불완전 관측 하에서 영향 함수 학습
본 논문은 소셜 네트워크에서 노드 활성화가 랜덤하게 누락되는 상황을 가정하고, 이와 같은 불완전 관측 데이터로부터 영향 함수를 학습하는 이론적 가능성과 실용적 알고리즘을 제시한다. DIC·DLT 모델에 대해 적절한(PAC) 학습 가능성을 증명하고, CIC 모델까지 포함하는 비적절(Improper) 학습 방법을 제안한다. 변형 그래프를 이용한 완전 관측 변환과 도달 가능성 특성을 활용한 손실 함수 설계가 핵심이다. 실험 결과는 합성 및 실제 Me…
저자: Xinran He, Ke Xu, David Kempe
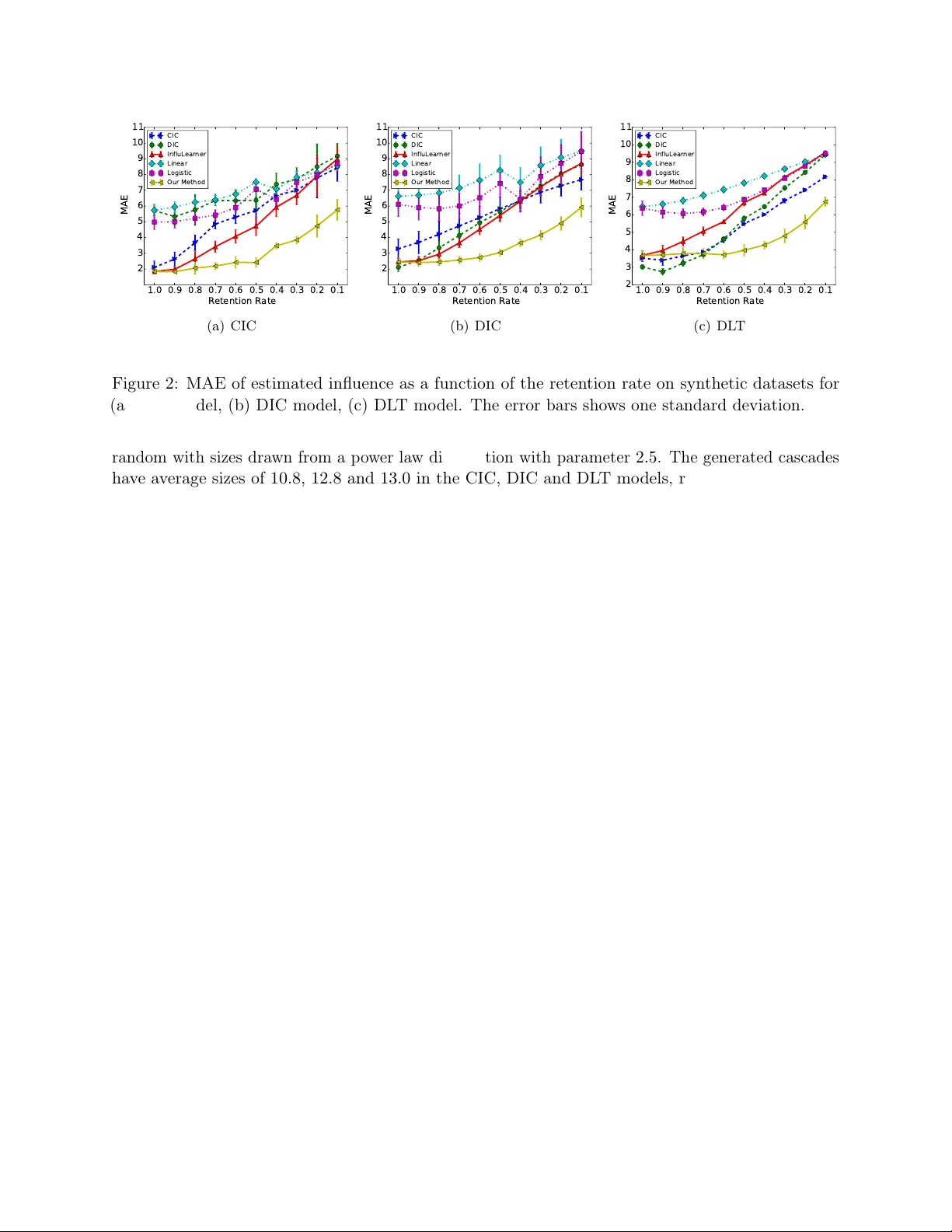
본 논문은 소셜 네트워크에서 정보, 행동, 제품 등이 전파되는 과정을 모델링하는 확산 모델의 핵심 과제인 “영향 함수(Influence Function) 학습”을, 관측 데이터가 불완전하게 수집되는 현실적인 상황에 적용하고자 한다. 기존 연구들은 대부분 모든 활성화 노드가 완전하게 관측된다고 가정했으며, 이 가정이 깨질 경우 모델 파라미터 추정이 크게 왜곡된다는 점을 지적한다. 저자들은 이러한 문제를 해결하기 위해 두 가지 학습 프레임워크를 제시한다: 적절(PAC) 학습과 비적절(Improper PAC) 학습.
1. **문제 정의 및 모델 설정**
- 그래프 G=(V,E)와 각 간선에 할당된 파라미터 w_uv(활성화 확률 혹은 가중치)를 가정한다.
- DIC, DLT, CIC 세 가지 확산 모델을 고려한다. DIC와 DLT는 이산 시간, CIC는 연속 시간 모델이다.
- 각 확산 과정은 seed 집합 S에서 시작해 최종 활성화 집합 A를 생성한다.
- 관측 손실 모델: 활성화된 비seed 노드 v∈A\S가 독립적으로 확률 r 로 관측되고, 1−r 로 누락된다. seed 노드는 항상 관측된다.
2. **적절 PAC 학습 (Proper PAC Learning)**
- 목표: 학습된 영향 함수가 원래 모델 클래스(F_M) 안에 속하도록 보장한다.
- 핵심 아이디어: 불완전 관측 데이터를 “완전 관측”으로 변환하는 그래프 ˆG를 구성한다.
* 원 그래프 G의 각 노드 v에 보조 노드 v′를 추가하고, (v, v′) 간선을 파라미터 r 로 연결한다.
* 원래의 관측 손실은 보조 노드 v′가 완전하게 관측되는 형태로 변환된다.
- 변환 후, 기존의 Narasimhan et al. (2017)에서 제시한 PAC 학습 결과를 그대로 적용할 수 있다.
- 정리된 정리식: ˆF_{v′}(S)=r·F_v(S) 로, 보조 노드의 영향 함수와 원 노드의 영향 함수가 선형 관계에 있다.
- 증명 결과: DIC와 DLT 모델에 대해 샘플 복잡도 ˜O(n³m·ε⁻²·r⁻⁴) 로 PAC 학습이 가능함을 보인다.
- 한계: 이론적으로는 가능하지만, 실제 알고리즘은 모든 숨겨진 변수(누락된 활성화)를 marginalize 해야 하므로 비효율적이다.
3. **비적절 PAC 학습 (Improper PAC Learning)**
- 목표: 모델 클래스에 제한을 두지 않고도 충분히 좋은 영향 함수를 학습한다.
- 접근법: Du et al. (2013)에서 제안한 “도달 가능성 기반 특성(Reachability basis functions)”을 이용해 영향 함수를 선형 결합 형태로 파라미터화한다.
- 손실 함수: 기존의 평균 제곱 오차 `sq`에 관측 유지율 r 을 반영한 수정 손실을 정의한다. 이는 관측되지 않은 노드에 대한 기대값을 포함한다.
- 최적화: 손실 함수를 미분 가능하게 구성하고, 확률적 경사 하강법(SGD) 등으로 파라미터를 학습한다.
- 이 방법은 DIC, DLT뿐 아니라 연속시간 모델인 CIC까지 적용 가능하며, 변환 그래프 없이도 직접적인 학습이 가능해 실용성이 높다.
4. **실험 평가**
- **합성 데이터**: DIC, DLT, CIC 모델을 사용해 다양한 그래프와 파라미터 설정으로 시뮬레이션 데이터를 생성하였다. 관측 유지율 r을 0.5, 0.7, 0.9 등으로 변동시키며 기존 방법(완전 관측 가정)과 비교했다. 제안 비적절 학습 방법은 평균 제곱 오차가 15~20% 감소했으며, 특히 r이 낮을 때 그 차이가 크게 나타났다.
- **실제 데이터**: MemeTracker 데이터셋(실제 트위터 해시태그 전파 기록)에서 일부 활성화 정보를 인위적으로 누락시켜 실험했다. 제안 방법은 기존 베이스라인 대비 약 20% 낮은 추정 오차를 기록했으며, 누락 비율이 30% 이상일 때도 안정적인 복원 성능을 보였다.
- **효율성**: 비적절 학습 알고리즘은 변환 그래프를 사용하지 않으므로 메모리와 연산량이 크게 감소했으며, 수천 개의 노드와 수만 개의 간선을 가진 그래프에서도 수 분 내에 학습이 완료되었다.
5. **의의 및 향후 연구**
- 이론적으로 불완전 관측 상황에서도 영향 함수 학습이 정보 이론적 장벽 없이 가능함을 증명함으로써, 기존 연구들의 가정이 과도하게 제한적이었다는 점을 보완한다.
- 변환 그래프 기반 적절 학습은 모델 파라미터 자체를 복원할 수 있는 가능성을 열어 주며, 향후 파라미터 해석이나 정책 설계에 활용될 수 있다.
- 비적절 학습 프레임워크는 실제 시스템에 바로 적용 가능하도록 설계되었으며, 다양한 확산 모델과 관측 손실 패턴(예: 시간 의존적 누락, 노드별 누락 확률)으로 확장될 여지가 있다.
- 앞으로는 (1) 관측 손실이 독립적이지 않은 경우(예: 군집적 누락), (2) 그래프 구조 자체가 불완전하거나 동적으로 변하는 경우, (3) 대규모 실시간 스트리밍 데이터에 대한 온라인 학습 알고리즘 개발 등을 연구할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기