양방향 LSTM CNN CRF 기반 엔드투엔드 시퀀스 라벨링
본 논문은 단어와 문자 수준의 표현을 동시에 학습하는 양방향 LSTM‑CNN‑CRF 모델을 제안한다. 사전 정의된 특징이나 전처리 없이 사전 학습된 워드 임베딩만을 입력으로 사용해 POS 태깅과 NER 두 과제에서 각각 97.55% 정확도와 91.21% F1 점수를 기록함으로써 현재 최고 성능을 달성하였다.
저자: Xuezhe Ma, Eduard Hovy
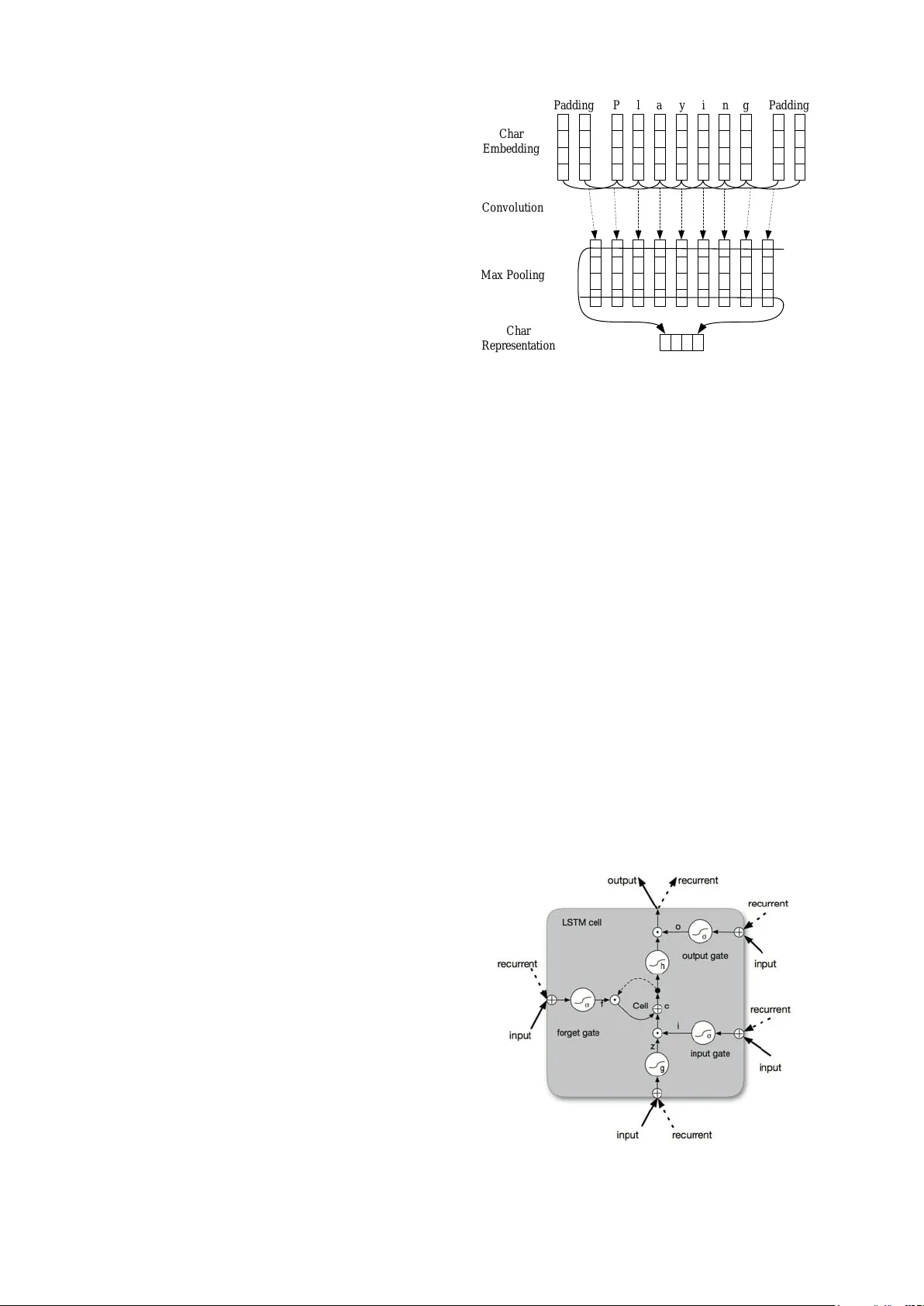
논문은 자연어 처리에서 가장 기본적인 단계인 시퀀스 라벨링, 즉 품사 태깅(POS)과 명명 엔터티 인식(NER)을 위한 새로운 신경망 아키텍처를 제시한다. 기존의 고성능 모델들은 HMM, CRF와 같은 선형 통계 모델에 의존하면서 수많은 손수 만든 특징과 외부 사전(예: gazetteer)을 필요로 했으며, 이는 새로운 언어나 도메인에 적용하기 어려운 단점이 있었다. 최근에는 워드 임베딩을 활용한 RNN, LSTM 기반 모델이 등장했지만, 이들 역시 문자 수준의 정보를 완전히 대체하지 못하고 보조적인 특징으로만 활용되는 경우가 많았다. 이를 극복하고자 저자들은 세 가지 핵심 모듈을 결합한 엔드투엔드 구조를 설계했다. 첫 번째 모듈은 문자 수준 정보를 추출하는 1‑D CNN이다. 각 문자에 30‑dim 임베딩을 부여하고, 필터 크기 3의 컨볼루션을 30개 적용해 문자 시퀀스에서 형태소적 패턴을 자동으로 학습한다. 컨볼루션 결과는 max‑pooling을 통해 고정 차원의 문자 벡터로 압축된다. 두 번째 모듈은 양방향 LSTM(BLSTM)이다. 문자 벡터와 사전 학습된 워드 임베딩(주로 GloVe 100‑dim)을 연결해 단어의 복합 표현을 만든 뒤, 이 표현을 BLSTM에 입력한다. BLSTM은 과거와 미래 컨텍스트를 동시에 고려해 각 토큰에 대한 풍부한 은닉 상태를 생성한다. 세 번째 모듈은 조건부 랜덤 필드(CRF)이다. BLSTM의 출력에 선형 변환을 적용한 뒤, 라벨 전이 매트릭스를 학습해 전체 시퀀스에 대한 점수를 계산한다. Viterbi 알고리즘을 이용해 가장 높은 점수를 갖는 라벨 시퀀스를 선택함으로써, 개별 토큰 예측이 아니라 전역적인 라벨 구조를 최적화한다. 학습 단계에서는 Theano 기반 구현으로 GTX Titan X GPU에서 실행했으며, 미니배치 SGD(배치 10, 모멘텀 0.9)와 학습률 감쇠(η₀=0.01~0.015, ρ=0.05)를 사용했다. 그래디언트 폭주를 방지하기 위해 5.0으로 클리핑하고, 입력·출력 모두에 0.5 드롭아웃을 적용해 과적합을 억제했다. 파라미터 초기화는 Glorot 방식과 uniform 분포를 사용했으며, LSTM의 forget‑gate bias는 1.0으로 초기화했다. 실험은 Penn Treebank WSJ( POS)와 CoNLL‑2003( NER) 두 데이터셋에서 수행되었다. 기본 설정으로 BLSTM만 사용할 경우 POS 정확도 96.88%, NER F1 90.56%를 기록했으며, 여기에 문자‑CNN을 추가한 BLSTM‑CNN 모델은 각각 97.34%와 93.07%로 향상되었다. 최종적으로 CRF 레이어를 결합한 BLSTM‑CNN‑CRF 모델은 POS 97.55% 정확도와 NER 91.21% F1 점수를 달성해 기존 최고 성능을 넘어섰다. 비교 실험에서는 다른 사전 학습 임베딩(Senna, Word2Vec)과 무작위 초기화된 임베딩을 사용했을 때도 비슷한 수준의 성능을 보였으며, 특히 워드 임베딩을 미세조정(fine‑tune)했을 때 가장 큰 이득을 얻었다. Ablation study는 문자‑CNN과 CRF 각각이 모델 성능에 기여하는 바를 명확히 보여준다. 전체적으로 이 논문은 복잡한 전처리 없이도 문자와 단어 수준 정보를 동시에 학습하고, 라벨 전이 제약을 활용함으로써 다양한 시퀀스 라벨링 작업에 적용 가능한 범용적인 엔드투엔드 솔루션을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기