End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF
State-of-the-art sequence labeling systems traditionally require large amounts of task-specific knowledge in the form of hand-crafted features and data pre-processing. In this paper, we introduce a novel neutral network architecture that benefits fro…
Authors: Xuezhe Ma, Eduard Hovy
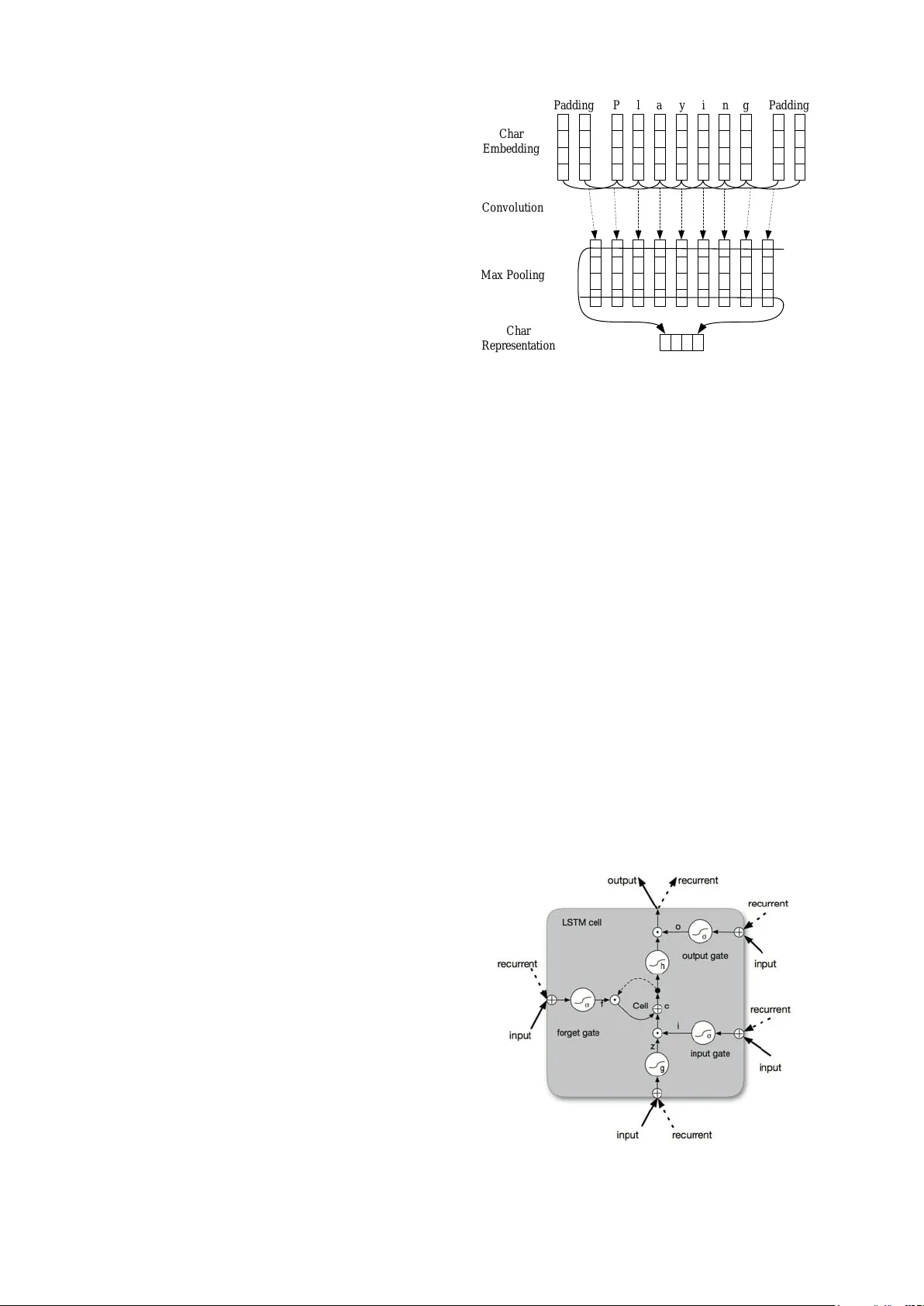
End-to-end Sequence Labeling via Bi-dir ectional LSTM-CNNs-CRF Xuezhe Ma and Eduard Hovy Language T echnologies Institute Carnegie Mellon Uni v ersity Pittsbur gh, P A 15213, USA xuezhem@cs.cmu.edu, ehovy@cmu.edu Abstract State-of-the-art sequence labeling systems traditionally require large amounts of task- specific kno wledge in the form of hand- crafted features and data pre-processing. In this paper , we introduce a nov el neu- tral network architecture that benefits from both word- and character-le vel representa- tions automatically , by using combination of bidirectional LSTM, CNN and CRF . Our system is truly end-to-end, requir- ing no feature engineering or data pre- processing, thus making it applicable to a wide range of sequence labeling tasks. W e e valuate our system on two data sets for two sequence labeling tasks — Penn T reebank WSJ corpus for part-of-speech (POS) tagging and CoNLL 2003 cor- pus for named entity recognition (NER). W e obtain state-of-the-art performance on both datasets — 97.55% accuracy for POS tagging and 91.21% F1 for NER. 1 Introduction Linguistic sequence labeling, such as part-of- speech (POS) tagging and named entity recogni- tion (NER), is one of the first stages in deep lan- guage understanding and its importance has been well recognized in the natural language processing community . Natural language processing (NLP) systems, like syntactic parsing (Nivre and Scholz, 2004; McDonald et al., 2005; Koo and Collins, 2010; Ma and Zhao, 2012a; Ma and Zhao, 2012b; Chen and Manning, 2014; Ma and Ho vy , 2015) and entity coreference resolution (Ng, 2010; Ma et al., 2016), are becoming more sophisticated, in part because of utilizing output information of POS tagging or NER systems. Most traditional high performance sequence la- beling models are linear statistical models, includ- ing Hidden Marko v Models (HMM) and Condi- tional Random Fields (CRF) (Ratinov and Roth, 2009; Passos et al., 2014; Luo et al., 2015), which rely hea vily on hand-crafted features and task- specific resources. For e xample, English POS tag- gers benefit from carefully designed word spelling features; orthographic features and e xternal re- sources such as gazetteers are widely used in NER. Ho we ver , such task-specific knowledge is costly to dev elop (Ma and Xia, 2014), making sequence labeling models difficult to adapt to new tasks or ne w domains. In the past few years, non-linear neural net- works with as input distributed word representa- tions, also known as word embeddings, hav e been broadly applied to NLP problems with great suc- cess. Collobert et al. (2011) proposed a simple but ef fecti ve feed-forward neutral network that inde- pendently classifies labels for each w ord by us- ing contexts within a window with fixed size. Re- cently , recurrent neural networks (RNN) (Goller and Kuchler , 1996), together with its v ariants such as long-short term memory (LSTM) (Hochreiter and Schmidhuber, 1997; Gers et al., 2000) and gated recurrent unit (GR U) (Cho et al., 2014), hav e shown great success in modeling sequential data. Se veral RNN-based neural network mod- els ha ve been proposed to solve sequence labeling tasks like speech recognition (Gra ves et al., 2013), POS tagging (Huang et al., 2015) and NER (Chiu and Nichols, 2015; Hu et al., 2016), achieving competiti ve performance against traditional mod- els. Howe ver , e ven systems that hav e utilized dis- tributed representations as inputs hav e used these to augment, rather than replace, hand-crafted fea- tures (e.g. word spelling and capitalization pat- terns). Their performance drops rapidly when the models solely depend on neural embeddings. In this paper , we propose a neural network ar- chitecture for sequence labeling. It is a truly end- to-end model requiring no task-specific resources, feature engineering, or data pre-processing be- yond pre-trained word embeddings on unlabeled corpora. Thus, our model can be easily applied to a wide range of sequence labeling tasks on dif- ferent languages and domains. W e first use con- volutional neural networks (CNNs) (LeCun et al., 1989) to encode character-le vel information of a word into its character-le vel representation. Then we combine character- and word-le vel represen- tations and feed them into bi-directional LSTM (BLSTM) to model context information of each word. On top of BLSTM, we use a sequential CRF to jointly decode labels for the whole sen- tence. W e ev aluate our model on two linguistic sequence labeling tasks — POS tagging on Penn T reebank WSJ (Marcus et al., 1993), and NER on English data from the CoNLL 2003 shared task (Tjong Kim Sang and De Meulder , 2003). Our end-to-end model outperforms previous state- of-the-art systems, obtaining 97.55% accuracy for POS tagging and 91.21% F1 for NER. The con- tributions of this work are (i) proposing a novel neural network architecture for linguistic sequence labeling. (ii) giving empirical e v aluations of this model on benchmark data sets for tw o classic NLP tasks. (iii) achieving state-of-the-art performance with this truly end-to-end system. 2 Neural Network Ar chitecture In this section, we describe the components (lay- ers) of our neural network architecture. W e intro- duce the neural layers in our neural network one- by-one from bottom to top. 2.1 CNN f or Character-le vel Representation Pre vious studies (Santos and Zadrozny , 2014; Chiu and Nichols, 2015) hav e shown that CNN is an effecti ve approach to extract morphological information (like the prefix or suffix of a word) from characters of words and encode it into neural representations. Figure 1 sho ws the CNN we use to extract character -level representation of a gi ven word. The CNN is similar to the one in Chiu and Nichols (2015), except that we use only character embeddings as the inputs to CNN, without char- acter type features. A dropout layer (Sriv astav a et al., 2014) is applied before character embeddings are input to CNN. P l a y i n g P a d d i n g P a d d i n g C h a r E m b e d d i n g C o n v o l u t i o n M a x P o o l i n g C h a r R e p r e s e n t a t i o n Figure 1: The con volution neural network for ex- tracting character-le vel representations of words. Dashed arro ws indicate a dropout layer applied be- fore character embeddings are input to CNN. 2.2 Bi-directional LSTM 2.2.1 LSTM Unit Recurrent neural networks (RNNs) are a po werful family of connectionist models that capture time dynamics via cycles in the graph. Though, in the- ory , RNNs are capable to capturing long-distance dependencies, in practice, they fail due to the gra- dient v anishing/exploding problems (Bengio et al., 1994; Pascanu et al., 2012). LSTMs (Hochreiter and Schmidhuber , 1997) are variants of RNNs designed to cope with these gradient v anishing problems. Basically , a LSTM unit is composed of three multiplicativ e gates which control the proportions of information to forget and to pass on to the next time step. Fig- ure 2 giv es the basic structure of an LSTM unit. Figure 2: Schematic of LSTM unit. Formally , the formulas to update an LSTM unit at time t are: i t = σ ( W i h t − 1 + U i x t + b i ) f t = σ ( W f h t − 1 + U f x t + b f ) ˜ c t = tanh( W c h t − 1 + U c x t + b c ) c t = f t c t − 1 + i t ˜ c t o t = σ ( W o h t − 1 + U o x t + b o ) h t = o t tanh( c t ) where σ is the element-wise sigmoid function and is the element-wise product. x t is the input vector (e.g. word embedding) at time t , and h t is the hidden state (also called out- put) v ector storing all the useful information at (and before) time t . U i , U f , U c , U o denote the weight matrices of dif ferent gates for input x t , and W i , W f , W c , W o are the weight matrices for hidden state h t . b i , b f , b c , b o denote the bias vectors. It should be noted that we do not include peephole connections (Gers et al., 2003) in the our LSTM formulation. 2.2.2 BLSTM For many sequence labeling tasks it is benefi- cial to have access to both past (left) and future (right) contexts. Howe ver , the LSTM’ s hidden state h t takes information only from past, know- ing nothing about the future. An elegant solution whose effecti veness has been prov en by pre vious work (Dyer et al., 2015) is bi-directional LSTM (BLSTM). The basic idea is to present each se- quence forwards and backwards to two separate hidden states to capture past and future informa- tion, respectiv ely . Then the two hidden states are concatenated to form the final output. 2.3 CRF For sequence labeling (or general structured pre- diction) tasks, it is beneficial to consider the cor- relations between labels in neighborhoods and jointly decode the best chain of labels for a giv en input sentence. For example, in POS tagging an adjecti ve is more likely to be follo wed by a noun than a verb, and in NER with standard BIO2 an- notation (Tjong Kim Sang and V eenstra, 1999) I-ORG cannot follo w I-PER. Therefore, we model label sequence jointly using a conditional random field (CRF) (Lafferty et al., 2001), instead of de- coding each label independently . Formally , we use z = { z 1 , · · · , z n } to repre- sent a generic input sequence where z i is the input vector of the i th word. y = { y 1 , · · · , y n } rep- resents a generic sequence of labels for z . Y ( z ) denotes the set of possible label sequences for z . The probabilistic model for sequence CRF defines a family of conditional probability p ( y | z ; W , b ) ov er all possible label sequences y giv en z with the follo wing form: p ( y | z ; W , b ) = n Q i =1 ψ i ( y i − 1 , y i , z ) P y 0 ∈Y ( z ) n Q i =1 ψ i ( y 0 i − 1 , y 0 i , z ) where ψ i ( y 0 , y , z ) = exp( W T y 0 ,y z i + b y 0 ,y ) are potential functions, and W T y 0 ,y and b y 0 ,y are the weight vector and bias corresponding to label pair ( y 0 , y ) , respecti vely . For CRF training, we use the maximum con- ditional likelihood estimation. For a training set { ( z i , y i ) } , the logarithm of the likelihood (a.k.a. the log-likelihood) is gi ven by: L ( W , b ) = X i log p ( y | z ; W , b ) Maximum likelihood training chooses parameters such that the log-likelihood L ( W , b ) is maxi- mized. Decoding is to search for the label sequence y ∗ with the highest conditional probability: y ∗ = argmax y ∈Y ( z ) p ( y | z ; W , b ) For a sequence CRF model (only interactions be- tween two successive labels are considered), train- ing and decoding can be solved efficiently by adopting the V iterbi algorithm. 2.4 BLSTM-CNNs-CRF Finally , we construct our neural network model by feeding the output vectors of BLSTM into a CRF layer . Figure 3 illustrates the architecture of our network in detail. For each word, the character-le vel represen- tation is computed by the CNN in Figure 1 with character embeddings as inputs. Then the character-le vel representation vector is concate- nated with the word embedding v ector to feed into the BLSTM network. Finally , the output vectors of BLSTM are fed to the CRF layer to jointly de- code the best label sequence. As shown in Fig- ure 3, dropout layers are applied on both the in- put and output vectors of BLSTM. Experimen- tal results show that using dropout significantly W e W o r d E m b e d d i n g a r e p l a y i n g s o c c e r C h a r R e p r e s e n t a t i o n F o r w a r d L S T M B a c k w a r d L S T M L S T M L S T M L S T M L S T M L S T M L S T M L S T M L S T M P R P V B P N N V B G C R F L a y e r Figure 3: The main architecture of our neural network. The character representation for each word is computed by the CNN in Figure 1. Then the character representation vector is concatenated with the word embedding before feeding into the BLSTM network. Dashed arro ws indicate dropout layers applied on both the input and output vectors of BLSTM. improv e the performance of our model (see Sec- tion 4.5 for details). 3 Network T raining In this section, we provide details about training the neural network. W e implement the neural net- work using the Theano library (Bergstra et al., 2010). The computations for a single model are run on a GeForce GTX TIT AN X GPU. Using the settings discussed in this section, the model train- ing requires about 12 hours for POS tagging and 8 hours for NER. 3.1 Parameter Initialization W ord Embeddings. W e use Stanford’ s pub- licly av ailable GloV e 100-dimensional embed- dings 1 trained on 6 billion words from W ikipedia and web text (Pennington et al., 2014) 1 http://nlp.stanford.edu/projects/ glove/ W e also run experiments on two other sets of published embeddings, namely Senna 50- dimensional embeddings 2 trained on Wikipedia and Reuters RCV -1 corpus (Collobert et al., 2011), and Google’ s W ord2V ec 300-dimensional embed- dings 3 trained on 100 billion words from Google Ne ws (Mikolov et al., 2013). T o test the effec- ti veness of pretrained word embeddings, we ex- perimented with randomly initialized embeddings with 100 dimensions, where embeddings are uni- formly sampled from range [ − q 3 dim , + q 3 dim ] where dim is the dimension of embeddings (He et al., 2015). The performance of dif ferent word embeddings is discussed in Section 4.4. Character Embeddings. Character embed- dings are initialized with uniform samples from [ − q 3 dim , + q 3 dim ] , where we set dim = 30 . W eight Matrices and Bias V ectors. Matrix pa- rameters are randomly initialized with uniform samples from [ − q 6 r + c , + q 6 r + c ] , where r and c are the number of of rows and columns in the structure (Glorot and Bengio, 2010). Bias vec- tors are initialized to zero, except the bias b f for the forget gate in LSTM , which is initialized to 1.0 (Jozefo wicz et al., 2015). 3.2 Optimization Algorithm Parameter optimization is performed with mini- batch stochastic gradient descent (SGD) with batch size 10 and momentum 0.9. W e choose an initial learning rate of η 0 ( η 0 = 0 . 01 for POS tag- ging, and 0 . 015 for NER, see Section 3.3.), and the learning rate is updated on each epoch of training as η t = η 0 / (1 + ρt ) , with decay rate ρ = 0 . 05 and t is the number of epoch completed. T o reduce the ef fects of “gradient exploding”, we use a gradient clipping of 5 . 0 (Pascanu et al., 2012). W e explored other more sophisticated optimization algorithms such as AdaDelta (Zeiler, 2012), Adam (Kingma and Ba, 2014) or RMSProp (Dauphin et al., 2015), but none of them meaningfully improv e upon SGD with momentum and gradient clipping in our pre- liminary experiments. Early Stopping. W e use early stopping (Giles, 2001; Grav es et al., 2013) based on performance on validation sets. The “best” parameters appear at around 50 epochs, according to our experiments. 2 http://ronan.collobert.com/senna/ 3 https://code.google.com/archive/p/ word2vec/ Layer Hyper -parameter POS NER CNN windo w size 3 3 number of filters 30 30 LSTM state size 200 200 initial state 0.0 0.0 peepholes no no Dropout dropout rate 0.5 0.5 batch size 10 10 initial learning rate 0.01 0.015 decay rate 0.05 0.05 gradient clipping 5.0 5.0 T able 1: Hyper-parameters for all e xperiments. Fine T uning. F or each of the embeddings, we fine-tune initial embeddings, modifying them dur- ing gradient updates of the neural network model by back-propagating gradients. The effecti veness of this method has been previously e xplored in se- quential and structured prediction problems (Col- lobert et al., 2011; Peng and Dredze, 2015). Dropout T raining. T o mitigate ov erfitting, we ap- ply the dropout method (Sriv astav a et al., 2014) to regularize our model. As sho wn in Figure 1 and 3, we apply dropout on character embeddings before inputting to CNN, and on both the input and out- put vectors of BLSTM. W e fix dropout rate at 0 . 5 for all dropout layers through all the experiments. W e obtain significant improvements on model per - formance after using dropout (see Section 4.5). 3.3 T uning Hyper -Parameters T able 1 summarizes the chosen hyper -parameters for all experiments. W e tune the hyper-parameters on the de velopment sets by random search. Due to time constrains it is infeasible to do a ran- dom search across the full hyper-parameter space. Thus, for the tasks of POS tagging and NER we try to share as man y hyper -parameters as possible. Note that the final hyper-parameters for these two tasks are almost the same, except the initial learn- ing rate. W e set the state size of LSTM to 200 . T uning this parameter did not significantly impact the performance of our model. For CNN, we use 30 filters with windo w length 3. 4 Experiments 4.1 Data Sets As mentioned before, we ev aluate our neural net- work model on two sequence labeling tasks: POS tagging and NER. Dataset WSJ CoNLL2003 T rain SENT 38,219 14,987 TOKEN 912,344 204,567 De v SENT 5,527 3,466 TOKEN 131,768 51,578 T est SENT 5,462 3,684 TOKEN 129,654 46,666 T able 2: Corpora statistics. SENT and TOKEN refer to the number of sentences and tokens in each data set. POS T agging . For English POS tagging, we use the W all Street Journal (WSJ) portion of Penn T reebank (PTB) (Marcus et al., 1993), which con- tains 45 different POS tags. In order to com- pare with previous work, we adopt the standard splits — section 0–18 as training data, section 19– 21 as development data and section 22–24 as test data (Manning, 2011; Søgaard, 2011). NER . For NER, W e perform experiments on the English data from CoNLL 2003 shared task (Tjong Kim Sang and De Meulder , 2003). This data set contains four different types of named entities: PERSON, LOCATION, ORGA- NIZA TION , and MISC . W e use the BIOES tag- ging scheme instead of standard BIO2 , as pre- vious studies have reported meaningful improve- ment with this scheme (Ratinov and Roth, 2009; Dai et al., 2015; Lample et al., 2016). The corpora statistics are shown in T able 2. W e did not perform any pre-processing for data sets, leaving our system truly end-to-end. 4.2 Main Results W e first run experiments to dissect the effecti ve- ness of each component (layer) of our neural net- work architecture by ablation studies. W e com- pare the performance with three baseline systems — BRNN, the bi-direction RNN; BLSTM, the bi- direction LSTM, and BLSTM-CNNs, the combi- nation of BLSTM with CNN to model character- le vel information. All these models are run using Stanford’ s GloV e 100 dimensional word embed- dings and the same hyper-parameters as sho wn in T able 1. According to the results shown in T a- ble 3, BLSTM obtains better performance than BRNN on all ev aluation metrics of both the two tasks. BLSTM-CNN models significantly outper- form the BLSTM model, sho wing that character- le vel representations are important for linguistic sequence labeling tasks. This is consistent with POS NER Dev T est De v T est Model Acc. Acc. Prec. Recall F1 Prec. Recall F1 BRNN 96.56 96.76 92.04 89.13 90.56 87.05 83.88 85.44 BLSTM 96.88 96.93 92.31 90.85 91.57 87.77 86.23 87.00 BLSTM-CNN 97.34 97.33 92.52 93.64 93.07 88.53 90.21 89.36 BRNN-CNN-CRF 97.46 97.55 94.85 94.63 94.74 91.35 91.06 91.21 T able 3: Performance of our model on both the de velopment and test sets of the tw o tasks, together with three baseline systems. Model Acc. Gim ´ enez and M ` arquez (2004) 97.16 T outanov a et al. (2003) 97.27 Manning (2011) 97.28 Collobert et al. (2011) ‡ 97.29 Santos and Zadrozny (2014) ‡ 97.32 Shen et al. (2007) 97.33 Sun (2014) 97.36 Søgaard (2011) 97.50 This paper 97.55 T able 4: POS tagging accuracy of our model on test data from WSJ proportion of PTB, together with top-performance systems. The neural net- work based models are marked with ‡ . results reported by previous work (Santos and Zadrozny , 2014; Chiu and Nichols, 2015). Fi- nally , by adding CRF layer for joint decoding we achie ve significant improv ements ov er BLSTM- CNN models for both POS tagging and NER on all metrics. This demonstrates that jointly decod- ing label sequences can significantly benefit the fi- nal performance of neural network models. 4.3 Comparison with Pre vious W ork 4.3.1 POS T agging T able 4 illustrates the results of our model for POS tagging, together with se ven previous top- performance systems for comparison. Our model significantly outperform Senna (Collobert et al., 2011), which is a feed-forward neural network model using capitalization and discrete suffix fea- tures, and data pre-processing. Moreover , our model achiev es 0.23% improvements on accu- racy over the “CharWNN” (Santos and Zadrozny , 2014), which is a neural network model based on Senna and also uses CNNs to model character - le vel representations. This demonstrates the ef fec- ti veness of BLSTM for modeling sequential data Model F1 Chieu and Ng (2002) 88.31 Florian et al. (2003) 88.76 Ando and Zhang (2005) 89.31 Collobert et al. (2011) ‡ 89.59 Huang et al. (2015) ‡ 90.10 Chiu and Nichols (2015) ‡ 90.77 Ratinov and Roth (2009) 90.80 Lin and W u (2009) 90.90 Passos et al. (2014) 90.90 Lample et al. (2016) ‡ 90.94 Luo et al. (2015) 91.20 This paper 91.21 T able 5: NER F1 score of our model on test data set from CoNLL-2003. For the purpose of com- parison, we also list F1 scores of previous top- performance systems. ‡ marks the neural models. and the importance of joint decoding with struc- tured prediction model. Comparing with traditional statistical models, our system achieves state-of-the-art accuracy , ob- taining 0.05% improvement o ver the previously best reported results by Søgaard (2011). It should be noted that Huang et al. (2015) also ev aluated their BLSTM-CRF model for POS tagging on WSJ corpus. But they used a different splitting of the training/de v/test data sets. Thus, their results are not directly comparable with ours. 4.3.2 NER T able 5 shows the F1 scores of pre vious models for NER on the test data set from CoNLL-2003 shared task. For the purpose of comparison, we list their results together with ours. Similar to the observ ations of POS tagging, our model achiev es significant improv ements o ver Senna and the other three neural models, namely the LSTM-CRF pro- posed by Huang et al. (2015), LSTM-CNNs pro- Embedding Dimension POS NER Random 100 97.13 80.76 Senna 50 97.44 90.28 W ord2V ec 300 97.40 84.91 GloV e 100 97.55 91.21 T able 6: Results with different choices of word embeddings on the two tasks (accuracy for POS tagging and F1 for NER). posed by Chiu and Nichols (2015), and the LSTM- CRF by Lample et al. (2016). Huang et al. (2015) utilized discrete spelling, POS and context fea- tures, Chiu and Nichols (2015) used character- type, capitalization, and lexicon features, and all the three model used some task-specific data pre- processing, while our model does not require any carefully designed features or data pre-processing. W e have to point out that the result (90.77%) re- ported by Chiu and Nichols (2015) is incompa- rable with ours, because their final model was trained on the combination of the training and de- velopment data sets 4 . T o our knowledge, the previous best F1 score (91.20) 5 reported on CoNLL 2003 data set is by the joint NER and entity linking model (Luo et al., 2015). This model used many hand-crafted features including stemming and spelling features, POS and chunks tags, W ordNet clusters, Brown Clusters, as well as external knowledge bases such as Freebase and W ikipedia. Our end-to-end model slightly improves this model by 0.01%, yielding a state-of-the-art performance. 4.4 W ord Embeddings As mentioned in Section 3.1, in order to test the importance of pretrained word embeddings, we performed experiments with different sets of pub- licly published w ord embeddings, as well as a ran- dom sampling method, to initialize our model. T a- ble 6 giv es the performance of three different word embeddings, as well as the randomly sampled one. According to the results in T able 6, models using pretrained word embeddings obtain a significant improv ement as opposed to the ones using random embeddings. Comparing the two tasks, NER relies 4 W e run e xperiments using the same setting and get 91.37% F1 score. 5 Numbers are taken from the T able 3 of the original pa- per (Luo et al., 2015). While there is clearly inconsistency among the precision (91.5%), recall (91.4%) and F1 scores (91.2%), it is unclear in which way they are incorrect. POS NER T rain Dev T est T rain De v T est No 98.46 97.06 97.11 99.97 93.51 89.25 Y es 97.86 97.46 97.55 99.63 94.74 91.21 T able 7: Results with and without dropout on two tasks (accurac y for POS tagging and F1 for NER). POS NER De v T est Dev T est IV 127,247 125,826 4,616 3,773 OO TV 2,960 2,412 1,087 1,597 OOEV 659 588 44 8 OOBV 902 828 195 270 T able 8: Statistics of the partition on each corpus. It lists the number of tokens of each subset for POS tagging and the number of entities for NER. more heavily on pretrained embeddings than POS tagging. This is consistent with results reported by previous work (Collobert et al., 2011; Huang et al., 2015; Chiu and Nichols, 2015). For dif ferent pretrained embeddings, Stanford’ s GloV e 100 dimensional embeddings achiev e best results on both tasks, about 0.1% better on POS accuracy and 0.9% better on NER F1 score than the Senna 50 dimensional one. This is dif- ferent from the results reported by Chiu and Nichols (2015), where Senna achiev ed slightly better performance on NER than other embed- dings. Google’ s W ord2V ec 300 dimensional em- beddings obtain similar performance with Senna on POS tagging, still slightly behind GloV e. But for NER, the performance on W ord2V ec is far be- hind GloV e and Senna. One possible reason that W ord2V ec is not as good as the other two embed- dings on NER is because of vocabulary mismatch — W ord2V ec embeddings were trained in case- sensiti ve manner, excluding many common sym- bols such as punctuations and digits. Since we do not use any data pre-processing to deal with such common symbols or rare words, it might be an is- sue for using W ord2V ec. 4.5 Effect of Dropout T able 7 compares the results with and without dropout layers for each data set. All other hyper- parameters remain the same as in T able 1. W e observe a essential improvement for both the two tasks. It demonstrates the ef fecti veness of dropout in reducing ov erfitting. POS De v T est IV OOTV OOEV OOBV IV OO TV OOEV OOBV LSTM-CNN 97.57 93.75 90.29 80.27 97.55 93.45 90.14 80.07 LSTM-CNN-CRF 97.68 93.65 91.05 82.71 97.77 93.16 90.65 82.49 NER De v T est IV OOTV OOEV OOBV IV OO TV OOEV OOBV LSTM-CNN 94.83 87.28 96.55 82.90 90.07 89.45 100.00 78.44 LSTM-CNN-CRF 96.49 88.63 97.67 86.91 92.14 90.73 100.00 80.60 T able 9: Comparison of performance on different subsets of w ords (accuracy for POS and F1 for NER). 4.6 OO V Error Analysis T o better understand the behavior of our model, we perform error analysis on Out-of-V ocab ulary words (OO V). Specifically , we partition each data set into four subsets — in-vocab ulary words (IV), out-of-training-v ocabulary words (OO TV), out-of-embedding-vocab ulary words (OOEV) and out-of-both-vocab ulary w ords (OOBV). A word is considered IV if it appears in both the training and embedding vocab ulary , while OOBV if nei- ther . OOTV words are the ones do not appear in training set but in embedding vocab ulary , while OOEV are the ones do not appear in embedding vocab ulary but in training set. For NER, an en- tity is considered as OOBV if there exists at lease one word not in training set and at least one word not in embedding vocab ulary , and the other three subsets can be done in similar manner . T able 8 in- forms the statistics of the partition on each corpus. The embedding we used is Stanford’ s GloV e with dimension 100, the same as Section 4.2. T able 9 illustrates the performance of our model on different subsets of w ords, together with the baseline LSTM-CNN model for comparison. The largest improv ements appear on the OOBV sub- sets of both the two corpora. This demonstrates that by adding CRF for joint decoding, our model is more po werful on words that are out of both the training and embedding sets. 5 Related W ork In recent years, se veral different neural network architectures ha ve been proposed and successfully applied to linguistic sequence labeling such as POS tagging, chunking and NER. Among these neural architectures, the three approaches most similar to our model are the BLSTM-CRF model proposed by Huang et al. (2015), the LSTM- CNNs model by Chiu and Nichols (2015) and the BLSTM-CRF by Lample et al. (2016). Huang et al. (2015) used BLSTM for word-le vel representations and CRF for jointly label decod- ing, which is similar to our model. But there are two main differences between their model and ours. First, they did not employ CNNs to model character-le vel information. Second, they combined their neural network model with hand- crafted features to improv e their performance, making their model not an end-to-end system. Chiu and Nichols (2015) proposed a hybrid of BLSTM and CNNs to model both character- and word-le vel representations, which is similar to the first two layers in our model. They e valuated their model on NER and achieved competiti ve perfor- mance. Our model mainly differ from this model by using CRF for joint decoding. Moreover , their model is not truly end-to-end, either , as it utilizes external knowledge such as character-type, capi- talization and lexicon features, and some data pre- processing specifically for NER (e.g. replacing all sequences of digits 0-9 with a single “0”). Re- cently , Lample et al. (2016) proposed a BLSTM- CRF model for NER, which utilized BLSTM to model both the character- and word-le vel infor- mation, and use data pre-processing the same as Chiu and Nichols (2015). Instead, we use CNN to model character-le vel information, achieving bet- ter NER performance without using any data pre- processing. There are sev eral other neural networks previ- ously proposed for sequence labeling. Labeau et al. (2015) proposed a RNN-CNNs model for Ger- man POS tagging. This model is similar to the LSTM-CNNs model in Chiu and Nichols (2015), with the difference of using vanila RNN instead of LSTM. Another neural architecture employing CNN to model character-le vel information is the “CharWNN” architecture (Santos and Zadrozny , 2014) which is inspired by the feed-forward net- work (Collobert et al., 2011). CharWNN obtained near state-of-the-art accuracy on English POS tag- ging (see Section 4.3 for details). A similar model has also been applied to Spanish and Portuguese NER (dos Santos et al., 2015) Ling et al. (2015) and Y ang et al. (2016) also used BSL TM to com- pose character embeddings to word’ s representa- tion, which is similar to Lample et al. (2016). Peng and Dredze (2016) Improved NER for Chinese So- cial Media with W ord Segmentation. 6 Conclusion In this paper , we proposed a neural network archi- tecture for sequence labeling. It is a truly end-to- end model relying on no task-specific resources, feature engineering or data pre-processing. W e achie ved state-of-the-art performance on two lin- guistic sequence labeling tasks, comparing with pre viously state-of-the-art systems. There are sev eral potential directions for future work. First, our model can be further improved by exploring multi-task learning approaches to combine more useful and correlated information. For example, we can jointly train a neural net- work model with both the POS and NER tags to improv e the intermediate representations learned in our network. Another interesting direction is to apply our model to data from other domains such as social media (T witter and W eibo). Since our model does not require any domain- or task- specific knowledge, it might be effortless to apply it to these domains. Acknowledgements This research was supported in part by D ARP A grant F A8750-12-2-0342 funded under the DEFT program. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the vie ws of D ARP A. References [Ando and Zhang2005] Rie Kubota Ando and T ong Zhang. 2005. A framework for learning predic- tiv e structures from multiple tasks and unlabeled data. The J ournal of Machine Learning Researc h , 6:1817–1853. [Bengio et al.1994] Y oshua Bengio, P atrice Simard, and Paolo Frasconi. 1994. Learning long-term de- pendencies with gradient descent is dif ficult. Neural Networks, IEEE T ransactions on , 5(2):157–166. [Bergstra et al.2010] James Bergstra, Olivier Breuleux, Fr ´ ed ´ eric Bastien, Pascal Lamblin, Razvan Pascanu, Guillaume Desjardins, Joseph T urian, David W arde- Farle y , and Y oshua Bengio. 2010. Theano: a cpu and gpu math expression compiler . In Pr oceedings of the Python for scientific computing conference (SciPy) , volume 4, page 3. Austin, TX. [Chen and Manning2014] Danqi Chen and Christopher Manning. 2014. A fast and accurate dependency parser using neural networks. In Pr oceedings of EMNLP-2014 , pages 740–750, Doha, Qatar , Octo- ber . [Chieu and Ng2002] Hai Leong Chieu and Hwee T ou Ng. 2002. Named entity recognition: a maximum entropy approach using global information. In Pro- ceedings of CoNLL-2003 , pages 1–7. [Chiu and Nichols2015] Jason PC Chiu and Eric Nichols. 2015. Named entity recognition with bidirectional lstm-cnns. arXiv pr eprint arXiv:1511.08308 . [Cho et al.2014] Kyunghyun Cho, Bart van Merri ¨ enboer , Dzmitry Bahdanau, and Y oshua Bengio. 2014. On the properties of neural machine translation: Encoder–decoder approaches. Syntax, Semantics and Structur e in Statistical T ranslation , page 103. [Collobert et al.2011] Ronan Collobert, Jason W eston, L ´ eon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pav el Kuksa. 2011. Natural language process- ing (almost) from scratch. The Journal of Machine Learning Resear ch , 12:2493–2537. [Dai et al.2015] Hong-Jie Dai, Po-T ing Lai, Y ung-Chun Chang, and Richard Tzong-Han Tsai. 2015. En- hancing of chemical compound and drug name recognition using representati ve tag scheme and fine-grained tok enization. Journal of cheminformat- ics , 7(S1):1–10. [Dauphin et al.2015] Y ann N Dauphin, Harm de Vries, Junyoung Chung, and Y oshua Bengio. 2015. Rmsprop and equilibrated adapti ve learning rates for non-con ve x optimization. arXiv pr eprint arXiv:1502.04390 . [dos Santos et al.2015] Cıcero dos Santos, V ictor Guimaraes, RJ Niter ´ oi, and Rio de Janeiro. 2015. Boosting named entity recognition with neural character embeddings. In Pr oceedings of NEWS 2015 The F ifth Named Entities W orkshop , page 25. [Dyer et al.2015] Chris Dyer , Miguel Ballesteros, W ang Ling, Austin Matthews, and Noah A. Smith. 2015. Transition-based dependency parsing with stack long short-term memory . In Pr oceedings of A CL-2015 (V olume 1: Long P apers) , pages 334–343, Beijing, China, July . [Florian et al.2003] Radu Florian, Abe Ittycheriah, Hongyan Jing, and T ong Zhang. 2003. Named en- tity recognition through classifier combination. In Pr oceedings of HLT -N AA CL-2003 , pages 168–171. [Gers et al.2000] Felix A Gers, J ¨ urgen Schmidhuber , and Fred Cummins. 2000. Learning to forget: Con- tinual prediction with lstm. Neural computation , 12(10):2451–2471. [Gers et al.2003] Felix A Gers, Nicol N Schraudolph, and J ¨ urgen Schmidhuber . 2003. Learning precise timing with lstm recurrent networks. The Journal of Machine Learning Resear ch , 3:115–143. [Giles2001] Rich Caruana Stev e Lawrence Lee Giles. 2001. Overfitting in neural nets: Backpropagation, conjugate gradient, and early stopping. In Advances in Neural Information Processing Systems 13: Pr o- ceedings of the 2000 Conference , volume 13, page 402. MIT Press. [Gim ´ enez and M ` arquez2004] Jes ´ us Gim ´ enez and Llu ´ ıs M ` arquez. 2004. Svmtool: A general pos tagger generator based on support vector machines. In In Pr oceedings of LREC-2004 . [Glorot and Bengio2010] Xavier Glorot and Y oshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. In In- ternational confer ence on artificial intelligence and statistics , pages 249–256. [Goller and Kuchler1996] Christoph Goller and An- dreas Kuchler . 1996. Learning task-dependent dis- tributed representations by backpropagation through structure. In Neural Networks, 1996., IEEE Inter- national Confer ence on , volume 1, pages 347–352. IEEE. [Grav es et al.2013] Alan Graves, Abdel-rahman Mo- hamed, and Geoffrey Hinton. 2013. Speech recog- nition with deep recurrent neural networks. In Pr o- ceedings of ICASSP-2013 , pages 6645–6649. IEEE. [He et al.2015] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving deep into recti- fiers: Surpassing human-lev el performance on ima- genet classification. In Pr oceedings of the IEEE In- ternational Conference on Computer V ision , pages 1026–1034. [Hochreiter and Schmidhuber1997] Sepp Hochreiter and J ¨ urgen Schmidhuber . 1997. Long short-term memory . Neural computation , 9(8):1735–1780. [Hu et al.2016] Zhiting Hu, Xuezhe Ma, Zhengzhong Liu, Eduard H. Hovy , and Eric P . Xing. 2016. Har- nessing deep neural networks with logic rules. In Pr oceedings of ACL-2016 , Berlin, Germany , Au- gust. [Huang et al.2015] Zhiheng Huang, W ei Xu, and Kai Y u. 2015. Bidirectional lstm-crf models for se- quence tagging. arXiv pr eprint arXiv:1508.01991 . [Jozefowicz et al.2015] Raf al Jozefowicz, W ojciech Zaremba, and Ilya Sutskev er . 2015. An empirical exploration of recurrent network architectures. In Pr oceedings of the 32nd International Confer ence on Machine Learning (ICML-15) , pages 2342–2350. [Kingma and Ba2014] Diederik Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization. arXiv pr eprint arXiv:1412.6980 . [K oo and Collins2010] T erry Koo and Michael Collins. 2010. Efficient third-order dependency parsers. In Pr oceedings of ACL-2010 , pages 1–11, Uppsala, Sweden, July . [Labeau et al.2015] Matthieu Labeau, Ke vin L ¨ oser , Alexandre Allauzen, and Rue John von Neumann. 2015. Non-lexical neural architecture for fine- grained pos tagging. In Proceedings of the 2015 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , pages 232–237. [Lafferty et al.2001] John Laf ferty , Andrew McCallum, and Fernando CN Pereira. 2001. Conditional ran- dom fields: Probabilistic models for segmenting and labeling sequence data. In Pr oceedings of ICML- 2001 , volume 951, pages 282–289. [Lample et al.2016] Guillaume Lample, Miguel Balles- teros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer . 2016. Neural architectures for named entity recognition. In Pr oceedings of N AA CL-2016 , San Diego, California, USA, June. [LeCun et al.1989] Y ann LeCun, Bernhard Boser , John S Denker , Donnie Henderson, Richard E How ard, W ayne Hubbard, and Lawrence D Jackel. 1989. Backpropagation applied to handwrit- ten zip code recognition. Neural computation , 1(4):541–551. [Lin and W u2009] Dekang Lin and Xiaoyun W u. 2009. Phrase clustering for discriminativ e learning. In Pr oceedings of ACL-2009 , pages 1030–1038. [Ling et al.2015] W ang Ling, Chris Dyer , Alan W Black, Isabel Trancoso, Ramon Fermandez, Silvio Amir , Luis Marujo, and T iago Luis. 2015. Finding function in form: Compositional character models for open vocabulary word representation. In Pro- ceedings of EMNLP-2015 , pages 1520–1530, Lis- bon, Portugal, September . [Luo et al.2015] Gang Luo, Xiaojiang Huang, Chin- Y e w Lin, and Zaiqing Nie. 2015. Joint entity recognition and disambiguation. In Pr oceedings of EMNLP-2015 , pages 879–888, Lisbon, Portugal, September . [Ma and Hovy2015] Xuezhe Ma and Eduard Hovy . 2015. Ef ficient inner-to-outer greedy algorithm for higher-order labeled dependency parsing. In Pro- ceedings of the EMNLP-2015 , pages 1322–1328, Lisbon, Portugal, September . [Ma and Xia2014] Xuezhe Ma and Fei Xia. 2014. Unsupervised dependency parsing with transferring distribution via parallel guidance and entropy reg- ularization. In Pr oceedings of A CL-2014 , pages 1337–1348, Baltimore, Maryland, June. [Ma and Zhao2012a] Xuezhe Ma and Hai Zhao. 2012a. Fourth-order dependency parsing. In Pr oceedings of COLING 2012: P osters , pages 785–796, Mumbai, India, December . [Ma and Zhao2012b] Xuezhe Ma and Hai Zhao. 2012b . Probabilistic models for high-order pro- jectiv e dependency parsing. T echnical Report, arXiv:1502.04174 . [Ma et al.2016] Xuezhe Ma, Zhengzhong Liu, and Ed- uard Hovy . 2016. Unsupervised ranking model for entity coreference resolution. In Pr oceedings of N AA CL-2016 , San Diego, California, USA, June. [Manning2011] Christopher D Manning. 2011. Part- of-speech tagging from 97% to 100%: is it time for some linguistics? In Computational Linguis- tics and Intelligent T ext Pr ocessing , pages 171–189. Springer . [Marcus et al.1993] Mitchell Marcus, Beatrice San- torini, and Mary Ann Marcinkiewicz. 1993. Build- ing a large annotated corpus of English: the Penn T reebank. Computational Linguistics , 19(2):313– 330. [McDonald et al.2005] Ryan McDonald, Koby Cram- mer , and Fernando Pereira. 2005. Online large- margin training of dependency parsers. In Pr oceed- ings of ACL-2005 , pages 91–98, Ann Arbor , Michi- gan, USA, June 25-30. [Mikolov et al.2013] T omas Mikolov , Ilya Sutskev er, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality . In Advances in neural information pr ocessing systems , pages 3111–3119. [Ng2010] V incent Ng. 2010. Supervised noun phrase coreference research: The first fifteen years. In Pr o- ceedings of A CL-2010 , pages 1396–1411, Uppsala, Sweden, July . Association for Computational Lin- guistics. [Nivre and Scholz2004] Joakim Ni vre and Mario Scholz. 2004. Deterministic dependency parsing of English text. In Pr oceedings of COLING-2004 , pages 64–70, Genev a, Switzerland, August 23-27. [Pascanu et al.2012] Razv an Pascanu, T omas Mikolov , and Y oshua Bengio. 2012. On the difficulty of training recurrent neural networks. arXiv pr eprint arXiv:1211.5063 . [Passos et al.2014] Alexandre Passos, V ineet Kumar , and Andrew McCallum. 2014. Lexicon infused phrase embeddings for named entity resolution. In Pr oceedings of CoNLL-2014 , pages 78–86, Ann Ar- bor , Michigan, June. [Peng and Dredze2015] Nanyun Peng and Mark Dredze. 2015. Named entity recognition for chi- nese social media with jointly trained embeddings. In Proceedings of EMNLP-2015 , pages 548–554, Lisbon, Portugal, September . [Peng and Dredze2016] Nanyun Peng and Mark Dredze. 2016. Improving named entity recognition for chinese social media with word segmenta- tion representation learning. In Proceedings of A CL-2016 , Berlin, Germany , August. [Pennington et al.2014] Jeffre y Pennington, Richard Socher , and Christopher Manning. 2014. Glove: Global v ectors for word representation. In Pro- ceedings of EMNLP-2014 , pages 1532–1543, Doha, Qatar , October . [Ratinov and Roth2009] Le v Ratinov and Dan Roth. 2009. Design challenges and misconceptions in named entity recognition. In Pr oceedings of CoNLL-2009 , pages 147–155. [Santos and Zadrozny2014] Cicero D Santos and Bianca Zadrozny . 2014. Learning character-le vel representations for part-of-speech tagging. In Pr oceedings of ICML-2014 , pages 1818–1826. [Shen et al.2007] Libin Shen, Giorgio Satta, and Ar - avind Joshi. 2007. Guided learning for bidirec- tional sequence classification. In Pr oceedings of A CL-2007 , volume 7, pages 760–767. [Søgaard2011] Anders Søgaard. 2011. Semi- supervised condensed nearest neighbor for part-of- speech tagging. In Pr oceedings of the 49th Annual Meeting of the Association for Computational Lin- guistics: Human Languag e T echnologies , pages 48– 52, Portland, Oregon, USA, June. [Sriv astav a et al.2014] Nitish Sriv astava, Geoffre y Hin- ton, Ale x Krizhevsk y , Ilya Sutskev er , and Ruslan Salakhutdinov . 2014. Dropout: A simple way to prev ent neural networks from overfitting. The Jour - nal of Machine Learning Resear ch , 15(1):1929– 1958. [Sun2014] Xu Sun. 2014. Structure regularization for structured prediction. In Advances in Neural Infor- mation Pr ocessing Systems , pages 2402–2410. [Tjong Kim Sang and De Meulder2003] Erik F . Tjong Kim Sang and Fien De Meulder . 2003. Intro- duction to the conll-2003 shared task: Language- independent named entity recognition. In Pr oceed- ings of CoNLL-2003 - V olume 4 , pages 142–147, Stroudsbur g, P A, USA. [Tjong Kim Sang and V eenstra1999] Erik F . Tjong Kim Sang and Jorn V eenstra. 1999. Representing text chunks. In Pr oceedings of EA CL’99 , pages 173–179. Bergen, Norw ay . [T outanov a et al.2003] Kristina T outanov a, Dan Klein, Christopher D Manning, and Y oram Singer . 2003. Feature-rich part-of-speech tagging with a cyclic de- pendency network. In Pr oceedings of NAA CL-HLT - 2003, V olume 1 , pages 173–180. [Y ang et al.2016] Zhilin Y ang, Ruslan Salakhutdinov , and William Cohen. 2016. Multi-task cross-lingual sequence tagging from scratch. arXiv preprint arXiv:1603.06270 . [Zeiler2012] Matthew D Zeiler . 2012. Adadelta: an adaptiv e learning rate method. arXiv prepr int arXiv:1212.5701 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment