 공격 근사 방식을 제시한다. 첫 번째는 f(x) 가 볼록이고 연속인 경우, 원래 비볼록 문제(4) 를 상한 문제(5) 로 변형해 다항식 시간에 최적해를 구한다. Lemma 4.1·Corollary 4.1 은 이 경우 근사 해가 실제 최적 해와 동일함을 보인다. 두 번째는 일반적인 비볼록·이산형 상황을 위한 좌표 탐욕(CoordinateGreedy, CG) 알고리즘이다. CG는 무작위로 선택된 특징을 순차적으로 개선하며, 무작위 재시작(L 번) 을 통해 전역 최적해에 수렴할 확률 p_L 을 정의한다. Proposition 4.2 는 CG‑기반 오라클 O_L 로 얻은 위험 L\*_A,01(O) 가 L_RN(β, O_L) + δ(p) 로 상한될 수 있음을 보여준다. 여기서 δ(p) 는 악성 샘플 수 B 와 p_L 에 의존하는 작은 보정항이다. 실험에서는 p_L 이 매우 작아짐을 확인했으며, 따라서 RAD 가 실질적으로 최적 적대적 위험에 근접함을 보장한다.
스케일러빌리티 측면에서 RAD는 기존 적대적 학습 방법이 10‑30 차원에 제한되던 문제를 크게 완화한다. 학습 알고리즘 자체를 수정하지 않고 ‘래퍼’ 형태로 적용 가능하므로, SVM, 로지스틱 회귀, 신경망 등 다양한 모델에 그대로 사용할 수 있다. 또한, 악성 샘플을 클러스터링하거나 온라인 SGD 와 결합하면 메모리·시간 복잡도를 더욱 낮출 수 있다.
실험에서는 두 도메인, 스팸 필터링과 MNIST 손글씨 인식을 대상으로 평가했다. 스팸에서는 단어 삽입·삭제, MNIST에서는 픽셀 변형( L2 비용 제한) 으로 회피 공격을 설계하였다. 결과는 다음과 같다. (1) 재학습 전에는 공격 성공률이 70‑90% 수준이었으나, RAD 적용 후 10% 이하로 급감하였다. (2) 비-공격 상황에서의 정확도 저하가 1‑2% 미만에 그쳐 실용성을 확보했다. (3) 동일한 방어 성능을 보이는 기존 최첨단 적대적 위험 최소화 방법에 비해 학습 시간은 5‑10배 빠르게 수행되었다.
논문의 한계로는 (i) 공격 오라클이 실제 공격자보다 약할 경우 방어가 과도하게 보수적일 수 있음, (ii) 좌표 탐욕이 지역 최적에 머물 가능성이 남아 있어 재시작 횟수 선택이 중요함, (iii) 이론적 보장은 0/1 손실에 국한되므로 다른 손실 함수에 대한 일반화는 추가 연구가 필요하다. 그럼에도 불구하고 RAD는 “어떠한 학습기와 공격 모델에도 적용 가능한, 확장 가능하고 이론적으로 뒷받침되는 적대적 재학습 프레임워크”라는 목표를 성공적으로 달성했다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기