예산 제한 구조 예측을 위한 적응형 특징 선택
본 논문은 테스트 시 예산(시간·에너지·연산량) 제약이 있는 구조화 예측 문제를 다룬다. 비용이 높은 복잡 특징을 필요할 때만 선택적으로 사용하도록 정책을 학습하고, 이를 기존 구조 학습 프레임워크에 매핑함으로써 효율적인 학습과 추론을 가능하게 한다. 기대 예산 제약과 언제든 중단 가능한(anytime) 두 상황을 모두 모델링하고, OCR 및 의존 구문 분석 실험을 통해 정확도 손실 없이 특징 비용을 크게 절감함을 보인다.
저자: Tolga Bolukbasi, Kai-Wei Chang, Joseph Wang
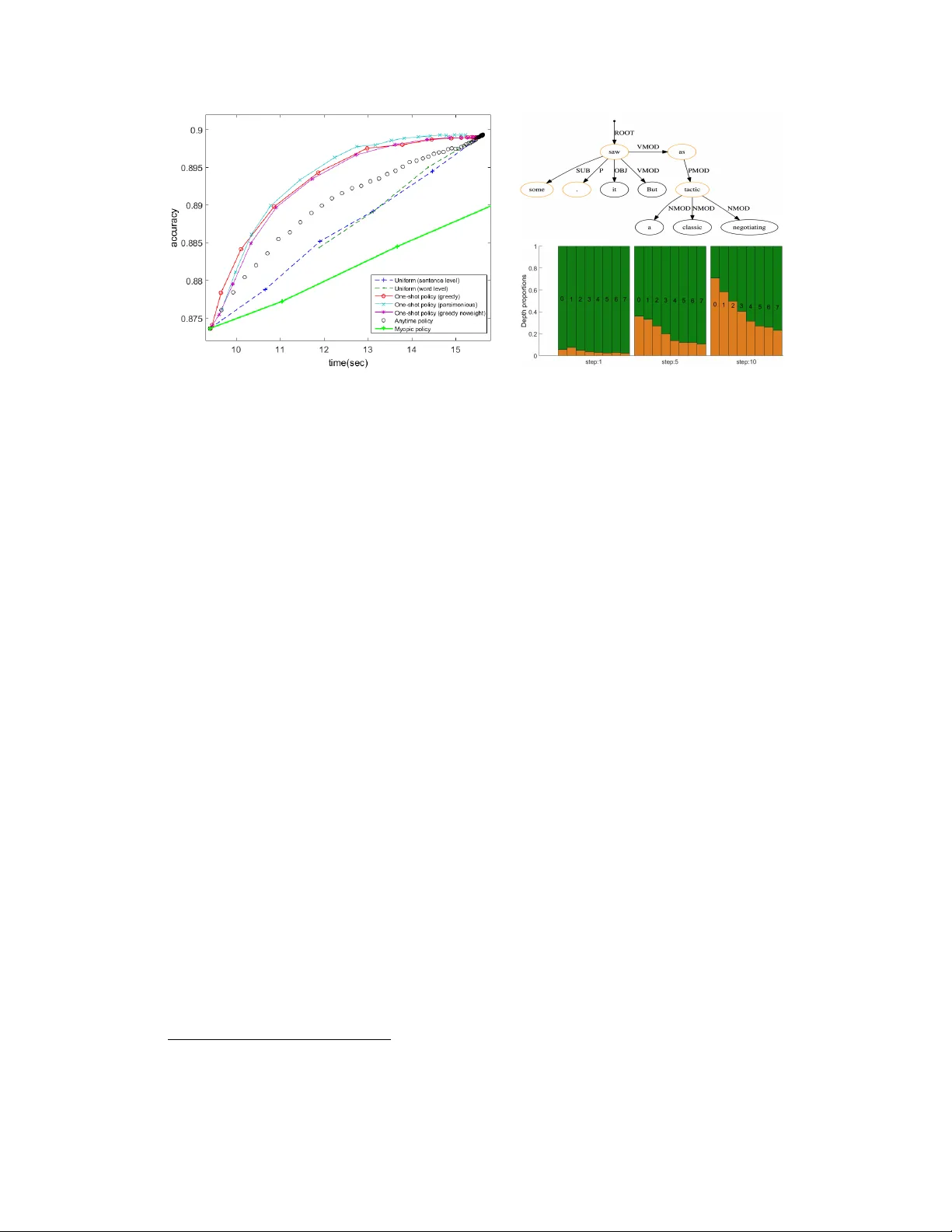
본 논문은 테스트 단계에서 예산(시간, 에너지, 연산량 등) 제약이 있는 구조화 예측 문제를 해결하기 위한 새로운 프레임워크를 제시한다. 구조화 예측은 이미지 분할, 텍스트 라벨링, 의존 구문 분석 등 다양한 분야에서 입력 X와 복합적인 출력 Y(예: 트리, 라벨 시퀀스)를 매핑하는 모델 F를 학습한다. 전통적인 연구는 주로 파트 응답 계산이나 조합 최적화 단계의 효율성에 초점을 맞추었지만, 저자는 특징 획득 자체가 큰 비용을 차지할 수 있음을 강조한다. 특히 복잡한 특징은 일부 “어려운” 파트에만 필요하고, 모든 파트에 일괄 적용하면 불필요한 연산이 발생한다.
이를 해결하기 위해 저자는 각 파트 c∈C에 대해 K개의 서로 다른 복잡도의 특징 집합을 정의하고, 상태 변수 S∈{0,1}^{K×|C|} 로 어떤 파트에 어떤 특징을 사용할지를 표시한다. 각 특징 k는 단위 비용 δ_k 를 갖는다. 상태 S에 대한 총 비용은 c(S)=∑_{c∈C}∑_{k∈K}S(k,c)·δ_k 로 정의된다. 모델 F는 입력 X와 상태 S를 받아 예측 Ȳ=F(X,S)를 생성한다. 예측 손실 L(Ȳ,Y)와 비용을 결합한 수정 손실 C(X,Y,S)=L(F(X,S),Y)+λ·c(S) 를 최소화하는 것이 목표이며, λ는 예산 제약을 조정하는 파라미터이다.
논문은 두 가지 예산 제약 시나리오를 다룬다. 첫 번째는 “예상 예산 제약(expected budget)”으로, 전체 테스트 집합에 대해 평균 비용이 사전에 정해진 B 이하가 되도록 하는 것이다. 이 경우 정책 π:X→S 를 학습해 각 예제마다 최적의 특징 집합을 선택한다. 목표 함수는 π* = argmin_{π∈Π} E_{(X,Y)∼D}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기