계층적 딥 강화학습: 시간 추상화와 내재 동기 통합
본 논문은 목표‑레벨 메타 컨트롤러와 행동‑레벨 컨트롤러를 결합한 계층적 DQN(h‑DQN) 프레임워크를 제안한다. 메타 컨트롤러는 내재 목표를 선택하고, 하위 컨트롤러는 해당 목표를 달성하기 위한 원자 행동을 학습한다. 목표는 엔티티·관계 기반 함수로 정의될 수 있어 탐색 공간을 효율적으로 축소한다. 두 단계의 Q‑네트워크를 각각 다른 시간 스케일에서 학습시키며, 내재 보상은 목표 달성 여부에 따라 제공된다. 실험은 복잡한 이산 MDP와 At…
저자: Tejas D. Kulkarni, Karthik R. Narasimhan, Ardavan Saeedi
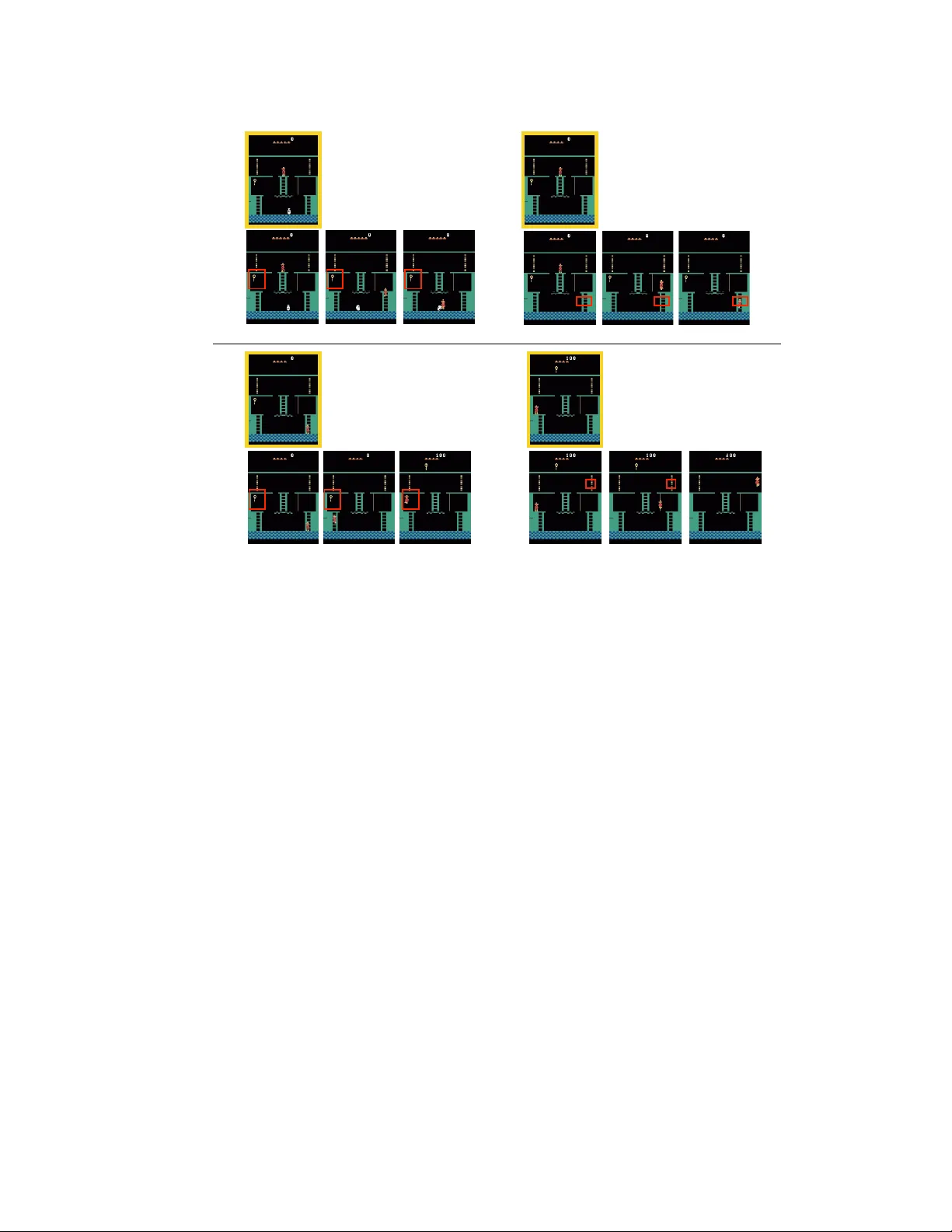
본 논문은 강화학습에서 가장 어려운 문제 중 하나인 희소하고 지연된 보상 환경에 대한 탐색 효율성을 개선하기 위해, 계층적 딥 강화학습 프레임워크인 h‑DQN(Hierarchical DQN)을 제안한다. h‑DQN은 두 개의 심층 Q‑네트워크, 즉 메타‑컨트롤러와 컨트롤러를 사용한다. 메타‑컨트롤러는 현재 환경 상태 sₜ를 관찰하고, 목표 집합 G 에서 하나의 목표 gₜ를 선택한다. 목표는 “엔티티‑관계 함수” 형태로 정의될 수 있어, 예를 들어 “키를 열쇠와 같은 위치에 놓는다”, “문을 열어 다음 방에 진입한다”와 같은 구체적인 서브‑목표를 표현한다. 이러한 목표 정의는 탐색 공간을 크게 축소하고, 인간이 사물과 관계를 인식하는 방식과 일맥상통한다.
선택된 목표 gₜ는 컨트롤러에 전달된다. 컨트롤러는 (sₜ, gₜ) 쌍을 입력으로 받아 Q₁(s,a;g) 를 추정하고, 목표가 달성될 때까지 혹은 에피소드가 종료될 때까지 원자 행동 aₜ를 선택한다. 목표 달성 여부는 내부 크리틱이 판단하며, 목표가 성공적으로 달성되면 내재 보상 rₜ(g) 를 반환한다. 이 내재 보상은 목표 달성 자체를 강화함으로써, 외재 보상이 거의 없는 상황에서도 에이전트가 의미 있는 행동을 지속하도록 만든다.
두 Q‑네트워크는 각각 독립적인 리플레이 메모리 D₁, D₂에 저장된 전이 샘플을 사용해 손실 함수를 최소화한다. 컨트롤러의 손실 L₁은 전통적인 DQN 손실과 동일하게 TD 오차를 최소화한다. 메타‑컨트롤러의 손실 L₂는 (sₜ, gₜ, fₜ, sₜ₊ₙ) 전이를 이용해, 목표 선택 정책이 외재 보상 fₜ(·) 를 최대화하도록 학습한다. 여기서 n 은 컨트롤러가 목표를 달성하거나 종료될 때까지 걸린 시간 단계 수이며, 메타‑컨트롤러는 더 긴 시간 스케일에서 작동한다.
시간적 추상화는 h‑DQN의 핵심이다. 컨트롤러는 매 타임스텝마다 업데이트되며 빠른 피드백을 받는다. 반면 메타‑컨트롤러는 목표가 바뀔 때마다(즉, 컨트롤러가 종료될 때)만 업데이트되므로, 장기적인 전략을 학습한다. 이 구조는 기존 ε‑greedy, Boltzmann, Thompson 샘플링 등 저수준 탐색 전략이 희소 보상 환경에서 겪는 “탐색 정체” 문제를 해결한다.
논문은 또한 기존 연구와의 관계를 상세히 논의한다. 옵션 프레임워크와 SMDP 이론을 기반으로 하면서, 옵션을 목표‑조건부 Q‑함수 V(s,g) 로 일반화한다. 기존 옵션 학습 방법이 주로 선형/표 형식이거나 보상이 명시적으로 정의된 경우에 한정된 반면, h‑DQN은 비선형 신경망을 이용해 목표를 입력으로 받아 다수의 옵션을 공유 학습한다. 이는 옵션 간 파라미터 공유와 확장성을 동시에 제공한다.
내재 동기에 관한 부분에서는 인간 영유아가 세계를 엔티티와 관계로 인식하고, 호기심을 통해 자체 목표를 설정한다는 인지·신경과학 연구를 인용한다. 이러한 관점에서 h‑DQN의 목표‑조건부 탐색은 “인공 호기심”을 구현한 것으로, 목표 달성 자체가 보상이 되게 함으로써 탐색을 자극한다.
실험은 두 가지 도메인에서 수행되었다. 첫 번째는 복잡한 전이 확률을 가진 이산 MDP이며, 목표를 달성하기 위해 최소 100 단계가 필요하고 보상은 마지막 단계에서만 주어진다. h‑DQN은 목표‑조건부 옵션을 학습해 빠르게 최적 경로를 찾아내며, 기존 DQN 기반 방법은 거의 학습이 진행되지 않는다. 두 번째는 Atari 2600 게임 ‘Montezuma’s Revenge’이다. 이 게임은 키를 얻고 문을 열어 새로운 방에 진입하는 일련의 서브‑목표가 존재하고, 보상이 매우 지연되어 있다. h‑DQN은 “키 획득 → 문 열기 → 보물 획득”과 같은 목표 시퀀스를 내재 보상으로 학습해, 수천 에피소드 내에 인간 수준에 근접하는 점수를 기록한다. 기존 Deep Q‑Network, Double‑DQN, Prioritized Replay 등은 수백만 프레임을 학습해도 거의 진전이 없었다.
논문의 한계로는 목표 집합 G 를 사전에 정의하거나 도메인 지식에 의존해야 한다는 점, 메타‑컨트롤러의 목표 선택이 여전히 ε‑greedy 탐색에 의존해 목표 공간이 매우 클 경우 효율이 떨어질 수 있다는 점을 들었다. 또한, 현재 구현은 이산 행동 공간에 초점을 맞추고 있어 연속 제어 문제에 대한 확장은 추가 연구가 필요하다.
향후 연구 방향으로는 자동 목표 생성 메커니즘(예: 정보 이득 기반 목표 제안), 메타‑강화학습을 통한 목표 선택 정책의 최적화, 그리고 연속 행동 및 다중 에이전트 환경에 대한 확장이 제시된다. 전반적으로 h‑DQN은 계층적 구조와 내재 동기를 결합해, 희소 보상 환경에서의 탐색 효율성을 크게 향상시키는 실용적인 프레임워크로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기