오프폴리시 보정이 적용된 Q(λ) 알고리즘
본 논문은 행동 정책과 목표 정책이 다를 때, 전통적인 중요도 가중치 대신 현재 추정된 Q‑함수를 이용해 보상을 직접 보정하는 새로운 오프폴리시 TD(λ) 방법을 제안한다. 보정된 반환 연산자를 정의하고, 정책 평가와 제어 두 경우에 대해 λ와 정책 차이 ε 사이의 수렴 조건(λ‑ε 트레이드오프)을 이론적으로 증명한다. 또한 연속 상태 제어 과제인 Bicycle 도메인에서 실험을 통해 제시된 이론적 관계를 검증한다.
저자: Anna Harutyunyan, Marc G. Bellemare, Tom Stepleton
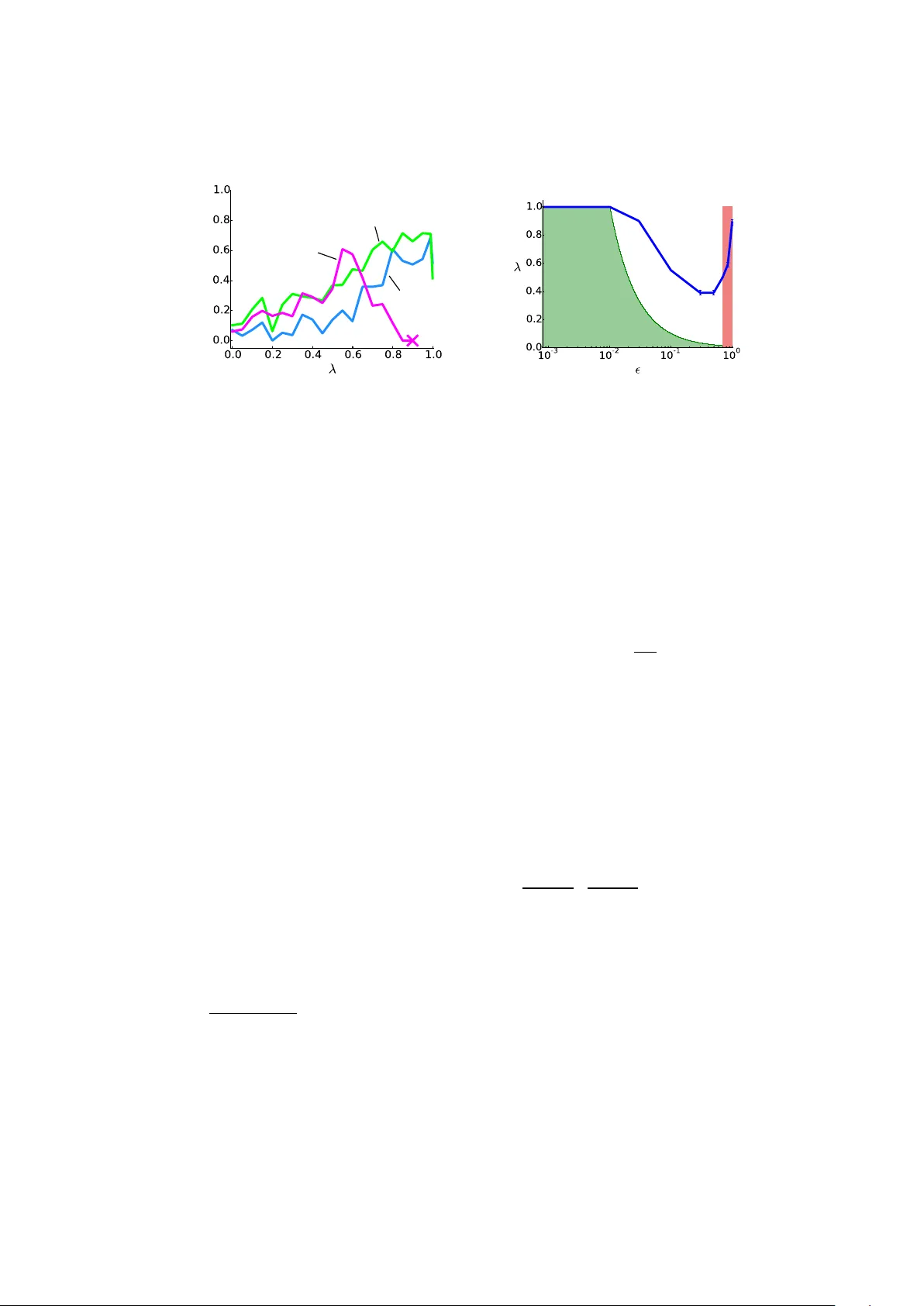
본 논문은 강화학습에서 행동 정책(behavior policy)과 목표 정책(target policy)이 다를 때 발생하는 오프폴리시 학습 문제를 새로운 관점에서 접근한다. 전통적인 오프폴리시 방법은 중요도 샘플링을 통해 행동 정책과 목표 정책 사이의 확률 차이를 보정하지만, 이는 높은 분산을 초래하고, 특히 다단계 반환을 사용할 경우 백업이 조기에 종료되는 현상이 있다. 저자들은 이러한 한계를 극복하기 위해, 현재 추정된 Q‑함수를 이용해 즉시 보상을 목표 정책의 기대값으로 보정하는 새로운 연산자 \(R_{\pi,\mu}\) 를 정의한다.
연산자 \(R_{\pi,\mu}\)는 상태‑행동 쌍 \((x,a)\)에 대해
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기