Learning Influence Functions from Incomplete Observations
We study the problem of learning influence functions under incomplete observations of node activations. Incomplete observations are a major concern as most (online and real-world) social networks are not fully observable. We establish both proper and…
Authors: Xinran He, Ke Xu, David Kempe
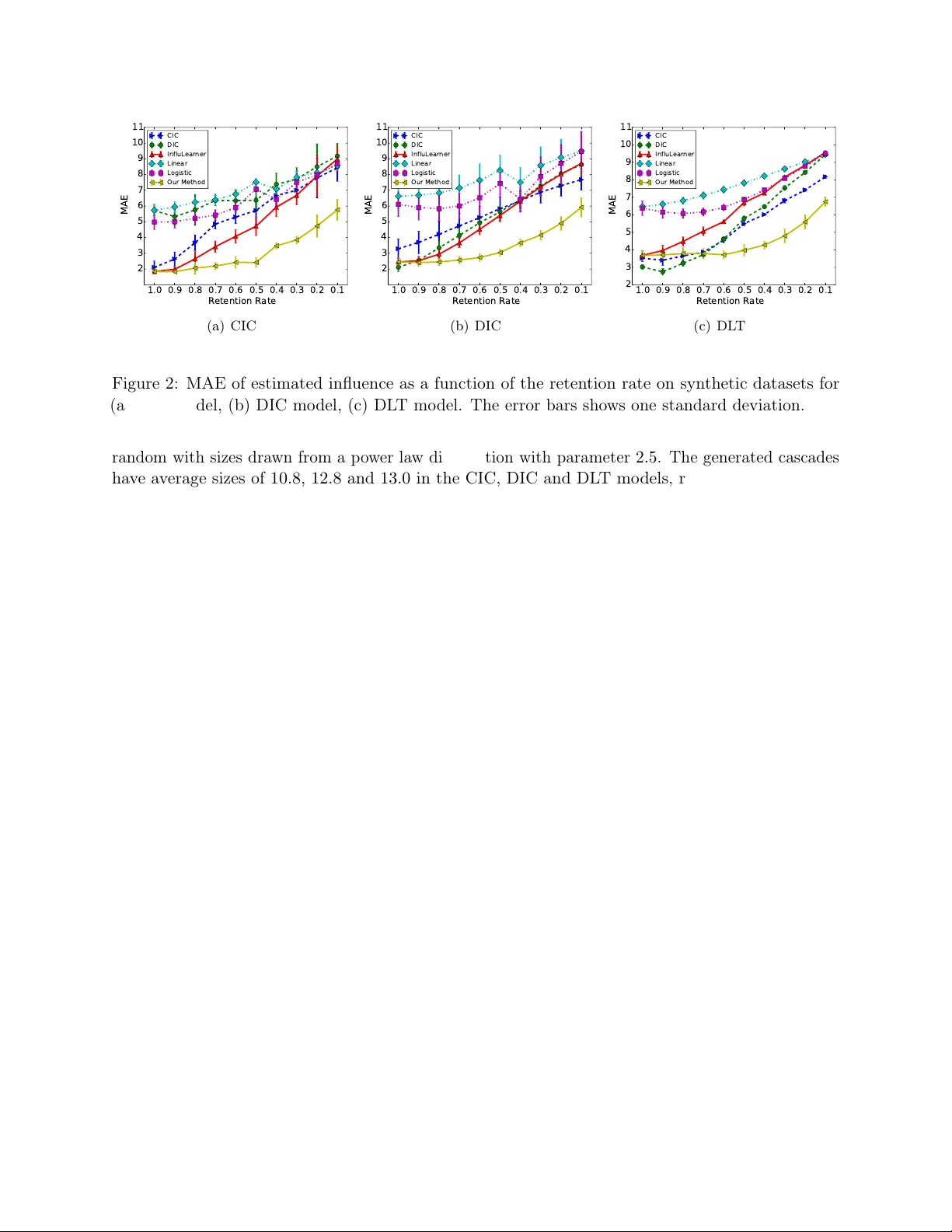
Learning Influence F unctions from Incomplete Observ ations Xinran He Ke Xu Da vid Kemp e Y an Liu Univ ersit y of Southern California, Los Angeles, CA 90089 {xinranhe, xuk, dkempe, yanliu.cs}@usc.edu No v em b er 9, 2016 Abstract W e study the problem of learning influence functions under incomplete observ ations of no de activ ations. Incomplete observ ations are a ma jor concern as most (online and real-w orld) so cial net works are not fully observ able. W e establish both proper and improper P A C learnabilit y of influence functions under randomly missing observ ations. Proper P AC learnabilit y under the Discrete-Time Linear Threshold (DL T) and Discrete-Time Indep endent Cascade (DIC) mo dels is established b y reducing incomplete observ ations to complete observ ations in a mo dified graph. Our improp er P AC learnability result applies for the DL T and DIC mo dels as well as the Con tinuous-Time Indep endent Cascade (CIC) mo del. It is based on a parametrization in terms of reachabilit y features, and also gives rise to an efficient and practical heuristic. Exp erimen ts on synthetic and real-world datasets demonstrate the ability of our metho d to comp ensate even for a fairly large fraction of missing observ ations. 1 In tro duction Man y so cial phenomena, suc h as the spread of diseases, b ehaviors, tec hnologies, or products, can naturally b e modeled as the diffusion of a contagion across a netw ork. Owing to the p otentially high so cial or economic v alue of accelerating or inhibiting suc h diffusions, the goal of understanding the flow of information and predicting information cascades has b een an active area of research [ 10 , 7 , 9 , 14 , 1 , 20 ]. In this context, a k ey task is learning influenc e functions : the functions mapping sets of initial adopters to the individuals who will b e influenced (also called active ) b y the end of the diffusion pro cess [10]. Man y metho ds hav e b een developed to solve the influence function learning problem [ 9 , 7 , 5 , 8 , 3 , 16 , 18 , 24 , 25 ]. Most approaches are based on fitting the parameters of a diffusion model based on observ ations, e.g., [ 8 , 7 , 18 , 9 , 16 ]. Recen tly , Du et al. [ 3 ] prop osed a mo del-fr e e approac h to learn influence functions as co verage functions; Narasimhan et al. [ 16 ] establish prop er P AC learnabilit y of influence functions under several widely-used diffusion models. All existing approac hes rely on the assumption that the observ ations in the training dataset are complete, complete, in the sense that all activ e nodes are observed as b eing activ e. How ever, this assumption fails to hold in virtually all practical applications [ 15 , 6 , 2 , 21 ]. F or example, so cial media data are usually collected through cra wlers or acquired with public APIs provided by so cial media platforms, such as T witter or F aceb o ok. Due to non-tec hnical reasons and established restrictions on the APIs, it is often impossible to obtain a complete set of observ ations ev en for a short p erio d 1 of time. In turn, the existence of unobserv ed nodes, links, or activ ations ma y lead to a significant misestimation of the diffusion model’s parameters [19, 15]. In this pap er, w e take a step tow ards addressing the problem of learning influence functions from incomplete observ ations (Here sp ecifically w e mean missing activ ation in the observ ed cascades). Missing data are a complicated phenomenon, but to address it meaningfully and rigorously , one must mak e at least some assumptions about the pro cess resulting in the loss of data. As a first step, we fo cus on r andom loss of observ ations: for eac h activ ated node independently , the node’s activ ation is observed only with probabilit y r , the r etention r ate , and fails to b e observed with probabilit y 1 − r . Random observ ation loss naturally occurs when crawling data from so cial media, where rate restrictions are lik ely to affect all observ ations equally . W e establish both proper and improp er P A C learnabilit y of influence functions under incomplete observ ations for t wo p opular diffusion mo dels: the Discrete-Time Indep enden t Cascade (DIC) and Discrete-Time Linear Threshold (DL T) mo dels. The result is pro v ed by interpreting the incomplete observ ations as complete observ ations in a transformed graph, In fact, randomly missing observ ations do not significan tly increase the required sample complexit y . The P AC learnability result implies go o d sample complexity b ounds for the DIC and DL T mo dels. Ho w ev er, ev en without missing observ ations, proper P A C learnabilit y of the CIC and other models app ears to b e more challenging. F urthermore, the P AC learnability result do es not lead to an efficient algorithm, as it inv olves marginalizing a large n um b er of hidden v ariables (one for eac h no de not observ ed to b e activ e). T o w ards designing more practical algorithms and obtaining learnabilit y under a broader class of diffusion mo dels, we pursue improper learning approaches. Concretely , w e use the parameterization of Du et al. [ 3 ] in terms of reachabilit y basis functions, and optimize a mo dified loss function suggested b y Natara jan et al. [ 17 ] to address incomplete observ ations. W e pro ve that the algorithm ensures improp er P AC learning for the DIC, DL T and Con tin uous-Time Indep endent Cascade (CIC) models. Exp erimen tal results on synthetic cascades generated from these diffusion models and real-world cascades in the MemeT rack er dataset demonstrate the effectiv eness of our approac h. Our algorithm ac hiev es nearly a 20% reduction in estimation error compared to the best baseline metho ds on the MemeT rac k er dataset, b y comp ensating for incomplete observ ations. Sev eral recent works also aim to address the issue of missing observ ations in so cial netw ork analysis, but with differen t emphases. F or example, Chieric hetti et al. [ 2 ] and Sadiko v et al. [ 21 ] mainly fo cus on recov ering the size of a diffusion process, while our task is to learn the influence functions from several incomplete cascades. Myers et al. [ 15 ] mainly aim to mo del unobserv ed external influence in diffusion. Duong et al. [ 6 ] examine learning diffusion mo dels with missing links from c omplete observ ations, while w e learn influence functions from incomplete cascades with missing activ ations. Most related to our work are pap ers by W u et al. [ 23 ] and simultaneous work by Lokho v [ 13 ]. Both study the problem of net w ork inference under incomplete observ ations. Lokhov prop oses a dynamic message passing approach to marginalize all the missing activ ations, in order to infer diffusion mo del parameters using maximum likelihoo d estimation, while W u et al. dev elop an EM algorithm. Notice that the goal of learning the mo del parameters differs from our goal of learning the influence functions directly . Both [ 13 ] and [ 23 ] pro vide empirical ev aluation, but do not pro vide theoretical guaran tees. 2 2 Preliminaries 2.1 Mo dels of Diffusion and Incomplete Observ ations Diffusion Mo del. W e mo del propagation of opinions, pro ducts, or b eha viors as a diffusion pro cess o v er a so cial netw ork. The so cial netw ork is represented as a directed graph G = ( V , E ) , where n = | V | is the num b er of no des, and m = | E | is the num b er of edges. Each edge e = ( u, v ) is asso ciated with a parameter w uv represen ting the strength of influence user u has on v . W e assume that the graph structure (the edge set E ) is kno wn, while the parameters w uv are to b e learned. Dep ending on the diffusion mo del, there are different wa ys to represent the strength of influence b et w een individuals. No des can b e in one of t w o states, inactive or active . W e sa y that a node gets activ ated if it adopts the opinion/pro duct/b eha vior under the diffusion pro cess. In this w ork, we fo cus on pr o gr essive diffusion mo dels, where a node remains activ e once it gets activ ated. The diffusion pro cess b egins with a set of seed no des (initial adopters) S , who start active. The pro cess then proceeds in discrete or con tin uous time: according to a probabilistic process, additional no des may b ecome activ e based on the influence from their neigh b ors. Let N ( v ) b e the in-neighbors of no de v and A t the set of no des activ ated b y time t . W e consider the following three widely used diffusion mo dels: • Discrete-time Linear Threshold (DL T) mo del [10]: Eac h no de v has a threshold θ v dra wn indep enden tly and uniformly from the interv al [0 , 1] . The diffusion under the DL T mo del unfolds in discrete time steps: a no de v b ecomes active at step t if the total incoming w eigh t from its neighbors exceeds its threshold: P u ∈ N ( v ) ∩ A t − 1 w uv ≥ θ v . • Discrete-time Indep enden t Cascade (DIC) model [10]: The DIC mo del is also a discrete-time mo del. Under the DIC mo del, the weigh t w uv ∈ [0 , 1] captures an activ ation probabilit y . When a no de u b ecomes active in step t , it attempts to activ ate all currently inactiv e neighbors in step t + 1 . F or eac h neigh b or v , it succeeds with probabilit y w uv . If it succeeds, v b ecomes activ e; otherwise, v remains inactiv e. Once u has made all these attempts, it do es not get to mak e further activ ation attempts at later times. • Con tin uous-time Indep enden t Cascade (CIC) mo del [8]: The CIC model unfolds in con tin uous time. Each edge e = ( u, v ) is associated with a delay distribution with w uv as its parameter. When a node u b ecomes newly activ e at time t , for ev ery neigh b or v that is still inactiv e, a dela y time d uv is drawn from the delay distribution. d uv is the duration it takes u to activ ate v , whic h could b e infinite (if u do es not succeed in activ ating v ). No des are considered activ ated by the process if they are activ ated within a sp ecified observ ation windo w [0 , τ ] . Fix one of the diffusion mo dels defined ab ov e and its parameters. F or eac h seed set S , let ∆ S b e the distribution of final activ e sets when the seed set is S . (In the case of the DIC and DL T mo del, this is the set of active nodes when no new activ ations o ccur; for the CIC model, it is the set of no des active at time τ .) F or any no de v , let F v ( S ) = Prob A ∼ ∆ S [ v ∈ A ] b e the (marginal) probability that v is activ ated according to the dynamics of the diffusion model with initial seeds S . Then, define the influenc e function F : 2 V → [0 , 1] n mapping seed sets to the vector of marginal activ ation probabilities: F ( S ) = [ F 1 ( S ) , . . . , F n ( S )] . Notice that the marginal probabilities do not capture the full information about the diffusion pro cess contained in ∆ S (since they do not observ e co-activ ation patterns), but they are sufficient for man y applications, suc h as influence maximization [ 10 ] and influence estimation [4]. 3 Cascades and Incomplete Observ ations. W e fo cus on the problem of learning influence func- tions from cascades. A cascade C = ( S, A ) is a realization of the random diffusion pro cess; S is the set of seeds and A ∼ ∆ S , A ⊇ S is the set of activ ated nodes at the end of the random pro cess. Similar to Narasimhan et al. [ 16 ], w e focus on activation-only observ ations, namely , w e only observe which no des were activ ated, but not when these activ ations occurred. 1 T o capture the fact that some of the no de activ ations ma y ha v e b een unobserv ed, w e use the follo wing mo del of indep enden tly randomly missing data: for eac h (activ ated) node v ∈ A \ S , the activ ation of v is actually observe d indep enden tly with probabilit y r . With probability 1 − r , the no de’s activ ation is unobserv able. F or seed no des v ∈ S , the activ ation is never lost. F ormally , define ˜ A as follows: each v ∈ S is deterministically in ˜ A , and eac h v ∈ A \ S is in ˜ A indep enden tly with probabilit y r . Then, the incomplete cascade is denoted b y ˜ C = ( S, ˜ A ) . 2.2 Ob jectiv e F unctions and Learning Goals T o measure estimation error, w e primarily use a quadratic loss function, as in [ 16 , 3 ]. F or t wo n -dimensional v ectors x , y , the quadratic loss is defined as ` sq ( x , y ) = 1 n · || x − y || 2 2 . W e also use this notation when one or both argumen ts are sets: when an argument is a set S , w e formally mean to use the indic ator function χ S as a v ector, where χ S ( v ) = 1 if v ∈ S , and χ S ( v ) = 0 otherwise. In particular, for an activ ated set A , w e write ` sq ( A, F ( S )) = 1 n || χ A − F ( S ) || 2 2 . W e no w formally define the problem of learning influence functions from incomplete observ ations. Let P b e a distribution ov er seed sets (i.e., a distribution ov er 2 V ), and fix a diffusion model M and parameters, together giving rise to a distribution ∆ S for eac h seed set. The algorithm is giv en a set of M incomplete cascades ˜ C = { ( S 1 , ˜ A 1 ) , . . . , ( S M , ˜ A M ) } , where eac h S i is drawn indep endently from P , and ˜ A i is obtained by the incomplete observ ation pro cess describ ed ab o v e from the (random) activ ated set A i ∼ ∆ S i . The goal is to learn an influence function F that accurately captures the diffusion pro cess. Accuracy of the learned influence function is measured in terms of the squared error with resp ect to the true mo del: err sq [ F ] = E S ∼P ,A ∼ ∆ S [ ` sq ( A, F ( S ))] . That is, the exp ectation is ov er the seed set and the randomness in the diffusion process, but not the data loss process. P A C Learnabilit y of Influence F unctions. W e characterize the learnabilit y of influence func- tions under incomplete observ ations using the Probably Approximately Correct (P AC) learning framew ork [ 22 ]. Let F M b e the class of influence functions under the diffusion mo del M , and F L the class of influence functions the learning algorithm is allo w ed to c ho ose from. W e say that F M is P A C learnable if there exists an algorithm A with the follo wing prop ert y: for all ε, δ ∈ (0 , 1) , all parametrizations of the diffusion model, and all distributions P o v er seed sets S : when given activation-only and inc omplete training cascades ˜ C = { ( S 1 , ˜ A 1 ) , . . . , ( S M , ˜ A M ) } with M ≥ pol y ( n, m, 1 /ε, 1 /δ ) , A outputs an influence function F ∈ F L satisfying: Prob ˜ C [ err sq [ F ] − err sq [ F ∗ ] ≥ ε ] ≤ δ. Here, F ∗ ∈ F M is the ground truth influence function. The probabilit y is o v er the training cascades, including the seed set generation, the stochastic diffusion pro cess, and the missing data pro cess. W e say that an influence function learning algorithm A is pr op er if F L ⊆ F M ; that is, the learned influence function is guaran teed to b e an instance of the true diffusion mo del. Otherwise, w e sa y that A is an impr op er learning algorithm. 1 Narasimhan et al. [ 16 ] refer to this mo del as p artial observations ; we change the terminology to av oid confusion with “incomplete observ ations.” 4 𝐺 𝑢 𝑣 𝑤 𝑥 𝑢 𝑣 𝑤 𝑥 𝑢 ’ 𝑣′ 𝑤′ 𝑥′ 𝐺 ' Figure 1: Illustration of the graph transformation. The light green node is the seed, the dark green no des are the activ ated and observed no des while the yello w no de is activ ated but lost due to incomplete observ ations. 3 Prop er P A C Learning under Incomplete Observ ations In this section, w e establish prop er P A C learnabilit y of influence functions under the DIC and DL T mo dels. F or b oth diffusion mo dels, F M can b e parameterized by an edge parameter vector w , whose en tries w e are the activ ation probabilities (DIC model) or edge w eights (DL T model). Our goal is to find an influence function F w ∈ F M that outputs accurate marginal activ ation probabilities. While our goal is pr op er learning — meaning that the function must b e from F M — we do not require that the inferred parameters matc h the true edge parameters w . Our main theoretical results are summarized in Theorem 1 and Theorem 2. Theorem 1. L et λ ∈ (0 , 0 . 5) . The class of influenc e functions under the DIC mo del in which al l e dge activation pr ob abilities satisfy w e ∈ [ λ, 1 − λ ] is P A C le arnable under inc omplete observations with r etention r ate r . The sample c omplexity is ˜ O ( n 3 m ε 2 r 4 ) . Theorem 2. L et λ ∈ (0 , 0 . 5) , and c onsider the class of influenc e functions under the DL T mo del such that the e dge weight for every e dge satisfies w e ∈ [ λ, 1 − λ ] , and for every no de v , 1 − P u ∈ N ( v ) w uv ∈ [ λ, 1 − λ ] . This class is P AC le arnable under inc omplete observations with r etention r ate r . The sample c omplexity is ˜ O ( n 3 m ε 2 r 4 ) . In this section, we present the intuition and a pro of sk etch for the t w o theorems. Details of the pro of are pro vided in App endix A. The ke y idea of the pro of of b oth theorems is that a set of incomplete cascades ˜ C on G under the t w o models can b e considered as essentially complete cascades on a transformed graph ˆ G = ( ˆ V , ˆ E ) . The influence functions of nodes in ˆ G can b e learned using a mo dification of the result of Narasimhan et al. [ 16 ]. Subsequen tly , the influence functions for G are directly obtained from the influence functions for ˆ G , by exploiting that influence functions only fo cus on the marginal activ ation probabilities. The transformed graph ˆ G is built b y adding a la yer of n no des to the original graph G . F or each no de v ∈ V of the original graph, w e add a new node v 0 ∈ V 0 and a directed edge ( v , v 0 ) with kno wn and fixed edge parameter ˆ w v v 0 = r . (Con v enien tly , the same parameter v alue serv es as activ ation probabilit y under the DIC model and as edge weigh t under the DL T mo del.) The new no des V 0 ha v e no other inciden t edges, and w e retain all edges e = ( u, v ) ∈ E . Inferring their parameters is the learning task. An example of the transformation on a simple graph consisting of four nodes is sho wn in Figure 1. 5 F or each observ ed (incomplete) cascade ( S i , ˜ A i ) on G (with S i ⊆ ˜ A i ), we pro duce an observed activ ation set A 0 i as follows: (1) for each v ∈ ˜ A i \ S i , we let v 0 ∈ A 0 i deterministically; (2) for each v ∈ S i indep enden tly , we include v 0 ∈ A 0 i with probability r . This defines the training cascades ˆ C = { ( S i , A 0 i ) } . No w consider any edge parameters w , applied to b oth G and the first la y er of ˆ G . Let F ( S ) denote the influence function on G , and ˆ F ( S ) = [ ˆ F 1 0 ( S ) , . . . , ˆ F n 0 ( S )] the influence function of the no des in the added la yer V 0 of ˆ G . Then, by the transformation, w e get that ˆ F v 0 ( S ) = r · F v ( S ) (1) for all nodes v ∈ V . And b y the definition of the observ ation loss pro cess, we also ha ve that for all non-seed no des v / ∈ S i , Prob[ v ∈ ˜ A i ] = r · F v ( S ) = ˆ F v 0 ( S ) . While the cascades ˆ C are not complete on all of ˆ G , in a precise sense, they pro vide complete information on the activ ation of no des in V 0 . In App endix A, we show that Theorem 2 of Narasimhan et al. [ 16 ] can b e extended to pro vide iden tical guaran tees for learning ˆ F ( S ) from the mo dified observ ed cascades ˆ C . F or the DIC model, this is a straightforw ard mo dification of the pro of from [ 16 ]. F or the DL T model, [ 16 ] had not established P A C learnabilit y 2 , so w e pro vide a separate proof. Because the results of [ 16 ] and our generalizations ensure pr op er learning, they provide edge w eigh ts w b et w een the no des of V . W e use these exact same edge weigh ts to define the learned influence functions in G . Equation (1) then implies that the learned influence functions on V satisfy F v ( S ) = 1 r · ˆ F v 0 ( S ) . The detailed analysis in App endix A sho ws that the learning error only scales b y a m ultiplicativ e factor 1 r 2 . The P AC learnability result shows that there is no information-theoretical obstacle to influence function learning under incomplete observ ations. Ho w ev er, it do es not imply an efficient algorithm. The reason is that a hidden v ariable w ould b e asso ciated with each no de not observ ed to be activ e, and computing the ob jectiv e function for empirical risk minimization would require marginalizing o v er all of the hidden v ariables. The prop er P AC learnability result also do es not readily generalize to the CIC mo del and other diffusion mo dels, ev en under complete observ ations. This is due to the lac k of a succinct c haracterization of influence functions as under the DIC and DL T mo dels. Therefore, in the next section, w e explore improper learning approaches with the goal of designing practical algorithms and establishing learnabilit y under a broader class of diffusion mo dels. 4 Efficien t Improp er Learning Algorithm In this section, w e develop improper learning algorithms for efficient influence function learning. Instead of parameterizing the influence functions using the edge parameters, w e adopt the mo del-free influence function learning framework, InfluLearner, proposed by Du et al. [ 3 ] to represent the influence function as a sum of w eigh ted basis functions. F rom no w on, we fo cus on the influence function F v ( S ) of a single fixed node v . 2 [ 16 ] shows that the DL T mo del with fixed thresholds is P AC learnable under complete cascades. W e study the DL T mo del when the thresholds are uniformly distributed random v ariables. 6 Influence F unction P arameterization. F or all three diffusion mo dels (CIC, DIC and DL T), the diffusion pro cess can be characterized equiv alently using liv e-edge graphs. Concretely , the results of [ 10 , 4 ] state that for each instance of the CIC, DIC, and DL T mo dels, there exists a distribution Γ o ver liv e-edge graphs H assigning probabilit y γ H to eac h liv e-edge graph H suc h that F ∗ v ( S ) = P H : at le ast one no de in S has a path to v in H γ H . T o reduce the represen tation complexity , notice that from the p ersp ective of activ ating v , tw o differen t liv e-edge graphs H , H 0 are “equiv alent” if v is reac hable from exactly the same no des in H and H 0 . Therefore, for an y node set T , let β ∗ T := P H : exactly the no des in T hav e paths to v in H γ H . W e then use c haracteristic vectors as feature v ectors r T = χ T , where we will in terpret the entry for no de u as u ha ving a path to v in a liv e-edge graph. More precisely , let φ ( x ) = min { x, 1 } , and χ S the characteristic v ector of the seed set S . Then, φ ( χ > S · r T ) = 1 if and only if v is reachable from S , and we can write F ∗ v ( S ) = X T β ∗ T · φ ( χ > S · r T ) . This represen tation still has exponentially man y features (one for each T ). In order to make the learning problem tractable, we sample a smaller set T of K features from a suitably chosen distribution, implicitly setting the weigh ts β T of all other features to 0. Th us, we will parametrize the learned influence function as F β v ( S ) = X T ∈T β T · φ ( χ > S · r T ) . The goal is then to learn w eigh ts β T for the sampled features. (They will form a distribution, i.e., || β || 1 = 1 and β ≥ 0 .) The crux of the analysis is to show that a sufficien tly small n um b er K of features (i.e., sampled sets) suffices for a go o d appro ximation, and that the weigh ts can b e learned efficien tly from a limited n umber of observed incomplete cascades. Sp ecifically , w e consider the log lik eliho o d function ` ( t, y ) = y log t + (1 − y ) log (1 − t ) , and learn the parameter vector β via the follo wing maximum likelihoo d estimation problem: Maximize P M i =1 ` ( F β v ( S i ) , χ A i ( v )) sub ject to || β || 1 = 1 , β ≥ 0 . Handling Incomplete Observ ations. The maximum likelihoo d estimation cannot b e directly applied to incomplete cascades, as w e do not ha v e access to A i (only the incomplete v ersion ˜ A i ). T o address this issue, notice that the MLE problem is actually a binary classification problem with log loss and y i = χ A i ( v ) as the label. F rom this persp ective, incompleteness is simply class-conditional noise on the labels. Let ˜ y i = χ ˜ A i ( v ) b e our observation of whether v w as activ ated or not under the incomplete cascade i . Then, Prob[ ˜ y i = 1 | y i = 1] = r and Prob[ ˜ y i = 1 | y i = 0] = 0 . In words, the incomplete observ ation ˜ y i suffers from one-sided error compared to the complete observ ation y i . Known tec hniques can b e used to address this issue. By results of Natara jan et al. [ 17 ], we can construct an unbiased estimator of ` ( t, y ) using only the incomplete observ ations ˜ y , as in the following lemma. 7 Lemma 3 (Corollary of Lemma 1 [ 17 ]) . L et y b e the true activation of no de v and ˜ y the inc omplete observation. Then, defining ˜ ` ( t, y ) := 1 r y log t + 2 r − 1 r (1 − y ) log (1 − t ) , for any t , we have E ˜ y h ˜ ` ( t, ˜ y ) i = ` ( t, y ) . Based on this lemma, we solve the maxim um lik eliho o d estimation problem with the adjusted lik eliho o d function ˜ ` ( t, y ) : Maximize P M i =1 ˜ ` ( F β v ( S i ) , χ ˜ A i ( v )) (2) sub ject to || β || 1 = 1 , β ≥ 0 . W e analyze conditions under which the solution to (2) pro vides improp er P AC learnabilit y under incomplete observ ations; these conditions will apply for all three diffusion mo dels. These conditions are similar to those of Lemma 1 in the w ork of Du et al. [ 3 ], and concern the appro ximabilit y of the reac habilit y distribution β ∗ T . Specifically , let q b e a distribution o ver no de sets T suc h that q ( T ) ≤ C β ∗ T for all no de sets T . Here, C is a (p ossibly v ery large) num b er that we will wan t to b ound b elow. Let T 1 , . . . , T K b e K i.i.d. samples dra wn from the distribution q . The features are then r k = χ T k . W e use the truncated v ersion of the function F β ,λ v ( S ) with parameter 3 λ as in [3]: F β ,λ v ( S ) = (1 − 2 λ ) F β v ( S ) + λ. Let M λ b e the class of all such truncated influence functions, and F ˜ β ,λ v ∈ M λ the influence functions obtained from the optimization problem (2) . The following theorem (pro v ed in App endix B) establishes the accuracy of the learned functions. Theorem 4. Assume that the le arning algorithm uses K = ˜ Ω ( C 2 ε 2 ) fe atur es in the influenc e function it c onstructs, and observes 4 M = ˜ Ω ( log C ε 4 r 2 ) inc omplete c asc ades with r etention r ate r . Then, with pr ob ability at le ast 1 − δ , the le arne d influenc e functions F ˜ β ,λ v for e ach no de v and se e d distribution P satisfy E S ∼P h ( F ˜ β ,λ v ( S ) − F ∗ v ( S )) 2 i ≤ ε. The theorem implies that with enough incomplete cascades, an algorithm can approximate the ground truth influence function to arbitrary accuracy . Therefore, all three diffusion mo dels are improp erly P A C learnable under incomplete observ ations. The final sample complexit y does not con tain the graph size, but is implicitly captured by C , whic h will dep end on the graph and how well the distribution β ∗ T can b e appro ximated. Notice that with r = 1 , our b ound on M has logarithmic dep endency on C instead of p olynomial, as in [ 3 ]. The reason for this impro vemen t is discussed further in Appendix B. 3 The pro of of Theorem 4 in App endix B will show how to choose λ . 4 The ˜ Ω notation suppresses all logarithmic terms except log C , as C could b e exp onential or worse in the num b er of no des. 8 Efficien t Implemen tation. As mentioned ab ov e, the features T cannot b e sampled from the exact reachabilit y distribution β ∗ T , b ecause it is inaccessible (and complex). In order to obtain useful guaran tees from Theorem 4, w e follo w the approach of Du et al. [ 3 ], and approximate the distribution β ∗ T with the product of the marginal distributions, estimated from observed cascades. The optimization problem (2) is conv ex and can therefore be solved in time polynomial in the n um b er of features K . How ever, the guarantees in Theorem 4 require a p ossibly large num b er of features. In order to obtain an efficient algorithm for practical use and our exp eriments, we sacrifice the guarantee and use a fixed n um b er of features. Notice that the optimization problem (2) can b e solved independently for eac h no de v ; the learned functions F i ( S ) can then be com bined in to F ( S ) = [ F 1 ( S ) , . . . , F n ( S )] . As the optimization problem factorizes o v er nodes, the metho d is obviously parallelizable, th us scaling to large net works. A further p oin t regarding the implementation: in our theoretical analysis, we assumed that the retention rate r is known to the learning algorithm. In practice, it can b e estimated via cross- v alidation. As w e show in the next section, the algorithm is not v ery sensitive to the missp ecification of the reten tion rate. 5 Exp erimen ts In this section, we exp erimen tally ev aluate the algorithm from Section 4. Since no other metho ds explicitly accoun t for incomplete observ ations, w e compare it to several state-of-the-art metho ds for influence function learning with full information. Hence, the main goal of the comparison is to examine to what exten t the impact of missing data can b e mitigated b y b eing aw are of it. W e compare our algorithm to the following approac hes: (1) CIC is an approac h fitting the parameters of a CIC mo del, using the NetRate algorithm [ 7 ] with exponential delay distribution. (2) DIC fits the activ ation probabilities of a DIC mo del using the metho d in [ 18 ]. (3) InfluLearner is the mo del-free approac h proposed by Du et al. in [ 3 ] and discussed in Section 4. (4) Logistic uses logistic regression to learn the influence functions F u ( S ) = f ( χ > S · c u + b ) for eac h u indep enden tly , where c u is a learnable weigh t vector and f ( x ) = 1 1+ e − x is the logistic function. (5) Linear uses linear regression to learn the total influence σ ( S ) = c > · χ S + b of the set S . Notice that the CIC and DIC metho ds hav e access to the activation time of eac h node in addition to the final activ ation status, giving them an inheren t adv antage. 5.1 Syn thetic cascades Data generation. W e generate syn thetic net works with core-peripheral structure following the Kronec k er graph mo del [ 12 ] with parameter matrix [0 . 9 , 0 . 5; 0 . 5 , 0 . 3] . 5 Eac h generated net w ork has 512 no des and 1024 edges. W e then generate synthetic cascades follo wing the CIC, DIC and DL T mo dels. F or the CIC mo del, w e use an exp onen tial delay distribution on eac h edge whose parameters are drawn indep enden tly and uniformly from [0 , 1] . The observ ation window length is τ = 1 . 0 . F or the DIC mo del, the activ ation probabilit y for each edge is chosen indep endently and uniformly from [0 , 0 . 4] . F or the DL T mo del, w e follo w [ 10 ] and set the edge weigh t w uv as 1 /d v where d v is the in-degree of node v . F or each mo del, w e generate 8192 cascades as training data. The seed sets are sampled uniformly at 5 W e also exp erimented on Kronec ker graphs with hierarchical communit y structure ( [0 . 9 , 0 . 1; 0 . 1 , 0 . 9] ) and random structure ( [0 . 5 , 0 . 5; 0 . 5 , 0 . 5] ). The results are similar and omitted due to space constraints. 9 1.0 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 Retention Rate 2 3 4 5 6 7 8 9 10 11 MAE CIC DIC InfluLearner Linear Logistic Our Method (a) CIC 1.0 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 Retention Rate 2 3 4 5 6 7 8 9 10 11 MAE CIC DIC InfluLearner Linear Logistic Our Method (b) DIC 1.0 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 Retention Rate 2 3 4 5 6 7 8 9 10 11 MAE CIC DIC InfluLearner Linear Logistic Our Method (c) DL T Figure 2: MAE of estimated influence as a function of the reten tion rate on synthetic datasets for (a) CIC model, (b) DIC model, (c) DL T model. The error bars shows one standard deviation. random with sizes drawn from a p ow er la w distribution with parameter 2 . 5 . The generated cascades ha v e av erage sizes of 10 . 8 , 12 . 8 and 13 . 0 in the CIC, DIC and DL T models, respectively . W e then create incomplete cascades by v arying the retention rate betw een 0 . 1 and 0 . 9 . The test set con tains 200 indep endently sampled seed sets generated in the same w ay as the training data. T o sidestep the computational cost of running Monte Carlo sim ulations, we estimate the ground truth influence of the test seed sets using the method prop osed in [3], with the true mo del parameters. Algorithm settings. W e apply all algorithms to cascades generated from all three mo dels; that is, we also consider the results under mo del missp ecification. Whenever applicable, w e set the h yp erparameters of the five comparison algorithms to the ground truth v alues. When applying the NetRate algorithm to discrete-time cascades, w e set the observ ation windo w to 10 . 0 . When applying the metho d in [ 18 ] to contin uous-time cascades, we round activ ation times up to the nearest m ultiple of 0.1, resulting in 10 discrete time steps. F or the mo del-free approaches (InfluLearner and our algorithm), we use K = 200 features. Results. Figure 2 sho ws the Mean Absolute Error (MAE) b etw een the estimated total influence σ ( S ) and the true influence v alue, a veraged ov er all testing seed sets. F or each setting (diffusion mo del and reten tion rate), the reported MAE is a veraged o v er five indep endent runs. The main insight is that accounting for missing observ ations indeed strongly mitigates their effect: notice that for retention rates as small as 0 . 5 , our algorithm can almost completely compensate for the data loss, whereas b oth the mo del-free and parameter fitting approac hes deteriorate significantly ev en for reten tion rates close to 1. F or the parameter fitting approac hes, even such large reten tion rates can lead to missing and spurious edges in the inferred netw orks, and thus significant estimation errors. Additional observ ations include that fitting influence using (linear or logistic) regression do es not perform well at all, and that the CIC inference approac h appears more robust to model missp ecification than the DIC approac h. Sensitivit y of reten tion rate. W e presen ted the algorithms as kno wing r . Since r itself is inferred from noisy data, it ma y be somewhat misestimated. Figure 4 shows the impact of misestimating r . 10 96% 98% 100% 102% 104% 106% 0.02 0.05 0.1 0.2 CIC DIC DL T Figure 3: Relative error in MAE when the true reten tion rates are drawn from the truncated Gaussian distribution. The x -axis shows standard deviation σ of the reten tion rates from the mean, and the y -axis is the relativ e difference of the MAE compared to the case where all retention rates are the same and kno wn. W e generate syn thetic cascades from all three diffusion mo dels with a true retention rate of 0 . 8 , and then apply our algorithm with (incorrect) reten tion rate r ∈ { 0 . 6 , 0 . 65 , . . . , 0 . 95 , 1 } . The results are a v eraged o ver five indep endent runs. While the performance decreases as the misestimation gets w orse (after all, with r = 1 , the algorithm is basically the same as InfluLearner), the degradation is graceful. Non-uniform retention rate In practice, different no des may hav e different retention rates, while w e may b e able only to estimate the mean retention rate r . F or our exp eriments, w e dra w eac h no de v ’s retention rate r v indep enden tly from a distribution with mean r . Sp ecifically , in our exp erimen ts, we use uniform and Gaussian distributions; for the uniform distribution, we draw r v ∼ Unif [ r − σ, r + σ ] ; for the Gaussian distribution, we draw r v ∼ N ( r , σ 2 ) , truncating dra ws at 0 and 1. 6 In b oth cases, σ measures the lev el of noise in the estimated reten tion rate. W e set the mean reten tion rate r to 0 . 8 and v ary σ in { 0 , 0 . 02 , 0 . 05 , 0 . 1 , 0 . 2 } . Figure 3 shows the results for the Gaussian distribution; the results of uniform distribution are similar and omitted. The results show that our mo del is very robust to random and independent p erturbations of individual retention rates for each no de. 5.2 Influence Estimation on real cascades W e further ev aluate the p erformance of our method on the real-world MemeT rac k er 7 dataset [ 11 ]. The dataset consists of the propagation of short textual phrases, referred to as Memes , via the publication of blog p osts and main-stream media news articles b et w een March 2011 and F ebruary 2012. Sp ecifically , the dataset con tains seven groups of cascades corresponding to the propagation of Memes with certain keyw ords, namely “apple and jobs”, “tsunami earthquake”, “william k ate marriage” ’, “o ccupy wall-street”, “airstrikes”, “egypt” and “elections.” Eac h cascade group consists of 6 The truncation could lead to a bias on the mean of r . How ever, empirical simulations sho w that the bias is negligible (only 0 . 01 when σ = 0 . 2 ). 7 W e use the prepro cessed version of the dataset released by Du et al. [ 3 ] and av ailable at http://www.cc.gatech. edu/~ndu8/InfluLearner.html . Notice that the dataset is semi-real, as multi-node seed cascades are artificially created by merging single-no de seed cascades. 11 ! 10 !5 0 5 10 15 20 25 30 35 40 1 0.95 0.9 0.85 0.8 0.75 0.7 0.65 0.6 CI C DIC DL T Figure 4: Relative error in MAE under reten- tion rate misspecification. x -axis: reten tion rate r used b y the algorithm. y -axis: relativ e difference of MAE compared to using the true reten tion rate 0.8. ! " #! #" $! $" %! %" # $ % & " ' ( )*+ ,-./012 .324 54 51 Lin ear Logi stic DIC CIC In flu Lear ne r Our3 M ethod Figure 5: MAE of influence estimation on seven sets of real-w orld cascades with 20% of activ a- tions missing. 1000 nodes, with a n um b er of cascades v arying from 1000 to 44000 . W e follow exactly the same ev aluation metho d as Du et al. [3] with a training/test set split of 60%/40%. T o test the p erformance of influence function learning under incomplete observ ations, w e randomly delete 20% of the occurrences, setting r = 0 . 8 . The results for other reten tion rates are similar and omitted. Figure 5 shows the MAE of our metho ds and the fiv e baselines, av eraged o v er 100 random dra ws of test seed sets, for all groups of memes. While some baselines p erform v ery po orly , ev en compared to the best baseline (InfluLearner), our algorithm provides an 18% reduction in MAE (a v eraged ov er the seven groups), showing the p oten tial of data loss aw areness to mitigate its effects. 6 Mo del Extensions So far, w e hav e assumed that the retention rate is the same for all the no des; how ever, our approac h can b e easily generalized to the case in whic h eac h individual node has a different (but known) reten tion rate. The follo wing theorem generalizes Theorems 1 and 2. (The pro ofs of all theorems from this section are giv en in App endix C.) Theorem 5. L et λ ∈ (0 , 0 . 5) and for e ach no de v , let r v b e v ’s r etention r ate. W rite ¯ r = 1 n P n i =1 1 r 2 v . • The class of influenc e functions under the DIC mo del in which al l e dge activation pr ob abilities satisfy w e ∈ [ λ, 1 − λ ] is P A C le arnable with sample c omplexity ˜ O ( ¯ r 2 n 3 m ε 2 ) . • The class of influenc e functions under the DL T mo del such that the e dge weight for every e dge satisfies w e ∈ [ λ, 1 − λ ] , and for every no de v , 1 − P u ∈ N ( v ) w uv ∈ [ λ, 1 − λ ] , is P AC le arnable with sample c omplexity ˜ O ( ¯ r 2 n 3 m ε 2 ) . The empirical ev aluation in the previous section also shows that the p erformance do es not change significan tly if the true retention rate of eac h node is independently p erturb ed around the estimated mean loss rate. A second limitation of our approac h is that w e assume the retention rate r to b e kno wn to the algorithm. Estimating r in a real-w orld setting present s a “chic ken and egg” problem; how ev er, we 12 b eliev e that a somewhat accurate estimate of r (p erhaps based on past data for whic h ground truth can be obtained at m uch higher cost) will still be a significan t impro vemen t ov er the status quo, namely , pretending that no data are missing. Moreo v er, even approximate information about r leads to p ositiv e results on prop er P AC learnabilit y . W e show that the P A C learnabilit y result can be extended to the case where w e only kno w that the true reten tion rate lies in a given in terv al. Instead of kno wing the exact v alue r , we only kno w that r lies in an interv al measured by the relative error η , namely r ∈ I = [ ¯ r · (1 − η ) , ¯ r · (1 + η )] . Within that in terv al, the reten tion rate is adversarially chosen. W e can then generalize Theorems 1 and 2 as follows. Theorem 6. L et λ ∈ (0 , 0 . 5) , and assume that the gr ound truth r etention r ate r is adversarial ly chosen in I = [ ¯ r · (1 − η ) , ¯ r · (1 + η )] . F or al l ε, δ ∈ (0 , 1) , al l p ar ametrizations of the diffusion mo del, and al l distributions P over se e d sets S : when given activ ation-only and incomplete tr aining c asc ades ˜ C , ther e exists a pr op er le arning algorithm A which outputs an influenc e function F ∈ F M satisfying: Prob ˜ C [ err sq [ F ] − err sq [ F ∗ ] ≥ ε + 4 η 2 (1 − η ) 2 ] ≤ δ. • F or the DIC mo del, when al l e dge activation pr ob abilities satisfy w e ∈ [ λ, 1 − λ ] , the r e quir e d numb er of observations is M = ˜ O ( n 3 m ε 4 r 4 (1 − η ) 4 ) . • F or the DL T mo del, when al l e dges weights satisfy w e ∈ [ λ, 1 − λ ] , and for every no de v , 1 − P u ∈ N ( v ) w uv ∈ [ λ, 1 − λ ] , the r e quir e d numb er of observations is M = ˜ O ( n 3 m ε 4 r 4 (1 − η ) 4 ) . Notice that the result of Theorem 6 is not technically a P AC learnability result, due to the additiv e error that dep ends on the in terv al size. How ever, the theorem provides useful approximation guaran tees when the interv al size is small. A dep endence of the guaran tee on the in terv al size is inevitable. F or when nothing is known ab out the retention rate (for η large enough), all information ab out the marginal activ ation probabilities is lost in the incomplete data: for instance, if no no des are ever ob esrv ed active, we cannot distinguish the case r = 0 from the case in which no no des b ecome activ ated. The exp eriments from the previous section confirm that for moderate uncertain ty ab out the reten tion rate, the performance of our approac h is not v ery sensitiv e to the misestimation of r . 7 Conclusion and F uture W ork W e studied the problem of learning influence functions under incomplete observ ations, whic h are common in real-w orld applications. W e established prop er P AC learnabilit y of influence functions under tw o p opular diffusion mo dels, the DIC and DL T mo del. The incompleteness only has mo derate impact on the sample complexity b ound, but computational efficiency would require an oracle for efficien t empirical risk minimization. W e next designed an efficient improp er learning algorithm with learning guarantees for the DIC, DL T, and CIC models. Our framework can be easily generalized to handle non-uniform (but indep enden t) loss of no de activ ations. W e also ha ve partial results theoretically establishing robustness to misestimations of r (whic h we observ ed exp erimentally in Section 5). A m uch more significan t departure for future w ork would b e non-random loss of activ ations, e.g., losing all activ ations of some randomly c hosen 13 no des. As another direction, it w ould be w orthwhile to generalize the P AC learnabilit y results to other diffusion models, and to design an efficient algorithm with P AC learning guaran tees. A ckno wledgments W e w ould lik e to thank anon ymous reviewers for useful feedback. The research was sp onsored in part b y NSF research grant I IS-1254206 and b y the U.S. Defense Adv anced Researc h Pro jects Agency (DARP A) under the So cial Media in Strategic Communication (SMISC) program, Agreemen t Num b er W911NF-12-1-0034. The views and conclusions are those of the authors and should not be in terpreted as represen ting the official p olicies of the funding agency , or the U.S. Gov ernment. 14 References [1] K. Amin, H. Heidari, and M. Kearns. Learning from con tagion (without timestamps). In Pr o c. 31st Intl. Conf. on Machine L e arning , pages 1845–1853, 2014. [2] F. Chieric hetti, D. Liben-Now ell, and J. M. Klein b erg. Reconstructing Patterns of Informa- tion Diffusion from Incomplete Observ ations. In Pr o c. 23r d A dvanc es in Neur al Information Pr o c essing Systems , pages 792–800, 2011. [3] N. Du, Y. Liang, M.-F. Balcan, and L. Song. Influence F unction Learning in Information Diffusion Netw orks. In Pr o c. 31st Intl. Conf. on Machine L e arning , 2014. [4] N. Du, L. Song, M. Gomez-Ro driguez, and H. Zha. Scalable Influence Estimation in Contin uous- Time Diffusion Net works. In Pr o c. 25th A dvanc es in Neur al Information Pr o c essing Systems , pages 3147–3155, 2013. [5] N. Du, L. Song, S. Y uan, and A. J. Smola. Learning Net works of Heterogeneous Influence. In Pr o c. 24th A dvanc es in Neur al Information Pr o c essing Systems , pages 2780–2788. 2012. [6] Q. Duong, M. P . W ellman, and S. P . Singh. Mo deling information diffusion in netw orks with unobserv ed links. In So cialCom/P ASSA T , pages 362–369, 2011. [7] M. Gomez-Ro driguez, D. Balduzzi, and B. Sc hölkopf. Uncov ering the temp oral dynamics of diffusion netw orks. In Pr o c. 28th Intl. Conf. on Machine L e arning , pages 561–568, 2011. [8] M. Gomez-Ro driguez, J. Lesko vec, and A. Krause. Inferring net works of diffusion and influence. A CM T r ansactions on Know le dge Disc overy fr om Data , 5(4), 2012. [9] A. Go y al, F. Bonchi, and L. V. S. Lakshmanan. Learning influence probabilities in so cial net w orks. In Pr o c. 3r d ACM Intl. Conf. on W eb Se ar ch and Data Mining , pages 241–250, 2010. [10] D. Kemp e, J. Kleinberg, and E. T ardos. Maximizing the Spread of Influence in a So cial Netw ork. In Pr o c. 9th Intl. Conf. on Know le dge Disc overy and Data Mining , pages 137–146, 2003. [11] J. Lesk ov ec, L. Bac kstrom, and J. Klein b erg. Meme-tracking and the dynamics of the news cycle. In Pr o c. 15th Intl. Conf. on Know le dge Disc overy and Data Mining , pages 497–506, 2009. [12] J. Lesko vec, D. Chakrabarti, J. Kleinberg, C. F aloutsos, and Z. Ghahramani. Kronec k er graphs: An approach to mo deling net works. The Journal of Machine L e arning R ese ar ch , 11:985–1042, 2010. [13] A. Y. Lokho v. Reconstructing spreading couplings from partial observ ations of several cascades. In Pr o c. 28th A dvanc es in Neur al Information Pr o c essing Systems , 2016. [14] S. A. Myers and J. Lesk ov ec. On the conv exity of latent so cial net work inference. In Pr o c. 22nd A dvanc es in Neur al Information Pr o c essing Systems , pages 1741–1749, 2010. [15] S. A. My ers, C. Zhu, and J. Lesko vec. Information Diffusion and External Influence in Netw orks. In Pr o c. 18th Intl. Conf. on Know le dge Disc overy and Data Mining , pages 33–41. [16] H. Narasimhan, D. C. P arkes, and Y. Singer. Learnability of Influence in Netw orks. In Pr o c. 27th A dvanc es in Neur al Information Pr o c essing Systems , pages 3168–3176, 2015. 15 [17] N. Natara jan, I. S. Dhillon, P . K. Ra vikumar, and A. T ewari. Learning with noisy labels. In Pr o c. 25th A dvanc es in Neur al Information Pr o c essing Systems , pages 1196–1204, 2013. [18] N. Praneeth and S. Sujay . Learning the Graph of Epidemic Cascades. In Pr o c. 12th ACM Sigmetrics Conf. on Me asur ement and Mo deling of Computer Systems , pages 211–222, 2012. [19] D. Quang, W. M. P , and S. S. P . Mo deling Information Diffusion in Netw orks with Unobserved Links. In So cialCom , pages 362–369, 2011. [20] N. Rosenfeld, M. Nitzan, and A. Glob erson. Discriminativ e learning of infection mo dels. In Pr o c. 9th ACM Intl. Conf. on W eb Se ar ch and Data Mining , pages 563–572, 2016. [21] E. Sadiko v, M. Medina, J. Lesko v ec, and H. Garcia-Molina. Correcting for missing data in information cascades. In Pr o c. 4th A CM Intl. Conf. on W eb Se ar ch and Data Mining , pages 55–64, 2011. [22] L. G. V alian t. A theory of the learnable. Communic ations of the A CM , 27(11):1134–1142, 1984. [23] X. W u, A. Kumar, D. Sheldon, and S. Zilb erstein. P arameter learning for latent netw ork diffusion. In Pr o c. 29th Intl. Joint Conf. on A rtificial Intel ligenc e , pages 2923–2930, 2013. [24] S.-H. Y ang and H. Zha. Mixture of Mutually Exciting Pro cesses for Viral Diffusion. In Pr o c. 30th Intl. Conf. on Machine L e arning , 2013. [25] K. Zhou, H. Zha, and L. Song. Learning Social Infectivit y in Sparse Lo w-rank Net work Using Multi-dimensional Hawk es Processes. In Pr o c. 30th Intl. Conf. on Machine L e arning , 2013. 16 A Pro ofs for Section 3 A.1 Pro of of Theorem 1 Here, we flesh out the pro of sk etch from Section 3 for the DIC mo del. F or the transformed graph ˆ G , w e consider only the influence functions of the n no des in the added lay er V 0 . Recall that w e write ˆ F ( S ) = [ ˆ F 1 0 ( S ) , . . . , ˆ F n 0 ( S )] for the influence function of those nodes. Let ˆ F ∗ b e the ground truth influence function for the same no des, and F ∗ the ground truth influence function for G . Let M ( G ) and M ( ˆ G ) be the class of influence functions of G and ˆ G . F or functions ˆ F , w e write c err sq [ ˆ F ] = E S,A h 1 n P v 0 ∈ V 0 ( χ A ( v 0 ) − ˆ F v 0 ( S )) 2 i . Notice that the ground truth functions minimize the exp ected squared error, i.e., ˆ F ∗ ∈ argmin ˆ F ∈M ( ˆ G ) c err sq [ ˆ F ] and F ∗ ∈ argmin F ∈M ( G ) err sq [ F ] . W e will sho w that err sq [ F ] − err sq [ F ∗ ] can be made arbitrary small. W e first pro v e a v ariation of Theorem 2 from [ 16 ] for learning ˆ F , by verifying that all the supp orting lemmas still apply . The modified Theorem 2 from [16] is the following: Theorem 7. Assume that the le arning algorithm observes M = ˜ Ω ( ˆ − 2 n 3 m ) tr aining c asc ades ˆ C = { ( S i , A 0 i ) } under the DIC mo del. Then, with pr ob ability at le ast 1 − δ , we have c err sq [ ˆ F ] − c err sq [ ˆ F ∗ ] ≤ ˆ . (3) Pr o of. While the cascades in ˆ C are incomplete on V , they are c omplete on V 0 . W e use this completeness of the cascades as follows. Consider the restricted class of the DIC mo del on the transformed graph ˆ G in whic h only the m activ ation probabilities w b et w een no des in V are learnable, while the edges ( v , v 0 ) hav e a fixed w eight of r . Define the log-lik eliho o d for a cascade ( S, A 0 ) as L ( S, A 0 | w ) = X v 0 ∈ V 0 χ A 0 i ( v 0 ) log ( ˆ F w v 0 ( S )) + (1 − χ A 0 i ( v 0 )) log (1 − ˆ F w v 0 ( S )) . The algorithm outputs an influence function ˆ F based on the solution of the follo wing optimization problem: w ∗ ∈ argmax w ∈ [ λ, 1 − λ ] m M X i =1 L ( S i , A 0 i | w ) . As the function ˆ F is learned from the DIC model, Lemma 3 in [ 16 ] carries thorough to establish the Lipschitz contin uity of DIC influence functions. Lemma 8 (Lipsc hitz con tinuit y of DIC influence) . Fix S ⊆ V and v 0 ∈ V 0 . F or any w , w 0 ∈ R m with || w − w 0 || 1 ≤ , we have | ˆ F w v 0 ( S ) − ˆ F w 0 v 0 ( S ) | ≤ . Moreo v er, such instances (on 2 n no des) still only hav e m parameters, and the L ∞ co v ering n um b er b ound in Lemma 8 from [16] applies without an y c hanges. Lemma 9 (Co v ering n umber of DIC influence functions) . The L ∞ c overing numb er of the r estricte d class of the DIC influenc e functions on the tr ansforme d gr aph for r adius is O (( m/ ) m ) . Establishing the sample complexit y b ound on the log-likelihoo d ob jectiv e (Lemma 4 in [ 16 ]) requires that all function v alues be bounded a w a y from 0 and 1 (Lemma 9 in [ 16 ]). W e assume that r < 1 , as Lemma 4 in [ 16 ] directly holds when there are no missing data at all. Let λ > 0 b e the b ound on the edge activ ation probabilities in G from our Theorem 1; that is, λ ≤ w uv ≤ 1 − λ for all 17 u, v ∈ V . Due to the la yered structure of ˆ G , w e ha ve that r · λ n ≤ ˆ F v 0 ( S ) ≤ r · (1 − λ n ) . 8 Therefore, Lemma 4 in [16] carries thorough with the same sample complexity of ˜ O (ˆ − 2 n 3 m ) : Lemma 10 (Sample complexit y guarantee on the log-lik eliho o d ob jectiv e) . Fix , δ ∈ (0 , 1) and M = ˜ Ω(ˆ − 2 n 3 m ) . With pr ob ability at le ast 1 − δ (over the dr aws of the tr aining c asc ades), max w ∈ [ λ, 1 − λ ] m E S,A 0 1 n L ( S, A 0 | w ) − E S,A 0 1 n L ( S, A 0 | w ∗ ) ≤ . As all the lemmas used in the pro of of Theorem 2 from [ 16 ] remain true, w e ha ve prov ed our Theorem 7, with the guaran tee that err sq [ ˆ F ] − err sq [ ˆ F ∗ ] ≤ ˆ . Finally , we recall that according to Equation (1) , F v ( S ) = 1 r · ˆ F v 0 ( S ) and F ∗ v ( S ) = 1 r · ˆ F ∗ v 0 ( S ) , giving us that err sq [ F ] − err sq [ F ∗ ] ( ∗ ) = 1 n X v ∈ V E S ( F v ( S ) − F ∗ v ( S )) 2 Equation (1) = 1 n X v 0 ∈ ˆ V E S ( 1 r ˆ F v 0 ( S ) − 1 r ˆ F ∗ v 0 ( S )) 2 ( ∗ ) = c err sq [ ˆ F ] − c err sq [ ˆ F ∗ ] r 2 Equation (3) ≤ ˆ r 2 (The steps labeled (*) are applications of Equation (4) from [ 16 ].) No w, by taking ˆ = ε · r 2 , with ˜ O ( n 3 m ε 2 r 4 ) incomplete cascades, we obtain that err sq [ F ] − err sq [ F ∗ ] ≤ ε . A.2 Pro of of Theorem 2 W e will sho w that the analogue of Theorem 7 for the DL T mo del also holds. W e do so b y follo wing the same sequence of steps as in App endix A.1 and verifying that all the steps in the pro of of Theorem 2 in [ 16 ] still hold. The main difference is that a new pro of is needed for establishing Lipsc hitz con tinuit y of the DL T influence function with resp ect to the L 1 norm (the analogue of Lemma 3 in [16]). W e begin b y establishing this lemma. Lemma 11 (Lipsc hitz con tin uit y) . Fix S ⊆ V and u ∈ V . F or any w , w 0 ∈ R m with || w − w 0 || 1 ≤ ε , we have that | F w u ( S ) − F w 0 u ( S ) | ≤ ε . Pr o of. As sho wn in [ 10 ], the influence functions under the DL T model can b e also characterized via the reac hability under a distribution o ver live-edge graphs. Sp ecifically , the distribution is as follows [ 10 , Theorem 2.5]: for eac h no de v , pick at most one of its incoming edges at random, selecting the edge from z ∈ N ( v ) with probability w z v and selecting no incoming edge with probabilit y 1 − P z ∈ N ( v ) w z v . F or eac h no de v , let the random v ariable X v b e the incoming neigh b or chosen for v , with X v = ⊥ if v has no incoming edge. F or simplicity of notation, we define w ⊥ v = 1 − P z ∈ N ( v ) w z v . 8 As in the pro of of Lemma 4 in [ 16 ], we assume that there exists a path in the graph ˆ G from a no de in S to no de v 0 ; the cases where this assumption fails can b e handled easily . 18 Define X = ( X v ) v ∈ V , and write X for the set of all such v ectors X . F or any no de v , we write X − v for the set of all v ectors with edges (or ⊥ ) for all nodes except v . And for a vector X ∈ X − v , w e write X [ v 7→ z ] for the vector in whic h all en tries agree with those in X , except for the en try for v whic h is no w z . Let R X ( v , S ) b e the indicator function of whether node v is reachable from the seed set S in the graph ( V , X ) , where w e in terpret X as the set of all edges ( X v , v ) with X v 6 = ⊥ . Claim 2.6 of [ 10 ] implies that F w u ( S ) = X X Y v ∈ V w X v v R X ( u, S ) . W e fix an edge ( y, y 0 ) and tak e the partial deriv ative of F w u ( S ) with resp ect to w y y 0 : ∂ F w u ( S ) ∂ w y y 0 = ∂ ∂ w y y 0 X z ∈ N ( y ) ∪{⊥} w z y X X ∈X − y Y v ∈ V \{ y } w X v v · R X [ y 7→ z ] ( u, S ) = X X ∈X − y Y v ∈ V \{ y } w X v v · R X [ y 7→ y 0 ] ( u, S ) − X X ∈X − y Y v ∈ V \{ y } w X v v · R X [ y 7→⊥ ] ( u, S ) ≤ X X ∈X − y Y v ∈ V \{ y } w X v v = 1 . Therefore, ||∇ w F w u ( S ) || ∞ ≤ 1 , implying Lipschitz contin uity . Next, we b ound the v alues of the influence functions a w a y from 0 and 1. Because each edge weigh t w z v ∈ [ λ, 1 − λ ] by assumption, and we further assumed that w ⊥ v = 1 − P z ∈ N ( v ) w z v ∈ [ λ, 1 − λ ] , it follows directly (as in the pro of for the DIC mo del) that r · λ n ≤ ˆ F v 0 ( S ) ≤ r · (1 − λ n ) . This establishes the analogue of Lemma 9 in [ 16 ], and w e can therefore apply Lemma 4 in [ 16 ], obtaining a sample complexit y of ˜ O ( ˆ − 2 n 3 m ) under the DL T mo del. As all the used lemmas remain true, the results of Theorem 7 also hold for the DL T mo del. Finally , exploiting the same relation b etw een F ( S ) and ˆ F ( S ) as in the proof of Theorem 1 leads to the conclusion of Theorem 2. B Pro of of Theorem 4 Let M = ˜ Ω ( log C 4 r 2 ) , and let F ˜ β ,λ v ( S ) b e the influence functions obtained in Theorem 4. W e will sho w that for an y single no de v , with probability at least 1 − δ /n , E S h ( F ˜ β ,λ v ( S ) − F ∗ v ( S )) 2 i ≤ ε. The theorem then follows b y taking a union bound o ver all n no des. Recall that M λ is function class of all truncated influence functions. W e write R M ( M λ ) := E S i ∼P , ( i ) i ∼ Uniform ( {− 1 , 1 } M ) " sup F ∈M λ 1 M M X i =1 i · F v ( S i ) # 19 for its Rademac her complexit y , where the i ’s are i.i.d. Rademacher (symmetric Bernoulli) random v ariables. By Lemma 12 in [ 3 ], there exists a truncated influence function F ˆ β ,λ v ∈ M λ with K = O ( C 2 ε 2 log C n εδ ) features suc h that E S ∼P h ( F ˆ β ,λ v ( S ) − F ∗ v ( S )) 2 i ≤ 2 ε 2 + 2 λ 2 with probability at least 1 − δ 2 n . Using the log likelihoo d function ` ( t, y ) = y log t + (1 − y ) log (1 − t ) as defined in Section 4, we write the log loss of influence function F v as err log [ F v ] = E S,A [ − ` ( F v ( S ) , A )] . By Lemma 2 in [ 17 ], with probability at least 1 − δ 2 n , err log [ F ˜ β ,λ v ] ≤ min f ∈M λ err log [ f ] + 4 λ · r R M ( M λ ) + r log(2 n/δ ) 2 M . Because F ˆ β ,λ v ∈ M λ , we can b ound that min f ∈M λ err log [ f ] ≤ err log [ F ˆ β ,λ v ( S )] on the right-hand side. Subtracting err log [ F ∗ v ] from both sides, we obtain err log [ F ˜ β ,λ v ] − err log [ F ∗ v ] ≤ err log [ F ˆ β ,λ v ] − err log [ F ∗ v ] + 4 λ · r R M ( M λ ) + r log(2 n/δ ) 2 M . (4) The square and log errors can b e related to eac h other as in the proof of Theorem 2 in [ 16 ], as follo ws: E S h ( F ˜ β ,λ v ( S ) − F ∗ v ( S )) 2 i ≤ 1 2 ( err log [ F ˜ β ,λ v ] − err log [ F ∗ v ]) . Hence, in order to obtain a b ound on E S h ( F ˜ β ,λ v ( S ) − F ∗ v ( S )) 2 i , it suffices to upp er-b ound the righ t-hand side of (4) . The term err log [ F ˆ β ,λ v ] − err log [ F ∗ v ] can b e b ounded as in the pro of of Lemma 2 in [ 3 ], using Lemma 11 and Lemma 16 from [ 3 ]: Assume that F ˆ β ,λ v uses K = Ω( C 2 ˆ 2 log C n ˆ ˆ δ ) features. Then, with probabilit y at least 1 − ˆ δ , w e ha ve err log [ F ˆ β ,λ v ] − err log [ F ∗ v ] ≤ ˆ 2 + λ 2 λ (1 + log 1 λ ) . (5) Next, we b ound the Rademac her complexity of the function class M λ : Lemma 12. The R ademacher c omplexity R M ( M λ ) for the function class M λ with at most K fe atur es is at most q 2 log (1+ K ) M . Pr o of. Recall that w e use basis functions φ i ( S ) := min { 1 , χ > S r T i } . Let W = { φ i | i = 1 , . . . , K } ∪ { 1 } , where 1 is the constan t function with v alue 1 . By definition, we ha ve M λ ⊆ conv ( W ) , where con v ( W ) denotes the conv ex h ull. Therefore, R M ( M λ ) ≤ R M ( con v ( W )) = R M ( W ) . Since | φ i ( S ) | ≤ 1 , b y Massart’s finite lemma 9 , we hav e R M ( W ) ≤ q 2 log (1+ K ) M , completing the pro of. T o finish the pro of of Theorem 4, let b e the desired accuracy . Define ˆ δ = δ 2 n and ˆ = λ = c 0 log 1 , where c 0 is a sufficiently large constant. Then, the righ t-hand side of (5) is upp er-b ounded by ˆ · (1 + log 1 ˆ ) ≤ 2 . 9 Massart’s finite lemma states the follo wing: Let F b e a finite set of functions, such that sup f ∈F 1 n P n i =1 f ( X i ) 2 ≤ C 2 for any v ariables v alues X 1 , . . . , X n . Then, the Rademacher complexit y of F is upp er b ounded b y R n ( F ) ≤ q 2 C 2 log |F | n . 20 With M = Ω( log K 4 r 2 ) , we ha ve 4 λ · r R M ( M λ ) ≤ 4 . Whenev er M = Ω( log n δ 2 ) , we also get that q log( n/δ ) 2 M ≤ 4 . T aking M as the maxim um of the ab ov e three, whic h is satisfied when M = ˜ Ω ( log C 4 r 2 ) , we can substitute all of the b ounds in to the right-hand side of (4) and obtain that E S h ( F ˜ β ,λ v ( S ) − F ∗ v ( S )) 2 i ≤ with probability at least 1 − δ n . No w, taking a union b ound ov er all no des v concludes the proof. Discussion. Notice that when the reten tion rate is 1, our Theorem 4 significantly improv es the sample complexity b ound compared to Du et al. [ 3 ]. The sample complexit y in [ 3 ] is ˜ O ( C 2 3 ) , while our theorem implies a sample complexity of ˜ O ( log C 4 ) under complete observ ations. The impro v emen t is derived from bounding the Rademacher complexit y of the function class M λ instead of the L 2 , ∞ dimension. The Rademac her bound leads to a logarithmic dependence of the sample complexity on the num b er of features K , whereas the L 2 , ∞ b ound results in a polynomial dependence. C Pro ofs for Section 6 C.1 Pro of of Theorem 5 Let r i b e the retention rate of node i and ˆ ε i the desired error guarantee for learning the influence function F v i . It is immediate from the proofs of Theorems 1 and 2 that M = max i { ˜ O ( n 3 m ˆ ε 2 i r 4 i ) } incomplete cascades are sufficient to guarantee that with probabilit y at least 1 − δ , for eac h i , we obtain E S ( F v i ( S ) − F ∗ v i ( S )) 2 ≤ ˆ ε i . The estimation error for the ov erall influence is the av erage ε = 1 n P i ˆ ε i . Given non-uniform reten tion rates r i , we can c ho ose non-uniform ˆ ε i yielding the desired ε , so as to minimize the sample complexit y . The corresp onding optimization problem is the following: Minimize max i 1 ˆ ε 2 i r 4 i sub ject to 1 n X i ˆ ε i = ε, ˆ ε i > 0 for all i. The minim um is achiev ed when all 1 ˆ ε 2 i r 4 i are equal to some constant C , meaning that ˆ ε i = 1 √ C · r 2 i . The constant C can b e obtained from the constrain t 1 n P i ˆ ε i = ε , yielding that C = ¯ r 2 ε 2 , where ¯ r = 1 n P i 1 r 2 i . This completes the pro of of the theorem. C.2 Pro of of Theorem 6 The pro of of Theorem 6 is similar to that of Theorems 1 and 2. W e again treat the incomplete cascades as complete cascades in a transformed graph ˆ G . Because w e no longer know the true reten tion rate r , we cannot set the probabilit y on the egde ( v , v 0 ) to ˆ w v v 0 = r . Instead, w e treat the ˆ w v v 0 as parameters to infer, under the constraint that ˆ w v v 0 ∈ I = [ ¯ r · (1 − η ) , ¯ r · (1 + η )] . W e sp ell out the details of the pro of for the DIC mo del; the pro of for the DL T mo del is practically identical. 21 As in Theorem 1, w e consider only the influence functions of the n no des in the added la yer V 0 . F ollo wing the pro of of Theorem 1, with probability as least 1 − δ , using M = ˜ O ( n 3 m ε 2 ) cascades, for all v 0 ∈ V 0 , E S h ( ˆ F v 0 ( S ) − ˆ F ∗ v 0 ( S )) 2 i ≤ ˆ ε. (6) In the pro of of Theorem 1, the fact that ˆ w v v 0 = r allo w ed us to obtain the influence function at v via F v ( S ) = 1 r · ˆ F v 0 ( S ) . Since the edge probabilities ˆ w v v 0 are now inferred, we instead use the inferred probabilities for obtaining the activ ation functions for nodes v . On the other hand, the ground truth influence functions for v and v 0 are still related via the correct v alue r . W riting ˆ r v = ˆ w v v 0 , this giv es us the follo wing: F v ( S ) = ˆ F v 0 ( S ) ˆ r v F ∗ v ( S ) = ˆ F ∗ v 0 ( S ) r . (7) Consider E S ( F v ( S ) − F ∗ v ( S )) 2 for any no de v . The exp ected squared estimation error for no de v can now b e written as follows: E S ( F v ( S ) − F ∗ v ( S )) 2 Equation (7) = E S ˆ F v 0 ( S ) ˆ r v − ˆ F ∗ v 0 ( S ) r ! 2 = E S ˆ F v 0 ( S ) − ˆ F ∗ v 0 ( S ) r + ˆ F v 0 ( S ) r − ˆ r v r · ˆ r v ! 2 ≤ 1 r 2 · E S h ( ˆ F v i ( S ) − ˆ F ∗ v i ( S )) 2 i (8) + 2 r · E S " ˆ F v 0 ( S ) ˆ r v · | r − ˆ r v | r · | ˆ F v 0 ( S ) − ˆ F ∗ v 0 ( S ) | # (9) + E S " ˆ F 2 v 0 ( S ) ˆ r 2 v · ( r − ˆ r v ) 2 r 2 # . (10) W e will b ound the term (8) using Inequality (6) . In order to bound the terms (9) and (10) , observe the following: • F or all seed sets S and no des v 0 ∈ V 0 , we hav e ˆ F v 0 ( S ) ≤ ˆ r v b y the structure of the transformed graph. • | r − ˆ r v | r ≤ 2 η 1 − η follo ws from the assumption that ˆ r v , r ∈ [ ¯ r · (1 − η ) , ¯ r · (1 + η )] . • By Jensen’s inequalit y and Inequalit y (6), E S h | ˆ F v 0 ( S ) − ˆ F ∗ v 0 ( S ) | i ≤ √ ˆ ε . Using the preceding three inequalities, w e can b ound the term (9) b y 4 η √ ˆ ε r (1 − η ) and the term (10) b y 4 η 2 (1 − η ) 2 . When ˆ ε ≤ εr 2 2 , using the inequalit y (6) , the term (8) is upp er-b ounded b y 1 r 2 E S ( F v i ( S ) − F ∗ v i ( S )) 2 ≤ ε 2 . Similarly , when ˆ ε ≤ ε 2 r 2 (1 − η ) 2 64 η 2 , the additive term (9) is upp er-b ounded b y 2 η √ ˆ ε r (1 − η ) ≤ ε 2 . Thus, 22 taking ˆ ε = min { εr 2 2 , ε 2 r 2 (1 − η ) 2 64 η 2 } , the first tw o terms combined are bounded b y ε . Thus, using M = ˜ O ( n 3 m ε 4 r 4 (1 − η ) 4 ) cascades, with probability at least 1 − δ , for eac h no de v , E S ( F v ( S ) − F ∗ v ( S )) 2 ≤ ε + 4 η 2 (1 − η ) 2 . No w, taking an av erage on b oth sides of the ab ov e equation o ver all the no des v ∈ V concludes the pro of of Theorem 6. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment