프로그래머블 웹을 위한 고수준 R 인터페이스
RWebData 패키지는 REST 기반 웹 API에서 제공되는 XML, JSON, YAML 등 다양한 중첩형 데이터를 자동으로 파싱하고, 연구자가 바로 통계 분석에 활용할 수 있는 평탄한 데이터프레임 형태로 변환해 주는 고수준 R 인터페이스이다. 비전문가도 최소한의 코드만으로 대규모 공개 데이터를 수집·정제·재현 가능하게 만든다.
저자: Ulrich Matter
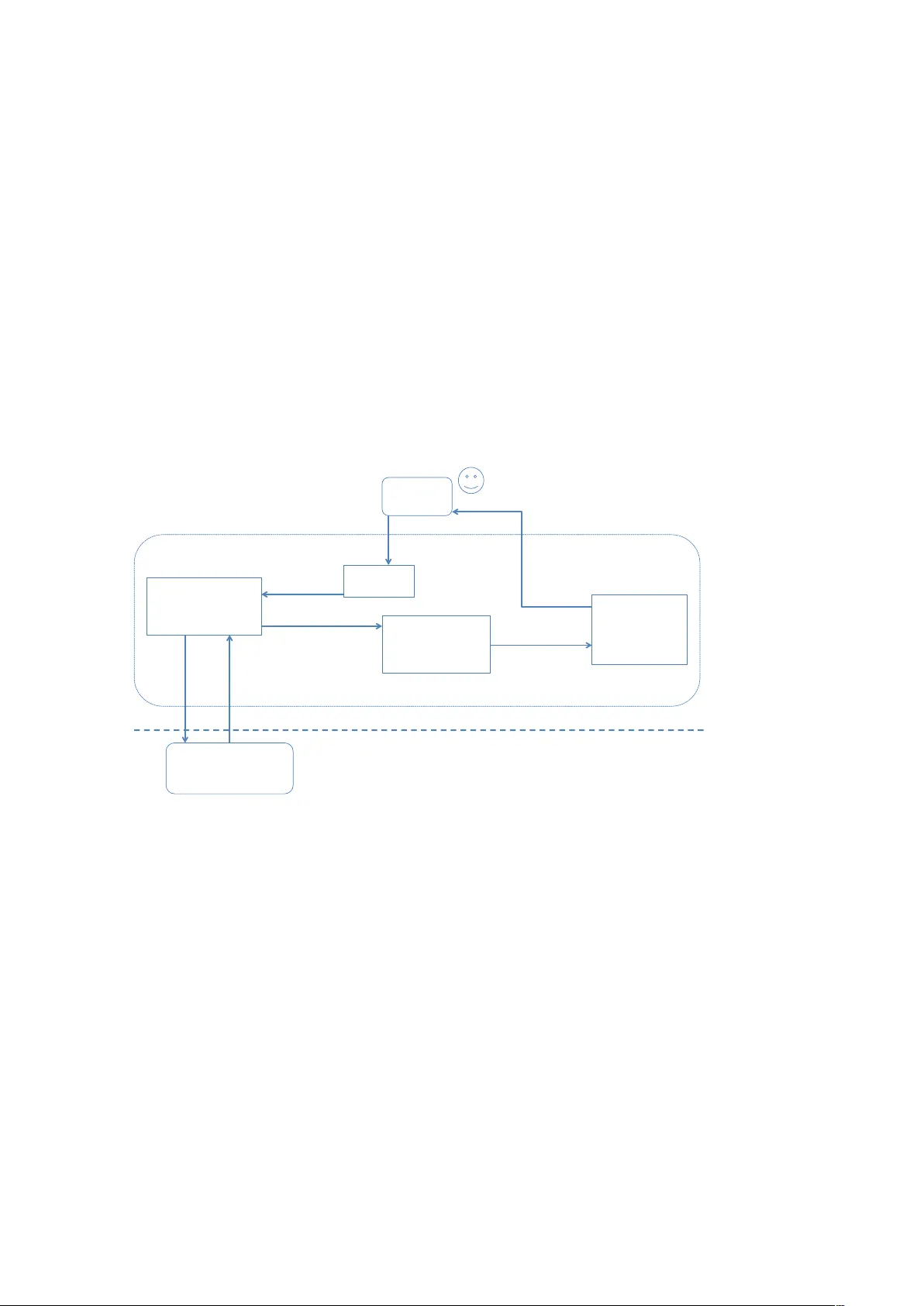
본 논문은 프로그래머블 웹(Programmable Web)이 사회과학 및 기타 학문 분야에 제공하는 방대한 데이터 자원을 활용하기 위한 실용적인 도구인 RWebData 패키지를 소개한다. 서론에서는 웹이 단순히 인간이 읽는 HTML 페이지를 넘어, 기계가 읽을 수 있는 구조화된 데이터(XML, JSON, YAML 등)를 REST API 형태로 제공하는 ‘프로그래머블 웹’으로 진화하고 있음을 설명한다. 이러한 변화는 연구자에게 새로운 데이터 원천을 제공하지만, 동시에 API 호출, 데이터 파싱, 중첩 구조 해석 등 기술적 장벽을 만든다. 특히, 비전문가가 다수의 API 엔드포인트를 조합해 데이터를 수집하고, 이를 통계 분석에 적합한 형태로 변환하는 과정은 복잡하고 오류가 발생하기 쉬워 재현 가능성을 저해한다.
이에 대한 해결책으로 제시된 것이 RWebData 패키지이다. 패키지는 크게 두 단계로 구성된 워크플로우를 제공한다. 첫 번째 단계는 RCurl 기반의 HTTP GET 요청을 통해 API 응답을 받아오고, 응답 본문을 해당 포맷에 맞는 R 객체(리스트)로 파싱한다. 이때 XML, JSON, YAML 각각에 특화된 파서가 자동으로 선택된다. 두 번째 단계는 ‘데이터 매핑 알고리즘’으로, 파싱된 리스트 구조를 관찰해 동일 레벨에 존재하는 반복 요소를 행으로, 속성을 열로 변환한다. 핵심은 트리 구조를 재귀적으로 탐색하면서, 각 노드가 관측치(Observation)와 변수(Variable)의 역할을 하는지를 판단하는 규칙이다. 예를 들어, `` 아래의 여러 `` 요소는 각각 하나의 관측치가 되며, ``, `` 같은 하위 태그는 변수로 매핑된다. 알고리즘은 또한 중첩된 리스트가 존재할 경우, 이를 별도의 데이터프레임으로 분리하거나, 필요에 따라 ‘넓은 형태’와 ‘긴 형태’ 중 선택적으로 결합한다.
패키지의 아키텍처는 고수준 함수와 저수준 유틸리티로 구분된다. `apiData(url)`는 URL만 입력하면 자동으로 파싱·매핑·데이터프레임 반환까지 수행한다. `apiDownload(url, destfile)`는 원시 데이터를 로컬에 저장하고, 캐시를 활용해 동일 요청을 재사용한다. `apiTable()`은 다중 API 호출 결과를 하나의 테이블로 병합한다. 저수준 함수인 `parseXML()`, `parseJSON()`, `flattenList()` 등은 사용자가 직접 파싱 과정을 제어하고 싶을 때 활용 가능하다.
논문은 실제 활용 사례를 통해 패키지의 유용성을 입증한다. 첫 번째 사례는 미국 연방정부 데이터 포털의 경제 지표 API를 이용해 연도별 GDP, 실업률, 인플레이션 데이터를 수집하고, 자동으로 데이터프레임에 정리하는 과정을 보여준다. 여기서는 페이지네이션(pagination) 처리와 오류 재시도 로직이 내장돼 있어, 수천 건의 요청을 안정적으로 수행한다. 두 번째 사례는 트위터 검색 API를 활용해 특정 키워드에 대한 트윗을 수집하고, 트윗 텍스트, 작성자, 시간, 리트윗 수 등을 평탄화한다. 복수의 JSON 배열이 중첩된 구조를 갖지만, `apiData()` 한 줄 호출만으로 깔끔한 테이블을 얻을 수 있다.
또한, 패키지는 오픈소스(GLP‑2, GLP‑3) 라이선스로 배포되며, Bitbucket 저장소와 `devtools::install_bitbucket()`을 통해 설치가 가능하다. 이는 연구 커뮤니티가 패키지를 자유롭게 확장·수정할 수 있게 하며, 다른 언어·플랫폼에서도 동일한 매핑 로직을 구현하도록 영감을 준다.
결론에서는 RWebData가 데이터 수집 비용을 크게 절감하고, 복잡한 중첩 데이터를 자동으로 평탄화함으로써 연구 재현성을 강화한다는 점을 강조한다. 특히, 빅 퍼블릭 데이터와 과학적 데이터 매시업을 촉진해 새로운 연구 질문을 탐색할 수 있는 기반을 제공한다. 향후 작업으로는 더 다양한 인증 방식(OAuth 등) 지원, 대용량 데이터 스트리밍 처리, 그리고 시각화·전처리 파이프라인과의 통합이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기