Symmetry-free SDP Relaxations for Affine Subspace Clustering
We consider clustering problems where the goal is to determine an optimal partition of a given point set in Euclidean space in terms of a collection of affine subspaces. While there is vast literature on heuristics for this kind of problem, such appr…
Authors: Francesco Silvestri, Gerhard Reinelt, Christoph Schn"orr
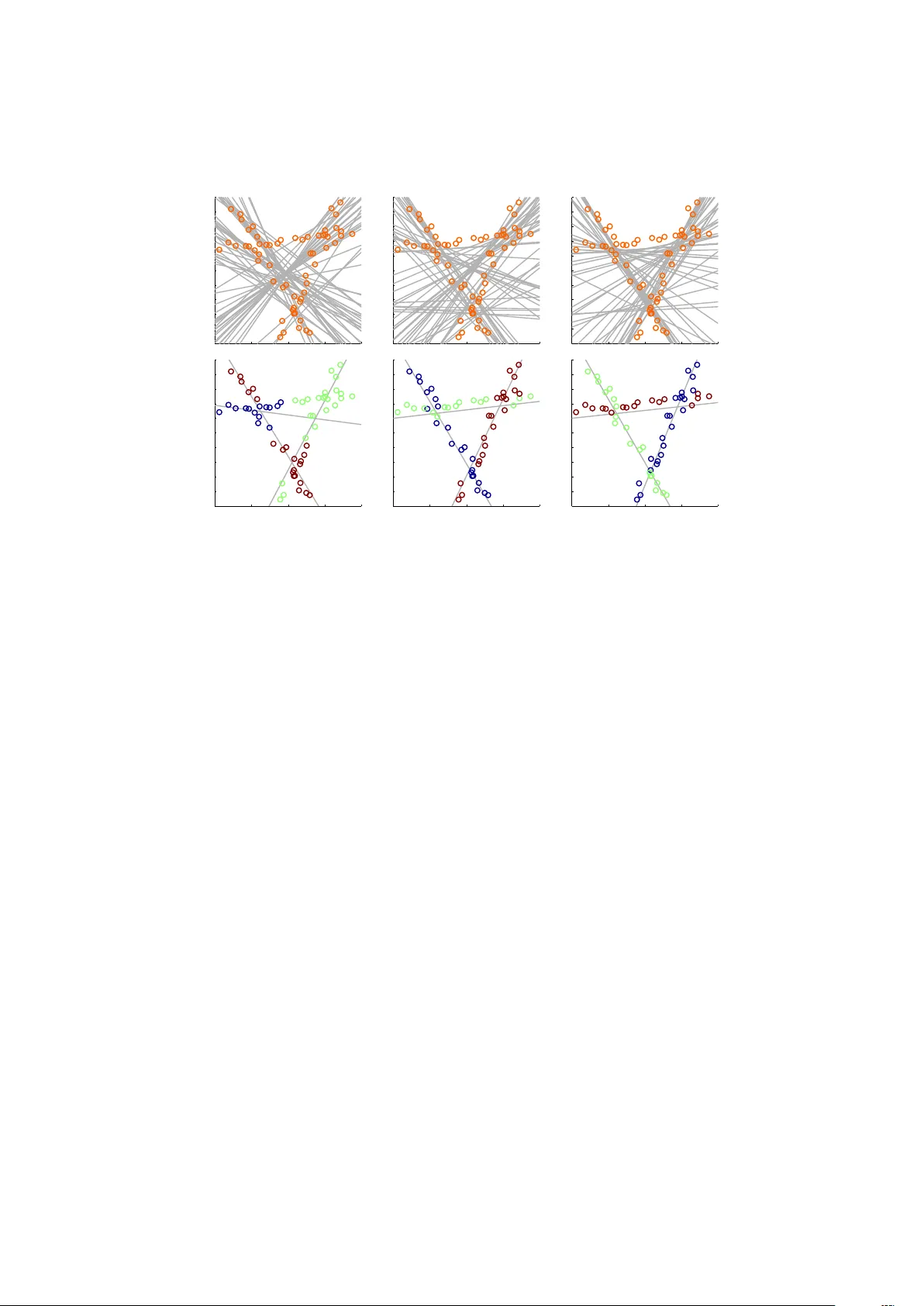
Symmetry-free SDP Relaxations for Affine Subspace Clustering ∗ F rancesco Silv estri † , ‡ Gerhard Reinelt † Christoph Sc hn¨ orr § April 21, 2022 Abstract W e consider clustering problems where the goal is to determine an optimal partition of a given point set in Euclidean space in terms of a collection of affine subspaces. While there is v ast literature on heuristics for this kind of problem, such approaches are known to b e susceptible to p oor initializations and getting trapp ed in bad lo cal optima. W e alleviate these issues b y in troducing a semidefinite relaxation based on Lasserre’s metho d of moments. While a similiar approach is known for classical Euclidean clustering problems, a generalization to our more general sub- space scenario is not straighforward, due to the high symmetry of the ob jective function that weak ens any conv ex relaxation. W e therefore in- tro duce a new mechanism for symmetry breaking based on cov ering the feasible region with p olytopes. Additionally , w e introduce and analyze a deterministic rounding heuristic. 1 In tro duction 1.1 Bac kground Giv en p oin ts b i ∈ R d , i ∈ [ n ] := { 1 , 2 , . . . , n } and k ∈ N , the classical Euclidean clustering problem asks to join tly minimize the ob jectiv e min u,x X i ∈ [ n ] X j ∈ [ k ] u ij k x j − b i k 2 (1) with resp ect to c entr oids x j ∈ R d , j ∈ [ k ], and assignment variables u ij ∈ { 0 , 1 } suc h that eac h row of the assignment matrix U = ( u ij ) i,j ∈ { 0 , 1 } n × k only con tains a single one. While optimizing o ver b oth sets of v ariables jointly is known to b e NP-hard due to its nonlinear, com binatorial structure, fixing one set of v ariables imme- diately leads to trivial subproblems. F or this reason, many p opular heuristics ∗ Authors gratefully acknowledge supp ort by the German Research F oundation (DFG), grant GRK 1653. † Institut f ¨ ur Informatik, Heidelb erg Universit y , INF205, 69120 Heidelb erg, Germany ‡ IWR, Heidelb erg Universit y , INF205, 69120 Heidelb erg, Germany § Institut f ¨ ur Angewandte Mathematik, Heidelb erg Universit y , INF205, 69120 Heidelb erg, Germany 1 ( k -means, mean-shift, etc. – cf. [11]) fo cus on alternatingly fixing one set of v ariables while optimizing the remaining ones. Although these heuristics are generally easy to implement and fast, they strongly dep end on prop er initial- izations and may easily get stuck in lo cal optima without any approximation guaran tees. This shortcoming can be av oided b y turning to combinatorial optimization tec hniques (e.g. [2]), but they do not scale up to large data sets. Alternativ ely , a semidefinite conv ex relaxation [6] has b een suggested. This approac h is remark able in that it a v oids the inherent problems with symmetry of (1) for con vex relaxations: Giv en any solution { x j } j ∈ [ k ] , U = [ U 1 , . . . , U k ] of (1), as well as a p erm utation π of [ k ], we get another solution { x π ( j ) } j ∈ [ k ] , [ U π (1) , . . . , U π ( k ) ] with equal ob- jectiv e v alue. F or this reason, con v ex relaxations tend to av erage o ver optimal solution through con vex combinations, making it nearly imposs i ble to recov er information ab out the individual clusters. The approach of [6] av oids this issue b y reducing the problem to a linear program ov er pro jection matrices constructed from U , which can be effectiv ely appro ximated by SDPs. This reduction how ever essen tially dep ends on the sp e cific simple close d form solution of optimal centroids x j , when the assignmen t v ariables U are fixed. In this pap er, we fo cus on con vex relaxations of the significantly more in- v olved problem min u,x X i ∈ [ n ] X j ∈ [ k ] u ij k A i x j − b i k 2 2 (2) with given data ( A i , b i ) ∈ R l × d × R l , i ∈ [ n ], unknown parameters x j ∈ R d , j ∈ [ k ], and an unknown assignmen t matrix U = ( u ij ) i,j ∈ { 0 , 1 } n × k . In comparison with (1), this approach extends the representation of data by p oints to affine subsp ac es , which is significan t for many applications. Not surprisingly , the approach of [6] cannot b e adapted to this adv anced setting. While it is possible, of course, to give the closed form of an optimal x j for fixed U , namely x j ( U ) = X i ∈ [ n ] u ij A > i A i † X i ∈ [ n ] u ij A > i b i , (3) this close d form inv olv es pseudo inv erses ( . . . ) † of linear functions of U and hence do es not yield an y exploitable structures for the reduced problem. In fact, due to the nonlinearity of ( . . . ) † , it is not even clear how to express x j ( U ) as a rational function in U without explicitly computing eac h x j ( U ) for ev ery p ossible choice of U b eforehand. Unions of subspaces as signal mo dels hav e b een adv o cated and studied in the researc h field of compressive sensing during the last years [1]. In order to prov e reco very guarantees by conv ex programming, sparsity assumptions ab out the represen tation are essen tial. Regarding the subspace clustering problem, such assumptions require the subspace dimensions to be lo w relativ e to the dimension of the em b edding space. In this pap er, w e do not rely on any such assumption. F or example, even the simplest case of clustering one-dimensional subspaces in R 2 violates the “indep enden t subspaces” assumption of [3, Section 4]. 2 1.2 Con tribution Our main con tribution is a hierarch y of con v ex relaxations for problem (2) based on Lasserre’s metho d of moments that av oids the degeneracy of solutions induced by symmetry . Our approach is based on the assumption that we can co v er the feasible region with p olytopes in such a w a y that each optimal cen ter { x j } j ∈ [ k ] is co v ered b y the interior of exactly one p olytop e. Under this assumption, w e are able to reduce (2) to a highly structured optimization problem ov er a constrained simplex. Using this new structure, symmetric solutions can b e relaxed aw a y , and Lassere’s metho d of moments can b e used to give a hierarch y of conv ex relaxations. 1.3 Organization of the Paper W e summarize Lasserre’s metho d of moments in section 2 and introduce the notation. In section 3, we reduce (2) to a highly structured optimization prob- lem ( R 1) ov er constrained simplices in order to derive the symmetry-free for- m ulation ( R 2). Section 4 is mostly devoted to the application of Lasserre’s metho d of mo- men ts to problem ( R 2), which yields the hierarch y ( R 2)[ t ]. After p oin ting out w ays to simplify ( R 2)[1], we also suggest a relaxed hierarch y ( R 3)[ t ] that can b e computed m uc h faster. T o complete the algorithmic procedure, w e also giv e a deterministic rounding heuristic in section 5. Finally , based on our nov el approach, we sketc h in section 6 several wa ys to extend (2) to more general settings. Some exp erimen ts are rep orted in section 7 to illustrate the mec hanism for symmetry breaking, that is essential for effectiv e SDP relaxation. 2 Preliminaries This section gives a basic description of Lasserre’s Method of Momen ts and is based mostly on the b ook [5], with some minor changes of notation. 2.1 Linear Algebra In the following, w e list some cones with their corresp onding partial order as • ( R n + , ≤ ) v ectors in R n with nonnegative entries, • ( S n + , ) symmetric p ositiv e semidefinite n × n matrices, • ( D n , 4 ) double nonnegative matrices given as D n = S n + ∩ R n × n + . Sp ecial matrices include the n × n identit y I n and the n × n all ones matrix J n = ee > where e denotes the v ector of all ones of appropriate dimension. 3 2.2 P olynomials Giv en a vector α ∈ N d and x ∈ R d define the monomial x α = Q i ∈ [ d ] x α i i and its total degree as deg( x α ) = h e, α i . Let R [ x ] denote the set of multiv ariate p olynomials in x where w e set deg( p ) := max { deg ( x α ) : p α 6 = 0 } for any elemen t p ∈ R [ x ]. F urthermore, the vector space of p olynomials of degree at most t is given as R t [ x ] = { p ∈ R [ x ] : deg ( p ) ≤ t } (4) where z ( t ) := dim( R t [ x ]) = d + t d . (5) By defining N d t := { α ∈ N d : h α, e i ≤ t } (6) w e see that eac h p olynomial p ∈ R t [ x ] can be written as p ( x ) = P α ∈ N d t p α x α and w e may identify R t [ x ] with R z ( t ) b y treating p as the v ector of its co efficien ts. In this context we will also write p ∈ R z ( t ) and enco de the canonical monomial base ( x α ) α ∈ N d t as v d ( x ) such that p ( x ) = h p, v d ( x ) i . Giv en y = ( y α ) α ∈ N d , we can use this identification to define the Riesz functional L y : R [ x ] → R as p 7→ L y ( p ) = h p, y i . 2.3 Momen t matrices F or t ∈ N and y ∈ R N d 2 t , the matrix M t ( y ) of size z ( t ) is defined b y ( M t ( y )) α,β := L y ( x α · x β ) = y α + β (7) and is called the momen t matrix of order t of y . More generally , let f b e a multiv ariate p olynomial and define td( f ) := d deg( f ) 2 e . F or t ≥ td( f ), the matrix M t ( f , y ) of size z ( t − td( f )) is defined by ( M t ( f , y )) α,β := L y ( x α · x β · f ) (8) and is called the lo calizing momen t matrix of order t of y with resp ect to f . Note that eac h en try of M t ( f , y ) is a linear expression in y and that we recov er M t ( y ) = M t (1 , y ) as a sp ecial case. 2.4 Measures and momen ts Let N ( K ) ⊆ R t [ x ] be the con vex cone of p olynomials that are nonnegativ e on K and denote the dual cone by N ∗ ( K ) = n y ∈ R N d L y ( f ) ≥ 0 , ∀ f ∈ N ( K ) o . (9) F or a set K ⊆ R d , denote by M + ( K ) the space of finite (nonnegative) Borel measures supp orted on K and by P ( K ) the subset of probability measures on K . W e can reco v er the cone of the corresp onding moments y ∈ R N d ∃ µ ∈ M + ( K ) : y α = Z K x α dµ ∀ α ∈ N d ⊆ N ∗ ( K ) (10) where equality holds if K is compact [5, Lemma 4.7]. 4 2.5 Reform ulation of Optimization Problems Let K ⊆ R d b e a compact set and f ( x ) = P α ∈ N d t f α x α b e a real-v alued multi- v ariate p olynomial, then inf x ∈ K f ( x ) = inf µ ∈P ( K ) Z K f dµ (11) can b e reduced to a conv ex linear programming problem. Indeed, we hav e that Z K f dµ = Z K X α ∈ N d t f α x α dµ = X α ∈ N d t f α Z K x α dµ = L y ( f ) (12) where y α = R K x α dµ is the momen t of order α . Consequen tly , if f is polynomial, then inf L y ( f ) s.t. y 0 = 1 , y ∈ N ∗ ( K ) (13) is a relaxation of problem (11) with the b enefit of b eing a reform ulation whenev er equalit y holds in (10). Note that the constrain t y 0 = 1 enforces that y represents a measure in P ( K ) ( M + ( K ), pro vided y ∈ N ∗ ( K ). Although problem (13) is a conv ex linear programming problem, the character- ization of y ∈ N ∗ ( K ) (known as K -moment problem in the literature) ma y b e notoriously hard for general K . Ho wev er, for compact semi-algebraic K given as K = { x ∈ R d : g i ( x ) ≥ 0 ∀ i ∈ [ k ] } , (14) for some p olynomials g i ∈ R [ x ], an explicit characterization of N ∗ ( K ) is a v ail- able. Since K is assumed to b e compact, we will assume without loss of gener- alit y that g 1 ( x ) = R 2 − k x k 2 ≥ 0 , (15) where R is a sufficiently large positive constan t (in fact, w e w ould only need an y function u in the quadratic mo dule generated by { g i } i ∈ [ k ] to hav e a compact sup erlev el set { x ∈ R d : u ( x ) ≤ 0 } for the following). This representation allows the application of a theorem on positivity by Putinar [5, Theorem 2.15], which leads to N ∗ ( K ) = { y ∈ R N d : M t ( y ) 0 , M t ( g i , y ) 0 ∀ i ∈ [ k ] , ∀ t ∈ N } (16) =: N ∗ ( g 1 , . . . , g k ) . (17) In particular, problem (13) is equiv alent to inf y ∈ R N d L y ( f ) s.t. y 0 = 1 , y ∈ N ∗ ( g 1 , . . . , g k ) . (18) T o summarize, if f is p olynomial and K a compact semi-algebraic set, then problem (11) is equiv alent to a conv ex linear programming problem with an infinite num b er of linear constrain ts on an infinite n umber of decision v ariables. 5 2.6 Semidefinite Relaxations No w, for t ≥ td( f ), consider the finite-dimensional truncations ρ t = inf y ∈ R N d 2 t L y ( f ) s.t. y 0 = 1 , y ∈ N ∗ t ( g 1 , . . . , g k ) (19) of problem (13) where N ∗ t ( g 1 , . . . , g k ) := y ∈ R N d 2 t M t ( y ) 0 , M t ( g i , y ) 0 ∀ i ∈ [ k ] : t ≥ td( g i ) . (20) By construction, {N ∗ t } t ∈ N generates a hierarch y of relaxations of Problem (13), where each {N ∗ t } t ∈ N , is concerned with moment and lo calizing matrices of fixed size t . The low erbounds ρ t monotonically conv erge tow ard the optimal v alue of (11) [5, Theorem 6.2] and finite conv ergence may take place, whic h can b e efficien tly chec k ed [5, Theorem 6.6]. F urthermore, in the b est case of finite conv ergence, (19) will yield the global optimal v alue and a conv ex combination of global optimal solutions as mini- mizer, whic h can be efficien tly decomposed in to optimal solutions [5, Sct. 6.1.2 ]. In the noncompact case, the ρ t are still monotonically increasing lo wer b ounds of (11), but con v ergence to the optim um is not guaranteed. Remark 1: In the literature, this construction is kno wn as Lasserre’s Metho d of Mo- men ts (LMM) where it is assumed that t ≥ max i td( g i ) in addition to t ≥ td( f ) in order to start with a complete description of all the constraints used in the problem. Our slightly differen t definition is more flexible by enabling us to start with an incomplete set of constraints of low degree while still fitting in to the o verall hierarch y . It should be noted that using a v alue of t that truncates most of the ’relev ant’ inequalities for the problem is not likely to yield a useful lo wer b ound. F or conv enience, we will also introduce a shortcut notation for p olynomial equations h ( x ) = 0 (imp osed b y having b oth h ( x ) ≥ 0 and − h ( x ) ≥ 0) b y setting N ∗ t ( { h j } , { g i } ) := y ∈ R N d 2 t M t ( y ) 0 M t ( h i , y ) = 0 ∀ j : t ≥ td( h j ) M t ( g i , y ) 0 ∀ i : t ≥ td( g i ) . (21) 3 Dealing with the Symmetry of the k -Clustering Problem This section starts b y outlining the problem of k -clustering and the assoc i ated difficulties in solving it, in section 3.1. In section 3.2, we prepro cess the k - clustering problem by reducing it to a quadratic optimization problem ov er a simplex with an additional partition structure. W e then use this description in section 3.3 as a basis to relax the partition constraints in a wa y that remov es symmetric solutions. 6 3.1 Problem F orm ulation W e study (2) in the form min u,x X i ∈ [ n ] X j ∈ [ k ] u ij k A i x j − b i k 2 2 (22a) s.t. U e = e, U ∈ { 0 , 1 } n × k , (22b) where { A i } ⊆ R l × d and { b i } ⊆ R l . Since k A i x j − b i k 2 = x > j ( A > i A i ) x j − 2( b > i A i ) x j + k b i k 2 2 (23) and u ij ∈ { 0 , 1 } ⇔ u ij (1 − u ij ) = 0 (24) for all i ∈ [ n ] , j ∈ [ k ], we see that (22) asks us to optimize a polynomial o ver a real v ariety . By assuming that all sensible solutions { x j } j ∈ [ k ] are contained in a compact set K , we could apply LMM from the preceding section in order to approximate the solution of this problem. Ho wev er, due to increasing size w e cannot exp ect to compute the level of con vergence in LMM. In particular, it is hard to extract feasible solutions from lo wer levels of LMM, and the symmetric structure of the partition matrix U mak es this even harder. F or example, consider any p erm utation π ∈ S k and an optimal solution ( U ∗ , X ∗ ) to (22). Then one can chec k that the v alues ( U π , X π ) where u π ij := u ∗ iπ ( j ) and x π j := x ∗ π ( j ) are an optimal solution for (22), which corresp onds to relab eling the clusters. F urthermore, ( U 0 , X 0 ) given by ( U 0 , X 0 ) = 1 k ! X π ∈ S k ( U π , X π ) (25) will be a v alid solution for eac h step of LMM. Since u 0 ij = 1 k for all i ∈ [ n ] , j ∈ [ k ] and x 0 i = x 0 j for all i, j ∈ [ k ], there is no wa y to reco v er an optimal assignment. Since w e need the assignment as well, we will reformulate the problem in the next section to a v oid this symmetry . 3.2 P arametrization with Constrained Simplices Throughout this pap er, we will assume that the feasible region can b e cov ered b y a finite set of p olytop es, which is a reasonable assumption since the feasible region of most practical problems are b ounded [11]. Section 6 will commen t on more elab orate wa ys to parametrize the feasible region using simplices. W e therefore start with the follo wing central assumption. T riangulation Assumption: The optimal solution { x j } j ∈ [ k ] to (22) is c ontaine d in a union of simplic es, e.g. { x j } j ∈ [ k ] ⊆ P = [ s ∈ [ q ] P s (26) 7 is a valid c onstr aint for (22) wher e the { P s } s ∈ [ q ] ar e d -dimensional simplic es with disjoint interior. F urthermor e, P c an b e c onstructe d fr om { ( A i , b i ) } i ∈ [ n ] . T o exploit this, let V s b e the matrix whose ro ws denote the v ertices of P s suc h that conv( V s ) = P s . Let m := X s ∈ [ q ] | V s | = q ( d + 1) (27) suc h that for λ > := ( λ > v (1) , . . . , λ > v ( q ) ) ∈ ∆ m and V = ( V 1 , . . . , V q ) we hav e x = V λ = X s ∈ [ q ] V s λ v ( s ) . (28) Remark 2: Note that if the simplices P s ha ve common v ertices, V will hav e m ultiple iden- tical columns across different V s . This is done on purp ose, as the remov al of redundan t copies will be treated in section 6. Then we can express P as the image of ∆ m constrained by P = { x ∈ R d | ∃ λ ∈ ∆ m : x = V λ, λ v ( r ) λ > v ( s ) = 0 ∀ r, s ∈ [ q ] , r 6 = s } . (29) The nonlinear orthogonality constrain t λ v ( r ) λ > v ( s ) = 0 ∀ r, s ∈ [ q ] , r 6 = s (30) ensures that exactly one λ v ( s ) is nonzero, which implies x = V λ = V s λ v ( s ) ∈ P s . Since λ ≥ 0, we can see that (30) is equiv alent to the sum λ > Ω λ = 0 (31) where Ω = ( J q − I q ) ⊗ J d +1 ∈ { 0 , 1 } m × m (32) is given by a Kronec ker pro duct and zero on a blo c k diagonal. This suggests to set ∆ m Ω := { λ ∈ ∆ m : λ > Ω λ = 0 } (33) so that in particular, w e can write P = V ∆ m Ω as a shorthand for (29). Remark 3: Note that unless q = 1, the represen tation of P in (29) is in general not unique since our assumption do es not exclude the case that the intersection of b oundaries bd( P r ) ∩ b d( P s ) is nonempty . Ho w ev er, by Caratheo dory’s the- orem [7, Thm. 2.29] we get a unique representation for all interior p oin ts x ∈ ˙ S s ∈ [ q ] in t( P s ). Using the parametrization (29) in (22) and using 1 = h λ, e i to homogenize, w e can use x j = V λ j to rewrite k A i x − b i k 2 2 = h λ j , W i λ j i , (34) where W i := V > A > i A i V − ( eb > i A i V + V > A > i b i e > ) + k b i k 2 2 · J m (35) 8 for all i ∈ [ n ]. This leads to the reformulation (R1) min u,λ X i ∈ [ n ] X j ∈ [ k ] u ij h λ j , W i λ j i (36a) s.t. U e = e, U ∈ { 0 , 1 } n × k , (36b) λ j ∈ ∆ m Ω ∀ j ∈ [ k ] . (36c) 3.3 Remo ving Symmetry with Separating T riangluations The goal of this section is to eliminate the v ariable U in (R1). T o this end, recall that the purp ose of U is to mo del that each term W i is only ev aluated at a single p oin t in { λ j } j ∈ [ k ] . In particular, (R1) mo dels the problem min λ X i ∈ [ n ] h λ i , W i λ i i s.t. λ i ∈ { λ j } j ∈ [ k ] ⊆ ∆ m Ω ∀ i ∈ [ n ] , (37) where the membership constrain t λ i ∈ { λ j } j ∈ [ k ] is mo deled b y U . While it is imp ortan t to mo del this mem b ership constraint in a more tractable form ulation for optimization, using the U v ariable introduces the inherent prob- lematic symmetries mentioned in Section 3.1 in the first place by turning the unordered set { λ j } j ∈ [ k ] in to an arbitrarily ordered list. As a main idea of this paper, we prop ose another, symmetry free form ulation for this membership based on the following prop ert y . Definition 4 (Separating T riangulation) : Let P = S s ∈ [ q ] P s b e a triangulation satisfying (26). A set of p oin ts { x j } j ∈ [ k ] ⊆ P is called separated by P if |{ x j } j ∈ [ k ] ∩ P s | ≤ 1 ∀ s ∈ [ q ] . (38) P is called separating (for (22)) if an optimal set of cen troids { x j } j ∈ [ k ] for (22) is separated by P . The central adv antage of a separating triangulation is that the representation of the optimal { x j } j ∈ [ k ] in (R1) b ecomes orthogonal. Lemma 5: L et P = S s ∈ [ q ] P s b e a triangulation satisfying (26) . F or a set of p oints { x j } j ∈ [ k ] ⊆ P , let x j = V λ j with λ j ∈ ∆ m Ω for al l j ∈ [ k ] b e their r epr esentation in (R1). Then { x j } j ∈ [ k ] is sep ar ate d if and only if whenever j, j 0 ∈ [ k ] and j 6 = j 0 , λ j v ( s ) λ j 0 v ( s ) > = 0 ∀ s ∈ [ q ] . (39) In p articular, their r epr esentations ar e c o or dinatewise ortho gonal. F urthermor e, if P is sep ar ating, then (39) holds for an optimal solution of (R1). This simple observ ation implies that we can enco de the mem b ership con- strain t in (37) with linear inequalities and quadratic constraints. Theorem 6: L et P in (26) b e sep ar ating and let λ ∗ := X j ∈ [ k ] λ j (40) 9 for the optimal solution { λ j } j ∈ [ k ] in (R1). Then for λ ∈ ∆ m Ω we have the e quivalenc e λ ∈ { λ j } j ∈ [ k ] ⇔ λ ≤ λ ∗ . (41) Pr o of. Implication ” ⇒ ” is straigh tforw ard. Consider the reverse direction. Denoting by supp( λ ) the supp ort of λ , it follows from λ > Ω λ = 0, 0 ≤ λ ≤ λ ∗ and Lemma 5 that w e hav e supp( λ ) ⊆ v ( s j 0 ) ⊆ supp( λ ∗ ) = ˙ [ j ∈ [ k ] supp( λ j ) = ˙ [ j ∈ [ k ] v ( s j ) (42) for some j 0 ∈ [ k ], where supp( λ j ) = v ( s j ) for all j ∈ [ k ]. Therefore, 0 ≤ λ ≤ λ j 0 and h λ, e i = 1 = h λ j 0 , e i , (43) whic h is only possible if λ = λ j 0 . Theorem 6 reduces the mem b ership in { λ j } j ∈ k to a more tractable relation in volving λ ∗ . How ev er, since λ ∗ enco des the v ariables that we try to optimize, w e still need to give a prop er characterization of those λ ∗ corresp onding to separated solutions { λ j } j ∈ [ k ] . Lemma 7: L et L := { λ j } j ∈ [ k ] ⊆ ∆ m Ω | (39) holds (44) and L 0 := { λ ∈ k · ∆ m | h λ v ( s ) , e i λ v ( s ) = λ v ( s ) ∀ s ∈ [ q ] } . (45) Then L and L 0 ar e in one-to-one c orr esp ondenc e with a bije ction φ : L → L 0 given by φ ( { λ j } j ∈ [ k ] ) := X j ∈ [ k ] λ j . (46) Pr o of. It is obvious that φ is w ell-defined. W e pro ceed by constructing a function ψ : L 0 → L , so let λ ∈ L 0 . By taking the scalar product with e on the defining equation in (45), w e see that h λ v ( s ) , e i ∈ { 0 , 1 } . So b y definition, there is a set { s j } j ∈ [ k ] ⊆ [ q ] such that h λ v ( s j ) , e i = 1 for all j ∈ [ k ]. No w define vectors { λ j } j ∈ [ k ] according to λ j v ( s ) := ( λ v ( s ) if s = s j , 0 else ∀ s ∈ [ q ] , ∀ j ∈ [ k ] (47) and set ψ ( λ ) := { λ j } j ∈ [ k ] . It is easy to chec k that ψ is well-defined. Now for λ ∈ L 0 one has φ ( ψ ( λ )) v ( s ) = X j ∈ [ k ] λ j v ( s ) = ( λ v ( s ) if s ∈ { s j } j ∈ [ k ] , 0 = λ v ( s ) else, (48) whic h shows φ ◦ ψ = id L 0 . F or { λ j } j ∈ [ k ] ∈ L , let λ = φ ( { λ j } j ∈ [ k ] ). Then w e can c ho ose { s j } j ∈ [ k ] suc h that 1 = h λ v ( s j ) , e i = X j 0 ∈ [ k ] h λ j 0 v ( s j ) , e i = h λ j v ( s j ) , e i (49) b y Lemma 5, whic h shows ψ ◦ φ = id L . 10 W e are now prepared to restate v ariant (37) of (R1) as the following, sym- metry free p olynomial optimization problem. (R2) min λ X i ∈ [ n ] h λ i , W i λ i i (50a) s.t. λ ∗ ∈ k · ∆ m , h ( λ ∗ ) v ( s ) , e i ( λ ∗ ) v ( s ) = ( λ ∗ ) v ( s ) ∀ s ∈ [ q ] , (50b) λ i ∈ ∆ m Ω , λ i ≤ λ ∗ ∀ i ∈ [ n ] . (50c) Corollary 8: (R2) is e quivalent to finding the optimal sep ar ate d solution of ( R 1) . In p artic- ular, if P in (26) is sep ar ating, then b oth pr oblems ar e e quivalent. 4 SDP Relaxations In this section w e will exploit av ailable theoretical results to appro ximate (R2) b y a hierarch y of conic programs (R2)[t]. After some simplifications of (R2)[1], w e will also in tro duce a relaxation of (R2)[1] which is faster to solv e. 4.1 The Hierarc h y ( R 2)[ t ] In order to apply results from section 2.6 to (R2), we ha ve to give an explicit list of p olynomial inequalities. T o this end, we will use the follo wing system, where each co ordinate corresp onds to one p olynomial (in)equality: min λ X i ∈ [ n ] h λ i ,W i λ i i s.t. (51a) λ ∗ ≥ λ i , λ i ≥ 0 ∀ i ∈ [ n ] (51b) h λ ∗ , e i = k , h λ i , e i = 1 ∀ i ∈ [ n ] (51c) h ( λ ∗ ) v ( s ) , e i ( λ ∗ ) v ( s ) = ( λ ∗ ) v ( s ) ∀ s ∈ [ q ] (51d) ( λ i ) v ( s ) ( λ i ) > v ( t ) = 0 ∀ i ∈ [ n ] , ∀ s 6 = t ∈ [ q ] (51e) ( λ ∗ ) v ( s ) ( λ i ) > v ( s ) = ( λ i ) v ( s ) ( λ i ) > v ( s ) ∀ i ∈ [ n ] , ∀ s ∈ [ q ] (51f ) One can easily chec k that (51a)-(51e) is a reformulation of (R2). Addition- ally , we add the redundant equations (51f) implied by Lemma 5 since they hav e lo w degree and directly reduce the num b er of moments we ha v e to consider in LMM. F or t ≥ 1, we can therefore construct the hierarch y (19) accordingly , where w e will call the optimization problem corresp onding to the t -th step in the hierarch y as (R2)[t]. 4.2 Simplifying (R2)[1] In practice, we can only compute ( R 2)[ t ] for small v alues of t . In this section, w e will in vestigate ( R 2)[1] in more detail and show that it can b e simplified to get a smaller formulation that can b e solved with curren t SDP solvers. T o this 11 end, we will first e x plicitly write down an SDP-representation of ( R 2)[1] where w e use the notation M 1 ( y ) = 1 λ > 1 · · · λ > n λ > ∗ λ 1 Λ 11 · · · Λ 1 n Λ 1 ∗ . . . . . . . . . . . . . . . λ n Λ n 1 · · · Λ nn Λ n ∗ λ ∗ Λ ∗ 1 · · · Λ ∗ n Λ ∗∗ 0 (52) for the moment matrix inv olved. An imp ortan t observ ation is that each polynomial in (51) b elongs to R [ λ i , λ ∗ ] for some i ∈ [ n ] and that these sets satisfy the running intersection prop ert y . Using results about sparse representations [5, Section 8.1], this means we can ignore the matrices Λ ij for i 6 = j ∈ [ n ] and replace M 1 ( y ) 0 by the collection of muc h smaller submatrices M 1 ( y | i ) := 1 λ > i λ > ∗ λ i Λ ii Λ i ∗ λ ∗ Λ ∗ i Λ ∗∗ 0 (53) to get the reduced form ulation ( R 2)[1] min λ X i ∈ [ n ] h W i , Λ ii i (54a) s.t. h λ ∗ , e i = k , Λ ∗∗ e = k λ ∗ , (54b) (Λ ∗∗ ) v ( s ) e = ( λ ∗ ) v ( s ) ∀ s ∈ [ q ] , (54c) (Λ i ∗ ) v ( s ) = (Λ ii ) v ( s ) ∀ s ∈ [ q ] , h Λ ii , Ω i = 0 , h λ i , e i = 1 , Λ ii e = λ i , Λ ∗ i e = λ ∗ , Λ i ∗ e = k λ i , λ ∗ ≥ λ i ≥ 0 , Λ ∗∗ ≥ Λ ∗ i ≥ Λ ii ≥ 0 , M 1 ( y | i ) 0 ∀ i ∈ [ n ] . (54d) F ortunately , we can also discard the linear monomials λ i and λ ∗ with the help of the follo wing Lemma. Lemma 9: Consider a matrix Λ 0 and a ve ctor a . L et a > Λ a = ν and define λ := Λ a . Then ν Λ λλ > or e quivalently ν λ > λ Λ 0 . (55) Pr o of. Since Λ 0, there is L such that Λ = L > L and consequen tly ν = a > Λ a = k La k 2 2 . Then for arbitrary x we hav e x > ( ν Λ − (Λ a )(Λ a ) > ) x = ν · h Lx, Lx i − h Lx, La i 2 = k La k 2 2 · k Lx k 2 2 − |h Lx, La i| 2 ≥ 0 where the last inequalit y is the Cauc hy-Sc hw arz inequality . The equiv alen t second formulation of (55) follows from the Sch ur Complement Theorem. 12 In terms of (54), using Lemma 9 on Λ ii Λ i ∗ Λ ∗ i Λ ∗∗ 0 (56) with the vector a = e 0 > already yields the condition M 1 ( y | i ) 0, which means we can discard the linear monomials in the following equiv alent form u- lation ( R 2 0 )[1] min λ X i ∈ [ n ] h W i , Λ ii i (57a) s.t. (Λ i ∗ ) v ( s ) = (Λ ii ) v ( s ) ∀ s ∈ [ q ] , (Λ ∗∗ ) v ( s ) e = (Λ ∗ i e ) v ( s ) ∀ s ∈ [ q ] , h Λ ii , Ω i = 0 , k Λ ii e = Λ i ∗ e, h Λ ii , J i = 1 , k Λ ∗ i e = Λ ∗∗ e, h Λ ∗ i , J i = k , Λ ∗∗ ≥ Λ ∗ i ≥ Λ ii ≥ 0 , Λ ii Λ i ∗ Λ ∗ i Λ ∗∗ 0 ∀ i ∈ [ n ] . (57b) This reform ulation uses n SDP matrices of dimension 2 m = 2 q ( d + 1), whic h is still very limiting. Note, how ev er, that since h Λ ii , Ω i = 0, there is still a h uge sparsit y pattern in the blo c kdiagonal Λ ii , which is not prop erly exploited. F or this reason, we prop ose to relax ( R 2 0 )[1] by dropping all v ariables in Λ i ∗ and Λ ∗∗ that do not b elong to the blo c kdiagonal structure induced by Ω. Effectiv ely , this means we lose information of en tries in Λ ∗∗ that only ha ve an indirect impact on Λ ii . This turns each SDP constraint in ( R 2 0 )[1] into q separate SDP constraints (Λ ii ) v ( s ) (Λ i ∗ ) v ( s ) (Λ ∗ i ) v ( s ) (Λ ∗∗ ) v ( s ) 0 ∀ s ∈ [ q ] (58) of size 2( d + 1), whic h is again muc h smaller. How ever, since (Λ i ∗ ) v ( s ) = (Λ ii ) v ( s ) , (59) this is equiv alen t to (Λ ∗∗ ) v ( s ) (Λ ii ) v ( s ) ∀ s ∈ [ q ] , (60) since A A A B 0 is equiv alent to B A 0 as a consequence of the Sch ur complemen t theorem. F ormally , w e end up with the following relaxation of ( R 2)[1], whic h we will call ( R 2 00 )[1] min λ X i ∈ [ n ] h W i , Λ ii i (61a) s.t. h Λ ii , Ω i = 0 , h Λ ii , J i = 1 , (Λ ∗∗ ) v ( s ) < (Λ ii ) v ( s ) < 0 ∀ s ∈ [ q ] ∀ i ∈ [ n ] , (61b) X s ∈ [ q ] h (Λ ∗∗ ) v ( s ) , J i = k . (61c) 13 Note that the last constrain t follows from ( R 2 0 )[1] as k = h Λ i ∗ , J i = X s ∈ [ q ] e > v ( s ) (Λ ∗ i e ) v ( s ) = X s ∈ [ q ] e > (Λ ∗ i ) v ( s ) e. (62) 4.3 The v arian t (R3)[t] Instead of in troducing λ ∗ as the sum of optimal parameters λ j in (40), we migh t directly work with the corresp onding moment sequences. Letting y j ∈ N ∗ (∆ d Ω ) denote the moment sequence of λ j , we can define y ∗ = X j ∈ [ k ] y j ∈ N ∗ (∆ d Ω ) , ( y ∗ ) 0 = k , (63) to get the implication y ∈ { y j } j ∈ [ k ] ⇒ y , y ∗ − y ∈ N ∗ (∆ d Ω ) , y 0 = 1 (64) as a w eaker alternativ e to (41). Applying LMM on the set N ∗ (∆ d Ω ) then leads to the hierarch y (R3)[t] min y X i ∈ [ n ] L y i ( W i ) (65a) s.t. y i ∈ N ∗ t (∆ m Ω ) , ( y i ) 0 = 1 , y ∗ − y i ∈ N ∗ t (∆ m Ω ) , y ∗ 0 − ( y i ) 0 = k − 1 ∀ i ∈ [ n ] , (65b) where it can b e shown that for t = 1, this coincides with ( R 2 00 )[1] after prop erly reform ulating (61). ( R 3)[1] uses 2 nq SDP constrain ts of the rather small size d + 1 and is only w eakly coupled, so that parallel computing schemes can be efficiently used to solv e the relaxation for problems of mo derate paramaters ( n, q , d ). Remark 10: Mo del ( R 3)[1] coincides with problem (21) given in [8] in the resp ectiv e setting. 5 Rounding Giv en a solution ( y ∗ , y i ) to ( R 3)[1], a rounding pro cedure has to determine a prop er partition of [ n ]. T o do this, we will use the information provided b y the con vex relaxation and a k-center clustering algorithm, as detailed next. Definition 11 (k-center Clustering) : Giv en a set K = { x i } i ∈ [ n ] ⊆ R d and a norm k · k , the k-cen ter clustering problem is defined as C k·k ∞ ( K, k ) := min C ⊆ K, | C | = k max i ∈ [ n ] min y ∈ C k y − x i k . (66) Since this problem is NP-hard, we need to use a heuristic instead, which should b e insensitiv e to initializations. This can b e achiev ed as follows. 14 Theorem 12 (Approximating k-Center Clustering [4]) : F or d > 2 , achieving an appr oximation r atio for (66) b etter than 2 is NP-har d. A 2 -appr oximation is given by the fol lowing deterministic algorithm. Algorithm 1: FPC( K , k , k · k ) (F arthest Poin t Clustering) Data : Data K = { x i } i ∈ [ n ] ⊆ R d , norm k · k , k ∈ [ n ] Result : Centers C ⊆ { x i } i ∈ [ n ] , | C | = k 1 B ← ∞ , C ← ∅ ; 2 for i ∈ [ n ] do 3 C i ← ∅ , c 1 ← x i ; 4 for j ∈ [ k ] do 5 C i ← C i ∪ { c j } , c j +1 ← argmax x ∈ K min y ∈ C i k x − y k ; 6 if min y ∈ C i k c k +1 − y k < B then 7 B ← min y ∈ C i k c k +1 − y k , C ← C i ; 8 return C ; Algorithm 1 greedily builds the set of cluster centers C by iteratively choos- ing those points whic h are farthest aw a y from all prior centers. As initialization, ev ery p oin t is c hosen as the first cluste r center once and the b est ov erall result is kept as the output of the algorithm. Our rounding pro cedere can now b e describ ed as follows, where W = ( W i ) i ∈ [ n ] denotes the ob jective function. Algorithm 2: k-Cluster Rounding Data : Ob jectiv e W and solution ( y ∗ , y i ) of ( R 3)[1]. Result : Solution to (22) of v alue rnd( W ). 1 Extract the second order moments Λ i of y i according to section 4.2; 2 set λ i = Λ i e for all i ∈ [ n ]; 3 set U equal to the partition of the minimizer of FPC( { λ i } i ∈ [ n ] , k , ` 1 ); 4 for fixed U , compute optimal cen ters { x j } j ∈ [ k ] in (22); 5 set rnd( W ) to the ob jective v alue of ( U, { x j } j ∈ [ k ] ) in (22); 6 return ( U, { x j } j ∈ [ k ] , rnd( W )); Algorithm 2 clusters the λ -representations from ( R 3)[1] according to their ` 1 -norm to construct the assignmen t matrix U . Afterw ards, the actual centers are computed as the analytic solution to (22) with fixed assignments. 6 Extensions W e next commen t on the c hoice of ( V , Ω) in section 3 and then indicate a generalization of P to semialgebraic sets and more general ob jective functions. Ev en though the v arian ts here are presen ted in terms of the original problem (22) and (R1), the machinery of section 2 can b e used in a straightforw ard wa y to pro cess the mo difications for (R2) and (R3[t]). Recall that Ω is assumed to separate the individual parametrization of the lo cal parameters { λ i } i ∈ [ n ] in V in the preceding sections. While this guarantees that ( R 2) is a reformulation of ( R 1), we might also consider relaxing this con- strain t by breaking up the blockdiagonal structure. While w e lose m uc h of the underlying theory this w a y , we may also gain a sp eed up heuristically . 15 6.1 Unique Columns in V As mentioned in Remark 2, we do not assume the columns of V to b e unique in Section 3. This is done to ensure the blo c kdiagonal structure of Ω, but can b e relaxed. Example 13: Let P = P 1 ∪ P 2 where V 1 = − 1 0 0 1 and V 2 = ( 0 1 1 0 ) to get V = − 1 0 0 1 0 1 1 0 and Ω = 0 J 2 J 2 0 . Inste ad , we migh t as well use V = − 1 0 1 0 1 0 and Ω = 0 0 1 0 0 0 1 0 0 . It is imp ortan t to note that while this reduces m and therefore impro v es the running time for solving ( R 2[ t ]) and ( R 3[ t ]), it also has a negative impact on the quality of the solutions if P 1 and P 2 are each assumed to contain a differen t lo cal optimizer x j . In particular, the new formulation gives a “discount” on using the common v ertex ( 0 1 ) so that more weigh t is assigned to − 1 0 and − 1 0 . Consequen tly , the individual λ i will ha v e a larger spread, as can b e seen by comparing Figures 1 and 2. This is b ecause the reduced formulation only needs to increase one entry of λ ∗ to use ( 0 1 ) in conv ex combinations of b oth P 1 and P 2 , while one en try for e ach P 1 and P 2 had to b e increased in the original formulation for the same effect. Note that this is desirable if the union P 1 ∪ P 2 is meant to only contain a single lo cal optimizer x j . 6.2 P as σ -Sk eleton of Arbitrary Polytopes In order to suppress certain combinations of v ertices of P to app ear sim ulta- neously in a parametrization, Ω can be extended to sum up the corresp onding momen ts as well. Con versely , we can start with an arbitrary p olytope P and remo ve all faces whose dimension exceeds σ ∈ N to describ e the σ -skeleton of P . Definition 14: Let P b e a single p olytope, A P the adjacency matrix of the graph of P and Ω = J m − I m − A P , so that Ω enco des all pairs of vertices whose connecting line segment passes through the interior of P . Then the σ -skeleton sk el σ ( P ) of P can be formally defined as sk el σ ( P ) := { x = V λ : λ ∈ ∆ m Ω , k λ k 0 ≤ σ + 1 } , (67) whic h is the union of all faces of P of dimension at most σ . Remark 15: The set { λ ∈ ∆ m : k λ k 0 ≤ σ } can b e describ ed b y adding the equation X S ⊆ [ m ] : | S |≥ σ +1 y S = 0 (68) whic h can b e incorp orated in to the equation giv en by Ω. Of course, this will b ecome quickly impractical since it requires t > σ in ( R 2[ t ]) or ( R 3[ t ]) to work. Example 16: The unit square C 2 is given as the conv ex h ull of V = ( 0 1 0 1 0 0 1 1 ) and sk el 1 ( C 2 ) consists of 4 line segmen ts. Cho osing P = sk el 1 ( C 2 ) we need 4 simplices and 16 consequen tly m = 8 v ertices for the approach in section 3, but adding the sparsit y constraint k λ k 0 ≤ 2 in ( R 2[2]) or ( R 3[2]) allows us to use eac h v ertex only once to end up with m = 4. It would b e interesting to inv estigate low-degree p olynomials as approxima- tions of sparsity constrain ts. 6.3 Semialgebraic K While the preceding sections w ork ed on constraints regarding the parametriza- tion, p olynomial constrain ts on the lo cal optimizers { x j } j ∈ [ k ] can b e incorp o- rated into the framework laid out in section 2 as w ell. In fact, for x = V λ an y p olynomial expression f ( x ) can b e easily turned into a p olynomial expression in λ of the same de gr e e by setting f 0 ( λ ) = f ( V λ ). So, in general, the feas i ble space K can be assumed as a compact basic semialgebraic set - one only needs to cov er this set by p olytop es to use our approach. In particular, there is no need to appr oximate K b y p olytopes as long as K is c over e d by them. Ho wev er, dep ending on the geometry of the underlying set, it may be harder to choose a separating triangulation P . Example 17: Assume each lo cal optimizer x j ∈ R d , j ∈ [ k ] should b e normalized by k x j k 2 = 1. Squaring this condition giv es the quadratic polynomial equation x > j x j = 1. Now substituting x j = V λ j yields again a quadratic constrain t λ j > V > V λ j = 1. Example 18: Assume each lo cal optimizer x j ∈ R 4 , j ∈ [ k ] should enco de a vectorized or- thogonal 2 × 2 matrix X j . This yields four quadratic equations, one for each en try of X j X > j = I 2 . Denoting them b y x > j Q l x j = q l , substituting x j = V λ j yields again quadratic constrain ts λ j > V > Q l V λ j = q l . As a cav eat, how ev er, we point out that even though the hierarch y ( R 2[ t ]) will conv erge tow ards feasibility in the actual sets, low er lev els may only give crude approximations. 6.4 Clustering V arieties As already mentioned in the introduction, our approach can b e easily extended from affine subspaces to the case of v arieties. W e simply replace A i x j − b i in (22) with F i ( x j ), where F i ∈ R [ x ] is an arbitrary multiv ariate p olynomial and enco des the v ariety V R ( k F i k 2 2 ). F ollowing Section 3, we may replace x j b y V λ j and homogenize k F i ( V λ j ) k 2 2 using h λ j , e i = 1 to end up with a v arian t of (R2) where the ob jectiv e function has b een replaced. The results from Section 4 follo w according to this replacement, with the additional constraint that we can only consider ( R 2)[ t ] or ( R 3)[ t ] for v alues of t ≥ max i ∈ [ n ] deg( F i ). Of course, w e can still use our rounding heuristic presen ted in section 5. 17 6.5 Regularization with resp ect to k It should b e noted that our relaxation (R2) nev er explicitly dep ends on the n umber k apart from the constraint h λ ∗ , e i = k (69) in (51). It is therefore p ossible to treat k throughout as a v ariable and include a weigh ted k in the ob jective function in order to dynamically search for the n umber of clusters. 7 Exp erimen ts All the examples in this section were carried out in Matlab using the SDPT3 pac k age [9, 10]. 7.1 Euclidean Clustering By choosing A i = I in (22) we recov er the classical problem of Euclidean clus- tering for the points { b i } i ∈ [ n ] ⊆ R d . F or this problem, it is well kno wn that P ⊇ conv( { b i } i ∈ [ n ] ) (70) will contain all optimal parameters [6]. In particular, for the triangulation as- sumption it suffices that P cov ers a b o x which includes all { b i } i ∈ [ n ] , which can b e easily extracted. W e can use Euclidean clustering to get a b etter in tuition of ho w the relax- ation w orks. Regarding the c hoice of P , consider Figure 1. Using any simplex con taining all the points is the coarsest appro ximation but yields useless results, since each lo cal estimate V λ i can b e c hosen as b i . In view of corollary 8, the algorithm will p erform b est if the triangulation is separating, so that the cluster cen ters are separated b y the polytop es in P . This suggests that there should b e at least k p olytopes, and that an o v ersegmentation remo ves the need kno wing the ground truth, as can b e observed in Figure 1. Since we set up P as choice of arbitrary p olytop es, we can easily restrict the feasible set in a w ay to force the optimal solution into sp ecific regions. F or example, b y c ho osing eac h polytop e in P to b e a single vertex, w e reduce ( R 3[1]) to an LP which aims to c ho ose an optimal collection of lo cations from a discrete set of p oin ts, as can b e seen in figure 3. In this case, our exp erimen ts alw ays returned the optimal solution. 7.2 Hyp erplane Clustering By choosing A i = a i as row vectors in R d and setting b i = 0, (22) b ecomes the problem of c hoosing minimal h a i , x j i 2 terms. W e can in terpret this as simulta- neously choosing k hyperplanes parameterized by their normal vectors x j and assigning the p oin ts a i to them according to their weigh ted angle. W e can uniquely parametrize these hyperplanes by c ho osing an element x of their complement space whic h satisfies membership in both S d k·k = { x ∈ R d : k x k = 1 } (71) 18 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 Figure 1: Euclidean Clustering with d = 2, k = 3, n = 60. T op: Circles corresp onding to data p oin ts and crosses corresp onding to lo cal estimates for cen ters parametrized b y λ i extracted from ( R 3[1]). Bottom: Different Choices of P . F rom left to right: Minimal cov er, nonseparating cov er, p erfect cov er (based on ground truth), ov ersegmen tation. The rounding pro cedure w as able to recov er the optimal solution implied b y the right plot in each scenario. −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 Figure 2: Euclidean Clustering with d = 2, k = 3, n = 60. T op: Circles corresp onding to data p oin ts and crosses corresp onding to lo cal estimates for cen ters parametrized b y λ i extracted from ( R 3[1]). Bottom: V ariants describ ed in section 6.1 for describing the feasible set [ − 1 , 1] 2 . F rom left to right: P is the union of 1 , 2 , 3 p olytopes resp ectiv ely . V ertices at dashed lines are unique rows in V and used in each b ordering p olytop e. in any fixed norm k · k and the ’upp er halfspace’ H d + = { x ∈ R d : x 1 ≥ 0 } . (72) Note that the norm will weigh t eac h p oin t x ∈ S d k·k ∩ H d b y k x k . In particular, ev en though an y p olyhedral appro ximation of S d ` 2 ∩ H d + corresp onds to a norm and can b e used as P , this will introduce a sligh t bias. The application of this approac h is illustrated b y Figure 4. 19 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 Figure 3: Euclidean Clustering with d = 2, k = 3, n = 100 restricted to discrete P . T op: Circles corresp onding to data p oin ts, diamonds corresp onding to centers and colors corresp onding to clusters. Bottom: Differen t choices of discrete P . −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 -1 1 1 0 -1 1 1 0 -1 1 1 0 Figure 4: Hyp erplane Clustering with d = 2, k = 3, n = 60. T op: Circles corresp onding to data p oin ts and lines corresp onding to lo cal estimates for cen- ters parametrized by λ i extracted from ( R 3[1]). Bottom: Approximations of S 2 ` 2 ∩ H 2 + b y p olygonal lines. F or b etter visibility the ends of each line segment are connected to the origin with an dotted line. Dashed lines end in ground truth angles. As an application of Section 6.3, we can also work directly with S 2 ` 2 ∩ H 2 + b y adding the quadratic constraint x > j x j = 1 and choosing P ⊆ H 2 + . Since S 2 ` 2 is not polyhedral, we need to use 3-dimensional simplices for P in Figure 5 whereas 2-dimensional simplices sufficed for the p olyhedral appro ximation shown by Fig- ure 4. 20 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 -1 1 0 -1 1 0 -1 1 0 Figure 5: Hyp erplane Clustering with d = 2, k = 3, n = 60. T op: Cir- cles corresponding to data p oin ts and lines corresp onding to lo cal estimates for centers parametrized by λ i extracted from ( R 3[1]). Bottom: The semicircle S 2 ` 2 ∩ H 2 + is co vered with triangles in P . Dashed lines end in ground truth angles. 7.3 Affine Hyp erplane Clustering W e can easily extend the hyperplane clustering to the more general case of clustering affine h yp erplanes by changing to homogeneous coordinates. In par- ticular, we can encode the data point a i ∈ R d as ( a i , 1) ∈ R d +1 and try to find a hyperplane orthogonal to ( x j , z j ) ∈ R d to get the minimization of terms like h ( a i , 1) , ( x j , z j ) i 2 = ( h a i , x j i + z j ) 2 , (73) whic h approximate mem b ership in the affine hyperplane a i ∈ H ( x j ,z j ) = { a ∈ R d : h a, x j i = − z j } . (74) Since the manipulation only amoun ts to lifting the input data { a i } i ∈ [ n ] , this is just an instance of the Hyp erplane Clustering problem in a space with dimension increased by 1. In particular, the problem of Figure 6 can b e computed as an instance of clustering points from R 3 in to 2-dimensional hyperplanes. 8 Conclusion W e introduced the concept of separating triangulations for affine subspace clus- tering problems. Based on this prop ert y , a symmetry-free reformulation was deduced for this problem, which allow ed us to apply the framework of Lasserres metho d of moments to construct a hierarch y of conv ex SDP relaxations. W e sho wed how the first step of this hierarc hy can b e simplified and ga v e a second hierarc hy of relaxation with b etter computational prop erties. Based on this, we w ere able to sho w exp erimen tal results as a proof of concept. W e hop e that this paper gives some insight in to ho w to remov e symmetry from SDPs without reducing them to the in v ariant space and losing information in this pro cess. While higher steps in the hierarch y ma y not b e tractable for big datasets yet, w e hop e that this approach may con tribute to finding the global solutions for this problem class in the future. 21 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.5 0 0.5 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 Figure 6: Affine Hyp erplane Clustering with d = 2, k = 3, n = 60 as a sp ecial case of Hyp erplane Clustering with d = 3. T op: Circles corresp ond- ing to data p oin ts and gray lines corresp onding to lo cal estimates for centers parametrized b y λ i extracted from ( R 3[1]). Bottom: Gray lines corresp onding to rounded solution of ( R 3[1]) and colored data p oin ts according to the ex- tracted clustering. F rom left to righ t: Discretization of S 2 ` 2 ∩ H 2 + × [ − 0 . 3 , 0 . 3] in to (2 × 8) , (4 × 4) and (8 × 2) line segments, where S 2 ` 2 ∩ H 2 is approximated lik e in figure 4. References [1] L. Carin, R.G. Baraniuk, V. Cevher, V. Dunson, M.I. Jordan, G. Sapiro, and M.B. W akin. Learning Lo w-Dimensional Signal Mo dels. IEEE Signal Pr o c. Mag. , 28(2):39–51, 2011. [2] O. du Merle, P . Hansen, B. Jaumard, and N. Mladeno vi ´ c. An interior p oin ts algorithm for minimum sum-of-squares clustering. SIAM J. Sci. Comput. , 21(4):1485–1505, 2000. [3] E. Elhamifar and R. Vidal. Sparse Subspace Clustering: Algorithm, The- ory , and Applications. IEEE T r ans. Patt. A nal. Mach. Intel l. , 35(11):2765– 2781, 2013. [4] Dorit S. Ho c h baum and Da vid B. Shmo ys. A Best Possible Heuristic for the k-Center Problem. Mathematics of Op er ations R ese ar ch , 10(2):180–184, Ma y 1985. [5] J.B. Lasserre. A n Intr o duction to Polynomial and Semi-A lgebr aic Opti- mization . Cambridge T exts in Applied Mathematics. Cam bridge Univ ersity Press, 2015. [6] J. Peng and Y. W ei. Appro ximating K -means-type Clustering via Semidef- inite Programming. SIAM J. Optimization , 18(1):186–205, 2007. 22 [7] R.T. Ro c k afellar and R. J.-B. W ets. Variational Analysis . Springer, 2nd edition, 2009. [8] F rancesco Silvestri, Gerhard Reinelt, and Christoph Schn¨ orr. A con v ex relaxation approac h to the affine subspace clustering problem. In Pattern R e c o gnition - 37th German Confer enc e, GCPR 2015, A achen, Germany, Octob er 7-10, 2015, Pr o c e e dings , pages 67–78, 2015. [9] K. C. T oh, M. J. T o dd, and R. H. T ¨ ut ¨ unc¨ u. SDPT3 — a MA TLAB softwar e p ackage for semidefinite pr o gr amming , Decem b er 1996. [10] R. H. T¨ ut ¨ unc ¨ u, K. C. T oh, and M. J. T o dd. Solving semidefinite-quadratic- linear programs using sdpt3. Math. Pr o gr am. , 95(2):189–217, 2003. [11] R. Xu and D. W unsch I I. Survey of Clustering Algorithms. IEEE T r ans. Neur al Networks , 16(3):645–678, Ma y 2005. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment