Deep Exploration via Bootstrapped DQN
Efficient exploration in complex environments remains a major challenge for reinforcement learning. We propose bootstrapped DQN, a simple algorithm that explores in a computationally and statistically efficient manner through use of randomized value …
Authors: Ian Osb, Charles Blundell, Alex
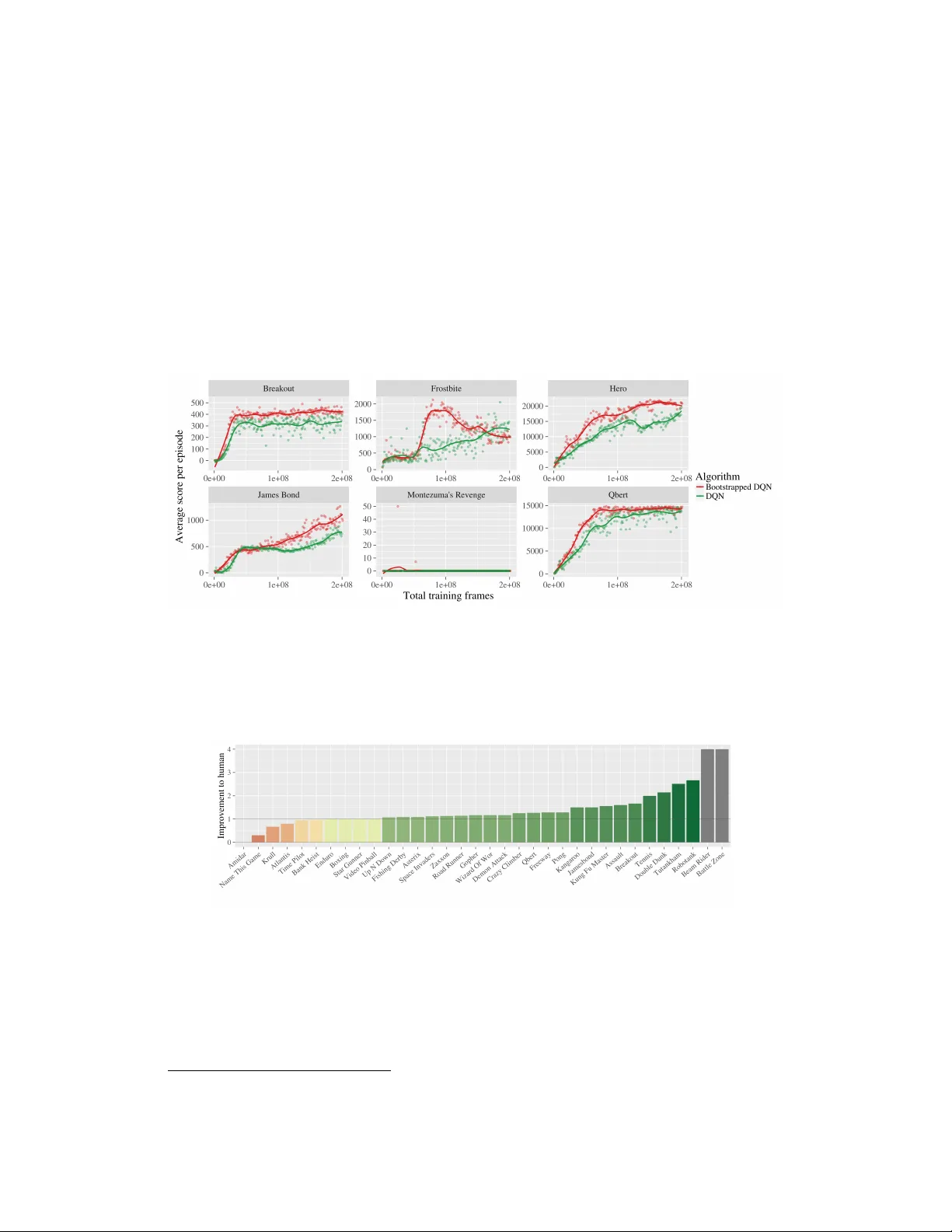
Deep Exploration via Bo otstrapp ed DQN Ian Osband 1 , 2 , Charles Blundell 2 , Alexander Pritzel 2 , Benjamin V an Ro y 1 1 Stanford Univ ersity , 2 Go ogle DeepMind {iosband, cblundell, apritzel}@google.com, bvr@stanford.edu Abstract Efficien t exploration remains a major challenge for reinforce ment learning (RL). Common dithering strategies for exploration, such as -greedy , do not carry out temp orally-extended (or deep) exploration; this can lead to exp onentially larger data requiremen ts. Ho w ev er, most algorithms for statistically efficien t RL are not computationally tractable in complex en- vironmen ts. Randomized v alue functions offer a promising approach to efficien t exploration with generalization, but existing algorithms are not compatible with nonlinearly parameterized v alue functions. As a first step to wards addressing such con texts we develop b o otstr app e d DQN . W e demon- strate that b o otstrapp ed DQN can combine deep exploration with deep neural net w orks for exp onen tially faster learning than any dithering strat- egy . In the Arcade Learning Environmen t b o otstrapp ed DQN substantially impro ves learning sp eed and cumulativ e p erformance across most games. 1 In tro duction W e study the reinforcement learning (RL) problem where an agent in teracts with an unknown en vironment. The agen t tak es a sequence of actions in order to maximize cum ulative rewards. Unlik e standard planning problems, an RL agen t do es not begin with p erfect kno wledge of the environmen t, but learns through exp erience. This leads to a fundamental trade-off of exploration versus exploitation; the agent may improv e its future rewards by exploring p o orly understoo d states and actions, but this ma y require sacrificing immediate rewards. T o learn efficiently an agent should explore only when there are v aluable learning opp ortunities. F urther, since any action may hav e long term consequences, the agent should reason ab out the informational v alue of possible observ ation sequences. Without this sort of temp orally extended (deep) exploration, learning times can w orsen by an exp onential factor. The theoretical RL literature offers a v ariety of prov ably-efficient approaches to deep explo- ration [ 9 ]. How ever, most of these are designed for Marko v decision pro cesses (MDPs) with small finite state spaces, while others require solving computationally in tractable planning tasks [ 8 ]. These algorithms are not practical in complex environmen ts where an agent must generalize to op erate effectively . F or this reason, large-scale applications of RL hav e relied up on statistically inefficient strategies for exploration [ 12 ] or even no exploration at all [ 23 ]. W e review related literature in more detail in Section 4. Common dithering strategies, suc h as -greedy , appro ximate the v alue of an action by a single n um b er. Most of the time they pick the action with the highest estimate, but sometimes they choose another action at random. In this pap er, we consider an alternative approac h to efficient exploration inspired b y Thompson sampling. These algorithms ha ve some notion of uncertaint y and instead maintain a distribution ov er p ossible v alues. They explore b y randomly select a p olicy according to the probability it is the optimal policy . Recen t w ork has sho wn that randomized v alue functions can implement something similar to Thompson sampling without the need for an in tractable exact p osterior up date. How ev er, this w ork is restricted to linearly-parameterized v alue functions [ 16 ]. W e present a natural extension of this approach that enables use of complex non-linear generalization metho ds suc h as deep neural netw orks. W e show that the b o otstrap with random initialization can pro duce reasonable uncertaint y estimates for neural net works at lo w computational cost. Bo otstrapp ed DQN leverages these uncertaint y estimates for efficient (and deep) exploration. W e demonstrate that these b enefits can extend to large scale problems that are not designed to highligh t deep exploration. Bo otstrapp ed DQN substantially reduces learning times and impro ves p erformance across most games. This algorithm is computationally efficient and parallelizable; on a single machine our implementation runs roughly 20 % slow er than DQN. 2 Uncertain t y for neural netw orks Deep neural netw orks (DNN) represen t the state of the art in many sup ervised and re- inforcemen t learning domains [ 12 ]. W e wan t an exploration strategy that is statistically computationally efficient together with a DNN representation of the v alue function. T o explore efficiently , the first step to quantify uncertaint y in v alue estimates so that the agent can judge p otential b enefits of exploratory actions. The neural netw ork literature presen ts a sizable b o dy of w ork on uncertaint y quantification founded on parametric Ba yesian inference [ 3 , 7 ]. W e actually found the simple non-parametric b o otstrap with random initialization [ 5 ] more effective in our exp eriments, but the main ideas of this pap er would apply with an y other approac h to uncertaint y in DNNs. The b o otstrap princple is to approximate a p opulation distribution by a sample distribution [ 6 ]. In its most common form, the b o otstrap takes as input a data set D and an estimator ψ . T o generate a sample from the b o otstrapp ed distribution, a data set ˜ D of cardinalit y equal to that of D is sampled uniformly with replacemen t from D . The b o otstrap sample estimate is then taken to b e ψ ( ˜ D ) . The b o otstrap is widely hailed as a great adv ance of 20th century applied statistics and even comes with theoretical guarantees [ 2 ]. In Figure 1a we present an efficient and scalable metho d for generating b o otstrap samples from a large and deep neural netw ork. The netw ork consists of a shared architecture with K b o otstrapp ed “heads” branc hing off indep enden tly . Each head is trained only on its b o otstrapp ed sub-sample of the data and represen ts a single b o otstrap sample ψ ( ˜ D ) . The shared netw ork learns a join t feature representation across all the data, which can provide significan t computational adv antages at the cost of low er div ersity betw een heads. This t yp e of b o otstrap can b e trained efficiently in a single forw ard/bac kward pass; it can b e thought of as a data-dep endent drop out, where the drop out mask for eac h head is fixed for each data p oint [19]. (a) Shared net work architecture (b) Gaussian pro cess p osterior (c) Bo otstrapp ed neural nets Figure 1: Bo otstrapp ed neural nets can pro duce reasonable p osterior estimates for regression. Figure 1 presents an example of uncertaint y estimates from b o otstrapp ed neural netw orks on a regression task with noisy data. W e trained a fully-connected 2-lay er neural netw orks with 50 rectified linear units (ReLU) in each lay er on 50 b o otstrapp ed samples from the data. As is standard, w e initialize these netw orks with random parameter v alues, this induces an imp ortan t initial diversit y in the mo dels. W e we re unable to generate effective uncertaint y estimates for this problem using the dropout approach in prior literature [ 7 ]. F urther details are pro vided in App endix A. 3 Bo otstrapp ed DQN F or a p olicy π w e define the v alue of an action a in state s Q π ( s, a ) := E s,a,π [ P ∞ t =1 γ t r t ] , where γ ∈ (0 , 1) is a discount factor that balances immediate v ersus future rewards r t . This exp ectation indicates that the initial state is s , the initial action is a , and thereafter actions 2 are selected b y the p olicy π . The optimal v alue is Q ∗ ( s, a ) := max π Q π ( s, a ) . T o scale to large problems, w e learn a parameterized estimate of the Q-v alue function Q ( s, a ; θ ) rather than a tabular enco ding. W e use a neural netw ork to estimate this v alue. The Q-learning up date from state s t , action a t , rew ard r t and new state s t +1 is giv en by θ t +1 ← θ t + α ( y Q t − Q ( s t , a t ; θ t )) ∇ θ Q ( s t , a t ; θ t ) (1) where α is the scalar learning rate and y Q t is the target v alue r t + γ max a Q ( s t +1 , a ; θ − ) . θ − are target net work parameters fixed θ − = θ t . Sev eral important mo difications to the Q-learning up date improv e stability for DQN [ 12 ]. First the algorithm learns from sampled transitions from an exp erience buffer, rather than learning fully online. Second the algorithm uses a target netw ork with parameters θ − that are copied from the learning netw ork θ − ← θ t only every τ time steps and then k ept fixed in b et ween up dates. Double DQN [25] mo difies the target y Q t and helps further 1 : y Q t ← r t + γ max a Q s t +1 , arg max a Q ( s t +1 , a ; θ t ); θ − . (2) Bo otstrapp ed DQN mo difies DQN to approximate a distribution o v er Q-v alues via the b o otstrap. At the start of each episo de, b o otstrapp ed DQN samples a single Q-v alue function from its approximate p osterior. The agent then follows the p olicy which is optimal for that sample for the duration of the episo de. This is a natural adaptation of the Thompson sampling heuristic to RL that allows for temp orally extended (or deep) exploration [ 21 , 13 ]. W e implemen t this algorithm efficiently by building up K ∈ N b o otstrapped estimates of the Q-v alue function in parallel as in Figure 1a. Importantly , eac h one of these v alue function function heads Q k ( s, a ; θ ) is trained against its own target netw ork Q k ( s, a ; θ − ) . This means that eac h Q 1 , .., Q K pro vide a temp orally extended (and consistent) estimate of the v alue uncertaint y via TD estimates. In order to k eep trac k of which data b elongs to whic h b o otstrap head w e store flags w 1 , .., w K ∈ { 0 , 1 } indicating whic h heads are privy to whic h data. W e appro ximate a b o otstrap sample by selecting k ∈ { 1 , .., K } uniformly at random and following Q k for the duration of that episo de. W e present a detailed algorithm for our implemen tation of b o otstrapp ed DQN in App endix B. 4 Related w ork The observ ation that temp orally extended exploration is necessary for efficient reinforcement learning is not new. F or any prior distribution o ver MDPs, the optimal exploration strategy is a v ailable through dynamic programming in the Bay esian b elief state space. How ev er, the exact solution is intractable even for very simple systems[ 8 ]. Many successful RL applications fo cus on generalization and planning but address exploration only via inefficient exploration [12] or ev en none at all [23]. How ever, such exploration strategies can b e highly inefficient. Man y exploration strategies are guided b y the principle of “optimism in the face of uncertain t y” (OFU). These algorithms add an exploration b onus to v alues of state-action pairs that ma y lead to useful learning and select actions to maximize these adjusted v alues. This approac h w as first proposed for finite-armed bandits [ 11 ], but the principle has b een extended successfully across bandits with generalization and tabular RL [ 9 ]. Except for particular deterministic contexts [ 27 ], OFU metho ds that lead to efficient RL in complex domains ha ve b een computationally intractable. The w ork of [ 20 ] aims to add an effective b onus through a v ariation of DQN. The resulting algorithm relies on a large num b er of hand-tuned parameters and is only suitable for application to deterministic problems. W e compare our results on A tari to theirs in App endix D and find that b o otstrapp ed DQN offers a significant impro vemen t ov er previous metho ds. P erhaps the oldest heuristic for balancing exploration with exploitation is given by Thompson sampling [ 24 ]. This bandit algorithm takes a single sample from the p osterior at ev ery time step and chooses the action which is optimal for that time step. T o apply the Thompson sampling principle to RL, an agent should sample a v alue function from its p osterior. Naiv e applications of Thompson sampling to RL which resample every timestep can b e extremely 1 In this pap er we use the DDQN up date for all DQN v arian ts unless explicitly stated. 3 inefficien t. The agen t m ust also commit to this sample for several time steps in order to ac hieve deep exploration [ 21 , 8 ]. The algorithm PSRL do es exactly this, with state of the art guaran tees [ 13 , 14 ]. Ho wev er, this algorithm still requires solving a single known MDP , whic h will usually b e intractable for large systems. Our new algorithm, b o otstrapp ed DQN, approximates this approach to exploration via randomized v alue functions sampled from an approximate p osterior. Recently , authors hav e prop osed the RLSVI algorithm which accomplishes this for linearly parameterized v alue functions. Surprisingly , RLSVI recov ers state of the art guarantees in the setting with tabular basis functions, but its p erformance is crucially dep endent up on a suitable linear represen tation of the v alue function [ 16 ]. W e extend these ideas to produce an algorithm that can sim ultaneously perform generalization and exploration with a flexible nonlinear v alue function representation. Our metho d is simple, general and compatible with almost all adv ances in deep RL at low computational cost and with few tuning parameters. 5 Deep Exploration Uncertain ty estimates allo w an agent to direct its exploration at p otentially informativ e states and actions. In bandits, this choice of directed exploration rather than dithering generally categorizes efficient algorithms. The story in RL is not as simple, directed exploration is not enough to guaran tee efficiency; the exploration must also b e deep. Deep exploration means exploration whic h is directed o v er m ultiple time steps; it can also b e called “planning to learn” or “far-sighted” exploration. Unlike bandit problems, which balance actions which are immediately rewarding or immediately informative, RL settings require planning ov er sev eral time steps [ 10 ]. F or exploitation, this means that an efficient agent m ust consider the future rewards ov er several time steps and not simply the my opic rewards. In exactly the same wa y , efficient exploration may require taking actions which are neither immediately rew arding, nor immediately informative. T o illustrate this distinction, consider a simple deterministic chain { s − 3 , .., s +3 } with three step horizon starting from state s 0 . This MDP is kno wn to the agent a priori, with deterministic actions “left” and “right” . All states hav e zero reward, except for the leftmost state s − 3 whic h has kno wn rew ard > 0 and the rightmost state s 3 whic h is unkno wn. In order to reac h either a rewarding state or an informative state within three steps from s 0 the agen t must plan a consisten t strategy o ver sev eral time steps. Figure 2 depicts the planning and lo ok ahead trees for several algorithmic approaches in this example MDP . The action “left” is gra y , the action “right” is black. Rew arding states are depicted as red, informative states as blue. Dashed lines indicate that the agen t can plan ahead for either rewards or information. Unlik e bandit algorithms, an RL agent can plan to exploit future rew ards. Only an RL agen t with deep exploration can plan to learn. (a) Bandit algorithm (b) RL+dithering (c) RL+shallow explore (d) RL+deep explore Figure 2: Planning, learning and exploration in RL. 4 5.1 T esting for deep exploration W e no w presen t a series of didactic computational experiments designed to highligh t the need for deep exploration. These environmen ts can b e describ ed by c hains of length N > 3 in Figure 3. Each episo de of interaction lasts N + 9 steps after which p oint the agen t resets to the initial state s 2 . These are to y problems intended to b e exp ository rather than entirely realistic. Balancing a well kno wn and mildly successful strategy v ersus an unknown, but p oten tially more rewarding, approach can emerge in many practical applications. Figure 3: Scalable environmen ts that requires deep exploration. These environmen ts may b e described by a finite tabular MDP . How ever, w e consider algorithms which interact with the MDP only through raw pixel features. W e consider t wo feature mappings φ 1hot ( s t ) := ( 1 { x = s t } ) and φ therm ( s t ) := ( 1 { x ≤ s t } ) in { 0 , 1 } N . W e present results for φ therm , which work ed better for all DQN v arian ts due to b etter generalization, but the difference was relativ ely small - see App endix C. Thompson DQN is the same as b o otstrapp ed DQN, but resamples ev ery timestep. Ensemble DQN uses the same arc hitecture as b o otstrapp ed DQN, but with an ensemble p olicy . W e sa y that the algorithm has successfully learned the optimal policy when it has successfully completed one hundred episo des with optimal reward of 10 . F or each chain length, we ran eac h learning algorithm for 2000 episo des across three seeds. W e plot the median time to learn in Figure 4, together with a conserv ativ e low er b ound of 99 + 2 N − 11 on the exp ected time to learn for an y shallow exploration strategy [ 16 ]. Only bo otstrapp ed DQN demonstrates a graceful scaling to long c hains which require deep exploration. Figure 4: Only Bo otstrapp ed DQN demonstrates deep exploration. 5.2 Ho w do es b o otstrapp ed DQN drive deep exploration? Bo otstrapp ed DQN explores in a manner similar to the pro v ably-efficient algorithm PSRL [ 13 ] but it uses a b o otstrapp ed neural netw ork to approximate a posterior sample for the v alue. Unlik e PSRL, b o otstrapp ed DQN directly samples a v alue function and so do es not require further planning steps. This algorithm is similar to RLSVI, which is also prov ably-efficient [ 16 ], but with a neural net w ork instead of linear v alue function and b o otstrap instead of Gaussian sampling. The analysis for the linear setting suggests that this nonlinear approac h will w ork well so long as the distribution { Q 1 , .., Q K } remains sto chastic al ly optimistic [ 16 ], or at least as spread out as the “correct” p osterior. Bo otstrapp ed DQN relies up on random initialization of the net work weigh ts as a prior to induce diversit y . Surprisingly , we found this initial diversit y was enough to maintain div erse generalization to new and unseen states for large and deep neural netw orks. This is effectiv e for our experimental setting, but will not w ork in all situations. In general it ma y be necessary to main tain some more rigorous notion of “prior”, p otentially through the use of artificial prior data to maintain diversit y [ 15 ]. One p oten tial explanation for the efficacy of simple random initialization is that unlike sup ervised learning or bandits, where all net w orks fit the same data, eac h of our Q k heads has a unique target net work. This, together with sto c hastic minibatc h and flexible nonlinear representations, means that ev en small differences at initialization ma y b ecome bigger as they refit to unique TD errors. 5 Bo otstrapp ed DQN do es not require that any single netw ork Q k is initialized to the correct p olicy of “right” at ev ery step, which would be exp onentially unlik ely for large chains N . F or the algorithm to be successful in this example we only require that the net w orks generalize in a diverse wa y to the actions they hav e never c hosen in the states they hav e not visited very often. Imagine that, in the example ab ov e, the netw ork has made it as far as state ˜ N < N , but nev er observed the action right a = 2 . As long as one head k imagines Q ( ˜ N , 2) > Q ( ˜ N , 2) then TD b o otstrapping can propagate this signal back to s = 1 through the target net work to drive deep exploration. The exp ected time for these estimates at n to propagate to at least one head gro ws gracefully in n , even for relatively small K , as our exp eriments sho w. W e expand up on this intuition with a video designed to highlight how b o otstrapp ed DQN demonstrates deep exploration https://youtu.be/e3KuV_d0EMk . W e present further ev aluation on a difficult sto chastic MDP in App endix C. 6 Arcade Learning Environmen t W e now ev aluate our algorithm across 49 Atari games on the Arcade Learning Environmen t [ 1 ]. Imp ortantly , and unlik e the experiments in Section 5, these domains are not sp ecifically designed to show case our algorithm. In fact, many A tari games are structured so that small rew ards alwa ys indicate part of an optimal p olicy . This may be crucial for the strong p erformance observed by dithering strategies 2 . W e find that exploration via b o otstrapp ed DQN pro duces significant gains versus -greedy in this setting. Bo otstrapp ed DQN reaches p eak p erformance roughly similar to DQN. How ev er, our impro v ed exploration mean w e reac h h uman p erformance on av erage 30% faster across all games. This translates to significantly impro ved cumulativ e rewards through learning. W e follow the setup of [ 25 ] for our netw ork architecture and b enchmark our p erformance against their algorithm. Our netw ork structure is identical to the con v olutional structure of DQN [ 12 ] except w e split 10 separate b o otstrap heads after the conv olutional lay er as p er Figure 1a. Recently , several authors hav e provided arc hitectural and algorithmic impro vemen ts to DDQN [ 26 , 18 ]. W e do not compare our results to these since their adv ances are orthogonal to our concern and could easily b e incorp orated to our b o otstrapp ed DQN design. F ull details of our exp erimental set up are av ailable in App endix D. 6.1 Implemen ting b o otstrapp ed DQN at scale W e now examine how to generate online b o otstrap samples for DQN in a computationally efficien t manner. W e fo cus on three k ey questions: ho w many heads do we need, how should w e pass gradients to the shared netw ork and how should w e bo otstrap data online? W e make significan t compromises in order to maintain computational cost comparable to DQN. Figure 5a presents the cumulativ e reward of bo otstrapp ed DQN on the game Breakout, for differen t num b er of heads K . More heads leads to faster learning, but even a small num b er of heads captures most of the b enefits of b o otstrapp ed DQN. W e choose K = 10 . (a) Number of b o otstrap heads K . (b) Probability of data sharing p . Figure 5: Examining the sensitivities of b o otstrapp ed DQN. The shared netw ork arc hitecture allows us to train this com bined net w ork via backpropagation. F eeding K net work heads to the shared con volutional netw ork effectiv ely increases the learning rate for this p ortion of the netw ork. In some games, this leads to premature and sub-optimal con vergence. W e found the b est final scores by normalizing the gradients by 1 /K , but this also leads to slo wer early learning. See App endix D for more details. 2 By con trast, imagine that the agent received a small immediate reward for dying; dithering strategies would be hop eless at solving this problem, just like Section 5. 6 T o implement an online b o otstrap we use an indep endent Bernoulli mask w 1 ,..,w K ∼ Ber ( p ) for each head in eac h episo de 3 . These flags are stored in the memory replay buffer and iden tify which heads are trained on which data. Ho w ev er, when trained using a shared minibatc h the algorithm will also require an effective 1 /p more iterations; this is undesirable computationally . Surprisingly , we found the algorithm p erformed similarly irresp ective of p and all outp erformed DQN, as shown in Figure 5b. This is strange and we discuss this phenomenon in App endix D. How ever, in light of this empirical observ ation for Atari, we c hose p =1 to sav e on minibatc h passes. As a result b o otstrapp ed DQN runs at similar computational sp eed to v anilla DQN on identical hardware 4 . 6.2 Efficien t exploration in A tari W e find that Bo otstrapp ed DQN driv es efficient exploration in sev eral Atari games. F or the same amount of game exp erience, b o otstrapp ed DQN generally outp erforms DQN with -greedy exploration. Figure 6 demonstrates this effect for a diverse selection of games. Figure 6: Bo otstrapp ed DQN drives more efficien t exploration. On games where DQN p erforms well, b o otstrapp ed DQN t ypically p erforms b etter. Bo ot- strapp ed DQN do es not reac h h uman performance on Amidar (DQN do es) but does on Beam Rider and Battle Zone (DQN do es not). T o summarize this improv emen t in learning time we consider the num b er of frames required to reac h human p erformance. If b o otstrapp ed DQN reac hes h uman p erformance in 1 /x frames of DQN we say it has impro ved b y x . Figure 7 sho ws that Bo otstrapp ed DQN typically reaches human p erformance significantly faster. Figure 7: Bo otstrapp ed DQN reaches h uman performance faster than DQN. On most games where DQN do es not reach human p erformance, b o otstrapped DQN do es not solve the problem by itself. On some challenging Atari games where deep exploration is conjectured to b e imp ortant [ 25 ] our results are not entirely successful, but still promising. In F rostbite, b o otstrapp ed DQN reaches the second lev el muc h faster than DQN but netw ork instabilities cause the p erformance to crash. In Montezuma’s Revenge, b o otstrapp ed DQN reac hes the first key after 20m frames (DQN nev er observes a reward ev en after 200m frames) but does not prop erly learn from this experience 5 . Our results suggest that impro ved exploration ma y help to solve these remaining games, but also highlight the imp ortance of other problems lik e netw ork instability , reward clipping and temp orally extended rewards. 3 p =0 . 5 is double-or-nothing b o otstrap [17], p =1 is ensem ble with no b o otstrapping at all. 4 Our implementation K =10 , p =1 ran with less than a 20 % increase on wall-time v ersus DQN. 5 An improv ed training metho d, such as prioritized repla y [18] may help solv e this problem. 7 6.3 Ov erall p erformance Bo otstrapp ed DQN is able to learn muc h faster than DQN. Figure 8 shows that bo otstrapp ed DQN also improv es up on the final score across most games. How ev er, the real b enefits to efficient exploration mean that b o otstrapp ed DQN outp erforms DQN by orders of magnitude in terms of the cumulative rewards through learning (Figure 9. In b oth figures w e normalize p erformance relativ e to a fully random p olicy . The most similar work to ours presents sev eral other approaches to improv ed exploration in Atari [ 20 ] they optimize for AUC-20, a normalized version of the cumulativ e returns after 20m frames. A ccording to their metric, a veraged across the 14 games they consider, we improv e up on b oth base DQN (0.29) and their b est metho d (0.37) to obtain 0.62 via b o otstrapped DQN. W e presen t these results together with results tables across all 49 games in App endix D.4. Figure 8: Bo otstrapp ed DQN typically impro v es up on the b est p olicy . Figure 9: Bo otstrapp ed DQN improv es cum ulative rew ards b y orders of magnitude. 6.4 Visualizing b o otstrapp ed DQN W e now presen t some more insigh t to how bo otstrapp ed DQN drives deep exploration in A tari. In eac h game, although each head Q 1 , .., Q 10 learns a high scoring p olicy , the p olicies they find are quite distinct. In the video https://youtu.be/Zm2KoT82O_M w e show the ev olution of these policies simultaneously for several games. Although each head p erforms well, they eac h follow a unique p olicy . By contrast, -greedy strategies are almost indistinguishable for small v alues of and totally ineffectual for larger v alues. W e b elieve that this deep exploration is k ey to improv ed learning, since diverse exp eriences allow for b etter generalization. Disregarding exploration, b o otstrapp ed DQN may b e b eneficial as a purely exploitative p olicy . W e can combine all the heads in to a single ensemble p olicy , for example by choosing the action with the most v otes across heads. This approac h migh t ha ve sev eral benefits. First, w e find that the ensemble p olicy can often outp erform any individual p olicy . Second, the distribution of votes across heads to give a measure of the uncertaint y in the optimal p olicy . Unlik e v anilla DQN, b ootstrapp ed DQN can know what it do esn’t know. In an application where executing a p o orly-understo o d action is dangerous this could b e crucial. In the video https://youtu.be/0jvEcC5JvGY w e visualize this ensemble p olicy across several games. W e find that the uncertaint y in this p olicy is surprisingly interpretable: all heads agree at clearly crucial decision p oin ts, but remain diverse at other less imp ortant steps. 7 Closing remarks In this pap er we present b o otstrapp ed DQN as an algorithm for efficient reinforcement learning in complex environmen ts. W e demonstrate that the b o otstrap can pro duce useful uncertain ty estimates for deep neural netw orks. Bo otstrapp ed DQN is computationally tractable and also naturally scalable to massive parallel systems. W e b eliev e that, b ey ond our sp ecific implementation, randomized v alue functions represent a promising alternative to dithering for exploration. Bo otstrapp ed DQN practically combines efficient generalization with exploration for complex nonlinear v alue functions. 8 References [1] Marc G Bellemare, Y av ar Naddaf, Joel V eness, and Mic hael Bowling. The arcade learning en vironment: An ev aluation platform for general agen ts. arXiv pr eprint arXiv:1207.4708 , 2012. [2] P eter J Bic kel and Da vid A F reedman. Some asymptotic theory for the b o otstrap. The A nnals of Statistics , pages 1196–1217, 1981. [3] Charles Blundell, Julien Cornebise, K oray Kavuk cuoglu, and Daan Wierstra. W eight uncertaint y in neural netw orks. ICML , 2015. [4] Christoph Dann and Emma Brunskill. Sample complexity of episodic fixed-horizon reinforcemen t learning. In A dvances in Neur al Information Pr o cessing Systems , pages 2800–2808, 2015. [5] Bradley Efron. The jackknife, the b o otstr ap and other r esampling plans , v olume 38. SIAM, 1982. [6] Bradley Efron and Robert J Tibshirani. A n intr oduction to the b o otstr ap . CRC press, 1994. [7] Y arin Gal and Zoubin Ghahramani. Drop out as a bay esian approximation: Representing mo del uncertain ty in deep learning. arXiv pr eprint arXiv:1506.02142 , 2015. [8] Arth ur Guez, David Silv er, and Peter Da y an. Efficien t bay es-adaptiv e reinforcemen t learning using sample-based searc h. In Advanc es in Neur al Information Pr o c essing Systems , pages 1025–1033, 2012. [9] Thomas Jaksch, Ronald Ortner, and P eter Auer. Near-optimal regret b ounds for reinforcement learning. Journal of Machine L e arning R ese ar ch , 11:1563–1600, 2010. [10] Sham Kakade. On the Sampl e Complexity of R einfor cement L earning . PhD thesis, Universit y College London, 2003. [11] T ze Leung Lai and Herb ert Robbins. Asymptotically efficient adaptive allo cation rules. A dvanc es in applie d mathematics , 6(1):4–22, 1985. [12] V olo dymyr et al. Mnih. Human-lev el control through deep reinforcement learning. Natur e , 518(7540):529–533, 2015. [13] Ian Osband, Daniel R usso, and Benjamin V an Roy . (More) efficient reinforcemen t learning via p osterior sampling. In NIPS , pages 3003–3011. Curran Asso ciates, Inc., 2013. [14] Ian Osband and Benjamin V an Roy . Mo del-based reinforcemen t learning and the eluder dimension. In A dvances in Neur al Information Pr o cessing Systems , pages 1466–1474, 2014. [15] Ian Osband and Benjamin V an Roy . Bo otstrapp ed thompson sampling and deep exploration. arXiv pr eprint arXiv:1507.00300 , 2015. [16] Ian Osband, Benjamin V an Ro y , and Zheng W en. Generalization and exploration via randomized v alue functions. arXiv pr eprint arXiv:1402.0635 , 2014. [17] Art B Owen, Dean Eckles, et al. Bo otstrapping data arrays of arbitrary order. The A nnals of Applie d Statistics , 6(3):895–927, 2012. [18] T om Schaul, John Quan, Ioannis Antonoglou, and David Silv er. Prioritized experience repla y . arXiv pr eprint arXiv:1511.05952 , 2015. [19] Nitish Sriv astav a, Geoffrey Hin ton, Alex Krizhevsky , Ilya Sutsk ev er, and Ruslan Salakh utdinov. Drop out: A simple wa y to prev ent neural net w orks from ov erfitting. The Journal of Machine L e arning R ese ar ch , 15(1):1929–1958, 2014. [20] Bradly C Stadie, Sergey Levine, and Pieter Abb eel. Incentivizing exploration in reinforcement learning with deep predictive models. arXiv pr eprint arXiv:1507.00814 , 2015. [21] Malcolm J. A. Strens. A bay esian framew ork for reinforcemen t learning. In ICML , pages 943–950, 2000. [22] Ric hard Sutton and Andrew Barto. R einfor c ement Le arning: A n Intr o duction . MIT Press, Marc h 1998. [23] Gerald T esauro. T emp oral difference learning and td-gammon. Communic ations of the A CM , 38(3):58–68, 1995. [24] W.R. Thompson. On the likelihoo d that one unknown probabilit y exceeds another in view of the evidence of tw o samples. Biometrika , 25(3/4):285–294, 1933. [25] Hado V an Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. arXiv preprint , 2015. [26] Ziyu W ang, Nando de F reitas, and Marc Lanctot. Dueling net work architectures for deep reinforcemen t learning. arXiv pr eprint arXiv:1511.06581 , 2015. [27] Zheng W en and Benjamin V an Roy . Efficient exploration and v alue function generalization in deterministic systems. In NIPS , pages 3021–3029, 2013. 9 APPENDICES A Uncertain t y for neural netw orks In this app endix we discuss some of the exp erimental setup to qualitatively ev aluate uncer- tain ty metho ds for deep neural netw orks. T o do this, we generated tw ent y noisy regression pairs x i , y i with: y i = x i + sin ( α ( x i + w i )) + sin ( β ( x i + w i )) + w i where x i are drawn uniformly from (0 , 0 . 6) ∪ (0 . 8 , 1) and w i ∼ N ( µ = 0 , σ 2 = 0 . 03 2 ) . W e set α = 4 and β = 13 . None of these numerical c hoices were imp ortant except to represen t a highly nonlinear function with lots of noise and sev eral clear regions where we should be uncertain. W e presen t the regression data together with an indication of the generating distribution in Figure 10. Figure 10: Underlying generating distribution. All our algorithms receiv e the same blue data. Pink p oin ts represent other samples, the mean function is shown in blac k. In terestingly , we did not find that using dropout pro duced satisfying confidence in terv als for this task. W e present one example of this drop out p osterior estimate in Figure 11a. (a) Drop out gives strange uncertaint y esti- mates. (b) Screenshot from accompan ying w eb demo to [ 7 ]. Dropout conv erges with high certain t y to the mean v alue. Figure 11: Comparing the b o otstrap to drop out uncertaint y for neural nets. These results are unsatisfactory for several reasons. First, the netw ork extrap olates the mean p osterior far outside the range of an y actual data for x = 0 . 75 . W e b elieve this is b ecause drop out only p erturbs lo cally from a single neural netw ork fit, unlike b o otstrap. Second, the p osterior samples from the drop out approximation are very spiky and do not lo ok like any sensible p osterior sample. Third, the netw ork collapses to almost zero uncertaint y in regions with data. W e spent some time altering our drop out sc heme to fix this effect, which migh t b e undesirable for stochastic domains and w e b elieved migh t be an artefact of our implemen tation. How ev er, 10 after further though t we b elieve this to b e an effect which you would exp ect for drop out p osterior approximations. In Figure 11b we present a didactic example tak en from the author’s w ebsite [7]. On the right hand side of the plot we generate noisy data with wildly different v alues. T raining a neural net work using MSE criterion means that the netw ork will surely conv erge to the mean of the noisy data. Any dropout samples remain highly concen trated around this mean. By contrast, b o otstrapp ed neural netw orks may include different subsets of this noisy data and so may produce a more intuitiv e uncertain t y estimates for our settings. Note this isn’t necessarily a failure of drop out to approximate a Gaussian pro cess p osterior, but this artefact could b e shared by any homosk edastic p osterior. The authors of [ 7 ] prop ose a heterosk edastic v ariant which can help, but do es not address the fundamental issue that for large netw orks trained to con vergence all drop out samples may conv erge to every single datap oin t... even the outliers. In this pap er we fo cus on the b o otstrap approach to uncertaint y for neural net works. W e lik e its simplicity , connections to established statistical methodology and empirical go o d p erformance. Ho w ev er, the key insigh ts of this pap er is the use of deep exploration via randomized v alue functions. This is compatible with any appro ximate p osterior estimator for deep neural netw orks. W e b elieve that this area of uncertain t y estimates for neural netw orks remains an imp ortan t area of research in its own right. Bo otstrapp ed uncertaint y estimates for the Q-v alue functions hav e another crucial adv antage o ver drop out whic h does not appear in the sup ervised problem. Unlik e random drop out masks trained against random target netw orks, our implementation of b o otstrap DQN trains against its own temp or al ly c onsistent target netw ork. This means that our b o otstrap estimates (in the sense of [ 5 ]), are able to “b o otstrap” (in the TD sense of [ 22 ]) on their own estimates of the long run v alue. This is imp ortant to quan tify the long run uncertaint y o v er Q and driv e deep exploration. B Bo otstrapp ed DQN implemen tation Algorithm 1 giv es a full description of Bo otstrapp ed DQN. It captures tw o modes of op eration where either k neural netw orks are used to estimate the Q k -v alue functions, or where one neural net work with k heads is used to estimate k Q -v alue functions. In b oth cases, as this is largely a parameterisation issue, we denote the v alue function netw orks as Q , where Q k is output of the k th netw ork or the k th head. A core idea to the full b o otstrapp ed DQN algorithm is the b o otstrap mask m t . The mask m t decides, for each v alue function Q k , whether or not it should train up on the exp erience generated at step t . In its simplest form m t is a binary v ector of length K , masking out or including eac h v alue function for training on that time step of exp erience (i.e., should it receive gradients from the corresp onding ( s t , a t , r t +1 , s t +1 , m t ) tuple). The masking distribution M is resp onsible for generating each m t . F or example, when M yields m t whose comp onents are indep enden tly drawn from a b ernoulli distribution with parameter 0 . 5 then this corresp onds to the double-or-nothing b o otstrap [ 17 ]. On the other hand, if M yields a mask m t with all ones, then the algorithm reduces to an ensemble metho d. Poisson masks M t [ k ] ∼ Poi (1) provides the most natural parallel with the standard non-parameteric b o ostrap since Bin ( N , 1 / N ) → Poi (1) as N → ∞ . Exp onential masks M t [ k ] ∼ Exp (1) closely resem ble the standard Bay esian nonparametric p osterior of a Dirichlet pro cess [15]. P erio dically , the replay buffer is play ed back to up date the parameters of the v alue function net work Q . The gradients of the k th v alue function Q k for the t th tuple in the repla y buffer B , g k t is: g k t = m k t ( y Q t − Q k ( s t , a t ; θ )) ∇ θ Q k ( s t , a t ; θ ) (3) where y Q t is given by (2) . Note that the mask m k t mo dulates the gradient, giving rise to the b o otstrap b eha viour. 11 Algorithm 1 Bo otstrapp ed DQN 1: Input: V alue function netw orks Q with K outputs { Q k } K k =1 . Masking distribution M . 2: Let B b e a repla y buffer storing exp erience for training. 3: for eac h episo de do 4: Obtain initial state from en vironment s 0 5: Pic k a v alue function to act using k ∼ Uniform { 1 , . . . , K } 6: for step t = 1 , . . . until end of episo de do 7: Pic k an action according to a t ∈ arg max a Q k ( s t , a ) 8: Receiv e state s t +1 and rew ard r t from en vironment, having taking action a t 9: Sample b o otstrap mask m t ∼ M 10: A dd ( s t , a t , r t +1 , s t +1 , m t ) to repla y buffer B 11: end for 12: end for C Exp erimen ts for deep exploration C.1 Bo otstrap metho dology A naive implementation of b o otstrapp ed DQN builds up K complete netw orks with K distinct memory buffers. This metho d is parallelizable up to many machines, how ever we w anted to produce an algorithm that was efficient even on a single mac hine. T o do this, w e implemented the b o otstrap heads in a single larger netw ork, lik e Figure 1a but without an y shared netw ork. W e implement b o otstrap b y masking each episo de of data according to w 1 , .., w K ∼ Ber( p ) . Figure 12: Bo otstrapp ed DQN performs well even with small num ber of b ootstrap heads K or high probabilit y of sharing p . In Figure 12 we demonstrate that b o otstrapp ed DQN can implement deep exploration even with relatively small v alues of K . How ever, the results are more robust and scalable with larger K . W e run our exp eriments on the example from Figure 3. Surprisingly , this metho d is ev en effective with p = 1 and complete data sharing b etw een heads. This degenerate full sharing of information turns out to b e remarkably efficient for training large and deep neural net works. W e discuss this phenomenon more in App endix D. Generating go o d estimates for uncertain ty is not enough for efficien t exploration. In Figure 13 w e see that other metho ds trained with the same net work arc hitecture are totally ineffective at implemen ting deep exploration. The -greedy policy follows just one Q -v alue estimate. W e allo w this p olicy to b e ev aluated without dithering. The ensemble p olicy is trained exactly as p er bo otstrapp ed DQN except at eac h stage the algorithm follo ws the p olicy whic h is ma jorit y vote of the b o otstrap heads. Thompson sampling is the same as b o otstrapp ed DQN except a new head is sampled ev ery timestep, rather than every episo de. W e can see that only b o otstrapp ed DQN demonstrates efficient and deep exploration in this domain. 12 Figure 13: Shallow exploration methods do not w ork. C.2 A difficult sto c hastic MDP Figure 4 shows that bo otstrapp ed DQN can implement effectiv e (and deep) exploration where similar deep RL architectures fail. How ever, since the underlying system is a small and finite MDP there ma y be several other simpler strategies which w ould also solve this problem. W e will now consider a difficult v arian t of this chain system with significant sto chastic noise in transitions as depicted in Figure 14. Action “left” deterministically mov es the agent left, but action “right” is only successful 50% of the time and otherwise also mo ves left. The agen t interacts with the MDP in episodes of length 15 and b egins eac h episo de at s 1 . Once again the optimal p olicy is to head righ t. Figure 14: A sto chastic MDP that requires deep exploration. Bo otstrapp ed DQN is unique amongst scalable approaches to efficient exploration with deep RL in sto chastic domains. F or benchmark p erformance w e implemen t three algorithms whic h, unlik e b o otstrapp ed DQN, will receive the true tabular representation for the MDP . These algorithms are based on three state of the art approac hes to exploration via dithering ( - greedy), optimism [ 9 ] and posterior sampling [ 13 ]. W e discuss the c hoice of these b enc hmarks in App endix C. (a) Bo otstrapp ed DQN matches efficien t tab- ular RL. (b) The regret b ounds for UCRL2 are near- optimal in ˜ O ( · ) , but they are still not very practical. Figure 15: Learning and regret b ounds on a sto chastic MDP . In Figure 15a we present the empirical regret of each algorithm av eraged o ver 10 seeds ov er the first tw o thousand episodes. The empirical regret is the cum ulativ e difference b etw een the exp ected rewards of the optimal p olicy and the realized rew ards of each algorithm. W e find that b o otstrapp ed DQN achiev es similar p erformance to state of the art efficient exploration sc hemes such as PSRL even without prior knowledge of the tabular MDP structure and in noisy en vironments. 13 Most telling is how m uch b etter b o otstrapp ed DQN do es than the state of the art optimistic algorithm UCRL2. Although Figure 15a seems to suggest UCRL2 incurs linear regret, actually it follows its b ounds ˜ O ( S √ AT ) [ 9 ] where S is the num b er of states and A is the n umber of actions. F or the example in Figure 14 we attempted to display our p erformance compared to several b enc hmark tabula rasa approac hes to exploration. There are many other algorithms we could hav e considered, but for a short pap er w e chose to fo cus against the most common approac h ( -greedy) the pre-eminent optimistic approach (UCRL2) and p osterior sampling (PSRL). Other common heuristic approac hes, such as optimistic initialization for Q-learning can b e tuned to work well on this domain, ho wev er the precise parameters are sensitiv e to the underlying MDP 6 . T o make a general-purp ose v ersion of this heuristic essentially leads to optimistic algorithms. Since UCRL2 is originally designed for infinite-horizon MDPs, we use the natural adaptation of this algorithm, which has state of the art guarantees in finite horizon MDPs as w ell [4]. Figure 15a displays the empirical regret of these algorithms together with bo otstrapp ed DQN on the example from Figure 14. It is somewhat disconcerting that UCRL2 app ears to incur linear regret, but it is prov en to satisfy near-optimal regret b ounds. Actually , as we show in Figure 15b, the algorithm pro duces regret which scales v ery similarly to its established b ounds [ 9 ]. Similarly , even for this tiny problem size, the recent analysis that prov es a near optimal sample complexity in fixed horizon problems [ 4 ] only guarantees that we will hav e few er than 10 10 = 1 suboptimal episo des. While these b ounds may b e acceptable in worst case ˜ O ( · ) scaling, they are not of m uch practical use. C.3 One-hot features In Figure 16 w e include the mean p erformance of bo otstrapp ed DQN with one-hot feature enco dings. W e found that, using these features, bo otstrapp ed DQN learned the optimal p olicy for most seeds, but was somewhat less robust than the thermometer enco ding. T wo out of ten seeds failed to learn the optimal p olicy within 2000 episo des, this is presented in Figure 16. Figure 16: Bo otstrapp ed DQN also p erforms well with one-hot features, but learning is less robust. D Exp erimen ts for Atari D.1 Exp erimen tal setup W e use the same 49 A tari games as [ 12 ] for our exp eriments. Eac h step of the agent corresp onds to four steps of the em ulator, where the same action is repeated, the rew ard v alues of the agents are clipp ed b etw een -1 and 1 for stability . W e ev aluate our agents and rep ort p erformance based up on the ra w scores. The conv olutional part of the netw ork used is identical to the one used in [ 12 ]. The input to the net w ork is 4x84x84 tensor with a rescaled, grayscale version of the last four observ ations. 6 F urther, it is difficult to extend the idea of optimistic initialization with function generalization, esp ecially for deep neural netw orks. 14 The first conv olutional (conv) la y er has 32 filters of size 8 with a stride of 4. The second conv la yer has 64 filters of size 4 with stride 2. The last conv la y er has 64 filters of size 3. W e split the netw ork beyond the final lay er into K = 10 distinct heads, each one is fully connected and iden tical to the single head of DQN [ 12 ]. This consists of a fully connected la yer to 512 units follo wed by another fully connected lay er to the Q-V alues for eac h action. The fully connected lay ers all use Rectified Linear Units(ReLU) as a non-linearity . W e normalize gradien ts 1 /K that flo w from eac h head. W e trained the netw orks with RMSProp with a momentum of 0.95 and a learning rate of 0.00025 as in [ 12 ]. The discount was set to γ = 0 . 99 , the num b er of steps betw een target up dates w as set to τ = 10000 steps. W e trained the agen ts for a total of 50m steps p er game, whic h corresp onds to 200m frames. The agents w ere every 1m frames, for ev aluation in b o otstrapp ed DQN we use an ensemble voting p olicy . The experience replay contains the 1m most recent transitions. W e up date the netw ork every 4 steps by randomly sampling a minibatc h of 32 transitions from the replay buffer to use the exact same minibatch schedule as DQN. F or training w e used an -greedy p olicy with b eing annealed linearly from 1 to 0 . 01 o ver the first 1m timesteps. D.2 Gradien t normalization in b o otstrap heads Most literature in deep RL for Atari fo cuses on learning the b est single ev aluation p olicy , with particular attention to whether this ab ov e or b elow human p erformance [ 12 ]. This is un usual for the RL literature, which typically fo cuses up on cumulativ e or final performance. Bo otstrapp ed DQN makes significant improv emen ts to the cum ulative rewards of DQN on A tari, as w e displa y in Figure 9, while the p eak p erformance is muc h more W e found that using bo otstrapp ed DQN without gradient normalization on each head t ypically learned even faster than our implementation with rescaling 1 /K , but it was somewhat prone to premature and sub optimal con vergence. W e present an example of this phenomenon in Figure 17. Figure 17: Normalization fights premature con v ergence. W e found that, in order to b etter the b enchmark “b est” p olicies rep orted by DQN, it was v ery helpful for us to use the gradien t normalization. How ev er, it is not en tirely clear whether this represents an impro vemen t for all settings. In Figures 18a and 18b we present the cum ulative rewards of the same algorithms on Beam Rider. Where an RL system is deplo yed to learn with real interactions, cum ulative rewards present a b etter measure for p erformance. In these settings the benefits of gradient normalization are less clear. Ho wev er, even with normalization 1 /K b o otstrapped DQN significantly outp erforms DQN in terms of cumulativ e rew ards. This is reflected most clearly in Figure 9 and T able 2. 15 (a) Normalization do es not help cum ulative rew ards. (b) Even o ver 200m frames the importance of exploration dominates the effects of an inferior final p olicy . Figure 18: Planning, learning and exploration in RL. D.3 Sharing data in b o otstrap heads In this setting all netw ork heads share all the data, so they are not actually a traditional b o otstrap at all. This is different from the regression task in Section 2, where bo otstrapp ed data w as essential to obtain meaningful uncertaint y estimates. W e hav e sev eral theories for wh y the net w orks main tain significan t diversit y even without data b o otstrapping in this setting. W e build up on the intuition of Section 5.2. First, they all train on different target net w orks. This means that even when facing the same ( s, a, r , s 0 ) datap oint this can still lead to drastically different Q-v alue up dates. Second, Atari is a deterministic environmen t, any transition observ ation is the unique correct datap oint for this setting. Third, the net works are deep and initialized from different random v alues so they will lik ely find quite diverse generalization even when they agree on given data. Finally , since all v ariants of DQN take many many frames to update their policy , it is likely that ev en using p = 0 . 5 they w ould still p opulate their replay memory with identical datap oints. This means using p = 1 to sav e on minibatch passes seems like a reasonable compromise and it do esn’t seem to negatively affect p erformance to o muc h in this setting. More research is needed to examine exactly where/when this data sharing is imp ortan t. D.4 Results tables In T able 1 the av erage score achiev ed by the agents during the most successful ev aluation p erio d, compared to human p erformance and a uniformly random p olicy . DQN is our implemen tation of DQN with the hyperparameters sp ecified ab ov e, using the double Q- Learning up date.[ 25 ]. W e find that p eak final performance is similar under b o otstrapp ed DQN to previous b enc hmarks. T o compare the b enefits of exploration via b o otstrapp ed DQN we benchmark our performance against the most similar prior work on incentivizing exploration in Atari [ 20 ]. T o do this, w e compute the AUC-100 measure sp ecified in this work. W e present these results in T able 2 compare to their b est p erforming strategy as well as their implementation of DQN. Imp ortan tly , b o otstrapp ed DQN outp erforms this prior work significantly . 16 Random Human Bo otstrapp ed DQN DDQN Nature Alien 227.8 7127.7 2436.6 4007.7 3069 Amidar 5.8 1719.5 1272.5 2138.3 739.5 Assault 222.4 742.0 8047.1 6997.9 3359 Asterix 210.0 8503.3 19713.2 17366.4 6012 Asteroids 719.1 47388.7 1032.0 1981.4 1629 A tlantis 12850.0 29028.1 994500.0 767850.0 85641 Bank Heist 14.2 753.1 1208.0 1109.0 429.7 Battle Zone 2360.0 37187.5 38666.7 34620.7 26300 Beam Rider 363.9 16926.5 23429.8 16650.7 6846 Bo wling 23.1 160.7 60.2 77.9 42.4 Bo xing 0.1 12.1 93.2 90.2 71.8 Break out 1.7 30.5 855.0 437.0 401.2 Cen tip ede 2090.9 12017.0 4553.5 4855.4 8309 Chopp er Command 811.0 7387.8 4100.0 5019.0 6687 Crazy Clim b er 10780.5 35829.4 137925.9 137244.4 114103 Demon A ttack 152.1 1971.0 82610.0 98450.0 9711 Double Dunk -18.6 -16.4 3.0 -1.8 -18.1 Enduro 0.0 860.5 1591.0 1496.7 301.8 Fishing Derb y -91.7 -38.7 26.0 19.8 -0.8 F reewa y 0.0 29.6 33.9 33.4 30.3 F rostbite 65.2 4334.7 2181.4 2766.8 328.3 Gopher 257.6 2412.5 17438.4 13815.9 8520 Gra vitar 173.0 3351.4 286.1 708.6 306.7 Hero 1027.0 30826.4 21021.3 20974.2 19950 Ice Ho c key -11.2 0.9 -1.3 -1.7 -1.6 Jamesb ond 29.0 302.8 1663.5 1120.2 576.7 Kangaro o 52.0 3035.0 14862.5 14717.6 6740 Krull 1598.0 2665.5 8627.9 9690.9 3805 Kung F u Master 258.5 22736.3 36733.3 36365.7 23270 Mon tezuma Revenge 0.0 4753.3 100.0 0.0 0 Ms P acman 307.3 6951.6 2983.3 3424.6 2311 Name This Game 2292.3 8049.0 11501.1 11744.4 7257 P ong -20.7 14.6 20.9 20.9 18.9 Priv ate Eye 24.9 69571.3 1812.5 158.4 1788 Qb ert 163.9 13455.0 15092.7 15209.7 10596 Riv erraid 1338.5 17118.0 12845.0 14555.1 8316 Road R unner 11.5 7845.0 51500.0 49518.4 18257 Rob otank 2.2 11.9 66.6 70.6 51.6 Seaquest 68.4 42054.7 9083.1 19183.9 5286 Space In v aders 148.0 1668.7 2893.0 4715.8 1976 Star Gunner 664.0 10250.0 55725.0 66091.2 57997 T ennis -23.8 -8.3 0.0 11.8 -2.5 Time Pilot 3568.0 5229.2 9079.4 10075.8 5947 T utankham 11.4 167.6 214.8 268.0 186.7 Up N Do wn 533.4 11693.2 26231.0 19743.5 8456 V enture 0.0 1187.5 212.5 239.7 380 Video Pin ball 0.0 17667.9 811610.0 685911.0 42684 Wizard Of W or 563.5 4756.5 6804.7 7655.7 3393 Zaxxon 32.5 9173.3 11491.7 12947.6 4977 T able 1: Maximal ev aluation Scores achiev ed b y agen ts W e now compare our metho d against the results in [ 20 ]. In this paper they introduce a new measure of p erformance called AUC-100, which is something similar to normalized cum ulative rew ards up to 20 million frames. T able 2 displays the results for our reference DQN and b o otstrapp ed DQN as Bo ot-DQN. W e repro duce their reference results for DQN 17 as DQN* and their b est p erforming algorithm, Dynamic AE. W e also present b o otstrapp ed DQN without head rescaling as Bo ot-DQN+. DQN* Dynamic AE DQN Bo ot-DQN Bo ot-DQN+ Alien 0.15 0.20 0.23 0.23 0.33 Asteroids 0.26 0.41 0.29 0.29 0.55 Bank Heist 0.07 0.15 0.06 0.09 0.77 Beam Rider 0.11 0.09 0.24 0.46 0.79 Bo wling 0.96 1.49 0.24 0.56 0.54 Break out 0.19 0.20 0.06 0.16 0.52 Enduro 0.52 0.49 1.68 1.85 1.72 F reewa y 0.21 0.21 0.58 0.68 0.81 F rostbite 0.57 0.97 0.99 1.12 0.98 Mon tezuma Revenge 0.00 0.00 0.00 0.00 0.00 P ong 0.52 0.56 -0.13 0.02 0.60 Qb ert 0.15 0.10 0.13 0.16 0.24 Seaquest 0.16 0.17 0.18 0.23 0.44 Space In v aders 0.20 0.18 0.25 0.30 0.38 A v erage 0.29 0.37 0.35 0.41 0.62 T able 2: AUC-100 for different agents compared to [20] W e see that, on a v erage, b oth bo otstrapp ed DQN implemen tations outp erform Dynamic AE, the b est algorithm from previous w ork. The only game in which Dynamic AE pro duces b est results is Bo wling, but this difference in Bowling is dominated by the implementation of DQN* vs DQN. Bo otstrapp ed DQN still gives ov er 100% improv emen t ov er its relev an t DQN baseline. Overall it is clear that Bo ot-DQN+ (b o otstrapp ed DQN without rescaling) p erforms b est in terms of AUC-100 metric. A veraged across the 14 games it is o ver 50% b etter than the next b est comp etitor, whic h is b o otstrapp ed DQN with gradient normalization. Ho wev er, in terms of p eak performance o v er 200m frames Bo ot-DQN generally reached higher scores. Bo ot-DQN+ sometimes plateaud early as in Figure 17. This highlights an imp ortant distinction b etw een ev aluation based on b est learned p olicy versus cumulativ e rewards, as w e discuss in App endix D.2. Bootstrapp ed DQN displa ys the biggest improv emen ts ov er DQN when doing w ell during learning is imp ortant. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment