딥러닝 기반 고차원 확률 제어 해결법
본 논문은 몬테카를로 샘플링을 이용해 고차원 확률 제어 문제를 직접 해결하는 딥러닝 프레임워크를 제안한다. 시간별 최적 제어를 피드포워드 신경망으로 근사하고, 각 시점의 네트워크를 시스템 동역학을 통해 연결해 하나의 깊은 네트워크로 구성한다. 목표 비용을 손실 함수로 사용해 전체 네트워크를 역전파로 학습한다. 최적 매매와 에너지 저장 두 사례에서 높은 차원의 문제를 만족스러운 정확도로 해결함을 실험적으로 입증한다.
저자: Jiequn Han, Weinan E
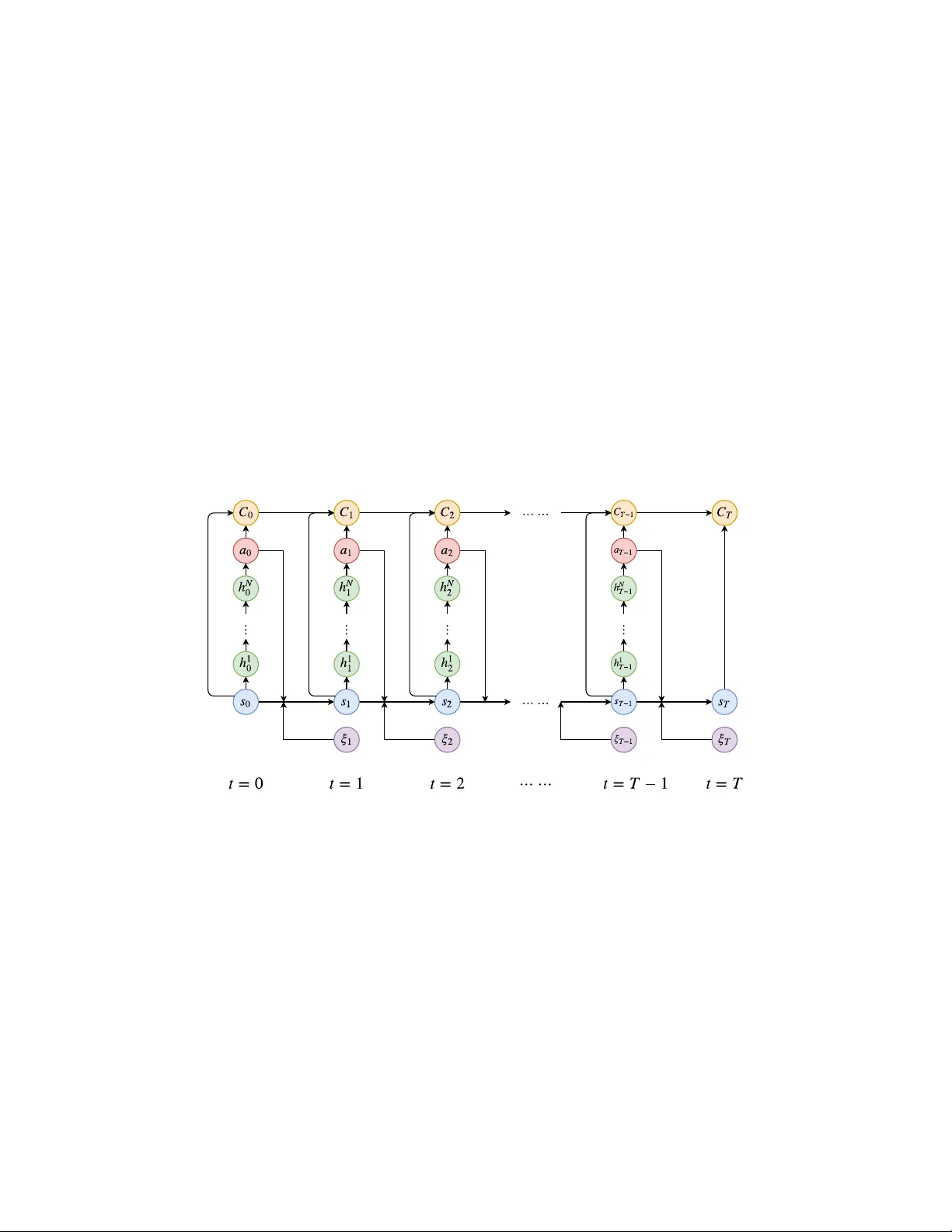
본 논문은 고차원 확률 제어 문제를 해결하기 위한 새로운 딥러닝 기반 알고리즘을 제시한다. 전통적인 동적 계획법은 상태·제어 차원이 증가함에 따라 계산량이 기하급수적으로 늘어나 ‘차원의 저주’를 겪는다. 이를 극복하고자 저자는 시간에 따라 변하는 최적 제어 정책을 직접 신경망으로 근사하고, 각 시점의 신경망을 시스템 동역학을 통해 연결함으로써 하나의 거대한 심층 네트워크를 구성한다.
**문제 설정**
확률 제어 문제는 유한 시간 horizon T 를 갖는 마코프 프로세스로 모델링된다. 상태 sₜ∈ℝᵐ, 제어 aₜ∈ℝⁿ, 그리고 노이즈 ξₜ₊₁가 주어지고, 시스템은 sₜ₊₁ = sₜ + bₜ(sₜ,aₜ) + ξₜ₊₁ 로 진화한다. 제어는 제약식 gᵢ(sₜ,aₜ)=0, hⱼ(sₜ,aₜ)≥0 를 만족해야 하며, 목표는 총 비용 C_T = Σ₀^{T-1} cₜ(sₜ,aₜ)+c_T(s_T) 를 최소화(또는 최대화)하는 것이다.
**신경망 근사**
각 시점 t마다 aₜ(sₜ) 를 다층 피드포워드 신경망 aₜ(sₜ|θₜ) 로 근사한다. 입력은 현재 상태 sₜ이며, 은닉층은 ReLU 활성화 함수를 사용하고 최종 출력층은 활성화를 적용하지 않아 연속적인 제어값을 직접 반환한다. 서브네트워크의 파라미터 θₜ 를 모두 모아 전체 파라미터 집합 Θ = {θ₀,…,θ_{T-1}} 로 정의한다.
**네트워크 구조**
전체 구조는 Figure 1에 제시된 바와 같이, 각 서브네트워크가 시간 순서대로 연결된다. 연결은 세 종류로 구분된다. (1) sₜ → h₁ₜ → … → h_Nₜ → aₜ : 제어를 생성하는 서브네트워크, (2) (sₜ,aₜ,Cₜ) → C_{t+1} : 비용 함수에 의해 결정되는 직접 연결, (3) (sₜ,aₜ,ξ_{t+1}) → s_{t+1} : 시스템 동역학에 의해 정의되는 단축 연결. 따라서 전체 네트워크는 (N+2)·T 층을 갖는 매우 깊은 구조가 된다.
**제약 처리**
제약은 페널티 방식으로 손실에 추가한다. 등식 제약은 λ_i·Pₑ(g_i)², 부등식 제약은 σ_j·Pᵢₑ(h_j)² 로 표현한다. 여기서 Pₑ(x)=x², Pᵢₑ(x)=min{0,x}² 를 사용한다. 학습 후에는 최적 제어를 허용 집합 Aₜ 로 투영(projection)해 제약을 완전히 만족하도록 한다.
**학습 알고리즘**
학습은 Monte‑Carlo 샘플링을 통해 ξₜ 시퀀스를 생성하고, 이를 입력으로 전체 비용 C_T 를 순전파한다. 손실 L(Θ)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기