Meta-learning within Projective Simulation
Learning models of artificial intelligence can nowadays perform very well on a large variety of tasks. However, in practice different task environments are best handled by different learning models, rather than a single, universal, approach. Most non…
Authors: Adi Makmal, Alexey A. Melnikov, Vedran Dunjko
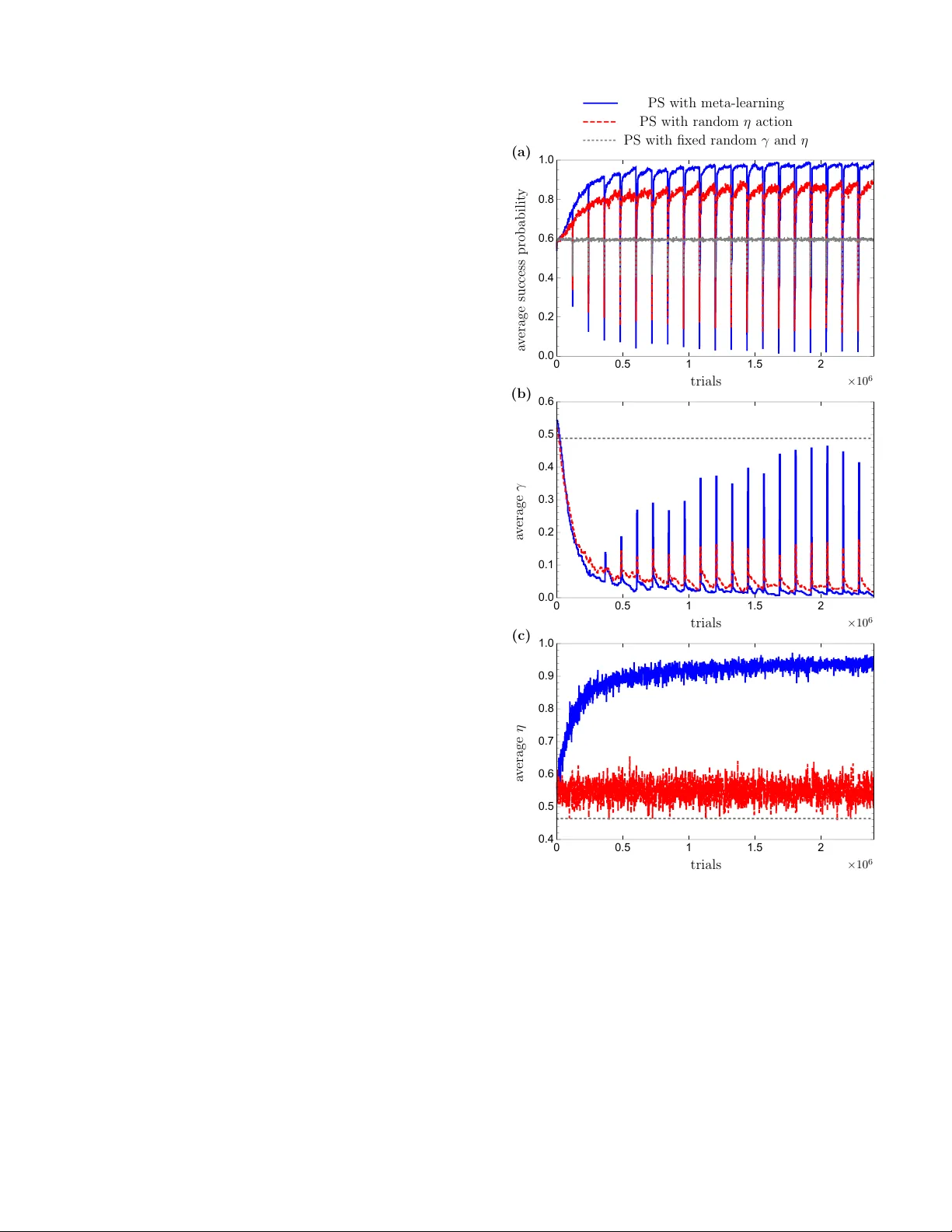
Meta-learning within Pro jectiv e Sim ulation Adi Makmal, 1 Alexey A. Melnik ov, 1, 2 V edran Dunjk o, 1 and Hans J. Briegel 1 1 Institut f¨ ur The or etische Physik, Universit¨ at Innsbruck, T e chnikerstr aße 21a, A-6020 Innsbruck, Austria 2 Institut f¨ ur Quantenoptik und Quanteninformation der ¨ Osterr eichischen Akademie der Wissenschaften, T e chnikerstr aße 21a, A-6020 Innsbruck, Austria (Dated: Septem b er 5, 2018) Learning mo dels of artificial intel ligence can now ada ys p erform very w ell on a large v ariet y of tasks. Ho wev er, in practice different task en vironmen ts are best handled by differen t learning models, rather than a single, universal, approach. Most non-trivial mo dels th us require the adjustment of several to man y learning parameters, which is often done on a case-by-case basis by an external part y . Meta-learning refers to the ability of an agent to autonomously and dynamically adjust its own learning parameters, or meta-parameters. In this w ork w e sho w ho w pro jectiv e sim ulation, a recently dev elop ed mo del of artificial intelligence, can naturally b e extended to account for meta-learning in reinforcement learning settings. The pro jectiv e sim ulation approac h is based on a random walk pro cess ov er a netw ork of clips. The suggested meta-learning sc heme builds up on the same design and employs clip netw orks to monitor the agent’s performance and to adjust its meta-parameters “on the fly”. W e distinguish betw een “reflexiv e adaptation” and “adaptation through learning”, and sho w the utility of both approac hes. In addition, a trade-off betw een flexibility and learning-time is addressed. The extended model is examined on three differen t kinds of reinforcemen t learning tasks, in whic h the agent has different optimal v alues of the meta-parameters, and is shown to p erform w ell, reaching near-optimal to optimal success rates in all of them, without ever needing to man ually adjust an y meta-parameter. I. INTR ODUCTION There are many differen t kinds of artificial intelligen t (AI) schemes. These schemes differ in their design, pur- p ose, and underlying principles [ 1 ]. One feature common to all non-trivial proposals is the existence of learning pa- rameters, whic h reflect certain assumptions or bias ab out the task or en vironment with whic h the agen t has to cop e [ 2 ]. Moreo ver, as a consequence of the so-called no-free lunc h theorems [ 3 ], it is known that it is imp ossible to ha ve a fixed set of parameters which are optimal for all task environmen ts. In practice these parameters (which, for some schemes, ma y b e more than a dozen, e.g. in the extended learning classifier systems [ 4 ]) are typically fine-tuned man ually by an external party (the user), on a case-by-case basis. An autonomous agent, how ev er, is exp ected to adjust its learning parameters, automat- ically , by itself. Suc h a self monitoring and adaptation of the agent’s own internal settings is often termed as meta-le arning [ 2 , 5 , 6 ]. In the AI literature the term meta-learning, defined as “learning to learn” [ 7 ] or as a process of acquiring meta- kno wledge [ 2 , 6 ], is used in a broad sense and accoun ts for v arious concepts. These concepts are tightly linked to practical problems, t wo of which are mostly consid- ered in the context of meta-learning. In the first prob- lem meta-learning accoun ts for a selection of a suitable learning mo del for a giv en task [ 8 – 12 ] or combination of mo dels [ 13 ], including automatic adjustments when the task is changed. In the second problem meta-learning accoun ts for automatic tuning of model learning param- eters, also referred to as meta-parameters [ 5 , 14 – 18 ] in reinforcemen t learning (RL) or hyperparameters [ 19 – 25 ] in supervised learning. Both of these concepts of meta-learning are widely ad- dressed in the framework of sup ervised learning. The problem of sup ervised learning mo del selection, or al- gorithm recommendation, is solv ed b y , e.g., the k- Nearest Neighbor algorithm [ 9 ], similarity-based meth- o ds [ 8 ], meta decision trees [ 13 ] or an empirical error criterion [ 11 ]. The second problem in meta-learning, the tuning of h yperparameters, is usually solved by gradien t-based optimization [ 19 ], grid search [ 20 ], ran- dom search [ 21 ], genetic algorithms [ 22 ] or Bay esian op- timization [ 23 , 25 ]. Approac hes to combined algorithm selection and hyperparameter optimization were recen tly presen ted in Refs. [ 23 – 25 ]. In the RL framew ork, where an agent learns from in teracting with a rewarding environmen t [ 26 ], the no- tion of meta-learning usually addresses the second prac- tical problem, the need to automatically adjust meta- parameters, such as the discoun t factor, the learning rate and the exploitation-exploration parameter [ 14 – 18 , 27 ]. In the context of RL it is also worth while to mention the G¨ odel machine [ 28 ], whic h is, due to its complexity , of in terest predominantly as a theoretical construction in whic h all p ossible meta-levels of learning are contained in fully self-referential learning system. In this paper w e develop a simple form of meta-learning for the recently introduced mo del of pro jectiv e simula- tion (PS) [ 29 ]. The PS is a mo del of artificial in telligence that is particularly suited to RL problems (see [ 30 – 32 ] where the PS was shown to p erform well, in compar- ison to more standard RL machinery , on b oth to y- and real-w orld tasks suc h as the “grid-w orld”, the “mountain- car”, the “cart-p ole balancing” problem and the “Infi- nite Mario” game, and see [ 33 ] where it handles infinitely large RL environmen ts through a particular generaliza- 2 tion mec hanism). The mo del is physics-orien ted, aiming at an embo died [ 34 ] (rather than computational) realiza- tion, with a random-walk through its memory structure as its primary pro cess. PS is based on a sp ecial type of memory , called the episo dic & c omp ositional memory (ECM), that can b e represented as a directed weigh ted graph of basic building blo cks, called clips , where each clip represents a memorized p ercept, action, or combi- nations thereof. Once a p ercept is p erceived by the PS agen t, the corresponding percept clip is activ ated, initiat- ing a random-w alk on the clip-netw ork, that is the ECM, un til an action clip is hit and the corresp onding action is p erformed b y the agen t. This realizes a sto c hastic pro- cessing of the agent’s exp erience. The elemen tary process of the PS, namely the random- w alk, is an established theoretical concept, with known applications in randomized algorithms [ 35 ], th us provid- ing a large theoretical to ol b ox for designing and analyz- ing the mo del. Moreov er, the random walk can b e ex- tended to the quan tum regime, leading to quantum walks [ 36 – 38 ], in which case polynomial and ev en exponential impro vemen ts ha ve been reported in e.g. hitting and mix- ing times [ 39 – 41 ]. The results in the theory of quantum w alks suggest that improv emen ts in the p erformance of the PS ma y b e achiev able by employing these quantum analogues. Recently , a quan tum v ariant of the PS (envi- sioned already in [ 29 ]) was indeed formalized and shown to exhibit a quadratic sp eed-up in delib eration time ov er its classical counterpart [ 42 – 44 ]. F rom the p ersp ective of meta-learning, the PS is a comparativ ely simple mo del with few num b er of learn- ing parameters [ 30 ]. This suggests that providing the PS agen t with a meta-learning mechanism ma y b e done while main taining its o verall simplicity . In addition to simplic- it y , we also aim at structural homogeneit y: the meta- learning comp onent should b e combined with the basic mo del in a natural w ay , with minimal external machin- ery . In accordance with these requirements, the meta- learning capability which we develop here is based on supplemen ting the basic ECM netw ork, which we call the base-level ECM netw ork, with additional meta-level ECM net w orks that dynamically monitor and control the PS meta-parameters. This extends the structure of the PS model from a single netw ork to several net works that influence eac h other. In general, when facing the challenge of meta-learning in RL, one imme diately encounters a trade-off b etw een efficiency (in terms of learning times) and success rates (in terms of achiev able rewards), on the one side, and flexibilit y on the other side (as p ointed out, e.g., also in [ 45 ]). Humans, for example, are extremely flexible and robust to changes in the environmen t, but are not v ery efficien t and reac h sub-optimal success rates. Machines, on the other hand, can learn fast and p erform optimally at a giv en task (or a family of tasks), yet fail completely on another. Clearly , to achiev e a level of robustness, ma- c hines would ha ve to rep eatedly revise and up date their in ternal design, i.e. to meta-learn, a pro cess whic h nec- essarily takes time. Moreov er, reac hing optimal success rates in certain tasks, ma y require an ov er-fitting of the sc heme’s meta-parameters, which migh t harm its success in other tasks. It can therefore b e exp ected that any form of meta-learning (which improv es the flexibility of the mo del), ma y do so at the exp ense of the mo del’s ef- ficiency and (p ossibly even) success rates, and we will observ e this inclination also in our w ork. Another asp ect of meta-learning which we highlight throughout the pap er is the underlying principles that go vern the agent’s in ternal adjustment. Here, we distin- guish b et w een tw o differen t (sometimes complementary) alternativ es whic h w e call r eflexive adaptation and adap- tation thr ough le arning . Informally , by reflexive adapta- tion we mean that the agent’s meta-parameters are ad- justed via a fixed recip e (whic h ma y or ma y not be deter- ministic), whic h takes into accoun t only the recen t p erfor- mance of the agent, while ignoring the rest of the agent’s history . Essen tially , this amounts to adaptation with- out a need for additional memory . An example for such a reflexive adaptation approach for meta-learning can b e found in [ 15 ] where the fundamental RL parameters, namely , the learning rate α , the exploitation-exploration parameter β , and the discoun t factor γ are tuned accord- ing to predefined equations; In contrast, an agen t which adapts its parameter through learning, exploits to that end its entire individual exp erience. Accordingly , adapta- tion through learning do es require an additional memory . In this work we consider b oth kinds of approaches 1 . The pap er is structured as follows: Section I I shortly describes the PS mo del including its meta- parameters. Section I II demonstrates the adv an tages of meta-learning, b y considering explicit task scenarios where the PS mo del has different optimal v alues of the meta-parameters. In Section IV we present the prop osed meta-learning design and explain ho w it combines with the basic mo del. The mo del is then examined and ana- lyzed through simulations in Section V , where the p er- formance of the meta-learning PS agent is ev aluated in three different types of changing environmen ts. Through- out this section the prop osed meta-learning scheme is further compared to other, more naive, alternatives of meta-learning sc hemes. Finally , Section VI concludes the pap er and discusses some of its op en questions. I I. THE PS MODEL F or the b enefit of the reader we first give a short sum- mary of the PS; for a more detailed description, including recen t developmen ts see [ 29 – 33 ]. The cen tral comp onent 1 The terminology w e emplo y is based on the basic classification of intelligen t agents; if w e p erceive the meta-learning machinery as an agent, then the reflexive adaptation mec hanism corresp onds to simple reflexive agents, whereas the learning adaptation mech- anism corresp onds to a learning agent. 3 of the PS mo del is the episo dic & comp ositional mem- ory (ECM), formally a netw ork of clips . The p ossible clips include p ercept clips (representing a p ercept) and action clips (represen ting an action), but can also include the representations of v arious com binations of p ercept and action sequences (thus represen ting e.g. an elapsed exc hange b etw een the agen t and environmen t, or sub- sets of the p ercept space as o ccurring in the mo del of PS with generalization [ 33 ]). Within the ECM, a clip c i ma y b e connected to clip c j via a weigh ted directed edge, with a corresp onding time-dep enden t real p ositive w eight h ( t ) ( c i , c j ) (called h -v alue), which is larger than or equal to its initial v alue of h 0 = 1. The delib eration pro cess of the agent corresp onds to a random walk in the ECM, where the transition probabil- ities are prop ortional to the h − v alues. More sp ecifically , up on encountering a p ercept, the clip corresp onding to that p ercept is activ ated, and a random walk is initiated. The transition probability from clip c i to c j at time step t , corresponds to the re-normalized h -v alues: p ( t ) ( c j | c i ) = h ( t ) ( c i , c j ) P k h ( t ) ( c i , c k ) . (1) The random walk is contin ued until an action clip has b een hit, up on which point the corresp onding action is carried out. The learning asp ect of the PS agent is achiev ed by the dynamic mo dification of the h − v alues, dep ending on the resp onse of the en vironment. F ormally , at each time-step, the h -v alues of the edges that were trav ersed during the preceding random walk are up dated as follo ws: h ( t +1) ( c i , c j ) = h ( t ) ( c i , c j ) − γ ( h ( t ) ( c i , c j ) − 1) + λ, (2) where 0 ≤ γ ≤ 1 is a damping parameter and λ is a non- negativ e reward given b y the environmen t. The h -v alues of the edges which were not trav ersed during the preced- ing random walk are not rew arded (no addition of λ ), but are nonetheless damp ed aw a y tow ard their initial v alue h 0 = 1 (by the γ term). With this up date rule in place, the probabilit y to tak e rew arded actions is increased with time, that is, the agent learns. The damping parameter γ is a meta-parameter of the PS mo del. The higher it is, the faster the agent forgets its knowledge. F or certain settings, introducing addi- tional parameters to the ECM netw ork can lead to b et- ter learning p erformance. A particularly useful general- ization is the “edge glow” mechanism, introduced to the mo del in [ 30 ]. Here, an additional time-dep endent v ari- able 0 ≤ g ≤ 1 is attributed to each edge of the ECM, and a term depending on its v alue is added to the update rule of the h − v alues: h ( t +1) ( c i , c j ) = h ( t ) ( c i , c j ) − γ ( h ( t ) ( c i , c j ) − 1) + g ( t ) ( c i , c j ) λ. (3) This up date rule holds for all edges, so that edges whic h w ere not tra versed still may end up b eing enhanced, pro- p ortional to their g − v alue. The g − v alue dynamically c hanges. Each time an edge is trav ersed, its g -v alue is set to g = 1, and dissipates in the following time steps with a rate η : g ( t +1) ( c i , c j ) = g ( t ) ( c i , c j )(1 − η ) . (4) The η parameter is th us another meta-parameter of the mo del. The decay of the g -v alues ensures that the reward ef- fects the edges tra versed at different p oints in time, to a differen t extent. In particular, recently tra versed edges are enhanced more (after a rewarding step), relative to edges trav ersed in the more remote past. The η param- eter controls the strength of this temp oral dep endence. F or instance, a low v alue of η implies that the edges which w ere trav ersed a while back in the past will nonetheless b e enhanced. In con trast, by setting η = 1, only the las t tra versed path is enhanced in which case the up date rule rev erts bac k to Eq. ( 2 ). The glow mechanism thus establishes temp oral cor- relations b etw een p ercept-action pairs, and enables the agen t to p erform well also in settings where the reward is delay ed (e.g. in the grid-world and the moun tain-car tasks [ 31 ]) and/or contingen t on more than just the im- mediate history of agent-en vironment interaction (such as in the n -ship game, as presented in [ 30 ]). The basic v arian t of the PS mo del (so-called t w o- la yered v arian t) can be formally con trasted to more stan- dard RL schemes, where it closely resem bles the SARSA algorithm [ 46 ]. An initial analysis of the relationship of the tw o mo dels was giv en in [ 33 ]. Readers familiar with the SARSA model may benefit from the observ ation that the functional roles of the α and γ parameters in SARSA are closely matc hed by the γ and η parameters of the PS, resp ectively . How ev er, as the PS is explicitly not a state-action v alue function-based mo del, the analogy is not exact. F or more details we refer the interested reader to [ 33 ]. In the following section, we describ e the b eha viour of the PS mo del, and the functional role of its meta-parameters in greater detail. I I I. ADV ANT A GES OF MET A-LEARNING The basic memory update mec hanism of the PS, as captured by Eq. ( 3 )-( 4 ) has t wo meta-parameters, namely the damping parameter γ , and the glow param- eter η . In what follows, we examine the role of these parameters in the learning pro cess of the agent. W e then demonstrate, through examples, that for none of these parameters there is a unique v alue that is univ ersally optimal, i.e. that different environmen ts induce different optimal γ and η v alues. These examples provide direct motiv ation for introducing a meta-learning mechanism for the PS mo del. 4 A. Damping: the γ parameter The damping parameter 0 ≤ γ ≤ 1 controls the for- getfulness of the agent, by con tinuously damping the h - v alues of the clip net work. A direct consequence of this is that a non-zero γ v alue b ounds the h -v alues of the clip net work to a finite v alue, which in turn limits the max- im um achiev able success probability of the agent. As a result, in many typical tasks considered in the RL litera- ture (grid-w orld, moun tain-car, and tic-tac-toe, to name a few), in which the environmen ts are consistent, i.e. not c hanging, the optimal p erformance is achiev ed without an y damping, that is by setting γ = 0. Ho wev er, when the environmen t do es change, the agen t ma y need to mo dify its “action pattern”, which implies v arying the relative weigh ts of the h -v alues. Presetting a finite γ parameter w ould then quick en the agen t’s learn- ing time in the new en vironmen t, at the exp ense of reach- ing low er success probabilities, as demonstrated and dis- cussed in Ref. [ 29 ]. This gives rise to a clear trend: The higher the v alue of γ , the faster is the relearning in a changing environmen t, and the lo wer is the agent’s asymptotic success probability . The trade-off b etw een learning time and success prob- abilit y in c hanging en vironmen ts can b e demonstrated on the inv asion game [ 29 ] example. The inv asion game is a sp ecial case of the contextual m ulti-armed bandit prob- lem [ 47 ] and has no temp oral dep endence. In this game an agen t is a defender and should try to blo ck an attac k er b y moving in the same direction (left or right) with the attac ker. Before making a mov e, the attack er shows a sym b ol (“ ⇐ ” or “ ⇒ ”), whic h encodes its future direction of mov ement. Essen tially , the agen t has to learn where to go for every given direction sym b ol. Fig. 1 illustrates ho w the PS agen t learns b y receiving rew ards for success- fully blo cking the attack er. Here, during a phase of 250 steps, the attack er go es right (left) whenever it shows a righ t (left) symbol, but then, at the second phase of the game, the attac ker inv erts its rules, and go es right (left) whenev er it shows left (right). It is seen that higher v al- ues of γ yield low er success probabilities, but allo w for a faster learning in the second phase of the game. T o illustrate further the slo w-down of the learning time in a c hanging en vironment when setting γ = 0, Fig. 2 sho ws the av erage success probability of the basic PS agen t in the inv asion game as a function of n umber of trials, on a log scale. Here the attac ker inv erts its rules whenev er the agent reaches a certain success probability (here set to 0.8). W e can see that the time that the agen t needs to learn at each phase grows exp onentially in the n umber of the changes of the phases, requiring more and more time for the agent to learn, s o that even tually , for an y finite learning time, there will b e a phase for which the agen t fails to learn. Setting a zero damping parameter in changing envi- ronmen ts ma y ev en b e more harmful for the agent than merely increasing its learning time. T o give an example, consider an inv asion game, where the attack er in verts its 100 200 300 400 500 0.0 0.2 0.4 0.6 0.8 1.0 γ = 1 / 50 (upp er) γ = 1 / 10 (mid dle) γ = 1 / 5 (lo w er) phase I ( ⇐ ⇒ ) phase I I ( ⇒ ⇐ ) trials a v erage success probabilit y Figure 1. (Color online) Invasion game: The attack er inv erts its strategy after 250 steps. The agen t’s a verage success prob- abilit y is plotted as a function of num ber of trials (games). A trade-off b etw een success probability and relearning time is depicted for different γ v alues. An optimal v alue of η = 1 is used. The simulation was done by av eraging ov er 10 6 agen ts. Adapted from [ 29 ]. 1 10 100 1000 10 4 10 5 0.2 0.4 0.6 0.8 1.0 trials (log scale) success probabilit y I I I I I I I I I I I I Figure 2. Invasion game: The attac ker inv erts its strategy whenev er the agent’s success probability reaches 0.8. The agen t’s p erformance is plotted as a function of num ber of tri- als on a log scale, demonstrating learning times that increase exp onen tially with the num ber of in versions. The sim ulation w as done with a single agen t, where the success probabili- ties were extracted directly from the agent’s base-level ECM net work. Meta-parameters: γ = 0, η = 1. rules every fixed finite num b er of steps. Without damp- ing, the agen t will only b e able to learn a single set of rules, while utterly failing on the inv erted set. This is sho wn in Fig. 3 . The p erformance of the PS agent in the considered examples, sho wn in Figs. 1 – 3 , suggests that it is im- p ortan t to raise the γ parameter whenever the environ- men t changes (the p erformance drops down) and set it to zero whenever the p erformance is steady . As w e will sho w in Section IV B this adjustment can be implemen ted b y means of reflexive adaptation. How ever the reflexive adaptation of the γ parameter makes meta-learning less general, b ecause it fixes the rule of the parameter adjust- men t. T o mak e the PS agent more general we will im- 5 0 1000 2000 3000 4000 5000 6000 0.0 0.2 0.4 0.6 0.8 1.0 trials a v erag e success probabilit y I I I I I I I I I I I I I I I I I I Figure 3. Invasion game: The attack er changes its strat- egy every 500 steps. The agent’s av erage success probability is plotted as a function of num b er of trials, demonstrating that only one of the tw o set of the attack er’s strategy can b e learned. Moreo ver, the p erformance of the agent, av eraged o ver the tw o phases, con verges to the p erformance of a ran- dom agent. The simulation was done by a veraging o ver 100 agen ts, where for each agent the success probabilities were extracted directly from its base-level ECM netw ork. Meta- parameters: γ = 0, η = 1. plemen t γ adaptation also through learning, which gives the agen t the possibility to le arn the opp osite rule, i.e. to decrease γ whenever the agent’s p erformance go es down. So far we assumed that the glo w mec hanism is turned off by setting η = 1, whic h is optimal for the in v asion game. The same holds in all environmen ts where the rew ards dep end only on the current p ercept-action pair, with no temp oral correlations to previous p ercepts and actions. In the next section, ho wev er, we lo ok further in to scenarios where such temp oral correlations do exist, and study their influence on the optimal η v alue. B. Glo w: the η parameter In task environmen ts where reward from an environ- men t is a consequence of a series of decisions made by an agen t, it is vital to ensure that not only the last action is rewarded, but the entire sequence of actions. Other- wise, these previous actions, which even tually led to a rew arded decision, will not b e learned. As describ ed in Sec. I I , rewarding a sequence of actions is done in the PS mo del by attributing a time dep endent g -v alue to each edge of the clip netw ork and rewarding the edge with a reward prop ortional to its g -v alue. Once an edge is excited, its g -v alue is set to g = 1, whereas all other g - v alues deca y with a rate η , whic h essentially determines the extent to whic h past actions are rewarded. As we sho w next, the actual v alue of the η parameter plays a crucial role in obtaining high av erage reward, its optimal v alue dep ends on the task, and finding it is not trivial. Here w e study the role of the η parameter in the n -ship game example, introduced in [ 30 ]. In this game n ships arriv e in a sequence, one b y one, and the agen t is capable of blo cking them. If the agent blo cks one or several ships out of the first n − 1 ships, it will get a rew ard of λ min = 1 for each ship immediately after blo cking it. If, how ev er, the agent will refrain from blo cking the ships, although there is an immediate reward for that, it will get a larger rew ard of λ max = 5 × ( n − 1) for blo c king only the last, n -th ship. In this scenario the optimal strategy differs from the greedy strategy of collecting immediate rew ards, b ecause the reward λ max is larger than the sum of all the small rew ards that can b e obtained during the game. The optimal strategy in the describ ed game can b e learned by using the glow mechanism and by carefully c ho osing the η parameter. The optimal η v alue dep ends on the num ber of ships n , as shown in Fig. 4 , where the dep endence of the av erage reward received during the game on the η parameter is plotted for each n ∈ { 2 , 3 , 4 } . It is seen that as the num b er of n ships grows, the best av erage rew ard is obtained using a smaller η v alue, i.e. the optimal η v alue decreases. This mak es sense as a smaller η v alue leads to larger sequences of rew arded actions. 0.2 0.4 0.6 0.8 1.0 0 2 4 6 8 10 12 14 η parameter a v erag e rew ard 2-ship game λ max = 5 3-ship game λ max = 10 4-ship game λ max = 15 γ = 10 − 4 Figure 4. (Color online) n -ship game: The dep endence of the p erformance on the η parameter is shown for different n . The p erformance is ev aluated by an av erage reward gained during the 10 6 -th game. The simulation was done by av eraging ov er 10 3 agen ts. The γ parameter was set to 10 − 4 . Adapted from [ 30 ]. The sim ulations of the n -ship game sho wn in Fig. 4 em- phasize the imp ortance of setting a suitable η v alue. In other, more inv olved scenarios, such a dep endency may b e more elusive, making the task of setting a prop er η v alue ev en harder. An in ternal mechanism that dynami- cally adapts the glo w parameter according to the (possi- bly c hanging) external environmen t w ould therefore fur- ther enhance the autonomy of the PS agen t. In Section IV A w e will show how to implement this in ternal mec h- anism b y means of adaptation through learning. IV. MET A-LEARNING WITHIN PS T o enhance the PS model with a meta-learning compo- nen t, w e supplement the base-level clip-netw ork (ECM) 6 with additional net works, one for each meta-parameter ξ (where ξ could b e, e.g. γ or η ). Each such meta-level net work, whic h w e denote b y ECM ξ ob eys the same prin- ciple structure and dynamic as the base-level ECM net- w ork as describ ed in Section I I : it is comp osed of clips, its activ ation initiates a random-walk through the clips un til an action-clip is hit, and its up date rule is giv en by the update rule of Eq. ( 2 ), alb eit with a differen t internal rew ard: h ( t +1) ξ ( c i , c j ) = h ( t ) ξ ( c i , c j ) − γ ξ ( h ( t ) ξ ( c i , c j ) − 1) + λ ξ . (5) The meta-lev el ECM netw orks w e consider in this w ork are t wo-la y ered, with a single p ercept-clip and several action-clips. The action clips of eac h meta-lev el net- w ork determine the next v alue of the corresp onding meta- parameter. This is illustrated sc hematically in Fig. 5 . ξ a 1 a 2 . . . a n h ξ set ξ to Figure 5. A schematic t w o-lay ered meta-lev el ECM ξ net work, whose actions control the v alue of a general meta-parameter ξ . While the base-lev el ECM net work is activ ated at every in teraction with the environmen t (where each p ercept- action pair of the agent coun ts as a single in teraction), a meta-lev el ECM ξ net work is activ ated only ev ery τ ξ in ter- actions with the environmen t. F ollowing eac h activ ation, an action-clip is encoun tered and the meta-parameter ξ (th us either γ or η ) is up dated accordingly . At the end of each such τ ξ time window the meta-level netw ork re- ceiv es an internal reward λ ξ whic h reflects how well the agen t p erformed during the past τ ξ in teractions, or time steps, compared to the performance during the previous τ ξ time window. This allows a statistical ev aluation of the agen t’s performance in the last τ ξ time windo w. Sp ecifically , w e consider the quantit y Λ ξ ( T ) = T X t = T − τ ξ +1 λ ( t ) , (6) whic h accounts for the sum of rew ards that the agen t has receiv ed from the en vironment in the τ ξ steps b efore the end of the time step T . The in ternal rew ard λ ξ is then set b y comparing tw o successive v alues of such accumulativ e rew ards: λ ξ = sgn (∆ ξ ) (7) where ∆ ξ ( T ) = Λ ξ ( T ) − Λ ξ ( T − τ ξ ) max { Λ ξ ( T ) , Λ ξ ( T − τ ξ ) } is the normalized dif- ference in the agent’s p erformance b etw een t wo succes- siv e time windows, b efore time step T . In short, the meta-lev el ECM ξ net work is rewarded p ositively (neg- ativ ely) whenever the agent p erforms b etter (worse) in the latter time window (implementation insures that the corresp onding h -v alues do not go b elow 1). The normal- ization plays no role at this p oin t, how ever the n umerical v alue of ∆ ξ will matter later on. When there is no c hange in p erformance (∆ ξ ( T ) = 0) the netw ork is not rew arded. The presented design requires the sp ecification of sev- eral quantities for each meta-level ECM ξ net work, includ- ing: the time windo w τ ξ , the num ber of its actions and the meaning of each action. In what follows we sp ecify these choices for b oth the η and the γ meta-level net- w orks. A. The glow meta-lev el netw ork (ECM η ) – adaptation through learning only The glow meta-level netw ork (ECM η ) we use in this w ork is depicted in Fig. 6 . The netw ork is comp osed of a single percept ( S η = 1) and A η = 10 actions whic h corre- sp ond to setting the η parameter to one of 10 v alues from the set { 0 . 1 , 0 . 2 , . . . , 1 } . The internal glow net work is ac- tiv ated ev ery τ η times steps. This time windo w should b e large enough so as to allow the agent to gather reliable statistics of its p erformance. It is therefore sensible to set τ η to b e of the order of the learning time of the agent, that is the time it takes the agen t to reac h a certain frac- tion of its asymptotic success probability (see also [ 30 ]). The learning time of the PS w as sho wn in [ 30 ] to b e lin- ear in the num ber of p ercepts S and actions A in the base-lev el netw ork. W e thus set the time window to b e τ η = N η S AS η A η , which is also linear with the num b er of p ercepts S η and actions A η of the meta-level netw ork. Here N η is a free parameter; the higher its v alue, the b etter the statistics the agent gathers. In this work, we set N η = 30 throughout, for all the examples we study . η 0 . 1 0 . 2 . . . 1 h η set η to Figure 6. The glow meta-level net work (ECM η ): The sp ecific realization emplo yed in this work. The h η -v alues of the η -net w ork are up dated through in ternal rewarding as describ ed, and the PS agen t learns with time what the preferable η v alues in a giv en scenario are. The preferable η v alues are further adjusted to ac- coun t for c hanges in the en vironment. These con tinuous adjustmen ts of the η -netw ork then allow the PS agent to adapt to new environmen ts by learning. 7 B. The damping meta-lev el netw ork (ECM γ ) – com bining reflexive adaptation with adaptation through learning The second meta-learning netw ork, the damping meta- lev el netw ork (ECM γ ), is presented in Fig. 7 . It is com- p osed of only tw o actions whic h corresp ond to up dating the γ parameter by using one of tw o functions according to the following rules: Rule I: γ ← f I ( γ ) = (1 − | ˜ ∆ γ | ) γ + | ˜ ∆ γ | − ˜ ∆ γ 2 (8) and Rule II: γ ← f II ( γ ) = (1 − | ˜ ∆ γ | ) γ + | ˜ ∆ γ | + ˜ ∆ γ 2 (9) where ˜ ∆ γ = ∆ γ + C γ 1+ C γ and ∆ γ is defined after Eq. ( 7 ). Rule I in vok es a reflexive increase of the γ parameter when the agen t’s p erformance deteriorates, and a reflexive de- crease when the p erformance improv es. This rule (“nat- ural rule”) is natural for typical RL scenarios: a drop of p erformance is assumed to signify a change in the envi- ronmen t, at which p oin t the agent should do w ell to for- get what it learned thus far, and fo cus on exploring new options - in the PS b oth are achiev ed b y the increase of γ . In contrast, if the environmen t is in a stable phase, as the agent learns, the p erformance impro ves, causing γ to decrease, which will lead to optimal p erformance. Rule I I (“opp osite rule”) is chosen to do exactly the opp osite, namely p erformance increase causes the agent to forget. Our main purp ose for the introduction of this rule is to demonstrate the flexibility of the meta-learning agent to learn even the correct strategy of up dating γ . Although in all the environmen ts whic h are typically considered in literature, and in this work, the natural rule is the b et- ter choice, and th us could in principle b e hard-wired, our agen t is challenged to learn even this 2 . The role of C γ parameter, which we set to C γ = 0 . 2 throughout this w ork, is to av oid un wan ted increase of γ under statistical fluctuations. Note that the functions in Eqs. ( 8 ) and ( 9 ) ensure that γ ∈ [0 , 1]. 2 It is possible to concoct settings where the opp osite rule may b e beneficial using minor and ma jor rew ards. The en vironmen t ma y use minor rewards to train the agent to a deterministic b ehavior ov er certain time p erio ds, after which a ma jor rew ard (domi- nating the total of all small rewards) is issued only if the agent nonetheless pro duced random outcomes all along. If the perio ds are appropriately tailored, this can train the meta-learning net- work to prefer the opp osite rule. The study of such pathological settings are not of our principal interest in this work. γ f I ( γ ) f II ( γ ) h γ set γ to Figure 7. The damping meta-level netw ork (ECM γ ): The sp ecific realization emplo yed in this work. The describ ed γ -netw ork is activ ated every τ γ = N γ τ η steps, where τ η is the time window of the glow netw ork as defined ab ov e, and where N γ is a free parameter of the γ -net w ork, which we set it to N γ = 5 throughout the pa- p er. The agent first learns an estimate of the range of an optimal η , and c hanges γ afterw ards. This is assured b y c ho osing the time window for the γ -net w ork larger than for the η -net w ork. This relationship b etw een the time windo ws τ γ and τ η is required in order for the PS agent to gain a meaningful statistics during τ γ steps. Other- wise, if η is not learned first, the agen t’s p erformance will significantly fluctuate, leading to erratic changes of γ through the reflexive adaptation rule. Note that large fluctuations in γ yield very p o or learning results as even mo derate v alues of γ lead to a rapid forgetting of the agen t. The meta-learning by the ECM γ net work is realized as follows. Starting from an initially random v alue, the γ parameter is adapted b oth via direct learning in the γ -net w ork and via reflexiv e adaptation through rule I or rule I I. Giv en that the o verall structure of the en viron- men t was learned ( i.e. whether the natural rule I or opp o- site rule I I is preferable), γ is henceforth adapted reflex- iv ely . These reflexive rules reflect an a-priory knowledge ab out what strategy is preferable in giv en environmen ts. W e note that the γ parameters could b e learned without suc h reflexive rules, by using net works which directly se- lect the γ v alues (lik e in the case of the η netw ork), how- ev er such approac hes hav e shown to be m uch less efficien t. In general, reflexive adaptation of the meta-parameters is preferable to adaptation through learning as it is sim- pler. The need for learning adaptation arises when the landscap e of optimal v alues of the meta-parameters is not straigh tforward, as is the case for the η parameter, as illustrated in Fig. 4 . V. SIMULA TIONS T o examine the prop osed meta-learning mec hanism w e next ev aluate the p erformance of the meta-learning PS agen t in several en vironmen ts, namely the in v asion game, the n -ship game and v arian ts of the grid-world setting. These en vironments were chosen b ecause of their differ- en t structures, whic h exhibit different optimal damping and glow parameters. The goal is that the PS agent 8 will adjust its meta-parameters prop erly , so as to cop e w ell with these different tasks. T o challenge the agent ev en further, eac h of the three environmen ts will sud- denly change, thereby forcing the agen t to readjust its parameters accordingly . Critically , for all tasks the same meta-lev el netw orks are used, along with the same choice of free parameters ( N η = 30, N γ = 5, and C γ = 0 . 2), as describ ed in Sections IV A - IV B . T o demonstrate the role of the meta-learning mecha- nism, we compare the p erformance of the meta-learning PS agent to the p erformance of the PS agen t without this mechanism. Without the meta-learning the PS agen t starts the task with random γ and η parameters and do es not change them afterwards. T o sho w the imp ortance of learning the optimal η parameter (which may not b e as ob vious as for the case of γ ) we construct a second refer- ence PS agen t for comparison, whic h uses the γ -netw ork to adjust the γ parameter, but tak es a random c hoice out of the p ossible η -actions in the η -netw ork. A. The inv asion game W e start with the simplest task: the in v asion game (see Section I I I A ). As b efore, the agen t is rewarded with λ = 1 whenever it manages to blo ck the attack er and it has to learn whether the attack er will go left or right, after presen ting one of tw o symbols. W e consider, once again, the scenario in which the attack er switc hes b etw een t wo strategies ev ery fixed num ber of trials. In one phase of the game it go es left (right) after showing a left (right) sym b ol, whereas in the other phase it do es the opp osite. This is rep eated several times. The task of the agent is to blo ck the attack er regardless of its strategy . W e recall that in such a scenario (see Fig. 3 ) the basic PS agent with fixed meta-parameters ( γ = 0 , η = 1) can only cop e with the first phase, but fails completely at the second. Fig. 8 (a) shows in solid blue the p erformance of the meta-learning PS agen t, in terms of av erage success prob- abilities, in this c hanging in v asion game. Here eac h phase lasts 1 . 2 × 10 5 steps, and the attac k er c hanges its strategy 20 times. It is seen that with time the av erage success probabilit y of the PS agents increases tow ards optimal v alues and that the agents manage to blo ck the attack er equally well for b oth of its strategies. This p erformance is achiev ed due to meta-learning of the γ and η param- eters, the dynamics of which are sho wn in solid blue in Fig. 8 (b) and (c), resp ectively . It is seen in Fig. 8 (b) that after some time and several phase c hanges, the v alue of the γ parameter raises sharply whenever the attac ker c hanges its strategy , and decays tow ard zero during the follo wing phase. This allows the agen t to rapidly forget its kno wledge of the previous strategy and then to learn the new one. Fig. 8 (c) shows the η parameter dynamics. As explained in Section I I I B the optimal glow v alue for the inv asion-game is η = 1, as the en vironment induces no temp oral correlations b etw een previous actions and rew ards. The meta-learning agent b egins with an 0 0.5 1 1.5 2 0.0 0.2 0.4 0.6 0.8 1.0 0 0.5 1 1.5 2 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0 0.5 1 1.5 2 0.4 0.5 0.6 0.7 0.8 0.9 1.0 PS with meta-lear ning PS with random η action PS with fixed random γ and η (a) (b) (c) trials trials trials × 10 6 × 10 6 × 10 6 a v erag e success probabilit y a v era ge γ a v era ge η Figure 8. (Color online) Invasion game: The attack er inv erts its strategy ev ery 1 . 2 × 10 5 steps. Three t ypes of PS agen ts are depicted: with full meta-learning capability (in solid blue), with adjusted γ v alue but with η v alue that is chosen ran- domly from the ECM η net work (in dashed red), and agents whose γ and η v alues are fixed to random v alues, each agent with its own v alues (in dotted gray). T op: The p erformances of the different agents are shown as a function of trials; Mid- dle: The av erage γ v alue is shown as a function of trials; Bottom: The av erage η v alue is sho wn as a function of tri- als. The simulations were done by av eraging ov er 100 agents, where for each agent the success probabilities were extracted directly from its base-level ECM netw ork. η -netw ork that has a uniform action probabilit y . Y et, 9 with time, its meta-level ECM η net work learns and the a verage η parameter approac hes the optimal v alue of η = 1. T o show the adv an tage of the meta-learning netw orks w e next consider the performance of agen ts without this mec hanism. First, we lo ok at the p erformance of a PS agen t with fixed random γ and η parameters as shown in Fig. 8 (a) in dotted gra y . It is seen that on av erage, suc h an agent p erforms rather p o or, with an a verage success rate of 0 . 6. This can b e exp ected, as most of the γ and η v alues are in fact harmful for the agent’s success. The a verage v alue of each parameter go es to 0 . 5 as depicted in Fig. 8 (b) for the γ parameter and in Fig. 8 (c) for the η parameter in dotted gray (the sligh t deviation from 0 . 5 is due to finite sample size). A more challenging comparison is shown in Fig. 8 (a) in dashed red, where the agen t adjusts its γ parameter exactly lik e the meta-learning one, but uses an η -netw ork (the same one as the meta-learning agen t) that do es not learn or up date. It is seen that such an in termediate agen t can already learn b oth phases to some exten t, but do es not reach optimal v alues. This is b ecause small η v alues – corresp onding to sustained glo w o ver several learning cycles – are harmful in this case. The dynamics of the parameters of this PS agent are shown in Fig. 8 (b) and (c) in dashed red, where γ b ehavior is similar to the one of the meta-learning agent, and the av erage η fluctuates around η = 0 . 55, which is the av erage v alue of the 10 p ossible actions in the η -net w ork. In this example we encounter for the first time the trade-off betw een flexibilit y and learning time. The meta-learning agent exhibits high flexibility and robust- ness, as it manages to rep eatedly adapt to c hanges in the environmen t. How ev er, this comes with a price: the learning time of the agent slows down and the agent re- quires millions of trials to master this task. This is, how- ev er, to be expected. Not only that the agen t has to learn ho w to act in a changing environmen t, but it must also learn ho w to prop erly adapt its meta-parameters, and the latter o ccurs at the time-scales of τ γ = 6000 elementary cycles. The agent b egins with no bias whatsoever regard- ing its a action pattern or its γ and η parameters. F ur- thermore, the agent b egins with no a-priory knowledge regarding the inheren t nature of the rew arding pro cess of the environmen t: is it a typical environmen t (where the agen t should prefer the natural rule), or is it an un typical en vironment which ultimately rew ards random b ehavior (where the opp osite rule will do better)? This to o needs to b e learned. Fig. 9 shows the av erage probability of c ho osing rule I (Eq. ( 8 )) in the γ − net work as a function of trials. It is seen that with time the γ − netw ork c hooses to up date the γ parameter according to rule I with increas- ing probability , reflecting the fact that in this setup the en vironment acts indeed acc ording to the natural rule. 0 0.5 1 1.5 2 0.4 0.5 0.6 0.7 0.8 0.9 1.0 trials, × 10 6 γ -net w o rk: probabilit y to c ho ose rule I PS with meta-lea rning Figure 9. Invasion game: The attac ker inv erts its strategy ev ery 1 . 2 × 10 5 steps as in Fig. 8 . The p erformance of the γ -netw ork of the meta-learning PS is shown as a function of trials, in terms of the probability to c ho ose rule I (see Eq. 8 ). The sim ulation was done by av eraging ov er 100 agents. B. The n -ship game In the n -ship game (see Section I I I B ) the environmen t rew ards the agent depending on its previous actions. In what follows we consider a dynamic n -ship gam e, that is w e allow n to change with time. In particular, the envi- ronmen t starts with n = 1 (where no temp oral correla- tions exist) and increases the num ber of ships n by one, ev ery 3 . 5 × 10 5 × n steps. As explained in Section I I I B eac h n -v alue requires a differen t glo w parameter η . This scenario therefore poses the c hallenge of con tin uously ad- justing the glow parameter. Fig. 10 (a) shows in solid blue the p erformance of the meta-learning PS agent in this changing n -ship game. The b est p ossible reward is indicated by a dashed blue horizon tal line, and it is seen that such agen ts learn to p erform optimally , for all n umber of ships n . This success is made p ossible by the meta-learning mec hanism. First, the γ parameter is adjusted, such that the agent forgets whenever its p erformance decrease and vice v ersa (see Eq. ( 8 )). Here w e assume that the γ -netw ork already learned in previous stages that the environmen t follo ws the natural rule (we used an h-v alue ratio of 10 5 to 1 for rule I). This γ -net work leads to a dynamics of the a verage γ parameter shown in Fig. 10 (b) in solid blue. It is seen that whenever the environmen t changes, the γ parameter increases, thereby allo wing the agent to forget its previous knowledge. A slow decrease of the damping parameter makes it then p ossible for the agent to learn ho w to act in the new setup. Second, the glow parameter η is adjusted dynamically . Fig. 10 (c) sho ws the probability distribution of choosing eac h action of the η -netw ork at the end of each phase. It is seen that as n grows, the η -netw ork learns to choose a smaller and smaller glow parameter v alue, which allows the back propagation of the reward from the final ship to the first n − 1 ships. A similar trend w as observed in Fig. 4 where larger n v alues result with smaller 10 0 0.5 1 1.5 2 2.5 3 3.5 0 2 4 6 8 10 12 14 0 0.5 1 1.5 2 2.5 3 3.5 0.0 0.1 0.2 0.3 0.4 0.2 0.4 0.6 0.8 1.0 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 PS with meta-lear ning PS with random η action optimal strategy greedy strategy random strategy ( a ) ( b ) ( c ) ship 2 ships 3 ships 4 ships trials trials η actions × 10 6 × 10 6 a v erag e rew ard a v era ge γ a v erag e η probabilit y 1-ship game 2-ship game 3-ship game 4-ship game Figure 10. (Color online) n-ship game: The num b er of ships n increases from one to four. Each phase lasts for 3 . 5 × 10 5 × n trials. Two types of PS agents are depicted: with full meta- learning capability (in solid blue), and with adjusted γ v alue but with η v alue that is chosen randomly from the ECM η net work (in dashed red). T op: The p erformance of the tw o differen t agents is shown as a function of trials in terms of a verage reward. F or each phase the av erage reward of the optimal strategy , a greedy strategy and a fully random one is plotted in dashed light-blue, dotted-dashed purple, and dot- ted orange, resp ectively; Middle: The av erage γ v alues of the tw o different kinds of agents are sho wn as a function of trials; Bottom: F or the meta-learning PS agent the proba- bilit y to choose each of the 10 η -actions is plotted at the end of each phase in a different plot. Connecting lines are sho wn to guide the ey es. The sim ulations w ere done by av eraging o ver 100 agents, where for each agent the av erage reward was extracted directly from its base-level ECM netw ork. optimal η v alues. As shown in Fig. 10 (c) the meta- learning PS agent essentially captures the same knowl- edge in its η -netw ork. Y et, this time the knowledge is obtained through the agen t’s exp erience, rather than by an external party . The PS agen t without the meta-learning is not able to achiev e similar p erformance. Performance of an agent with fixed random γ and η is p o or and not shown, b e- cause its b ehavior w as close to a random strategy (dotted orange horizontal lines in Fig. 10 (a)). This p erformance is exp ected, b ecause most of the v alues are harmful for the agent’s success. W e only show the more c halleng- ing comparison (dashed red in Fig. 10 ), where the agent adjusts its γ parameter exactly like the meta-learning one, but uses an η -netw ork (the same one as the meta- learning agen t) whic h does not learn or up date. It is seen that for n = 1 such an intermediate agent can cop e with the environmen t, but that for higher v alues of n it fails to reach the optimal p erformance b ecause of a random η parameter, and ac hiev es only a mixture of a greedy strat- egy (dot-dashed purple horizontal lines) and an optimal strategy (dashed light blue horizontal lines). C. The grid-world task As a last example, w e consider a b enchmark problem in the form of the grid-w orld setup as presen ted in Ref. [ 48 ]. This is a delay ed-rew ard s cenario, where the agent walks through a maze and gets rew arded with λ = 1 only when it reaches its goal. At each p osition, the agent can mov e in one of four directions: left, right, up, or do wn. Each mo ve counts as a single step. Reaching the goal marks the end of the curren t trial and the agent is then reset to its initial place, to start another round. The basic PS agen t was sho wn to perform w ell in this b enc hmark task [ 31 ]. Here, to c hallenge the new meta-learning scheme we situate the agent in three different kinds of grid-worlds: (a) The basic grid-w orld of Ref. [ 48 ], illustrated in the left part of Fig. 11 ; (b) The same sized grid-world with some of the w alls p ositioned differen tly , as sho wn in the middle part of Fig. 11 ; and (c) The original grid-w orld, but with an additional small distracting reward λ min = 1 3 , placed only 12 steps from the agent, shown in the right part of Fig. 11 . The game then ends either when the big rew ard λ max = 1 or the small reward λ min are reached. In all cases the shortest path to the (large) rew ard is comp osed of 14 steps. Since it is the same agent that go es through each of the phases, it has to forget its previous knowledge when- ev er a new phase is encoun tered, and to adjust its meta- parameters to fit the new scenario. The third phase p oses an additional c hallenge for the agent: for optimal p erfor- mance, it must a v oid taking the small rew ard and aim at the larger one. Fig. 12 (a) shows in solid blue the p erformance of the meta-learning PS agen t throughout the three different phases of the grid-world. The p erformance is shown in 11 1 2 3 4 5 6 1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 1 2 3 4 5 6 7 8 9 (a) (b) (c) Figure 11. (Color online) Three setups of the grid-world task. Left: The basic grid-world as presented in Ref. [ 48 ]; Middle: Some of the walls are p ositioned differently; Right: The basic grid-world with a distracting small reward λ min placed 12 steps from the agent . In all three setups a large reward of λ max a waits the agent in 14 steps. terms of steps p er rew ard as a function of trials. In all cases the optimal performance is 14 steps per one reward. In the last phase, a greedy agen t would reach the small rew ard of λ min = 1 3 in 12 steps, thus resulting with 36 steps p er unit of rew ard. It is seen that the meta-learning agen t p erforms optimally in all phases, except of the last phase, where the p erformance is only sub optimal with an av erage of ab out 16 steps p er unit rew ard (instead of 14). This flexibility through all phases is achiev ed due to the adjustments of the γ parameter, whose progress ov er time is shown in Fig. 12 (b) in solid blue. Similar to the n -ship game, w e assume that the γ -net w ork has already learned that the en vironment uses the “straigh tforward” logic, by setting the h -v alue ratio of 10 5 to 1 for choosing rule I. The PS agent with the same γ -net work, but with- out up dated η -netw ork, p erforms similarly in the first t wo phases (Fig. 12 (a) in dashed red) in terms of find- ing ev entually an optimal path. This is to b e exp ected b ecause for finding an optimal path it is only necessary that 0 < η < 1. It is seen, how ev er, that this agent learns m uch slow er than the full meta-learning agen t, so that hundreds of thousands more steps are required on a verage to find an optimal path. This is also reflected in the b ehavior of the γ parameter: with a random η v alue, the γ parameter go es to zero muc h slow er, as sho wn in Fig. 12 (b). The imp ortance of the η parameter is ho wev er b etter demonstrated in the third phase, where the difference b et ween the achiev ed p erformance of the agent with and without η -learning is very significant. In particular, the PS agent with a random η conv erges to the greedy strat- egy and gets a unit of reward every 36 steps (Fig. 12 (a) in dashed red). The reason is that optimal p erformance (a unit of a reward every 14 steps) can only b e achiev ed b y setting the η parameter to a v alue from a certain, limited, range, which we analyze next. The range of optimal η v alues can b e obtained by fo- cusing on the (4, 9) location in the grid-world (see Fig. 11 (c)). In this lo cation, the agent has tw o possible actions that lead faster to the large and small rewards, namely up and down, resp ectively . Because these tw o actions re- sult with a faster reward, edges corresp onding to these actions are enhanced stronger than for the other actions. This enhancemen t is gained by adding the increments g ( t ) ( c i , c j ) λ to the h -v alues at the end of each game, as one can see from the up date rule in Eq. ( 3 ). If the PS agen t follows the greedy strategy , then this increment is equal to λ min = 1 / 3 and is added to the edge correspond- ing to the action “down”. F or the optimal strategy the incremen t is λ max (1 − η ) 2 = (1 − η ) 2 (since λ max = 1), b ecause the large reward o ccurs tw o decisions aw a y from the current p osition and the g -v alue is damp ed from the v alue of 1 to the v alue of (1 − η ) 2 . The optimal strategy will prev ail only if the increment in each game is larger than for the greedy strategy . This is the only case when 0 < η < 1 − p 1 / 3 < 0 . 43. Most of the actions in the η -netw ork of the PS agent hav e v alues larger than 0 . 43, therefore the agent with random η actions conv erges to the greedy strategy and do es not get the b est possible re- w ard. The PS agent with meta-learning is able to learn to use the η parameter from the optimal range, and as sho wn in Fig. 12 (c) the agent indeed mostly uses the v alues of η = 0 . 1 and 0 . 2. VI. SUMMAR Y AND DISCUSSION W e hav e dev elop ed a meta-learning machinery that al- lo ws the PS agent to dynamically adjust its own meta- parameters. This was shown to b e desirable b y demon- strating that, like in other AI schemes, no unique choice of the mo del’s learning parameters can accoun t for all p ossible tasks, as optimal v alues for the meta-parameters v ary from one task environmen t to another. W e em- phasize that the presented meta-learning comp onent is based on the same design as the basic PS, using random w alk on clip-netw orks as the cen tral information pro cess- ing step. It is therefore naturally integrated in to the PS learning framework, preserving the mo del’s sto chastic na- ture, along with its simplicity . The basic PS has tw o principal meta-parameters: the damping parameter γ and the glo w parameter η . F or each meta-parameter we hav e assigned a meta-learning clip- net work, whose actions control the parameter’s v alue. Eac h meta-level netw ork is activ ated every fixed num ber of in teractions with the environmen t. This time 12 0 1 2 3 4 5 6 7 15 35 55 0 1 2 3 4 5 6 7 0.00 0.02 0.04 0.06 0.08 0.10 ( η = 0.1 ) or ( η = 0.2 ) other 8 values 0 1 2 3 4 5 6 7 0.2 0.4 0.6 0.8 PS with meta-le arning PS with random η action (a) (b) (c) trials trials trials × 10 6 × 10 6 × 10 6 a v erage n um b er of steps p er un it of rew ard a v erage γ a v era ge η probabilit y Figure 12. (Color online) Grid-world task: Two types of PS agen ts are depicted: with full meta-learning capability (in solid blue), and with adjusted γ v alue but with η v alue that is chosen randomly from the ECM η net work (in dashed red). T op: The p erformances of the tw o different agen ts are shown as a function of trials in terms of a verage num ber of steps p er unit rew ard; Middle: The av erage γ v alues of the tw o differen t kinds of agents are shown as a function of trials; Bottom: F or the meta-learning PS agent the probabilit y to c ho ose η = 0 . 1 or η = 0 . 2 and the probability to choose either of the other 8 η -actions are plotted as a function of trials; The first tw o phases of the game last 10 6 trials, whereas the last phase lasts 5 × 10 6 trials. These phases corresp ond to three different kinds of grid-worlds shown in Fig. 11 . The sim ulations were done by av eraging ov er 10 4 agen ts. windo w allows the agent to gather statistics ab out its p erformance, so as to monitor its recent success rates and thereby to ev aluate the setting of the corresp onding parameters. When the agent’s success increases, the pre- vious action of the meta-level netw ork is rewarded p os- itiv ely , otherwise, when the p erformance deteriorates, a negativ e reward is assigned (no reward is assigned when there is no change in the agent’s success). As a result, the probability that the random w alk on the meta-level net work hits more fav orable action clips increases with time and the meta-level netw ork essentially learns how to prop erly adjust the corresp onding parameter in the curren t en vironment. The meta-learning pro cess o ccurs on a m uch larger time-scale compared to the base-level netw ork learning time scale. This is necessary as meta-level learning re- quires statistical kno wledge of the agent’s p erformance, whic h is directly controlled by the base-level netw ork, whose learning time is linear with the state space of the task, represented by the num ber of percepts and actions in the base-level netw ork. In meta-lev el learning w e hav e distinguished b etw een adaptation through learning, whic h exploits the en tire individual history of the agent to up date the v alue of the meta-parameter, and reflexiv e adaptation, whic h up dates the meta-parameter using only recent, lo calized informa- tion of the agen t’s p erformance. W e sa w that the glo w pa- rameter can be well adjusted with a full learning net work that is only via adaptation through learning, whereas for the damping parameter, it is more sensible to com bine the t w o kinds of adaptations. The presented meta-learning scheme w as examined in three different environmen tal scenarios, eac h of whic h requires a differen t set of meta-parameters for optimal p erformance. Sp ecifically , we hav e considered the “in- v asion game”, where there are no temp oral correlations b et ween actions and rewards (implying that the optimal glo w v alue is η opt = 1), the “ n -ship game” where tem- p oral correlations do exist and η opt dep ends on n , and finally the “grid-world”, a real-world scenario with de- la yed rewards, for whic h it is sufficient that η opt 6 = 1 in the basic setup, but requires that η opt << 1 in the more adv anced setup, where the agen t can b e distracted b y a small rew ard. In all scenarios, the en vironment furthermore suddenly c hanges, thus requiring the agent to also adjust its for- getting parameter γ . Ov erall, situating an agent in such c hanging en vironments enforces it to rep eatedly and dy- namically revise its in ternal settings. The meta-learning PS agent was shown to cop e well in all scenarios, reac h- ing success probabilities that approach near-optimal or optimal v alues. F or comparison, we c heck ed ho w a PS agent with fixed set of random meta-parameters w ould handle these sce- narios, and observed that suc h an agent would p erform significan tly w orse. This is not surprising, as most of the p ossible meta-parameter v alues (esp ecially those of the γ parameter) are harmful for the agent. Therefore, for 13 a more challenging comparison, we c heck ed the p erfor- mance of an agent that adapts its forgetting parameter γ in exactly the same wa y as the meta-learning agen t, but c ho oses its glow parameter η randomly , out of the same set of actions a v ailable in the η -net work we used. Such an in termediate agent p erformed b etter than the basic PS agen t with random c hoice of meta-parameters, but sub- stan tially worse than the full meta-learning agent. This demonstrates the imp ortance of adjusting b oth γ and η in a prop er wa y . In particular, it shows that the learning of the η -net w ork plays a crucial role. Imp ortan tly , throughout the pap er, we used the same set of choices for the meta-learning scheme. In partic- ular, we used the same meta-level net works ECM γ (in- cluding the reflexiv e rules of the γ -parameter adaptation) and ECM η , and the same time windo ws τ γ and τ η . This indicates that the suggested meta-learning scheme is ro- bust, as it requires no further adjustment of additional parameters b y an external part y , for all the cases w e ha v e considered. [1] Russell, S. J. & Norvig, P . Artificial Intel ligence - A Mo d- ern Appr o ach , chap. 4 (Pearson Education, New Jersey , 2003). [2] Brazdil, P ., Giraud-Carrier, C., Soares, C. & Vilalta, R. Metale arning: Applic ations to Data Mining (Springer, 2009). [3] W olp ert, D. & Macready , W. No free lunch theorems for optimization. IEEE T r ansactions on Evolutionary Com- putation 1 , 67–82 (1997). [4] Wilson, S. W. Classifier fitness based on accuracy . Evo- lutionary computation 3 , 149–175 (1995). [5] Schaul, T. & Schmidh uber, J. Metalearning. Scholarp e dia 5 , 4650 (2010). [6] Giraudo-Carrier, C., Vilalta, R. & Brazdil, P . Intro- duction to the sp ecial issue on meta-learning. Machine L e arning 54 , 187–193 (2004). [7] Thrun, S. & Pratt, L. (eds.) L e arning to le arn (Springer Science & Business Media, 1998). [8] Duch, W. & Grudziski, K. Meta-learning via searc h com- bined with parameter optimization. In Kop otek, M., Wierzc ho, S. & Michalewicz, M. (eds.) Intel l igent Infor- mation Systems 2002 , vol. 17 of A dvanc es in Soft Com- puting , 13–22 (Ph ysica-V erlag HD, 2002). [9] Brazdil, P ., Soares, C. & da Costa, J. Ranking learning algorithms: Using IBL and meta-learning on accuracy and time results. Machine L e arning 50 , 251–277 (2003). [10] Zhao, P . & Y u, B. On mo del selection consistency of lasso. Journal of Machine L e arning R ese ar ch 7 , 2541– 2563 (2006). [11] Adankon, M. M. & Cheriet, M. Mo del selection for the LS-SVM. Application to handwriting recognition. Pat- tern Re c o gnition 42 , 3264–3270 (2009). [12] Ab dulrahman, S. M., Brazdil, P ., v an Rijn, J. N. & V an- sc horen, J. Algorithm selection via meta-learning and sample-based active testing. In Pr o c e e dings of the Meta- le arning and algorithm selection workshop at ECMLP- KDD 2015 , 55–66 (2015). [13] T o dorovski, L. & Deroski, S. Combining classifiers with meta decision trees. Machine Le arning 50 , 223–249 (2003). [14] Ishii, S., Y oshida, W. & Y oshimoto, J. Control of ex- ploitationexploration meta-parameter in reinforcemen t learning. Neur al Networks 15 , 665 – 687 (2002). [15] Sch w eighofer, N. & Doy a, D. Meta-learning in reinforce- men t learning. Neur al Networks 16 , 5–9 (2003). [16] Eriksson, A., Capi, G. & Doy a, K. Evolution of meta- parameters in reinforcement learning algorithm. In Pr o- c e e dings of the IEEE/RSJ International Conferenc e on Intel ligent R ob ots and Systems 2003 . [17] Kobay ashi, K., Mizoue, H., Kuremoto, T. & Obay ashi, M. A meta-learning metho d based on temp oral differ- ence error. In Leung, C., Lee, M. & Chan, J. (eds.) Neu- r al Information Pr o cessing , vol. 5863 of Le ctur e Notes in Computer Scienc e , 530–537 (Springer Berlin Heidelb erg, 2009). [18] T okic, M., Sch w enker, F. & Palm, G. Meta-learning of exploration and exploitation parameters with replacing eligibilit y traces. In Zhou, Z.-H. & Sc hw enk er, F. (eds.) Partial ly Sup ervise d L e arning , vol. 8183 of Le ctur e Notes in Computer Scienc e , 68–79 (Springer Berlin Heidelb erg, 2013). [19] Bengio, Y. Gradient-based optimization of hyperparam- eters. Neur al c omputation 12 , 1889–1900 (2000). [20] Bardenet, R. & K´ egl, B. Surrogating the surrogate: accelerating gaussian-pro cess-based global optimization with a mixture cross-entrop y algorithm. In Pr o c e e dings of the 27th International Confer enc e on Machine L e arn- ing , 55–62 (2010). [21] Bergstra, J. & Bengio, Y. Random search for hyper- parameter optimization. Journal of Machine L e arning R ese ar ch 13 , 281–305 (2012). [22] Reif, M., Shafait, F. & Dengel, A. Meta-learning for evo- lutionary parameter optimization of classifiers. Machine le arning 87 , 357–380 (2012). [23] Thornton, C., Hutter, F., Ho os, H. H. & Leyton-Brown, K. Auto-wek a: Combined selection and hyperparameter optimization of classification algorithms. In Pr o c e e dings of the 19th ACM SIGKDD International Confer enc e on Know le dge Disc overy and Data Mining , 847–855 (ACM, 2013). [24] Smith, M., Mitchell, L., Giraud-Carrier, C. & Martinez, T. Recommending learning algorithms and their asso- ciated h yp erparameters. In Pr o c e e dings of the Meta- le arning and algorithm sele ction workshop at ECAI 2014 , 39–40 (2014). [25] F eurer, M., Springenberg, T. & Hutter, F. Initial- izing Bay esian h yp erparameter optimization via meta- learning. In Pr o c ee dings of the 29th AAAI Confer enc e on Artificial Intel ligenc e , 1128–1135 (2015). [26] Sutton, R. S. & Barto, A. G. R einfor c ement le arning: An intr o duction (MIT Press, Cam bridge Massac husetts, 1998). [27] Ach ban y , Y., F ouss, F., Y en, L., Pirotte, A. & Saerens, M. T uning con tinual exploration in reinforcement learn- ing: An optimality prop erty of the b oltzmann strategy . Neur o c omputing 71 , 2507 – 2520 (2008). Artificial Neu- 14 ral Netw orks (ICANN 2006) / Engineering of Intelligen t Systems (ICEIS 2006). [28] Schmidh uber, J. Completely self-referential optimal re- inforcemen t learners. In Artificial Neur al Networks: F or- mal Mo dels and Their Applic ations , vol. 3697 of L e ctur e Notes in Computer Scienc e , 223–233 (Springer Berlin Heidelb erg, 2005). [29] Briegel, H. J. & De las Cuev as, G. Pro jectiv e simulation for artificial intelligence. Scientific R ep orts 2 , 400 (2012). [30] Mautner, J., Makmal, A., Manzano, D., Tiersch, M. & Briegel, H. J. Pro jectiv e simulation for classical learning agen ts: a comprehensive in vestigation. New Gener ation Computing 33 , 69–114 (2015). [31] Melniko v, A. A., Makmal, A. & Briegel, H. J. Pro jective sim ulation applied to the grid-world and the moun tain- car problem. Artificial Intel ligenc e Rese ar ch 3 (3), 24–34 (2014). [32] Bjerland, Ø. F. Pr oje ctive Simulation c omp ar e d to r ein- for c ement le arning . Master’s thesis, Universit y of Bergen, Norw ay (2015). [33] Melniko v, A. A., Makmal, A., Dunjko, V. & Briegel, H. J. Pro jectiv e sim ulation with generalization. Pr eprint, arXiv:1504.02247 [cs.AI] (2015). [34] Pfeiffer, R. & Scheier, C. Understanding intel ligenc e (MIT Press, Cam bridge Massach usetts, 1999). [35] Motw ani, R. & Raghav an, P . R andomize d Algorithms , c hap. 6 (Cam bridge Universit y Press, New Y ork, NY, USA, 1995). [36] F eynman, R. P . & Hibbs, A. R. Quantum mechanics and p ath inte gr als . International series in pure and applied ph ysics (McGraw-Hill, New Y ork, 1965). [37] Aharonov, Y., Davido vich, L. & Zagury , N. Quantum random walks. Physic al R eview A 48 , 1687–1690 (1993). [38] Aharonov, D., Ambainis, A., Kemp e, J. & V azirani, U. Quan tum walks on graphs. In Pr o c e edings of the 33r d An- nual ACM Symp osium on The ory of Computing , STOC ’01, 50–59 (A CM, New Y ork, 2001). [39] Childs, A. M. et al. Exp onential algorithmic sp eedup by a quan tum w alk. In Pr o c e e dings of the 35th Annual ACM Symp osium on The ory of Computing , STOC ’03, 59–68 (A CM, New Y ork, 2003). [40] Kemp e, J. Discrete quantum walks hit exponentially faster. Pr ob ability The ory and R elate d Fields 133 , 215– 235 (2005). [41] Krovi, H., Magniez, F., Ozols, M. & Roland, J. Quantum w alks can find a marked elemen t on any graph. Algorith- mic a 1–57 (2015). [42] Paparo, G. D., Dunjk o, V., Makmal, A., Martin-Delgado, M. A. & Briegel, H. J. Quantum sp eed-up for active learning agen ts. Physic al R eview X 4 , 031002 (2014). [43] Dunjko, V., F riis, N. & Briegel, H. J. Quantum-enhanced delib eration of learning agents using trapp ed ions. New Journal of Physics 17 , 023006 (2015). [44] F riis, N., Melniko v, A. A., Kirchmair, G. & Briegel, H. J. Coheren t con trolization using sup erconducting qubits. Scientific Rep orts 5 , 18036 (2015). [45] Anderson, M. L. & Oats, T. A review of recent research in metareasoning and metalearning. AI Magazine 28 , 7–16 (2007). [46] Rummery , G. A. & Niranjan, M. On-line Q-learning using connectionist systems. T ec h. Rep., Universit y of Cam bridge (1994). [47] W ang, C.-C., Kulk arni, S. R. & Poor, H. V. Bandit prob- lems with side observ ations. IEEE T r ansactions on Au- tomatic Control 50 , 338–355 (2005). [48] Sutton, R. S. Integrated architectures for learning, plan- ning, and reacting based on approximating dynamic pro- gramming. In Pr o c e e dings of the 7th International Con- fer enc e on Machine L e arning , 216–224 (1990).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment