Monotone Retargeting for Unsupervised Rank Aggregation with Object Features
Learning the true ordering between objects by aggregating a set of expert opinion rank order lists is an important and ubiquitous problem in many applications ranging from social choice theory to natural language processing and search aggregation. We…
Authors: Avradeep Bhowmik, Joydeep Ghosh
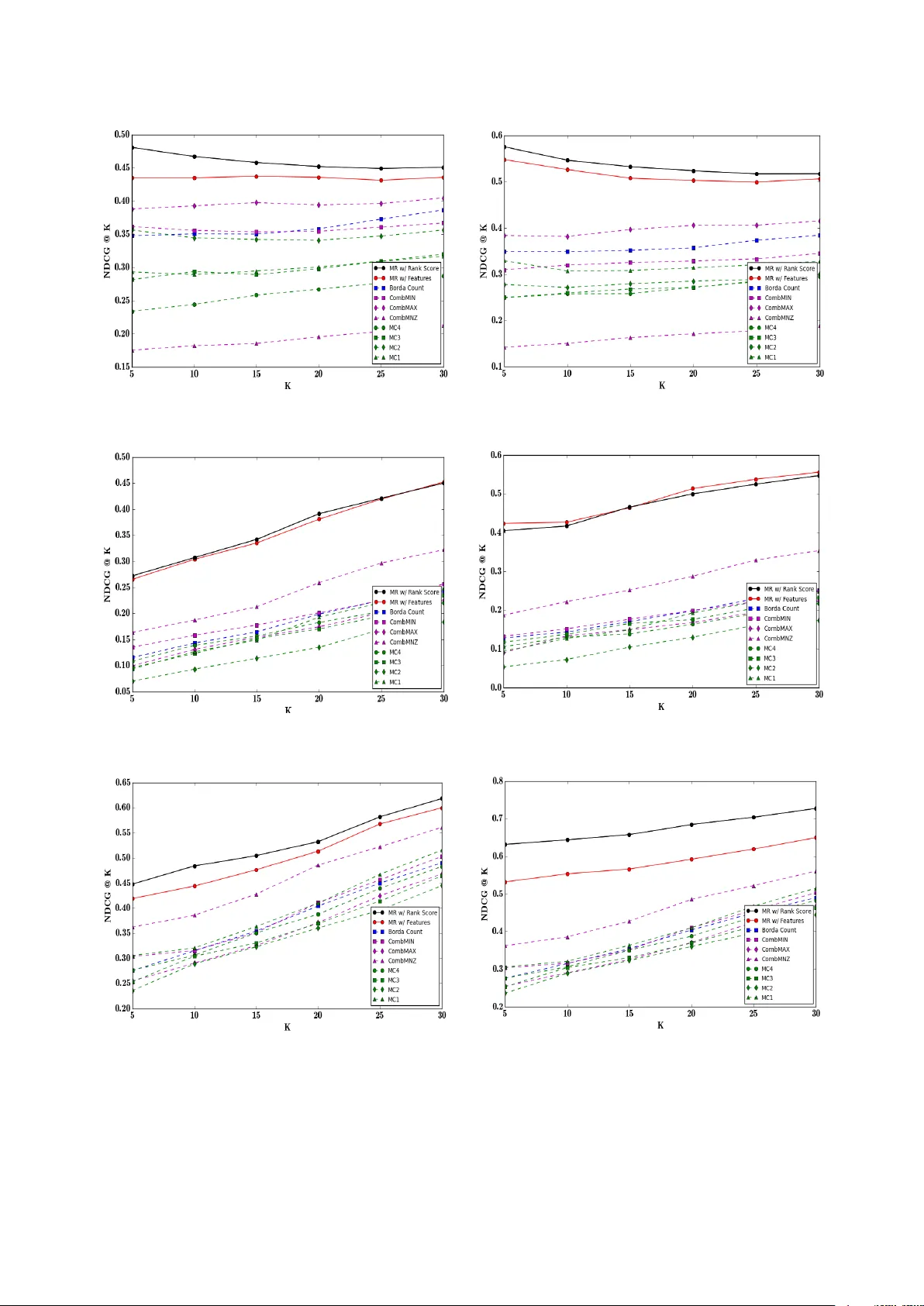
Monotone Retargeting for Unsup ervised Rank Aggregation with Ob ject F eatures Avradeep Bho wmik Univ ersit y of T exas at Austin Austin, TX Jo ydeep Ghosh Univ ersit y of T exas at Austin Austin, TX Septem b er 21, 2018 Abstract Learning the true ordering betw een ob jects by aggregating a set of exp ert opinion rank order lists is an imp ortan t and ubiquitous problem in many applications ranging from so cial choice theory to natural language pro cessing and search aggregation. W e study the problem of unsup ervised rank aggregation where no ground truth ordering information in a v ailable, neither ab out the true prefer- ence ordering b et w een any set of ob jects nor ab out the quality of individual rank lists. Aggregating the often inconsisten t and po or quality rank lists in such an unsup ervised manner is a highly chal- lenging problem, and standard consensus-based metho ds are often ill-defined, and difficult to solve. In this manuscript we prop ose a nov el framew ork to bypass these issues by using ob ject attributes to augment the standard rank aggregation framework. W e design algorithms that learn joint mo dels on b oth rank lists and ob ject features to obtain an aggregated rank ordering that is more accurate and robust, and also helps weed out rank lists of dubious v alidity . W e v alidate our techniques on syn thetic datasets where our algorithm is able to estimate the true rank ordering ev en when the rank lists are corrupted. Exp erimen ts on three real datasets, MQ2008, MQ2008 and OHSUMED, sho w that using ob ject features can result in significant impro vemen t in p erformance o ver existing rank aggregation metho ds that do not use ob ject information. F urthermore, when at least some of the rank lists are of high quality , our metho ds are able to effectively exploit their high exp ertise to output an aggregated rank ordering of great accuracy . 1 In tro duction Learning preference orderings among ob jects is a common problem in many mo dern applications includ- ing web search, do cumen t retriev al, collab orativ e filtering and recommendation systems. Rank aggrega- tion is a version of this problem that app ears in areas ranging from voting and so cial c hoice theory [ 35 ], to meta search and search aggregation [ 25 ] to ensemble metho ds for com bining classifiers [ 21 ]. W e fo cus on the problem of unsup ervised rank aggregation [ 22 , 23 ] in this manuscript. The standard setup consists of a set of n items or ob jects to b e ranked, and a set of p ranking lists from “exp erts” 1 (p ossibly inconsistent, and of v arying levels of exp ertise and credibilit y) con taining rank scores or rele- v ance scores for all or a subset of the n items, and the ob jective is to combine the lists from different exp erts and obtain a consensus rank order ov er the set of items. Note that this setup is different from sup ervised rank aggregation [ 28 , 30 , 37 ] or semi-sup ervised rank aggregation [ 10 , 15 ] where, in addition to the rank lists, we also hav e ground truth rank orderings b etw een at least a subset of the ob jects to b e ranked (for example, ground truth rank orderings supplied by high exp ertise human annotators or sub ject matter exp erts, that can then b e used as training data). In contrast, in the unsup ervised setup, w e are only giv en access to rank lists without an y information ab out the qualit y of each list, or any ground truth rank order b et ween ob jects. A related but v ery distinct problem that also lo oks at ordering among items is learning to rank or LETOR [ 17 , 14 , 9 ], which tries to learn ranking functions o ver ob jects given training data with known 1 Can be IR features or learning based algorithms or sub jective cro wd-sourced annotation, for example 1 rank scores or pairwise preference information. Standard metho ds for LETOR mo del the rank scores or orderings as a function of features asso ciated with the ob jects. The difference b etw een LETOR and unsup ervised rank aggregation is tw o-fold. First, unlike the latter, LETOR is supervised and has access to training data. Second, while LETOR models rank scores as func- tions of ob ject features, existing rank aggregation metho ds are completely agnostic to the prop erties of the ob jects being rank ed, even when suc h information is a v ailable, for example in the case of meta-searc h, searc h aggregation, or ensemble metho ds o ver learning agen ts[ 25 , 21 ]. As a result, rank aggregation is significan tly more challenging to tackle as compared to LETOR, or sup ervised/semi-sup ervised metho ds in general. Without access to any information ab out true preference ordering among ob jects, the standard rank aggregation problem b ecomes a hard com binatorial problem, and often rife with paradoxes [ 4 ]. Rule based approaches like Borda winner [ 38 ], Condorcet winner [ 8 ], etc., are commonly used, but many of these rules are incompatible with each other [ 35 ]. Alternative approaches learn consensus orderings by minimising “disagreements” or distance-like metrics among the rank scores or preference orderings sp ec- ified by the ranked lists from exp erts [ 19 , 20 ]. This approach runs into the problem that for many of the commonly used distance metrics, the corresp onding optimisation problem is NP-Hard [ 11 ]. Indeed, without additional information, one cannot form an incon trov ertible definition for “consensus” and “disagreemen t” b et ween rank scores, or even decide on the metric to b e used to find the consensus rank ordering. Moreov er, these metho ds are excessively dep enden t on the assumption that the exp erts are reliable and comp eten t. Spurious rank order lists or ev en the presence of noise in the rank ed lists can significantly deteriorate the p erformance of most standard metho ds used for rank aggregation. 1.1 Using Ob ject Information The absence of supervision reduces rank aggregation to a problem of c ho osing betw een comp eting heuris- tics. But obtaining even partial ground truth can b e exp ensiv e and time consuming and often requires the inv olvemen t of dedicated human exp erts as annotators. This manuscript introduces a nov el rank aggregation framework that mitigates the handicaps of unsu- p ervised rank aggregation by using information about ob ject attributes to augment standard approac hes and aid the recov ery of the “true” rank order. This is in contrast to existing metho ds which are “blind” in the sense that they are completely agnostic to the prop erties of the ob jects themselves. Our key contributions are summarised as follows- 1. T o the b est of our knowledge, we are the first to use ob ject information to aid the rank aggregation problem. W e introduce a nov el framework that combines information from rank scores and ob ject features to learn a consensus ordering ov er a set of items. 2. W e formulate the rank aggregation problem using isotonically coupled mo dels ov er exp ert lists and ob ject features to model rank scores, and describe a solution algorithm to estimate the true ordering that inv olves alternate but interdependent iterations b etw een a LETOR step and a rank aggrega- tion step, each of which is separately a simple conv ex optimisation problem with monotonicity constrain ts. 3. W e ev aluate our framework with exp eriments on synthetic data where, unlike existing metho ds, our algorithm is able to reconstruct the true rank ordering exactly given corrupted rank lists. W e also demonstrate our methods on three real datasets, where our algorithm significantly outperforms existing rank aggregation techniques that do not use ob ject information. W e note that ev en though our framew ork uses LETOR inspired metho ds, our formulation is still an unsup ervised learning algorithm since we do not assume access to any full or partial ground truth rank order or pairwise preferences, or ev en information ab out the quality of any rank lists. 1.2 Related W ork In light of the difficulties inherent in the rank aggregation problem, most of the commonly used rank ag- gregation applications apply heuristic based techniques ranging from classical methods for vote counting, 2 com bination metho ds inv olving linear and non-linear functions, and more recen t approaches inv olving Mark ov Chain Monte Carlo simulations. The Borda Count [ 38 ] is the traditional vote counting pro cedure that uses p ositional information as op- p osed to rank scores. The pro cedure orders the candidates (items) by the num b er of candidates ranked lo wer than them, av eraged ov er the set of voters (exp ert lists). Com bination metho ds [ 12 , 26 ] work on explicit relev ance scores provided by exp erts and include v ari- ous linear combinations like CombSUM, CombMNZ and CombANZ as well as non-linear metho ds like Com bMIN and CombMAX. It has b een seen [ 26 , 5 ] that out of the three linear combination metho ds, Com bMNZ has the b est p erformance. If all items hav e b een retrieved by all exp ert lists, all three meth- o ds give the same final ranking. Among non-linear metho ds [ 26 , 12 ], CombMIN and CombMAX resp ectiv ely rank the items on the min- im um and maximum scores received across the lists provided by exp erts. More recent work [ 11 ] on rank aggregation hav e introduced MCMC based metho ds. The basic idea is to use the items to b e ranked as states of a Mark ov Chain and define the transition probabilit y of switching from one state (item) to another, based on the relative scores or preference v alues of the corresp onding items across rank lists. F our different Marko v Chain constructions (MC1, MC2, MC3, MC4) hav e b een describ ed in [ 11 ] that use different heuristics to construct the transition probability matrix. The final ranking of the items is defined by the stationary distribution across the items defined by the states of the Marko v Chain. Note On Notation: The vector r is said to b e in increasing order if r i ≤ r j whenev er i ≤ j . The set of all such vectors in R n is denoted with a subscripted do wnw ard p oin ting arrow as R n ↓ . Two v ectors r and z are said to b e isotonic, r ∼ ↓ z , if r i ≥ r j if and only if z i ≥ z j for all i, j . 2 Problem Setup Let V b e a set of distinct items and Q = { q 1 , · · · , q |Q| } b e a set of queries. Each query q is asso ciated with a set of items V q ⊂ V . F or simplicity and with no loss in generality , we consider the case of a single query ov er a set of n items, and drop the notation q from all subsequent notation. Supp ose the true rank ordering ov er n items is given by a vector ρ ∗ ∈ R n . In searc h aggregation, for example, ρ ∗ could be true relev ance scores as annotated b y a human sub ject matter exp ert 2 . With sligh t abuse of notation, w e shall ov erload ρ ∗ to denote b oth a rank score as well as a rank ordering (p erm utation) defined by the rank score vector. In the standard rank aggregation setup, we are giv en access to rank lists b y a set of p exp erts, each of whom assert a rank ordering or relev ance score judgement ov er the entire set of items in V . Sup- p ose that the relev ance score vector for the k th exp ert is r k ∈ R n , where a higher score indicates a higher relev ance for the item. W e aggregate all relev ance score lists as columns of the rank list matrix R = [ r 1 ; r 2 ; · · · r p ] ∈ R n × p . In unsup ervised rank aggregation, the true ordering ρ ∗ is not known, even among a partial subset of ob jects. Ho wev er, it is assumed that at least some of the rank lists in R are generated using ρ ∗ (p erhaps from noisy or corrupted v ersions of ρ ∗ ) and standard rank aggregation metho ds try to recov er ρ ∗ b y learning a mo del that maps R to a vector r that is isotonic with ρ ∗ (e.g. Borda Count, com bination metho ds, etc. see section 1.2 ). In this manuscript we try to ov ercome the limitations of unsup ervised rank aggregation as describ ed in section 1 by augmenting our setup with ob ject features, which are often av ailable in applications like meta-searc h, IR, etc. Supp ose for the set of items V = { V 1 , V 2 , · · · V n } , each item V i can b e represented b y a d -dimensional feature vector x i ∈ R d . W e collect all these item feature vectors to form ro ws of the 2 we study rank aggregation in the context of applications lik e meta-search and IR where such a ρ ∗ is assumed to exist, as opposed to so cial c hoice theory where suc h a ρ ∗ may not alwa ys exist b ecause of Arrow’s Impossibility Theorem [ 4 ] 3 feature matrix X ∈ R n × d . The consensus rank ordering is then obtained using information from b oth R and X . T o motiv ate our approach, consider the standard sup ervised LETOR framework which has access to b oth X as w ell as ρ ∗ . Popular LETOR metho ds [ 14 , 9 , 27 ] pro ceed by learning a mo del that maps X to a rank score v ector z that is isotonic with ρ ∗ . Similarly , many standard metho ds for sup ervised rank aggregation [ 28 , 30 ] pro ceed by learning a mo del that maps R to a vector that agrees with av ailable information ab out ρ ∗ . In contrast, ρ ∗ is completely unkno wn in unsup ervised rank aggregation. The key idea for our metho d is that while we do not hav e explicit access to ρ ∗ , b oth X and R are implicitly tied together by ρ ∗ , and this implicit asso ciation can b e exploited to recov er ρ ∗ b y jointly mo delling the mappings that can b e learned from X and R resp ectiv ely . T o our kno wledge, while ob ject attributes are commonly av ailable for man y rank aggregation setups (e.g. meta-search or search aggregation), none of the existing rank aggregation metho ds exploit them sufficien tly . As a first work, w e explore the use of generalised linear mo dels or GLMs [ 29 ] as our mo deling framew ork since they are a large class of mo dels that subsume many standard mo deling framew orks (e.g. Gaussian or P oisson regression), and are widely used for many applications across a wide v ariety of domains. In particular, GLMs hav e found extensive usage in b oth LETOR [ 3 , 1 ] as well as most 3 rank aggregation metho ds [ 38 , 12 , 26 ]. 3 Rank Aggregation with Ob ject F eatures GLM’s mo del the target v ariable (in this case, rank score) as a linear function of the feature v ariables, monotonically transformed via a monotonic link function. W e assume that the true rank ordering ρ ∗ can b e mo deled as a monotonically transformed linear combination of the rank order lists R ∈ R n × p b y the exp erts, that is, ρ ∗ ∼ ↓ R β ∗ for some β ∗ ∈ R p . Even without the monotonic transformation, this setup subsumes standard score fusion algorithms, eg. see [ 16 , 12 ], and also the Borda-Count and weigh ted Borda-F use [ 38 , 35 ] if the rank scores are defined as the num b er of items ranked b elo w a particular item. This setup can also effectively handle the case when some of the ranked lists are of dubious v alidit y– suc h rank lists can simply b e assigned zero weigh t and discarded by the mo del. Similarly , w e also assume that the true rank score vector ρ ∗ is isotonic to a monotonically transformed linear function of the ob ject features, that is, ρ ∗ ∼ ↓ X ω ∗ for some ω ∗ ∈ R d . This is a standard assump- tion for many ranking problems that mo del the rank function using a generalised linear mo del (see [ 3 , 1 ] and references). The ob jective now is to estimate β ∗ and ω ∗ b y joint mo delling of X ω ∗ and R β ∗ to estimate ω ∗ and β ∗ b y minimising an appropriate distance-like cost function. Clearly , standard cost functions like square loss may not make sense in ev ery context (for example, when the domain is binary , or in teger v alued, or categorical), therefore we present our tec hniques for a muc h more general class of cost functions called Bregman div ergences, which are distance-like functions intimately asso ciated with GLM’s and include many standard and commonly used loss functions like square loss, KL-Divergence, Generalised I-Div ergence, etc. Bregman Divergences: The matching loss functions asso ciated with learning GLM parameters are distance-lik e functions called Bregman divergences, which are generalisations of square loss. Bregman Div ergences are alwa ys defined on a conv ex function φ ( · ), where the particular conv ex function used dep ends on the particular GLM mo del used (see [ 6 ]). F or any t wo vectors y and x , the Bregman div ergence D φ ( ·k· ) b etw een the vectors corresp onding to the function φ is defined as D φ ( y k x ) , φ ( y ) − φ ( x ) − h∇ φ ( x ) , y − x i A more detailed description of Bregman Div ergences is deferred to Appendix A , see also [ 6 ] for a rigorous exp osition on the relationship b et w een GLM’s and Bregman Divergences. In particular, for our w ork 3 specifically , many common rank aggregation mo dels, e.g. Borda, CombMNZ, etc. use simple linear schemata 4 w e use the fact that parameter estimation in a GLM with giv en ob ject features X and known target v ariable z is equiv alent to finding the minimiser ω ∗ for D φ z k ( ∇ φ ) − 1 ( X ω ) as, ω ∗ = arg min ω D φ z k ( ∇ φ ) − 1 ( X ω ) (1) where φ ( · ) is the conv ex function asso ciated with the sp ecific GLM used– for a Gaussian mo del or equiv- alen tly square loss, for example, φ is the identit y function (see [ 6 ]). Bregman Div ergences are alw ays non-negative D φ ( ·k· ) ≥ 0, and b y definition, D φ z k ( ∇ φ ) − 1 ( X ω ) is separately conv ex in z as well as in ω . Many standard distance-lik e functions like Square loss, Kullback- Leibler (KL) divergence and Generalised I-divergence can b e written as members of this family for their corresp onding φ . F or succinctness, w e shall henceforth denote D φ z k ( ∇ φ ) − 1 ( X ω ) simply as D φ ( z k X ω ). 3.1 Cost F unction F ollowing the discussion on using Bregman divergences as the loss function for estimating ω ∗ and β ∗ , it is tempting to use R β as the target v ariable and X ω as the feature map, and write the join t optimisation framew ork as follows: β ∗ , ω ∗ = arg min β , ω D φ ( R β k X ω ) (2) Alternativ ely , the order of arguments ( R β , X ω ) can b e reversed. How ever, b oth these formulations are deficien t in their modelling capacit y since they force a coupling betw een the domain of X and the domain of R . In particular, while X is often real v alued, R can often b e integer v alued or binary v alued, or ev en categorical with partial ordering and the same φ may not make sense for b oth. Moreov er, this do es not tak e into account the more general assumption that the true ordering need only b e isotonic to the tw o linear functions, that is R β ∼ ↓ X ω , but exact equality may b e an unnecessarily strong and sup erfluous constrain t. Incorporating monotonic inv ariance b et w een R β and X ω is a challenging problem in the ab o ve formulation. A far b etter alternative sc heme that bypasses all these issues inv olves decoupling the cost function into t wo parts- one inv olving the rank scores by exp erts and one inv olving the ob ject features. 3.1.1 Decoupled Cost F unction Consider r ∈ R n as the rank score v ector to b e fitted against a linear function of the rank score matrix R . This part of the decoupled cost function therefore consists of the term D φ r ( r k R β ) for an appropriate φ r . Since w e consider all rank score v ectors that inv oke the same ordering among items to b e equiv alen t, we shall b e learning r across all monotonic transformations to incorp orate inv ariance across isotonic vectors in our formulation. Similarly , supp ose z ∈ R n is the rank score vector obtained as the linear function of ob ject features. Corresp ondingly , this part of the cost function b ecomes D φ z ( z k X β ) for an appropriate φ z . Along the same lines as ab o ve, we learn z across all monotonic transformations. Therefore, the full cost function b ecomes C ( r , β , z , ω ) = D φ r ( r k R β ) + λD φ z ( z k X ω ) (3) to b e minimised ov er r , β , z , ω . T o retain the isotonicity relationship b et ween the linear functions R β and X ω , we add the constraint r ∼ ↓ z . The ov erall optimisation problem therefore b ecomes min r , β , z , ω D φ r ( r k R β ) + λD φ z ( z k X ω ) s.t. r ∼ ↓ z (4) Choice of divergence functions φ r and φ z dep ends on the domain (real v alued, integer, etc.) and the mo deling assumptions used on r and z , a discussion on learning the appropriate φ has b een detailed in [ 2 ]. W e shall see later that our optimisation framew ork inv olv es steps that are inv arian t to the λ v alue c hosen, so we use λ = 1 for simplicity . 5 4 Monotonically Retargeted Rank Aggregation Equation ( 4 ) is an optimisation problem of a function that is separately conv ex in its argumen ts, but o ver a non-conv ex set. Joint optimisation ov er all v ariables simultaneously is difficult, therefore we divide the v ariables in to tw o disjoin t sets and perform alternating minimisation o v er eac h set of v ariables separately . Nev ertheless, b ecause of the monotonic inv ariance of the isotonicity constraint we need to p erform each optimisation step ov er all monotonic transformations of the v ectors r and z , whic h is a very difficult problem in general. Ho wev er, it turns out that the setup b ecomes relatively easy to handle by using a tec hnique called monotone retargeting used in sup ervised learning to rank problems. Monotone Retargeting or MR [ 3 ] is a LETOR technique that uses ob ject attributes X and known rank score vector ρ ∗ and learns a mo del that finds the b est mapping from X o ver all p ossible monotonic transformations z of the rank score vector ρ ∗ . The sp ecific optimisation problem that MR handles in the case of Bregman Divergences (i.e., using GLM’s) is the following: min z , ω D φ z k ( ∇ φ ) − 1 ( X ω ) s.t. z ∼ ↓ ρ ∗ (5) T o imp ose strict ordering constraints and to av oid degenerate solutions, a v ariation of MR called Margin Equipp ed Monotone Retargeting or MEMR w as introduced in [ 1 ] that uses margin constrain ts on z together with ordering constraints defined by ρ ∗ . A detailed description of MR and MEMR is given in App endices B and C resp ectiv ely . The steps used in the exact optimisation algorithm for MR is summarised as Algorithm 1 . MR is a versatile framework that has found usage outside of the traditional sup ervised ranking application it was designed for. In particular, versions of this framework hav e b een used for collab orativ e filtering for recommendation systems [ 24 ], and learning generalised linear mo dels from aggregated data [ 7 ]. In this manuscript we apply this framework to the problem of rank aggregation. Algorithm 1 LETOR with Monotone Retargeting 1: pro cedure MR ( φ , X , ρ ∗ ) 2: Initialise ω , z 3: while not conv erged do 4: Solv e for z + using P A V z + = arg min z ∼ ↓ ρ ∗ D φ ( z k X ω ) 5: Solv e for ω + a std GLM param estimation ω + = arg min ω D φ z + k X ω 6: Up date v ariables ( z , ω ) = ( z + , ω + ) 7: end while 8: return z , ω 9: end pro cedure Consider the set of v ariables Υ = ( r , β , z , ω ) divided into tw o sets of v ariables Υ r = ( r , β ) and Υ z = ( z , ω ). After initialisation (which can b e done by using an y preferred rank aggregation algorithm), the algorithm pro ceeds in tw o alternating steps. First, keeping Υ z fixed, the optimisation problem ov er Υ r b ecomes min r , β D φ r ( r k R β ) s.t. r ∼ ↓ z (6) Similarly , keeping Υ r fixed, the optimisation problem ov er Υ z b ecomes min z , ω D φ z ( z k X ω ) s.t. z ∼ ↓ r (7) A t face v alue, b ecause of the common isotonicit y constraint r ∼ ↓ z applied to b oth steps of the optimi- sation problem, it ma y seem the algorithm will remain p erpetually stuck to the rank ordering defined 6 b y the initialisation of r or z . How ever, this do es not happen b ecause at alternate steps, the z or r that define the isotonicity constraint can b e partially ordered rather than totally ordered. This enables the algorithm to freely mo v e b et w een p erm utations at successive steps. A detailed discussion of this phenomenon is provided in Section 5.2 . Algorithm 2 Rank Aggregation with Ob ject F eatures 1: pro cedure MR-RankAgg ( φ r , R , φ z , X ) 2: Initialise r , β , z , ω 3: while not conv erged do 4: z + , ω + = MR ( φ z , X , r ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . LETOR-step 5: r + , β + = MR ( φ r , R , z + ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Rank-A gg step 6: Up date all v ariables ( r , β , z , ω ) ← ( r + , β + , z + , ω + ) 7: end while 8: return ( r , β , z , ω ) 9: end pro cedure Individually , b oth equations ( 6 ) and ( 7 ) are standalone instances of MR and inherit all the desirable prop erties of the algorithm as detailed in [ 3 , 1 ]. The t wo main steps of the algorithm hav e a nice in terpretation– equation ( 6 ) is equiv alent to MR( φ r , R , z ) and is analogous to a LETOR step, while equation ( 7 ) is equiv alent to MR( φ z , X , r ) and is analogous to a rank aggregation step. The steps used in the ov erall optimisation are summarised in Algorithm 2 . Con v ergence and Efficiency: Algorithm 2 uses alternating minimisation on a non-negative cost function, therefore the algorithm alwa ys conv erges to a stationary p oint. Each iteration inv olves the MR pro cedure detailed in Algorithm 1 , which can b e implemented very efficien tly in practice (see [ 1 ]). In particular, the P A V step has b een implemented in Θ( n ) (see references in [ 36 ]). Both the P A V step and the GLM-solver step hav e b een extensively studied, and fast off-the-shelf implementations are readily a v ailable. 4.1 Margin Equipp ed V ersion T o a void certain kinds of degeneracies (see [ 1 ]), MEMR uses a form ulation that enforces an -margin b e- t ween the relev ance scores b etw een any t wo items adjacent to eac h other in the learned rank score v ector z . W e can formulate a margin-equipp ed version for our metho ds as well, how ev er the MEMR scheme cannot b e used directly . As w e discuss in section 5.2 , one of the salient desiderata of our formulation is to b e able to mov e b et ween rank orderings at every step of the algorithm, which is achiev ed by using the partial orderings for r or z generated by the optimisation algorithm at the end of each iteration. Imp osing a strict ordering would make that no longer p ossible. In fact, in most cases a strict ordering is unnecessary– to av oid degenerate solutions as in [ 1 ], it is sufficien t to enforce a margin only b etw een the maximum and the minimum rank score. That is, the constrain t w e shall use, say on r , would b e of the form r ( max ) − r ( min ) > for some > 0. While this is a non-linear, non-conv ex condition in general, within the constraint set r ∼ ↓ z , this b ecomes a simple half-space constraint since the indic es for maximum and minimum in r are already sp ecified by the ordering defined by z . A similar margin constraint can b e applied to z as well. 5 Discussion 5.1 Regularisation Adding a conv ex regularisation term (esp ecially on the GLM parameters β and ω ) in equation 4 can ha ve man y useful effects while retaining conv exity prop erties in the optimisation problem. In particular, supp ose we kno w that some of the rank order lists are spurious or generated by sources of dubious ex- p ertise. In such a case, sparsity promoting metho ds like LASSO regularisation on β may help weed out the spurious rank lists b y enforcing sparsity . A similar argument can also b e made for adding sparsit y b oosting regularisers on ω to weed out spurious features. 7 5.2 Mo ving b etw een p erm utations One of the k ey desiderata of our algorithm is that the r or z in intermediate steps should b e free to mov e b et ween p erm utations, so that the final aggregated output for rank order do es not get influenced to o hea vily b y the initialisation. This is accomplished b y our algorithm in the follo wing manner. The up date step for z in the MR Algorithm 1 inv olves a p o ol-adjacen t-violator (P A V) smo othing op era- tion, which has the prop ert y that if the ordering constraint on z does not match the ordering of the right hand side X β , the final output w ould b e a partially ordered z . Supp ose at time t , w e start with some total ordering ρ 0 on z and r , and after step ( 4 ) in Algorithm 2 we end up with a z + whic h is consistent with ρ 0 but is partially ordered. When such a partially ordered z + is used as an input for estimating r + at step ( 5 ) of Algorithm 2 , the final output for r + ma y hav e a total ordering ρ 1 whic h is consisten t with the partial ordering sp ecified by z + , but not necessarily consistent with the total ordering ρ 0 . There- fore, betw een time t and time t + 1, the algorithm ends up mo ving from the ordering ρ 0 to the ordering ρ 1 . Subsequen tly , we shall sho w with exp erimen ts on synthetic data that this is indeed the case. Starting from an initialisation that do es not reflect the true ordering, the r and z obtained by our algorithm are allow ed to mo ve b etw een p ermutations till they con verge to a stationary p oin t corresp onding to the exact ordering. 5.3 Extensions While the methods outlined in this man uscript used GLM’s and Bregman Div ergences, our form ulation is m uch more general. Specifically , techniques like MR were used to illustrate one of many p ossible wa ys of join tly mo deling rank scores with ob ject features, and other methods from the sup ervised LETOR or rank aggregation literature can b e easily incorp orated into our framework by changing the cost function and optimisation algorithm. Similarly , our metho ds can b e extended to man y other con texts, including partial orderings that can be either learned at each step iterativ ely [ 3 ], or by using isotonic regression algorithms [ 36 ] when specified using directed acyclic graphs [ 33 ], or using additional constrain ts when specified using implicit feedbac k [ 34 ]. Finally , adding supervision to the framework is straigh tforward – simply add strict wide-margin (linear half-space) constraints to the margin equipp ed formulation describ ed in section 4.1 . 6 Exp erimen ts W e ev aluate the p erformance of our algorithm on b oth synthetic and real datasets. The metrics used for ev aluation are Kendall’s tau co efficien t [ 19 ] and Sp earman’s rho or rank correlation co efficien t [ 20 ], as w ell as the p opular NDCG metric [ 17 ] for list-wise ranking. In all three metrics, a higher v alue indicates b etter recov ery of rank order, and a v alue of 1.0 indicates exact order reco very . As baselines, we use the classical Borda Coun t. Among linear com bination metho ds, following [ 26 ] and [ 5 ] we use CombMNZ, and also show comparisons to non-linear aggregation metho ds like Com bMIN and Com bMAX [ 12 ]. F urther, we also compare against all four Marko v Chain based metho ds presen ted in [ 11 ]. 6.1 Syn thetic Data W e first ev aluate on synthetic data where the GLM assumption holds (mo dulo noise). The rank ag- gregation framework is ev aluated ov er n = 200 items for eac h query 4 . Matrix of feature v ectors X is generated using the standard m ultiv ariate normal distribution and a normally distributed ω ∗ is used to compute the true rank scores ρ ∗ from X ω ∗ , according to the generalised linear mo dels corresp ond- ing to Gaussian and Poisson distributions resp ectiv ely , with the appropriate φ function (see App endix A ). The rank lists consist of vectors generated by randomly corrupting the true rank score ρ ∗ with different p erturbations including translation, and additive or multiplicativ e noise. Multiple spurious exp ert rank 4 usually in most real life applications the set of items range between 50 and 300, eg. see the standard datasets in Microsoft LETOR 4.0 [ 31 ] 8 (a) Kendall-T au distance versus Iteration for Gaussian (b) Kendall-T au distance versus Iteration for P oisson (c) Spearman’s rho against iteration for Gaussian mo del (d) Spearman’s rho against iteration for Poisson model (e) NDCG@K v ersus K for Gaussian (f ) NDCG@K versus K for Poisson Figure 1: Syn thetic Data: Kendall-T au, Sp earman’s Rho and NDCG@K vs K against iterations of the algorithm for Gaussian [figures ( 1a ), ( 1c ), ( 1e ) resp ectiv ely] and Poisson mo dels [figures ( 1a ), ( 1d ), ( 1f ) resp ectiv ely] Results show that our metho d can exactly recov er the true rank order even from corrupted rank lists within only a few iterations. In contrast none of the baseline rank aggregation metho ds can recov er the true ordering. 9 (a) NDCG@K v ersus K on the OHSUMED dataset (b) NDCG@K vs K on OHSUMED with augmen ted rank list (c) NDCG@K v ersus K on the MQ2008 dataset (d) NDCG@K v ersus K on MQ2008 with augmen ted rank list (e) NDCG@K v ersus K on the MQ2007 dataset (f ) NDCG@K versus K on MQ2007 with augmented rank list Figure 2: Real Datasets: NDCG@K versus K (higher is b etter) av eraged across queries OHSUMED, MQ2008, MQ2007 datasets [figures: ( 2a ), ( 2c ), ( 2e ) resp ectively], and NDCG@K vs K a veraged across queries on the same datasets OHSUMED, MQ2008, MQ2007 with augmented rank lists [figures: ( 2b ), ( 2d ), ( 2f ) resp ectiv ely] Results show that our metho ds outp erform standard rank aggregation techniques in general. If the rank lists hav e ”go o d qualit y” exp erts, the improv ement in p erformance is substantial for our metho d as opp osed to baselines 10 lists are also generated as vectors constructed from pure random noise. In all, 10 rank lists are concate- nated to form R . X and R are then used as input to our Algorithm 2 with the appropriate Bregman divergence and φ ( · ), and the outputs z and r are then ev aluated 5 against ρ ∗ . Figures ( 1a ) and ( 1c ) resp ectiv ely show the v alue of Kendall’s tau and Sp earman’s rho b et ween the estimated r , z and the true ρ ∗ at eac h iteration of the algorithm, for the setup that uses a Gaussian mo del. Figures ( 1b ) and ( 1d ) show the same for a setup generated using a Poisson mo del. The plots sho w that in both models, the algorithm is able to exactly reco ver the original rank ordering (Kendall-tau and Sp earman’s rho b oth ev aluate to 1.0) within a small num b er of iterations. In con trast, none of the standard rank aggregation metho ds are able to recov er the true ordering. Figures ( 1e ) and ( 1f ) show NDCG@K vs K for the final ordering output by our metho d, as compared to baseline metho ds, in a Gaussian setup and a Poisson setup resp ectiv ely . As opp osed to the rank orderings output by our metho d which alwa ys p erfectly extracts the top K items for each K, none of the baselines are able to correctly iden tify the top K relev ant items for any v alue of K. 6.2 Real Datasets: MQ2008, MQ2007, and OHSUMED W e ev aluate our tec hniques as applied to the more c hallenging case of real datasets where the GLM assumption may not alwa ys hold. W e use three complex real w orld datasets widely used for ranking applications- MQ2008 and MQ2007 from Microsoft’s LETOR 4.0 rep ository [ 31 ], and OHSUMED from the LETOR 3.0 rep ository [ 32 ]. The MQ2008 and the MQ 2007 datasets from the LETOR 4.0 rep ository are query sets from the Mil- lion Query track of TREC 2008. The LETOR 4.0 rep ository contains, for each query and asso ciated do cumen t set, 46 ob ject features for ranking as well as a set of 25 rank lists. W e use the rank lists as our R and ob ject features as our X matrix resp ectiv ely . PageRank and relev ance scores computed from differen t IR metho ds [ 18 , 39 ] are also added to the rank lists (they are not used as ob ject features). The OHSUMED dataset is a subset of the MEDLINE database of medical publications, and the standard application in v olves extraction of relev ant documents giv en a set of medical queries. The rank list matrix is constructed from 15 columns of the dataset that contain relev ance scores computed using the BM25 score[ 18 ] and differen t IR metho ds based on language mo dels [ 39 ]. The remaining 30 columns are used as ob ject features. In each of these datasets, we compare against ground truth which is av ailable for each query and asso- ciated item as a relev ance score that go es from 0 (not relev ant) to 2 (most relev ant) (ground truth is not used for learning). Additional details ab out the datasets including feature lists are av ailable in [ 31 ] and [ 32 ] resp ectively . Note that for each exp erimen t, ob ject attributes and rank lists use disjoint sets of columns. W e compare the p erformance of different metho ds using the NDCG@K m etric applied to this relev ance score, a v eraged across queries for eac h K. The results are sho wn in figures ( 2a ), ( 2c ), ( 2e ) for OHSUMED, MQ2008, MQ2007 resp ectiv ely . The plots show that for all three datasets, even though the GLM as- sumption ma y not necessarily hold, our metho d nev ertheless outp erforms standard rank aggregation metho ds which do not take into accoun t ob ject features. An in teresting phenomenon that was observed with real datasets was that when at least one of the rank lists are of “high quality” in the sense that it is learned with sup ervision in the form of true relev ance scores, the p erformance of our algorithm improv es substantially . This effect is not seen on the baselines whic h only show marginal improv ement compared to their p erformance on set of rank lists which has 5 If the final output is partially ordered, evaluation is done on the total ordering most consistent with the corresp onding cov ariates X ω for z and R β for r 11 not b een augmented with high quality lists. W e p erformed a similar exp erimen ts as ab o v e, except w e augmented our rank lists from exp erts with the relev ance scores output by a ranking function learned from training data using the metho ds in [ 3 ]. The NDCG@K versus K plots for augmented rank lists are shown for the OHSUMED dataset in fig. ( 2b ), for the MQ2008 dataset in fig. ( 2d ), and for the MQ2007 dataset in fig. ( 2f ). Side by side comparison with original plots show that when the rank lists contain at least one list of high quality , our algorithm returns an aggregated ordering in which the NDCG sc ore sho ws a marked impro vemen t, while standard metho ds fail to exploit the augmented rank lists to any substan tial degree. Note that information ab out which rank lists are of high quality is not av ailable to any of the algorithms in these exp erimen ts. These exp erimen tal results suggest that if the set of rank lists are generated by sources whose exp ertise lev els lie on a wide sp ectrum, our framework is nevertheless able to use more information from rank lists with higher credibilit y , and recov er an ordering which matches the “true” ranking to a greater degree as compared to rank aggregation metho ds which dep end solely on the rank lists and are blind to ob ject features. 7 Conclusion In this manuscript we in tro duced a nov el rank aggregation scheme that augments exp ert rank lists with information from ob ject features to bypass the v arious issues that plague the standard rank aggregation setup, and in the pro cess obtain more accurate and robust aggregated rank scores. Exp eriments on syn thetic data and on real datasets indicate that using ob ject features can result in significant improv e- men t in p erformance, more so when the rank lists contain orderings generated by sources with genuine exp ertise. F uture work would cov er theoretical analyses of our scheme, including statistical guarantees and extensions to more general mo dels for ranking and rank aggregation. References [1] S. Ac haryya and J. Ghosh. MEMR: A margin equipp ed monotone retargeting framew ork for ranking. In Pr o c e e dings of the Thirtieth Confer enc e on Unc ertainty in Artificial Intel ligenc e , 2014. [2] S. Acharyy a and J. Ghosh. Parameter estimation of generalized linear mo dels without assuming their link function. Pr o c e e dings of the Eighte enth International Confer enc e on Artificial Intel ligenc e and Statistics , 2015. [3] S. Acharyy a, O. Koy ejo, and J. Ghosh. Learning to Rank with Bregman Div ergences and Monotone Retargeting . In Pr o c. UAI 2012 , pages 15–25, 2012. [4] K. J. Arrow. A difficulty in the concept of so cial welfare. The Journal of Politic al Ec onomy , pages 328–346, 1950. [5] J. A. Aslam and M. Montague. Mo dels for metasearch. In Pr o c e e dings of the 24th annual in- ternational ACM SIGIR c onfer enc e on R ese ar ch and development in information r etrieval , pages 276–284. ACM, 2001. [6] A. Banerjee, S. Merugu, I. S. Dhillon, and J. Ghosh. Clustering with Bregman divergences. The Journal of Machine L e arning R ese ar ch , 6:1705–1749, 2005. [7] A. Bhowmik, J. Ghosh, and O. Koy ejo. Generalized Linear Mo dels for Aggregated Data. In Pr o- c e e dings of the Eighte enth International Confer enc e on Artificial Intel ligenc e and Statistics , pages 93–101, 2015. [8] D. Black. On the rationale of group decision-making. The Journal of Politic al Ec onomy , pages 23–34, 1948. [9] C. Cav anagh and R. P . Sherman. Rank estimators for monotonic index mo dels. Journal of Ec ono- metrics , 84(2):351–381, 1998. 12 [10] S. Chen, F. W ang, Y. Song, and C. Zhang. Semi-sup ervised ranking aggregation. Information Pr o c essing & Management , 47(3):415–425, 2011. [11] C. Dwork, R. Kumar, M. Naor, and D. Siv akumar. Rank aggre gation revisited, 2001. [12] J. A. F o x and E. Shaw. Com bination of multiple sources: The trec-2 interactiv e track matrix exp erimen t. In ACM SIGIR-94 , 1994. [13] S. Grotzinger and C. Witzgall. Pro jections onto order simplexes. Applie d mathematics and Opti- mization , 12(1):247–270, 1984. [14] R. Herbrich, T. Graep el, and K. Ob erma yer. Supp ort vector learning for ordinal regression. 1999. [15] S. C. Hoi and R. Jin. Semi-sup ervised ensemble ranking. In AAAI , pages 634–639, 2008. [16] R. Iyer and J. Bilmes. The lov´ asz-bregman divergence and connections to rank aggregation, clus- tering, and web ranking. Unc ertainity in Artificial Intel ligenc e , 2013. [17] K. J¨ arv elin and J. Kek¨ al¨ ainen. Ir ev aluation metho ds for retrieving highly relev an t do cumen ts. In Pr o c e e dings of the 23r d annual international ACM SIGIR c onfer enc e on R ese ar ch and development in information r etrieval , pages 41–48. ACM, 2000. [18] K. S. Jones, S. W alker, and S. E. Rob ertson. A probabilistic mo del of information retriev al: develop- men t and comparative experiments: Part 2. Information Pr o c essing & Management , 36(6):809–840, 2000. [19] M. G. Kendall. A new measure of rank correlation. Biometrika , pages 81–93, 1938. [20] M. G. Kendall. Rank correlation metho ds. 1948. [21] A. Klementiev, D. Roth, and K. Small. Unsup ervised rank aggregation with distance-based mo dels. In Pr o c e e dings of the 25th international c onfer enc e on Machine le arning , pages 472–479. ACM, 2008. [22] A. Klementiev, D. Roth, and K. Small. Unsup ervised rank aggregation with distance-based mo dels. In Pr o c e e dings of the 25th international c onfer enc e on Machine le arning , pages 472–479. ACM, 2008. [23] A. Klemen tiev, D. Roth, K. Small, and I. Tito v. Unsup ervised rank aggregation with domain-sp ecific exp ertise. Urb ana , 51:61801, 2009. [24] O. Koy ejo, S. Acharyy a, and J. Ghosh. Retargeted matrix factorization for collab orativ e filtering. In Pr o c e e dings of the 7th ACM c onfer enc e on R e c ommender systems , pages 49–56. ACM, 2013. [25] G. Lebanon and J. Lafferty . Cranking: Combining rankings using conditional probability mo dels on p ermutations. In ICML , volume 2, pages 363–370, 2002. [26] J. H. Lee. Analyses of multiple evidence combination. In ACM SIGIR F orum , volume 31, pages 267–276. ACM, 1997. [27] H. Li. Learning to rank for information retriev al and natural language pro cessing. Synthesis L e ctur es on Human L anguage T e chnolo gies , 7(3):1–121, 2014. [28] Y.-T. Liu, T.-Y. Liu, T. Qin, Z.-M. Ma, and H. Li. Sup ervised rank aggregation. In Pr o c e e dings of the 16th international c onfer enc e on World Wide Web , pages 481–490. ACM, 2007. [29] P . McCullagh and J. A. Nelder. Generalized linear mo dels. 1989. [30] M. Pujari and R. Kanaw ati. Sup ervised rank aggregation approach for link prediction in complex net works. In Pr o c e e dings of the 21st international c onfer enc e c omp anion on world wide web , pages 1189–1196. ACM, 2012. [31] T. Qin and T.-Y. Liu. In tro ducing letor 4.0 datasets. arXiv pr eprint arXiv:1306.2597 , 2013. [32] T. Qin, T.-Y. Liu, J. Xu, and H. Li. Letor: A b enc hmark collection for research on learning to rank for information retriev al. Information R etrieval , 13(4):346–374, 2010. [33] V. Raman and S. Saurabh. Parameterized algorithms for feedback set problems and their duals in tournamen ts. The or etic al Computer Scienc e , 351(3):446–458, 2006. 13 [34] S. Rendle, C. F reuden thaler, Z. Gantner, and L. Schmidt-Thieme. BPR: Bay esian p ersonalized ranking from implicit feedbac k. In Pr o c e e dings of the Twenty-Fifth Confer enc e on Unc ertainty in A rtificial Intel ligenc e , pages 452–461. AUAI Press, 2009. [35] D. G. Saari. Explaining all three-alternative v oting outcomes. Journal of Ec onomic The ory , 87(2):313–355, 1999. [36] Q. F. Stout. F astest isotonic regression algorithms, 2014. [37] K. Subbian and P . Melville. Sup ervised rank aggregation for predicting influencers in twitter. In Privacy, Se curity, R isk and T rust (P ASSA T) and 2011 IEEE Thir d Inernational Confer enc e on So cial Computing (So cialCom), 2011 IEEE Thir d International Confer enc e on , pages 661–665. IEEE, 2011. [38] M. V an Erp and L. Schomak er. V arian ts of the b orda count metho d for combining ranked classifier h yp otheses. In Seventh International Workshop on F r ontiers in Handwriting R e c o gnition , 2000. [39] C. Zhai and J. Lafferty . A study of smo othing methods for language models applied to ad ho c information retriev al. In Pr o c e e dings of the 24th annual international ACM SIGIR c onfer enc e on R ese ar ch and development in information r etrieval , pages 334–342. ACM, 2001. APPENDIX A Bregman Div ergences The matc hing loss functions asso ciated with learning GLM parameters are distance-like functions called Bregman div ergences, which are generalisations of square loss. Let φ : Θ 7→ R b e a strictly con vex, closed function on a conv ex domain Θ ⊆ R m . Supp ose φ is differentiable on in t(Θ). Then, for any x , y ∈ Θ, the Bregman divergence D φ ( ·k· ) b etw een y and x corresp onding to the function φ is defined as D φ ( y k x ) , φ ( y ) − φ ( x ) − h∇ φ ( x ) , y − x i Bregman divergences are conv ex in their first argument. Although strictly sp eaking they are not a dis- tance metric, they satisfy many prop erties of metrics, for example D φ ( y k x ) ≥ 0 and D φ ( y k x ) = 0 if and only if y = x . Many standard distance-like functions like Square loss and KL-div ergence are members of this family (see T able 1 ). There is a one-one correspondence b et w een eac h GLM and each Bregman divergence via the conv ex function φ ( · ), and parameter estimation in a GLM with given ob ject features X and target v ariable z is equiv alent to finding the minimiser for D φ z k ( ∇ φ ) − 1 ( X ω ) o ver ω , where φ ( · ) is the conv ex function asso ciated with the particular GLM used (refer to [ 6 ] for a detailed exposition on the relationship b et ween Bregman Divergences and GLM’s). φ ( x ) D φ ( y k x ) 1 2 k x k 2 1 2 k y − x k 2 P i ( x ( i ) log x ( i ) ) x ∈ Prob. Simplex KL( y k x ) = P i y ( i ) log( y ( i ) x ( i ) ) P i x ( i ) log x ( i ) − x ( i ) x ∈ R n + GI( y k x ) = P i y ( i ) log( y ( i ) x ( i ) ) − y ( i ) + x ( i ) T able 1: Examples of Bregman Div ergences 14 B Monotone Retargeting Monotone retargeting [ 3 , 1 ] or MR is a LETOR framework that mo dels ranking functions of ob ject features on monotonic transformations of given relev ance scores, and learns b oth the ranking function as w ell as the b est monotonic transformation. The pap er [ 3 ] solves the LETOR problem using MR b y mo deling the monotonically transformed rank score z as a generalised linear mo del ov er ob ject features X and learns the GLM parameter ω that b est fits the data ov er all p ossible monotonic transformations z of the given “true” relev ance scores ρ ∗ . The LETOR setup used by MR is the following. Consider a single query . Supp ose for a given set of n items { V 1 , V 2 , · · · V n } to b e ranked, X ∈ R n × p is the matrix of ob ject features. Supp ose the sup ervision is pro vided as a rank score vector ρ ∗ ∈ R n . The ob jectiv e of MR is to find a monotonic transformation of the given rank scores z ∼ ↓ ρ ∗ and a real v alued parameter ω ∈ R p whic h minimises the Bregman div ergence D φ z k ( ∇ φ ) − 1 ( X ω ) . The optimisation problem, therefore, is the following min z , ω D φ z k ( ∇ φ ) − 1 ( X ω ) s.t. z ∼ ↓ ρ ∗ (8) Giv en ρ ∗ and X , this problem is separately conv ex in z and ω , and with appropriate regularisation can also b e made jointly con vex in the t wo v ariables[ 1 ]. A top level description of the algorithm as adapted from [ 3 ] is presented as Algorithm 1 in the main manuscript. In particular, the steps in volv ed include a standard GLM parameter estimation for ω and the p o ol adjacent violators algorithm [ 13 ], widely used in isotonic regression, for z . If ρ ∗ is partially ordered, an intermediate step inv olves the estimation of a total ordering consistent with the partial ordering sp ecified b y ρ ∗ . Each step of the algorithm has b een widely studied in the literature and off-the-shelf solvers can b e used to efficiently iterate through each step of the algorithm to con verge to a stationary p oint. See [ 3 ] for a more detailed discussion on the prop erties of the solution obtained via this framework, and efficient algorithms for optimisation. C Margin Equipp ed Monotone Retargeting A margin equipp ed v ariation of this problem, MEMR[ 1 ], av oids degenerate stationary p oin ts b y enforcing a margin b et ween the relev ance score b et ween any tw o items in the setup. That is, supp ose = [ 1 , 2 , · · · n − 1 ] ∈ R n − 1 + , where each j ≥ 0. Suppose the sp ecified rank score vector ρ ∗ is ordered as ( τ 1 , τ 2 , · · · τ n ), where each τ j ∈ { 1 , 2 , · · · , n } . That is, ρ τ j ≥ ρ τ j +1 for each j = 1 , 2 , · · · ( n − 1). Then the reformulated optimisation problem used in MEMR is as follows min z , β D φ z k ( ∇ φ ) − 1 ( X β ) s.t. z ∼ ↓ ρ ∗ z τ j − z τ j +1 ≥ j ∀ j = 1 , 2 , · · · n − 1 (9) Since the additional constraints are conv ex half-space constraints o v er z , most of the standard prop erties of monotone retargeting are main tained (see [ 1 ] for a more detailed analysis as well as optimisation algorithms). 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment