Q($lambda$) with Off-Policy Corrections
We propose and analyze an alternate approach to off-policy multi-step temporal difference learning, in which off-policy returns are corrected with the current Q-function in terms of rewards, rather than with the target policy in terms of transition p…
Authors: Anna Harutyunyan, Marc G. Bellemare, Tom Stepleton
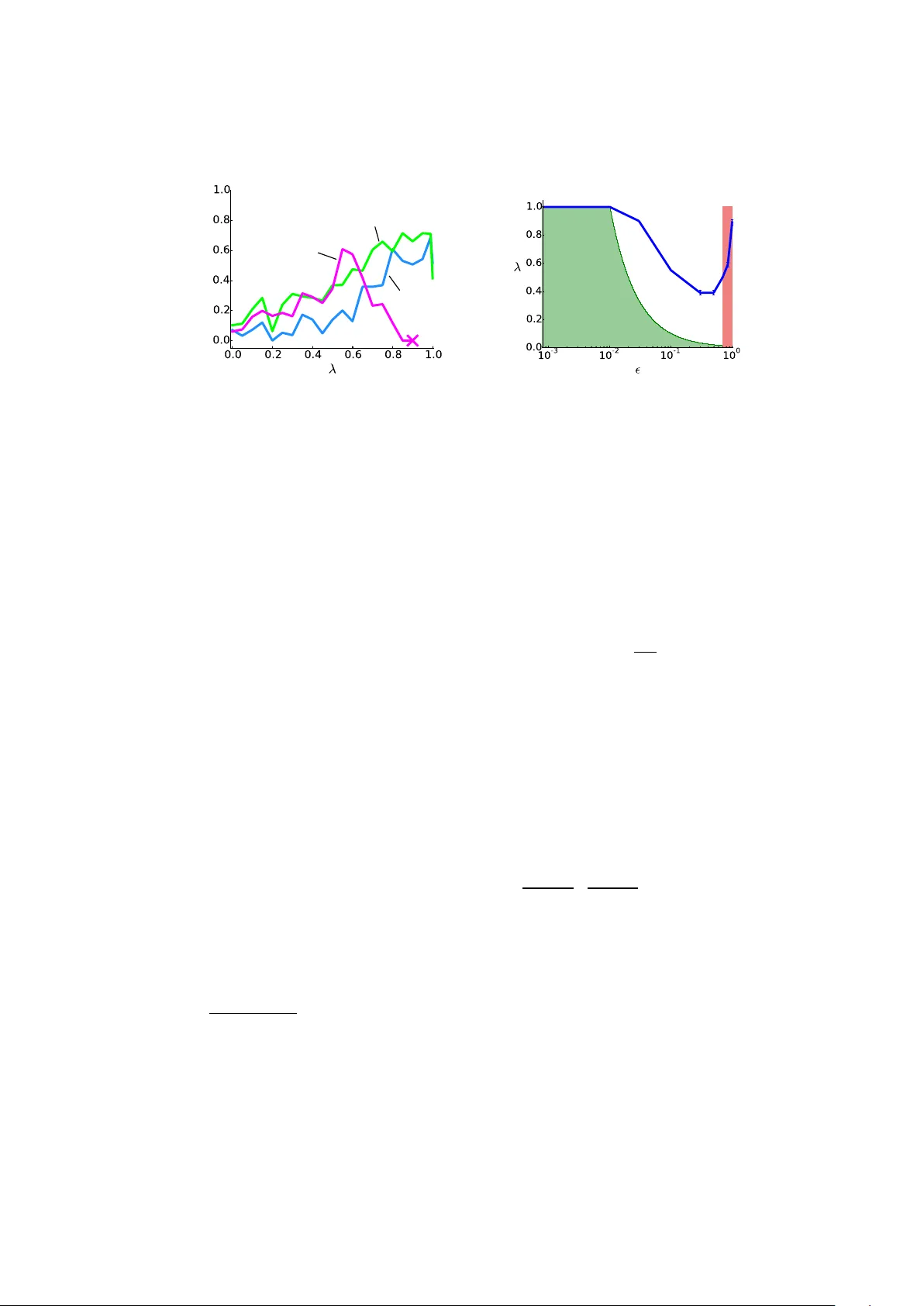
Q( λ ) with Off-P olicy Corrections Anna Harut yuny an 1 ? , Marc G. Bellemare 2 , T om Stepleton 2 , and R ´ emi Munos 2 1 VU Brussel 2 Go ogle DeepMind aharutyu@vub.ac.be {bellemare, stepleton, munos}@google.com Abstract. W e propose and analyze an alternate approach to off-policy m ulti-step temp oral difference learning, in whic h off-p olicy returns are corrected with the curren t Q-function in terms of rew ards, rather than with the target p olicy in terms of transition probabilities. W e prov e that suc h approximate corrections are sufficient for off-policy con vergence b oth in policy ev aluation and con trol, provided certain conditions. These conditions relate the distance b et ween the target and b eha vior policies, the eligibilit y trace parameter and the discoun t factor, and formalize an underlying tradeoff in off-p olicy TD( λ ). W e illustrate this theoretical relationship empirically on a contin uous-state control task. 1 In tro duction In reinforcemen t learning (RL), learning is off-p olicy when samples generated b y a b ehavior p olicy are used to learn ab out a distinct tar get p olicy . The usual approac h to off-p olicy learning is to disregard, or altogether discard transitions whose target policy probabilities are lo w. F or example, W atkins’s Q( λ ) [21] cuts the tra jectory backup as soon as a non-greedy action is encoun tered. Similarly , in p olicy ev aluation, imp ortance sampling methods [8] weigh t the returns according to the mismatc h in the target and b eha vior probabilities of the corresp onding actions. This approach treats transitions conserv atively , and hence may unnec- essarily terminate backups, or introduce a large amoun t of v ariance. Man y off-p olicy methods, in particular of the Monte Carlo kind, ha ve no other option than to judge off-p olicy actions in the probability sense. How ev er, temp or al differ enc e metho ds [14] in RL main tain an approximation of the v alue function along the wa y , with eligiblity tr ac es [22] pro viding a con tinuous link b et w een one-step and Monte Carlo approaches. The v alue function assesses ac- tions in terms of the following expected cum ulative reward, and thus provides a w ay to directly correct immediate r ewar ds , rather than transitions. W e show in this pap er that such approximate corrections can b e sufficient for off-p olicy con- v ergence, sub ject to a tradeoff condition betw een the eligibility trace parameter and the distance b et ween the target and b eha vior p olicies. The t wo extremes of this tradeoff are one-step Q-learning, and on-policy learning. F ormalizing the con tinuum of the tradeoff is one of the main insigh ts of this pap er. ? This work was carried out during an internship at Google DeepMind. In particular, we propose an off-p olicy return op erator that augmen ts the return with a correction term, based on the current approximation of the Q- function. W e then formalize three algorithms stemming from this op erator: (1) off-p olicy Q π ( λ ), and its sp ecial case (2) on -p olicy Q π ( λ ), for policy ev aluation, and (3) Q ∗ ( λ ) for off-p olicy con trol. In p olicy ev aluation, b oth on- and off-p olicy Q π ( λ ) are nov el, but closely related to several existing algorithms of the TD( λ ) family . Section 7 discusses this in detail. W e pro ve conv ergence of Q π ( λ ), sub ject to the λ − ε tradeoff where ε def = max x k π ( ·| x ) − µ ( ·| x ) k 1 is a measure of dissimilarit y b et ween the b eha vior and target p olicies. More precisely , we pro ve that for any amoun t of “off-p olicy-ness” ε ∈ [0 , 2] there is an inheren t maxim um allow ed bac kup length v alue λ = 1 − γ γ ε , and taking λ b elo w this v alue guarantees conv ergence to Q π with- out inv olving p olicy probabilities. This is desirable due to the instabilities and v ariance in tro duced by the lik eliho od ratio products in the importance sampling approac h [9]. In con trol, Q ∗ ( λ ) is in fact iden tical to W atkins’s Q( λ ), except it do es not cut the eligiblit y trace at off-policy actions. Sutton and Barto [16] mention such a v ariation, which they call naive Q( λ ). W e analyze this algorithm for the first time and prov e its con vergence for small v alues of λ . Although we w ere not able to prov e a λ − ε tradeoff similar to the policy ev aluation case, w e provide empirical evidence for the existence of such a tradeoff, confirming the intuition that naiv e Q( λ ) is “not as naive as one migh t at first supp ose” [16]. W e first give the technical bac kground, and define our op erators. W e then sp ecify the incremental v ersions of our algorithms based on these operators, and state their con vergence. W e follo w b y proving con v ergence: sub ject to the λ − ε tradeoff in policy ev aluation, and more conserv atively , for small v alues of λ in con trol. W e illustrate the tradeoff emerge empirically in the Bicycle domain in the control setting. Finally , w e conclude by placing our algorithms in context within existing work in TD( λ ). 2 Preliminaries W e consider an environmen t mo delled by the usual discrete-time Mark ov Deci- sion Pro cess ( X , A , γ , P, r ) comp osed of the finite state and action spaces X and A , a discoun t factor γ , a transition function P mapping eac h ( x, a ) ∈ ( X , A ) to a distribution ov er X , and a rew ard function r : X × A → [ − R max , R max ]. A p olicy π maps a state x ∈ X to a distribution ov er A . A Q-function Q is a mapping X × A → R . Giv en a p olicy π , w e define the op erator P π o ver Q-functions: ( P π Q )( x, a ) def = X x 0 ∈X X a 0 ∈A P ( x 0 | x, a ) π ( a 0 | x 0 ) Q ( x 0 , a 0 ) . T o eac h p olicy π corresp onds a unique Q-function Q π whic h describ es the ex- p ected discoun ted sum of rew ards achiev ed when following π : Q π def = X t ≥ 0 γ t ( P π ) t r , (1) where for an y operator X , ( X ) t denotes t successiv e applications of X , and where we commonly treat r as one particular Q-function. W e write the Bel lman op er ator T π , and the Bel lman e quation for Q π : T π Q def = r + γ P π Q, T π Q π = Q π = ( I − γ P π ) − 1 r . (2) The Bel lman optimality op er ator T is defined as T Q def = r + γ max π P π Q, and it is well known [e.g. 1, 10] that the optimal Q-function Q ∗ def = sup π Q π is the unique solution to the Bellman optimality equation T Q = Q. (3) W e write Greedy ( Q ) def = { π | π ( a | x ) > 0 ⇒ Q ( x, a ) = max a 0 Q ( x, a 0 ) } to denote the set of greedy p olicies w.r.t. Q . Th us T Q = T π Q for an y π ∈ Greed y ( Q ). T emp oral difference (TD) learning [14] rests on the fact that iterates of b oth op erators T π and T are guaranteed to con verge to their resp ectiv e fixed p oin ts Q π and Q ∗ . Given a sample experience x, a, r, x 0 , a 0 , SARSA(0) [12] up dates its Q-function estimate at k th iteration as follows: Q k +1 ( x, a ) ← Q k ( x, a ) + α k δ, δ = r + γ Q k ( x 0 , a 0 ) − Q k ( x, a ) , where δ is the TD-err or , and ( α k ) k ∈ N a sequence of nonnegativ e stepsizes. One need not only consider short exp eriences, but may sample tra jectories x 0 , a 0 , r 0 , x 1 , a 1 , r 1 , . . . , and accordingly apply T π (or T ) rep eatedly . A particu- larly flexible w a y of doing this is via a w eighted sum A λ of suc h n -step op erators: T π λ Q def = A λ [( T π ) n +1 Q ] = Q + ( I − λγ P π ) − 1 ( T π Q − Q ) , A λ [ f ( n )] def = (1 − λ ) X n ≥ 0 λ n f ( n ) . Naturally , Q π remains the fixed p oin t of T π λ . T aking λ = 0 yields the usual Bellman op erator T π , and λ = 1 remov es the recursion on the approximate Q- function, and restores Q π in the Monte Carlo sense. It is well-kno wn that λ trades off the bias from b o otstr apping with an appro ximate Q-function, with the v ariance from using a sampled m ulti-step return [4], with in termediate v alues of λ usually p erforming b est in practice [15, 13]. The ab o v e λ -operator can b e efficien tly implemen ted in the online setting via a mechanism c al led eligibility tr ac es . As w e will see in Section 7, it in fact corresp onds to a n umber of online algorithms, eac h subtly different, of whic h SARSA( λ ) [12] is the canonical instance. Finally , we mak e an imp ortan t distinction b et ween the tar get p olicy π , whic h w e wish to estimate, and the b ehavior p olicy µ , from which the actions hav e been generated. If µ = π , the learning is said to be on-p olicy , otherwise it is off-p olicy . W e will write E µ to denote exp ectations ov er sequences x 0 , a 0 , r 0 , x 1 , a 1 , r 1 , . . . , a i ∼ µ ( ·| x i ), x i +1 ∼ P ( ·| x i , a i ) and assume conditioning on x 0 = x and a 0 = a wherev er appropriate. Throughout, we will write k · k for suprem um norm. 3 Off-P olicy Return Op erators W e will now describe the Monte Carlo off-p olicy c orr e cte d r eturn op er ator R π ,µ that is at the heart of our con tribution. Giv en a target π , and a return generated b y the b eha vior µ , the op erator R π ,µ attempts to approximate a return that w ould ha ve b een generated by π , by utilizing a correction built from a curren t appro ximation Q of Q π . Its application to Q at a state-action pair ( x, a ) is defined as follows: ( R π ,µ Q )( x, a ) def = r ( x, a ) + E µ X t ≥ 1 γ t r t + E π Q ( x t , · ) − Q ( x t , a t ) | {z } off-p olicy correction , (4) where w e use the shorthand E π Q ( x, · ) ≡ P a ∈A π ( a | x ) Q ( x, a ). That is, R π ,µ giv es the usual exp ected discounted sum of future rewards, but each reward in the tra jectory is augmented with an off-p olicy c orr e ction , whic h we define as the difference b et w een the exp e cte d (with resp ect to the target p olicy) Q-v alue and the Q-v alue for the taken action. Th us, how m uch a rew ard is corrected is determined by b oth the appro ximation Q , and the target p olicy probabilities. Notice that if actions are similarly v alued, the correction will ha ve little effect, and learning will b e roughly on-p olicy , but if the Q-function has conv erged to the correct estimates Q π , the correction tak es the immediate rew ard r t to the expected rew ard with resp ect to π exactly . Indeed, as we will see later, Q π is the fixed p oin t of R π ,µ for an y b eha vior p olicy µ . W e define the n -step and λ -versions of R π ,µ in the usual wa y: R π ,µ λ Q def = A λ [ R π ,µ n ] , (5) ( R π ,µ n Q )( x, a ) def = r ( x, a ) + E µ n X t =1 γ t r t + E π Q ( x t , · ) − Q ( x t , a t ) + γ n +1 E π Q ( x n +1 , · ) . Note that the λ parameter here tak es us from TD(0) to the Monte Carlo version of our op erator R π ,µ , rather than the traditional Monte Carlo form (1). 4 Algorithm W e consider the problems of off-p olicy p olicy evaluation and off-p olicy c ontr ol . In b oth problems we are given data generated by a sequence of behavior policies ( µ k ) k ∈ N . In p olicy ev aluation, we wish to estimate Q π for a fixed target policy π . In control, we wish to estimate Q ∗ . Our algorithm constructs a sequence ( Q k ) k ∈ N of estimates of Q π k from tra jectories sampled from µ k , by applying the R π k ,µ k λ -op erator: Q k +1 = R π k ,µ k λ Q k , (6) where π k is the k th in terim target p olicy . W e distinguish b et ween three algo- rithms: Algorithm 1 Q( λ ) with off-p olicy corrections Giv en: Initial Q -function Q 0 , stepsizes ( α k ) k ∈ N for k = 1 . . . do Sample a tra jectory x 0 , a 0 , r 0 , . . . , x T k from µ k Q k +1 ( x, a ) ← Q k ( x, a ) ∀ x, a e ( x, a ) ← 0 ∀ x, a for t = 0 . . . T k − 1 do δ π k t ← r t + γ E π k Q k +1 ( x t +1 , · ) − Q k +1 ( x t , a t ) for all x ∈ X , a ∈ A do e ( x, a ) ← λγ e ( x, a ) + I { ( x t , a t ) = ( x, a ) } Q k +1 ( x, a ) ← Q k +1 ( x, a ) + α k δ π k t e ( x, a ) end for end for end for On-p olicy Q π ( λ ): µ k = π k = π . Off-p olicy Q π ( λ ): µ k 6 = π k = π . Q ∗ ( λ ): π k ∈ Greedy ( Q k ). Off-p olicy Q π ( λ ) for p olicy ev aluation: π k = π is the fixed target p olicy . W e write the corresp onding operator R π λ . On-p olicy Q π ( λ ) for p olicy ev aluation: for the sp ecial case of µ k = µ = π . Q ∗ ( λ ) for off-p olicy control: ( π k ) k ∈ N is a sequence of greedy p olicies with resp ect to Q k . W e write the corresp onding operator R ∗ λ . W e wish to write the update (6) in terms of a simulated tra jectory x 0 , a 0 , r 0 , . . . , x T k dra wn according to µ k . First, notice that (5) can b e rewritten: R π ,µ λ Q ( x, a ) = Q ( x, a ) + E µ X t ≥ 0 ( λγ ) t δ π t , δ π t def = r t + γ E π Q ( x t +1 , · ) − Q ( x t , a t ) , where δ π t is the exp e cte d TD-error. The offline forw ard view 1 is then Q k +1 ( x, a ) ← Q k ( x, a ) + α k T k X t =0 ( γ λ ) t δ π k t , (7) While (7) resem bles many existing TD( λ ) algorithms, it subtly differs from all of them, due to R π ,µ λ (rather than T π λ ) b eing at its basis. Section 7 discusses the distinctions in detail. The practical every-visit [16] form of (7) is written Q k +1 ( x, a ) ← Q k ( x, a ) + α k T X t =0 δ π k t t X s =0 ( γ λ ) t − s I { ( x s , a s ) = ( x, a ) } , (8) 1 The true online v ersion can be deriv ed as given by v an Seijen and Sutton [19] and the corresp onding online backw ard view of all three algorithms is summa- rized in Algorithm 1. The following theorem states that when µ and π are sufficiently close, the off-p olicy Q π ( λ ) algorithm conv erges to its fixed point Q π . Theorem 1. Consider the se quenc e of Q-functions c ompute d ac c or ding to Algo- rithm 1 with fixe d p olicies µ and π . L et ε = max x k π ( ·| x ) − µ ( ·| x ) k 1 . If λε < 1 − γ γ , then under the same c onditions r e quir e d for the c onver genc e of T D ( λ ) (1–3 in Se ction 5.3) we have, almost sur ely: lim k →∞ Q k ( x, a ) = Q π ( x, a ) . W e state a similar, alb eit w eak er result for Q ∗ ( λ ). Theorem 2. Consider the se quenc e of Q-functions c ompute d ac c or ding to A l- gorithm 1 with π k the gr e e dy p olicy with r esp e ct to Q k . If λ < 1 − γ 2 γ , then under the same c onditions r e quir e d for the c onver genc e of TD( λ ) (1–3 in Se ction 5.3) we have, almost sur ely: lim k →∞ Q k ( x, a ) = Q ∗ ( x, a ) . The pro ofs of these theorems rely on showing that R π λ and R ∗ λ are contrac- tions (under the stated conditions), and in voking classical stochastic appro xima- tion con vergence to their fixed p oin t (such as Prop osition 4.5 from [2]). W e will fo cus on the contraction lemmas, whic h are the crux of the pro ofs, then outline the sk etch of the online con vergence argumen t. Discussion Theorem 1 states that for any λ ∈ [0 , 1] there exists some degree of “off-p olicy-ness” ε < 1 − γ λγ under whic h Q k con verges to Q π . This is the λ − ε tradeoff for the off-p olicy Q π ( λ ) learning algorithm for policy ev aluation. In the con trol case, the result of Theorem 2 is w eaker as it only holds for v alues of λ smaller than 1 − γ 2 γ . Notice that this threshold corresp onds to the p olicy ev aluation case for ε = 2 (arbitrary off-policy-ness). W e w ere not able to pro v e con v ergence to Q ∗ for any λ ∈ [0 , 1] and some ε > 0. This is left as an op en problem for no w. The main technical difficulty lies in the fact that in control, the greedy p ol- icy with resp ect to the curren t Q k ma y c hange drastically from one step to the next, while Q k itself changes incrementally (under small learning steps α k ). So the curren t Q k ma y not offer a go od off-p olicy correction to ev aluate the new greedy p olicy . In order to circumv en t this problem we may w ant to use slowly c hanging target p olicies π k . F or example we could keep π k fixed for slowly in- creasing perio ds of time. This can be seen as a form of optimistic p olicy iteration [10] where p olicy improv emen t steps alternate with approximate p olicy ev alua- tion steps (and when the policy is fixed, Theorem 1 guarantees con vergence to the v alue function of that p olicy). Another option would be to define π k as the empirical a verage π k def = 1 k P k i =1 π 0 i of the previous greedy p olicies π 0 i . W e conjec- ture that defining π k suc h that (1) π k c hanges slowly with k , and (2) π k b ecomes increasingly greedy , then w e could extend the λ − ε tradeoff of Theorem 1 to the con trol case. This is left for future w ork. 5 Analysis W e b egin by verifying that the fixed p oin ts of R π ,µ λ in the policy ev aluation and control settings are Q π and Q ∗ , resp ectively . W e then prov e the contractiv e prop erties of these op erators: R π λ is alw ays a con traction and will conv erge to its fixed p oin t, R ∗ λ is a contraction for particular choices of λ (giv en in terms of γ ). The contraction co efficien ts dep end on λ , γ , and ε : the distance b et w een p olicies. Finally , w e giv e a pro of sk etch for online con vergence of Algorithm 1. Before we b egin, it will b e conv enien t to rewrite (4) for all state-action pairs: R π ,µ Q = r + X t ≥ 1 γ t ( P µ ) t − 1 [ P µ r + P π Q − P µ Q ] . W e can then write R π λ and R ∗ λ from (5) as follows: R π λ Q def = Q + ( I − λγ P µ ) − 1 [ T π Q − Q ] , (9) R ∗ λ Q def = Q + ( I − λγ P µ ) − 1 [ T Q − Q ] . (10) It is not surprising that the abov e along with the Bellman equations (2) and (3) directly yields that Q π and Q ∗ are the fixed p oin ts of R π λ and R ∗ λ : R π λ Q π = Q π , R ∗ λ Q ∗ = Q ∗ . It then remains to analyze the b eha vior of R π ,µ λ as it gets iterated. 5.1 λ -return for p olicy ev aluation: Q π ( λ ) W e first consider the case with a fixed arbitrary policy π . F or simplicit y , we tak e µ to b e fixed as well, but the same will hold for any sequence ( µ k ) k ∈ N , as long as eac h µ k satisfies the condition imp osed on µ . Lemma 1. Consider the p olicy evaluation algorithm Q k = ( R π λ ) k Q . Assume the b ehavior p olicy µ is ε -away fr om the tar get p olicy π , in the sense that max x k π ( ·| x ) − µ ( ·| x ) k 1 ≤ ε . Then for ε < 1 − γ λγ , the se quenc e ( Q k ) k ≥ 1 c onver ges to Q π exp onential ly fast: k Q k − Q π k = O ( η k ) , wher e η = γ 1 − λγ (1 − λ + λε ) < 1 . Pr o of. First notice that k P π − P µ k = sup k Q k≤ 1 k ( P π − P µ ) Q k = sup k Q k≤ 1 max x,a X y P ( y | x, a ) X b (( π ( b | y ) − µ ( b | y )) Q ( y , b ) ≤ max x,a X y P ( y | x, a ) X b | π ( b | y ) − µ ( b | y ) | ≤ ε. Let B = ( I − λγ P µ ) − 1 b e the resolv en t matrix. F rom (9) we ha ve R π λ Q − Q π = B T π Q − Q + ( I − λγ P µ )( Q − Q π ) = B r + γ P π Q − Q π − λγ P µ ( Q − Q π ) = B γ P π ( Q − Q π ) − λγ P µ ( Q − Q π ) = γ B (1 − λ ) P π + λ ( P π − P µ ) ( Q − Q π ) . T aking the sup norm, since µ is ε -aw a y from π : kR π λ Q − Q π k ≤ η k Q − Q π k for η = γ 1 − λγ (1 − λ + λε ) < 1. Thus k Q k − Q π k = O ( η k ). 5.2 λ -return for control: Q ∗ ( λ ) W e next consider the case where the k th target policy π k is greedy with resp ect to the v alue estimate Q k . The following Lemma states that is p ossible to select a small, but nonzero λ and still guarantee con v ergence. Lemma 2. Consider the off-p olicy c ontr ol algorithm Q k = ( R ∗ λ ) k Q . Then kR ∗ λ Q k − Q ∗ k ≤ γ + λγ 1 − λγ k Q k − Q ∗ k , and for λ < 1 − γ 2 γ the se quenc e ( Q k ) k ≥ 1 c onver ges to Q ∗ exp onential ly fast. Pr o of. Fix µ and let B = ( I − λγ P µ ) − 1 . Using (10), we write R ∗ λ Q − Q ∗ = B [ T Q − Q + ( I − λγ P µ )( Q − Q ∗ )] = B [ T Q − Q ∗ − λγ P µ ( Q − Q ∗ )] . T aking the sup-norm, since kT Q − Q ∗ k ≤ γ k Q − Q ∗ k , w e deduce the result: R ∗ λ Q − Q ∗ ≤ γ + λγ 1 − λγ Q − Q ∗ . 5.3 Online Conv ergence W e are no w ready to prov e the online con v ergence of Algorithm 1. Let the follo wing hold for every sample tra jectory τ k and all x ∈ X , a ∈ A : 1. Minim um visit frequency: P t ≥ 0 P { x t , a t = x, a } ≥ D > 0. 2. Finite tra jectories: E µ k T 2 k < ∞ , where T k is the length of τ k . 3. Bounded stepsizes: P k ≥ 0 α k ( x, a ) = ∞ , P k ≥ 0 α 2 k ( x, a ) < ∞ . Assumption 2 requires tra jectories to be finite w.p. 1, whic h is satisfied b y pr op er b eha vior p olicies. Equiv alently , we may require from the MDP that all tra jecto- ries even tually reac h a zero-v alue absorbing state. The pro of closely follows that of Prop osition 5.2 from [2], and requires rewriting the up date in the suitable form, and verifying Assumptions (a) through (d) from their Prop osition 4.5. Pr o of. (Sk etch) Let z k,t ( x, a ) def = P t s =0 ( γ λ ) t − s I { ( x s , a s ) = ( x, a ) } denote the accum ulating trace. It follows from Assumptions 1 and 2 that the total update at phase k is b ounded, whic h allows us to write the online v ersion of (8) as Q o k +1 ( x, a ) ← (1 − D k α k ) Q o k ( x, a ) + D k α k R π k ,µ k λ Q o k ( x, a ) + w k + u k w k def = ( D k ) − 1 h X t ≥ 0 z k,t δ π k t − E µ k X t ≥ 0 z k,t δ π k t i , u k def = ( D k α k ) − 1 Q o k +1 ( x, a ) − Q k +1 ( x, a ) , where D k ( x, a ) def = P t ≥ 0 P { x t , a t = x, a } , and w e use the shorthand y k ≡ y k ( x, a ) for α k , D k , w k , u k , and z k,t . Combining Assumptions 1 and 2, w e hav e 0 < D ≤ D k ( x, a ) < ∞ , whic h, combined in turn with Assumption 3, assures that the new stepsize sequence ˜ α k ( x, a ) = ( D k α k )( x, a ) satisfies Assumption (a) of Prop. 4.5. Assumptions (b) and (d) require the v ariance of the noise term w k ( x, a ) to b e b ounded, and the residual u k ( x, a ) to conv erge to zero, b oth of which can b e sho wn iden tically to the corresp onding results from [2], if Assumption 2 and Assumption (a) are satisfied. Finally , Assumption (c) is satisfied by Lemmas 1 and 2 for the p olicy ev aluation and control cases, resp ectiv ely . 2 W e conclude that the sequence ( Q o k ) k ∈ N con verges to Q π or Q ∗ in the resp ectiv e settings, w.p. 1. 6 Exp erimen tal Results Although w e do not ha ve a pro of of the λ − ε tradeoff (see Section 4) in the con trol case, w e wished to in vestigate whether such a tradeoff can b e observed exp erimen tally . T o this end, w e applied Q ∗ ( λ ) to the Bicycle domain [11]. Here, the agen t must simultaneously balance a bicycle and drive it to a goal p osition. Six real-v alued v ariables describ e the state – angle, velocity , etc. – of the bicycle. The reward function is prop ortional to the angle to the goal, and gives -1 for falling and +1 for reac hing the goal. The discount factor is 0.99. The Q-function w as approximated using multilinear interpolation o ver a uniform grid of size 10 × · · · × 10, and the stepsize w as tuned to 0.1. W e are chiefly interested in the in terplay b et ween the λ parameter in Q ∗ ( λ ) and an ε -greedy exploration p olicy . Our main p erformance indicator is the frequency at which the goal is reac hed by the greedy p olicy after 500,000 episodes of training. W e rep ort three findings: 1. Higher v alues of λ lead to impro ved learning; 2. V ery lo w v alues of ε exhibit low er p erformance; and 3. The Q-function diverges when λ is high relativ e to ε . T ogether, these findings suggest that there is indeed a λ − ε tradeoff in the con trol case as well, and lead us to conclude that with prop er care it can b e b eneficial to do off-p olicy con trol with Q ∗ ( λ ). 2 Note that the con trol case go es through without modifications, for the v alues of λ prescrib ed b y Lemma 2. Av erage End Performance ✏ =0 ✏ =0 . 003 ✏ =0 . 03 Maxim um Non-diverging Fig. 1. Left. Performance of Q ∗ ( λ ) on the Bicycle domain. Each configuration is an a verage of five trials. The ’X’ marks the low est v alue of λ for which ε = 0 . 03 causes div ergence. Right. Maxim um non-diverging λ in function of ε . The left-hand shaded region corresp onds to our hypothesized b ound. Parameter settings in the right-hand shaded region do not pro duce meaningful policies. Learning sp eed and p erformance. Figure 1 (left) depicts the p erformance of Q ∗ ( λ ), in terms of the goal-reaching frequency , for three v alues of ε . The agent p erforms best ( p < 0 . 05) for ε ∈ [0 . 003 , 0 . 03] and high (w.r.t. ε ) v alues of λ . 3 Div ergence. F or each v alue of ε , w e determined the highest safe choice of λ whic h did not result in divergence. As Figure 1 (right) illustrates, there is a mark ed decrease in what is a safe v alue of λ as ε increases. Note the left-hand shaded region corresp onding to the p olicy evaluation b ound 1 − γ γ ε . Supp orting our hypothesis on the true b ound on λ (Section 5), it app ears clear that the maxim um safe v alue of λ dep ends on ε . In particular, notice ho w λ = 1 stops div erging exactly where predicted by this bound. 7 Related W ork In this section, w e place the presen ted algorithms in con text of the existing w ork in TD( λ ) [16], fo cusing in particular on action-v alue metho ds. As usual, let ( x t , a t , r t ) t ≥ 0 b e a tra jectory generated by following a behavior p olicy µ , i.e. a t ∼ µ ( ·| x t ). A t time s , SARSA( λ ) [12] updates its Q -function as follows: Q s +1 ( x s , a s ) ← Q s ( x s , a s ) + α s ( A λ R ( n ) s − Q ( x s , a s ) | {z } ∆ s ) , (11) R ( n ) s = s + n X t = s γ t − s r t + γ n +1 Q ( x s + n +1 , a s + n +1 ) , (12) where ∆ s denotes the up date made at time s , and can b e rewritten in terms of one-step TD-errors: 3 Recall that Randløv and Alstrøm’s agent was trained using SARSA( λ ) with λ = 0 . 95. ∆ s = X t ≥ s ( λγ ) t − s δ t , (13) δ t = r t + γ Q ( x t +1 , a t +1 ) − Q ( x t , a t ) . SARSA( λ ) is an on-p olicy algorithm and conv erges to the v alue function Q µ of the b eha vior p olicy . Different algorithms arise b y instan tiating R ( n ) s or ∆ s from (11) differently . T able 1 provides the full details, while in text w e will sp ecify the most rev ealing comp onen ts of the up date. 7.1 P olicy Ev aluation One can imagine considering exp e ctations o v er action-v alues at the corresp onding states E π Q ( x t , · ), in place of the v alue of the sampled action Q ( x t , a t ), i.e.: δ t = r t + γ E π Q ( x t +1 , · ) − E π Q ( x t , · ) . (14) This is the one-step update for Gener al Q-L e arning [18], which is a generalization of Exp e cte d SARSA [20] to arbitrary p olicies. W e refer to the direct eligibilit y trace extensions of these algorithms formed via Equations (11)-(13) by General Q( λ ) and Exp ected SARSA( λ ) (first men tioned b y Sutton et al. [17]) Unfor- tunately , in an off-p olicy setting, General Q( λ ) will not conv erge to the v alue function Q π of the target p olicy , as stated b y the following proposition. Prop osition 1. The stable p oint of Gener al Q( λ ) is Q µ,π = ( I − λγ ( P µ − P π ) − γ P π ) − 1 r which is the fixe d p oint of the op er ator (1 − λ ) T π + λ T µ . Pr o of. W riting the algorithm in operator form, we get R Q = (1 − λ ) X n ≥ 0 λ n h n X t =0 γ t ( P µ ) t r + γ n +1 ( P µ ) n P π Q i = X t ≥ 0 ( λγ ) t ( P µ ) t h r + (1 − λ ) γ P π Q i = ( I − λγ P µ ) − 1 h r + (1 − λ ) γ P π Q i . Th us the fixed p oin t Q µ,π of R satisfies the following: Q µ,π = ( I − λγ P µ ) − 1 h r + (1 − λ ) γ P π Q µ,π i = (1 − λ ) T π Q µ,π + λ T µ Q µ,π . Solving for Q µ,π yields the result. Alternativ ely to replacing both terms with an expectation, one may only replace the v alue at the next state x t +1 b y E π Q ( x t +1 , · ), obtaining: δ π t = r t + γ E π Q ( x t +1 , · ) − Q ( x t , a t ) . (15) This is exactly our p olicy ev aluation algorithm Q π ( λ ). Sp ecifically , when π = µ , w e get the on-p olicy Q π ( λ ). The induced on-p olicy correction ma y serve as a v ariance reduction term for Exp ected SARSA( λ ) (it may b e helpful to refer to the n -step return in T able 1 to observ e this), but w e leav e v ariance analysis of this algorithm for future w ork. When π 6 = µ , w e reco ver off-p olicy Q π ( λ ), whic h (under the stated conditions) conv erges to Q π . T arget Policy Probabilit y Metho ds: The algorithms ab o v e directly descend from basic SARSA( λ ), but often learning off-p olicy requires sp ecial treatment. F or example, a typical off-p olicy technique is imp ortance sampling (IS) [9]. It is a classical Monte Carlo metho d that allows one to sample from the av ailable distribution, but obtain (un biased or consistent) samples of the desired one, by rew eighing the samples with their likelihoo d ratio according to the tw o distribu- tions. That is, the up dates for the ordinary p er-de cision IS algorithm for p olicy ev aluation are made as follo ws: ∆ s = X t ≥ s ( λγ ) t − s δ t t Y i = s +1 π ( a i | x i ) µ ( a i | x i ) δ t = r t + γ π ( a t +1 | s t +1 ) µ ( a t +1 | s t +1 ) Q ( x t +1 , a t +1 ) − Q ( x t , a t ) . This family of algorithms conv erges to Q π with probability 1, under an y soft, stationary behavior µ [8]. There are several (recent) off-p olicy algorithms that reduce the v ariance of IS methods, at the cost of added bias [5, 6, 3]. Ho wev er, off-policy Q π ( λ ) is p erhaps related closest to the T r e e-Backup (TB) algorithm , also discussed by Precup et al. [8]. Its one-step TD-error is the same as (15), the algorithms bac k up the same tree, and neither requires knowledge of the b eha vior p olicy µ . The imp ortan t difference is in the weigh ting of the up dates. As an off-p olicy precaution, TB( λ ) weighs up dates along a tra jectory with the cumulativ e target probabilit y of that tra jectory up until that p oin t: ∆ s = X t ≥ s ( λγ ) t − s δ π t t Y i = s +1 π ( a i | x i ) . (16) The weigh ting simplifies the conv ergence argument, allowing TB( λ ) to con- v erge to Q π without further restrictions on the distance b et ween µ and π [8]. The dra wback of TB( λ ) is that in the case of near on-p olicy-ness (when µ is close to π ) the pro duct of the probabilities cuts the traces unnecessarily (es- p ecially when the p olicies are sto c hastic). What we sho w in this pap er, is that plain TD-learning c an conv erge off-p olicy with no sp ecial treatmen t, sub ject to a tradeoff condition on λ and ε . Under that condition, Q π ( λ ) applies b oth on- and off-p olicy , without mo difications. An ideal algorithm should b e able to au- tomatically cut the traces (lik e TB( λ )) in case of extreme off-p olicy-ness while rev erting to Q π ( λ ) when b eing near on-policy . 7.2 Con trol P erhaps the most p opular version of Q( λ ) is due to W atkins and Day an [21]. Off-p olicy , it truncates the return and b ootstraps as so on as the behavior p olicy tak es a non-greedy action, as describ ed b y the following update: ∆ s = s + τ X t = s ( λγ ) t − s δ t , (17) where τ = min { u ≥ 1 : a s + u / ∈ arg max a Q ( x s + u , a ) } . Note that this up date is a sp ecial case of (16) for deterministic greedy policies, with Q t i = s +1 I { a i ∈ arg max a Q ( x i , a ) } replacing the probabilit y pro duct. When the policies µ and π are not too similar, and λ is not to o small, the truncation ma y greatly reduce the b enefit of complex bac kups. Q( λ ) of P eng and Williams [7] is meant to remedy this, by being a hy- brid b et w een SARSA( λ ) and W atkins’s Q( λ ). Its n -step return P s + n t = s γ t − s r t + γ n +1 max a Q ( x s + n +1 , a ) requires the follo wing form for the TD-error: δ t = r ( x t , a t ) + γ max a Q ( x t +1 , a ) − max a Q ( x t , a ) . This is, in fact, the same update rule as the General Q( λ ) defined in (14), where π is the greedy p olicy . F ollo wing the same steps as in the proof of Prop osition 1, the limit of this algorithm (if it conv erges) will b e the fixed p oin t of the op erator (1 − λ ) T + λ T µ whic h is different from Q ∗ unless the b eha vior is alwa ys greedy . Sutton and Barto [16] mention another, naive v ersion of W atkins’s Q( λ ) that do es not cut the trace on non-greedy actions. That is exactly the Q ∗ ( λ ) algo- rithm describ ed in this pap er. Notice that despite the similarity to W atkins’s Q( λ ), the equiv alence representation for Q ∗ ( λ ) is different from the one that w ould be derived by setting τ = ∞ in (17), since the n -step return uses the c orr e cte d immediate reward r t + γ max a Q ( x t , a ) − Q ( x t , a t ) instead of the im- mediate reward alone. This correction is in visible in W atkins’s Q( λ ), since the b eha vior policy is assumed to b e greedy , before the return is cut off. 8 Conclusion W e formulated new algorithms of the TD( λ ) family for off-p olicy p olicy ev alu- ation and con trol. Unlik e traditional off-p olicy learning algorithms, these meth- o ds do not in v olve weigh ting returns b y their p olicy probabilities, yet under the righ t conditions conv erge to the correct TD fixed points. In policy ev aluation, con vergence is sub ject to a tradeoff b et ween the degree of b ootstrapping λ , dis- tance b et w een p olicies ε , and the discount factor γ . In control, determining the existence of a non-trivial ε -dep enden t b ound for λ remains an op en problem. Supp orted b y telling empirical results in the Bicycle domain, w e hypothesize that such a b ound exists, and closely resembles the 1 − γ γ ε b ound from the p olicy ev aluation case. Ac kno wledgements The authors thank Hado v an Hasselt and others at Go ogle DeepMind, as w ell as the anonymous reviewers for their though tful feedback on the paper. References 1. Ric hard Bellman. Dynamic Pr o gr amming . Princeton Univ ersity Press, 1957. 2. Dimitry P . Bertsek as and John N. Tsitsiklis. Neur o-Dynamic Pr o gr amming . A thena Scien tific, 1996. 3. Assaf Hallak, Aviv T amar, R´ emi Munos, and Shie Mannor. Generalized emphatic temp oral difference learning: Bias-v ariance analysis. , 2015. 4. Mic hael J. Kearns and Satinder P . Singh. Bias-v ariance error b ounds for temp oral difference up dates. In Confer enc e on Computational L e arning The ory , pages 142– 147, 2000. 5. Ashique R. Mahmo od and Ric hard S. Sutton. Off-p olicy learning based on weigh ted imp ortance sampling with linear computational complexity . In Confer enc e on Un- c ertainty in A rtificial Intel ligenc e , 2015. 6. Ashique R. Mahmo od, Huizhen Y u, Martha White, and Ric hard S. Sutton. Em- phatic temp oral-difference learning. arXiv pr eprint arXiv:1507.01569 , 2015. 7. Jing Peng and Ronald J. Williams. Incremental multi-step q-learning. Machine L e arning , 22(1-3):283–290, 1996. 8. Doina Precup, Richard S. Sutton, and Satinder Singh. Eligibilit y traces for off- p olicy p olicy ev aluation. In International Confer enc e on Machine L e arning , 2000. 9. Doina Precup, Richard S. Sutton, and Sanjoy Dasgupta. Off-p olicy temporal- difference learning with function approximation. In International Confer enc e on Machine L e arning , 2001. 10. Martin L. Puterman. Markov Decision Pr o c esses: Discr ete Sto chastic Dynamic Pr o gr amming . John Wiley & Sons, Inc., New Y ork, NY, USA, 1st edition, 1994. 11. Jette Randløv and Preb en Alstrøm. Learning to drive a bicycle using reinforcemen t learning and shaping. In International Confer ence on Machine L e arning , 1998. 12. Ga vin A. Rummery and Mahesan Niranjan. On-line q-learning using connectionist systems. T echnical rep ort, Cambridge Universit y Engineering Department., 1994. 13. Satinder Singh and Peter Day an. Analytical mean squared error curves for tem- p oral difference learning. Machine L e arning , 32(1):5–40, 1998. 14. Ric hard S. Sutton. Learning to predict by the methods of temp oral differences. Machine le arning , 3(1):9–44, 1988. 15. Ric hard S. Sutton. Generalization in reinforcemen t learning: Successful examples using sparse coarse coding. In A dvanc es in Neural Information Pr o c essing Systems , 1996. 16. Ric hard S. Sutton and Andrew G. Barto. R einforc ement le arning: An intr o duction . Cam bridge Univ Press, 1998. 17. Ric hard S. Sutton, Ashique R. Mahmo od, Doina Precup, and Hado v an Hasselt. A new q ( λ ) with interim forw ard view and monte carlo equiv alence. In International Confer enc e on Machine L e arning , pages 568–576, 2014. 18. Hado Philip v an Hasselt. Insights in R einfor c ement L e arning: formal analysis and empiric al evaluation of tempor al-differ enc e le arning algorithms . PhD thesis, Univ ersiteit Utrec ht, January 2011. 19. Harm v an Seijen and Richard S. Sutton. T rue online TD( λ ). In International Confer enc e on Machine L e arning , pages 692–700, 2014. 20. Harm v an Seijen, Hado v an Hasselt, Shimon Whiteson, and Marco Wiering. A theoretical and empirical analysis of exp ected sarsa. In A daptive Dynamic Pr o- gr amming and R einfor c ement L e arning , pages 177–184. IEEE, 2009. 21. Christopher J. C. H. W atkins and Peter Day an. Q-learning. Machine Le arning , 8 (3):272–292, 1992. 22. Christopher John Cornish Hellab y W atkins. L e arning fr om delaye d r ewar ds . PhD thesis, King’s College, Cam bridge, 1989. T able 1. Comparison of the update rules of sev eral learning algorithms using the λ -return. W e show both the n -step return and the resulting update rule for the λ -return from an y state x s when follo wing a b eha vior policy a t ∼ µ ( ·| x t ). T op part. P olicy ev aluation algorithms: SARSA( λ ), Exp ected SARSA( λ ), General Q( λ ), Per-Decision Importance Sampling (PDIS( λ )), TB( λ ), and Q π ( λ ), in b oth on-p olicy (i.e. π = µ ) and off-p olicy settings (with a target p olicy π 6 = µ ). Note the same Q π ( λ ) equation applies to b oth on- and off-p olicy settings. W e abbreviate π i ≡ π ( a i | x i ), µ i ≡ µ ( a i | x i ), ρ i ≡ π i /µ i , and write E a 6 = b π Q ( x, · ) ≡ P a ∈A\ b π ( a | x ) Q ( x, a ). Bottom part, control algorithms: W atkins’s Q ( λ ), Peng and Williams’s Q ( λ ), and Q ∗ ( λ ). The FP column denotes the stable point of these algorithms (i.e. the fixed point of the expected up date), regardless of whether the algorithm con verges to it. General Q( λ ) may conv erge to Q µ,π defined as the fixed p oin t of the Bellman op erator (1 − λ ) T π + λ T µ . The fixed p oin t of W atkins’s Q( λ ) is Q ∗ but the case λ > 0 ma y not b e significan tly b etter than λ = 0 (regular Q-learning) if the b eha vior policy is different from the greedy one. The fixed p oin t Q µ, ∗ of Peng and Williams’s Q ( λ ) is the fixed p oin t of (1 − λ ) T + λ T µ , which is different from Q ∗ when µ 6 = π (see Proposition 1). The algorithms analyzed in this paper are Q π ( λ ) and Q ∗ ( λ ), for whic h conv ergence to respectively Q π and Q ∗ o ccurs under some conditions (see Lemmas). Algorithm n -step return Up date rule for the λ -return FP TD( λ ) P s + n t = s γ t − s r t + γ n +1 V ( x s + n +1 ) P t ≥ s ( λγ ) t − s δ t V µ (on-p olicy) δ t = r t + γ V ( x t +1 ) − V ( x t ) SARSA( λ ) P s + n t = s γ t − s r t + γ n +1 Q ( x s + n +1 , a s + n +1 ) P t ≥ s ( λγ ) t − s δ t Q µ (on-p olicy) δ t = r t + γ Q ( x t +1 , a t +1 ) − Q ( x t , a t ) E SARSA( λ ) P s + n t = s γ t − s r t + γ n +1 E µ Q ( x s + n +1 , · ) P t ≥ s ( λγ ) t − s δ t + E µ Q ( x s , · ) − Q ( x s , a s ) Q µ (on-p olicy) δ t = r t + γ E µ Q ( x t +1 , · ) − E µ Q ( x t , · ) General Q( λ ) P s + n t = s γ t − s r t + γ n +1 E π Q ( x s + n +1 , · ) P t ≥ s ( λγ ) t − s δ t + E π Q ( x s , · ) − Q ( x s , a s ) Q µ,π (off-p olicy) δ t = r t + γ E π Q ( x t +1 , · ) − E π Q ( x t , · ) PDIS( λ ) P s + n t = s γ t − s r t Q t i = s +1 ρ i P t ≥ s ( λγ ) t − s δ t Q t i = s +1 ρ i Q π (off-p olicy) + γ n +1 Q ( x s + n +1 , a s + n +1 ) Q s + n i = s ρ i δ t = r t + γ ρ t +1 Q ( x t +1 , a t +1 ) − Q ( x t , a t ) TB( λ ) P s + n t = s γ t − s Q t i = s +1 π i r t + γ E a 6 = a t +1 π Q ( x t +1 , · ) P t ≥ s ( λγ ) t − s δ t Q t i = s +1 π i Q π (off-p olicy) + γ n +1 Q s + n +1 i = s +1 π i Q ( x s + n +1 , a s + n +1 ) δ t = r t + γ E π Q ( x t +1 , · ) − Q ( x t , a t ) Q π ( λ ) P s + n t = s γ t − s r t + E π Q ( x t , · ) − Q ( x t , a t ) P t ≥ s ( λγ ) t − s δ t Q π (on/off-p olicy) + γ n +1 E π Q ( x s + n +1 , · ) δ t = r t + γ E π Q ( x t +1 , · ) − Q ( x t , a t ) Q( λ ) P s + n t = s γ t − s r t + γ n +1 max a Q ( x s + n +1 , a ) P s + τ t = s ( λγ ) t − s δ t Q t i = s +1 Q ∗ (W atkins’s) (for any n < τ = arg min u ≥ 1 I { π s + u 6 = µ s + u } ) δ t = r t + γ max a Q ( x t +1 , a ) − Q ( x t , a t ) Q( λ ) P s + n t = s γ t − s r t + γ n +1 max a Q ( x s + n +1 , a ) P s + n t = s ( λγ ) t − s δ t + max a Q ( x s , a ) − Q ( x s , a s ) Q µ, ∗ (P & W’s) δ t = r t + γ max a Q ( x t +1 , a ) − max a Q ( x t , a ) Q ∗ ( λ ) P s + n t = s γ t − s r t + max a Q ( x t , a ) − Q ( x t , a t ) P t ≥ s ( λγ ) t − s δ t Q ∗ + γ n +1 max a Q ( x s + n +1 , a ) δ t = r t + γ max a Q ( x t +1 , a ) − Q ( x t , a t )
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment