문자 기반 신경 기계 번역
본 논문은 기존 단어 임베딩을 대체하여 문자 수준의 CNN‑Highway 구조로 만든 무제한 어휘 소스 임베딩을 신경 기계 번역 시스템에 적용한다. 이를 통해 독일어‑영어 WMT 과제에서 소스 언어의 미지 단어를 제거하고, BLEU 점수를 최대 3점 향상시켰다.
저자: Marta R. Costa-Juss`a, Jose A. R. Fonollosa
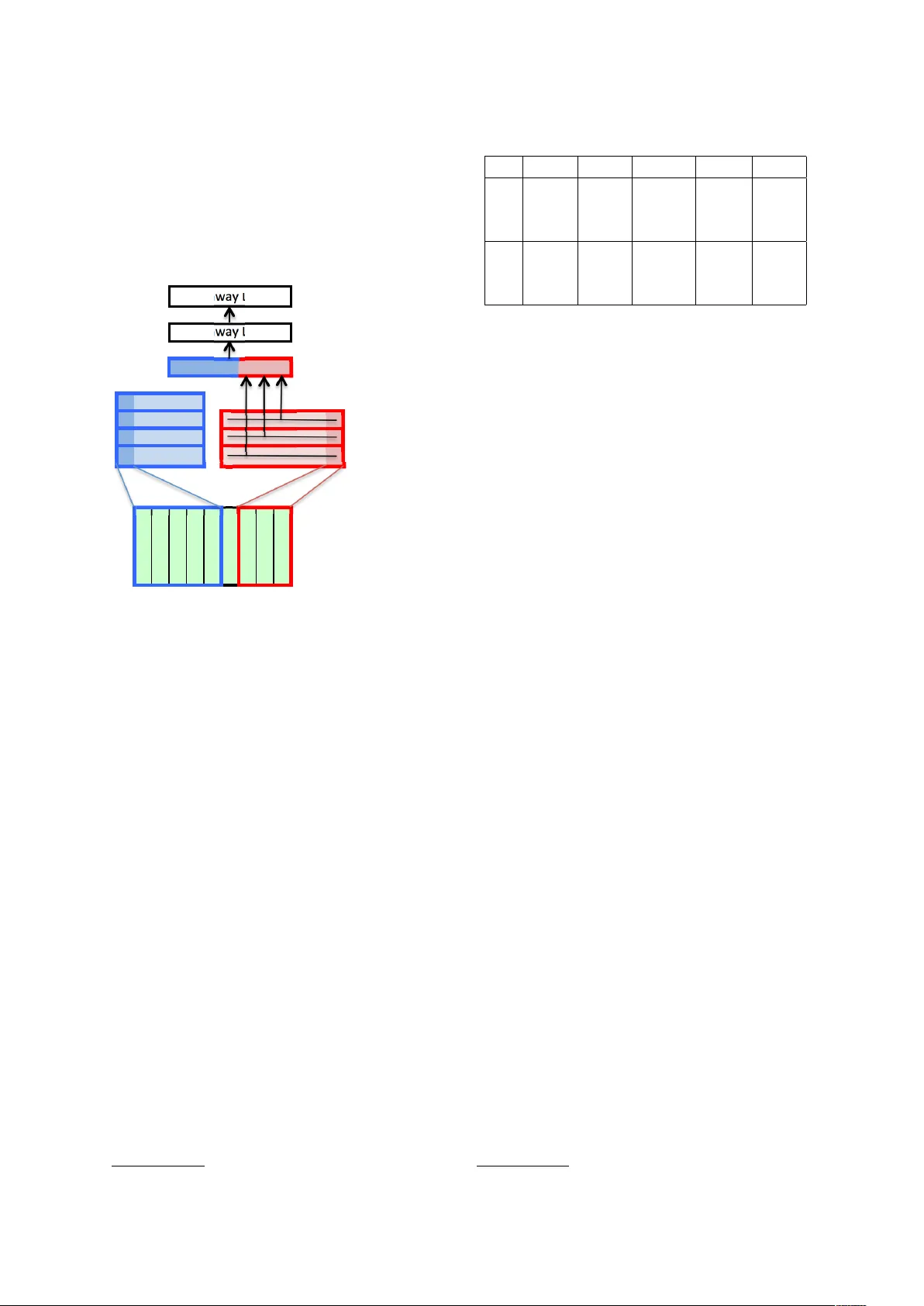
본 논문은 신경 기계 번역(NMT) 시스템에서 어휘 제한 문제를 해결하기 위해 문자 기반 임베딩을 도입한 새로운 아키텍처를 제안한다. 기존 NMT는 단어 수준의 고정된 어휘 집합에 의존하는 lookup‑based 임베딩을 사용한다. 이는 어휘가 큰 언어, 특히 형태소가 풍부한 언어에서 OOV(Out‑of‑Vocabulary) 문제를 야기하고, 번역 품질을 저하시킨다. 저자들은 이러한 문제를 완화하고자, 각 단어를 문자 시퀀스로 분해하고, 이를 1‑D 컨볼루션 신경망(CNN)과 Highway 네트워크를 통해 고정 차원의 벡터로 변환하는 방식을 채택한다.
구체적인 임베딩 과정은 다음과 같다. 먼저 문자 사전에서 각 문자를 임베딩 벡터로 매핑한다. 이어서 길이 1부터 7까지 다양한 커널 크기의 1‑D 컨볼루션 필터를 적용하고, 각 필터에 대해 max‑pooling을 수행해 가장 큰 활성값을 추출한다. 이렇게 얻어진 여러 필터의 최대값을 연결(concatenation)하면, 필터 수에 비례하는 차원의 초기 단어 표현이 생성된다. 이후 두 개의 Highway 레이어를 통과시켜 비선형 변환과 게이트 메커니즘을 적용함으로써, 문자 수준 정보가 풍부히 반영된 최종 단어 임베딩을 얻는다. 이 임베딩은 기존의 lookup‑based 임베딩을 완전히 대체한다.
시스템 전체 구조는 Bahdanau et al. (2015)의 어텐션 기반 인코더‑디코더와 동일하게 유지한다. 인코더는 양방향 GRU(bi‑GRU)를 사용해 소스 문장을 인코딩하고, 디코더는 GRU와 어텐션 메커니즘을 통해 타깃 문장을 생성한다. 차별점은 인코더 입력 단계에만 문자 기반 임베딩을 적용한다는 점이다. 타깃 측 어휘는 기존과 같이 90 000개의 단어로 제한되며, 소프트맥스 레이어도 동일하게 유지한다. 따라서 소스 측에서는 무제한 어휘를 다룰 수 있게 되지만, 타깃 측 OOV 문제는 여전히 존재한다.
실험은 WMT15 독일어‑영어 병렬 코퍼스를 사용했다. 데이터 전처리 단계에서는 토크나이징, 트루케이싱, 구두점 정규화 등을 수행하고, 5 % 이상이 비독일어·비영어인 문장은 제외하였다. 베이스라인 시스템은 (1) Moses 기반 구문 기반 MT, (2) 동일 설정의 단어 임베딩 NMT이며, NMT는 DL4MT 구현을 사용해 임베딩 차원 620, 은닉 차원 1024, 배치 크기 32, 드롭아웃 없이 학습하였다.
성능 평가는 BLEU 점수와 UNK(unknown word) 수를 기준으로 했다. 독일어→영어 방향에서는 베이스라인 NMT가 20.99 BLEU를 기록했으며, 문자 기반 NMT는 21.40으로 0.41점 상승했다. 영어→독일어에서는 17.04→19.53으로 2.49점 향상되었다. UNK 교체(post‑processing) 후에는 각각 22.10, 20.22로 최대 3점 이상 상승하였다. 또한 소스 측 UNK 수가 1491→1260, 타깃 측 UNK 수가 3148→2640으로 크게 감소했다. 번역 예시 분석에서는 소스 UNK 감소가 의미 적합성을 높이고, 형태소 변형(예: 동사 어미, 복수형) 처리에 도움이 되었으며, 의미 소거(disambiguation)에서도 개선이 관찰되었다.
논문의 주요 기여는 다음과 같다. (1) 문자 기반 CNN‑Highway 임베딩을 NMT에 성공적으로 통합해 소스 어휘 제한을 사실상 없앴다. (2) 소스 OOV 감소가 전체 번역 품질에 긍정적 영향을 미쳐 BLEU 점수를 최대 3점까지 끌어올렸다. (3) 기존 어텐션 기반 인코더‑디코더 구조를 크게 변경하지 않으면서도 성능 향상을 달성했다.
한계점으로는 타깃 어휘가 여전히 고정된 크기로 제한되어 있어, 타깃 측 OOV 문제는 해결되지 않는다. 또한 문자 기반 임베딩은 추가적인 CNN·Highway 연산을 필요로 하므로 학습 및 추론 시 약간의 연산량 증가가 있다. 향후 연구에서는 (a) Chung et al. (2016)의 문자 디코더를 도입해 타깃 측에도 무제한 어휘를 적용, (b) 더 깊은 컨볼루션·어텐션 구조를 탐색하거나, (c) 멀티모달 입력(예: 이미지, 음성)과 결합해 전반적인 번역 시스템의 일반화 능력을 강화하는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기