RWebData: A High-Level Interface to the Programmable Web
The rise of the programmable web offers new opportunities for the empirically driven social sciences. The access, compilation and preparation of data from the programmable web for statistical analysis can, however, involve substantial up-front costs …
Authors: Ulrich Matter
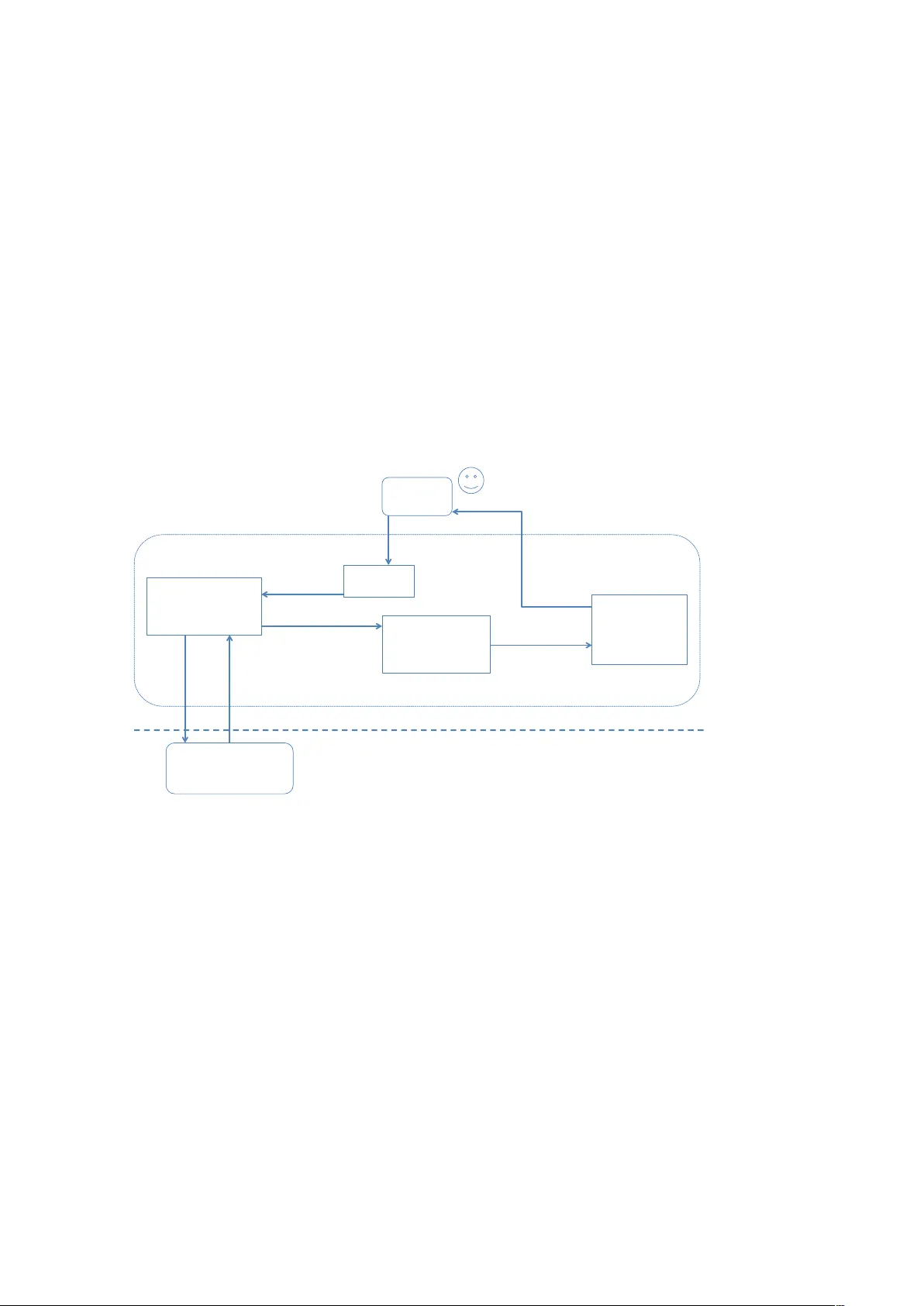
RWebData : A High-Lev el In terface to the Programmable W eb Ulric h Matter Univ ersit y of Basel Abstract The rise of the programmable w eb offers new opp ortunities for the empirically driv en so cial sciences. The access, compilation and preparation of data from the programmable w eb for statistical analysis can, ho w ev er, in volv e subst antial up-fron t costs for the practical researc her. The R -pac k age RWebData pro vides a high-level framew ork that allo ws data to b e easily collected from the programmable web in a format that can directly be used for statistical analysis in R ( R Core T eam 2013 ) without b othering ab out the data’s initial format and nesting structure. It was developed sp ecifically for users who ha ve no experience with web tec hnologies and merely use R as a statistical soft ware. The c ore idea and metho dological con tribution of the pack age are the disen tangling of parsing web data and mapping them with a generic algorithm (indep enden t of the initial data structu re) to a flat table-lik e represen tation. This pap er pro vides an o verview of the high-lev el f unctions for R -users, ex plains the basic arc hitecture of the pac k age, and illustrates the implemen ted data mapping algorithm. Keywor ds : R , programmable w eb, big public data, w eb api, rest. 1. In tro duction Digital data from the In ternet has in many wa ys b ecome part of our daily lives. Broadband facilities, the separation of data and design, as w ell as a broader adaption of certain web tec hnology standards increasingly facilitate the in tegration of data across differen t softw are applications and hardware devices ov er the w eb. The Internet is increasingly b ecoming a programmable w eb 1 , where data is published not only in HTML-based w ebsites for h uman readers, but also in standardized mac hine-readable formats to be “shared and reused across application, enterprise, and comm unity boundaries” ( W3C 2013 ). The techni cal ecology of this programmable web consists essen tially of web servers providing data in formats such as Extensible Markup Language (XML) via Application Programming Interfaces (APIs) 2 1 I use the term programmable w eb synonymously for “Seman tic W eb” or “W eb of Data” and as conceptually motiv ated b y Sw artz ( 2013 ). 2 W eb APIs are a collection of predefined HTTP requests and resp onse messages to facilitate the program- matic exchange of data b etw een a web serv er and clients. 2 RWebData : A High-Lev el Inter face to the Programmable W eb to other serve r- or client-side applications (see, e.g., Nolan and T emple Lang 2014 for a detailed introduction to web tech nologies for R -programmers). In the conceptual framework of this pap er, APIs serve a dual function: they are the cen tral nodes b et w een different web applications and, at the same time, t he cen tral access p oints for researchers when they w ant to systematically collect and analyze data from the programmable web. More and more of these access p oin ts are b ecoming av ailable every da y . Moreo v er, this trend is likely to con tinue with the increasing num b er of p eople who ha ve devices to access the In ternet and the increasing amoun t of data recorded by em b edded systems (i.e., sensors and applications in devices such as p ortable m usic pla y ers or cars that automatically feed data to w eb services). 3 The rise of the programmable web offers v arious new opp ortunities for data-driven sciences. First, for the so cial sciences, it provides big data cov ering ev ery-da y human activities and in terrelationships as people lea ve digital traces b y using mobile devices and applicat ions based on APIs. The systematic analysis of suc h data is lik ely to offer new insigh ts in fields as div erse as economics, political science, and so ciology (see Matter and Stutzer 2015a for a review of the argumen ts in the case of political economics and p olitical science, as well as, e.g., Dodds et al. 2011 ; Di Grazia et al. 2013 ; Preis et al. 2013 ; Barber´ a 2015 ; Matter and Stutzer 2015b for primary research based on data collected via w eb APIs). In fact, web APIs migh t b ecome an imp ortan t domain of data sources for the evolving field of computational so cial science (see, e.g., Lazer et al. 2009 ; Cioffi-Revilla 2010 ; Con te et al. 2012 ; Giles 2012 ). Second, researchers from all fields of science can provide their own prepared data via APIs as a resource to facilitate research, and the consequen t aggregation of data sets from diverse disciplines offers new opp ortunities to create new ‘scien tific data mash-ups’ ( Bell 2009 ) and driv e innov ation. The pro vision and hosting of APIs b y researc h institutes and scientists for other scien tists is already common practice in the life sciences (see, e.g., the API to the NCBI Gene Expression Omnibus data rep ository , NCBI 2014 ). Third, the use of standardized proto cols and data formats to exchange data o ver the w eb via APIs offers, in general, new approaches to facilitate repro ducibilit y and replicabilit y of research. While the adv antages of accessing the programmable web and in tegrating it in to researc h pro jects are very promising, the practical utilization of this technology comes at a cost and demands that researc hers p ossess a sp ecific skill set and a certain knowledge of web tech- nologies. The new R -pac k age RWebData substan tially reduces these costs by providi ng seve ral high-lev el functions that facilitate the exploration and systematic collection of data from APIs based on a Represen tational State T ransfer (REST) architecture 4 . Moreov er, the pack age con- tains a unified framew ork to summarize, visualize, and conv ert nested/tree-structured web 3 The n um b er of publicly accessib le web APIs has gro wn from around 1,000 at the end of 2008 to ov er 10,000 at the end of 2013 ProgrammableW eb ( 2014 ). T urner et al. ( 2014 ) estimate that the share of a v ailable digital data stemming from em b edded systems will rise to 10% b y 2020 and will include up to 32 billion devices connected to the Int ernet. See also Helbing and P ournaras ( 2015 ) for a discussion of how this ‘In ternet of things’ could be fostered on a cro wd-sourced basis and emplo yed for big-data analytics. 4 See Richardson and Am undsen ( 2013 ) for an int ro duction to REST APIs. Ulric h Matter 3 data that w orks indep enden tly of the data’s initial format (XML/RSS, JSON, Y AML) as w ell as a framework to easily create R pack ages as clien t libraries for an y REST API. The pack age is aimed at empirical researchers using R as their daily data analysis- and statistics to ol, but who do not hav e a back ground in computer science or data science. In addition, several low er lev el function s of RWebData might also b e useful for more adv anced R -programmers who whish to develop client applications to interact with REST APIs. The pack age thu s bridges the gap b et w een the fundamen tal and v ery v aluable R -pack ages that integrate sever al web tec hnolo- gies into the R -envi ronmen t (see, e.g., T emple Lang 2013c , a ; Couture-Beil 2013 ; Ooms et al. 2014 ) and the statistical analysis of the programmable w eb univ erse. The dev elopmen t and use of RWebD ata is motiv ated in Section 2 , which explains the c hallenges of extracting data from the programmable web for statistical analysis and introduces the pac k ages that enable R -users to work with web technologies. Section 3 presen ts the central data mapping strategy and algorithm dev elop ed in RWebData as well as an o v erview of the pac k age’s basic architecture. Section 4 illustrates the high-level functionality of RWebData for a typical user. In Section 5 , more adv anced examples show ho w RWebData can b e used to write Op en Source Interfaces/API client libraries. The concluding discussion in Section 6 reviews the potential of RWebDat a for the empirically driv en so cial sciences in terms of big public data access as w ell as the repro ducibility and replicabilit y of research based on data from w eb APIs. RWebData is free, op en source (under GLP-2 and GLP-3 license), and published on Bit- buc k et ( https://bitbucket.org/ulrich-matter/rwebdata ). It can directly b e installed from the R -console (using the devtools -pack age; Wickham and Chang 2015 ) with the com- mand install_bitbucket(’ulrich-matter/RWebData’) . This pap er describes v ersion 0.1 of RWebData , whic h requires R version 3.0.2 or a subsequen t version. 2. Motiv ation Ho w to extract data from the programmable web in a format suitable for statistical analysis? P articularly so cial scientists are often confronted with APIs whose initial purp ose is not to provid e data for scien tific researc h in order to mak e the researchers’ liv es easier, but to facilitate the integration of the data in dynamic websites and smartphone applications. 5 In suc h a con text, API serv er and API clien t share the problem domain, but do not share the same goal. This makes it p er se harder to write an API client in order to compile data from the w eb API (see Richardson and Amundsen 2013 for a discussion of this issue). The API query metho ds might, for example, not pro vide the length and breadth of data that the researc her is lo oking for using a single query , but only with a com bination of several query 5 The v ast ma jority of APIs are explicitl y made for web dev elop ers and are hosted by companies or NGOs that hav e nothing to do with academic researc h (according to San tos 2012 , only ab out 195 of ov er 7,000 APIs listed in the Programma bleW eb.com API-directory were related to ‘science’ in 2012.). 4 RWebData : A High-Lev el Inter face to the Programmable W eb metho ds. Imp ortan tly , the returned data are – due to the initial purp ose of most APIs – usually not in a format that can b e directly integrated in a statistical analysis. Researchers trying to compile data from suc h an API are th us confron ted with t wo main challenges: 1. The need to query and com bine data from differen t API methods whic h is lik ely to in v olv e man y requests to the API and demands a basic kno wledge of how to interact with an API from within the R -en vironmen t. 2. The extraction and con v ersion of the data records from a nested web data format suc h as XML, JSON, or Y AML to a table-like representation that can b e directl y used for statistical analyses. An additional challenge is to ov ercome the tw o issues ab o v e in a wa y that supp orts the repro ducibilit y and replicabilit y of researc h based on API data (including the pre-pro cessing of ra w data). As p ointed out b y Matter and Stutzer ( 2015a ), this is an increasingly important issue in the con text of so cial science research which needs to b e resolved, as the new digital data sources hinder the replicabilit y of researc h owing to the presen t ‘unique purpose’ of the new data sets. 2.1. Intera cting with REST w eb APIs In order to visit a certain website, we normally t yp e a w ebsite’s address in a w eb bro wser’s address bar. The bro wser (a t yp e of web client ) then sends a message to the web server b ehind that address, requesting a copy of the website and then parses and renders the returned website (usually a HTML do cumen t) in the browser windo w. In REST terminology , the website’s address is an URL and the web site whic h the URL lo cates is a r esour c e . The do cument that the serv er sends in resp onse to the client’s request is a r epr esentation of that resource. Imp ortan tly , every URL p oints only to one resource and every resource should hav e only one URL (this is one of the REST principles and is referred to as addr essability ). The message that the bro wser sends to the web server is a HTTP GET request, a HTTP metho d that essen tially requests a represen tation of a giv en resource. REST w eb APIs w ork basically the same wa y as the website outlined ab ov e. The crucial difference is, that their design is inte nded for programmable clien ts (rather than h umans using a w eb bro wser) and that they therefore consist of URLs p ointing to resources that are not optimized for graphical rendering, but whic h instead contain the ra w data (often in a format such as XML or JSON that facilitates the integration of the data in a HTML do cumen t). In teracting with a REST API from within the R -environmen t, therefore, means, sending HTTP requests to a web server and handling the server’s resp onse with R . In addition to the basic functionality necessary for this, whic h are delivered in the base -pac k age ( R Core T eam Ulric h Matter 5 2013 ), more detailed functions for HTTP requests are provided in pack ages such as RCurl ( T emple Lang 2013a ) and httr ( Wic kham 2014a ). RWebData builds on the libcurl -based RCurl pac k age whic h is designed to interact with w eb serve rs hosting a REST API. The implemen tation is fo cused on a robust download of resources that chec ks the receiv ed HTTP resp onse for p otenti al problems (e.g., unexp ected binary conten t of the HTTP resp onses’ b o dy-en tit y) to make sure that the user do es not hav e to specify anything other than the URL. 2.2. W eb data con v ersion Most functions related to the fitting and testing of statistical mo dels as well as to exploratory data analysis and data visualization in the R computing environmen t w ork on data repre- sen ted in data-frames (a table-like flat representati on in whic h each row represen ts a data- record/observ ation and eac h column a v ariable describing these records). 6 Data-frames are probably the most common R -ob jects used b y researc hers when conducting an empirical anal- ysis with R . Many input/output-functionaliti es in R serv e to imp ort (exp ort) data into (from) R as data-frames. 7 Ho w ev er, when it comes to reading data from w eb APIs into R , this is not necessarily the case. The reason lies in the nature of web data formats whic h allo w for more flexibilit y than solely a table-lik e data represen tation and come (in the con text of web APIs) t ypically in a nested structure. While a con v ersion from one table in, e.g., a XML-document to a data-frame is straightforw ard (see, i.e., xmlToDataFrame() in T emple Lang 2013c ; see also Sievert 2014 ), a con version of a more complex XML-do cument with a nested data struc- ture to a flat table-like data represen tation in R or an y other computing en vironment is ex an te less clear and dep ends on the nature of the data and the purpose the data is conv erted for. 8 This is particularly the case for data prov ided by a non-scien tific API that is explicitly made for web dev elop ers in order to integrate the data in dynamic w ebsites or mobile appli- cations and not for researc hers to integrate the data in their analysis. Not surprisingly , there are differen t solutions offered in the R -environmen t to map web data formats suc h as JSON and XML to R -ob jects. 9 Most pack ages represen t web data as nested lists contain ing ob jects 6 T echnically , a data-frame can con tain other r-ob jects than just scalars (i.e., another data-frame). How ev er, in the v ast ma jority of applications in the context of statistical analysis and data visualization, data-frames are used for a table-like flat data represen tation. 7 See, i.e., data from CSV- and similar text files: read.table() in R Core T eam ( 2013 ) or similar functions in Wic kham and F rancois ( 2015 ), Microsoft Excel files: read.xls() in W arnes et al. ( 2014 ), data from other statistical computing en vironments suc h as Stata: read.dta() in R Core T eam ( 2014 ), or data from ODBC- data bases sqlQuery() in Ripley and Lapsley ( 2013 ). 8 See, e.g., the classical problem of mapping a set of XML-documents to a relational data base sc heme (RDBS; i.e., a set of linked tables) with or without knowing the scheme behind the XML-do cuments ( Moh et al. 2000 ; Men-hin and F u 2001 ). See also, in the R con text, the different implementations of mapping JSON to R -ob jects in Couture-Beil ( 2013 ), T emple Lang ( 2013b ), or Ooms et al. ( 2014 ) as well as a detailed discussion of this matter in Ooms ( 2014 ). 9 See, e.g., the CRAN T ask View on w eb tec hnologies and services ( http://cran.r- project.org/ web/views/WebTechnologies.ht ml ), the CRAN T ask View on open data ( https://github.com/ropen sci/ 6 RWebData : A High-Lev el Inter face to the Programmable W eb of differen t classes suc h as atomic v ectors or data-frames. After conv erting the original web data to R -ob jects, the user, therefore, often has to extract and rearrange the data records of in terest in order to obtain a data representation for statistical analysis. This pro cess b ecomes ev en more complex, as queries to the same API method migh t pro vide sligh tly differen t re- sults dep ending on the amoun t of detail embedded in the data records. In these cases, data extraction can b ecome particularly costly if the data set that needs to b e compiled dep ends on man y API requests in v olving v arious API metho ds. 3. Data mapping strategy and basic arc hitecture W eb data provided via REST APIs are typically in a format such as XML, JSON, or Y AML and are not structured in tables containing data v alues in rows and columns, but are rather organized in a nested (tree-like) structure. How ever, indep endent of the data format and data structure, do cuments pro vided by a particular REST API hav e basic asp ects in com- mon. Based on these commonalities, this section presen ts a conceptual and terminological framew ork as w ell as a description of ho w this framew ork is used to develop the data map- ping strategy applied in RWebData and serv es as the foundation of the data mapping algorithm whic h will b e outlined later on. 3.1. Original data structure and data semanti cs F rom the researc her’s p oint of view, the data sets pro vided by web APIs obey , indep endent of the raw data format and nesting structure, some very basic data semantics. F or these data seman tics, I use mainly the same terminology that is nicely outlined by Wickham ( 2014b , p. 3): 1. “A dataset is a collection of values , usually either nu mbers (if quan titativ e) or strings (if qualitativ e).” 2. “Every v alue b elongs to a variable and an observation .” 3. “A v ariable contains all v alues that measure the same underlying attribute (like height, temp erature, duration) across units.” 4. “An observ ation contains all v alues measured on the same unit (like a p erson, or a da y , or a race) across attributes.” opendata ), as w ell as the rOpenSci ( https://rop ensci.org/packages/ ) for an o verv iew of popular R -pac k ages that parse data from the w eb and map it to R -ob jects. Some contributions in this area also fo cus on the au- tomated information extraction from traditional websites made for h uman in teraction. Such metho ds are commonly summarized under the terms “web scraping” or “screen scraping” . See, e.g., the R -pack age rvest ( Wic kham 2015 ) for functions that facilitate w eb scraping as w ell as Munzert et al. ( 2014 ) for a practical in tro duction to web scraping with R . Ulric h Matter 7 In addition, each observ ation and eac h v ariable b elongs to a sp ecific observ ation typ e . Th us, in a m ulti-dimensional data set describing, for example, a city , observ ation t yp es could be buildings or citizens. The followi ng fictional XML example further illustrates this p oin t. John Smith Peter Pan S1 Karl Marx S2 Bill Gates MicroCapital Ltd 123 The XML do cument con tains a data set describing a firm. The v ariables “firstName” and “secondName” describ e observ ations of t yp e “emplo y ee” , while observ ations of type “share- holder” are described by the v ariables “ID” and “Name” . Finally , the v ariables “firmName” and “firmID” describ e the firm itself, which builds another t yp e of observ ation. The follo wing subsection illu strates ho w the data w ould b e mapped according to th e procedure implemen ted in RWebData . 3.2. Mapping nested w eb data to data-frames The core idea b ehind the data mapping pro cedure in RWebData is built around the basic se- 8 RWebData : A High-Lev el Inter face to the Programmable W eb man tics out lined abov e. According to this system, documen ts returned from APIs can con tain data describing observ ational units of one type or several differen t t yp es. RWebData returns one data-frame for eac h observ ation t yp e. Observ ations and v ariables b elonging to different t yp es are, th us, collected in different data-frames, each describing one type of observ ational unit. Some observ ations migh t describe the do cumen t (or main type of observ ational unit) itself (i.e. , metadata). These are collected in a separate data-frame. T ables 1 (a-c) presen t the XML-do cumen t from the example ab ov e after mapping to data-frames according to the outlined mapping pro cedure. The next subsection explains ho w this pro cess is implemented in RWebData . firmName firmID 1 MicroCapital Ltd 123 (a) Firm type firstName secondName 1 John Smith 2 P eter P an (b) Employ ee t yp e ID Name 1 S1 Karl Marx 2 S2 Bill Gates (c) Shareholder t yp e T able 1: The same data as in the XML co de example ab o ve but mapp ed to data-frames according to the generic RWebData mapping procedure. While (a) contains data describing the firm (the main observ ational unit) itself, (b) and (c) contain the observ ations and v ariables describing the observ ation types employ ee and shareholder, resp ectively . 3.3. Pars ing and generic mapping of differen t web data formats In order to map nested web data to data-frames, RWebData applies, in a first step, existing parsers for different formats (mime-types) of the data in the b o dy of the HTTP resp onse from the API to read the data in to R . 10 Indep enden t of the initial format, the data is parsed and co erced to a (nested) list represen ting the tree-structure of the raw data. In a next step, the data is mapp ed to one or several data-frames dep ending on the nesting structure and the recurrence of observ ation types and v ariables. App endix A.I presents a detailed description of the mapping algorithm. The data-frames are returned to the user either directly (in a list) or as part of an apiresponse -ob ject. The core idea b ehind the generic approach to w eb data conv ersion in the RWebData pack age is thus to disent angle the parsing of web data from the mapping of the data to data-frames. This allows the parsers for different w eb data formats to b e relativ ely simple, while the 10 In the case of JSON, either the parser provide d in Ooms et al. ( 2014 ) or (in order to increase robustness in sp ecial cases) the one contributed by T emple Lang ( 2013b ) is applied. XML-do cuments or RSS-documents are parsed with the parser pro vided in T emple Lang ( 2013c ) and Y AML-documents with the parser pro vided in Stephens ( 2014 ). Ulric h Matter 9 same mapping algorithm is fo cused on the data semantics and can b e applied independent of the initial raw data format. In addition, it allo ws differen t parsers’ adv antages to b e com bined in order to mak e the parsing pro cess more robust. The suggested procedure go es hand in hand with the ob ject-oriented approach applied in RWebData and pro vides summary and plot metho ds that work indep enden t of the initial data format. The mo dular design of mapping w eb data to data-frames facilitates the extension of RWebData ’s compatibilit y with additional w eb data formats or alternative parsers that are, for example, optimized for v ast w eb do cumen ts. P arsers simply need to read the w eb data as (nested) lists or in a format that conserv es the tree-structure of the ra w w eb data and can b e easily co erced to a nested list. 3.4. Basic data mapping algorithm Once the web data-do cument is do wnloaded from an API and co erced to a nested list, the algorithm consists essen tially of tw o procedures: 1. The extraction of different observ ation types (and their resp ectiv e observ ations and v ariables) as sub-trees. While rev ersely trav ersing the whole data-tree, the algorithm c hec ks at each level (no de) of the tree whether either the whole curren t sub-tree or one of its siblings can b e considered an observ ation type. If so, the respective sub-tree is extracted and sa ved in a deposit v ariable. If not, the algorithm tra verses further do wn in the tree-structure. Checks for observ ation types are defined as a set of control statements that incorp orate the abov e outlined data seman tics. Essentially , the recurrence of the same v ariables as siblings (containing the actual data v alues as leaf elemen ts) is decisive in order to recognize observ ation types. The result of this step is a set of sub-trees, eac h sub-tree con taining one observ ation type and its resp ective observ ations and v ariables. 2. F or each of the resulting observ ation types (in the form of sub-trees), the resp ective observ ations are extracted as char acter vector s and b ound as rows in a data-frame, while the v ariable names are conserv ed and added as column names. This pro cedure is built to b e robust to observ ations describ ed by a differing n um b er of v ariables. The result of this step is a set of data-frames, eac h describing one observ ation type and con taining individual observ ations as rows and v ariables as columns. Singly o ccurring leaf no des that are not nested within one of the detected observ ation types are collected along the w a y and then returned in one data-frame. According to the logic of the data seman tics and the algorithm outlined ab o v e, these remaining data can be seen as metadata d escribing the data set as a whole. App endix A.I presen ts a detailed, more technical outline of the data mapping algorithm. 10 RWebData : A High-Lev el Inter face to the Programmable W eb 3.5. Basic architecture RWebData is sp ecifically written to giv e practical researche rs a high-lev el interface to compile data from the programmable w eb. The common user will th us normally not b e confron ted with the range of in ternal pro cesses outlined ab o v e. The work-flo w with RWebData for an a v erage user th us mainly in vol ves the sp ecification of what data should b e requested from what API (in the form of either a list, a data-frame or simply a string with a URL) to one of RWebData ’s high-lev el functions in order to obtain the desired data mapped to data-frames. Figure 1 illustrates the basic arc hitecture of RWebData , summarizing its internal functionalit y and the pro cessing pro cedure when the pac k age is used b y an av erage user. Rw e b A P I: H ig h - L e v e l A r c h it e c t u r e U . M a t t e r , M a y 2 0 1 4 ! 1) S i m p l e C a s e : : G e t D a ta fr o m a n y (R ES T F U L ) A P I ! Gene rat e API -Request list, data frame, or URL (string) API - GE T (and Response- Handling) apirequest-object HTTP GET RESTFUL Web - API HTTP response Server Client apiresp-object (contains raw XML/JSON) R-Console/ R- Studio Parse and pre-process XML/JSON /YAML - dat a nested list Transform tree - structured data to one or several tables list of tables or apidata -object R WebData User Figure 1: Basic architecture of the RWebData pack age. RWebData ’s high lev el func tions tak e either lists, data frames, or a URL (as character string) as input v alues and return a list of data-frames or an apidata-ob ject. First, RWebData generates an apireq uest-object based on whic h the HTTP GET and resp onses are handled. Up on successful in teraction with the API, an apiresponse-object , con taining, in ter alia, the raw w eb data, is generated. Sub ject to consideration of the mime-t yp e of the ra w data, the data is then prepro cessed, parsed, and coerced to a nested list. Finally , the data mapping algorithm is applied in order to extract the data in the form of data frames as outlined in the previous section. The latter builds the main part of the pac k age. The pro cedure is straigh t-forw ard and user-friendly in practice. Ulric h Matter 11 4. Basic functionalit y In order to describe th e basic usage of RWebDa ta , this section offers a step-b y-step in tro duction to the high-lev el functionalit y of the pack age. Some of the functions describ ed here offer more options whic h are not all discussed in this section. 11 . RWebData ’s implemen tation is motiv ated by the conv ention o v er configuration paradigm and th us provides a w a y for the user to interact with APIs using as few sp ecifications as necessary to access the data. RWebData then conv erts data in the most common formats pro vided b y APIs to one data-frame or a list of sev eral data-frames. Hence, the user do es not need to sp ecify an y HTTP options or understand what XML or JSON is and is able to obtain the data directly in the expected format for statistical analysis. There are primarily tw o high-lev el functions in RWebData that provide this functionalit y in differen t w ays: getTabularData() and apiData() . 4.1. F etching data from REST APIs The function getTabularData() pro vides a straightforw ard w a y to get data from web APIs as data-frames. In the simplest case, the function tak es a string con taining the URL to the resp ectiv e API resource as an input. 12 The function then handles the HTTP request and resp onse, parses the b o dy of the resp onse (dep ending on the mime-type) and automatically extracts the data records from the nested data structure as data-frames. This enables us to fetc h data from different APIs provi ding data in differen t formats with essen tially the same command. Consider, for example, the W orld Bank Indicators API whic h pro vides time series data on financial indicators of different coun tries. 13 W e wan t to use data from that API to inv estigate ho w the United States’ public dept was affected by the financial crisis in 2008. All we need in order to do wnload and extract the data is the URL to the resp ectiv e resource on the API. 14 R> u <- paste0("http://api.wo rldbank.org/countries/USA/ind icators", # address + "/DP.DOD.DECN.CR.GG.CD? ", # query method + "&date=2005Q1:2013Q4") # parameters R> usdept <- getTabularData(u) 11 Details on all these options are provided by the resp ectiv e R help files. Users are generally encouraged to read the detailed pack age documentati on of RWebData . 12 The URL to the resource whic h a user wan ts to qu ery is very easy to find in an y REST API documentation. Ho w to call the resp ective resource methods of an API with URLs is the essential part of suc h do cumentations. 13 Note that this is an example of an API which is – unlike most APIs – explicitly made for researc hers retrieving data from the w eb. Nev ertheless, retrieving data from this API with functions from, e.g., the XML pack age ( T emple Lang 2013c ) is not necessarily straigh tforward for users without a background in web tec hnologies. 14 A URL to an API resource t ypically includes the base address of the API, a part sp ecifying the sp ecific API query metho d or resource, and some query parameters. Ho w to build query-URLs in the specific case of the W orld Bank Indicators API is w ell documented on http://data.worldbank.or g/node/203 . 12 RWebData : A High-Lev el Inter face to the Programmable W eb Without b othering ab out the initial format 15 , the returned data is already in the form of a data-frame and is ready to b e analyzed (e.g., by plotting the time series as presen ted in Figure 2 ): R> require(zoo) R> plot(as.ts(zoo(usdept$value, as.yearqtr(usdept$date) )), ylab="U.S. public dept (in USD)") Time U.S. public dept (in USD) 2006 2008 2010 2012 2014 1.0e+13 1.4e+13 1.8e+13 Figure 2: Plot of the time series on United St ates’ public dept extracted from the W orld Bank Indicators API The same approac h of fetching data with getTabularData() can b e applied to any other REST API that provides data in either XML/RSS, JSON, or Y AML. Instead of a URL, one can also use a list of request parameters plus the base URL that directs to the API’s 15 The W orld Bank Indicators API pro vides time series data b y default as XML in a compressed text file. Handling solely one API query of this t ype might already in v olve many steps to fetch and extract the data with the existing low er level functions. And, thus, might b e tedious for a user who only has limited exp erience with web technologies. Ulric h Matter 13 serv er as function argument s. W e use this approach in order to download data from the Harv ardEv en ts API ( https://manual.cs50.net/api/events/ ), which pro vides data ab out curren t or past ev en ts at Harv ard Univ ersity . Data on ev ents can b e fetc hed in v arious formats. In the following example, we query the API for up coming lectures at Harv ard and request a differen t data format eac h time (note the differen t format in the output parameter). R> hae_api <- "http://events.cs50.net/api/1.0/events?" R> haexml <- getTabularData(list(output="xml", q="lecture"), base.url=hae_api) R> haejson <- getTabularData(list(output="json", q="lecture"), base.url=hae_api) R> haerss <- getTabularData(list(output="rss", q="lecture"), base.url=hae_api) In eac h case, getTabularData() automatically con v erts the ra w web data in to data-frames. 16 The output to this example is presen ted in App endix A.I I . While the data format in the examples ab ov e v aries, the underlying data structure is rela- tiv ely simple in all these examples. The W orld Bank Indicators API is sp ecifically devised to pro vide data for st atistical analysis. The Harv ardEven ts API, although primarily designed for dev elop ers, provides data that can b e naturally represented in one table (with the exception of resp onses in RSS format). The next section considers examples where the pro vided data cannot easily b e though t of as one single table. 4.2. Nested data structures The high-level function getTabularData() automatically handles nested data and conv erts them to a list of v arious data-frames. It does not, ho w ev er, provide any information on the initial nesting structure and can only handle individ ual requests. Alternatively , w e can use apiData() in order to exploit RWebData ’s in ternal classes and methods to handle requests to APIs. The simplest wa y to call apiData() is again b y using a URL (as a string) pointing to an API resource. apiData() returns an ob ject of class apiresponse . Such apiresponse ob jects con tain additional information ab out the executed request to the API and supp ort generic plot and summary functions illustrating the structure and cont ent of the retriev ed w eb do cumen t. The follo wing example demonstrates the summary metho ds for apiresponse ob jects with data from the Ergast API ( http://ergast.com/m rd/ ) on F ormula 1 race results. R> f1 <- apiData( ' http://ergast.com/api/f1/2013/1/result s.json ' , + shortnames=TRUE) R> summary(f1) 16 Although an API offers its data in different formats, it do es not necessarily send exactly the same conten t for the same request in differen t formats. Differen t formats migh t serv e different purp oses for w eb dev elopers. It thus mak es sense that some con tain additional informat ion. Therefore, data requests with getTabularData() to the same API but in different formats do not automatically lead to ident ical results. While haexml and haejson are almost identical in the example abov e, haerss differs from the other results. 14 RWebData : A High-Lev el Inter face to the Programmable W eb API data summary: ================= The API data has been split into the following 2 data frames: Length Class Mode metadata 20 data.frame list Results 27 data.frame list The respective data frame(s) contain the following variables: 1. metadata: xmlns, series, url, limit, offset, total, season, round, 1, raceName, circuitId, 2, circuitName, lat, long, locality, country, date, time, path, 2. Results: number, position, positionText, points, driverId, permanentNumber, code, url, givenName, familyName, dateOfBirth, nationality, constructorId, url, name, nationality, grid, laps, status, millis, time, rank, lap, time, units, speed, path, The summary metho d called by the generic summary() , provide s an ov erview of the v ariables included in the data and shows ho w RWebData has split the data into sev eral data-frames. This is particularly helpful in an early phase of a research pro ject when exploring an API for the first time. The next example demonstrates the visualization of nested data returned from the Op en States API 17 . W e query data on a legislator in the Council of the District of Columbia with apiData() and call the generic plot() on the returned apiresponse ob ject. Figure 3 sho ws the result of the plot command b elo w. Note that the Op en States API is free to use for registered users. Up on registration a api-k ey is issued that is then added as a parameter- v alue to eac h API request (indicated with “ [YOUR-API-KEY] ” in the example b elow). R> url <- "http://openstates.org/api/v1/legislators/DCL 000004/ + ?apikey=[YOUR-API-KEY]" R> p <- apiData(url) R> plot(p, type="jitter") 17 See https://sunlightlabs.github.io/openstates- api/ for details. Ulric h Matter 15 The apiresponse plot method illustrates the nesting structure of the original data b y d rawin g en tities (v ariables or types) as no des and nesting relationships as edges in a Reingold-Tilford tree-graph ( Reingold and Tilford 1981 ; see also Csardi and Nepusz 2006 for the implemen- tation in R on whic h RWebData relies.). The option type="jitter" shifts the nodes slightly v ertically to mak e long no de names b etter readable in the graph. The transformed data (in the form of a list of data-frames) sa v ed in an apiresponse -ob ject can be accessed with getdata() . In the current example, the data has b een split in to tw o data-frames: one with metadata con taining general v ariables describing the legislator, and one con taining data on the legislator’s roles in the 2011-2012 session. R> pdata <- getdata(p) R> summary(pdata) Length Class Mode metadata 23 data.frame list 2011-2012 11 data.frame list root +fax last_name updated_at sources full_name old_roles id first_name middle_name office_address state votesmart_id email all_ids1 all_ids2 leg_id active photo_url +phone url country created_at lev el offices suffixes sourcesurl 20112012 fax name phone address type term district chamber old_rolesstate party 20112012type committee_id committee position Figure 3: Reingold-Tilford tree-graph illustrating the nested structure of the raw JSON data from the Op en States API. 4.3. Intera ctiv e sessions So far, w e ha ve only considered individual requests to APIs. In practice, users migh t w ant to query an API in man y wa ys in an interactiv e session to explore the data and assemble 16 RWebData : A High-Lev el Inter face to the Programmable W eb the data set that meets their needs. This can easily be done with RWebData . W e con tinue with the Op en States API example. First, w e fetch general data on all legislators in the DC Council. R> url <- "http://openstates.org/api/v1/legislators/?st ate=dc&chamber=upper + &apikey=[YOUR-API-KEY]" R> dc_council <- getTabularData(url) The goal is to combine these general data with data on the legislators’ roles. In particular, we w an t to download the detailed role data on all legislators and combine these within one data set. As there is no API metho d provided to obtain these data with one call to the API, we use apiDownload() to handle all individual requests at once. By insp ecting the dc_council data-frame from ab ov e, we see that the fifth column of that data-frame contains all the IDs (id) p ointing to the resp ectiv e resources on individual c ouncil members. W e simply paste these ids with the legislators -method and use the resulting URLs as the function argumen t to apiDownload() in order to obtain all the data compiled in one data-frame. R> head(names(dc_council)) [1] "fax" "last_name" "updated_at" "full_name" "id" [6] "first_name" R> api_requests <- paste0("http://openstates.org/api/v1 /legislators/", + dc_council$id, + "/?apikey=", + "YOUR-API-KEY") R> dc_leg_roles <- apiDownload(api_requests) During the download, apiDown load() indicates the num b er of queries pro cessed on a progress bar prin ted to the R console. Moreo v er, apiDownload() perio dically sav es the pro cessed data lo cally in a temp orary file. This relieves the working memory assigned to the R -session and makes large downloads robust to net work interrupt ions. A summary of the resulting dc_leg_roles is presented in Appendix A.I I I . Ulric h Matter 17 5. W riting in terfaces to REST APIs In the context of an ongoing researc h pro ject, it might b e more comfortable to hav e a sp ecific function for specific queries to the same API. W e could manu ally program suc h a function based on RWebData ’s in ternal functions or using the functions of other pac k ages. How ever, RWebData provides a w a y to write suc h functions automatically . Given the parameters and the base URL for the resp ective API metho d/resource, generateQueryFunction() writes a function that includes all the functionalit y of the pac k age to handle queries to that specific API metho d/resource. The same works for APIs that accept requests via form URLs, such as the BisTip.com Search API. Here, only the base URL and the resp ective parameters ha ve to b e sp ecified. R> bi_trip <- "http://www.bistip.com/api/v1/trips.json? " R> bi_seek <- "http://www.bistip.com/api/v1/seeks.json? " R> bi_params <- list(from=NA, to=NA) # parameters without default value R> bitstipTrip <- generateQueryFunction(x=bi_params, base.url=bi_trip) R> bitstipSeek <- generateQueryFunction(x=bi_params, base.url=bi_seek) The new function s bitstipTrip() and bitstipSeek() can now be used to query the Bit- sTip.com API. R> all_t <- bitstipSeek(from="tokyo") R> j_s <- bitstipTrip(from="jakarta", to="singapore") R> names(j_s)[1:4] [1] "departure_date_medium_format" "origin_location" [3] "arrival_date_medium_format" "period" With only fiv e lines of co de, we hav e generated a complete BitsTip.com API R -clien t library (or Op en Source In terface; Matter and Stutzer 2015a ) that automaticall y pro vides the web data as data-frames. 6. Discussion Empirically driv en so cial sciences can substan tially profit from the rapidly growing pro- grammable w eb as a data source cov ering countless dimensions of so cio-economic activity . Ho w ev er, the purp ose and goals that dro ve the initial dev elopment of web APIs focused on pro viding general data for public use via dynamic w ebsites and other applications, and not on the pro vision of data formatted for scien tific research and statistical analyses. This leads to tec hnical hurdle s a researcher has to ov ercome in order to compile suc h data in a format 18 RWebData : A High-Lev el Inter face to the Programmable W eb that is suitable for statistical analysis. The presen ted R pac k age RWebData suggests a simple high-lev el inte rface that helps to o vercome such tec hnical hurdles (and the resp ectiv e costs) asso ciated with the statistical analysis of data from the programmable w eb. The pac k age con tributes to a frictionless and w ell do cumen ted raw data compilation and data preparation pro cess that substan tially increases the replicabili ty and reproducibilit y of original researc h based on data from the programmable web. As p ointed out b y Crosas et al. ( 2015 ), social science research with big data p oses generally new c hallenges to the reuse of data as well as the repro duction of results. Empirical research based on newly av ailable big public data from w eb data sources is a challenge demanding scien tific rigor. The need for replicability is even greater in the age of big data: Concision must b e an essential c haracteristic of data recording and retriev al with regard to parsing and compilation. Rigor applies not only to the final prepared data used in the analysis, but also to the documentation of the data preparation and data selection pro cess. With the further developmen t of RWebData , an R-script do cu- men ting how the pac k age’s high-lev el functions hav e b een applied to compile data as well as an y further step in the data preparation and analysis are enough to ensure the replicability of a study based on big public data from the programmable w eb. Ac kno wledgemen ts I am grateful to Dietmar Maringer, Armando Meier, Reto Odermatt, Mic haela Slotwins ki, Alois Stutzer, as w ell as seminar participan ts at the Univ ersity of Basel and the Univ ersit y of Oxford for helpful remarks. Sp ecial thanks go to Ingmar Schlec ht for man y productive discussions on softw are dev elopmen t and the metho dological asp ects of this paper. I also thank Jo erg Kalbfuss for excellen t research assistance. The author ackno wledges financial supp ort from the Univ ersit y of Basel Researc h F und. Ulric h Matter 19 References Barb er´ a P (2015). “Birds of the Same F eather Tweet T ogether: Bay esian Ideal Poin t Estima- tion Using Twitter Data.” Politic al Analysis , 23 (1), 76–91. Bell G (2009). “F oreword/D igital Libraries for Data and Do cumen ts: Just Like Mo dern Do cumen t Libraries.” In T Hey , S T ransley , K T olle (eds.), The F ourth Par adigm: Data- Intensive Scientific Disc overy . Microsoft Research, Redmond, W ashington. Cioffi-Revilla C (2010). “Computational So cial Science.” Wiley Inter disciplinary R eviews: Computational Statistics , 2 (3), 259–271. Con te R, Gilbert N, Bonelli G, Cioffi-Revil la C, Deffuan t G, Kertesz J, Loreto V, Moat S, Nadal JP , Sanc hez A, Now ak A, Flache A, San Miguel M, Helbing D (2012). “Manifesto of Computational So cial Science.” The Eur op e an Physic al Journal Sp e cial T opics , 214 (1), 325–346. Couture-Beil A (2013). rjson: JSON for R . R pac k age v ersion 0.2.13, URL http://CRAN. R- project.org/package=rjson . Crosas M, Honak er J, King G, Sw eeney L (2015). “Automating Op en Science for Big Data.” ANNALS of the Americ an A c ademy of Politic al and So cial Scienc e , 659 (1), 260–273. Csardi G, Nepusz T (2006). “The igraph Softw are P ac k age for Complex Net w ork Research.” InterJournal , Complex Systems , 1695. URL http://igraph.org . DiGrazia J, McKelvey K, Bollen J, Ro jas F (2013). “More Tw eets, More V otes: So cial Media as a Quan titativ e Indicator of P olitical Beha vior.” PL oS ONE , 8 (11), e79449. Do dds PS, Harris KD, Kloumann IM, Bliss CA, Danforth CM (2011). “T emp oral P atterns of Happiness and Information in a Global Social Netw ork: Hedonometrics and Twitter.” PL oS ONE , 6 (12), e26752. Giles J (2012). “Making the Links.” Natur e , 448 (7412), 448–450. Helbing D, P ournaras E (2015). “Build Digital Demo cracy .” Natur e , 527 (7576), 33–34. Lazer D, P entland A, Adamic L, Aral S, Barab´ asi AL, Brew er D, Christakis N, Con tractor N, F o wler J, Gutmann M, Jebara T, King G, Macy M, Roy D, V an Alst yne M (2009). “Computational So cial Science.” Scienc e , 323 (5915), 721–723. Matter U, Stutzer A (2015a). “p vsR: An Op en Source Interface to Big Data on the American P olitical Sphere.” PL oS ONE , 10 (7), e0130501. doi:10.1371/journal.pone.0130501 . 20 RWebData : A High-Lev el Inter face to the Programmable W eb Matter U, Stutzer A (2015b). “The Role of Lawy er-Legislators in Shaping the Law: Evidence from V oting Beha vior on T ort Reforms.” Journal of L aw and Ec onomics , 58 (2), 357–384. Men-hin Y, F u A Wc (2001). “F rom XML to Relational Databases.” In Pr o c e e dings of the 81h International Workshop on Know le dge R epr esentation Me ets Datab ases (KRDB 2001), R ome, Italy . Moh CH, Lim EP , Ng WK (2000). “Re-engineering Structures from W eb Do cuments.” In Pr o c e e dings of the fifth A CM Confer enc e on Digital libr aries , pp. 67–76. ACM. Munzert S, Rubba C, Meissner P , Nyh uis D (2014). Automate d Data Col le ction with R: A Pr actic al Guide to Web Scr aping and T ext Mining . John Wiley & Sons, Chichester, UK. NCBI (2014). “Programmatic Access to GEO.” URL http://www.ncbi.nlm.nih.gov/geo/ info/geo_paccess.html . Nolan D, T emple Lang D (2014). XML and Web T e chnolo gies for Data Scienc es with R . UseR! Springer, New Y ork. Ooms J (2014). “The jsonlite Pac k age: A Practical and Consisten t Mapping Betw een JSON Data and R Ob jects.” ArXiv e-prints . 1403.2805 . Ooms J, T emple Lang D, W allace J (2014). jsonlite: A smarter JSON enc o der/de c o der for R . R pack age version 0.9.8, URL http://CRAN.R- project.org/package=j sonlite . Preis T, Moat HS, Bishop SR, T releav en P , Stanley HE (2013). “Quantifying the Digital T races of Hurricane Sandy on Flic kr.” Scientific R ep orts , 3 . ProgrammableW eb (2014). “Programmablew eb Research Center: Grow th in W eb APIs F rom 2005 to 2013.” URL www.programmableweb.com/api- research . R Core T eam (2013). R: A L anguage and Envir onment for Statistic al Computing . R F oun- dation for Statistical Computing, Vienna, Austria. URL http://www.R- project.org/ . R Core T eam (2014). for eign: R e ad Data Stor e d by Minitab, S, SAS, SPSS, Stata, Systat, Weka, dBase, ... R pac k age versi on 0.8-59, URL http://CRAN.R- project.org/package= foreign . Reingold EM, Tilford JS (1981). “Tidier Drawings of T rees.” IEEE T r ansactions on Softwar e Engine ering , 7 (2), 223–228. Ric hardson L, Am undsen M (2013). RESTful Web APIs . O’Reilly Media, Cambri dge. Ripley B, Lapsley M (2013). R ODBC: ODBC Datab ase A c c ess . R pack age version 1.3-10, URL http://CRAN.R- project.org/package=RODBC . Ulric h Matter 21 San tos W (2012). “195 Science APIs: Springer, EP A and NCBI.” URL http://www. programmableweb.com/new s/195- science- apis- springer- epa- and- ncbi/2012/03/28 . Siev ert C (2014). XML2R: EasieR XML data c ol le ction . R pack age version 0.0.6, URL http://CRAN.R- project.org/package=XML2R . Stephens J (2014). yaml: Metho ds to Convert R Data to Y AML and Back . R pack age v ersion 2.1.11, URL http://CRAN.R- project.org/package=yaml . Sw artz A (2013). “Aaron Sw artz’s A Programmable W eb: An Unfinished W ork.” In J Hendler, Y Ding (eds.), Synthesis L e ctur es on The Semantic Web: The ory and T e chnolo gy . Morgan & Cla yp o ol Publishers. T emple Lang D (2013a). RCurl: Gener al network (HTTP/FTP/...) client interfac e for R . R pac k age v ersion 1.95-4.1, URL http://CRAN.R- project.org/package=RCurl . T emple Lang D (2013b). RJSONIO: Serialize R obje cts to JSON, JavaScript Obje ct Notation . R pac k age v ersion 1.0-3, URL http://CRAN.R- project.org/package=RJSONIO . T emple Lang D (2013c). XML: T o ols for Parsing and Gener ating XML Within R and S-Plus. R pac k age v ersion 3.95-0.2, URL http://CRAN.R- project.org/package=XML . T urner V, Gantz JF, Reinsel D, Min ton S (2014). “The Digital Universe of Opportunities: Ric h Data and the Increasing V alue of the In ternet of Things.” White p ap er , IDC, F ramingham, MA. W3C (2013). “W3C Seman tic W eb Activit y: What Is the Semantic W eb?” URL www.w3. org/2001/sw/ . W arnes GR, Bolker B, Gorjanc G, Grothendiec k G, Korosec A, Lumley T, MacQueen D, Magn usson A, Rogers J, others (2014). gdata: V arious R Pr o gr amming T o ols for Data Manipulation . R pack age version 2.13.3, URL http://CRAN.R- project.org/package= gdata . Wic kham H (2014a). httr: T o ols for Working with URLs and HTTP . R pack age v ersion 0.4, URL http://CRAN.R- project.org/package=httr . Wic kham H (2014b). “Tidy Data.” Journal of Statistic al Softwar e , 59 (10), 1–23. Wic kham H (2015). rvest: Easily Harvest (Scr ap e) Web Pages . R pack age ver sion 0.2.0, URL http://CRAN.R- project.org/package=rvest . Wic kham H, Chang W (2015). devto ols: T o ols to Make Developing R Packages Easier . R pac k age v ersion 1.7.0, URL http://CRAN.R- project.org/package=devtools . 22 RWebData : A High-Lev el Inter face to the Programmable W eb Wic kham H, F rancois R (2015). r e adr: R e ad T abular Data . R pack age vers ion 0.1.0, URL http://CRAN.R- project.org/package=readr . Ulric h Matter 23 App endix A.I. Data mapping algorithm As p ointed out in the main text, RWebData parses and co erces the raw w eb data to a nested list represen ting the tree-structure of the data. Call this list ~ x . The data mapping algorithm consists of tw o main parts. First, ~ x is split into n lists rep- resen ting sub-trees. One for eac h observation typ e in the data. The key problem that the algorithm has to solv e at this step is the identification of cutting p oints (i.e., what part of the tree b elongs to what observ ation t yp e). Second, each resulting sub-tree is then split into individual c haracter vectors. One for eac h observation . The individual observ ations are then stac k ed together in one data-frame with eac h vect or (observ ation) as a row. Algorithm A1 presen ts a formal description of these pro cedures. In the resulting data-frames, each ro w i represen ts one observation , and eac h column j represen ts a variable/char acteristic of the n observ ations. The data-frames are then returned in a list. In order to mak e the formal descriptions of the procedures in the data mapping algorithm con v enien tly readable, the pseudo-code describ es simple v ersions of these procedures (that are not necessarily most efficient). The algorithms’ R -implementation s in RWebData are more effi- cien t and con tain more con trol statemen ts to ensure robustness. The act ual R -implem entat ion relies partly on existing R functions and fav ors vectori zation ov er for-lo ops in some cases. 24 RWebData : A High-Lev el Inter face to the Programmable W eb Algorithm A1 Data mapping algorithm 1: pro cedure Types ( ~ x ) 2: T y pes ← empty list 3: deposit ← empty list 4: if ~ x is an observ ation t yp e then 5: add ~ x to T y pes 6: return T y pes 7: end if 8: if ~ x con tains a part i at the highest nesting lev el that is an observ ation t yp e then 9: add i to T y pes 10: remo v e i from ~ x 11: end if 12: for all elements i in ~ x do 13: if i is a non-empty list then 14: if i is an observ ation type then 15: add i to T y pes 16: else 17: apply this v ery pro cedure to i . recursiv e call 18: add the resulting observ ation types to T y pes 19: add the remaining lea v es (metadata) to deposit 20: end if 21: else 22: add i to deposit . it’s a leaf no de (i.e., just a v alue) 23: end if 24: end for 25: end pro cedure 26: pro cedure Obser v a tions ( T y pes ) 27: r ow s ← empty list 28: for all ~ obsty pe in T y pes do 29: for all obser v ation in ~ obsty pe do 30: unlist and transpose observ ation . extract lea v es as ve ctor 31: add resulting v ector to r ow s 32: end for 33: bind ro ws to one data-frame (preserving v ariable names) 34: end for 35: end pro cedure Ulric h Matter 25 A.I I. Harv ardEv ents API example R> hae_api <- "http://events.cs50.net/api/1.0/events?" R> haexml <- getTabularData(list(output="xml", q="lecture"), base.url=hae_api) R> haejson <- getTabularData(list(output="json", q="lecture"), base.url=hae_api) R> haerss <- getTabularData(list(output="rss", q="lecture"), base.url=hae_api) R> # comparison of results based on xml/json data: R> dim(haexml) [1] 14 10 R> names(haexml) [1] "summary" "dtstart" "dtend" [4] "location" "description" "calname" [7] "id" "calname" "INPUT_:_output" [10] "INPUT_:_q" R> haexml[1,4] [1] "The Harvard Ed Portal, 224 Western Ave., Allston, Mass." R> dim(haejson) [1] 14 10 R> names(haejson) [1] "summary" "dtstart" "dtend" [4] "location" "description" "calname" [7] "id" "calname" "INPUT_:_output" [10] "INPUT_:_q" R> haejson[1,4] [1] "The Harvard Ed Portal, 224 Western Ave., Allston, Mass." R> # rss response is differently structured: R> summary(haerss) 26 RWebData : A High-Lev el Inter face to the Programmable W eb Length Class Mode metadata 8 data.frame list item 8 dat a.frame list R> haerss$item[1,] guid title 1 http://events.cs50.net/20281645 Fundamentals of Social Media 1.0 link description category 1 http://events.cs50.net/20281645 events pubDate INPUT_:_output INPUT_:_q 1 Tue, 19 Jul 2016 17:00:00 -0400 rss lecture R> R> A.I I I. Op en States API R> url <- "http://openstates.org/api/v1/legislators/?st ate=dc&chamber=upper + &apikey=[YOUR-API-KEY]" R> c_council <- getTabularData(url) R> api_requests <- paste0("http://openstates.org/api/v1 /legislators/", dc_council$id, "&apikey=", "YOUR-API-KEY") | | | 0% | |====================== ======== | 50% | |====================== ============================= =========| 100% R> # explore the data R> summary(dc_leg_roles) Length Class Mode metadata 54 data.frame list 2013-2014 13 data.frame list 2011-2012 13 data.frame list Ulric h Matter 27 R> dim(dc_leg_roles$roles) NULL Affiliation: Ulric h Matter F acult y of Business and Economics Univ ersit y of Basel P eter Merian-W eg 6 4002 Basel, Switzerland E-mail: ulrich.matter@unibas.ch W ebsite: http://wwz.unibas.ch/matter
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment