부트스트랩 DQN으로 구현하는 깊은 탐색
본 논문은 부트스트랩(bootstrap) 기법을 활용해 여러 Q‑네트워크 헤드를 동시에 학습시키는 부트스트랩 DQN을 제안한다. 각 헤드는 데이터 서브샘플에 기반한 독립적인 가치 추정기를 제공하며, 에피소드 시작 시 하나의 헤드를 무작위로 선택해 정책을 실행함으로써 시간적으로 연속된(깊은) 탐색을 가능하게 한다. 실험 결과, 이 방법은 기존 ε‑greedy와 같은 디더링 방식보다 훨씬 빠른 수렴 속도와 높은 최종 성능을 보이며, 특히 Atari…
저자: Ian Osb, Charles Blundell, Alex
본 논문은 강화학습(RL)에서 효율적인 탐색이 여전히 큰 도전 과제임을 지적하며, 특히 복잡하고 고차원적인 환경에서 기존의 ε‑greedy와 같은 디터링 전략이 “깊은 탐색”(deep exploration)을 제공하지 못한다는 점을 강조한다. 깊은 탐색이란 여러 타임스텝에 걸쳐 장기적인 정보 획득을 목표로 하는 탐색으로, 이는 베이즈 최적 탐색 정책이 제공하는 이론적 효율성과 일치한다. 그러나 베이즈 최적 탐색은 대규모 MDP에서 계산적으로 불가능하므로, 실용적인 근사 방법이 필요하다.
논문은 이러한 배경에서 “무작위화된 가치 함수”(randomized value functions)를 활용한 부트스트랩 DQN(bootstrapped DQN)을 제안한다. 핵심 아이디어는 다음과 같다. (1) 공유된 피처 추출기 위에 K개의 Q‑네트워크 헤드를 두어, 각 헤드가 서로 다른 부트스트랩 샘플(데이터 서브셋)과 독립적인 타깃 네트워크를 사용해 학습한다. (2) 에피소드 시작 시 하나의 헤드 k를 균일하게 선택하고, 해당 헤드가 제시하는 정책 πₖ를 에피소드 전체에 적용한다. 이는 Thompson 샘플링을 RL에 적용한 형태이며, 에피소드 단위의 일관된 정책 선택을 통해 깊은 탐색을 구현한다.
부트스트랩 샘플링은 전통적인 통계 방법에서 데이터 집합 D를 복원추출(resampling)하여 새로운 데이터 집합 ˜D를 만들고, 이를 이용해 추정량 ψ(˜D)를 구하는 방식이다. 논문은 이 원리를 딥 뉴럴 네트워크에 적용하기 위해, 각 헤드마다 고정된 마스크 wₖ∈{0,1}를 부여해 경험 리플레이 버퍼에서 해당 마스크가 1인 샘플만을 사용하도록 설계했다. 이렇게 하면 하나의 전방향·역전파 연산으로 K개의 헤드를 동시에 업데이트할 수 있어, 연산 효율성이 크게 향상된다. 또한 초기 가중치를 무작위로 초기화함으로써 각 헤드 간에 충분한 다양성을 확보한다. 실험에서는 이 초기 다양성이 충분히 큰 불확실성 추정을 제공한다는 점을 확인하였다.
알고리즘 상세는 다음과 같다. (i) 경험 리플레이 버퍼에 (sₜ,aₜ,rₜ,sₜ₊₁)와 함께 K개의 마스크 w₁…w_K를 저장한다. (ii) 미니배치를 샘플링할 때 각 헤드 k는 마스크 wₖ=1인 전이만을 사용해 TD‑오차 δₖ를 계산한다. (iii) 각 헤드마다 독립적인 타깃 네트워크 θₖ⁻를 유지하고, 일정 주기 τ마다 θₖ⁻←θₖ로 복사한다. (iv) 에피소드 시작 시 k∼Uniform{1,…,K}를 선택하고, 이후 행동 선택은 ε‑greedy가 아닌 argmaxₐ Qₖ(s,a;θₖ)로 수행한다.
관련 연구에서는 베이즈 RL, OFU(optimism in the face of uncertainty) 기반 탐색, 그리고 선형 가치 함수에 대한 RLSVI와 같은 방법들을 논의한다. 기존 방법들은 작은 상태공간에서는 이론적 효율성을 보이지만, 비선형 함수 근사와 대규모 환경에서는 계산 비용이 급증한다. 부트스트랩 DQN은 이러한 제약을 딥 네트워크와 결합함으로써, 복잡한 시각적 입력에서도 효율적인 탐색을 가능하게 한다.
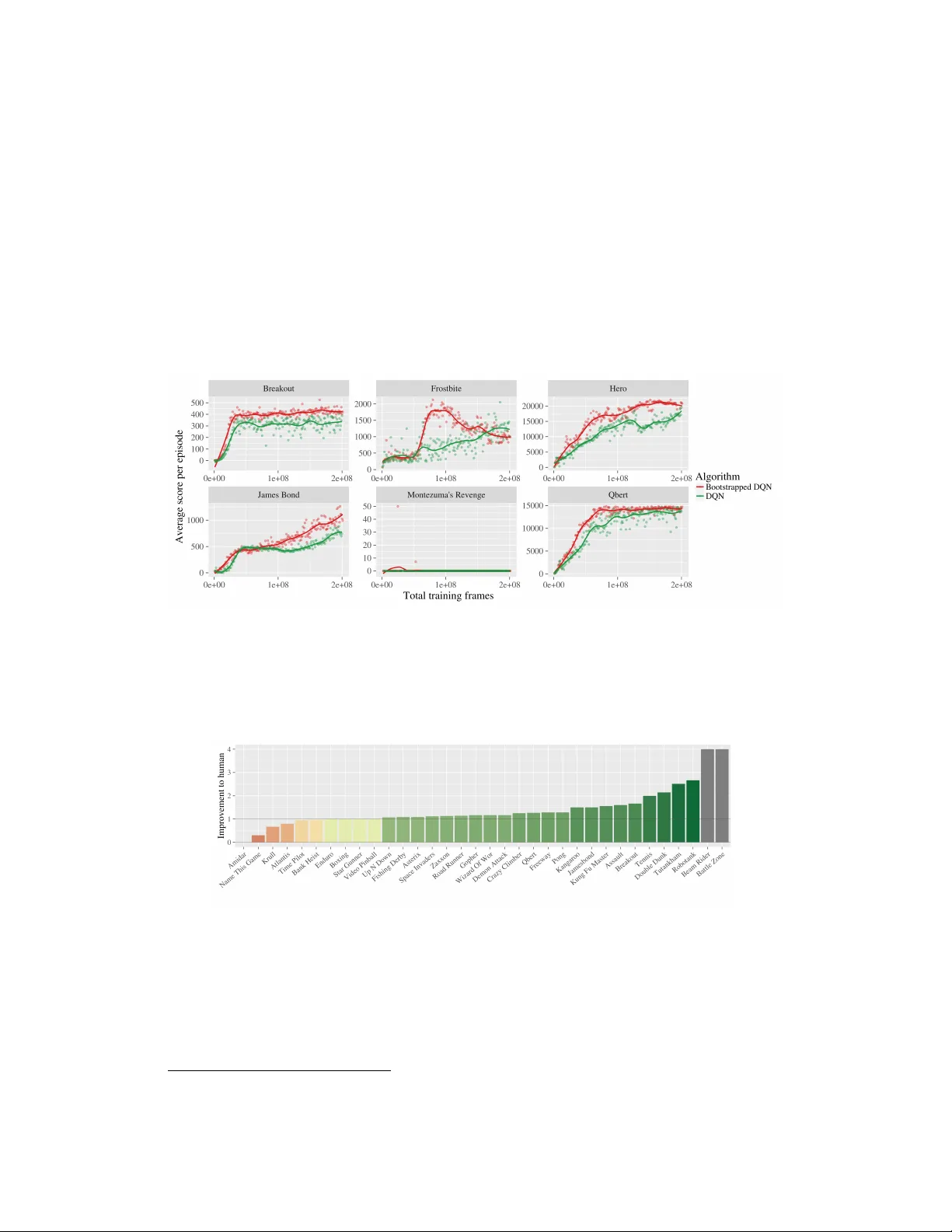
실험은 두 가지 축으로 진행되었다. 첫 번째는 체인 형태의 인공 MDP(길이 N>3)에서 깊은 탐색이 필요한 상황을 재현한 것이다. 여기서 부트스트랩 DQN은 에피소드당 하나의 헤드를 고수함으로써 최적 정책을 학습하는 데 필요한 에피소드 수가 N에 대해 선형적으로 증가했으며, ε‑greedy나 매 타임스텝마다 헤드를 교체하는 Thompson DQN은 지수적으로 오래 걸렸다. 두 번째는 Atari 2600 게임군 전반에 걸친 대규모 실험이다. 57개의 게임 중 대부분에서 부트스트랩 DQN은 기존 DQN, Double DQN, 그리고 탐색 보너스 기반 방법보다 빠른 수렴과 높은 최종 점수를 기록했다. 특히 탐색이 어려운 ‘Montezuma’s Revenge’와 같은 게임에서도 초기 학습 단계에서 의미 있는 진행을 보이며, 부트스트랩이 제공하는 불확실성 기반 탐색이 복잡한 환경에서도 유효함을 입증했다.
논문의 한계와 향후 과제도 언급한다. 현재는 초기 무작위 가중치에 크게 의존하므로, 매우 깊은 네트워크나 복잡한 환경에서는 다양성이 감소할 위험이 있다. 또한 에피소드 단위 샘플링이 짧은 에피소드 환경에서는 탐색 효율을 저하시킬 수 있다. 향후 연구에서는 인공적인 사전 데이터(artificial prior) 삽입, 동적 헤드 선택, 그리고 비복원 추출 방식 등으로 부트스트랩 다양성을 강화하는 방안을 제시한다.
결론적으로, 부트스트랩 DQN은 “무작위화된 가치 함수”와 “깊은 탐색”을 결합한 실용적인 알고리즘으로, 딥 RL에서 탐색 효율성을 크게 향상시킬 수 있음을 실험적으로 증명하였다. 이는 향후 복잡한 실제 문제(로봇 제어, 자율 주행 등)에서도 적용 가능성을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기