Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
Learning goal-directed behavior in environments with sparse feedback is a major challenge for reinforcement learning algorithms. The primary difficulty arises due to insufficient exploration, resulting in an agent being unable to learn robust value f…
Authors: Tejas D. Kulkarni, Karthik R. Narasimhan, Ardavan Saeedi
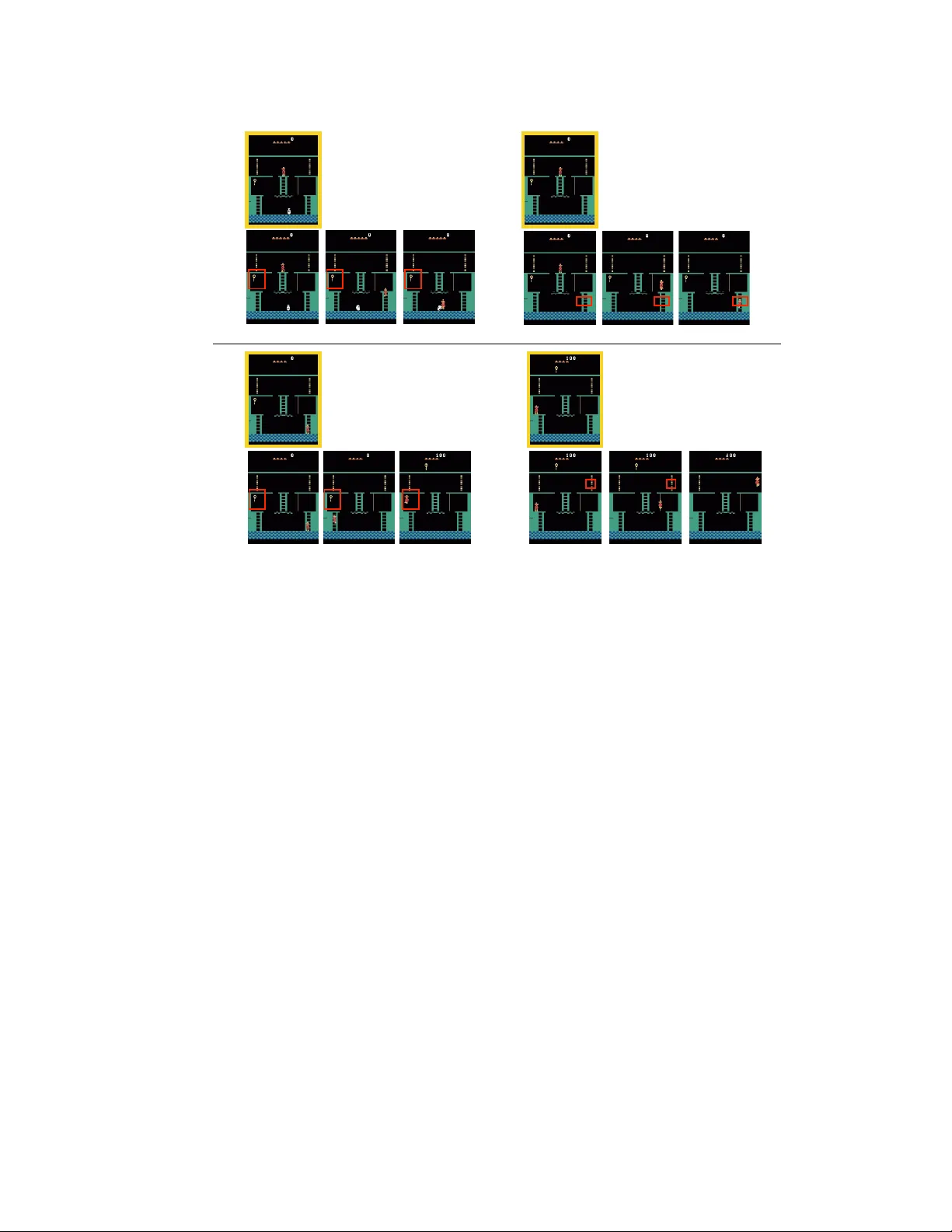
Hierarc hical Deep Reinforcemen t Learning: In tegrating T emp oral Abstraction and In trinsic Motiv ation T ejas D. Kulk arni ∗ BCS, MIT tejask@mit.edu Karthik R. Narasimhan ∗ CSAIL, MIT karthikn@mit.edu Arda v an Saeedi CSAIL, MIT ardavans@mit.edu Josh ua B. T enen baum BCS, MIT jbt@mit.edu Abstract Learning goal-directed b eha vior in environmen ts with sparse feedback is a ma jor c hallenge for reinforcemen t learning algorithms. The primary difficult y arises due to insufficien t exploration, resulting in an agent being unable to learn robust v alue functions. Intrinsically motiv ated agen ts can explore new b eha vior for its o w n sak e rather than to directly solve problems. Suc h in trinsic b ehaviors could ev entually help the agen t solv e tasks p osed b y the en vironment. W e presen t hierarchical-DQN (h-DQN), a framew ork to integrate hierarc hical v alue functions, op erating at differen t temp oral scales, with intrinsically motiv ated deep reinforcement learning. A top-lev el v alue function learns a p olicy ov er intrinsic goals, and a lo wer-lev el function learns a p olicy o v er atomic actions to satisfy the giv en goals. h-DQN allo ws for flexible goal sp ecifications, such as functions o ver en tities and relations. This pro vides an efficien t space for exploration in complicated environmen ts. W e demonstrate the strength of our approach on tw o problems with very sparse, delay ed feedback: (1) a complex discrete sto c hastic decision pro cess, and (2) the classic A T ARI game ‘Mon tezuma’s Rev enge’. 1 In tro duction Learning goal-directed b ehavior with sparse feedback from complex environmen ts is a fundamen tal challenge for artificial intelligence. Learning in this setting requires the agent to represent kno wledge at multiple lev els of spatio-temp oral abstractions and to explore the environmen t efficiently . Recen tly , non-linear function appro ximators coupled with reinforcemen t learning [ 21 , 28 , 37 ] ha ve made it p ossible to learn abstractions ov er high- dimensional state spaces, but the task of exploration with sparse feedbac k still remains a ma jor c hallenge. Existing methods like Boltzmann exploration and Thomson sampling [ 45 , 32 ] offer significant improv ements ov er -greedy , but are limited due to the underlying mo dels functioning at the level of basic actions. In this work, w e prop ose a framework that integrates deep reinforcement learning with hierarchical v alue functions (h-DQN), where the agent is motiv ated to solve in trinsic goals (via learning options) to aid exploration. These goals pro vide for efficien t exploration and help mitigate the sparse feedbac k problem. Additionally , w e observ e that goals defined in the space of en tities and relations can help significantly constrain the exploration space for data-efficien t learning in complex en vironmen ts. ∗ Authors contributed equally and listed alphabetically . 1 Reinforcemen t learning (RL) formalizes con trol problems as finding a policy π that maximizes exp ected future rewards [ 46 ]. V alue functions V ( s ) are central to RL, and they cache the utilit y of any state s in ac hieving the agent’s ov erall ob jective. Recen tly , v alue functions hav e also been generalized as V ( s, g ) in order to represent the utility of state s for ac hieving a given goal g ∈ G [ 47 , 34 ]. When the environmen t provides delay ed rewards, we adopt a strategy to first learn wa ys to achiev e intrinsically generated goals, and subsequently learn an optimal p olicy to chain them together. Eac h of the v alue functions V ( s, g ) can b e used to generate a p olicy that terminates when the agent reaches the goal state g . A collection of these policies can b e hierarc hically arranged with temp oral dynamics for learning or planning within the framew ork of semi-Mark o v decision pro cesses [48, 49]. In high-dimensional problems, these v alue functions can b e appro ximated b y neural net w orks as V ( s, g ; θ ). W e propose a framework with hierarc hically organized deep reinforcement learning mo dules w orking at differen t time-scales. The model tak es decisions ov er t w o levels of hierarc hy – (a) the top level mo dule ( meta-c ontr ol ler ) takes in the state and pic ks a new goal, (b) the lo w er-level mo dule ( c ontr ol ler ) uses b oth the state and the chosen goal to select actions either un til the goal is reached or the episo de is terminated. The meta-c ontr ol ler then chooses another goal and steps (a-b) rep eat. W e train our mo del using sto chastic gradient descent at different temp oral scales to optimize exp ected future intrinsic ( c ontr ol ler ) and extrinsic rew ards ( meta-c ontr ol ler ). W e demonstrate the strength of our approach on problems with long-range dela y ed feedbac k: (1) a discrete stochastic decision pro cess with a long chain of states before receiving optimal extrinsic rewards and (2) a classic A T ARI game (‘Mon tezuma’s Rev enge’) with even longer-range delay ed rewards where most existing state-of-art deep reinforcemen t learning approac hes fail to learn p olicies in a data-efficient manner. 2 Literature Review 2.1 Reinforcemen t Learning with T emp oral Abstractions Learning and operating o v er different levels of temp oral abstraction is a key challenge in tasks in v olving long-range planning. In the context of reinforcement learning [1], Sutton et al.[ 48 ] prop osed the options framework, whic h inv olves abstractions o ver the space of actions. A t each step, the agen t c ho oses either a one-step “primitive” action or a “m ulti-step” action p olicy (option). Eac h option defines a policy o ver actions (either primitiv e or other options) and can b e terminated according to a sto chastic function β . Th us, the traditional MDP setting can b e extended to a semi-Marko v decision pro cess (SMDP) with the use of options. Recen tly , sev eral methods ha ve b een prop osed to learn options in real-time by using v arying rew ard functions [ 49 ] or by comp osing existing options [ 42 ]. V alue functions hav e also b een generalized to consider goals along with states [ 34 ]. This universal v alue function V ( s, g ; θ ) pro vides an universal option that approximately represen ts optimal b ehavior tow ards the goal g . Our work is inspired by these pap ers and builds up on them. There has also been a lot of work on option discov ery in the tabular v alue function setting [ 26 , 38 , 25 , 27 ]. In more recen t w ork, Machado et al. [ 24 ] presen ted an option disco very algorithm where the agent is encouraged to explore regions that w ere previously out of reac h. Ho w ever, option disco v ery where non-linear state approximations are required is still an op en problem. Other related work for hierarchical formulations include the mo del of Day an and Hinton [ 6 ] whic h consisted of “managers” taking decisions at v arious levels of gran ularit y , p ercolating all the w a y do wn to atomic actions made by the agent. The MAXQ framework [ 7 ] built up on this work to decomp ose the v alue function of an MDP into combinations of v alue functions of smaller constituen t MDPs, as did Guestrin et al.[ 17 ] in their factored MDP formulation. Hernandez-Gardiol and Mahadev an [ 19 ] combined hierarchical RL with a v ariable length short-term memory of high-lev el decisions. In our w ork, we prop ose a scheme for temp oral abstraction that inv olves simultaneously learning options and a control p olicy to comp ose options in a deep reinforcemen t learning setting. Our approach do es not use separate Q-functions for eac h option, but instead treats the option as part of the input, similar to [ 34 ]. This has t wo adv an tages: (1) there is shared 2 learning b etw een different options, and (2) the mo del is p otentially scalable to a large n um b er of options. 2.2 In trinsically motiv ated RL The nature and origin of ‘goo d’ intrinsic reward functions is an open question in reinf orcemen t learning. Singh et al.[ 41 ] explored agents with intrinsic reward structures in order to learn generic options that can apply to a wide v ariety of tasks. Using a notion of “salient ev ents” as sub-goals, the agent learns options to get to such ev ents. In another pap er, Singh et al.[ 40 ] take an evolutionary p ersp ective to optimize o v er the space of reward functions for the agent, leading to a notion of extrinsically and intrinsically motiv ated b eha vior. In the con text of hierarchical RL, Go el and Hub er [ 13 ] discuss a framework for subgoal discov ery using the structural asp ects of a learned p olicy model. S ¸ im¸ sek et al. [ 38 ] provide a graph partioning approac h to subgoal iden tification. Sc hmidh ub er [ 36 ] provides a coherent form ulation of intrinsic motiv ation, which is measured b y the improv ements to a predictive world mo del made by the learning algorithm. Mohamed and Rezende [ 29 ] hav e recently prop osed a notion of in trinsically motiv ated learning within the framew ork of mutual information maximization. F rank et al. [ 11 ] demonstrate the effectiv eness of artificial curiosity using information gain maximization in a humanoid rob ot. 2.3 Ob ject-based RL Ob ject-based represen tations [ 8 , 4 ] that can exploit the underlying structure of a problem ha v e b een prop osed to alleviate the curse of dimensionality in RL. Diuk et al.[ 8 ] prop ose an Obje ct-Oriente d MDP , using a represen tation based on ob jects and their in teractions. Defining eac h state as a set of v alue assignments to all p ossible relations b etw een ob jects, they in tro duce an algorithm for solving deterministic ob ject-orien ted MDPs. Their represen tation is similar to that of Guestrin et al.[ 16 ], who describ e an ob ject-based represen tation in the con text of planning. In contrast to these approaches, our represen tation do es not require explicit enco ding for the relations b etw een ob jects and can b e used in sto chastic domains. 2.4 Deep Reinforcement Learning Recen t adv ances in function approximation with deep neural netw orks hav e shown promise in handling high-dimensional sensory input. Deep Q-Net works and its v ariants hav e b een successfully applied to v arious domains including Atari games [ 28 ] and Go [ 37 ], but still p erform p o orly on environmen ts with sparse, delay ed reward signals. Strategies such as prioritized exp erience replay [ 35 ] and b o otstrapping [ 32 ] hav e b een prop osed to alleviate the problem of learning from sparse rewards. These approaches yield significant improv ements o v er prior w ork but struggle when the rew ard signal has a long dela yed horizon. This is b ecause the exploration strategy is not sufficien t for the agent to obtain the required feedbac k. 2.5 Cognitiv e Science and Neuroscience The nature and origin of intrinsic goals in humans is a thorny issue but there are some notable insights from existing literature. There is conv erging evidence in developmen tal psyc hology that human infants, primates, children, and adults in div erse cultures base their core kno wledge on certain cognitiv e systems including – entities, agen ts and their actions, numerical quantities, space, so cial-structures and intuitiv e theories [ 43 , 23 ]. Even newb orns and infants seem to represen t the visual world in terms of coherent visual entities, cen tered around spatio-temp oral principles of cohesion, contin uity , and contact. They also seem to explicitly represent other agents, with the assumption that an agen t’s b ehavior is goal-directed and efficien t. Infants can also discriminate relative siz es of ob jects, relative distances and higher order numerical relations such as the ratio of ob ject sizes. During curiosit y-driv en activities, to ddlers use this knowledge to generate in trinsic goals suc h as building physically stable blo ck structures. In order to accomplish these goals, to ddlers seem to construct sub-goals in the space of their core knowledge, such as – putting a hea vier entit y on top of (relation) a ligh ter entit y in order to build tall blo c ks. 3 Kno wledge of space can also b e utilized to learn a hierarchical decomp osition of spatial en vironmen ts, where the b ottlenecks b etw een different spatial groupings corresp ond to sub-goals. This has b een explored in neuroscience with the successor representation, which represen ts a v alue function in terms of the expected future state occupancy . Decomp osition of the successor representation yields reasonable sub-goals for spatial na vigation problems [5, 12, 44]. Botvinick et al.[3] hav e written a general ov erview of hierarchical reinforcement learning in the con text of cognitiv e science and neuroscience. 3 Mo del Consider a Marko v decision pro cess (MDP) represented b y states s ∈ S , actions a ∈ A , and transition function T : ( s, a ) → s 0 . An agent op erating in this framew ork receives a state s from the external environmen t and can take an action a , which results in a new state s 0 . W e define the extrinsic rew ard function as F : ( s ) → R . The ob jectiv e of the agen t is to maximize this function ov er long p erio ds of time. F or example, this function can take the form of the agen t’s surviv al time or score in a game. Agen ts Effectiv e exploration in MDPs is a significant challenge in learning go o d control p olicies. Metho ds such as -greedy are useful for lo cal exploration but fail to pro vide imp etus for the agent to explore different areas of the state space. In order to tackle this, w e utilize a notion of go als g ∈ G , which provide intrinsic motiv ation for the agent. The agen t fo cuses on setting and ac hieving sequences of goals in order to maximize cumulativ e extrinsic rew ard. W e use the temp oral abstraction of options [ 48 ] to define p olicies π g for eac h goal g . The agen t learns these option p olicies sim ultaneously along with learning the optimal sequence of goals to follow. In order to learn each π g , the agent also has a critic, which provides intrinsic r ewar ds , based on whether the agent is able to achiev e its goals (see Figure 1). T emp oral Abstractions As shown in Figure 1, the agent uses a tw o-stage hierarch y consisting of a c ontr ol ler and a meta-c ontr ol ler . The meta-con troller receives state s t and c ho oses a goal g t ∈ G , where G denotes the set of all p ossible current goals. The controller then selects an action a t using s t and g t . The goal g t remains in place for the next few time steps either un til it is achiev ed or a terminal state is reached. The internal critic is responsible for ev aluating whether a goal has b een reac hed and providing an appropriate reward r t ( g ) to the con troller. The ob jective function for the controller is to maximize cumulativ e intrinsic rew ard: R t ( g ) = P ∞ t 0 = t γ t 0 − t r t 0 ( g ). Similarly , the ob jective of the meta-controller is to optimize the cumulativ e extrinsic reward F t = P ∞ t 0 = t γ t 0 − t f t 0 , where f t are rew ard signals receiv ed from the en vironmen t. One can also view this setup as similar to optimizing ov er the space of optimal rew ard functions to maximize fitness [ 39 ]. In our case, the reward functions are dynamic and temp orally dep endent on the sequential history of goals. Figure 1 pro vides an illustration of the agen t’s use of the hierarc h y o v er subsequen t time steps. Deep Reinforcement Learning with T emp oral Abstractions W e use the Deep Q-Learning framework [ 28 ] to learn p olicies for b oth the controller and the meta-con troller. Sp ecifically , the controller estimates the following Q-v alue function: Q ∗ 1 ( s, a ; g ) = max π ag E[ ∞ X t 0 = t γ t 0 − t r t 0 | s t = s, a t = a, g t = g , π ag ] = max π ag E[ r t + γ max a t +1 Q ∗ 1 ( s t +1 , a t +1 ; g ) | s t = s, a t = a, g t = g , π ag ] (1) where g is the agen t’s goal in state s and π ag = P ( a | s, g ) is the action p olicy . Similarly , for the meta-con troller, w e ha v e: Q ∗ 2 ( s, g ) = max π g E[ t + N X t 0 = t f t 0 + γ max g 0 Q ∗ 2 ( s t + N , g 0 ) | s t = s, g t = g , π g ] (2) 4 External Environment agent extrinsic rewar d Meta Controller Controller Critic action action intrinsic rewar d observations goal . . . . . . . . . . Meta Controller s t g t g t Controller s t s t +1 . . . . . . s t + N s t + N g t + N Q 2 ( s t ,g ; ✓ 2 ) Q 2 ( s t + N ,g t + N ; ✓ 2 ) Meta Controller Controller Controller Q 1 ( s t ,a ; ✓ 1 ,g t ) Q 1 ( s t +1 ,a ; ✓ 1 ,g t ) Q 1 ( s t + N ,a ; ✓ 1 ,g t ) a t a t +1 a t + N Figure 1: Ov erview: The agent produces actions and receiv es sensory observ ations. Separate deep-Q net works are used inside the meta-c ontr ol ler and c ontr ol ler . The meta-controller that lo oks at the raw states and pro duces a p olicy ov er goals b y estimating the v alue function Q 2 ( s t , g t ; θ 2 ) (by maximizing exp ected future extrinsic rew ard). The controller takes in states and the current goal, and pro duces a p olicy ov er actions by estimating the v alue function Q 2 ( s t , a t ; θ 1 , g t ) to solv e the predicted goal (by maximizing exp ected future intrinsic rew ard). The in ternal critic chec ks if goal is reac hed and provides an appropriate intrinsic rew ard to the controller. The con troller terminates either when the episo de ends or when g is accomplished. The meta-controller then chooses a new g and the pro cess rep eats. 5 where N denotes the num b er of time steps until the controller halts given the current goal, g 0 is the agent’s goal in state s t + N , and π g = P ( g | s ) is the p olicy o ver goals. It is imp ortant to note that the transitions ( s t , g t , f t , s t + N ) generated by Q 2 run at a slow er time-scale than the transitions ( s t , a t , g t , r t , s t +1 ) generated b y Q 1 . W e can re presen t Q ∗ ( s, g ) ≈ Q ( s, g ; θ ) using a non-linear function approximator with param- eters θ , called a deep Q-net work (DQN). Each Q ∈ { Q 1 , Q 2 } can b e trained b y minimizing corresp onding loss functions – L 1 ( θ 1 ) and L 2 ( θ 2 ). W e store exp eriences ( s t , g t , f t , s t + N ) for Q 2 and ( s t , a t , g t , r t , s t +1 ) for Q 1 in disjoint memory spaces D 1 and D 2 resp ectiv ely . The loss function for Q 1 can then b e stated as: L 1 ( θ 1 ,i ) = E ( s,a,g ,r,s 0 ) ∼ D 1 [( y 1 ,i − Q 1 ( s, a ; θ 1 ,i , g )) 2 ] , (3) where i denotes the training iteration n um b er and y 1 ,i = r + γ max a 0 Q 1 ( s 0 , a 0 ; θ 1 ,i − 1 , g ). F ollo wing [ 28 ], the parameters θ 1 ,i − 1 from the previous iteration are held fixed when opti- mising the loss function. The parameters θ 1 can b e optimized using the gradient: ∇ θ 1 ,i L 1 ( θ 1 ,i ) = E ( s,a,r,s 0 ∼ D 1 ) " r + γ max a 0 Q 1 ( s 0 , a 0 ; θ 1 ,i − 1 , g ) − Q 1 ( s, a ; θ 1 ,i , g ) ∇ θ 1 ,i Q 1 ( s, a ; θ 1 ,i , g ) # The loss function L 2 and its gradien ts can b e derived using a similar pro cedure. Learning Algorithm W e learn the parameters of h-DQN using sto chastic gradient descent at differen t time scales – exp eriences (or transitions) from the controller are collected at ev ery time step but exp eriences from meta-controller are only collected when the controller terminates (i.e. when a goal is re-pick ed or the episode ends). Each new goal g is drawn in an -greedy fashion (Algorithms 1 & 2) with the exploration probability 2 annealed as learning pro ceeds (from a starting v alue of 1). In the controller, at every time step, an action is drawn with a goal using the exploration probabilit y 1 ,g whic h is dependent on the current empirical success rate of reaching g . The mo del parameters ( θ 1 , θ 2 ) are p erio dically up dated by dra wing experiences from repla y memories D 1 and D 2 ), resp ectiv ely (see Algorithm 3). 4 Exp erimen ts W e p erform exp eriments on t w o differen t domains in v olving dela y ed rew ards. The first is a discrete-state MDP with sto chastic transitions, and the second is an A T ARI 2600 game called ‘Mon tezuma’s Rev enge’. 4.1 Discrete sto chastic decision pro cess s 1 s 2 s 3 s 4 s 5 s 6 0 . 5 0 . 5 0 . 5 0 . 5 0 . 5 0 . 5 0 . 5 0 . 5 0 . 5 0 . 5 1 . 0 1 . 0 1 . 0 1 . 0 1 . 0 or r =1 r =1 / 100 Figure 2: A sto chastic decision pro cess where the reward at the terminal state s 1 dep ends on whether s 6 is visited ( r = 1) or not ( r = 1 / 100). Game Setup W e consider a stochastic de- cision pro cess where the extrinsic rew ard dep ends on the history of visited states in addition to the curren t state. W e selected this task in order to demonstrate the imp or- tance of intrinsic motiv ation for exploration in suc h en vironmen ts. There are 6 p ossible states and the agent alw a ys starts at s 2 . The agent mov es left deterministically when it c ho oses left action; but the action right only succeeds 50% of the time, resulting in a left mov e otherwise. The terminal state is s 1 and the agent receives the rew ard of 1 when it first visits s 6 and then s 1 . The reward for going to s 1 without visiting s 6 is 0.01. This is a mo dified version of the MDP in [ 32 ], with the rew ard structure adding complexit y to the task. The pro cess is illustrated in Figure 2. 6 Algorithm 1 Learning algorithm for h-DQN 1: Initialize exp erience replay memories {D 1 , D 2 } and parameters { θ 1 , θ 2 } for the con troller and meta-con troller resp ectiv ely . 2: Initialize exploration probability 1 ,g = 1 for the controller for all goals g and 2 = 1 for the meta-con troller. 3: for i = 1 , num episodes do 4: Initialize game and get start state description s 5: g ← epsGreedy ( s, G , 2 , Q 2 ) 6: while s is not terminal do 7: F ← 0 8: s 0 ← s 9: while not ( s is terminal or goal g reached) do 10: a ← epsGreedy ( { s, g } , A , 1 ,g , Q 1 ) 11: Execute a and obtain next state s 0 and extrinsic rew ard f from environmen t 12: Obtain in trinsic rew ard r ( s, a, s 0 ) from in ternal critic 13: Store transition ( { s, g } , a, r, { s 0 , g } ) in D 1 14: upda teP arams ( L 1 ( θ 1 ,i ) , D 1 ) 15: upda teP arams ( L 2 ( θ 2 ,i ) , D 2 ) 16: F ← F + f 17: s ← s 0 18: end while 19: Store transition ( s 0 , g , F , s 0 ) in D 2 20: if s is not terminal then 21: g ← epsGreedy ( s, G , 2 , Q 2 ) 22: end if 23: end while 24: Anneal 2 and adaptiv ely anneal 1 ,g using a v erage success rate of reac hing goal g . 25: end for Algorithm 2 : epsGreedy ( x, B , , Q ) 1: if random() < then 2: return random elemen t from set B 3: else 4: return argmax m ∈B Q ( x, m ) 5: end if Algorithm 3 : upda teP arams ( L , D ) 1: Randomly sample mini-batc hes from D 2: P erform gradien t descent on loss L ( θ ) (cf. (3)) W e consider eac h state as a p ossible goal for exploration. This encourages the agent to visit state s 6 (whenev er it is chosen as a goal) and hence, learn the optimal p olicy . F or eac h goal, the age n t receives a p ositive intrinsic reward if and only if it reac hes the corresp onding state. Results W e compare the p erformance of our approac h (without the deep neural netw orks) with Q-Learning as a baseline (without in trinsic rewards) in terms of the av erage extrinsic rew ard gained in an episo de. In our exp eriments, all parameters are annealed from 1 to 0.1 o v er 50,000 steps. The learning rate is set to 0 . 00025. Figure 3 plots the evolution of rew ard for b oth metho ds av eraged ov er 10 different runs. As exp ected, we see that Q-Learning is unable to find the optimal p olicy even after 200 ep o chs, conv erging to a sub-optimal p olicy of reaching state s 1 directly to obtain a reward of 0.01. In contrast, our approach with hierarc hical Q-estimators learns to choose goals s 4 , s 5 or s 6 , which statistically lead the agen t to visit s 6 b efore going back to s 1 . Therefore, the agen t obtains a significantly higher a v erage rew ard of around 0.13. 7 5 / 1 8 / 2 0 1 6 R e w a r d . h t m l fi l e : / / / U s e r s / t e j a s / D o c u m e n t s / d e e p R e l a t i o n a l R L / d q n / R e w a r d . h t m l 1 / 1 0 50 100 150 200 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 E x p o r t t o p l o t . l y » Steps Baseline Our Approach Figure 3: Average reward for 10 runs of our approach compared to Q-learning. 5 / 1 8 / 2 0 1 6 S t a t e 3 , S t a t e 4 , S t a t e 5 , S t a t e 6 | fi l l e d s c a t t e r c h a r t m a d e b y A r d a v a n s | p l o t l y h t t p s : / / p l o t . l y / ~ a r d a v a n s / 4 . e m b e d 1 / 1 2 4 6 8 10 12 0 0.2 0.4 0.6 0.8 1 1.2 E d i t c h a r t » Episodes (*1000) State 3 State 4 State 5 State 6 Figure 4: Number of visits (for states s 3 to s 6 ) a veraged o ver 1000 episo des. The initial state is s 2 and the terminal state is s 1 . Figure 4 illustrates that the num b er of visits to states s 3 , s 4 , s 5 , s 6 increases with episo des of training. Eac h data p oint sho ws the av erage n umber of visits for eac h state ov er the last 1000 episo des. This indicates that our mo del is choosing goals in a wa y so that it reaches the critical state s 6 more often. 4.2 A T ARI game with delay ed rewards Game Description W e consider ‘Montezuma’s Revenge’, an A T ARI game with sparse, dela y ed rew ards. The game (Figure 5(a)) requires the play er to navigate the explorer (in red) through several ro oms while collecting treasures. In order to pass through do ors (in the top righ t and top left corners of the figure), the pla y er has to first pick up the key . The play er has to then climb down the ladders on the right and mov e left tow ards the key , resulting in a long sequence of actions b efore receiving a reward (+100) for collecting the key . After this, na vigating to w ards the do or and op ening it results in another reward (+300). Existing deep RL approaches fail to learn in this environmen t since the agent rarely reac hes a s tate with non-zero reward. F or instance, the basic DQN [ 28 ] achiev es a score of 0 while ev en the b est p erforming system, Gorila DQN [30], manages only 4.16 on av erage. Setup The agen t needs in trinsic motiv ation to explore meaningful parts of the scene b efore it can learn ab out the adv antage of getting the key for itself. Inspired by the dev elopmental psyc hology literature [ 43 ] and ob ject-oriented MDPs [ 8 ], we use entities or ob jects in the scene to parameterize goals in this en vironment. Unsup ervised detection of ob jects in visual scenes is an op en problem in computer vision, although there has b een recent progress in obtaining ob jects directly from image or motion data [ 10 , 9 , 14 ]. In this w ork, we built a custom ob ject detector that provides plausible ob jec t candidates. The controller and 8 (a) (b) image (s) + goal (g) Q 1 (s, a; g) Linear ReLU:Conv (filter:8, ftr -maps:32, strides:4) ReLU:Linear (h=512) ReLU:Conv (filter:4, ftr -maps:64, strides:2) ReLU:Conv (filter:3, ftr -maps:64, strides:1) Figure 5: (a) A sample screen from the A T ARI 2600 game called ‘Mon tezuma’s Revenge’. (b) Arc hitecture : DQN architecture for the controller ( Q 1 ). A similar arc hitecture pro duces Q 2 for the meta-controller (without goal as input). In practice, b oth these netw orks could share lo w er lev el features but w e do not enforce this. meta-con troller are conv olutional neural net w orks (see Figure 5(b)) that learn representations from ra w pixel data. W e use the Arcade Learning Environmen t [ 2 ] to p erform exp eriments. The in ternal critic is defined in the space of h entity 1 , r elation, entity 2 i , where r elation is a function o ver configurations of the entities. In our exp eriments, the agent is free to choose an y entity 2 . F or instance, the agen t is deemed to hav e completed a goal (and receiv es a rew ard) if the agen t en tit y r e aches another entit y suc h as the do or . Note that this notion of relational intrinsic rewards can b e generalized to other settings. F or instance, in the A T ARI game ‘Asteroids’, the agent could b e rew arded when the bullet reac hes the asteroid or if simply the ship never reac hes an asteroid. In the game of ‘P acman’, the agent could b e rewarded if the p ellets on the screen are reac hed . In the most general case, we can p oten tially let the model evolv e a parameterized intrinsic reward function giv en en tities. W e lea v e this for future w ork. Mo del Architecture and T raining As sho wn in Figure 5b, the mo del consists of stac ked con v olutional la yers with rectified linear units (ReLU). The input to the meta-controller is a set of four consecutive images of size 84 × 84. T o enco de the goal output from the meta-con troller, we app end a binary mask of the goal location in image space along with the original 4 consecutiv e frames. This augmented input is passed to the con troller. The exp erience replay memories D 1 and D 2 w ere set to b e equal to 1E6 and 5E4 resp ectively . W e set the learning rate to b e 2 . 5E − 4 , with a discoun t rate of 0 . 99. W e follow a tw o phase training pro cedure – (1) In the first phase, we set the exploration parameter 2 of the meta-con troller to 1 and train the controller on actions. This effectively leads to pre-training the controller so that it can learn to solv e a subset of the goals. (2) In the second phase, w e join tly train the con troller and meta-con troller. Results Figure 6(a) shows reward progress from the joint training phase from which it is eviden t that the mo del starts gradually learning to both reach the key and open the do or to get a reward of around +400 p er episo de. As sho wn in Figure 6(b), the agent learns to choose the key more often as training pro ceeds and is also successful at reac hing it. As training pro ceeds, we observe that the agent first learns to p erform the simpler goals (such as reac hing the right do or or the middle ladder) and then slowly starts learning the ‘harder’ goals such as the key and the b ottom ladders, which pro vide a path to higher rew ards. Figure 6(c) shows the evolution of the success rate of goals that are pick ed. A t the end of training, w e can see that the ’k ey’, ’b ottom -left-ladder’ and ’bottom-right-ladders’ are chosen increasingly more often. In order to scale-up to solve the entire game, sev eral key ingredien ts are missing such as – automatic discov ery of ob jects from videos to aid goal parametrization we considered, a flexible short-term memory , abilit y to in termitten tly terminate ongoing options. 9 5 / 1 8 / 2 0 1 6 R e w a r d . h t m l fi l e : / / / U s e r s / t e j a s / D o c u m e n t s / d e e p R e l a t i o n a l R L / d q n / R e w a r d . h t m l 1 / 1 0 0.5M 1M 1.5M 2M 0 50 100 150 200 250 300 350 400 Expor t t o p l o t . l y » Steps Our Approach DQN (a) T otal extrinsic rew ard 5 / 1 8 / 2 0 1 6 s u b g o a l _ 6 . h t m l fi l e : / / / U s e r s / t e j a s / D o c u m e n t s / d e e p R e l a t i o n a l R L / d q n / s u b g o a l _ 6 . h t m l 1 / 1 0 0.5M 1M 1.5M 2M 0 0.2 0.4 0.6 0.8 1 E x p o r t t o p l o t . l y » Steps (b) Success ratio for reac hing the goal ’k ey’ 5 / 1 8 / 2 0 1 6 B a r g r a p h . h t m l fi l e : / / / U s e r s / t e j a s / D o c u m e n t s / d e e p R e l a t i o n a l R L / d q n / B a r % 2 0 g r a p h . h t m l 1 / 1 0.5M 1M 1.5M 2M 0 0.05 0.1 0.15 0.2 0.25 E x p o r t t o p l o t . l y » Steps top-left door top-right door middle-ladder bottom-left-ladder bottom-right-ladder key (c) Success % of differen t goals o v er time Figure 6: Results on Montezuma’s Revenge: These plots depict the joint training phase of the mo del. As describ e d in Section 4.2, the first training phase pre-trains the low er level con troller for ab out 2.3 million steps. The joint training learns to consistently get high rew ards after additional 2 million steps as shown in (a) . (b) Goal success ratio: The agen t learns to choose the k ey more often as training pro ceeds and is successful at achieving it. (c) Goal statistics: During early phases of joint training, all goals are equally preferred due to high exploration but as training pro ceeds, the agent learns to select appropriate goals suc h as the k ey and b ottom-left do or. W e also show some screen-shots from a test run with our agent (with epsilon set to 0.1) in Figure 7, as w ell as a sample animation of the run. 1 1 Sample tra jectory of a run on ’Montezuma’s Revenge’ – https://goo.gl/3Z64Ji 10 1 2 3 4 5 6 7 8 9 10 11 12 termination (death) goal reached goal reached Meta Controller Controller Meta Controller Controller Figure 7: Sample gameplay by our agen t on Mon tezuma’s Revenge: The four quadran ts are arranged in a temp orally coherent manner (top-left, top-right, b ottom-left and b ottom-righ t). At the very b eginning, the meta-controller chooses key as the goal (illustrated in r e d ). The controller then tries to satisfy this goal by taking a series of low lev el actions (only a subset shown) but fails due to colliding with the skull (the episode terminates here). The meta-controller then chooses the b ottom-right ladder as the next goal and the controller terminates after reaching it. Subsequently , the meta-controller chooses the key and the top-righ t do or and the con troller is able to successfully achiev e b oth these goals. 5 Conclusion W e hav e presen ted h-DQN, a framew ork consisting of hierarc hical v alue functions op erating at differen t time scales. T emp orally decomp osing the v alue function allows the agent to p erform in trinsically motiv ated b ehavior, which in turn yields efficient exploration in en vironmen ts with delay ed rewards. W e also observe that parameterizing intrinsic motiv ation in the space of entities and relations pro vides a promising a ven ue for building agen ts with temp orally extended exploration. W e also plan to explore alternative parameterizations of goals with h-DQN in the future. The current framew ork has several missing comp onents including automatically disentangling ob jects from raw pixels and a short-term memory . The state abstractions learnt by v anilla deep-Q-net w orks are not structured or sufficiently comp ositional. There has b een recen t w ork [ 9 , 14 , 33 , 22 , 50 , 15 , 20 ] in using deep generativ e mo dels to disentangle m ultiple factors of v ariations (ob jects, p ose, lo cation, etc) from pixel data. W e hop e that our w ork motiv ates the combination of deep generative mo dels of images with h-DQN. Additionally , in order to handle longer range dep endencies, the agent needs to store a history of previous goals, actions and represen tations. There has b een some recent work in using recurrent netw orks in conjunction with reinforcement learning [ 18 , 31 ]. In order to scale-up our approac h to harder non-Marko vian settings, it will b e necessary to incorp orate a flexible episo dic memory mo dule. 11 Ac knowledgemen ts W e w ould like to thank V aibhav Unhelk ar, Ramy a Ramakrishnan, Sam Gershman, Michael Littman, Vlad Firoiu, Will Whitney , Max Kleiman-W einer and Pedro Tsividis for critical feedbac k and discussions. W e are grateful to receive supp ort from the Center for Brain, Mac hines and Minds (NSF STC a w ard CCF - 1231216) and the MIT Op enMind team. References [1] A. G. Barto and S. Mahadev an. Recent adv ances in hierarchical reinforcement learning. Discr ete Event Dynamic Systems , 13(4):341–379, 2003. [2] M. G. Bellemare, Y. Naddaf, J. V eness, and M. Bowling. The arcade learning environmen t: An ev aluation platform for general agents. Journal of Artificial Intel ligence R ese ar ch , 2012. [3] M. M. Botvinic k, Y. Niv, and A. C. Barto. Hierarc hically organized b ehavior and its neural foundations: A reinforcement learning persp ective. Co gnition , 113(3):262–280, 2009. [4] L. C. Cob o, C. L. Isb ell, and A. L. Thomaz. Ob ject fo cused q-learning for autonomous agents. In Pr o c e edings of the 2013 international confer enc e on Autonomous agents and multi-agent systems , pages 1061–1068. In ternational F oundation for Autonomous Agents and Multiagent Systems, 2013. [5] P . Day an. Impro ving generalization for temp oral difference learning: The successor representa- tion. Neur al Computation , 5(4):613–624, 1993. [6] P . Day an and G. E. Hinton. F eudal reinforcement learning. In Advanc es in neur al information pr o c essing systems , pages 271–271. Morgan Kaufmann Publishers, 1993. [7] T. G. Dietterich. Hierarchical reinforcement learning with the maxq v alue function decomp osi- tion. J. Artif. Intel l. R es.(JAIR) , 13:227–303, 2000. [8] C. Diuk, A. Cohen, and M. L. Littman. An ob ject-oriented represen tation for efficient reinforcemen t learning. In Pr o c e e dings of the 25th international c onfer enc e on Machine le arning , pages 240–247. ACM, 2008. [9] S. Eslami, N. Heess, T. W eber, Y. T assa, K. Kavuk cuoglu, and G. E. Hinton. Attend, infer, rep eat: F ast scene understanding with generative mo dels. arXiv pr eprint arXiv:1603.08575 , 2016. [10] K. F ragkiadaki, P . Arb elaez, P . F elsen, and J. Malik. Learning to segment moving ob jects in videos. In Computer Vision and Pattern R e c o gnition (CVPR), 2015 IEEE Confer enc e on , pages 4083–4090. IEEE, 2015. [11] M. F rank, J. Leitner, M. Stollenga, A. F¨ orster, and J. Schmidh ub er. Curiosity driven rein- forcemen t learning for motion planning on human oids. Intrinsic motivations and op en-ende d development in animals, humans, and r ob ots , page 245, 2015. [12] S. J. Gershman, C. D. Mo ore, M. T. T odd, K. A. Norman, and P . B. Sederb erg. The successor represen tation and temp oral context. Neur al Computation , 24(6):1553–1568, 2012. [13] S. Go el and M. Hub er. Subgoal disco very for hierarchical reinforcement learning using learned p olicies. In FLAIRS c onfer enc e , pages 346–350, 2003. [14] K. Greff, R. K. Sriv astav a, and J. Schmidh ub er. Binding via reconstruction clustering. arXiv pr eprint arXiv:1511.06418 , 2015. [15] K. Gregor, I. Danihelk a, A. Grav es, and D. Wierstra. Draw: A recurrent neural netw ork for image generation. arXiv pr eprint arXiv:1502.04623 , 2015. [16] C. Guestrin, D. Koller, C. Gearhart, and N. Kano dia. Generalizing plans to new environmen ts in relational mdps. In Pro c e e dings of the 18th international joint c onfer enc e on A rtificial intel ligenc e , pages 1003–1010. Morgan Kaufmann Publishers Inc., 2003. [17] C. Guestrin, D. Koller, R. Parr, and S. V enk ataraman. Efficient solution algorithms for factored mdps. Journal of Artificial Intel ligenc e R ese ar ch , pages 399–468, 2003. [18] M. Hausknech t and P . Stone. Deep recurrent q-learning for partially observ able mdps. arXiv pr eprint arXiv:1507.06527 , 2015. [19] N. Hernandez-Gardiol and S. Mahadev an. Hierarc hical memory-based reinforcemen t learning. A dvanc es in Neur al Information Pr o c essing Systems , pages 1047–1053, 2001. [20] J. Huang and K. Murphy . Efficient inference in occlusion-aw are generativ e mo dels of images. arXiv pr eprint arXiv:1511.06362 , 2015. 12 [21] J. Koutn ´ ık, J. Schmidh ub er, and F. Gomez. Evolving deep unsup ervised conv olutional netw orks for vision-based reinforcement learning. In Pr o c e e dings of the 2014 c onfer enc e on Genetic and evolutionary c omputation , pages 541–548. ACM, 2014. [22] T. D. Kulk arni, W. F. Whitney , P . Kohli, and J. T enenbaum. Deep con v olutional in verse graphics netw ork. In A dvanc es in Neur al Information Pr oc essing Systems , pages 2530–2538, 2015. [23] B. M. Lake, T. D. Ullman, J. B. T enenbaum, and S. J. Gershman. Building mac hines that learn and think like p eople. arXiv pr eprint arXiv:1604.00289 , 2016. [24] M. C. Machado and M. Bowling. Learning purp oseful b ehaviour in the absence of rewards. arXiv pr eprint arXiv:1605.07700 , 2016. [25] S. Mannor, I. Menache, A. Hoze, and U. Klein. Dynamic abstraction in reinforcement learning via clustering. In Pr o c e e dings of the twenty-first international c onfer enc e on Machine le arning , page 71. ACM, 2004. [26] A. McGov ern and A. G. Barto. Automatic discov ery of subgoals in reinforcement learning using diverse density . Computer Scienc e Department F aculty Public ation Series , page 8, 2001. [27] I. Menache, S. Mannor, and N. Shimkin. Q-cutdynamic discov ery of sub-goals in reinforcement learning. In Machine L e arning: ECML 2002 , pages 295–306. Springer, 2002. [28] V. Mnih, K. Kavuk cuoglu, D. Silver, A. A. Rusu, J. V eness, M. G. Bellemare, A. Grav es, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al. Human-lev el control through deep reinforcemen t learning. Natur e , 518(7540):529–533, 2015. [29] S. Mohamed and D. J. Rezende. V ariational information maximisation for intrinsically motiv ated reinforcemen t learning. In A dvanc es in Neural Information Pro c essing Systems , pages 2116–2124, 2015. [30] A. Nair, P . Sriniv asan, S. Blackw ell, C. Alcicek, R. F earon, A. De Maria, V. Panneershelv am, M. Suleyman, C. Beattie, S. Petersen, et al. Massively parallel metho ds for deep reinforcement learning. arXiv pr eprint arXiv:1507.04296 , 2015. [31] K. Narasimhan, T. Kulk arni, and R. Barzilay . Language understanding for text-based games using deep reinforcement learning. arXiv pr eprint arXiv:1506.08941 , 2015. [32] I. Osband, C. Blundell, A. Pritzel, and B. V an Roy . Deep exploration via b o otstrapp ed dqn. arXiv pr eprint arXiv:1602.04621 , 2016. [33] D. J. Rezende, S. Mohamed, I. Danihelk a, K. Gregor, and D. Wierstra. One-shot generalization in deep generative mo dels. arXiv pr eprint arXiv:1603.05106 , 2016. [34] T. Sc haul, D. Horgan, K. Gregor, and D. Silver. Universal v alue function approximators. In Pr o c ee dings of the 32nd International Confer enc e on Machine L e arning (ICML-15) , pages 1312–1320, 2015. [35] T. Schaul, J. Quan, I. Antonoglou, and D. Silver. Prioritized exp erience replay . arXiv pr eprint arXiv:1511.05952 , 2015. [36] J. Schmidh ub er. F ormal theory of creativit y , fun, and intrinsic motiv ation (1990–2010). Autonomous Mental Development, IEEE T r ansactions on , 2(3):230–247, 2010. [37] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. v an den Driessche, J. Schritt wieser, I. Antonoglou, V. P anneershelv am, M. Lanctot, et al. Mastering the game of go with deep neural netw orks and tree search. Natur e , 529(7587):484–489, 2016. [38] ¨ O. S ¸ im¸ sek, A. W olfe, and A. Barto. Identifying useful subgoals in reinforcement learning by lo cal graph partitioning. In Pro c e e dings of the International c onfer enc e on Machine le arning , pages 816–823, 2005. [39] S. Singh, R. L. Lewis, and A. G. Barto. Where do rewards come from. In Pr o c e e dings of the annual c onfer enc e of the c o gnitive scienc e so ciety , pages 2601–2606, 2009. [40] S. Singh, R. L. Lewis, A. G. Barto, and J. Sorg. Intrinsically motiv ated reinforcemen t learning: An ev olutionary p ersp ective. Autonomous Mental Development, IEEE T r ansactions on , 2(2):70– 82, 2010. [41] S. P . Singh, A. G. Barto, and N. Chentanez. Intrinsically motiv ated reinforcemen t learning. In A dvanc es in neur al information pr o c essing systems , pages 1281–1288, 2004. [42] J. Sorg and S. Singh. Linear options. In Pr o ce e dings of the 9th International Conferenc e on Autonomous A gents and Multiagent Systems: V olume 1 - V olume 1 , AAMAS ’10, pages 31–38, Ric hland, SC, 2010. International F oundation for Autonomous Agents and Multiagent Systems. [43] E. S. Sp elke and K. D. Kinzler. Core kno wledge. Developmental scienc e , 10(1):89–96, 2007. 13 [44] K. L. Stachenfeld, M. Botvinick, and S. J. Gershman. Design principles of the hipp o campal cognitiv e map. In A dvanc es in neur al information pr o c essing systems , pages 2528–2536, 2014. [45] B. C. Stadie, S. Levine, and P . Abb eel. Incen tivizing exploration in reinforcement learning with deep predictive mo dels. arXiv pr eprint arXiv:1507.00814 , 2015. [46] R. S. Sutton and A. G. Barto. Intr o duction to r einfor cement le arning , volume 135. MIT Press Cam bridge, 1998. [47] R. S. Sutton, J. Mo dayil, M. Delp, T. Degris, P . M. Pilarski, A. White, and D. Precup. Horde: A scalable real-time architecture for learning knowledge from unsup ervised sensorimotor in teraction. In The 10th International Conferenc e on Autonomous A gents and Multiagent Systems-V olume 2 , pages 761–768. In ternational F oundation for Autonomous Agen ts and Multiagen t Systems, 2011. [48] R. S. Sutton, D. Precup, and S. Singh. Betw een mdps and semi-mdps: A framework for temp oral abstraction in reinforcement learning. A rtificial intel ligenc e , 112(1):181–211, 1999. [49] C. Szep esv ari, R. S. Sutton, J. Mo dayil, S. Bhatnagar, et al. Universal option mo dels. In A dvanc es in Neur al Information Pr o c essing Systems , pages 990–998, 2014. [50] W. F. Whitney , M. Chang, T. Kulk arni, and J. B. T enenbaum. Understanding visual concepts with contin uation learning. arXiv pr eprint arXiv:1602.06822 , 2016. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment