Randomized Distributed Mean Estimation: Accuracy vs Communication
We consider the problem of estimating the arithmetic average of a finite collection of real vectors stored in a distributed fashion across several compute nodes subject to a communication budget constraint. Our analysis does not rely on any statistic…
Authors: Jakub Konev{c}ny, Peter Richtarik
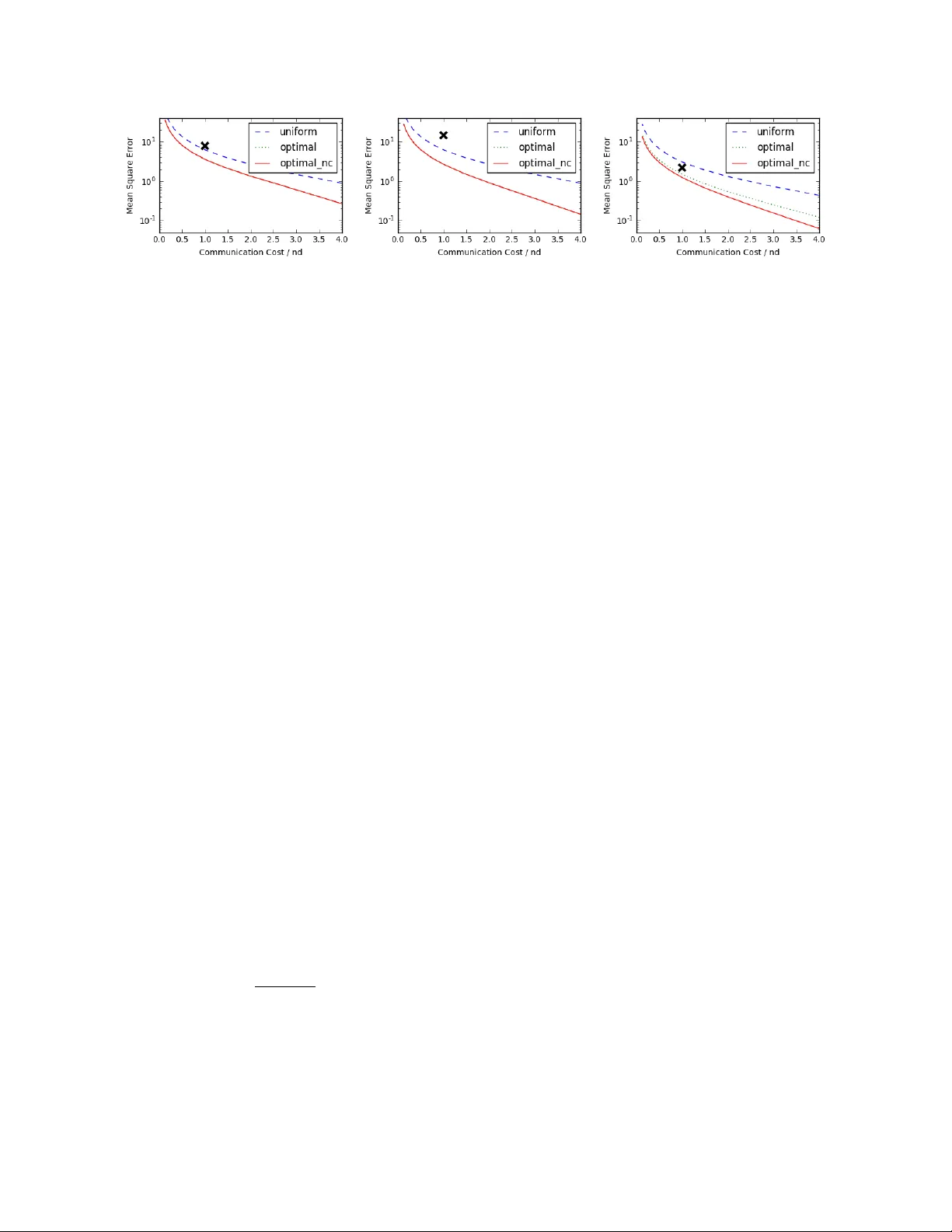
Randomized Distributed Mean Estimation: Accuracy vs Comm unication Jakub Kone ˇ cn´ y ∗ P eter Rich t´ arik † Scho ol of Mathematics The University of Edinbur gh Unite d Kingdom No vem ber 24, 2016 Abstract W e consider the problem of estimating the arithmetic a verage of a finite collection of real v ectors stored in a distributed fashion across several compute nodes sub ject to a comm unication budget constrain t. Our analysis do es not rely on an y statistical assumptions ab out the source of the vectors. This problem arises as a subproblem in man y applications, including reduce- all op erations within algorithms for distributed and federated optimization and learning. W e prop ose a flexible family of randomized algorithms exploring the trade-off b etw een exp ected comm unication cost and estimation error. Our family contains the full-communication and zero-error metho d on one extreme, and an -bit comm unication and O (1 / ( n )) error metho d on the opp osite extreme. In the sp ecial case where we comm unicate, in expectation, a single bit per co ordinate of eac h vector, w e impro ve up on existing results b y obtaining O ( r /n ) error, where r is the n umber of bits used to represent a floating p oint v alue. 1 In tro duction W e address the problem of estimating the arithmetic mean of n v ectors, X 1 , . . . , X n ∈ R d , stored in a distributed fashion across n compute no des, sub ject to a constraint on the comm unication cost. In particular, w e consider a star net work topology with a single serv er at the cen tre and n nodes connected to it. All nodes send an encoded (possibly via a lossy randomized transformation) version of their vector to the serv er, after whic h the server performs a deco ding op eration to estimate the true mean X def = 1 n n X i =1 X i . The purp ose of the enco ding operation is to compress the v ector so as to sav e on communication cost, which is typically the b ottlenec k in practical applications. ∗ The author ackno wledges support from Google via a Go ogle European Do ctoral F ello wship. † The author ac knowledges supp ort from Amazon, and the EPSRC Gran t EP/K02325X/1, Accelerated Coordinate Descen t Metho ds for Big Data Optimization. 1 T o b etter illustrate the setup, consider the naiv e approach in which all no des send the v ec- tors without p erforming any enco ding op eration, follo wed by the application of a simple av eraging deco der by the serv er. This results in zero estimation error at the exp ense of maximum commu- nication cost of ndr bits, where r is the n umber of bits needed to comm unicate a single floating p oin t entry/coordinate of X i . 1.1 Bac kground and Con tributions The distributed mean estimation problem w as recen tly studied in a statistical framew ork where it is assumed that the vectors X i are indep endent and identicaly distributed samples from some sp ecific underlying distribution. In such a setup, the goal is to estimate the true mean of the underlying distribution [ 14 , 13 , 2 , 1 ]. These w orks formulate lo wer and upp er b ounds on the comm unication cost needed to achiev e the minimax optimal estimation error. In con trast, w e do not mak e any statistical assumptions on the source of the v ectors, and study the trade-off betw een exp ected comm unication costs and mean square error of the estimate. Arguably , this setup is a more robust and accurate mo del of the distributed mean estimation problems arising as subproblems in applications such as reduce-all op erations within algorithms for distributed and federated optimization [ 9 , 6 , 5 , 8 , 3 ]. In these applications, the av eraging op erations need to be done rep eatedly throughout the iterations of a master learning/optimization algorithm, and the vectors { X i } corresp ond to up dates to a global mo del/v ariable. In these applications, the v ectors ev olve throughout the iterativ e process in a complicated pattern, t ypically approac hing zero as the master algorithm con verges to optimalit y . Hence, their statistical prop erties change, which renders fixed statistical assumptions not satisfied in practice. F or instance, when training a deep neural netw ork mo del in a distributed en vironment, the v ector X i corresp onds to a stochastic gradient based on a minibatch of data stored on no de i . In this setup we do not hav e any useful prior statistical kno wledge ab out the high-dimensional vectors to be aggregated. It has recen tly b een observ ed that when communication cost is high, whic h is t ypically the case for commo dity clusters, and even more so in a federated optimization framework, it is can b e very useful to sacrifice on estimation accuracy in fav or of reduced communication [ 7 , 4 ]. In this pap er we prop ose a p ar ametric family of r andomize d metho ds for estimating the me an X , with parameters b eing a set of pr ob abilities p ij for i = 1 , . . . , n and j = 1 , 2 , . . . , d and no de c enters µ i ∈ R d for i = 1 , 2 , . . . , n . The exact meaning of these parameters is explained in Section 3 . By v arying the probabilities, at one extreme, w e recov er the exact method describ ed, enjo ying zero estimation error at the expense of full comm unication cost. At the opp osite extreme are metho ds with arbitrarily small exp ected comm unication cost, which is achiev ed at the expense of suffering an explo ding estimation error. Practical metho ds app ear somewhere on the con tinuum b et ween these t w o extremes, dep ending on the specific requirements of the application at hand. Suresh et al. [ 10 ] prop ose a method combining a pre-pro cessing step via a random structured rotation, follo wed b y randomized binary quantization. Their quantization protocol arises as a sub optimal sp ecial case of our parametric family of me thods. T o illustrate our results, consider the sp ecial case in which w e c ho ose to communicate a single bit p er element of X i only . W e then obtain an O r n R b ound on the mean square error, where r is n umber of bits used to represent a floating p oint v alue, and R = 1 n P n i =1 k X i − µ i 1 k 2 with µ i ∈ R b eing the av erage of elemen ts of X i , and 1 the all-ones v ector in R d (see Example 7 in Section 5 ). Note that this b ound impro ves up on the p erformance of the metho d of [ 10 ] in t wo asp ects. First, the b ound is independent of d , improving from logarithmic dependence. F urther, 2 due to a prepro cessing rotation step, their metho d requires O ( d log d ) time to b e implemen ted on eac h no de, while our metho d is linear in d . This and other sp ecial cases are summarized in T able 1 in Section 5 . While the abov e already impro ves up on the state of the art, the impro ved results are in fact obtained for a sub optimal choice of the parameters of our metho d (constant probabilities p ij , and no de centers fixed to the mean µ i ). One can decrease the MSE further b y optimizing o ver the probabilities and/or no de centers (see Section 6 ). How ev er, apart from a v ery low communication cost regime in which w e ha ve a closed form expression for the optimal probabilities, the problem needs to b e solved n umerically , and hence w e do not hav e expressions for how m uch impro vemen t is p ossible. W e illustrate the effect of fixed and optimal probabilities on the trade-off b etw een comm unication cost and MSE exp erimentally on a few selected datasets in Section 6 (see Figure 1 ). 1.2 Outline In Section 2 we formalize the concepts of enco ding and deco ding proto cols. In Section 3 we de- scrib e a parametric family of randomized (and un biased) enco ding proto cols and giv e a simple form ula for the mean squared error. Subsequen tly , in Section 4 w e formalize the notion of com- m unication cost, and describ e sev eral communication proto cols, which are optimal under different circumstances. W e giv e simple instantiations of our proto col in Section 5 , illustrating the trade-off b et ween communication costs and accuracy . In Section 6 w e address the question of the optimal c hoice of parameters of our proto col. Finally , in Section 7 w e comment on p ossible extensions we lea ve out to future work. 2 Three Proto cols In this work w e consider (randomized) enc o ding pr oto c ols α , c ommunic ation pr oto c ols β and de c o ding pr oto c ols γ using whic h the av eraging is p erformed inexactly as follows. No de i computes a (p ossibly sto c hastic) estimate of X i using the enco ding proto col, which we denote Y i = α ( X i ) ∈ R d , and sends it to the server using communication proto col β . By β ( Y i ) we denote the num b er of bits that need to b e transferred under β . The server then estimates X using the deco ding proto col γ of the estimates: Y def = γ ( Y 1 , . . . , Y n ) . The ob jective of this work is to study the trade-off b et ween the (exp ected) num b er of bits that need to b e communicated, and the accuracy of Y as an estimate of X . In this work we fo cus on enco ders which are unbiased, in the following sense. Definition 2.1 (Un biased and Indep enden t Enco der) . W e say that enco der α is unbiased if E α [ α ( X i )] = X i for all i = 1 , 2 , . . . , n . W e sa y that it is indep endent, if α ( X i ) is indep endent from α ( X j ) for all i 6 = j . Example 1 (Identit y Enco der) . A trivial example of an enco ding proto col is the identit y function: α ( X i ) = X i . It is b oth un biased and indep enden t. This enco der do es not lead to an y sa vings in comm unication that would b e otherwise infeasible though. 3 W e now formalize the notion of accuracy of estimating X via Y . Since Y can b e random, the notion of accuracy will naturally b e probabilistic. Definition 2.2 (Estimation Error / Mean Squared Error) . The me an squar e d err or of proto col ( α, γ ) is the quantit y M S E α,γ ( X 1 , . . . , X n ) = E α,γ k Y − X k 2 = E α,γ h k γ ( α ( X 1 ) , . . . , α ( X n )) − X k 2 i . T o illustrate the ab ov e concept, w e now giv e a few examples: Example 2 (Averaging Deco der) . If γ is the av eraging function, i.e., γ ( Y 1 , . . . , Y n ) = 1 n P n i =1 Y i , then M S E α,γ ( X 1 , . . . , X n ) = 1 n 2 E α n X i =1 α ( X i ) − X i 2 . The next example generalizes the iden tity enco der and a veraging deco der. Example 3 (Linear Encoder and In verse Linear Deco der) . Let A : R d → R d b e linear and in v ertible. Then we can set Y i = α ( X i ) def = AX i and γ ( Y 1 , . . . , Y n ) def = A − 1 1 n P n i =1 Y i . If A is random, then α and γ are random (e.g., a structured random rotation, see [ 12 ]). Note that γ ( Y 1 , . . . , Y n ) = 1 n n X i =1 A − 1 Y i = 1 n n X i =1 X i = X , and hence the MSE of ( α , γ ) is zero. W e shall now prov e a simple result for unbiased and indep endent enco ders used in subsequen t sections. Lemma 2.3 (Unbiased and Indep endent Enco der + Averaging Deco der) . If the enco der α is un biased and indep endent, and γ is the a veraging decoder, then M S E α,γ ( X 1 , . . . , X n ) = 1 n 2 n X i =1 E α k Y i − X i k 2 = 1 n 2 n X i =1 V ar α [ α ( X i )] . Pr o of. Note that E α [ Y i ] = X i for all i . W e ha ve M S E α ( X 1 , . . . , X n ) = E α k Y − X k 2 ( ∗ ) = 1 n 2 E α n X i =1 Y i − X i 2 ( ∗∗ ) = 1 n 2 n X i =1 E α h k Y i − E α [ Y i ] k 2 i = 1 n 2 n X i =1 V ar α [ α ( X i )] , 4 where (*) follows from un biasedness and (**) from indep endence. One ma y wish to define the encoder as a com bination of t wo or more separate encoders: α ( X i ) = α 2 ( α 1 ( X i )). See [ 10 ] for an example where α 1 is a random rotation and α 2 is binary quantization. 3 A F amily of Randomized Enco ding Proto cols Let X 1 , . . . , X n ∈ R d b e given. W e shall write X i = ( X i (1) , . . . , X i ( d )) to denote the en tries of v ector X i . In addition, with eac h i w e also associate a parameter µ i ∈ R . W e refer to µ i as the cen ter of data at no de i , or simply as no de c enter . F or now, we assume these parameters are fixed and w e shall later commen t on ho w to choose them optimally . W e shall define supp ort of α on no de i to b e the set S i def = { j : Y i ( j ) 6 = µ i } . W e now define t wo parametric families of randomized encoding proto cols. The first results in S i of random size, the second has S i of a fixed size. 3.1 Enco ding Proto col with V ariable-size Supp ort With each pair ( i, j ) w e asso ciate a parameter 0 < p ij ≤ 1, represen ting a probabilit y . The collection of parameters { p ij , µ i } defines an enco ding proto col α as follows: Y i ( j ) = ( X i ( j ) p ij − 1 − p ij p ij µ i with probabilit y p ij , µ i with probabilit y 1 − p ij . (1) R emark 1 . Enforcing the probabilities to b e p ositiv e, as opp osed to nonnegativ e, leads to v astly simplified notation in what follows. How ev er, it is more natural to allo w p ij to b e zero, in whic h case w e ha ve Y i ( j ) = µ i with probabilit y 1. This raises issues suc h as p oten tial lac k of un biasedness, whic h can b e resolv ed, but only at the exp ense of a larger-than-reasonable notational o verload. In the rest of this section, let γ b e the a veraging deco der (Example 2 ). Since γ is fixed and de- terministic, we shall for simplicit y write E α [ · ] instead of E α,γ [ · ]. Similarly , we shall write M S E α ( · ) instead of M S E α,γ ( · ). W e now prov e t wo lemmas describing prop erties of the enco ding proto col α . Lemma 3.1 states that the proto col yields an unbiased estimate of the av erage X and Lemma 3.2 provides the exp ected mean square error of the estimate. Lemma 3.1 (Unbiasedness) . The enco der α defined in ( 1 ) is unbiased. That is, E α [ α ( X i )] = X i for all i . As a result, Y is an un biased estimate of the true a verage: E α [ Y ] = X . Pr o of. Due to linearit y of exp ectation, it is enough to sho w that E α [ Y ( j )] = X ( j ) for all j . Since Y ( j ) = 1 n P n i =1 Y i ( j ) and X ( j ) = 1 n P n i =1 X i ( j ), it suffices to show that E α [ Y i ( j )] = X i ( j ): E α [ Y i ( j )] = p ij X i ( j ) p ij − 1 − p ij p ij µ i ( j ) + (1 − p ij ) µ i ( j ) = X i ( j ) , and the claim is prov ed. 5 Lemma 3.2 (Mean Squared Error) . Let α = α ( p ij , µ i ) b e the enco der defined in ( 1 ). Then M S E α ( X 1 , . . . , X n ) = 1 n 2 X i,j 1 p ij − 1 ( X i ( j ) − µ i ) 2 . (2) Pr o of. Using Lemma 2.3 , w e hav e M S E α ( X 1 , . . . , X n ) = 1 n 2 n X i =1 E α h k Y i − X i k 2 i = 1 n 2 n X i =1 E α d X j =1 ( Y i ( j ) − X i ( j )) 2 = 1 n 2 n X i =1 d X j =1 E α ( Y i ( j ) − X i ( j )) 2 . (3) F or an y i, j we further hav e E α ( Y i ( j ) − X i ( j )) 2 = p ij X i ( j ) p ij − 1 − p ij p ij µ i − X i ( j ) 2 + (1 − p ij ) ( µ i − X i ( j )) 2 = (1 − p ij ) 2 p ij ( X i ( j ) − µ i ) 2 + (1 − p ij ) ( µ i − X i ( j )) 2 = 1 − p ij p ij ( X i ( j ) − µ i ) 2 . It suffices to substitute the abov e into ( 3 ). 3.2 Enco ding Proto col with Fixed-size Supp ort Here we prop ose an alternative enco ding proto col, one with deterministic supp ort size. As we shall see later, this results in deterministic comm unication cost. Let σ k ( d ) denote the set of all subsets of { 1 , 2 , . . . , d } containing k elements. The protocol α with a single in teger parameter k is then working as follo ws: First, each no de i samples D i ∈ σ k ( d ) uniformly at random, and then sets Y i ( j ) = ( dX i ( j ) k − d − k k µ i if j ∈ D i , µ i otherwise . (4) Note that due to the design, the size of the supp ort of Y i is alwa ys k , i.e., | S i | = k . Naturally , w e can expect this proto col to p erform practically the same as the proto col ( 1 ) with p ij = k /d , for all i, j . Lemma 3.4 indeed suggests this is the case. While this proto col admits a more efficien t comm unication proto col (as we shall see in Section ), proto col ( 1 ) enjoys a larger parameters space, ultimately leading to b etter MSE. W e comment on this tradeoff in subsequent sections. As for the data-dep endent protocol, w e prov e basic prop erties. The pro ofs are similar to those of Lemmas 3.1 and 3.2 and w e defer them to App endix A . 6 Lemma 3.3 (Unbiasedness) . The enco der α defined in ( 1 ) is unbiased. That is, E α [ α ( X i )] = X i for all i . As a result, Y is an un biased estimate of the true a verage: E α [ Y ] = X . Lemma 3.4 (Mean Squared Error) . Let α = α ( k ) b e e ncoder defined as in ( 4 ). Then M S E α ( X 1 , . . . , X n ) = 1 n 2 n X i =1 d X j =1 d − k k ( X i ( j ) − µ i ) 2 . (5) 4 Comm unication Proto cols Ha ving defined the enco ding proto cols α , w e need to sp ecify the wa y the enco ded vectors Y i = α ( X i ), for i = 1 , 2 , . . . , n , are communicated to the server. Given a sp ecific c ommunic ation pr oto c ol β , w e write β ( Y i ) to denote the (exp ected) num b er of bits that are communicated b y no de i to the server. Since Y i = α ( X i ) is in general not deterministic, β ( Y i ) can b e a random v ariable. Definition 4.1 (Comm unication Cost) . The c ommunic ation c ost of communication proto col β under randomized enco ding α is the total exp ected num b er of bits transmitted to the server: C α,β ( X 1 , . . . , X n ) = E α " n X i =1 β ( α ( X i )) # . (6) Giv en Y i , a go o d communication proto col is able to enco de Y i = α ( X i ) using a few bits only . Let r denote the num b er of bits used to represen t a floating p oint n um b er. Let ¯ r b e the the num b er of bits representing µ i . In the rest of this section we describe several comm unication proto cols β and calculate their comm unication cost. 4.1 Naiv e Represen t Y i = α ( X i ) as d floating p oin t n umbers. Then for all enco ding proto cols α and all i we ha ve β ( α ( X i )) = dr , whence C α,β = E α " n X i =1 β ( α ( X i )) # = ndr . 4.2 V arying-length W e will use a single v ariable for ev ery element of the v ector Y i , whic h do es not hav e constant size. The first bit decides whether the v alue represen ts µ i or not. If yes, end of v ariable, if not, next r bits represen t the v alue of Y i ( j ). In addition, w e need to comm unicate µ i , whic h tak es ¯ r bits 1 . W e 1 The distinction here is b ecause µ i can b e chosen to b e data indep enden t, such as 0, so we don’t hav e to commu- nicate anything (i.e., ¯ r = 0) 7 th us hav e β ( α ( X i )) = ¯ r + d X j =1 1 ( Y i ( j )= µ i ) + ( r + 1) × 1 ( Y i ( j ) 6 = µ i ) , (7) where 1 e is the indicator function of even t e . The exp ected n umber of bits comm unicated is giv en b y C α,β = E α " n X i =1 β ( α ( X i ))) # ( 7 ) = n ¯ r + n X i =1 d X j =1 (1 − p ij + ( r + 1) p ij ) = n ¯ r + n X i =1 d X j =1 (1 + r p ij ) In the sp ecial case when p ij = p > 0 for all i, j , w e get C α,β = n ( ¯ r + d + pdr ) . 4.3 Sparse Communication Proto col for Enco der ( 1 ) W e can represent Y i as a sparse v ector; that is, a list of pairs ( j, Y i ( j )) for whic h Y i ( j ) 6 = µ i . The n umber of bits to represent eac h pair is d log ( d ) e + r . An y index not found in the list, will b e in terpreted b y serv er as having v alue µ i . Additionally , w e ha ve to communicate the v alue of µ i to the serv er, which takes ¯ r bits. W e assume that the v alue d , size of the vectors, is kno wn to the serv er. Hence, β ( α ( X i )) = ¯ r + d X j =1 1 ( Y i ( j ) 6 = µ i ) × ( d log d e + r ) . Summing up through i and taking exp ectations, the the communication cost is giv en by C α,β = E α " n X i =1 β ( α ( X i )) # = n ¯ r + ( d log d e + r ) n X i =1 d X j =1 p ij . (8) In the sp ecial case when p ij = p > 0 for all i, j , w e get C α,β = n ¯ r + ( d log d e + r ) ndp. R emark 2 . A practical improv emen t up on this could b e to (without loss of generality) assume that the pairs ( j, Y i ( j )) are ordered b y j , i.e., we hav e { ( j s , Y i ( j s )) } k s =1 for some k and j 1 < j 2 < · · · < j k . F urther, let us denote j 0 = 0. W e can then use a v arian t of v ariable-length quantit y [ 11 ] to represen t the set { ( j s − j s − 1 , Y i ( j s )) } k s =1 . With careful design one can hop e to reduce the log ( d ) factor in the a verage case. Nevertheless, this do es not improv e the worst case analysis we fo cus on in this pap er, and hence we do not delv e deep er in this. 8 4.4 Sparse Communication Proto col for Enco der ( 4 ) W e no w describ e a sparse communication proto col compatible only with fixed length enco der defined in ( 4 ). Note that subset selection can b e compressed in the form of a random seed, letting us a void the log ( d ) factor in ( 8 ). This includes the proto col defined in ( 4 ) but also ( 1 ) with uniform probabilities p ij . In particular, w e can represent Y i as a sparse vector con taining the list of the v alues for which Y i ( j ) 6 = µ i , ordered b y j . Additionally , we need to communicate the v alue µ i (using ¯ r bits) and a random seed (using ¯ r s bits), whic h can b e used to reconstruct the indices j , corresp onding to the comm unicated v alues. Note that for an y fixed k defining proto col ( 4 ), w e ha ve | S i | = k . Hence, comm unication cost is deterministic: C α,β = n X i =1 β ( α ( X i )) = n ( ¯ r + ¯ r s ) + nk r. (9) In the case of the v ariable-size-support encoding protocol ( 1 ) with p ij = p > 0 for all i, j , the sparse communication proto col describ ed here yields exp ected communication cost C α,β = E α " n X i =1 β ( α ( X i )) # = n ( ¯ r + ¯ r s ) + ndpr . (10) 4.5 Binary If the elemen ts of Y i tak e only tw o different v alues, Y min i or Y max i , we can use a binary c ommuni- c ation pr oto c ol . That is, for each no de i , we comm unicate the v alues of Y min i and Y max i (using 2 r bits), follow ed b y a single bit p er elemen t of the arra y indicating whether Y max i or Y min i should b e used. The resulting (deterministic) communication cost is C α,β = n X i =1 β ( α ( X i )) = n (2 r ) + nd. (11) 4.6 Discussion In the ab ov e, we ha ve presen ted several comm unication proto cols of different complexit y . How ev er, it is not possible to claim any of them is the most efficien t one. Which communication protocol is the b est, dep ends on the specifics of the used enco ding protocol. Consider the extreme case of enco ding proto col ( 1 ) with p ij = 1 for all i, j . The naive comm unication proto col is clearly the most efficient, as all other proto cols need to send some additional information. Ho wev er, in the interesting case when we consider small comm unication budget, the sparse comm unication proto cols are the most efficient. Therefore, in the following sections, we fo cus primarily on optimizing the p erformance using these proto cols. 5 Examples In this section, w e highligh t on sev eral instan tiations of our protocols, reco vering existing tec hniques and formulating no vel ones. W e commen t on the resulting trade-offs b etw een communication cost and estimation error. 9 5.1 Binary Quantization W e start by recov ering an existing metho d, which turns ev ery element of the vectors X i in to a particular binary representation. Example 4 . If we set the parameters of proto col ( 1 ) as µ i = X min i and p ij = X i ( j ) − X min i ∆ i , where ∆ i def = X max i − X min i (assume, for simplicit y , that ∆ i 6 = 0), we exactly recov er the quantization algorithm prop osed in [ 10 ]: Y i ( j ) = ( X max i with probabilit y X i ( j ) − X min i ∆ i , X min i with probabilit y X max i − X i ( j ) ∆ i . (12) Using the formula ( 2 ) for the enco ding proto col α , we get M S E α = 1 n 2 n X i =1 d X j =1 X max i − X i ( j ) X i ( j ) − X min i X i ( j ) − X min i 2 ≤ d 2 n · 1 n n X i =1 k X i k 2 . This exactly reco vers the MSE b ound established in [ 10 , Theorem 1]. Using the binary comm u- nication proto col yields the communication cost of 1 bit p er elemen t if X i , plus a t wo real-v alued scalars ( 11 ). R emark 3 . If w e use the ab ov e proto col jointly with randomized linear enco der and decoder (see Example 3 ), where the linear transform is the randomized Hadamard transform, w e reco ver the metho d describ ed in [ 10 , Section 3] whic h yields impro ved M S E α = 2 log d +2 n · 1 n P n i =1 k X i k 2 and can b e implemented in O ( d log d ) time. 5.2 Sparse Communication Proto cols No w we mo ve to comparing the communication costs and estimation error of v arious instantiations of the enco ding protocols, utilizing the deterministic sparse comm unication proto col and uniform probabilities. F or the remainder of this section, let us only consider instan tiations of our proto col where p ij = p > 0 for all i, j , and assume that the no de centers are set to the v ector a verages, i.e., µ i = 1 d P d j =1 X i ( j ). Denote R = 1 n P n i =1 P d j =1 ( X i ( j ) − µ i ) 2 . F or simplicit y , we also assume that | S | = nd , whic h is what w e can in general exp ect without any prior kno wledge about the v ectors X i . The prop erties of the following examples follo w from Equations ( 2 ) and ( 10 ). When considering the communication costs of the proto cols, keep in mind that the trivial b enc hmark is C α,β = ndr , whic h is ac hieved b y simply sending the vectors unmo dified. Comm unication c ost of C α,β = nd corresp onds to the in teresting sp ecial case when w e use (on a verage) one bit p er elemen t of each X i . Example 5 (F ull communication) . If we c ho ose p = 1, we get C α,β = n ( ¯ r s + ¯ r ) + ndr, M S E α,γ = 0 . In this case, the enco ding proto col is lossless, whic h ensures M S E = 0. Note that in this case, w e could get rid of the n ( ¯ r s + ¯ r ) factor by using naiv e communication protocol. 10 Example p C α,β M S E α,γ Example 5 (F ull) 1 ndr 0 Example 6 (Log M S E ) 1 / log d n ( ¯ r s + ¯ r ) + ndr log d (log( d ) − 1) R n Example 7 (1-bit) 1 /r n ( ¯ r s + ¯ r ) + nd ( r − 1) R n Example 9 (b elow 1-bit) 1 /d n ( ¯ r s + ¯ r ) + nr ( d − 1) R n T able 1: Summary of ac hiev able comm unication cost and estimation error, for v arious c hoices of probabilit y p . Example 6 (Log MSE) . If w e choose p = 1 / log d , we get C α,β = n ( ¯ r s + ¯ r ) + ndr log d , M S E α,γ = log( d ) − 1 n R. This proto col order-wise matc hes the M S E of the metho d in Remark 3 . Ho w ever, as long as d > 2 r , this proto col attains this error with smal ler comm unication cost. In particular, this is on exp ectation less than a single bit p er elemen t of X i . Finally , note that the factor R is alw a ys smaller or equal to the factor 1 n P n i =1 k X i k 2 app earing in Remark 3 . Example 7 (1-bit p er element comm unication) . If we c ho ose p = 1 /r , w e get C α,β = n ( ¯ r s + ¯ r ) + nd, M S E α,γ = r − 1 n R. This proto col communicates on exp ectation single bit p er element of X i (plus additional ¯ r s + ¯ r bits p er client), while attaining b ound on M S E of O ( r /n ). T o the b est of out knowledge, this is the first metho d to attain this b ound without additional assumptions. Example 8 (Alternative 1-bit per elemen t communication) . If w e choose p = d − ¯ r s − ¯ r dr , we get C α,β = nd, M S E α,γ = dr d − ¯ r s − ¯ r − 1 n R. This alternativ e protocol attains on exp ectation exactly single bit per elemen t of X i , with (a sligh tly more complicated) O ( r /n ) b ound on M S E . Example 9 (Below 1-bit comm unication) . If we c ho ose p = 1 /d , w e get C α,β = n ( ¯ r s + ¯ r ) + nr, M S E α,γ = d − 1 n R. This proto col attains the MSE of protocol in Example 4 while at the same time communicating on a verage significantly less than a single bit p er elemen t of X i . W e summarize these examples in T able 1 . Using the deterministic sparse proto col, there is an obvious low er b ound on the communication cost — n ( ¯ r s + ¯ r ). W e can b ypass this threshold b y using the sparse proto col, with a data-indep endent c hoice of µ i , such as 0, setting ¯ r = 0. By setting p = /d ( d log d e + r ), we get arbitrarily small exp ected communication cost of C α,β = , and the cost of explo ding estimation error M S E α,γ = O (1 /n ). 11 Note that all of the ab ov e examples hav e random comm unication costs. What w e present is the exp e cte d communication cost of the proto cols. All the ab o ve examples can b e mo dified to use the enco ding proto col with fixed-size supp ort defined in ( 4 ) with the parameter k set to the v alue of pd for corresp onding p used ab ov e, to get the same results. The only practical difference is that the communication cost will be deterministic for eac h node, which can b e useful for certain applications. 6 Optimal Enco ders Here we consider ( α, β , γ ), where α = α ( p ij , µ i ) is the encoder defined in ( 1 ), β is the asso ciated the sparse communication proto col, and γ is the av eraging deco der. Recall from Lemma 2 and ( 8 ) that the mean square error and comm unication cost are giv en by: M S E α,γ = 1 n 2 X i,j 1 p ij − 1 ( X i ( j ) − µ i ) 2 , C α,β = n ¯ r + ( d log d e + r ) n X i =1 d X j =1 p ij . (13) Ha ving these closed-form formulae as functions of the parameters { p ij , µ i } , we can no w ask questions such as: 1. Giv en a communication budget, whic h enco ding proto col has the smallest mean squared error? 2. Giv en a b ound on the mean squared error, which enco der suffers the minimal communication cost? Let us no w address the first question; the second question can b e handled in a similar fashion. In particular, consider the optimization problem minimize X i,j 1 p ij − 1 ( X i ( j ) − µ i ) 2 sub ject to µ i ∈ R , i = 1 , 2 , . . . , n X i,j p ij ≤ B (14) 0 < p ij ≤ 1 , i = 1 , 2 , . . . , n ; j = 1 , 2 , . . . , d, (15) where B > 0 represents a bound on the part of the total communication cost in ( 13 ) whic h dep ends on the choice of the probabilities p ij . Note that while the constrain ts in ( 14 ) are conv ex (they are linear), the ob jective is not jointly con vex in { p ij , µ i } . How ev er, the ob jective is conv ex in { p ij } and conv ex in { µ i } . This suggests a simple alternating minimization heuristic for solving the ab o ve problem: 1. Fix the probabilities and optimize ov er the no de centers, 2. Fix the no de centers and optimize o ver probabilities. These t w o steps are rep eated until a suitable con v ergence criterion is reached. Note that the first step has a closed form solution. Indeed, the problem decomp oses across the no de cen ters to n univ ariate unconstrained con vex quadratic minimization problems, and the solution is given b y µ i = P j w ij X i ( j ) P j w ij , w ij def = 1 p ij − 1 . (16) 12 The second step do es not hav e a closed form solution in general; w e provide an analysis of this step in Section 6.1 . R emark 4 . Note that the upp er b ound P i,j ( X i ( j ) − µ i ) 2 /p ij on the ob jective is join tly conv ex in { p ij , µ i } . W e may therefore instead optimize this upper b ound b y a suitable conv ex optimization algorithm. R emark 5 . An alternative and a more practical model to ( 14 ) is to choose p er-no de budgets B 1 , . . . , B n and require P j p ij ≤ B i for all i . The problem b ecomes separable across the no des, and can therefore b e solved by each no de indep endently . If we set B = P i B i , the optimal solution obtained this wa y will lead to MSE which is lo wer bpunded b y the MSE obtained through ( 14 ). 6.1 Optimal Probabilities for Fixed No de Cen ters Let the no de centers µ i b e fixed. Problem ( 14 ) (or, equiv alen tly , step 2 of the alternating mini- mization metho d describ ed ab ov e) then takes the form minimize X i,j ( X i ( j ) − µ i ) 2 p ij sub ject to X i,j p ij ≤ B (17) 0 < p ij ≤ 1 , i = 1 , 2 , . . . n, j = 1 , 2 , . . . , d. Let S = { ( i, j ) : X i ( j ) 6 = µ i } . Notice that as long as B ≥ | S | , the optimal solution is to set p ij = 1 for all ( i, j ) ∈ S and p ij = 0 for all ( i, j ) / ∈ S . 2 In such a case, we hav e M S E α,γ = 0 . Hence, w e can without loss of generality assume that B ≤ | S | . While we are not able to deriv e a closed-form solution to this problem, we can form ulate upp er and low er b ounds on the optimal estimation error, given a b ound on the communication cost form ulated via B . Theorem 6.1 (MSE-Optimal Protocols sub ject to a Comm unication Budget) . Consider problem ( 17 ) and fix any B ≤ | S | . Using the sparse communication proto col β , the optimal enco ding proto col α has communication complexit y C α,β = n ¯ r + ( d log d e + r ) B , (18) and the mean squared error satisfies the b ounds 1 B − 1 R n ≤ M S E α,γ ≤ | S | B − 1 R n , (19) where R = 1 n P n i =1 P d j =1 ( X i ( j ) − µ i ) 2 = 1 n P n i =1 k X i − µ i 1 k 2 . Let a ij = | X i ( j ) − µ i | and W = P i,j a ij . If, moreo ver, B ≤ P ( i,j ) ∈ S a ij / max ( i,j ) ∈ S a ij (whic h is true, for instance, in the ultra-lo w 2 W e interpret 0 / 0 as 0 and do not worry about infeasibility . These issues can b e prop erly formalized by allowing p ij to b e zero in the enco ding proto col and in ( 17 ). How ever, handling this singular situation requires a notational o verload which we are not willing to pay . 13 comm unication regime with B ≤ 1), then M S E α,γ = W 2 n 2 B − R n . (20) Pr o of. Setting p ij = B / | S | for all ( i, j ) ∈ S leads to a feasible solution of ( 17 ). In view of ( 13 ), one then has M S E α,γ = 1 n 2 | S | B − 1 X ( i,j ) ∈ S ( X i ( j ) − µ i ) 2 = | S | B − 1 R n , where R = 1 n P n i =1 P d j =1 ( X i ( j ) − µ i ) 2 = 1 n P n i =1 k X i − µ i 1 k 2 . If we relax the problem b y removing the constraints p ij ≤ 1, the optimal solution satisfies a ij /p ij = θ > 0 for all ( i, j ) ∈ S . At optimalit y the b ound inv olving B must b e tigh t, which leads to P ( i,j ) ∈ S a ij /θ = B , whence θ = 1 B P ( i,j ) ∈ S a ij . So, p ij = a ij B / P ( i,j ) ∈ S a ij . The optimal MSE therefore satisfies the low er b ound M S E α,γ ≥ 1 n 2 X ( i,j ) ∈ S 1 p ij − 1 ( X i ( j ) − µ i ) 2 = 1 n 2 B W 2 − R n , where W def = P ( i,j ) ∈ S a ij ≥ P ( i,j ) ∈ S a 2 ij 1 / 2 = ( nR ) 1 / 2 . Therefore, M S E α,γ ≥ 1 B − 1 R n . If B ≤ P ( i,j ) ∈ S a ij / max ( i,j ) ∈ S a ij , then p ij ≤ 1 for all ( i, j ) ∈ S , and hence w e ha ve optimality . (Also note that, by Cauch y-Sc hw arz inequality , W 2 ≤ nR | S | .) 6.2 T rade-off Curves T o illustrate the trade-offs betw een communication cost and estimation error (MSE) ac hiev able by the proto cols discussed in this section, w e presen t simple numerical examples in Figure 1 , on three syn thetic data sets with n = 16 and d = 512. W e c ho ose an array of v alues for B , directly b ounding the communication cost via ( 18 ), and ev aluate the M S E ( 2 ) for three enco ding proto cols (we use the sparse communication proto col and av eraging deco der). All these proto cols hav e the same comm unication cost, and only differ in the selection of the parameters p ij and µ i . In particular, w e consider (i) uniform probabilities p ij = p > 0 with a verage no de centers µ i = 1 d P d j =1 X i ( j ) (blue dashed line), (ii) optimal probabilities p ij with av erage no de cen ters µ i = 1 d P d j =1 X i ( j ) (green dotted line), and (iii) optimal probabilities with optimal no de centers, obtained via the alternating minimization approac h describ ed ab ov e (red solid line). In order to put a scale on the horizon tal axis, we assumed that r = 16. Note that, in practice, one would choose r to b e as small as p ossible without adversely affecting the application utilizing our distributed mean estimation metho d. The three plots represen t X i with en tries drawn in an i.i.d. fashion from Gaussian ( N (0 , 1)), Laplace ( L (0 , 1)) and c hi-squared ( χ 2 (2)) distributions, 14 Figure 1: T r ade-off curves b et ween communication cost and estimation error (MSE) for four pro- to cols. The plots correspond to vectors X i dra wn in an i.i.d. fashion from Gaussian, Laplace and χ 2 distributions, from left to right. The blac k cross marks the p erformance of binary quantization (Example 4 ). resp ectiv ely . As we can see, in the case of non-symmetric distributions, it is not necessarily optimal to set the no de centers to a verages. As exp ected, for fixed no de cen ters, optimizing o ver probabilities results in impro ved p erfor- mance, across the entire trade-off curve. That is, the curve shifts down wards. In the first t wo plots based on data from symmetric distributions (Gaussian and Laplace), the av erage no de centers are nearly optimal, whic h explains why the red solid and green dotted lines coalesce. This can b e also established formally . In the third plot, based on the non-symmetric c hi-squared data, optimizing o ver node cen ters leads to further improv ement, which gets more pronounced with increased com- m unication budget. It is p ossible to generate data where the difference b etw een an y pair of the three trade-off curves b ecomes arbitrarily large. Finally , the blac k cross represen ts performance of the quan tization proto col from Example 4 . This approac h app ears as a single p oint in the trade-off space due to lac k of any parameters to b e fine-tuned. 7 F urther Considerations In this section we outline further ideas worth consideration. How ever, we lea ve a detailed analysis to future work. 7.1 Bey ond Binary Enco ders W e can generalize the binary enco ding proto col ( 1 ) to a k -ary proto col. T o illustrate the concept without unnecessary notation ov erload, w e present only the ternary (i.e., k = 3) case. Let the collection of parameters { p 0 ij , p 00 ij , ¯ X 0 i , ¯ X 00 i } define an enco ding proto col α as follows: Y i ( j ) = ¯ X 0 i with probabilit y p 0 ij , ¯ X 00 i with probabilit y p 00 ij , 1 1 − p 0 ij − p 00 ij X i ( j ) − p 0 ij ¯ X 0 i − p 00 ij ¯ X 00 i with probabilit y 1 − p 0 ij − p 00 ij . (21) It is straigh tforward to generalize Lemmas 3.1 and 3.2 to this case. W e omit the pro ofs for brevit y . 15 Lemma 7.1 (Un biasedness) . The encoder α defined in ( 21 ) is unbiased. That is, E α [ α ( X i )] = X i for all i . As a result, Y is an un biased estimate of the true a verage: E α [ Y ] = X . Lemma 7.2 (Mean Squared Error) . Let α = α p 0 ij , p 00 ij , ¯ X 0 i , ¯ X 00 i b e the proto col defined in ( 21 ). Then M S E α ( X 1 , . . . , X n ) = 1 n 2 n X i =1 d X j =1 p 0 ij X i ( j ) − ¯ X 0 i 2 + p 00 ij X i ( j ) − ¯ X 00 i 2 + p 0 ij ¯ X 0 i + p 00 ij ¯ X 00 i 2 . W e exp ect the k -ary proto col to lead to b etter (lo wer) MSE b ounds, but at the exp ense of an increase in communication cost. Whether or not the trade-off offered by k > 2 is b etter than that for the k = 2 case in vestigated in this pap er is an interesting question to consider. 7.2 Prepro cessing via Random Rotations F ollowing the idea prop osed in [ 10 ], one can explore an enco ding protocol α Q whic h arises as the comp osition of a random rotation, Q , applied to X i for all i , follow ed b y the proto col α describ ed in Section 3 . Letting Z i = QX i and Z = 1 n P i Z i , we thus hav e Y i = α ( Z i ) , i = 1 , 2 , . . . , n. With this proto col we asso ciate the deco der γ ( Y 1 , . . . , Y n ) = 1 n P n i =1 Q − 1 Y i . Note that M S E α,γ = E h k γ ( Y 1 , . . . , Y n ) − X k 2 i = E h Q − 1 γ ( Y 1 , . . . , Y n ) − Q − 1 Z 2 i = E h k γ ( α ( Z 1 ) , . . . , α ( Z n )) − Z k 2 i = E h E h k γ ( α ( Z 1 ) , . . . , α ( Z n )) − Z k 2 | Q ii . This approac h is motiv ated by the follo wing observ ation: a random rotation can be identified b y a single random seed, which is easy to comm unicate to the server without the need to communicate all floating p oint en tries defining Q . So, a random rotation pre-pro cessing step implies only a minor comm unication o verhead. Ho wev er, if the preprocessing step helps to dramatically reduce the MSE, we get an impro vemen t. Note that the inner exp ectation ab ov e is the formula for MSE of our basic enco ding-deco ding proto col, given that the data is Z i = QX i instead of { X i } . The outer exp ectation is o ver Q . Hence, w e would like the to find a mapping Q which tends to transform the data { X i } in to new data { Z i } with b etter MSE, in exp ectation. F rom now on, for simplicity assume the no de cen ters are set to the av erage, i.e., ¯ Z i = 1 d P d j =1 Z i ( j ). F or an y vector x ∈ R d , define σ ( x ) def = d X j =1 ( x ( j ) − ¯ x ) 2 = k x − ¯ x 1 k 2 , 16 where ¯ x = 1 d P j x ( j ) and 1 is the v ector of all ones. F urther, for simplicity assume that p ij = p for all i, j . Then using Lemma 3.2 , we get M S E = 1 − p pn 2 n X i =1 E Q k Z i − ¯ Z i 1 k 2 = 1 − p pn 2 n X i =1 E Q [ σ ( QX i )] . It is in teresting to in vestigate whether choosing Q as a random rotation, rather than iden tity (whic h is the implicit choice done in previous sections), leads to improv emen t in MSE, i.e., whether w e can in some w ell-defined sense obtain an inequality of the t yp e X i E Q [ σ ( QX i )] X i σ ( X i ) . This is the case for the quan tization proto col proposed in [ 10 ], whic h arises as a sp ecial case of our more general proto col. This is because the quan tization proto col is sub optimal within our family of enco ders. Indeed, as we ha ve shown, with a different choice of the parameter we can obtained results whic h impro ve, in theory , on the rotation + quantization approach. This suggests that p erhaps combining an appropriately chosen rotation pre-pro cessing step with our optimal enco der, it may b e p ossible to achiev e further improv ements in MSE for any fixed comm unication budget. Finding suitable random rotations Q requires a careful study whic h we leav e to future researc h. References [1] Mark Bra verman, Ankit Garg, T engyu Ma, Huy L. Nguy en, and Da vid P . W o o druff. Com- m unication low er bounds for statistical estimation problems via a distributed data pro cessing inequalit y . , 2015. [2] Ankit Garg, T engyu Ma, and Huy L. Nguy en. On comm unication cost of distributed statistical estimation and dimensionalit y . In A dvanc es in Neur al Information Pr o c essing Systems 27 , pages 2726–2734, 2014. [3] Jakub Koneˇ cn ´ y, H. Brendan McMahan, Daniel Ramage, and Peter Ric ht´ arik. F ederated optimization: distributed machine learning for on-device intelligence. , 2016. [4] Jakub Koneˇ cn´ y, H. Brendan McMahan, F elix X. Y u, P eter Ric ht´ arik, Ananda Theertha Suresh, and Dav e Bacon. F ederated learning: Strategies for improving comm unication efficiency . arXiv:1610.05492 , 2016. [5] Chenxin Ma, Jakub Kone ˇ cn´ y, Martin Jaggi, Virginia Smith, Mic hael I. Jordan, P eter Rich t´ arik, and Martin T ak´ a ˇ c. Distributed optimization with arbitrary local solv ers. , 2015. [6] Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan, Peter Ric ht´ arik, and Martin T ak´ aˇ c. Adding vs. a v eraging in distributed primal-dual optimization. In Pr o c e e dings of The 32nd International Confer enc e on Machine L e arning , pages 1973–1982, 2015. [7] H. Brendan McMahan, Eider Mo ore, Daniel Ramage, and Blaise Aguera y Arcas. F ederated learning of deep netw orks using mo del av eraging. , 2016. 17 [8] Sashank J. Reddi, Jakub Kone ˇ cn´ y, Peter Rich t´ arik, Barnab´ as P´ ocz´ os, and Alex Smola. Aide: F ast and comm unication efficient distributed optimization. , 2016. [9] P eter Ric h t´ arik and Martin T ak´ aˇ c. Distributed co ordinate descen t metho d for learning with big data. Journal of Machine L e arning R ese ar ch , 17(75):1–25, 2016. [10] Ananda Theertha Suresh, F elix X. Y u, H. Brendan McMahan, and Sanjiv Kumar. Distributed mean estimation with limited communication. , 2016. [11] Wikip edia. V ariable-length quantit y , 2016. [Online; accessed 9-No v-2016]. [12] F elix X. Y u, Ananda Theertha Suresh, Krzysztof Choromanski, Daniel Holtmann-Rice, and Sanjiv Kumar. Orthogonal random features. arXiv pr eprint arXiv:1610.09072 , 2016. [13] Y uchen Zhang, John Duchi, Mic hael I. Jordan, and Martin J. W ain wright. Information- theoretic lo wer b ounds for distributed statistical estimation with communication constraints. In A dvanc es in Neur al Information Pr o c essing Systems 26 , pages 2328–2336, 2013. [14] Y uchen Zhang, Martin J. W ainwrigh t, and John C. Duchi. Communication-efficien t algorithms for statistical optimization. In A dvanc es in Neur al Information Pr o c essing Systems , pages 1502–1510, 2012. A Additional Pro ofs In this section we provide pro ofs of Lemmas 3.3 and 3.4 , describing prop erties of the enco ding proto col α defined in ( 4 ). F or completeness, we also rep eat the statements. Lemma A.1 (Unbiasedness) . The enco der α defined in ( 1 ) is un biased. That is, E α [ α ( X i )] = X i for all i . As a result, Y is an un biased estimate of the true a verage: E α [ Y ] = X . Pr o of. Since Y ( j ) = 1 n P n i =1 Y i ( j ) and X ( j ) = 1 n P n i =1 X i ( j ), it suffices to show that E α [ Y i ( j )] = X i ( j ): E α [ Y i ( j )] = 1 | σ k ( d ) | X σ ∈ σ k ( d ) 1 ( j ∈ σ ) dX i ( j ) k − d − k k µ i + 1 ( j 6∈ σ ) µ i = d k − 1 d − 1 k − 1 dX i ( j ) k − d − k k µ i + d − 1 k µ i = d k − 1 d − 1 k − 1 d k X i ( j ) + d − 1 k − d − 1 k − 1 d − k k µ i = X i ( j ) and the claim is prov ed. 18 Lemma A.2 (Mean Squared Error) . Let α = α ( k ) b e e ncoder defined as in ( 4 ). Then M S E α ( X 1 , . . . , X n ) = 1 n 2 n X i =1 d X j =1 d − k k ( X i ( j ) − µ i ) 2 . Pr o of. Using Lemma 2.3 , w e hav e M S E α ( X 1 , . . . , X n ) = 1 n 2 n X i =1 E α h k Y i − X i k 2 i = 1 n 2 n X i =1 E α d X j =1 ( Y i ( j ) − X i ( j )) 2 = 1 n 2 n X i =1 d X j =1 E α ( Y i ( j ) − X i ( j )) 2 . (22) F urther, E α ( Y i ( j ) − X i ( j )) 2 = d k − 1 X σ ∈ σ k ( d ) " 1 ( j ∈ σ ) dX i ( j ) k − d − k k µ i − X i ( j ) 2 + 1 ( j 6∈ σ ) ( µ i − X i ( j )) 2 # = d k − 1 d − 1 k − 1 ( d − k ) 2 k 2 ( X i ( j ) − µ i ) 2 + d − 1 k ( µ i − X i ( j )) 2 = d − k k ( X i ( j ) − µ i ) 2 . It suffices to substitute the abov e into ( 22 ). 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment