Deep Learning Approximation for Stochastic Control Problems
Many real world stochastic control problems suffer from the "curse of dimensionality". To overcome this difficulty, we develop a deep learning approach that directly solves high-dimensional stochastic control problems based on Monte-Carlo sampling. W…
Authors: Jiequn Han, Weinan E
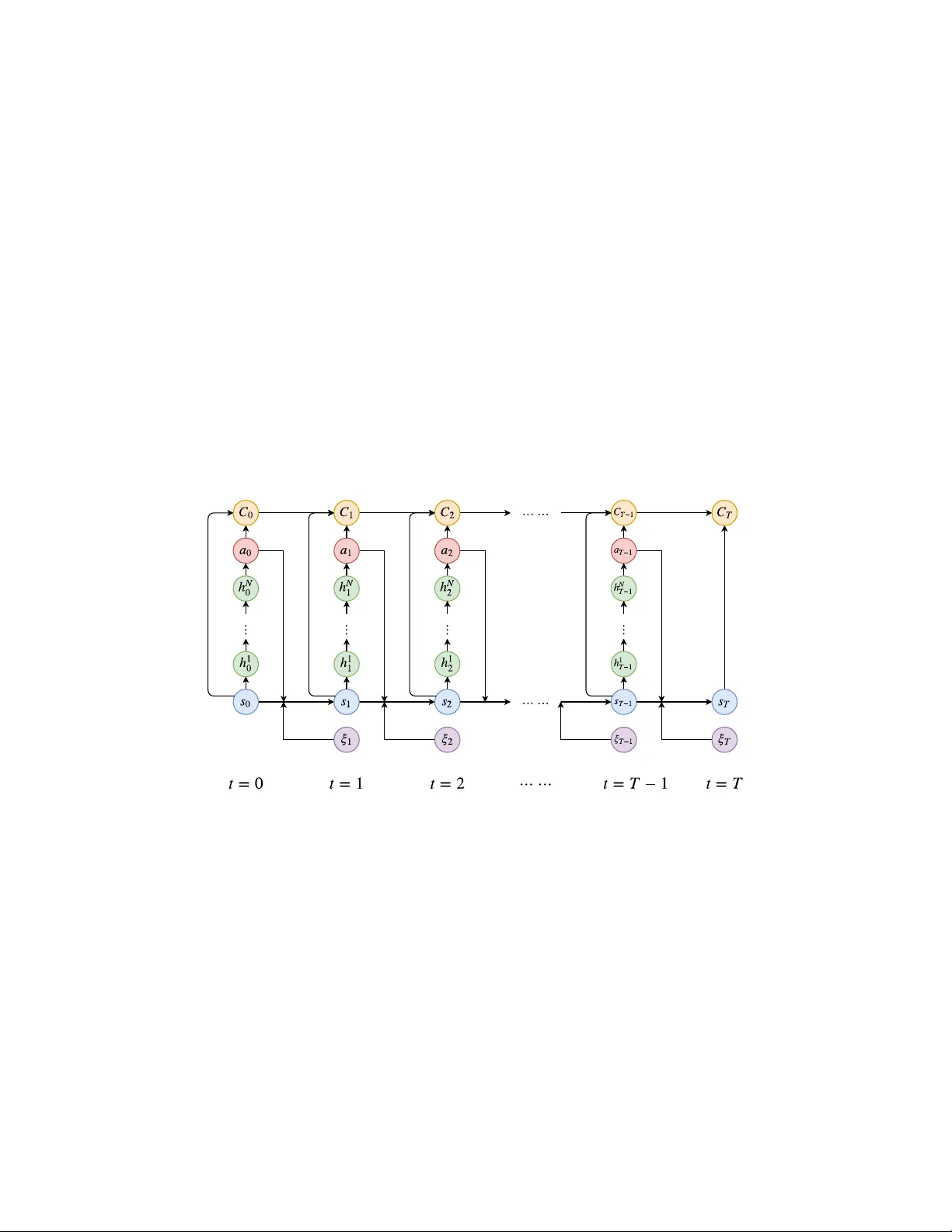
Deep Lear ning A ppr oximation f or Stochastic Contr ol Pr oblems Jiequn Han 1 and W einan E 1,2,3 1 The Program of Applied Mathematics, Princeton Univ ersity 2 School of Mathematical Sciences, Peking Univ ersity 3 Beijing Institute of Big Data Research Abstract Many real world stochastic control problems suf fer from the “curse of dimensional- ity”. T o o vercome this dif ficulty , we dev elop a deep learning approach that directly solves high-dimensional stochastic control problems based on Monte-Carlo sam- pling. W e approximate the time-dependent controls as feedforw ard neural networks and stack these networks together through model dynamics. The objective function for the control problem plays the role of the loss function for the deep neural network. W e test this approach using examples from the areas of optimal trading and energy storage. Our results suggest that the algorithm presented here achiev es satisfactory accuracy and at the same time, can handle rather high dimensional problems. 1 Introduction The traditional way of solving stochastic control problems is through the principle of dynamic programming. While being mathematically elegant, for high-dimensional problems this approach runs into the technical difficulty associated with the “curse of dimensionality”. In fact, it is precisely in this context that the term w as first introduced, by Richard Bellman [ 1 ]. It turns out that the same problem is also at the heart of many other subjects such as machine learning and quantum man y-body physics. In recent years, deep learning has shown impressi ve results on a v ariety of hard problems in machine learning [ 2 – 5 ], suggesting that deep neural networks might be an effecti ve tool for dealing with the curse of dimensionality problem. It should be emphasized that although there are partial analytical results, the reason why deep neural networks ha ve performed so well still lar gely remains a mystery . Ne vertheless, it moti vates using the deep neural netw ork approximation in other conte xts where curse of dimensionality is the essential obstacle. In this paper , we de velop the deep neural network approximation in the conte xt of stochastic control problems. Even though this is not such an une xpected idea, and has in fact already been e xplored in the context of reinforcement learning [ 6 ], a subject that overlaps substantially with control theory , our formulation of the problem still has some merits. First of all, the framew ork we propose here is much simpler than the corresponding work for reinforcement learning. Secondly , we study the problem in finite horizon. This makes the optimal controls time dependent. Thirdly , instead of formulating approximations to the value function as is commonly done [ 7 ], our formulation is in terms of approximating the optimal control at each time. In fact, the control at each time step is approximated by a feedforward subnetwork. W e stack these subnetworks together to form a very deep network and train them simultaneously . Numerical examples in section 4 suggest that this approximation can achiev e near -optimality and at the same time handle high-dimensional problems with relativ e ease. W e note in passing that research on similar stochastic control problems has ev olv ed under the name of deep reinforcement learning in the artificial intelligence (AI) community [ 8 – 12 ]. As was stressed in [ 13 ], most of these papers deal with the infinite horizon problem with time-independent policy . In contrast, our algorithm only in volves a single deep network obtained by stacking together , through model dynamics, the different subnetw ork approximating the time-dependent controls. In dealing with high-dimensional stochastic control problems, the con ventional approach taken by the operations research (OR) community has been “approximate dynamic programming” (ADP) [ 7 ]. There are tw o essential steps in ADP . The first is replacing the true v alue function using some function approximation. The second is adv ancing forward in time from a sample path with backw ard sweep to update the v alue function. Unlike ADP , we do not deal with v alue function at all. W e deal directly with the controls. In addition, our approximation scheme appears to be more generally applicable. 2 Mathematical formulation W e consider a stochastic control problem with finite time horizon T on a probability space (Ω , F , P ) with a filtration F 0 ⊂ F 1 ⊂ · · · ⊂ F T = F . Throughout the paper we adopt the con vention that an y variable inde x ed by t is F t -measurable. W e use s t ∈ S t ⊂ R m to denote the state variable, where S t is the set of potential states. The control v ariable is denoted by a t ∈ R n . Our setting is model-based. W e assume that the ev olution of the system is described by the stochastic model: s t +1 = s t + b t ( s t , a t ) + ξ t +1 . (1) Here b t is the deterministic drift term giv en by the model. ξ t +1 ∈ R n is a F t +1 -measurable random variable that contains all the noisy information arri ving between time t and t + 1 . One can vie w this as a discretized version of stochastic differential equations. T o ensure generality of the model, we allow some state-dependent constraints on the control for all t : g i ( s t , a t ) = 0 , for i = 1 , . . . , I . (2) h j ( s t , a t ) ≥ 0 , for j = 1 , . . . , J. (3) Assuming the state v ariable s t completely characterizes the model (in the sense that the optimal control a t depends only on the current state s t ), we can write the set of admissible functions for a t as a t ∈ A t = a t ( s t ) : R m → R n g i ( s t , a t ) = 0 for i = 1 , . . . , I , ∀ s t ∈ S t h j ( s t , a t ) ≥ 0 for j = 1 , . . . , J, ∀ s t ∈ S t . (4) Our problem is finally formulated as (taking minimization for example) min a t ∈A t , t =0 , ··· ,T − 1 E C T | s 0 = min a t ∈A t , t =0 , ··· ,T − 1 E T − 1 X t =0 c t ( s t , a t ( s t )) + c T ( s T ) | s 0 , (5) where c t ( s t , a t ) is the intermediate cost, c T ( s T ) is the final cost and C T is the total cost. For later purpose we also define the cumulativ e cost C t = t X τ =0 c τ ( s τ , a τ ) , t < T . (6) 3 An neural network approximation algorithm Our task is to approximate the functional dependence of the control on the state, i.e. a t as a function of s t . Here we assumed that there are no memory ef fects b ut if necessary , memory ef fects can also be taken into account with no dif ference in principle. W e represent this dependence by a multilayer feedforward neural network, a t ( s t ) ≈ a t ( s t | θ t ) , (7) where θ t denotes parameters of the neural network. Note that we only apply the nonlinear activ ation function at the layers for the hidden variables and no activ ation function is used at the final layer . 2 T o better explain the algorithm, we assume temporarily that there are no other constraints but the F t -measurability for the control. Then the optimization problem becomes min { θ t } T − 1 t =0 E T − 1 X t =0 c t ( s t , a t ( s t | θ t )) + c T ( s T ) } . (8) Here for clarity , we ignore the conditional dependence on the initial distribution. A key observ ation for the deriv ation of algorithm is that giv en a sample of the stochastic process { ξ t } T t =1 , the total cost C T can be regarded as the output of a deep neural network. The general architecture of the network is illustrated in Figure 1. Note that there are three types of connections in this network: 1) s t → h 1 t → h 2 t → · · · → h N t → a t is the multilayer feedforward neural netw ork approximating the control at time t . The weights θ t of this subnetwork are the parameters we aim to optimize. 2) ( s t , a t , C t ) → C t +1 is the direct contribution to the final output of the network. Their functional form is determined by the cost function c t ( s t , a t ) . There are no parameters to be optimized in this type of connection. 3) ( s t , a t , ξ t +1 ) → s t +1 is the shortcut connecting blocks at dif ferent time, which is completely characterized by (1). There are also no parameters to be optimized in this type of connection. If we use N hidden layers in each subnetwork, as illustrated in Figure 1, then the whole network has ( N + 2) T layers in total. Figure 1: Illustration of the network architecture for stochastic control problems with N hidden layers for each subnetwork. Each column (except ξ t ) corresponds to a subnetwork at t . h 1 t , ...h N t are the hidden variables in the subnetw ork at time t . T o deal with constraints, we revise the cumulati ve cost C t in Figure 1 by introducing: C t ← C t + I X i =1 λ i P e ( g i ( s t , a t )) + J X j =1 σ j P ie ( h j ( s t , a t )) , t < T . (9) Here P e ( · ) , P ie ( · ) are the penalty functions for equality and inequality constraints while λ i , σ j are penalty coefficients. Specific examples can be found belo w . W e should stress that in the testing stage, we project the optimal controls we learned to the admissible set to ensure that they strictly satisfy all the constraints. 3.1 T raining algorithm During training we sample { ξ t } T t =1 as the input data and compute C T from the neural network. The standard stochastic gradient descent (SGD) method with backpropagation can be easily adapted 3 to this situation. The training algorithm can be easily implemented using common libraries ( e.g. , T ensorFlo w [ 14 ]) without modifying the SGD-type optimizers. W e also adopted the technique of batch normalization [ 15 ] in the subnetworks, right after each linear transformation and before activ ation. This method accelerates the training by allo wing a lar ger step size and easier parameter initialization. 3.2 Implementation W e briefly mention some details of the implementation. All our numerical examples are run on a Dell desktop with 3.2GHz Intel Core i7, without any GPU accerleration. W e use T ensorFlow to implement our algorithm with the Adam optimizer [ 16 ] to optimize parameters. Adam is an v ariant of the SGD algorithm, based on adapti ve estimates of lo wer-order moments. W e set the def ault v alues for corresponding hyper -parameters as recommended in [ 16 ]. T o deal with the constraints, we choose the quadratic function as penalty functions: P e ( x ) = x 2 and P ie ( x ) = min { 0 , x 2 } . (10) For the architecture of the subnetworks, we set the number of layers to 4, with 1 input layer (for the state variable), 2 hidden layers and 1 output layer (representing the control). W e choose rectified linear unit (ReLU) as our activ ation function for the hidden v ariables. All the weights in the network are initialized using a normal distribution without an y pre-training. In the numerical results reported belo w , to facilitate the comparison with the benchmark, we fix the initial state to some deterministic value rather than from a random distrib ution. Therefore the optimal control at t = 0 is also deterministic and batch normalization is skipped at t = 1 . 4 Numerical results and discussion 4.1 Execution costs for portfolios Our first example is in the area of finance. It is concerned with minimizing the expected cost for trading blocks of stocks ov er a fix ed time horizon. When a portfolio requires frequent rebalancing, large orders across many stocks may appear , which must be ex ecuted within a relati vely short time horizon. The execution costs associated with such tradings are often substantial, and this calls for smart trading strategies. Here we consider a linear percentage price-impact model based on the work of [ 17 , 18 ]. The reason we choose this example is that it has an analytic solution, which facilitates the ev aluation of our numerical solutions. Denote by a t = ( a 1 t , a 2 t , · · · , a nt ) T ∈ R n the number of shares of each stock bought in period t at price p t = ( p 1 t , p 2 t , · · · , p nt ) T ∈ R n , t = 0 , 1 , · · · , T − 1 . The in vestor’ s objective is to min { a t } T − 1 t =0 E T − 1 X t =0 p T t a t , (11) subject to P T − 1 t =0 a t = ¯ a ∈ R n , where ¯ a denotes the shares of the n stocks to be purchased within time T . The ex ecution price p t is assumed to be the sum of two components p t = ˜ p t + δ t . Here ˜ p t is the “no-impact” price, modeled by geometric Brownian motion, and δ t is the impact price, modeled by δ t = ˜ P t ( A ˜ P t a t + B x t ) , (12) where ˜ P t = diag [ ˜ p t ] , x t ∈ R m captures the potential influence of market conditions and A ∈ R n × n , B ∈ R n × m . T o complete the model specification, we set the dynamics of x t as a simple multiv ariate autoregressiv e process: x t = C x t − 1 + η t , (13) where η t is a white noise vector and C ∈ R m × m . The state variable of this model can be chosen as ( ˜ p t , x t , w t ) , where w t denotes the remaining shares to be bought at time t . This problem can be 4 solved analytically using dynamic programming, see [ 18 ] for the analytic expression of the optimal ex ecution strategy and the corresponding optimal cost. In our implementation, all the parameters of the model are assigned with realistic values. W e choose n = 10 and m = 3 , which gi v es us a generic high-dimensional problem with the control space: R 23 → R 10 . W e set the number of hidden units in the tw o hidden layers to 100, the initial learning rate to 0.001, the batch size to 64 and iteration steps to 15000. The learning curves over fi v e different random seeds with different time horizons are plotted in Figure 2. analytic optimal cost 0 20 40 60 4000 8000 12000 iteration relative tr ading cost Time horizon T=20 T=25 T=30 (a) relative trading c ost 0.0 2.5 5.0 7.5 4000 8000 12000 iteration relative error f or the controls Time horizon T=20 T=25 T=30 (b) relative error for the control s Figure 2: Relati ve trading cost and relati ve error for the controls (compared to the exact solution) as a function of the number of iterations on v alidation samples. The shaded area depicts the mean ± the standard de viation o ver five different random seeds. The a verage relative trading cost and relative error for the controls on test samples are 1 . 001 , 1 . 002 , 1 . 009 and 3 . 7% , 3 . 7% , 8 . 6% for T = 20 , 25 , 30 . The av erage running time is 605 s, 778 s, 905 s respecti vely . The dashed line in Figure 2 (a) represents the analytical optimal trading cost (rescaled to 1), defined as the optimal ex ecution cost in cents/share abo ve the no-impact cost p T 0 ¯ a . For this problem, the objectiv e function achie v es near-optimality with good accuracy: average relati v e trading cost to the exact solution are 1 . 001 , 1 . 002 , 1 . 009 for T = 20 , 25 , 30 . From Figure 2 (b) we also observe that computed optimal strategy approximates the exact solution well. Note that for T = 30 , there are 120 layers in total. In most practical applications, there are usually constraints on ex ecution strate gies. F or example, a feasible buying strate gy might require a t to be nonnegati ve. Such constraints can be imposed easily 5 by adding penalty terms in our algorithm. Here we leave the optimization task with constraints to the next e xample. 4.2 Energy storage and allocation benchmark Storage of wind energy has recently recei ved significant attention as a way to increase the efficienc y of the electrical grid. Practical and adaptive methods for the optimal energy allocation on such power systems are critical for them to operate reliably and economically . Here we consider an allocation problem from [ 19 , 20 ], which aims at optimizing rev enues from a storage device and a renew able wind energy source while satisfying stochastic demand. The model is set up as follows. Let the state variable be s t = ( r t , w t , p t , d t ) , where r t is the amount of energy in the storage device, w t is the amount of energy produced by the wind source, p t is the price of electricity on the spot market, and d t is the demand to be satisfied. Let γ c , γ d be the maximum rates of charging and discharging from the storage device respectiv ely , and r max be the capacity of the storage device. The control variable is giv en by a t = ( a wd t , a md t , a rd t , a wr t , a rm t ) , where a ij t is the amount of ener gy transferred from i to j at time t . The superscript w stands for wind, d for demand, r for storage and m for spot market. Figure 3 illustrates the meaning of the control components in a network diagram. Demand Storage Wind Source Spot Market Figure 3: Network diagram for the ener gy storage problem. W e require that all components of a t be nonnegati ve. W e also require: a wd t + a rd t + a md t = d t , a wr t + a wd t ≤ w t , a rd t + a rm t ≤ min { r t , γ d } , a wr t ≤ min { r max − r t , γ c } . The intermediate rew ard function at time t is c t ( s t , a t ) = p t ( d t + a rm t − a md t ) . (14) Here we do not consider the holding cost. Let φ = (0 , 0 , − 1 , 1 , − 1) T . The dynamics for r t is characterized by r t +1 = r t + φ T a t , (15) and w t , p t , d t are modeled by first-order Markov chains in bounded domains, which are all indepen- dent from the control (See S2 case in [20] for the exact specification). T o maximize the total re ward, we need to find optimal control in the space R 4 → R 5 . Since all the components of control should be negati ve, we add a ReLU acti v ation at the final layer of each subnetwork. W e set the number of hidden units in the two hidden layers to 400, the batch size to 256, all the penalty coefficients to 500 and iteration steps to 50000. The learning rate is 0.003 for the first half of the iterations and 0.0003 for the second half. In the literature, man y algorithms for multidimensional stochastic control problems, e .g. the ones in [ 19 , 20 ], proceed by discretizing the state variable and the control v ariable into a finite set, and present the optimal control in the form of a lookup table. In contrast, our algorithm can handle continuous variables directly . Ho we ver , for the ease of comparison with the optimal lookup table obtained from backward dynamic programing as in 6 benchmark reward of lookup table 0.96 0.97 0.98 0.99 1.00 0 10000 20000 30000 40000 50000 iteration relative re ward Time horizon T=10 T=15 Figure 4: Relativ e rew ard as a function of the number of iterations on validation samples, with optimal lookup table obtained from backward dynamic programming being a benchmark. The shaded area depicts the mean ± the standard deviation ov er fi ve dif ferent random seeds. The av erage relativ e rew ard on test samples is 1 . 002 , 0 . 995 for T = 10 , 15 . The average running time is 5041 s and 8150 s. [ 20 ], here we artificially confine w t , p t , d t to the values in their lookup table. The relativ e reward ov er fi ve dif ferent random seeds are plotted in Figure 4. Despite the presence of multiple constraints, our algorithm still gives near -optimal re ward. When T = 10 , the neural-network polic y gi v es e ven higher e xpected re ward than the lookup table policy . It should be noted that if we relax the discretization constraint we imposed on w t , p t , d t , then our method can achiev e better re ward than the lookup table in both cases of T = 10 and 15 . The learning curves in Figure 4 display clearly a feature of our algorithm for this problem: as time horizon increases, variance becomes larger with the same batch size and more iteration steps are required. W e also see that the learning curves are rougher than those in the first example. This might be due to the presence of multiple constraints that result in more nonlinearity in the optimal control policy . 4.3 Multidimensional energy storage Now we extend the pre vious example to the case of n devices and test the algorithm’ s performance for the rather high dimensional problems, in which we do not find any other a v ailable solution for comparison. W e consider the situation of pure arbitrage, i.e . d t = 0 for all t , and allo w buying electricity from the spot market to store in the device. The state variable is s t = ( r t , w t , p t ) ∈ R n +2 where r t = ( r 1 t , r 2 t , · · · , r nt ) ∈ R n is the resource vector denoting the storage of each de vice. The control variable is characterized by a t = ( a wr 1 t , a rm 1 t , a mr 1 t , · · · , a wr nt , a rm nt , a mr nt ) ∈ R 3 n . r i, max , γ c i , γ d i denote the energy capacity , maximum charging rates and discharging rates of storage device i respectiv ely . W e also introduce η c i , η d i , which are no lar ger than 1 , as the char ging and dischar ging efficienc y of storage de vice i . The holding cost is no longer zero as before, b ut denoted by β i . The intermediate rew ard function at time t is revised to be c t ( s t , a t ) = n X i =1 p t ( η d i a rm it − a mr it ) − β i r it , (16) and the dynamics for r it becomes r i ( t +1) = r it + φ T i a it , (17) with φ i = ( η c i , − 1 , η c i ) T . W e make a simple but realistic assumption that a device with higher energy capacity r i, max has lower power transfer capacity γ c i , γ d i , lower ef ficienc y η c i , η d i and lower holding cost β i . All these model 7 0.6 0.7 0.8 0.9 1.0 1.1 10000 20000 30000 40000 50000 iteration rew ard relative to the case n=50 Number of devices n=30 n=40 n=50 Figure 5: Rew ard relati ve to the expected total re ward (with controls satisfying constraints strictly) in the case n = 50 as a function of the number of iterations on validation samples. The shaded area depicts the mean ± the standard deviation ov er five different random seeds. The average relativ e rew ard on test samples is 0 . 926 , 0 . 965 for n = 30 , 40 . The av erage running time for three cases is 6672 s, 8374 s and 10219 s. parameters are distributed in the bounded domains. As the number of devices increases, we look for more refined allocation policy and the e xpected re ward should be lar ger . W e use the same learning parameters as in the case of single device except that we reduce all the penalty coefficients to 30 and batch size to 64 . Learning curv es plotted in Figure 5 confirms our expectation that the re ward increases as the number of devises increases. The learning curves behav e similarly as in the case of a single de vice and different random initializations still gi ve similar e xpected rew ard. Note that the function space of the control policy: R n +2 → R 3 n grows as n increases from 30 to 50, while our algorithm still finds near -optimal solution with slightly increased computational time. 5 Conclusion In this paper , we formulate a deep learning approach to directly solve high-dimensional stochastic control problems in finite horizon. W e use feedforward neural networks to approximate the time- dependent control at each time and stack them together through model dynamics. The objectiv e function for the control problem plays the role of the loss function in deep learning. Our numerical results suggest that for dif ferent problems, e v en in the presence of multiple constraints, this algorithm finds near-optimal solutions with great e xtendability to high-dimensional case. The approach presented here should be applicable to a wide variety of problems in different areas including dynamic resource allocation with many resources and demands, dynamic game theory with many agents and wealth management with large portfolios. In the literature these problems were treated under different assumptions such as separability or mean-field approximation. As suggested by the results of this paper , the deep neural network approximation should provide a more general setting and should giv e better results. References [1] Richard Ernest Bellman. Dynamic Pro gramming . Rand Corporation research study . Princeton Univ ersity Press, 1957. [2] Y . Lecun, L. Bottou, Y . Bengio, and P . Haffner . Gradient-based learning applied to document recognition. Pr oceedings of the IEEE , 86(11):2278–2324, 1998. [3] Y . Bengio. Learning deep architectures for AI. F oundations and T rends in Machine Learning , 2(1):1–127, 2009. 8 [4] Alex Krizhe vsky , Ilya Sutskever , and Geoffrey E. Hinton. Imagenet classification with deep conv olutional neural networks. In F . Pereira, C. J. C. Burges, L. Bottou, and K. Q. W einberger , editors, Advances in Neural Information Processing Systems 25 , pages 1097–1105. Curran Associates, Inc., 2012. [5] Y ann LeCun, Y oshua Bengio, and Geoffrey Hinton. Deep learning. Natur e , 521(7553):436–444, may 2015. [6] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning . The MIT Press, 1998. [7] W arren B. Powell. Appr oximate Dynamic Pr ogr amming: Solving the Curses of Dimensionality . John W iley & Sons, 2011. [8] V olodymyr Mnih, Koray Ka vukcuoglu, David Silv er , Andrei A. Rusu, et al. Human-lev el control through deep reinforcement learning. Natur e , 518(7540):529–533, February 2015. [9] David Silver , Aja Huang, Chris J. Maddison, Arthur Guez, et al. Mastering the game of Go with deep neural networks and tree search. Natur e , 529(7587):484–489, January 2016. [10] John Schulman, Serge y Le vine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In Pr oceedings of The 32nd International Conference on Machine Learning (ICML) , June 2015. [11] T imothy P . Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, and David Silv er Daan W ierstra T om Erez, Y uval T assa. Continuous control with deep reinforcement learning. In Pr oceedings of the International Confer ence on Learning Representations (ICLR) , May 2016. [12] John Schulman, Philipp Moritz, Serge y Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized adv antage estimation. In Pr oceedings of the International Confer ence on Learning Representations (ICLR) , May 2016. [13] Y an Duan, Xi Chen, Rein Houthooft, John Schulman, and Pieter Abbeel. Benchmarking deep reinforcement learning for continuous control. In Pr oceedings of The 32nd International Conference on Machine Learning (ICML) , June 2016. [14] Martín Abadi, Ashish Agarwal, P aul Barham, Eugene Bre vdo, et al. T ensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software av ailable from tensorflow .org. [15] Serge y Iof fe and Christian Szegedy . Batch normalization: accelerating deep network training by reducing internal covariate shift. In Pr oceedings of The 32nd International Confer ence on Machine Learning (ICML) , June 2015. [16] Diederik Kingma and Jimmy Ba. Adam: a method for stochastic optimization. In Pr oceedings of the International Confer ence on Learning Representations (ICLR) , May 2015. [17] Dimitris Bertsimas and Andrew W . Lo. Optimal control of ex ecution costs. Journal of F inancial Markets , 1(1):1–50, April 1998. [18] Dimitris Bertsimas, Andrew W . Lo, and P . Hummel. Optimal control of execution costs for portfolios. Computing in Science and Engineering , 1(6):40–53, November 1999. [19] Daniel F . Salas and W arren B. Powell. Benchmarking a scalable approximation dynamic programming algorithm for stochastic control of multidimensional energy storage problems. T echnical report, Princeton Univ ersity , 2013. [20] Daniel R. Jiang and W arren B. Powell. An approximate dynamic programming algorithm for monotone value functions. Operations Researc h , 63(6):1489–1511, December 2015. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment