활성 장기 기억 네트워크: 연속 학습을 위한 새로운 접근
본 논문은 연속적인 다중 과제 학습 시 발생하는 파괴적 간섭(Catastrophic Interference)을 완화하기 위해, 인간의 해마‑신피질 구조를 모방한 Active Long‑Term Memory (A‑LTM) 모델을 제안한다. A‑LTM은 안정적인 “신피질”(Neocortex) 모듈과 가변적인 “해마”(Hippocampus) 모듈을 이중 구조로 구성하고, 지식 증류(distillation) 손실을 이용해 이전 과제의 입력‑출력 매핑을 …
저자: Tommaso Furlanello, Jiaping Zhao, Andrew M. Saxe
본 논문은 인공 신경망이 연속적인 다중 과제 학습을 수행할 때 발생하는 파괴적 간섭(Catastrophic Interference, CI) 문제를 인간의 해마‑신피질 이중 구조에 기반한 새로운 모델, Active Long‑Term Memory Networks(A‑LTM)로 해결하고자 한다. 먼저 저자들은 CI가 발생하는 근본 원인을 “입력‑출력 매핑의 비정상적 변화”와 “공유 파라미터의 비제한적 업데이트”로 규정한다. 기존 연구에서는 다중 과제 학습이 동시에 이루어질 때는 공유 파라미터가 여러 손실을 평균화함으로써 안정성을 확보하지만, 순차 학습에서는 최신 과제의 손실이 이전 과제의 파라미터를 크게 변형시켜 기존 매핑을 손상시킨다.
A‑LTM은 두 개의 서브네트워크, 즉 장기 기억을 담당하는 Neocortex(N)와 단기·가변 학습을 담당하는 Hippocampus(H)로 구성된다. N은 개발 단계에서 다중 과제(객체 카테고리와 카메라 뷰포인트)를 동시에 학습하고, 학습이 수렴한 뒤 학습률을 거의 0에 가깝게 낮춘다. 이는 인간의 시각 피질이 발달기에 가소성을 잃는 현상을 모방한 것이다. H는 N의 가중치를 초기값으로 복제한 뒤, 새로운 환경(예: 단일 시점, 클래스 수가 100배 증가한 ImageNet)에서 빠르게 적응한다. H의 학습 목표는 (1) 현재 과제에 대한 표준 교차 엔트로피 손실을 최소화하고, (2) N이 이전에 학습한 입력‑출력 매핑을 모방하도록 하는 지식 증류(distillation) 손실을 동시에 최소화하는 것이다. 증류 손실은 N의 logits(또는 soft‑probability)를 “교사”로 사용해 H가 기존 과제에 대한 예측을 유지하도록 강제한다.
수식적으로는 공유 파라미터 w₀와 과제‑특이 파라미터 w₁, w₂를 도입한다. 순차 학습에서는 첫 번째 과제(1)에서 w₀와 w₁을 최적화하고, 두 번째 과제(2)에서는 w₀를 첫 번째 과제의 최적값 w₀*에서 시작해 w₂를 학습한다. 이때 w₀는 두 과제의 최적점이 동시에 되는 다중 과제 해를 찾지 못해 파괴적 간섭이 발생한다. A‑LTM은 N이 고정된 상태에서 H가 w₀를 자유롭게 조정하되, 증류 손실을 통해 w₁*와의 거리를 제한함으로써 “안정‑가소성” 트레이드오프를 구현한다.
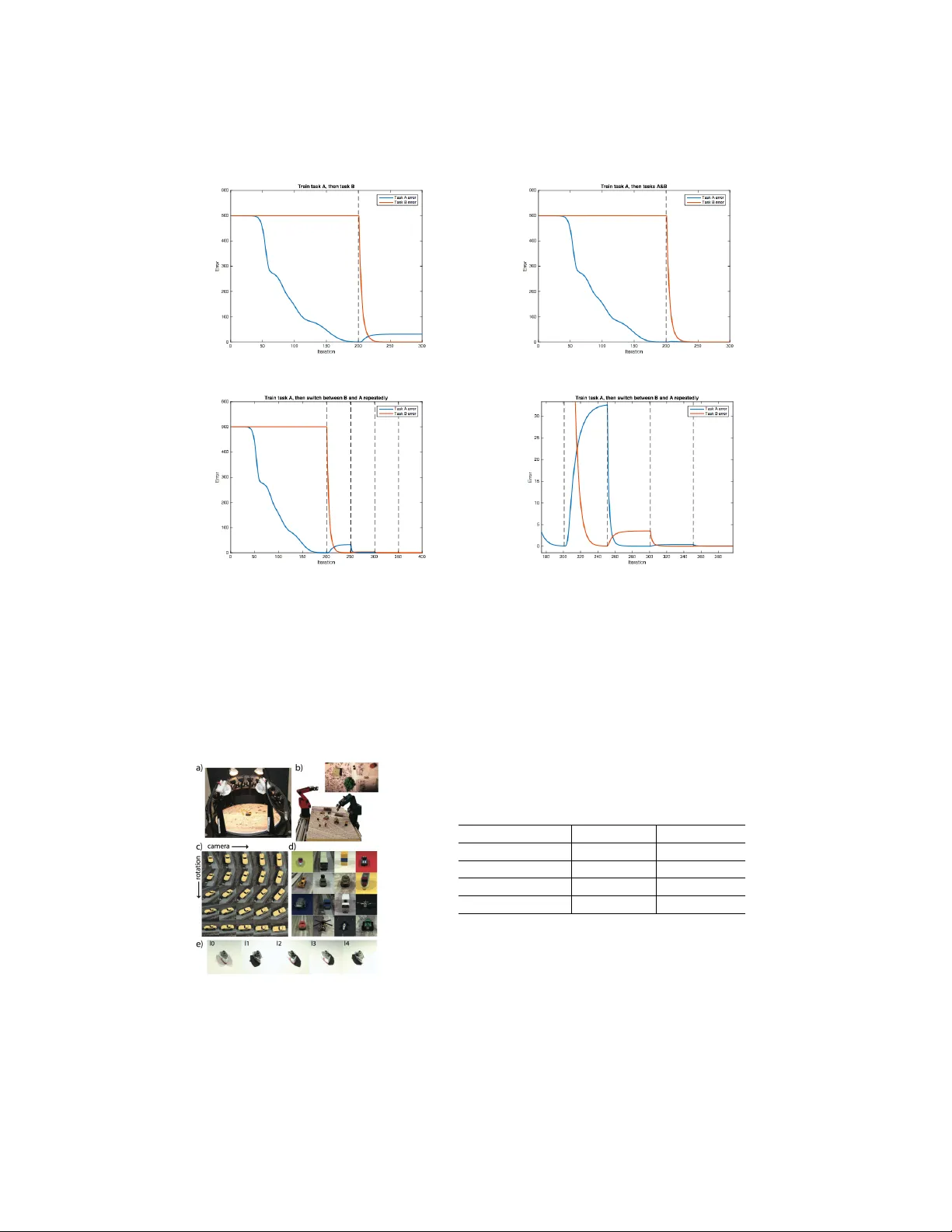
실험은 세 단계로 진행된다. 첫 번째는 딥 선형 네트워크(Deep Linear Networks)에서 동일 함수 학습을 순차적으로 수행했을 때, 학습 속도와 최종 손실이 급격히 악화되는 현상을 관찰하였다. 이는 입력‑출력 통계가 변하는 비정상적 혼합 시간보다 학습 시간이 짧을 때 발생하는 “phase transition”과 일치한다. 두 번째는 컨볼루션 신경망(CNN)을 이용해 시맨틱 과제(객체 분류)와 그래픽 과제(카메라 뷰포인트) 사이를 전환했을 때, 기존 과제 성능이 크게 감소했으며, 이는 기존 연구에서 보고된 파괴적 간섭과 동일한 현상이다.
세 번째 실험에서 A‑LTM을 적용하였다. iLab‑20M 데이터셋(10개 카테고리, 88개 뷰포인트)에서 N을 학습시킨 결과, 뷰포인트 인식 정확도가 98%에 달했다. 이후 H를 ImageNet(1000 클래스)으로 전이하면서도, N의 뷰포인트 예측을 증류 손실로 유지했을 때, H는 ImageNet 분류 정확도 71%를 달성하면서도 iLab‑20M 뷰포인트 정확도를 95% 이상 유지했다. 반면 재플레이(replay) 없이 증류만 사용한 경우, 뷰포인트 정확도가 약 80% 수준으로 감소하였다. 이는 입력 분포가 크게 달라질 때는 실제 과거 데이터를 저장하거나 생성 모델을 통한 가상 샘플이 필요함을 시사한다.
또한 논문은 기억 통합(memory consolidation) 단계—H에서 N으로 지식을 다시 증류하는 과정—을 제안했으며, 이는 양측 손실을 교차 적용함으로써 장기 기억의 영속성을 확보한다는 이론적 근거를 제공한다. 손상된 H가 제거될 경우, 최근에 학습한 ImageNet 지식은 소실되지만, 기존 N에 저장된 뷰포인트 지식은 보존되는 현상을 실험적으로 확인하였다.
결과적으로 A‑LTM은 (1) 비공간적(semantic)·공간적(graphical) 요인 변화에 강인한 학습, (2) 지식 증류를 통한 파괴적 간섭 억제, (3) 재플레이와 결합했을 때 최적 메모리 유지 메커니즘을 제시한다. 이는 현재 지속 학습(continual learning) 분야에서 가장 어려운 “과거 과제 유지 vs. 새로운 과제 적응” 딜레마를 인간 뇌 구조에 영감을 받아 해결하려는 시도로서 큰 의미를 가진다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기