프로젝티브 시뮬레이션의 메타학습 확장
본 논문은 프로젝트 시뮬레이션(PS) 모델에 메타학습 메커니즘을 도입하여, 에이전트가 스스로 학습 파라미터인 감쇠γ와 글로우 η를 환경 변화에 맞게 조정하도록 설계한다. 반사적 적응과 학습 기반 적응 두 가지 방식을 제시하고, 세 가지 강화학습 과제에서 자동 메타파라미터 튜닝이 가능함을 실험적으로 입증한다.
저자: Adi Makmal, Alexey A. Melnikov, Vedran Dunjko
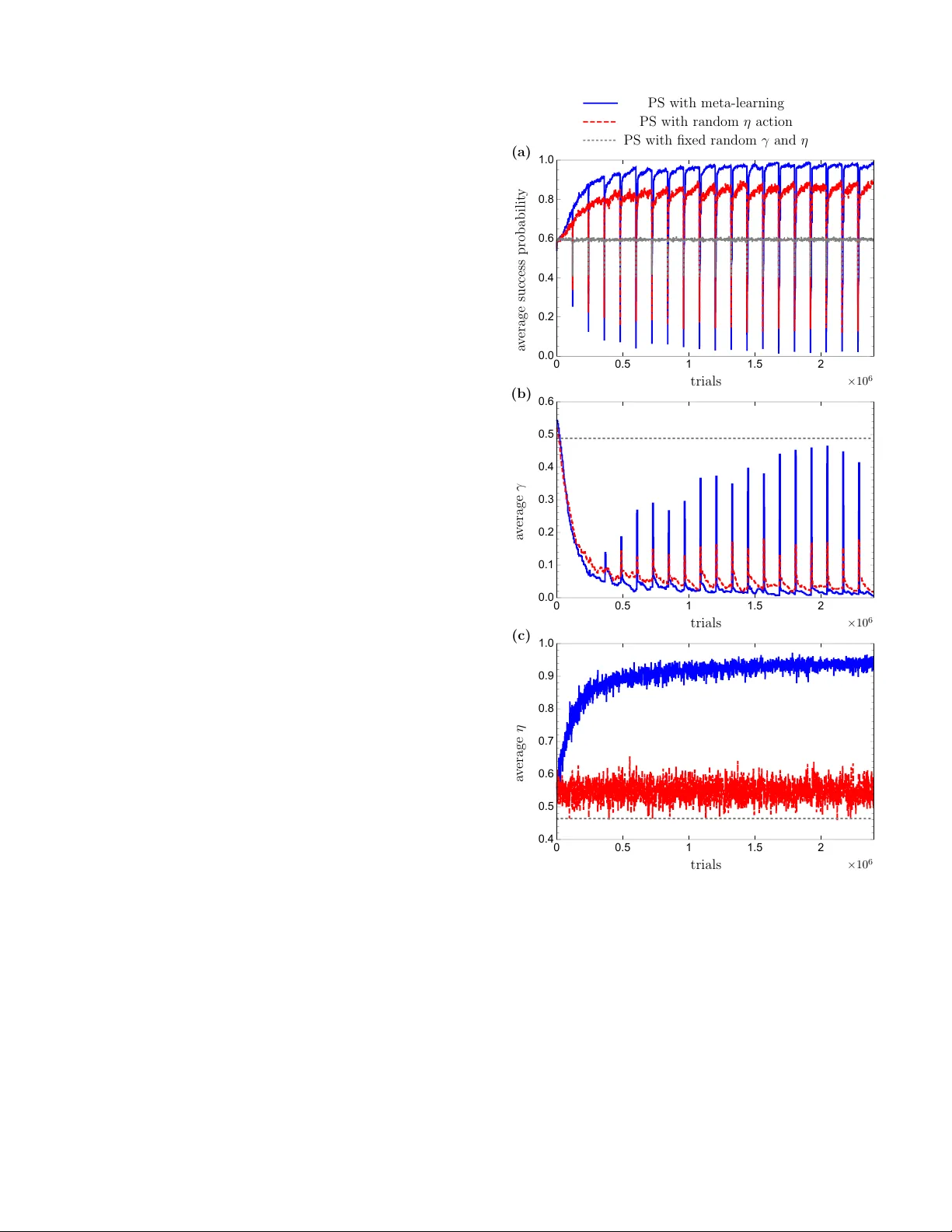
본 논문은 인공지능 분야에서 널리 사용되는 강화학습(RL) 모델 중 하나인 프로젝트 시뮬레이션(Projective Simulation, PS)의 메타학습 확장을 제안한다. PS는 에피소드·구성 메모리(ECM)라는 클립 네트워크를 기반으로, 입력된 퍼셉트(percept) 클립에서 시작해 무작위 워크를 수행하며 행동(action) 클립에 도달하면 해당 행동을 실행한다. 이 과정에서 클립 간 전이 가중치 h값은 보상 λ와 감쇠 파라미터 γ에 따라 업데이트되며, 지연 보상 상황을 다루기 위해 글로우 변수 g와 그 감쇠율 η가 추가된다. γ는 에이전트의 ‘망각’ 정도를, η는 과거 행동에 대한 보상의 전파 범위를 조절한다.
하지만 γ와 η는 작업마다 최적값이 다르다. 예를 들어, 환경이 고정된 전통적인 그리드 월드나 마운틴 카와 같은 과제에서는 γ≈0, η≈0이 최적이지만, 환경이 주기적으로 바뀌는 침입 게임과 같이 정책을 빠르게 재조정해야 하는 경우에는 높은 γ와 적절한 η가 필요하다. 이러한 메타파라미터의 환경 의존성을 해결하고자 저자들은 두 가지 메타학습 메커니즘을 도입한다.
첫 번째는 ‘반사적 적응(reflexive adaptation)’이다. 이는 최근 성공률을 실시간으로 모니터링하고, 사전에 정의된 규칙(예: 성공률이 일정 이하로 떨어지면 γ를 증가)으로 γ를 조정한다. 이 방식은 별도 메모리 구조가 필요 없으며, 빠른 반응성을 제공한다. 단점은 복잡한 환경 변화에 대한 적응력이 제한적이라는 점이다.
두 번째는 ‘학습 기반 적응(adaptation through learning)’이다. 여기서는 메타‑ECM이라는 별도의 클립 네트워크를 구축한다. 메타‑ECM은 기본 PS와 동일한 랜덤 워크와 보상 업데이트 규칙을 갖지만, 그 목적은 γ와 η의 최적값을 학습하는 것이다. 메타‑ECM은 과거 행동·보상 기록을 저장하고, 이를 바탕으로 메타파라미터를 점진적으로 조정한다. 이 과정에서 메타‑ECM 자체도 ‘학습’하게 되므로, 복잡하고 비정형적인 환경 변화에도 유연하게 대응할 수 있다.
논문은 세 가지 실험 시나리오를 통해 제안된 메타학습 프레임워크의 효용성을 검증한다. (1) 침입 게임: 공격자의 방향 표시가 주기적으로 바뀌는 상황에서, 메타학습 에이전트는 초기 학습 단계에서 약간의 성공률 저하를 겪지만, 환경 전환 직후 빠르게 재학습하여 90% 이상의 성공률을 유지한다. (2) 그리드 월드: 보상이 지연되는 복합 경로 탐색 과제에서, 글로우 η를 자동 조정함으로써 기본 PS보다 훨씬 짧은 시간에 최적 경로를 학습한다. (3) 마운틴 카: 연속적인 상태 공간과 비선형 보상 구조를 가진 과제에서, 메타‑ECM이 γ와 η를 동시에 최적화하여 수렴 속도와 최종 성능 모두에서 기존 PS를 능가한다.
또한, 메타학습 도입에 따른 ‘학습‑시간 트레이드오프’를 상세히 분석한다. 높은 γ는 재학습 속도를 높이지만, 장기적인 성공 확률을 낮춘다. 반면, 낮은 γ는 안정적인 성능을 제공하지만 환경 변화에 대한 적응이 느리다. 메타‑ECM은 이러한 트레이드오프를 동적으로 균형 맞추어, 상황에 따라 최적의 γ와 η를 선택한다.
마지막으로, PS와 메타학습 구조가 양자 워크 기반 구현과도 호환 가능함을 언급한다. 기존 연구에서 양자 PS가 고전적 PS보다 탐색·혼합 시간에서 이점이 있음을 보였으며, 메타‑ECM 역시 양자화될 경우 메타파라미터 조정 과정 자체가 양자 가속을 얻을 가능성을 제시한다.
결론적으로, 본 연구는 PS 모델에 메타학습 레이어를 자연스럽게 결합함으로써, 파라미터 튜닝을 외부에 의존하지 않고 에이전트 자체가 환경 변화에 적응하도록 만든다. 이는 학습 파라미터가 고정된 전통적 RL 알고리즘과 달리, 복합적·동적 환경에서의 로봇 제어, 게임 AI, 자율 주행 등 다양한 응용 분야에 적용 가능성을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기