Resource Constrained Structured Prediction
We study the problem of structured prediction under test-time budget constraints. We propose a novel approach applicable to a wide range of structured prediction problems in computer vision and natural language processing. Our approach seeks to adapt…
Authors: Tolga Bolukbasi, Kai-Wei Chang, Joseph Wang
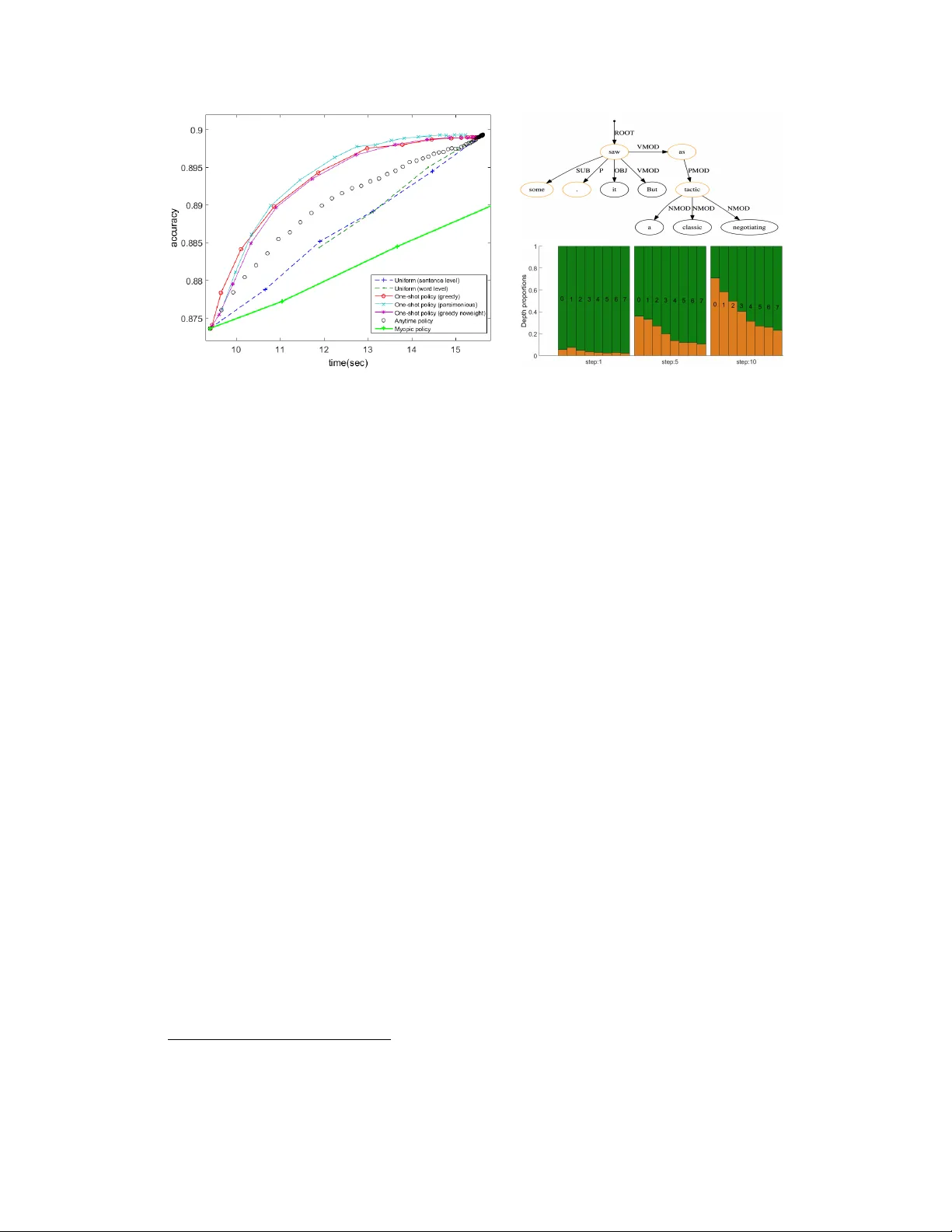
Resour ce Constrained Structur ed Pr ediction T olga Bolukbasi 1 , Kai-W ei Chang 2 , Joseph W ang 1 , V enkatesh Saligrama 1 1 Boston Univ ersity , Boston, MA 2 Microsoft Research, Cambridge, MA Abstract W e study the problem of structured prediction under test-time budget constraints. W e propose a nov el approach applicable to a wide range of structured prediction problems in computer vision and natural language processing. Our approach seeks to adaptiv ely generate computationally costly features during test-time in order to reduce the computational cost of prediction while maintaining prediction performance. W e show that training the adapti ve feature generation system can be reduced to a series of structured learning problems, resulting in ef ficient training using existing structured learning algorithms. This frame work provides theoretical justification for se veral existing heuristic approaches found in literature. W e ev aluate our proposed adaptiv e system on two structured prediction tasks, optical character recognition (OCR) and dependency parsing and sho w strong performance in reduction of the feature costs without degrading accurac y . 1 Introduction Structured prediction is a po werful and flexible frame work for making a joint prediction o ver mutually dependent output variables. It has been successfully applied to a wide range of computer vision and natural language processing tasks ranging from text classification to human detection. Ho wev er , the superior performance and flexibility of structured predictors come at the cost of computational complexity . In order to construct computationally efficient algorithms, a trade-off must be made between the expressi veness and speed of structured models. The cost of inference in structured prediction can be broken down into three parts: acquiring the features, ev aluating the part responses and solving a combinatorial optimization problem to make a prediction based on part responses. Past research has focused on ev aluating part responses and solving the combinatorial optimization problem, and proposed efficient inference algorithms for specific structures (e.g., V iterbi and CKY parsing algorithms) and general structures (e.g., variational inference [ 8 ]). Howe ver , these methods overlook feature acquisition and part response, which are bottlenecks when the underlying structure is relativ e simple or is efficiently solved. Consider the dependenc y parsing task, where the goal is to create a directed tree that describes semantic relations between words in a sentence. The task can be formulated as a structured prediction problem, where the inference problem concerns finding the maximum spanning trees (MSTs) in a directed graphs [ 12 ]. Each node in the graph represents a word, and the directed edge ( x i , x j ) represents how likely x j depends on x i . Fig. 1 shows an example of a dependency parse and the trade off between a rich set of features and the prediction time. Introducing complex features has the potential to increase system performance, ho wever the y only distinguish among a small subset of “difficult” parts. Therefore, computing complex features for all parts on every e xample is both computationally costly and unnecessary to achiev e high levels of performance. W e address the problem of structured prediction under test-time b udget constraints, where the goal is to learn a system that is computationally efficient during test-time with little loss of predictiv e performance. W e consider test-time costs associated with the computational cost of ev aluating feature transforms or acquiring ne w sensor measurements. Intuitively , our goal is to learn a system Root I saw a friend today Figure 1: Left: When predicting the dependency tree, some dependencies (e.g., the dashed edges) are easily resolved, and there is less need for e xpressiv e features in making a prediction. Right: Our system diagram and operating region. When relativ ely feature and inference costs are both not insignificant the policy must carefully balance the ov erhead costs due to feedback from the predictor with feature acquisition costs. that identifies the parts in each example incorrectly classified/localized using “cheap” features and additionally yield large reductions in error over the entire structure gi ven “expensi ve” features due to improv ed distinguishability and relationships to other parts in the example. W e consider two forms of the budgeted structured learning problem, prediction under e xpected budget constraints and anytime prediction. For both cases, we consider the streaming test-time scenario where the system operates on each test example without observation or interaction of other test examples. In the expected budg et constraint setting, the system chooses features to acquire for each example, to minimize prediction error subject to an av erage feature cost constraint. A fixed budget is giv en by the user during training time, and during test-time, the system is tasked with both allocating resources as well as determining the features to be acquired with the allocated resources. In the anytime structur ed pr ediction setting, the system chooses features to be acquired sequentially for each example to minimize prediction error at each time step, allo wing for accurate prediction at anytime. No budget is specified by the user during training time. Instead,the system sequentially chooses features to minimize prediction error at any time as features are acquired. This setting requires a single system able to predict for any b udget constraint on each example. W e learn systems capable of adaptiv e feature acquisition for both settings. W e propose learning polic y functions to exploit relationships between parts and adapt to varying length e xamples. This problem naturally reduces policy learning to a structured learning problem, allo wing the original model to be used with minor modification. The resulting systems reduce prediction cost during test-time with minimal loss of predictiv e performance. W e summarize our contributions as follo ws: • Formulation of structured prediction under expected b udget constraints and anytime prediction. • Reduction of both these settings to conv entional structured prediction problems. • Demonstration that structured models benefit from having access to features of multiple complexi- ties and can perform well when a only a subset of parts use the expensi ve features. 2 Budgeted Structured Learning W e begin with re viewing structured prediction problem and formulating it under an expected b udget constraint. W e then extend the formulation to anytime structured prediction. Structured Prediction: The goal in structured prediction is to learn a function, F , that maps from an input space, X , to a structure space, Y . In contrast to multi-class classification, the space of outputs Y is not simply categorical but instead is assumed to be some exponential space of outputs (often of varying size dependent on the feature space) containing some underlying structure, generally represented by multiple parts and relationships between parts. For e xample, in dependency parsing, x ∈ X are features representing a sentence (e.g., words, pos tags), and y ∈ Y is a parse tree. In a structured prediction model, the mapping function F is often modeled as F ≡ max y ∈ Y Ψ( x, y ) , where Ψ : ( X, Y ) → R is a scoring function. W e assume the score can be broken up into sub-scores across components C , Ψ( x, y ) = P c ∈ C ψ c ( x, y c ) , where y c is the output assignment associated with the component c . The number of sub-components, | C | , varies across e xamples. For the dependency parsing example, each c is an edge in the directed graphs, and y c is an indicator variable for whether the edge is in the parse tree. The score of a parse tree consists of the scores ψ c ( x, y c ) of all its edges. 2.1 Structured Prediction Under an Expected Budget Our goal is to reduce the cost of prediction during test-time (representing computational time, energy consumption, etc.). W e consider the case where a v ariety of scoring functions are a vailable to be used for each component. Additionally , associated with each scoring function is an ev aluation cost (such as the time or energy consumption required to e xtract the features for the scoring function). 2 For each example, we define a state S ∈ S , where the space of states is defined S = { 0 , 1 } K ×| C | , representing which of the K features is used for the | C | components during prediction. In the state, the element S ( k , c ) = 1 indicates that the k th feature will be used during prediction for component c . For any state S , we define the ev aluation cost: c ( S ) = P c ∈ C P k ∈ K S ( k , c ) δ k , where δ k is the (known) cost of e valuating the k th feature for a single part. W e assume that we are giv en a structured prediction model F : X × S → Y that maps from a set of features X ∈ X and a state S ∈ S to a structured label prediction ˆ Y ∈ Y . For a predicted label, we ha ve a loss L : Y × Y → R that maps from a predicted and true structured label, ˆ Y and Y , respectiv ely , to an error cost, generally either an indicator error , L ( ˆ Y , Y ) = 1 − Q k i =1 1 ˆ Y ( i )= Y ( i ) , or a Hamming error, L ( ˆ Y , Y ) = P k i =1 1 ˆ Y ( i ) 6 = Y ( i ) . For an example ( X, Y ) and state S , we now define the modified loss C ( X , Y , S ) = L ( F ( X, S ) , Y ) + λc ( S ) that represents the error induced by predicting a label from X using the sensors in S combined with the cost of acquiring the sensors in S , where λ is a trade-off pattern adjusted according to the budget B 1 . A small value of λ encourages correct classification at the expense of feature cost, whereas a large value of λ penalizes use of costly features, enforcing a tighter budget constraint. W e define a policy π : X → S that maps from the feature space X and the initial state S 0 to a new state. For ease of reference, we refer to this policy as the feature selection policy . Our goal is to learn a policy π chosen from a family of functions Π that, for a giv en example X , maps to a state with minimal expected modified loss, π ∗ = argmin π ∈ Π E D [ C ( X , Y , π ( X ))] . In practice, D denotes a set of I.I.D training examples: π ∗ = argmin π ∈ Π X n i =1 C ( X i , Y i , π ( X i )) . (1) Note that the objectiv e of the minimization can be expanded with respect to the space of states, allowing the optimization problem in (1) to be expressed π ∗ = argmin π ∈ Π P n i =1 P S ∈S C ( X i , Y i , S ) 1 π ( X i )= S . From this, we can reformulate the problem of learning a policy as a structured learning problem. Theorem 2.1. The minimization in (1) is equivalent to the structur ed learning pr oblem: argmin π ∈ Π n X i =1 X S ∈S max ˜ S ∈S C ( X i , Y i , ˜ S ) − C ( X i , Y i , S ) 1 π ( X i ) 6 = S . Proofs can be found in Suppl. Material. Theorem 2.1 maps the polic y learning problem in (1) to a weighted structured learning problem. For each example X i , an example/label pair is created for each state S with an importance weight representing the savings lost by not choosing the state S . Unfortunately , the expansion of the cost function o ver the space of states introduces the summation ov er the combinatorial space of states. T o av oid this, we instead introduce an approximation to the objectiv e in (1). Using a single indicator function, we formulate the approximate policy ˆ π = argmin π ∈ Π X n i =1 " W ( X i , Y i ) 1 π ( X i ) 6 = S ∗ ( X i ,Y i ) + C ( X i , Y i , S ∗ ( X i , Y i )) # , (2) where the pseudo-label is defined: S ∗ ( X i , Y i ) = argmin S ∈S C ( X i , Y i , S ) (3) and the example weight is defined as W ( X i , Y i ) = max S 0 ∈S C ( X i , Y i , S 0 ) − C ( X i , Y i , S ∗ ( X i , Y i )) . This formulation reduces the objecti ve from a summation over the combinatorial set of states to a single indicator function for each example and represents an upper -bound on the original risk. Theorem 2.2. The objective in (2) is an upper-bound on the objective in (1) . Note that the second term (2) is not dependent on π . Thus, Theorem 2.2 leads to an efficient algorithm for learning a policy function π by solving an importance-weighted structured learning problem: ˆ π = argmin π ∈ Π X n i =1 W ( X i , Y i ) 1 π ( X i ) 6 = S ∗ ( X i ,Y i ) , (4) where each example X i having a pseudo-label S ∗ ( X i , Y i ) and importance weight W ( X i , Y i ) . 1 Our framew ork does not restrict the type of modified loss, C ( X, Y , S ) , or the state cost, C ( S ) and extends to general losses 3 Combinatorial Search Space: Finding the psuedo-label in Eqn. (3) in v olves searching over the combinatorially large search space of states, S , which is computationally intractable. Instead, we present trajectory-based and parsimonious pseudo-labels for approximating S ∗ . T rajectory Sear ch: The trajectory-based pseudo-label is a greedy approximation to the optimization in Eqn. (3) . T o this end, define S + i as the 1-stage feasible transitions: S t i = { S | d ( S, ˆ S t − 1 i ) ≤ 1 , S ∧ ˆ S t − 1 i = ˆ S t − 1 i } , where d is the Hamming distance. W e define a trajectory of states ˆ S t i where ˆ S t i = argmin S ∈S t i C ( X i , Y i , S ) . The initial state is assumed to be ˆ S 0 i = 0 K ×| C | where none of the K features are ev aluated for the C components. For each example i , we obtain a trajectory S 0 i , S 1 i , . . . , S T i , where the terminal state S T i is the all-one state. W e choose the pseudo-label from the trajectory: ˆ S ∗ i = argmin S ∈{ ˆ S 0 i ,..., ˆ S T i } C ( X i , Y i , S ) . Note that by restricting the search space of states differing by a single component, the approximation needs to only perform a polynomial search ov er states as opposed to the exhausti ve combinatorial search in Eqn. (3) . Observe that the modified loss is not strictly decreasing, as the cost of adding features may outweigh the reduction in loss at an y time. Empirically , this approach is computationally tractable and is shown to produce strong results. P arsimonious Searc h: Rather than a trajectory search, which requires an inference update as we acquire more features, we consider an alternativ e one stage update here. The idea is to look for 1-step transitions that can potentially improve the cost. W e then simultaneously up- date all the features that produce improvement. This obviates the need for a trajectory search. In addition we can incorporate a guaranteed loss improv ement for our parsimonious search. S + i ∈ argmin S ∈S t i 1 { C ( X i ,Y i ,S t − 1 i ) ≥ C ( X i ,Y i ,S )+ τ } . Note that the potential candidate transitions can be non-unique and thus we generate a collection of potential state transitions, S + i . T o obtain the final state we take the union o ver these transitions, namely , ˆ S ∗ = W S ∈S + i S. Suppose we set the margin τ = 0 , replace the cost-function with the loss function then this optimization is relatively simple (assuming that acquiring more features does not increase the loss). This is because the ne w state is simply the collection of transitions where the sub-components are incorrect. Finding the parsinomious pseudo-label is computationally efficient and empirically shows similar performance to the trajectory-based pseudo-label. Choosing the pseudo-label requires kno wledge of the budget B to set the cost trade-of f parameter λ . If the b udget is unspecified or v aries ov er time, a system capable of adapting to changing b udget demands is necessary . T o handle this scenario, we propose an anytime system in the next section. 2.2 Anytime Structured Prediction In many applications, the budget constraint is unknown a priori or v aries from example to example due to changing resource av ailability and an expected b udget system as in Section 2.1 does not yield a feasible system. W e instead consider the problem of learning an anytime system [ 6 ]. In this setting, a single system is designed such that when a new example arriv es during test-time, features are acquired until an arbitrary b udget constraint (that may v ary over dif ferent examples) is met for the particular example. Note that an anytime system is a special case of the expected b udget constrained system. Instead of an expected b udget, instead a hard per-example b udget is gi ven. A single system is applied to all feasible budgets, as opposed to learning unique systems for each b udget constraint. W e model the anytime learning problem as sequential state selection. The goal is to select a trajectory of states, starting from an initial state S 0 = 0 k ×| C | where all components use features with ne gligible cost. T o select this trajectory of states, we define polic y functions π 1 , . . . , π T , where π t : X × S → S is a function that maps from a set of structured features X and current state S to a new state S 0 . The sequential selection system is then defined by the policy functions π 1 , . . . , π T . For an example X , the policy functions produce a trajectory of states S 1 ( X ) . . . , S T ( X ) defined as follo ws: S t ( X ) = π t ( X, S t − 1 ( X )) , S 0 ( X ) = S 0 . Our goal is to learn a system with small expected loss at any time t ∈ [0 , T ] . Formally , we define this as the av erage modified loss of the system ov er the trajectory of states: π ∗ 1 , ...,π ∗ T = argmin π 1 ,...,π T ∈ Π (1 /T ) E D X T t =1 C X, Y , S t ( X ) (5) 4 Algorithm 1 Anytime Polic y Learning input T raining set, { X i , Y i } i =1 ,...,n set S 0 i = 0 ∀ i = 1 , ..., n, t = 1 while A ( S i ) 6 = ∅ for any i do T rain π t according to Thm. 2.3 for i ∈ [ n ] do Update states: S t i = π t ( X i , S t − 1 i ) t ← t + 1 retur n π = { π 1 , . . . , π T } Algorithm 2 Anytime Structured Prediction input Policy , π 1 , ..., π T , Example, X , Bud- get, B set S 0 = 0 , t = 0 while A ( S t ) 6 = ∅ and c ( S t ) < B do S t +1 = π t ( X, S t ) , t ← t + 1 retur n y = F ( X , S t ) where Π is a user-specified family of functions. Unfortunately , the problem of learning the policy functions is highly coupled due to the dependence of the state trajectory on all policy functions. Note that as there is no fixed budget, the choice of λ dictates the behavior of the an ytime system. Decreasing λ leads to larger increases in classification performance at the e xpense of budget granularity . W e propose a greedy approximation to the polic y learning problem by sequentially learning policy functions π 1 , . . . , π T that minimize the modified loss: π t = argmin π ∈ Π E D C X, Y , S t ( X ) (6) for t ∈ { 1 , . . . , T } . Note that the π t selected in (6) does not take into account the future effect on the loss in (5) . W e consider π t in (6) to be a greedy approximation as it is instead chosen to minimize the immediate loss at time t . W e restrict the output space of states for the policy π t to hav e the same non-zero components as the pre vious state with a single feature added. This space of states can be defined S ( S ) = { S 0 | d ( S 0 , S ) = 1 , S 0 ∧ S = S } , where d is the Hamming distance. Note that this mirrors the trajectory used for the trajectory-based pseudo-label. As in Section 2.1, we take an empirical risk minimization approach to learning policies. T o this end we sequentially learn a set of function π 1 , . . . , π T minimizing the risk: argmin π ∈ Π n X i =1 X s ∈S ( S t − 1 ( X i )) C ( X i , Y i , s ) 1 π ( X i ,S t − 1 ( X i ))= s , (7) enumerating ov er the space of states that the policy π t can map each example. Note that the space of states S ( S t − 1 ( X i )) may be empty if all features are acquired for example X i by step t − 1 . As in Thm. 2.1, the problem of learning the sequence of policy functions π 1 , . . . , π T can be viewed as a weighted structured learning problem. Theorem 2.3. The optimization pr oblem in (7) is equivalent to solving an importance weighted structur ed learning pr oblem using an indicator risk of the form: argmin π ∈ Π n X i =1 X s ∈S ( S t − 1 ( X i )) W ( X i , Y i , s ) 1 π ( X i ,S t − 1 ( X i )) 6 = s , (8) wher e the weight is defined: W ( X i , Y i , s ) = max s 0 ∈S ( S t − 1 ( X i )) C ( X i , Y i , s 0 ) − C ( X i , Y i , s ) . This is equivalent to an importance weighted structur ed learning pr oblem, wher e each state s in S ( S t − 1 ( X i )) defines a pseudo-label for the example X i with an associated importance max s 0 ∈S ( S t − 1 ( X i )) C ( X i , Y i , s 0 ) − C ( X i , Y i , s ) . Theorem 2.3 reduces the problem of learning a policy to an importance weighted structured learning problem. Replacement of the indicators with upper -bounding con ve x surrogate functions results in a con ve x minimization problem to learn the policies π 1 , ..., π T . In particular, use of a hinge-loss surrogate con verts this problem to the commonly used structural SVM. Experimental results sho w significant cost savings by applying this sequential polic y . The training algorithm is presented in Algorithm 1. At time t = 0 , the policy π 1 is trained to minimize the immediate loss. Giv en this policy , the states of examples at time t = 1 are fixed, and π 2 is trained to minimize the immediate loss giv en these states. The algorithm continues learning policies until ev ery feature for every e xample as been acquired. During test-time, the system sequentially applies the trained policy functions until the specified b udget is reaches, as sho wn in Algorithm 2. 5 3 Related W ork Multi-class prediction with test-time budget has recei ved significant attention (see e.g., [ 20 , 3 , 1 , 9 , 26 , 18 , 10 , 21 , 22 ]). Fundamentally , multi-class classification based approaches cannot be directly applied to structured settings for two reasons: (1) Structured Feature Selection Policy: Unlike multi- class prediction, in a structured setting, we hav e many parts with associated features and costs for each part. This often requires a coupled adaptive part by part feature selection polic y applied to v arying structures; (2) Structured Inference Costs : In contrast to multi-class prediction, structured prediction requires solving a constrained optimization problem in test-time, which is often computationally expensi ve and must be taken into account. Strubell et al. [ 16 ] improv e the speed of a parser that operates on search-based structured prediction models, where joint prediction is decomposed to a sequence of deci sions. In such a case, resource- constrained multi-class approaches can be applied, howe ver this reduction only applies to search-based models that are fundamentally dif ferent from the graph-based models we discussed (with dif ferent types of theoretical guarantees and use cases). Applying their policy to the case of graphical models requires repeated inferences, dramatically increasing the computational cost when inference is slow . 2 Similar observations apply to W eiss et al. [ 23 , 25 ], who present a scheme for adaptive feature selection assuming the computational costs of polic y ex ecution and inference are ne gligible. Their approach uses a reinforcement learning scheme, requiring inference at each step of their policy to estimate re wards. For comple x inference tasks, repeatedly ex ecuting the policy (performing inference) can negate an y computational gains induced by adapti ve feature selection (see Fig. 3 in [25]). He et al. [ 7 ] use imitation learning to adaptiv ely select features for dependency parsing. Their approach can be viewed as an approximation of Eqn. (4) with a parsimonious search. Although their policy av oids performing inference to estimate reward, multiple inferences are required for each instance due to the design of action space. Overhead is a v oided by exploiting the specific inference structure (maximal spanning tree ov er fully connected graph), and it is unclear if it can be generalized. Methods to increase the speed of inference (predicting the given part responses) ha ve been proposed [ 24 , 14 ]. These approaches can be incorporated into our approach to further reduce computational cost and therefore are complementary . More focused research has improv ed the speed of individual algorithms such as object detection using deformable parts models [ 4 , 27 ] and dependenc y parsing [ 7 , 16 ]. These methods are specialized, failing to generalize to v arying graph size and/or structures and relying on problem-specific heuristics or algorithm-specific properties. Adaptiv e features approaches hav e been designed to improv e accuracy , including easy-first decoding strategies [5, 15], ho wever these methods focus on performance as opposed to computational cost. 4 Experiments In this section, we demonstrate the effecti veness of the proposed algorithm on two structured prediction tasks in dif ferent domains: dependency parsing and OCR. W e report the results on both anytime and expected case policies and refer to the latter one as one-shot policy . Our focus is mainly on the policy and not on achie ving the state of the art performance on either of these domains. At a high-lev el, policies for resource constrained structured prediction must manage & tradeoff benefits of three resources, namely , feature acquisition costs, intermediate inferencing costs, and policy o verhead costs that decides between feature acquisition and inferencing. Some methods as described earlier account for feature costs but not inference and ov erhead costs. Other methods incorporate inference into their policy (meta-features) for selecting ne w features but do not account for the resulting polic y ov erhead. Our approach poses polic y optimization as a structured learning problem and in turn jointly optimizes these resources as demonstrated empirically in our e xperiments. W e compare our system to the Q-learning approach in [ 25 ] and two baselines: a uniform policy and a myopic policy . The uniform policy takes random part lev el actions. The uniform policy will help us show that the performance of our policy does not come from removing redundant features, but clev er allocation of them among samples. As a second baseline, we adapt the myopic policy used by 2 The equiv alent policy of [ 16 ] applied to our inference algorithm is marked as the myopic policy in our experiments. Due to the high cost of repeated inference, the resulting policy is computationally intensiv e. 6 Figure 2: An example word from the OCR test dataset is shown. Note that the word is initially incorrectly identified due to degra- dation in letters "u" and "n". The letter clas- sification accuracy increases after the polic y acquires the HOG features at strategic posi- tions. Figure 3: The performance of our one-shot policy (in red) is compared to the uniform strate gy (in black) and policy of W eiss et. al. [ 25 ] for the OCR dataset. Although the policy with complex features is more efficient with features, the simple feature policy has a lower total run-time in the low budget re gion due to the ov erhead of additional inference. [ 18 ] to the structured prediction case. The myopic policy runs the structured predictor initially on all cheap features, then looks at the total confidence of the classifier normalized by the sample size (e.g. sentence length). If the confidence is belo w a threshold, it chooses to acquire expensi ve features for all positions. Finally , we compare against the Q-learning method proposed by [ 25 ]. This method requires global features for structures with v arying size. From no w on we will refer to features that require access to more than one part as complex features and part le vel features as simple features. In their case, the y use confidence feedback from the structured predictor which induces additional inference ov erhead for the policy . In addition to this, it is not straightforward to apply this approach to do part by part feature selection on structures with varying sizes. W e adopt Structured-SVM [ 19 ] to solve the policy learning problems for expected and anytime cases defined in (4) and (8) , respectiv ely . For the structure of the policy π we use a graph with no edges due to its simplicity . In this form, the policy learning problem can be written as a sample weighted SVM. W e discuss the details in the appendix due to space constraints. W e show in the follo wing that comple x features indeed benefit the policy , but simple features perform better for cases where the inference time and feature costs are comparable and the additional o verhead is unwanted. Finally , we show that part by part selection outperforms global selection. Optical Character Recognition W e tested our algorithm on a sequence-label problem, the OCR dataset [ 17 ] composed of 6,877 handwritten words, where each word is represented as a sequence of 16x8 binary letter images. W e use a linear-chain Marko v model, and similar to the setup in [ 23 , 21 ], use raw pix el values and HOG features with 3x3 cell size as our feature templates. W e split the data such that 90% percent is used for training and 10% is used for test. Fig. 3 shows the average letter accuracy vs. total running time. The proposed system reduces the budget for all performance le vels, with a sa vings of up to 50 percent at the top performance. Note that W eiss13 can not operate on part by part level when the graph structure is varying. W e see that using complex part by part selection has significant adv antage ov er using uniform feature templates. Furthermore, Fig 2 shows the behavior of the policy on an indi vidual example for the anytime model, significant gains in accuracy are made in first se veral steps by correctly identifying the noisy letters. Dependency Parsing W e follow the setting in [ 7 ] and conduct e xperiments on English Penn Treebank (PTB) corpus [ 11 ]. All algorithms are implemented based on the graph-based dependenc y parser [ 12 ] in Illinois-SL library [ 2 ], where the code is optimized for speed. T wo sets of feature templates are considered for the parser . 3 The first ( ψ Full ) considers the part-of-speech (POS) tags and lexicons of x i , x j , and their surrounding words (see [ 12 ]). The other ( ψ POS ) only considers the POS features. 3 Complex features often contribute to small performance improvement. Adding complex or redundant features can easily yield arbitrarily large speedups, and comparing speedups of dif ferent systems with different accuracy le vels is not meaningful (see Fig. 3 in [ 7 ]). In addition, greedy-style parser such as [ 16 ] might be faster by nature. Discussing different architecture and features is outside the scope of this paper . 7 Figure 4: Left: Performance of various adapti ve policies for varying b udget le vels (dependency tree accurac y vs. total execution time), is compared to a uniform strategy on word and sentence level, and myopic policy for the 23 section of PTB dataset. Right: Distribution of parse-tree depth for words that use cheap (green) or expensi ve features (orange) for an ytime policy . Time increases from left to right. Each group of columns show the distribution of depths from 0(root) to 7. The policy is concentrated on acquiring features for lower depth words. A sentence example also sho ws this effect. It is easy to identify parents of the adjectiv es and determiner . Howe ver , additional features(orange) are required for the root(verb), subject and object. The policy assigns one of these two feature templates to each word in the sentence, such that all the directed edges ( x i , x j ) corresponding to the word x i share the same feature templates. The first feature template, ψ POS , takes 165 µ s per word and the second feature template, ψ Full , takes 275 µ s per word to extract the features and compute edge scores. The decoding by Chu–Liu-Edmonds algorithm is 75 µ s per word, supporting our hypothesis that feature extraction makes a significant portion of the total running time yet the inference time is not negligible. Due to the space limit, we present further details of the experiment setting in the appendix. Fig. 4 sho ws the test performance (unlabeled attachment accurac y) along with inference time. W e see that all one-shot policies perform similarly , losing negligible accuracy when using half of the av ailable expensiv e features. When we apply the length dictionary filtering heuristic in [ 7 , 13 ], our parser achie ves 89.7% U AS on PTB section 23 with ov erall running time merely 7.5 seconds (I/O excluded, 10s with I/O) and obtains 2.9X total speed-up with losing only 1% U AS comparing to the baseline. 4 This significant speed-up ov er an efficient implementation is remarkable. 5 Although marginal, one-shot policy with greedy trajectory has the strongest performance in lo w budget re gions. This is because the greedy trajectory search has better granularity than parsimonious search in choosing positions that decrease the loss early on. The anytime policy is belo w one-shot policy for all b udget lev els. As discussed in 2.2, the anytime policy is more constrained in that it has to achie ve a fix ed budget for all examples. The naiv e myopic policy performs worse than uniform since it has to run inference on samples with lo w confidence two times, adding approximately 4.5 seconds of extra time for the full test dataset. W e then explore the ef fect of importance weights for the greedy policy . W e notice a small improv ement. W e hypothesize that this is due to the policy functional complexity being a limiting factor . W e also conduct ablative studies to better understand the policy behavior . Fig. 4 shows the distrib ution of depth for the words that use expensiv e and cheap features in the ground truth dependency tree. W e expect in vesting more time on the low-depth words (root in the extreme) to yield higher accuracy gains. W e observe this phenomenon empirically , as the policy concentrates on extracting features close to the root. 4 This heuristic only works for parsing. Therefore, we exclude it when presenting Figure 4 as it does not reflect the performance of policies in general. 5 In contrast, the baseline system in [ 7 ] is slow than us by about three times. When operating in the accuracy lev el of 90%, Figure 3 in [ 7 ] sho ws that their final system takes about 20s. W e acknowledge that [ 7 ] use dif ferent features, policy settings, and hardware from ours; therefore these numbers might not be comparable. 8 A Proofs Proof of Theorem 2.1 The objectiv e in (1) can be expressed: n X i =1 X S ∈S C ( X i , Y i , S ) 1 π ( X i )= S = n X i =1 X S ∈S C ( X i , Y i , S ) 1 − 1 π ( X i ) 6 = S = n X i =1 " max S 0 ∈S C ( X i , Y i , S 0 ) − max S 0 ∈S C ( X i , Y i , S 0 ) + X S ∈S C ( X i , Y i , S ) 1 − 1 π ( X i ) 6 = s # . Note that P S ∈S 1 − 1 π ( X i ) 6 = S = 1 , allowing for further simplification: = n X i =1 " max S 0 ∈S C ( X i , Y i , s 0 ) + X s ∈S C ( X i , Y i , S ) − max S 0 ∈S C ( X i , Y i , S 0 ) 1 − 1 π ( X i ) 6 = S # = n X i =1 " max S 0 ∈S C ( X i , Y i , S 0 ) + X S ∈S max S 0 ∈S C ( X i , Y i , S 0 ) − C ( X i , Y i , S ) 1 π ( X i ) 6 = s − 1 # . Removing constant terms (that do not af fect the output of the argmin ) yields the expression in Thm. 2.1. Proof of Theorem 2.2 For a single e xample/label pair ( X i , Y i ) , consider the two possible v alues of the term in the summation of (4). In the ev ent that π ( X i ) = S ∗ ( X i , Y i ) : W ( X i , Y i ) 1 π ( X i ) 6 = S ∗ ( X i ,Y i ) + C ( X i , Y i , S ∗ ( X i , Y i )) = C ( X i , Y i , S ∗ ( X i , Y i )) , which is equiv alent to the value of (2) if π ( X i ) = S ∗ ( X i , Y i ) . Otherwise, π ( X i ) 6 = S ∗ ( X i , Y i ) , and therefore: W ( X i , Y i ) 1 π ( X i ) 6 = S ∗ ( X i ,Y i ) + C ( X i , Y i , S ∗ ( X i , Y i )) = W ( X i , Y i ) + C ( X i , Y i , S ∗ ( X i , Y i )) = max S 0 ∈S C ( X i , Y i , S 0 ) . This is an upper-bound on (1), and therefore (2) is a v alid upper-bound on (1). 9 Proof of Theorem 2.3 Note that the objectiv e in (7) can be expressed: n X i =1 X S ∈S ( S t − 1 ( X i )) C ( X i , Y i , S ) 1 π ( X i ,S t − 1 ( X i ))= S = n X i =1 X S ∈S ( S t − 1 ( X i )) C ( X i , Y i , S ) 1 − 1 π ( X i ,S t − 1 ( X i )) 6 = S = n X i =1 " max S 0 ∈S ( S t − 1 ( X i ) C ( X i , Y i , S 0 ) − max S 0 ∈S ( S t − 1 ( X i )) C ( X i , Y i , S 0 ) + X S ∈S ( S t − 1 ( X i )) C ( X i , Y i , S ) 1 − 1 π ( X i ,S t − 1 ( X i )) 6 = S # . Note that P S ∈S ( S t − 1 )( X i ) 1 − 1 π ( X i ,S t − 1 ( X i )) 6 = S = 1 , allowing for further simplification: = n X i =1 " max S 0 ∈S ( S t − 1 )( X i ) C ( X i , Y i , S 0 ) + X S ∈S ( S t − 1 ( X i )) C ( X i , Y i , S ) − max S 0 ∈S ( S t − 1 ( X i )) C ( X i , Y i , S 0 ) ! 1 − 1 π ( X i ,S t − 1 ( X i )) 6 = s # = n X i =1 " max S 0 ∈S ( S t − 1 ( X i )) C ( X i , Y i , S 0 ) + X S ∈S ( S t − 1 ( X i )) max S 0 ∈S ( S t − 1 )( X i )) C ( X i , Y i , S 0 ) − C ( X i , Y i , S ) ! 1 π ( X i ,S t − 1 ( X i )) 6 = S − 1 # . Removing constant terms (that do not af fect the output of the argmin ) yields the expression in (8). B Implementation details Dependency parsing W e split PTB corpus into two parts, Sections 02-22 and Section 23 as training and test sets. W e then conduct a modified cross-validation mechanism to train the feature selector and the dependency parser . Note that the cost of policy is dependent on the structured predictor . Therefore, learning policy on the same training set of the predictor may cause the structured loss to be overly optimistic. W e follow the cross validation scheme in to deal with this issue by splitting the training data into n folds. For each fold, we generate label predictions based on the structured predictor trained on the remaining folds. Finally , we gather these label predictions and train a policy on the complete data. The dependency parser is trained by the av eraged Structured Perceptron modelwith learning rate and number of epochs set to be 0.1 and 50, respecti vely . This setting achiev es the best test performance as reported in Notice that if we trained two dependency models with different feature sets separately the scale of the edge scores may be different, resulting sub-optimal test performance. T o fix this issue, we generate data with random edge features and train the model to minimize the joint loss ov er all states. min w λ || w || 2 + 1 n n X i =1 E S [ L ( F w ( X i , S ) , Y i )] Finally , W e found that for dependency parsing expensi ve features are only necessary in several critical locations in the sentence. Therefore, budget levels above 10% turned out to be unachiev able for any feature-tradeoff parameter lambda in the pseudo-labels. T o obtain those regions, we varied the class weights of feature templates in the training of one-shot feature selector . 10 References [1] R. Busa-Fekete, D. Benbouzid, and B. Kégl. Fast classification using sparse decision DA Gs. In 29th International Confer ence on Machine Learning (ICML 2012) , pages 951–958. Omnipress, 2012. [2] K.-W . Chang, S. Upadhyay , M.-W . Chang, V . Srikumar , and D. Roth. IllinoisSL: A J A V A Library for Structured Prediction. arXiv preprint , 2015. [3] M. Chen, K. Q. W einberger , O. Chapelle, D. Kedem, and Z. Xu. Classifier cascade for minimizing feature ev aluation cost. In International Conference on Artificial Intelligence and Statistics , pages 218–226, 2012. [4] P . F . Felzenszwalb, R. B. Girshick, D. McAllester , and D. Ramanan. Object detection with discriminati vely trained part-based models. P attern Analysis and Machine Intelligence, IEEE T ransactions on , 32(9):1627– 1645, 2010. [5] Y . Goldberg and M. Elhadad. An efficient algorithm for easy-first non-directional dependency parsing. In Human Language T echnologies: The 2010 Annual Confer ence of the North American Chapter of the Association for Computational Linguistics , pages 742–750. Association for Computational Linguistics, 2010. [6] A. Grubb and D. Bagnell. Speedboost: Anytime prediction with uniform near-optimality. In International Confer ence on Artificial Intelligence and Statistics , pages 458–466, 2012. [7] H. He, H. Daumé III, and J. Eisner . Dynamic Feature Selection for Dependenc y Parsing. In EMNLP , pages 1455–1464, 2013. [8] M. I. Jordan, Z. Ghahramani, T . S. Jaakkola, and L. K. Saul. An introduction to v ariational methods for graphical models. Machine learning , 37(2):183–233, 1999. [9] S. Karayev , M. Fritz, and T . Darrell. Dynamic feature selection for classification on a budget. In International Confer ence on Machine Learning (ICML): W orkshop on Prediction with Sequential Models , 2013. [10] M. J. Kusner , W . Chen, Q. Zhou, Z. E. Xu, K. Q. W einberger , and Y . Chen. Feature-Cost Sensiti ve Learning with Submodular T rees of Classifiers. In AAAI , pages 1939–1945, 2014. [11] M. P . Marcus, M. A. Marcinkie wicz, and B. Santorini. Building a large annotated corpus of English: The Penn T reebank. Computational linguistics , 19(2):313–330, 1993. [12] R. McDonald, F . Pereira, K. Ribarov , and J. Haji ˇ c. Non-projective dependency parsing using spanning tree algorithms. In Pr oceedings of the conference on Human Langua ge T echnology and Empirical Methods in Natural Languag e Pr ocessing , pages 523–530. Association for Computational Linguistics, 2005. [13] A. Rush and S. Petrov . V ine pruning for efficient multi-pass dependency parsing learned prioritization for trading off accurac y and speed. In NAA CL , 2012. [14] T . Shi, J. Steinhardt, and P . Liang. Learning Where to Sample in Structured Prediction. In AIST ATS , 2015. [15] V . Stoyanov and J. Eisner . Easy-first Coreference Resolution. In COLING , pages 2519–2534. Citeseer , 2012. [16] E. Strubell, L. V ilnis, K. Silverstein, and A. McCallum. Learning Dynamic Feature Selection for Fast Sequential Prediction. arXiv preprint , 2015. [17] B. T askar, C. Guestrin, and D. K oller . Max-Margin Marko v Networks. In Advances in Neural Information Pr ocessing Systems , page None, 2003. [18] K. T rapeznikov and V . Saligrama. Supervised sequential classification under budget constraints. In Pr oceedings of the Sixteenth International Confer ence on Artificial Intelligence and Statistics , pages 581–589, 2013. [19] I. Tsochantaridis, T . Joachims, T . Hofmann, and Y . Altun. Large margin methods for structured and interdependent output variables. In Journal of Machine Learning Resear ch , pages 1453–1484, 2005. [20] P . V iola and M. Jones. Robust real-time object detection. International Journal of Computer V ision , 4, 2001. [21] J. W ang, T . Bolukbasi, K. Trapezniko v , and V . Saligrama. Model selection by linear programming. In Computer V ision–ECCV 2014 , pages 647–662. Springer , 2014. [22] J. W ang, K. T rapeznikov , and V . Saligrama. An LP for Sequential Learning Under Budgets. In Pr oceedings of the Seventeenth International Confer ence on Artificial Intelligence and Statistics , pages 987–995, 2014. [23] D. W eiss, B. Sapp, and B. T askar. Dynamic structured model selection. In Pr oceedings of the IEEE International Confer ence on Computer V ision , pages 2656–2663, 2013. [24] D. W eiss and B. T askar . Structured Prediction Cascades. In International Conference on Artificial Intelligence and Statistics , pages 916–923, 2010. 11 [25] D. J. W eiss and B. T askar . Learning adaptiv e value of information for structured prediction. In Advances in Neural Information Pr ocessing Systems , pages 953–961, 2013. [26] Z. Xu, M. Kusner , M. Chen, and K. Q. W einberger . Cost-Sensitiv e T ree of Classifiers. In Pr oceedings of the 30th International Confer ence on Machine Learning (ICML-13) , pages 133–141, 2013. [27] M. Zhu, N. Atanasov , G. J. Pappas, and K. Daniilidis. Active deformable part models inference. In Computer V ision–ECCV 2014 , pages 281–296. Springer , 2014. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment