Active Long Term Memory Networks
Continual Learning in artificial neural networks suffers from interference and forgetting when different tasks are learned sequentially. This paper introduces the Active Long Term Memory Networks (A-LTM), a model of sequential multi-task deep learnin…
Authors: Tommaso Furlanello, Jiaping Zhao, Andrew M. Saxe
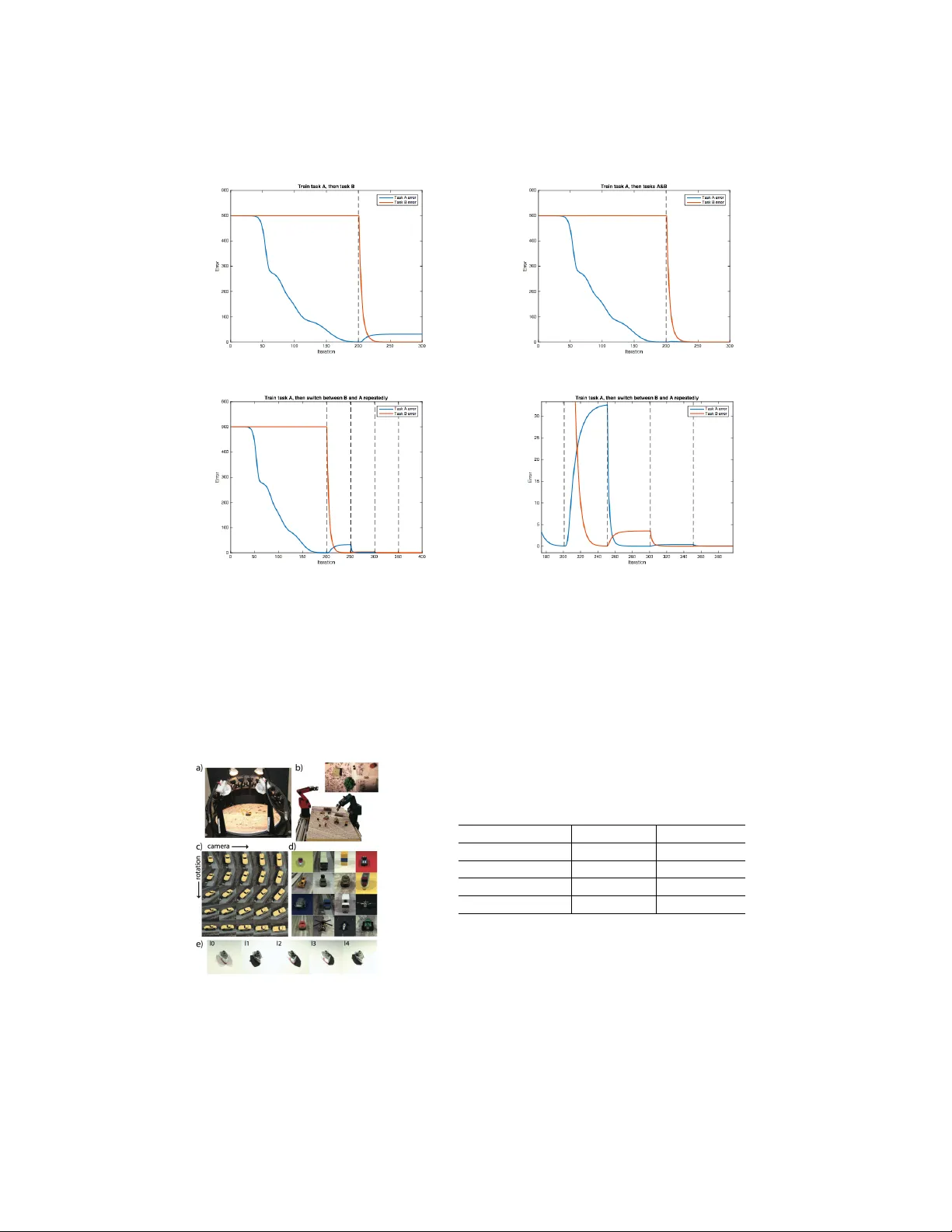
Activ e Long T erm Memory Networks T ommaso Furlanello ∗ Univ ersity of Southern California furlanel@usc.edu Jiaping Zhao Univ ersity of Southern California JustinZo@hotmail.com Andrew M. Saxe Harvard Uni v ersity asaxe@fas.harvard.edu Laurent Itti Univ ersity of Southern California itti@usc.edu Bosco S. Tjan Univ ersity of Southern California btjan@usc.edu Abstract Continual Learning in artificial neural netw orks suf fers from interference and for - getting when different tasks are learned sequentially . This paper introduces the Activ e Long T erm Memory Netw orks (A-L TM), a model of sequential multi- task deep learning that is able to maintain pre viously learned association between sensory input and beha vioral output while acquiring kne w knowledge. A-L TM exploits the non-con ve x nature of deep neural networks and activ ely maintains knowledge of previously learned, inactiv e tasks using a distillation loss [1]. Dis- tortions of the learned input-output map are penalized b ut hidden layers are free to transverse to wards new local optima that are more fav orable for the multi-task objectiv e. W e re-frame the McClelland’ s seminal Hippocampal theory [2] with respect to Catastrophic Inference (CI) beha vior exhibited by modern deep archi- tectures trained with back-propagation and inhomogeneous sampling of latent fac- tors across epochs. W e present empirical results of non-trivial CI during continual learning in Deep Linear Networks trained on the same task, in Con volutional Neu- ral Networks when the task shifts from predicting semantic to graphical factors and during domain adaptation from simple to complex en vironments. W e present results of the A-L TM model’ s ability to maintain viewpoint recognition learned in the highly controlled iLab-20M [3] dataset with 10 object categories and 88 cam- era vie wpoints, while adapting to the unstructured domain of Imagenet [4] with 1,000 object categories. 1 Introduction The recent interest in bridging human and machine computations [5, 6, 7, 8] obliges to consider a learning frame work that is continual, sequential in nature and potentially lifelong [9, 10].Therefore, such a learning framework is prone to interferences and forgetting. On the positiv e side, intrinsic correlations between multiple tasks and datasets allo w to train deep learning architectures that can make use of multiple data and supervision sources to achie ve better generalization [11]. The fav or- able effect of multi-task learning [12, 13] depends on the shared parametrization of the indi vidual functions and the simultaneous estimation and averaging of multiple losses. When trained simulta- neously shared layers are obliged to learn a common representation, effecti v ely cross-regularizing ∗ Corresponding Author 1 each task. Generally , in the sequential estimation case, the most recent task benefits from an induc- tiv e bias [14, 11] while older tasks become distorted [15, 16, 17] by unconstrained back-propagation [18, 19] of errors in shared parameters, a problem identified as Catastrophic Interferences (CI) be- tween tasks [15]. In humans the dyadic interaction between Hippocampus and Neocorte x [2] is thought to mitigate the problem of CI by carefully balancing the sensitivity-stability [20] trade-off such that new expe- riences can be integrated without e xposing the system to risk of abrupt phase transitions. Think of the classical e xample of a child e xploring new objects through structured play [21], who samples from multiple points of view , lighting directions and generates movement of the object in space. This exploration creates inputs for the perceptual systems that span homogeneously all the underlying v ariation in vie wing parameters and construct general purpose graphical, cate gorical or semantic level representations of its perception. Such representations can be used in the future to activ ely regularize e xperience in en vironments where exploration is constrained or costly . W e conjecture that CI arises because during the learning lifespan of a system the distrib ution of locally observed states [22, 23] in the en vironment is non-stationary and potentially chaotic, while the neural representation of the en vironment with respect to its mode of variation as latent graphical [24, 25] and semantic [26, 27] factors must be stable and slowly ev olving to store non-transient knowledge. Early experiments on neural networks’ ability to learn the meso-scale structure [28] of their train- ing en vironment required interleav ed exposure to the dif ferent semantic variations. This heuristic is respected in modern architectures for object recognition [29] trained with stochastic mini batches with uniform, and possibly alternated, rich sampling of categories [30]. Analogously data augmen- tation regularizes the distribution of graphical factors. W e hypothesize that the inability of CNNs to learn object cate gorization with strongly correlated batches is caused by interferences across the vast number of cate gories and latent graphical factors that must be memorized. Similarly , the outstanding success of Deep-Q-Networks (DQN) [5, 31] can partially be found in their intrinsic replay system [32] that augments learning batches with state-action transitions that hav e not been observed in a long time. This procedure allows the creation of representations that DQNs transverse quasi-hierarchically [33] during play . It is dif ficult to imagine ho w these representations could be remembered if past states are not visited again through the replay system. For the simplified case of Deep Linear Networks, it is possible to obtain an e xact analytical treatment of the network’ s learning time as a function of input-output statistics and network depth [34, 35]. Suggesting that phase transitions typical of catastrophic interference might appear when the mixing time of the data generating process is longer than the learning time of the system, obliging the neural network to track the local dependencies between factors of v ariation instead of learning to represent the data generating process in the completeness of its ergodic state. In this paper, we develop the Activ e Long T erm Memory networks inspired by the Hippocampus- Neocortex duality and based on the knowledge distillation [1] framework. Our model is composed by a stable component containing the long term task memory and a fle xible module that is initialized from the stable component and faces the ne w en vironment. W e capitalize on the human infant metaphor and show that is possible to maintain the ability to predict the viewpoint of an object while adapting to a new domain with more images, object categories, and viewing conditions than the original training domain. Moreo ver , we discuss on the necessity to store and replay input from the old domain to fully maintain the original task. 2 Related W ork W ith a non-con vex system to store knowledge in a changing en vironment, is important to understand what kno wledge is synthesized in a neural network. The general intuition is that for hierarchical models with thousands of intermediate representations and millions of parameters it is difficult to identify the contained knowledge with respect to its parameters value across all layers. Without any guarantee of being in a unique global optimum, multiple configurations of weight parameters could sustain the same input-output map, making the association between parameters and knowledge vague. 2 The Kno wledge Distillation (KD) frame work [36, 1] introduces the concept of model compression to transfer the kno wledge of a computationally expensi ve ensemble into a single, easy to deploy , model using the prediction of the complex model as supervision for the compressed one. In the born- again-tree paradigm, Leo Breiman [37] proposed to use one tree model to predict outputs of random forest ensembles for better interpretability . In the KD framework, knowledge in neural networks is therefore identified in the input-output map without regard of its parametrization. Transferring knowledge between two neural architecture (”from teacher to student”) therefore corresponds to supervised training of the student network using the logits of the original teacher netw ork, or by matching the soft-probabilities that they induce. This frame work recei ved a lot of recent interest and has been extended to what is called Generalized Distillation [38] to incorporate some theoretical results of V apnik’ s privile ged information algorithm [39]. Recently large scale experiments [40, 41, 42] have been carried on the ability to compress fully connected into shallow models or con volutional models into Long Short T erm Memory [43] networks and vice-versa. The introduction of double streams architecture inspired by the classical Siamese Network [44] for metric learning, and the consequent generalization of the multi-task framework to domain adaptation [45, 46] of fers a natural extension of KD, where distillation happens between streams made to handle different data or supervision sources, b ut with a shared parametrization. The case for a strong effect of CI during sequential learning in deep neural networks has been shown, respectiv ely between semantic [17] and graphical f actors [3]. In [24] the authors are able to estimate an encoder-decoder model with correlated mini-batches using interlea ved learning with carefully selected factors ratio and ad-hoc clamping of the neurons learning rate. In [47, 48] multiple Atari games are learned with interlea ved distillation across games, the correct ratio between batch size and interleaving was again carefully curated and crucial for the algorithm success. The authors [47] also present a nov el self-distillation framework remembering the Minskian Sequence of T eaching Selves [49]. 3 The A-L TM Model W e approach the problem of learning with a sequence of input-outputs that exhibits transitions in its latent factors using a dual system. Our model is inspired from the seminal theory of McClelland on the dyadic role of hippoca mpus and neocorte x in preserving long-term memory and av oiding catastrophic interferences in mammals [2]. The first A-L TM component is a mature and stable network, Neocortex ( N ), which is trained during a dev elopment phase in a homogeneous en vironment rich of supervision sources. T o prevent the interference of new experience with pre viously stored functions, the N networks’ s learning rate is drastically reduced during post-developmental phases in an imitation of the visuo-cortical critical period of plasticity [50]. The second component in the A-L TM is a flexible network, Hippocampus ( H ), which is subject to a general unstructured en vironment. H weights are initialized from N and learning dynamics are activ ely regularized from H output activity . This dual mechanism allows to maintain stability in N without ignoring new inputs. H can quickly adapt to ne w information in a non-stationary en vironment without generating a risk for the inte grity of knowledge already stored in N . Furthermore long term information in N are activ ely distilled into H , with the effect of constraining the gradient descent dynamics ongoing in H towards a better local minimum able to sustain both new and old kno wledge. Operationally: 1. During dev elopment: N is trained in a controlled en vironment where multiple examples of the same object and of its potential graphical transformation are present. W e train N with a multi-task objective to predict both semantic (category) and graphical (camera-vie wpoint) labels of the object. After conv ergence, the learning rate of N is set to 0. 2. During maturity: H is initialized from N and f aces a novel en vironment, where objects are typically av ailable from a single perspectiv e and the number of cate gories is increased by two orders of magnitude (from 10 to 1000 classes). H is trained with a multi-task objectiv e to predict both the new higher dimensional semantic task and the output of N with respect 3 to the dev elopmental tasks, in this case N ’ s ability to dif ferentiate between different point of view of the same object. A-L TM networks relies on the core idea that all the tasks to memorize need simultaneous experience to find a multi-task optimum that is a critical point for all the objectives. Therefore, if the en viron- ment has unstable input-output because of missing labels, H has to rely on predictions from N . In the complementary case, where instabilities are generated by changes in the distrib ution of input, an auxiliary replay mechanism is also necessary . A Sequential En vironment W e study the situation where an agent interacts with a sequential en vironment, defined by the joint distribution P ( y , x ) of visual stimuli x ∈ X and their binary latent f actors y ∈ Y . The agent receiv es information through a perceptual mechanism Ψ( x ) : X 7→ S and makes decision based on a hierarchical representation of its percept φ ( s ) : S 7→ Φ d . The agent’ s goal is to name the underlying latent factors for each stimulus. Actions are chosen by the agent with a n-way soft- max that transforms φ d ( s ) , the last layer of the hierarchical representation of sensory inputs, into a probability distribution o ver actions. The en vironment responds to actions with a supervised signal y ∈ Y informing the agent on the correct action given a particular stimulus. The hierarchical representation φ is updated in order to minimize the cross-entropy loss L ( φ d ( s ) , y ) . This task is computationally tedious because of the vast range of possible transformations in sensory inputs τ : S 7→ S that do not hav e any meaningful consequence on the semantic nature of the stimulus. W e call these transformations latent graphical factors. Perceptual inputs to our system s hav e therefore two modes of v ariation: 1. V ariations in semantic factors that alters the category of stimulus x and its percept s , parametrized by the subcomponent y s ∈ y . 2. V ariations in graphical factors that are in variant with respect to the category of x but alter its percept s , parametrized by the subcomponent y g ∈ y . Catastrophic interference happens when the distribution of supervised signals P ( y , x ) is not homo- geneous. While modeling environment’ s non-stationarity in the language of stochastic process could lead to interesting insights, we limit ourselves to the simple regime with a single discrete transition from P 1 ( y 1 , x 1 ) to P 2 ( y 2 , x 2 ) . Bridging Sequential and Multi-T ask Learning via Knowledge Distillation Let the multitask function representing the input - output maps of network be f ( w 0 , w 1 , w 2 ; x ) : X 7→ Y , where w 0 are shared parameters and w 1 , w 2 the task-specific parameters defining a map from the common representation to the individual tasks y 1 , y 2 . Sequential Learning corresponds to solving in this sequence the follo wing two optimization prob- lems. First the minimization of the cross entropy loss L ( f ( w 0 , w 1 ; x 1 ) , y 1 ) between the en vironment data generating process P 1 ( y 1 | x 1 ) and the softmax probability distribution induced o ver the task 1 predictions f ( w 0 , w 1 ; x 1 ) , with a Gaussian initializations w 0 0 and w 0 1 : min w 0 ,w 1 L ( f ( w 0 , w 1 ; x 1 ) , y 1 ) s. t. w 0 0 ∼ N (0 , σ ) w 0 1 ∼ N (0 , σ ) (1) with solutions w ∗ 0 , w ∗ 1 . Follo wed by analogous problem for the second en vironment with starting condition equal to the solution of the previous problem for the shared parameters w 0 : min w 0 ,w 2 L ( f ( w 0 , w 2 ; x 2 ) , y 2 ) s. t. w 0 0 = w ∗ 0 w 0 2 ∼ N (0 , σ ) (2) with solutions w ∗∗ 0 , w ∗∗ 2 , making f ( w ∗∗ 0 , w ∗ 1 ; x 1 ) an unlikely critical point of problem 1. Multitask learning mitigates the problem of CI by averaging weight updates across different objec- tiv es and corresponds to solving 1 and 2 simultaneously , with an omitted scaling factors between the 4 two objecti ves: min w 0 ,w 1 ,w 2 L ( f ( w 0 , w 1 ; x 1 ) , y 1 ) + L ( f ( w 0 , w 2 ; x 2 ) , y 2 ) s. t. w 0 0 ∼ N (0 , σ ) w 0 1 ∼ N (0 , σ ) w 0 2 ∼ N (0 , σ ) (3) The drawback of this approach is that ( y 1 , x 1 ; y 2 , x 2 ) must be a vailable to the network during the whole training phase. In absence of labels y 1 for the old task, Kno wledge Distillation can be used as a surrogate. In A-L TM the stable module N trained with the problem 1 can be used to hallucinate missing labels. This way , the ne w learning phase of H can be recast in the multi-task framew ork e ven in absence of external supervision solving the following: min w 0 ,w 1 ,w 2 L ( f ( w 0 , w 1 ; x 1 ) , f ( w ∗ 0 , w ∗ 1 ; x 1 )) + L ( f ( w 0 , w 2 ; x 2 ) , y 2 ) s. t. w 0 0 = w ∗ 0 w 0 1 = w ∗ 1 w 0 2 ∼ N (0 , σ ) (4) W ith respect to the av ailability of inputs, if they belong to the same modality and share the same distribution of graphical factors of variation, the active stream of perception can be used to train both activ e and inactiv e tasks in the flexible module. Otherwise, either inputs ha ve to be stored or the networks must rely on some generativ e mechanism to generate imaginary samples for the non- ongoing task. In eq 4 we assume the presence of a replay mechanism allo wing the A-L TM netw orks to ha ve access to both x 1 and x 2 during training. W e relax this assumption in the experiments and present results also for the problem with objective function L ( f ( w 0 , w 1 ; x 2 ) , f ( w ∗ 0 , w ∗ 1 ; x 2 )) + L ( f ( w 0 , w 2 ; x 2 ) , y 2 ) . Beyond Active Maintenance, Memory Consolidation While in this article we focus on the early phase of memory maintenance, a successi ve phase called memory consolidation, where kno wledge is distilled from H to N is necessary for non-activ e long term memory . W e interpret the phase of learning that we model as the step right before consolidation. An irrepara- ble damage to H w ould create a memory loss equi valent to temporally graded retrograde amnesia. In case of bilateral lesions [51] to the hippocampus pre viously kno wn information stored in N would be safe, b ut recent adaptations to ne wly kno wn en vironments only stored in H would be completely lost. 4 Experiments As a first illustration of the Activ e Long T erm Memory framework, we conduct a sequence of exper - iments on sequential, multitask and A-L TM learning. W e employ three datasets in experiments of increasing comple xity . W e first sho w that interferences emer ge in the tri vial case sequential learning of the same function in deep linear networks. W e analyze the situation where complete forget- ting happens during sequential learning of semantic and graphical factors of variation. Finally , we demonstrate the ability of A-L TM to preserve memory during domain adaptation with and without access to replays of the previous en vironment. The datasets used are: • Synthetic Hierarchical F eatures [35]: we employ a procedure based on independent sam- pling from a branching diffusion process, previously used to study Deep Linear Networks learning (DLNs) dynamics, to generate a synthetic dataset with a hierarchical structure similar to the taxonomy of categories typical to the domain of li ving things. • iLab20M [3]: in this highly controlled dataset, images of toy-vehicles are collected ov er a turntable with multiple cameras, with different lighting directions. Ilab totals 704 objects from 15 categories, 8 rotating angles, 11 cameras 5 lighting conditions and multiple focus and background, for a complete dataset of o ver 22M images. Each object has 1320 images 5 per background. Because of the highly controlled nature of the dataset, we reach high accu- racy with a random subset of 850k images from 10 categories and 11*8 camera positions: thus, we do not e xploit variations in all the other factors for a matter of simplicity . iLab20M is freely av ailable. • Imagenet 2010 [4]: is an image database with 1000 cate gories and ov er 1.3 M images for training set. Imagenet is the most used dataset for large scale object recognition, since Alexnet [29] won the 2012 submission only deep learning model have been on the leader- board of the annual ILSVRC competition. Except for the DLNs experiments, we train using stochastic gradient descent Alexnet’ s like Archi- tecture with drop-out without any form of data augmentation on a central 256-by-256 crop of the images. W e train until con ver gence,1 to 3 epochs, in iLab20M and for 10 epochs in Imagenet. Dur- ing multi-domain and A-L TM, the loss function associated to iLAB is scaled by a factor of 0.1, as larger factors tend to stuck the Imagenet training in local minima. Kno wledge distillation is imple- mented using an l 2 loss between the decision layers of the N and H network of both iLab categories and viewpoints; we adopted the l 2 instead of cross-entropy to a void tuning an additional parameter for the teacher soft-max temperature. All of the experiments are implemented in Matcon vnet [52] and run three Nvidia GPUs, two T itan X and one T esla K-40. 4.1 Catastrophic Interference in Deep Linear Networks W e first study the aforementioned discrete transition in Deep Linear Networks [34] for the tri vial case of learning sequentially the same function. DLNs exhibits interesting non-linear dynamics typ- ical of their non-linear counterpart, but are amenable to interpretation. Their optimization problem is non-conv ex and, since their deep structure can be transformed to a shallo w linear map by simple factorization of layers, each deep local minimum can be compared to the shallo w global optima. In our experiments, the netw ork architecture has an input layer , a single hidden layer , and two output layers, one for each task. W e examine the trivial situation where T ask A is equiv alent to T ask B. In this situation, obviously a multi-task solution corresponds to the network re-learning the hidden to output layer without any modification of the input to hidden layer . Alternati vely , multiple solutions that maintain the input-output relationship constant but modify weights of the input-hidden layer , therefore requiring and adjustment of the hidden-output weights, are possible. In Fig 1a, we first train the network with respect to T ask A till conv ergence and then be gin training with respect to the identical T ask B; we find that back-propagation systematically has an effect on the input-hidden layer , generating interference of the original network. In Fig 1b, multi-task learning does not ha ve the same problem. In Fig 1c-1d we instead alternate task ev ery 50 epochs, generating reciprocal interference of decreasing intensity that delays con vergence for more than 100 epochs with respect to the multi-task case. 4.2 Sequential and Multi-task Learning of Orthogonal Factors on iLab20M Because of its parametrized nature, iLab20M is a good en vironment for the early training phase of models that can be taught to incorporate the ability to predict multiple semantic (like cate gories and identities) and graphical factors (like luminance or vie wpoint). W e train single task architectures to classify either between 10 Categories (ST -Category ) or 88 V iewpoints (ST -V iewpoint) and use its weights at con vergence to warm up a network for the com- plementary task. W e compare the Inducti ve Bias and Catastrophic Interference ef fect to single and multi-task solutions. The results in table b of fig 2 confirm the inductiv e bias of V iewpoints over Category and the dramatic interference of sequential training between the two tasks. Finally , as expected, multi-task learning can easily learn both tasks, incorporating the inductiv e bias from viewpoints to categories. 4.3 Sequential, Multi-T ask and A-L TM Domain Adaptation over Imagenet Imagenet is a popular benchmark for state of the art architecture for visual recognition because of its 1000 categories and over 1M images. W e compare the adaptation performance to Imagenet of 6 (a) Sequential Learning: T ask A 7→ B (b) Multitask Learning: T ask A 7→ A+B (c) Interleav ed Learning: T ask A 7→ B 7→ A 7→ B (d) Zoom of (c): Catastrophic Interference Figure 1: Catastrofic Intereference experiments with Deep Linear Networks: T ask A is equi v alent to T ask B (a) Turntable setup for iLab20M, figure from [3] Categories V iewpoints ST - Category 0.81 / ST - V iewpoint / 0.94 Cat 7→ V iew 0.12 0.93 V iew 7→ Cat 0.84 0.02 MT - Cat/V iew 0.85 0.91 (b) T est set Accuracy for experiment 4.2: ST for single task model, 7→ indicate sequential learning, MT for multitask learning. The effects of Catastrophic Interference in bold. Figure 2: a): example of turntable setup and of multiple-camera viewpoint, lighting directions and objects from iLab20M. b): : Results of Sequential and Multi-T ask learning of cate gories and viewpoitns onf iLab20M 7 T able 1: T est set Accuracy of domain adaptation ov er Imagenet and Memory of the V iewpoint task for iLAB for single task (ST), multi-task/domain (MD) and Activ e Long T erm Memory networks with and without replay . Imagenet V iewpoints ST - Gauss Init 0.44 ST - iLab Init 0.46 0.03 MD - Gauss Init 0.44 0.81 MD - iLab Init 0.45 0.84 A-L TM - naiv e 0.40 0.57 A-L TM - replay 0.41 0.90 multiple architectures: a single task network with Gaussian initialization (ST - Gauss), sequential transfer from the iLab20M multi task network (ST -iLab), multi-domain networks trained simulta- neously o ver the iLab and Imagenet tasks either initialized randomly (MD - Gauss) or from the iLab20M multi task network (MD - iLab). As seen in T able 1 we confirm the general intuition dev eloped in the previous experiment. Ini- tializing from iLab has a positiv e effect on the transferred performance; moreov er unconstrained adaptation completely wipes the ability of the network to perform vie wpoint identification. Multi- T ask/Domain learning is able to reach the same performances on Imagenet while maintaining almost completely the viewpoint detection task. A-L TM: Domain Adaptation from iLab20M to Imagenet without extrinsic supervision While Multi-task learning seems to be a good strategy for finding local minimum able to mantain multiple tasks it requires two expensi ve sources of supervision: Images and Labels from the original domain. The A-L TM architecture is able to exploit the absence of supervision by using its stable compo- nent to hallucinate the missing labels and con vert the otherwise sequential learning in a multi-task scenario. If the distribution of input is homogeneous across datasets, i.e P ( y 1 | x 1 ) = P ( y 1 | x 2 ) the input-output map of the stable network can be e xpressed, therefore distilled, using only images from the ne w domain as input a voiding completely the limitations of multi-task learning (A-L TM - naiv e). In the contrary case a replay system either based on re-generation or storage of the past input is necessary (A-L TM - replay). The multi-task architecture of experiment 4.2 is used as stable component N for both experiments, i.e. we use it to for weight initialization of H and as a source of supervision for KD in both A-L TM models. The results on Imagenet in table 1 sho w that the A-L TM architectures are able to maintain the long term memory of the V ie wpoint task at the cost of a slower adaptation. The reduced memory performance in table 1 of A-L TM-naive (without replay), especially the strong initial drop, for both viewpoints and categories as illustrated in figure 3 is indicati ve of the strong shift in underlying factors between the two datasets and the importance of generativ e mechanisms to re-balance these differences with replay . 5 Discussion In this work we introduced a model of long term memory inspired from neuroscience and based on the knowledge distillation frame work that bridges sequential learning with multi-task learning. W e show empirically that the ability to recognize dif ferent viewpoints of an object can be maintained also after the exposure to millions of ne w examples without extrinsic supervision using kno wledge distillation and a replay mechanism. Furthermore we report encouraging results on the ability of A-L TM to maintain kno wledge only relying on the current perceptual stream. The theoretical anal- ysis of DLNs linking con vergence time of stochastic gradient descent to input-output statistics and network depth, and the plethora of tricks de veloped to successfully train deep netw orks suggest a potential relationship with the v anishing gradient problem [43, 53]. In order to learn in complex en vironments whose data generating process take a long time to mix it is necessary to use deeper 8 Figure 3: T est Set Accuracy on iLab20M of A-L TM: categories in blue and vie wpoints in red. A-L TM with replay is indicated by circles while A-L TM without replay with plus signs, the dashed horizontal lines represents the accuracies at initialization. Both models suf fers from an initial drop in accurac y during the first epochs b ut the A-L TM netw ork that has access to samples of the original dataset is able to fully recov er . architectures that hav e a longer con ver gence time, that in turn are plagued by the problem of propa- gating the gradient across multiple layers. While it seems easy to confuse the two memory problems, in supervised classification with Long Short T erm Memory netw orks a careful balance of positive and ne gati ve examples in the mini- batches is crucial to the model performance, similarly to the interleaved scheme for sampling cate- gories in CNNs. References [1] Geoffrey Hinton, Oriol V inyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint , 2015. [2] James L McClelland, Bruce L McNaughton, and Randall C O’Reilly . Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory . Psychological re view , 102(3):419, 1995. [3] Borji Ali, W ei Liu, Izadi Saeed, and Itti Laurent. ilab-20m: A large-scale controlled object dataset to investigate deep learning. In The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2016. [4] Olga Russakovsky , Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy , Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer V ision , 115(3):211–252, 2015. [5] V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel V eness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature , 518(7540):529–533, 2015. [6] Qianli Liao and T omaso Poggio. Bridging the gaps between residual learning, recurrent neural networks and visual cortex. arXiv preprint , 2016. [7] Brenden M Lake, T omer D Ullman, Joshua B Tenenbaum, and Samuel J Gershman. Building machines that learn and think like people. arXiv preprint arXiv:1604.00289 , 2016. [8] T ejas D Kulkarni, Karthik R Nara simhan, Ardav an Saeedi, and Joshua B T enenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motiv ation. arXiv preprint , 2016. [9] T omas Mikolov , Armand Joulin, and Marco Baroni. A roadmap towards machine intelligence. arXiv pr eprint arXiv:1511.08130 , 2015. [10] Chen T essler, Shahar Giv ony , T om Zahavy , Daniel J Manko witz, and Shie Mannor . A deep hierarchical approach to lifelong learning in minecraft. arXiv pr eprint arXiv:1604.07255 , 2016. [11] Jason Y osinski, Jeff Clune, Y oshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? In Advances in Neural Information Pr ocessing Systems , pages 3320–3328, 2014. [12] Rich Caruana. Learning many related tasks at the same time with backpropagation. Advances in neural information pr ocessing systems , pages 657–664, 1995. [13] Rich Caruana. Multitask learning. Machine learning , 28(1):41–75, 1997. [14] Lorien Y Pratt, Jack Mostow , Candace A Kamm, and Ace A Kamm. Direct transfer of learned information among neural networks. In AAAI , volume 91, pages 584–589, 1991. [15] Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. The psychology of learning and motivation , 24(109-165):92, 1989. [16] Robert M French. Catastrophic forgetting in connectionist networks. T rends in co gnitive sciences , 3(4):128–135, 1999. [17] Ian J Goodfellow , Mehdi Mirza, Da Xiao, Aaron Courville, and Y oshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv pr eprint arXiv:1312.6211 , 2013. [18] Robert Hecht-Nielsen. Theory of the backpropagation neural network. In Neural Networks, 1989. IJCNN., International Joint Conference on , pages 593–605. IEEE, 1989. [19] B Boser Le Cun, John S Denker, D Henderson, Richard E Ho ward, W Hubbard, and Lawrence D Jackel. Handwritten digit recognition with a back-propagation network. In Advances in neural information pr ocessing systems . Citeseer, 1990. [20] Donald Olding Hebb. The or ganization of behavior: A neuropsyc hological theory . Psychology Press, 2005. 9 [21] Jean Piaget and Barbel Inhelder. The psychology of the child . Basic Books, 2008. [22] James P Crutchfield and Cosma Rohilla Shalizi. Thermodynamic depth of causal states: Objective complexity via minimal representations. Physical revie w E , 59(1):275, 1999. [23] Cosma Rohilla Shalizi et al. Causal arc hitecture, complexity and self-organization in the time series and cellular automata . PhD thesis, Uni versity of W isconsin– Madison, 2001. [24] T ejas D Kulkarni, W illiam F Whitney , Pushmeet Kohli, and Josh T enenbaum. Deep convolutional inverse graphics network. In Advances in Neural Information Pr ocessing Systems , pages 2530–2538, 2015. [25] Y oshua Bengio, Aaron Courville, and Pierre V incent. Representation learning: A revie w and new perspectives. P attern Analysis and Machine Intelligence, IEEE T ransactions on , 35(8):1798–1828, 2013. [26] James V Haxby , M Ida Gobbini, Maura L Furey , Alumit Ishai, Jennifer L Schouten, and Pietro Pietrini. Distributed and ov erlapping representations of faces and objects in ventral temporal cortex. Science , 293(5539):2425–2430, 2001. [27] Daniel L Y amins, Ha Hong, Charles Cadieu, and James J DiCarlo. Hierarchical modular optimization of conv olutional networks achieves representations similar to macaque it and human ventral stream. In Advances in Neural Information Processing Systems , pages 3093–3101, 2013. [28] Geoffrey E Hinton. Learning distributed representations of concepts. [29] Alex Krizhevsky , Ilya Sutskever , and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information pr ocessing systems , pages 1097–1105, 2012. [30] Y ann A LeCun, L ´ eon Bottou, Genevieve B Orr, and Klaus-Robert M ¨ uller . Efficient backprop. In Neural networks: Tricks of the trade , pages 9–48. Springer, 2012. [31] David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George V an Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, V eda Panneer- shelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. Nature , 529(7587):484–489, 2016. [32] Long-Ji Lin. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine learning , 8(3-4):293–321, 1992. [33] T om Zahavy , Nir Ben Zrihem, and Shie Mannor. Graying the black box: Understanding dqns. arXiv preprint , 2016. [34] Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv pr eprint arXiv:1312.6120 , 2013. [35] Andrew M Saxe, James L McClelland, and Surya Ganguli. Learning hierarchical categories in deep neural networks. [36] Cristian Bucilu, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. In Pr oceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining , pages 535–541. A CM, 2006. [37] Leo Breiman and Nong Shang. Born again trees. Available onlin e at: ftp://ftp. stat. berkeley . edu/pub/users/breiman/BAtr ees. ps , 1996. [38] David Lopez-Paz, L ´ eon Bottou, Bernhard Sch ¨ olkopf, and Vladimir V apnik. Unifying distillation and privileged information. arXiv preprint , 2015. [39] Vladimir V apnik and Rauf Izmailov . Learning using pri vileged information: Similarity control and knowledge transfer . Journal of Machine Learning Resear ch , 16:2023–2049, 2015. [40] Jimmy Ba and Rich Caruana. Do deep nets really need to be deep? In Advances in neural information processing systems , pages 2654–2662, 2014. [41] Krzysztof J Geras, Abdel-rahman Mohamed, Rich Caruana, Gregor Urban, Shengjie W ang, Ozlem Aslan, Matthai Philipose, Matthew Richardson, and Charles Sutton. Compressing lstms into cnns. arXiv preprint , 2015. [42] Gregor Urban, Krzysztof J Geras, Samira Ebrahimi Kahou, Ozlem Aslan, Shengjie Wang, Rich Caruana, Abdelrahman Mohamed, Matthai Philipose, and Matt Richardson. Do deep conv olutional nets really need to be deep (or ev en conv olutional)? arXiv preprint , 2016. [43] Sepp Hochreiter and J ¨ urgen Schmidhuber . Long short-term memory. Neural computation , 9(8):1735–1780, 1997. [44] Jane Bromley , James W Bentz, L ´ eon Bottou, Isabelle Guyon, Y ann LeCun, Cliff Moore, Eduard S ¨ ackinger, and Roopak Shah. Signature verification using a siamese time delay neural network. International Journal of P attern Recognition and Artificial Intelligence , 7(04):669–688, 1993. [45] Mingsheng Long and Jianmin W ang. Learning multiple tasks with deep relationship networks. arXiv pr eprint arXiv:1506.02117 , 2015. [46] Artem Rozantsev , Mathieu Salzmann, and Pascal Fua. Beyond sharing weights for deep domain adaptation. arXiv preprint , 2016. [47] A. A. Rusu, S. Gomez Colmenarejo, C. Gulcehre, G. Desjardins, J. Kirkpatrick, R. Pascanu, V . Mnih, K. Kavukcuoglu, and R. Hadsell. Polic y Distillation. ArXiv e-prints , November 2015. [48] Emilio Parisotto, Jimmy Lei Ba, and Ruslan Salakhutdinov . Actor-mimic: Deep multitask and transfer reinforcement learning. arXiv pr eprint arXiv:1511.06342 , 2015. [49] Marvin Minsky . Society of mind . Simon and Schuster, 1988. [50] T orsten N W iesel, David H Hubel, et al. Effects of visual deprivation on morphology and physiology of cells in the cat’ s lateral geniculate body . J Neurophysiol , 26(978):6, 1963. [51] William Beecher Scoville and Brenda Milner. Loss of recent memory after bilateral hippocampal lesions. Journal of neurology , neurosur gery, and psychiatry , 20(1):11, 1957. [52] Andrea V edaldi and Karel Lenc. Matcon vnet: Conv olutional neural networks for matlab. In Proceedings of the 23rd Annual ACM Conference on Multimedia Conference , pages 689–692. A CM, 2015. [53] Sepp Hochreiter, Y oshua Bengio, Paolo Frasconi, and J ¨ urgen Schmidhuber . Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment