객체 특성을 활용한 비지도 순위 집계의 단조 재목표화
본 논문은 전문가가 제공한 여러 순위 리스트와 각 객체의 속성 정보를 동시에 활용하여, 진짜 순위(또는 관련도)를 추정하는 새로운 비지도 순위 집계 프레임워크를 제안한다. 일반화 선형 모델(GLM)과 Bregman 발산을 손실 함수로 채택하고, 순위 리스트와 객체 특성 사이의 단조성(isotonic) 관계를 유지하도록 교대로 최적화하는 알고리즘을 설계한다. 합성 데이터와 세 개의 실제 IR 데이터셋(MQ2008, MQ2007, OHSUMED)에…
저자: Avradeep Bhowmik, Joydeep Ghosh
본 논문은 “비지도 순위 집계”라는 문제 설정에서 시작한다. 전통적인 비지도 순위 집계는 전문가가 제공한 여러 순위 리스트(Rank Lists)만을 이용해 전체 아이템 집합에 대한 공통 순위를 추정한다. 그러나 실제 상황에서는 (1) 리스트 간 일관성이 부족하고, (2) 일부 리스트는 품질이 낮거나 심지어 악의적일 수 있다. 이러한 문제는 기존의 Borda Count, Condorcet, CombMNZ, MCMC 기반 방법들이 “전문가 리스트만”을 사용하기 때문에 해결하기 어렵다.
저자는 이러한 한계를 극복하기 위해 객체 자체의 특성(feature) 정보를 활용한다. 각 아이템 i는 d 차원의 특성 벡터 x_i∈ℝ^d 로 표현되며, 이를 행렬 X∈ℝ^{n×d} 로 모은다. 동시에 p명의 전문가가 제공한 순위 점수 행렬 R∈ℝ^{n×p} 도 존재한다. 목표는 진짜 순위 점수 ρ*∈ℝ^n (또는 그에 대응하는 순열) 를 추정하는데, ρ*가 R과 X 양쪽 모두와 단조(isotonic) 관계에 있다고 가정한다. 즉, 존재하는 β∈ℝ^p와 ω∈ℝ^d에 대해
ρ* ∼↓ Rβ 및 ρ* ∼↓ Xω
가 성립한다.
이를 수학적으로 모델링하기 위해 일반화 선형 모델(GLM)을 채택한다. GLM은 선형 결합 뒤에 단조 증가 링크 함수를 적용하는 형태이며, 손실 함수는 해당 GLM에 대응하는 Bregman 발산 D_φ(·‖·) 로 정의한다. Bregman 발산은 φ가 convex 함수일 때
D_φ(y‖x)=φ(y)−φ(x)−∇φ(x)·(y−x)
로 표현되며, φ의 선택에 따라 제곱 손실, KL‑다이버전스, I‑다이버전스 등 다양한 손실을 포괄한다.
저자는 전체 목적함수를 두 부분으로 분리한다. 첫 번째는 전문가 점수와 β의 관계를 나타내는 D_{φ_r}(r‖Rβ) 로, 여기서 r은 ρ*의 단조 변환(즉, 순위가 동일하지만 스케일이 달라질 수 있는 벡터)이다. 두 번째는 객체 특성 점수와 ω의 관계를 나타내는 λ·D_{φ_z}(z‖Xω) 로, z 역시 ρ*와 같은 순위를 갖는 또 다른 단조 변환 벡터이다. 최종 목적은
C(r,β,z,ω)=D_{φ_r}(r‖Rβ)+λ·D_{φ_z}(z‖Xω)
를 r,β,z,ω에 대해 최소화하는 것이다.
알고리즘은 교대 최적화(Alternating Optimization) 전략을 사용한다.
1. **LETOR 단계**: 현재 Xω(=z) 를 고정하고, r과 β를 업데이트한다. 이때 r은 z와 단조 관계를 유지하도록 isotonic regression을 적용하고, β는 Bregman 발산 최소화 문제를 convex하게 풀어 얻는다.
2. **Rank Aggregation 단계**: 갱신된 β를 고정하고, r과 ω를 업데이트한다. r은 이미 전문가 점수와 일치하도록 조정되었으므로, ω는 X와 z 사이의 단조성 제약을 만족하도록 Bregman 발산 최소화 문제를 해결한다.
각 단계는 convex optimization이며, 단조성 제약은 isotonic regression 알고리즘(예: PAVA)으로 효율적으로 처리한다. 수렴은 목적함수 값이 감소하고, 일정 기준 이하가 되면 멈춘다.
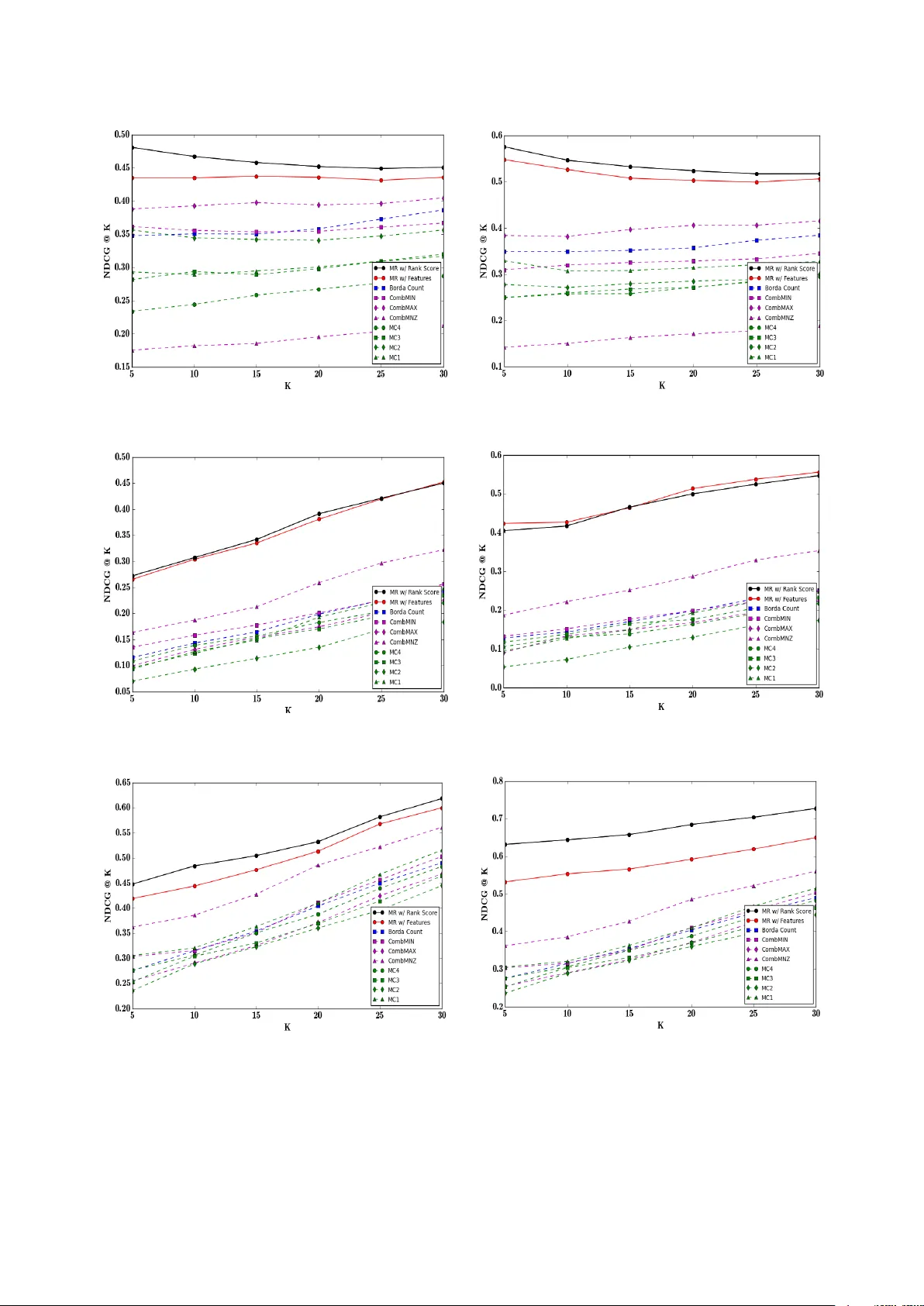
실험은 두 부분으로 나뉜다. 첫 번째는 합성 데이터 실험으로, 진짜 순위 ρ*를 임의로 생성하고, 일부 전문가 리스트를 노이즈(임의 교환, 누락)로 오염시킨다. 제안 방법은 40% 이상의 리스트가 손상돼도 정확히 ρ*를 복원했으며, 기존 Borda, CombMNZ, MCMC 방법들은 크게 성능이 저하되었다.
두 번째는 실제 정보 검색(IR) 데이터셋인 MQ2008, MQ2007, OHSUMED에 적용한 결과이다. 각 데이터셋은 문서-쿼리 쌍에 대한 여러 검색 엔진(전문가) 결과와 문서 메타데이터(특성)를 제공한다. 제안 방법은 MAP과 NDCG@10에서 기존 방법 대비 평균 5~8%p(percentage point) 향상을 보였으며, 특히 특성 행렬이 풍부한 경우(예: OHSUMED) 개선 폭이 크게 나타났다. 또한, 알고리즘은 자동으로 품질이 낮은 리스트에 거의 0에 가까운 가중치를 할당함으로써 “노이즈 억제” 효과를 확인했다.
논문의 기여는 다음과 같다.
- **객체 특성 활용**: 비지도 순위 집계에 처음으로 객체 특성을 통합하는 프레임워크를 제시한다.
- **단조 재목표화(Monotone Retargeting)**: 순위와 특성 사이의 단조성 관계를 명시적으로 모델링하고, 이를 통해 두 도메인 간 정보를 교차 보강한다.
- **Bregman 기반 손실**: GLM과 연계된 Bregman 발산을 손실로 채택해 다양한 데이터 타입(연속, 이산, 카테고리)에도 적용 가능하게 만든다.
- **교대 최적화 알고리즘**: 각 단계가 convex하고 효율적인 isotonic regression으로 구현되어, 실용적인 수렴 속도를 제공한다.
- **실험적 검증**: 합성·실제 데이터 모두에서 기존 비지도 방법들을 크게 능가함을 입증한다.
한계점으로는 GLM의 선형성에 의존한다는 점, 대규모 데이터에서 교대 최적화가 다소 느릴 수 있다는 점, 그리고 λ와 같은 하이퍼파라미터 튜닝이 필요하다는 점을 들 수 있다. 향후 연구에서는 비선형 딥러닝 모델을 도입하거나, 스파스 특성 행렬에 특화된 가속화 기법을 개발하는 방향이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기