분산 평균 추정의 정확도와 통신 비용 트레이드오프
본 논문은 통신 예산이 제한된 환경에서 여러 노드에 분산된 실수 벡터들의 평균을 추정하는 문제를 다룬다. 통계적 가정을 두지 않고, 확률적 양자화와 압축 방식을 결합한 파라미터화된 랜덤 인코더/디코더 체계를 제안한다. 기대 통신 비트 수와 평균 제곱 오차(MSE) 사이의 명시적 관계를 도출하고, 한 비트당 평균 오차가 O(r/n)인 새로운 방법을 제시한다. 또한, 최적 확률 선택과 센터값 설정을 통해 실제 데이터셋에서 통신 효율과 정확도 사이의…
저자: Jakub Konev{c}ny, Peter Richtarik
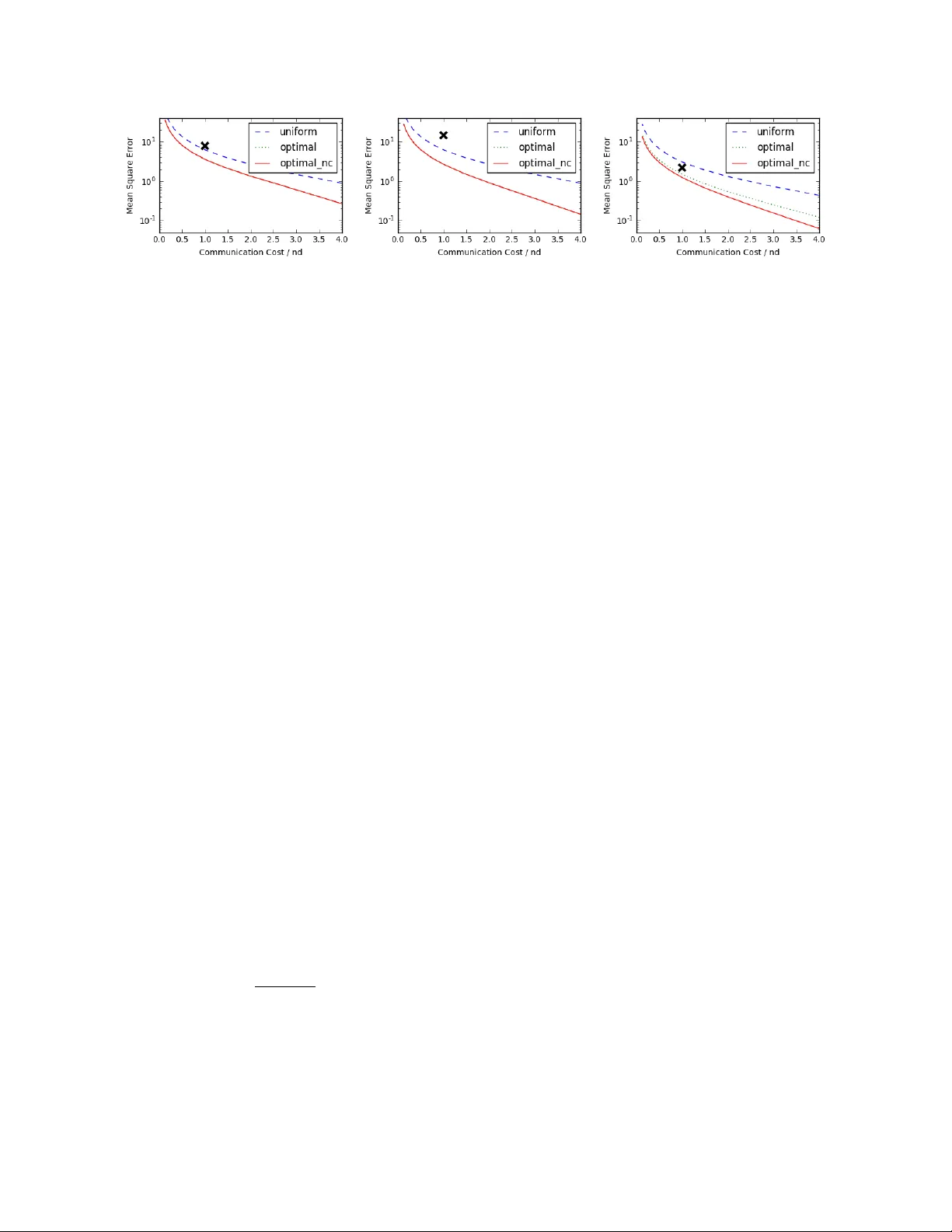
본 연구는 다수의 컴퓨팅 노드에 분산 저장된 d 차원 실수 벡터 X₁,…,Xₙ의 산술 평균 X = (1/n)∑₁ⁿ X_i 를, 제한된 통신 예산 하에서 정확히 추정하는 문제를 다룬다. 기존 연구는 주로 X_i 가 i.i.d. 샘플이라는 통계적 전제를 두고 최소화 가능한 통신량과 최소 MSE 사이의 경계(미니맥스)를 분석했지만, 실제 분산 학습·최적화 시나리오에서는 X_i 가 시간에 따라 변하고, 사전 분포에 대한 지식이 거의 없으며, 통신 비용이 주된 병목이 된다. 따라서 저자는 통계적 가정을 완전히 배제하고, 무편향(unbiased) 랜덤 인코더와 평균 디코더를 기반으로 한 파라미터화된 프레임워크를 제시한다.
### 1. 문제 설정 및 기본 정의
- 네트워크 토폴로지는 스타형이며, 각 노드 i는 자신의 벡터 X_i 를 서버에 전송한다.
- 인코더 α: X_i → Y_i ∈ ℝ^d 로, Y_i는 확률적 변환이며 무편향성 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기