Character-based Neural Machine Translation
Neural Machine Translation (MT) has reached state-of-the-art results. However, one of the main challenges that neural MT still faces is dealing with very large vocabularies and morphologically rich languages. In this paper, we propose a neural MT sys…
Authors: Marta R. Costa-Juss`a, Jose A. R. Fonollosa
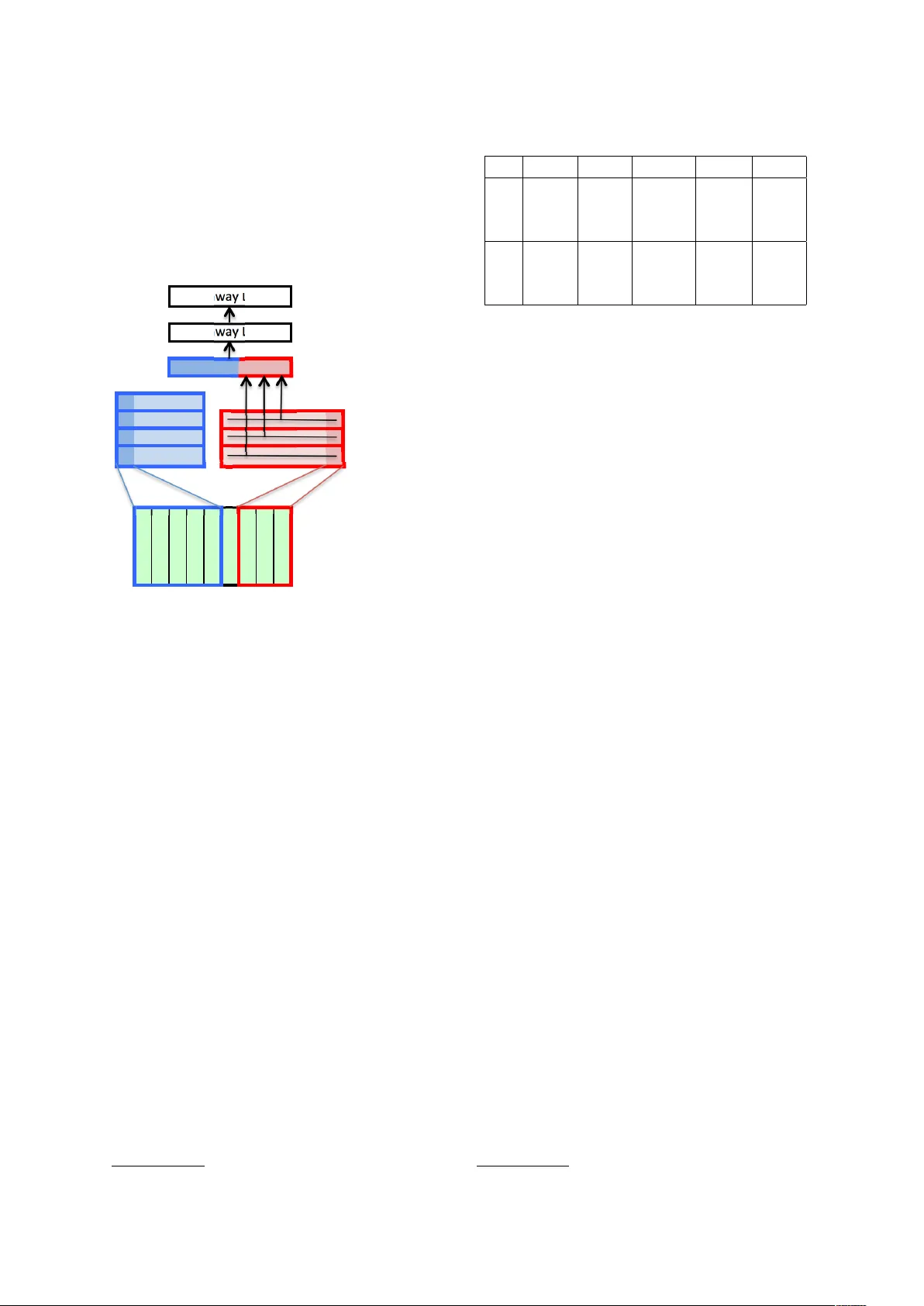
Character -based Neural Machine T ranslation Marta R. Costa-juss ` a and Jos ´ e A. R. F onollosa T ALP Research Center Uni versitat Polit ` ecnica de Catalunya, Barcelona { marta.ruiz,jose.fonollosa } @upc.edu Abstract Neural Machine T ranslation (MT) has reached state-of-the-art results. Ho we ver , one of the main challenges that neural MT still faces is dealing with v ery large v o- cabularies and morphologically rich lan- guages. In this paper , we propose a neural MT system using character-based embeddings in combination with con volutional and highway layers to replace the standard lookup-based word representations. The resulting unlimited-vocabulary and affix- aw are source word embeddings are tested in a state-of-the-art neural MT based on an attention-based bidirectional recurrent neural netw ork. The proposed MT scheme provides improv ed results ev en when the source language is not morphologically rich. Improv ements up to 3 BLEU points are obtained in the German-English WMT task. 1 Introduction Machine T ranslation (MT) is the set of algorithms that aim at transforming a source language into a tar get language. For the last 20 years, one of the most popular approaches has been statistical phrase-based MT , which uses a combination of features to maximise the probability of the tar - get sentence given the source sentence (Koehn et al., 2003). Just recently , the neural MT approach has appeared (Kalchbrenner and Blunsom, 2013; Sutske ver et al., 2014; Cho et al., 2014; Bahdanau et al., 2015) and obtained state-of-the-art results. Among its dif ferent strengths neural MT does not need to pre-design feature functions before- hand; optimizes the entire system at once because it provides a fully trainable model; uses word em- beddings (Sutske ver et al., 2014) so that w ords (or minimal units) are not independent anymore; and is easily extendable to multimodal sources of in- formation (Elliott et al., 2015). As for weaknesses, neural MT has a strong limitation in vocab ulary due to its architecture and it is difficult and com- putationally expensi ve to tune all parameters in the deep learning structure. In this paper , we use the neural MT baseline system from (Bahdanau et al., 2015), which fol- lo ws an encoder-decoder architecture with atten- tion, and introduce elements from the character - based neural language model (Kim et al., 2016). The translation unit continues to be the word, and we continue using word embeddings related to each word as an input vector to the bidirectional recurrent neural network (attention-based mecha- nism). The dif ference is that now the embeddings of each word are no longer an independent vec- tor , but are computed from the characters of the corresponding word. The system architecture has changed in that we are using a con volutional neu- ral network (CNN) and a highway network o ver characters before the attention-based mechanism of the encoder . This is a significant difference from pre vious work (Sennrich et al., 2015) which uses the neural MT architecture from (Bahdanau et al., 2015) without modification to deal with sub- word units (b ut not including unigram characters). Subword-based representations hav e already been explored in Natural Language Process- ing (NLP), e.g. for POS tagging (Santos and Zadrozny , 2014), name entity recognition (San- tos and aes, 2015), parsing (Ballesteros et al., 2015), normalization (Chrupala, 2014) or learning word representations (Botha and Blunsom, 2014; Chen et al., 2015). These previous works sho w dif ferent advantages of using character-le vel in- formation. In our case, with the ne w character- based neural MT architecture, we take advantage of intra-word information, which is proven to be extremely useful in other NLP applications (San- tos and Zadrozny , 2014; Ling et al., 2015a), es- pecially when dealing with morphologically rich languages. When using the character-based source word embeddings in MT , there ceases to be un- kno wn words in the source input, while the size of the target vocab ulary remains unchanged. Al- though the target vocabulary continues with the same limitation as in the standard neural MT sys- tem, the fact that there are no unknown words in the source helps to reduce the number of un- kno wns in the tar get. Moreover , the remaining un- kno wn tar get words can no w be more successfully replaced with the corresponding source-aligned words. As a consequence, we obtain a significant improv ement in terms of translation quality (up to 3 BLEU points). The rest of the paper is organized as follo ws. Section 2 briefly explains the architecture of the neural MT that we are using as a baseline sys- tem. Section 3 describes the changes introduced in the baseline architecture in order to use character - based embeddings instead of the standard lookup- based word representations. Section 4 reports the experimental framew ork and the results obtained in the German-English WMT task. Finally , sec- tion 5 concludes with the contributions of the pa- per and further work. 2 Neural Machine T ranslation Neural MT uses a neural network approach to compute the conditional probability of the tar - get sentence giv en the source sentence (Cho et al., 2014; Bahdanau et al., 2015). The approach used in this work (Bahdanau et al., 2015) fol- lo ws the encoder-decoder architecture.First, the encoder reads the source sentence s = ( s 1 , ..s I ) and encodes it into a sequence of hidden states h = ( h 1 , ..h I ) . Then, the decoder generates a corresponding translation t = t 1 , ..., t J based on the encoded sequence of hidden states h . Both en- coder and decoder are jointly trained to maximize the conditional log-probability of the correct trans- lation. This baseline autoencoder architecture is im- prov ed with a attention-based mechanism (Bah- danau et al., 2015), in which the encoder uses a bi-directional gated recurrent unit (GRU). This GR U allows for a better performance with long sentences. The decoder also becomes a GR U and each word t j is predicted based on a recurrent hid- den state, the previously predicted word t j − 1 , and a context vector . This context vector is obtained from the weighted sum of the annotations h k , which in turn, is computed through an alignment model α j k (a feedforward neural network). This neural MT approach has achie ved competiti ve re- sults against the standard phrase-based system in the WMT 2015 e v aluation (Jean et al., 2015). 3 Character -based Machine T ranslation W ord embeddings have been shown to boost the performance in many NLP tasks, including ma- chine translation. Howe ver , the standard lookup- based embeddings are limited to a finite-size vo- cabulary for both computational and sparsity rea- sons. Moreo ver , the orthographic representation of the words is completely ignored. The standard learning process is blind to the presence of stems, prefixes, suffix es and any other kind of af fixes in words. As a solution to those drawbacks, ne w alterna- ti ve character-based word embeddings hav e been recently proposed for tasks such as language mod- eling (Kim et al., 2016; Ling et al., 2015a), pars- ing (Ballesteros et al., 2015) or POS tagging (Ling et al., 2015a; Santos and Zadrozny , 2014). Even in MT (Ling et al., 2015b), where authors use the character transformation presented in (Ballesteros et al., 2015; Ling et al., 2015a) both in the source and tar get. Ho wev er, they do not seem to get clear improv ements. Recently , (Luong and Manning, 2016) propose a combination of w ord and char- acters in neural MT . For our experiments in neural MT , we selected the best character-based embedding architecture proposed by Kim et al. (Kim et al., 2016) for lan- guage modeling. As the Figure 1 shows, the com- putation of the representation of each word starts with a character-based embedding layer that as- sociates each word (sequence of characters) with a sequence of vectors. This sequence of vectors is then processed with a set of 1D con volution filters of different lengths (from 1 to 7 charac- ters) follo wed with a max pooling layer . For each con volutional filter , we keep only the output with the maximum v alue. The concatenation of these max values already provides us with a representa- tion of each word as a vector with a fixed length equal to the total number of con volutional ker - nels. Howe ver , the addition of two highway layers was shown to improve the quality of the language model in (Kim et al., 2016) so we also kept these additional layers in our case. The output of the second Highway layer will gi ve us the final vec- tor representation of each source word, replacing the standard source word embedding in the neural machine translation system. ! " # $ % & ' ( ) *)+,)$-)./0. -1&"&-2)". )3')!!#$45 6,(2#7(). -/$8/(,2#/$. 0#(2)"5./0.!#00)")$2 . ()$4125 6&9./,27,2./0. )&-1.0#(2)" :#41;&<.=&<)" :#41 ; &< . =&<)" :#41;&<.=&<)"5 Figure 1: Character -based word embedding In the target size we are still limited in vocab u- lary by the softmax layer at the output of the net- work and we kept the standard target word em- beddings in our experiments. Howe ver , the results seem to show that the affix-a ware representation of the source words has a positi ve influence on all the components of the network. The global optimiza- tion of the integrated model forces the translation model and the internal vector representation of the target w ords to follow the af fix-aware codification of the source words. 4 Experimental framework This section reports the data used, its preprocess- ing, baseline details and results with the enhanced character-based neural MT system. 4.1 Data W e used the German-English WMT data 1 includ- ing the EPPS, NEWS and Commoncrawl. Pre- processing consisted of tokenizing, truecasing, normalizing punctuation and filtering sentences with more than 5% of their w ords in a language 1 http://www .statmt.org/wmt15/translation-task.html other than German or English. Statistics are shown in T able 1. L Set S W V OO V De T rain 3.5M 77.7M 1.6M - De v 3k 63.1k 13.6k 1.7k T est 2.2k 44.1k 9.8k 1.3k En T rain 3.5M 81.2M 0.8M - De v 3k 67.6k 10.1k 0.8k T est 2.2k 46.8k 7.8k 0.6k T able 1: Corpus details. Number of sentences (S), words (W), vocab ulary (V) and out-of-vocab ulary- words (OO V) per set and language (L). M standing for millions, k standing for thousands. 4.2 Baseline systems The phrase-based system w as b uilt using Moses (K oehn et al., 2007), with standard parameters such as grow-final-diag for alignment, Good- T uring smoothing of the relativ e frequencies, 5- gram language modeling using Kneser -Ney dis- counting, and lexicalized reordering, among oth- ers. The neural-based system was built using the software from DL4MT 2 av ailable in github . W e generally used settings from pre vious work (Jean et al., 2015): networks hav e an embedding of 620 and a dimension of 1024, a batch size of 32, and no dropout. W e used a vocabulary size of 90 thou- sand w ords in German-English. Also, as proposed in (Jean et al., 2015) we replaced unkno wn words (UNKs) with the corresponding source word using the alignment information. 4.3 Results T able 3 shows the BLEU results for the baseline systems (including phrase and neural-based, NN) and the character-based neural MT (CHAR). W e also include the results for the CHAR and NN systems with post-processing of unknown words, which consists in replacing the UNKs with the cor- responding source word (+Src), as suggested in (Jean et al., 2015). BLEU results improve by al- most 1.5 points in German-to-English and by more than 3 points in English-to-German. The reduction in the number of unknown words (after postpro- cessing) goes from 1491 (NN) to 1260 (CHAR) in the direction from German-to-English and from 3148 to 2640 in the opposite direction. Note the 2 http://dl4mt.computing.dcu.ie/ 1 SRC Berichten zufolge hofft Indien darber hinaus auf einen V ertrag zur V erteidigungszusammenarbeit zwischen den beiden Nationen . Phrase reportedly hopes India , in addition to a contract for the defence cooperation between the two nations . NN according to reports , India also hopes to establish a contract for the UNK between the two nations . CHAR according to reports , India hopes to see a Treaty of Defence Cooperation between the tw o nations . REF India is also reportedly hoping for a deal on defence collaboration between the two nations . 2 SRC der durchtrainierte Mainzer sagt von sich , dass er ein “ ambitionierter Rennradler “ ist . Phrase the will of Mainz says that he a more ambitious . NN the UNK Mainz says that he is a “ ambitious , . “ CHAR the UNK in Mainz says that he is a ’ ambitious racer ’ . REF the well-conditioned man from Mainz said he was an “ ambitious racing cyclist . “ 3 SRC die GDL habe jedoch nicht gesagt , wo sie streiken wolle , so dass es schwer sei , die F olgen konkret vorherzusehen . Phrase the GDL have , ho wever , not to say , where they strik e , so that it is difficult to predict the consequences of concrete . NN howe ver , the UNK did not tell which they wanted to UNK , so it is dif ficult to predict the consequences . CHAR howe ver , the UNK did not say where they wanted to strike , so it is dif ficult to predict the consequences . REF the GDL have not said , ho wever , where the y will strike , making it difficult to predict e xactly what the consequences will be . 4 SRC die Premierminister Indiens und Japans trafen sich in T okio . Phrase the Prime Minister of India and Japan in T okyo . NN the Prime Minister of India and Japan met in T okyo CHAR the Prime Ministers of India and Japan met in T okyo REF India and Japan prime ministers meet in T okyo 5 SRC wo die Beamten es aus den Augen verloren . Phrase where the officials lost sight of NN where the officials lost it out of the e yes CHAR where officials lose sight of it REF causing the officers to lose sight of it T able 2: T ranslation examples. De- > En En- > De Phrase 20.99 17.04 NN 18.83 16.47 NN+Src 20.64 17.15 CHAR 21.40 19.53 CHAR+Src 22.10 20.22 T able 3: De-En BLEU results. number of out-of-vocabulary words of the test set is sho wn in T able 1. The character-based embedding has an impact in learning a better translation model at various le vels, which seems to include better alignment, reordering, morphological generation and disam- biguation. T able 2 shows some examples of the kind of improvements that the character-based neural MT system is capable of achieving com- pared to baseline systems. Examples 1 and 2 sho w ho w the reduction of source unknowns improves the adequacy of the translation. Examples 3 and 4 sho w ho w the character-based approach is able to handle morphological v ariations. Finally , e xample 5 sho ws an appropriate semantic disambiguation. 5 Conclusions Neural MT of fers a ne w perspectiv e in the way MT is managed. Its main adv antages when com- pared with pre vious approaches, e.g. statistical phrase-based, are that the translation is faced with trainable features and optimized in an end-to-end scheme. Ho we ver , there still remain man y chal- lenges left to solv e, such as dealing with the limi- tation in vocab ulary size. In this paper we hav e proposed a modification to the standard encoder/decoder neural MT architec- ture to use unlimited-vocab ulary character-based source word embeddings. The improv ement in BLEU is about 1.5 points in German-to-English and more than 3 points in English-to-German. As further work, we are currently studying dif- ferent alternatives (Chung et al., 2016) to extend the character -based approach to the target side of the neural MT system. Acknowledgements This work is supported by the 7th Frame work Pro- gram of the European Commission through the In- ternational Outgoing Fello wship Marie Curie Ac- tion (IMT raP-2011-29951) and also by the Span- ish Ministerio de Econom ´ ıa y Competitividad and European Regional Developmend Fund, contract TEC2015-69266-P (MINECO/FEDER, UE). References [Bahdanau et al.2015] Dimitry Bahdanau, Kyunghyun Cho, and Y oshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. CoRR , abs/1409.0473. [Ballesteros et al.2015] Miguel Ballesteros, Chris Dyer , and Noah A. Smith. 2015. Improved transition- based parsing by modeling characters instead of words with lstms. In Pr oceedings of the 2015 Confer ence on Empirical Methods in Natur al Lan- guage Pr ocessing , pages 349–359, Lisbon, Portug al, September . Association for Computational Linguis- tics. [Botha and Blunsom2014] Jan A. Botha and Phil Blun- som. 2014. Compositional Morphology for W ord Representations and Language Modelling. In Pr o- ceedings of the 31st International Confer ence on Machine Learning (ICML) , Beijing, China, jun. *A ward for best application paper*. [Chen et al.2015] Xinxiong Chen, Lei Xu, Zhiyuan Liu, Maosong Sun, and Huan-Bo Luan. 2015. Joint learning of character and word embeddings. In Qiang Y ang and Michael W ooldridge, editors, IJ- CAI , pages 1236–1242. AAAI Press. [Cho et al.2014] Kyunghyun Cho, Bart van v an Mer- rienboer , Dzmitry Bahdanau, and Y oshua Bengio. 2014. On the properties of neural machine trans- lation: Encoder–decoder approaches. In Pr oc. of the Eighth W orkshop on Syntax, Semantics and Struc- tur e in Statistical T ranslation , Doha. [Chrupala2014] Grzegorz Chrupala. 2014. Normaliz- ing tweets with edit scripts and recurrent neural em- beddings. In Pr oceedings of the 52nd Annual Meet- ing of the Association for Computational Linguis- tics, A CL 2014, J une 22-27, 2014, Baltimor e, MD, USA, V olume 2: Short P apers , pages 680–686. [Chung et al.2016] Junyoung Chung, K yunghyun Cho, and Y oshua Bengio. 2016. A character-le vel de- coder without explicit segmentation for neural ma- chine translation. CoRR , abs/1603.06147. [Elliott et al.2015] Desmond Elliott, Stella Frank, and Eva Hasler . 2015. Multi-language image de- scription with neural sequence models. CoRR , abs/1510.04709. [Jean et al.2015] Sebastien Jean, Orhan Firat, Kyunghun Cho, Roland Memisevic, and Y oshua Bengio. 2015. Montreal neural machine translation systems for wmt15. In Pr oc. of the 10th W orkshop on Statistical Machine T ranslation , Lisbon. [Kalchbrenner and Blunsom2013] Nal Kalchbrenner and Phil Blunsom. 2013. Recurrent continuous translation models. In Proc. of the Confer ence on Empirical Methods in Natur al Languag e Pr ocessing , Seattle. [Kim et al.2016] Y oon Kim, Y acine Jernite, Da vid Son- tag, and Alexander M. Rush. 2016. Character- aware neural language models. In Pr oceedings of the 30th AAAI Confer ence on Artificial Intelligence (AAAI’16) . [K oehn et al.2003] Philipp K oehn, Franz Joseph Och, and Daniel Marcu. 2003. Statistical Phrase-Based T ranslation. In Pr oc. of the 41th Annual Meeting of the Association for Computational Linguistics . [K oehn et al.2007] Philipp K oehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicolas Bertoldi, Brooke Cow an, W ade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondrej Bojar , Ale xandra Constantin, and Evan Herbst. 2007. Moses: Open Source T oolkit for Statistical Machine T ranslation. In Pr oc. of the 45th Annual Meeting of the Association for Computational Linguistics , pages 177–180. [Ling et al.2015a] W ang Ling, Chris Dyer, Alan W Black, Isabel T rancoso, Ramon Fermandez, Silvio Amir , Luis Marujo, and T iago Luis. 2015a. Finding function in form: Compositional character models for open vocab ulary w ord representation. In Pr o- ceedings of the 2015 Conference on Empirical Meth- ods in Natural Languag e Processing , pages 1520– 1530, Lisbon, Portugal, September . Association for Computational Linguistics. [Ling et al.2015b] W ang Ling, Isabel T rancoso, Chris Dyer , and Alan W . Black. 2015b. Character-based neural machine translation. CoRR , abs/1511.04586. [Luong and Manning2016] Minh-Thang Luong and Christopher D. Manning. 2016. Achie ving open vocab ulary neural machine translation with hybrid word-character models. In Association for Com- putational Linguistics (ACL) , Berlin, Germany , August. [Santos and aes2015] Cicero D. Santos and V ic- tor Guimar aes. 2015. Boosting named entity recognition with neural character embeddings. In Pr oceedings of the F ifth Named Entity W orkshop , pages 25–33, Beijing, China, July . Association for Computational Linguistics. [Santos and Zadrozny2014] Cicero D. Santos and Bianca Zadrozny . 2014. Learning character-le vel representations for part-of-speech tagging. In T ony Jebara and Eric P . Xing, editors, Pr oceedings of the 31st International Confer ence on Machine Learning (ICML-14) , pages 1818–1826. [Sennrich et al.2015] Rico Sennrich, Barry Haddo w , and Alexandra Birch. 2015. Neural machine trans- lation of rare words with subword units. CoRR , abs/1508.07909. [Sutske ver et al.2014] Ilya Sutskev er , Oriol V inyals, and Quoc V . Le. 2014. Sequence to sequence learning with neural networks. In Z. Ghahramani, M. W elling, C. Cortes, N. D. Lawrence, and K. Q. W einberger , editors, Advances in Neural Informa- tion Pr ocessing Systems 27 , pages 3104–3112. Cur- ran Associates, Inc.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment