IISCNLP at SemEval-2016 Task 2: Interpretable STS with ILP based Multiple Chunk Aligner
Interpretable semantic textual similarity (iSTS) task adds a crucial explanatory layer to pairwise sentence similarity. We address various components of this task: chunk level semantic alignment along with assignment of similarity type and score for …
Authors: Lavanya Sita Tekumalla, Sharmistha
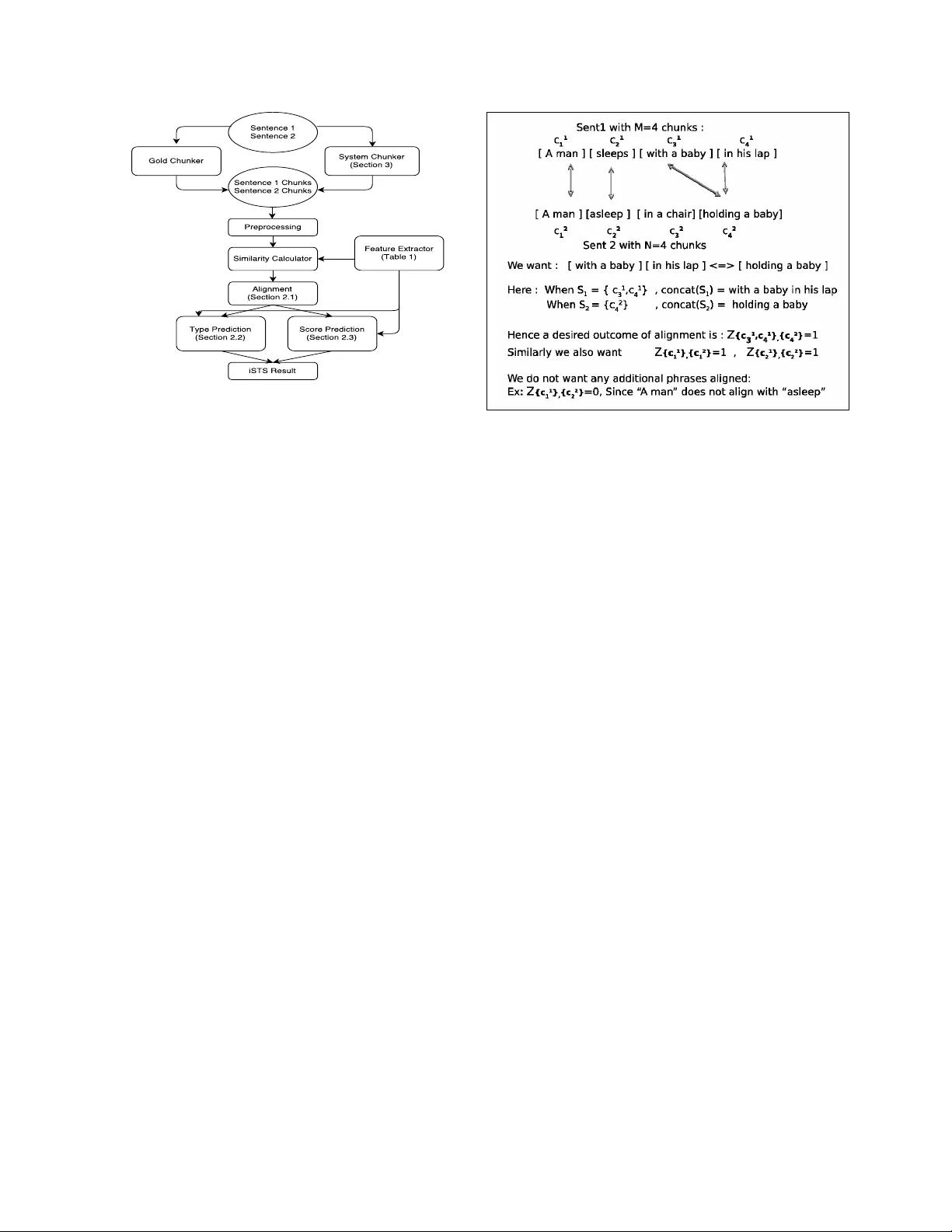
IISCNLP at SemEval-2016 T ask 2: Interpr etable STS with ILP based Multiple Chunk Aligner La vanya Sita T ekumalla and Sharmistha lav an ya.tekumalla@gmail.com sharmistha.jat@gmail.com Indian Institute of Science, Bangalore, India Abstract Interpretable semantic textual similarity (iSTS) task adds a crucial explanatory layer to pairwise sentence similarity . W e address various components of this task: chunk lev el semantic alignment along with assignment of similarity type and score for aligned chunks with a novel system presented in this paper . W e propose an algorithm, iMA TCH, for the alignment of multiple non-contiguous chunks based on Integer Linear Programming (ILP). Similarity type and score assignment for pairs of chunks is done using a supervised multiclass classification technique based on Random Forrest Classifier . Results sho w that our algorithm iMA TCH has lo w execution time and outperforms most other participating systems in terms of alignment score. Of the three datasets, we are top ranked for answer- students dataset in terms of overall score and hav e top alignment score for headlines dataset in the gold chunks track. 1 Introduction and Related W ork Semantic T extual Similarity (STS) refers to measur - ing the degree of equi valence in underlying seman- tics(meaning) of a pair of text snippets. It finds ap- plications in information retriev al, question answer- ing and other natural language processing tasks. In- terpretable STS (iSTS) adds an e xplanatory layer , by measuring similarity across chunks of se gmented text, leading to an improved interpretability . It in- volv es aligning multiple chunks across sentences with similar meaning along with similarity score(0- 5) and type assignment. Interpretable STS task was first introduced as a pilot task in 2015 Semev al STS task. Se veral ap- proaches were proposed including NeRoSim (Ban- jade et al., 2015), UBC-Cubes (Agirre et al., 2015) and Exb-Thermis (H ¨ anig et al., 2015). For the task of alignment, these submissions used approaches based on monolingual aligner using word similarity and conte xtual features (Md Araf at Sultan and Sum- mer , 2014), J A CANA that uses phrase based semi- marko v CRFs (Y ao and Durme, 2015) and Hun- garian Munkers algorithm (Kuhn and Y aw , 1955). Other popular approaches for mono-lingual align- ment include two-stage logistic-regression based aligner (Md Arafat Sultan and Summer , 2015), tech- niques based on edit rate computation such as (lien Maxe Anne V ilnat, 2011) and TER-Plus (Snover et al., 2009). (Bodrumlu et al., 2009) used ILP for word alignment problem. The iSTS task in 2016 introduced problem of many-to-man y chunk align- ment, where multiple non-contiguous chunks of the source can align with multiple-non-contiguous chunks of the target sentence, that previous mono- lingual alignment techniques cannot handle. W e propose iMA TCH, a ne w technique for monolingual alignment for many-to-many alignment at the chunk le vel, that can combine non-contiguous chunks based on inte ger linear programming (ILP). W e also explore sev eral features to define a similarity score between chunks to define the objective function for our optimization problem, similarity type and score classification modules. T o summarize our contribu- tions: • W e propose a novel algorithm for monolingual alignment : iMA TCH that handles many-to- Figure 1: Flow diagram of proposed iSTS system many chunk lev el alignment, based on Integer Linear Programming. • W e propose a system for Interpretable Se- mantic T extual Similarity: In the Gold-chunks track, our system is the top performer for the students-dataset and our alignment score is in that of the best two teams for all datasets. 2 System f or Interpretable STS Our system comprises of (a) alignment module, iMA TCH (section 2.1), (2) T ype prediction module (section 2.2) and (3) Score prediction module (sec- tion 2.3). In the case of system chunks, there is an additional chunking module for segmenting in- put sentences into chunks. Figure 1 sho ws the block diagram of proposed system. Problem F ormulation : Follo wing is the for- mal definition of our problem. Consider source sentence ( S ent 1 ) with M chunks and target sen- tence ( S ent 2 ) with N chunks. Consider sets C 1 = { c 1 1 , . . . , c 1 M } , the chunks of sentence S ent 1 and C 2 = { c 2 1 , . . . , c 2 N } , the chunks of sentence S ent 2 . Consider sets S 1 ⊂ P ower S et ( C 1 ) − φ and S 2 ⊂ P ow erS et ( C 2 ) − φ . Note that S 1 and S 2 are sub- sets of the power set (set of all possible combina- tions of sentence chunks) of C 1 and C 2 respecti vely . Consider sets S 1 ∈ S 1 and S 2 ∈ S 2 , which de- notes a specific subset of chunks that are likely to be combined during alignment. Let concat ( S 1 ) denote the phrase resulting from concatenation of chunks in S 1 and concat ( S 2 ) denote the phrase resulting from concatenation of chunks of S 2 . Consider a binary Figure 2: iMatch: An example illustrating notation v ariable Z S 1 ,S 2 that tak es v alue 1 if concat ( S 1 ) is aligned with concat ( S 2 ) and 0 otherwise. The goal of alignment module is to determine the decision variables ( Z S 1 ,S 2 ), which are non-zero. S 1 and S 2 can hav e more than one chunk (mul- tiple alignment), that are not necessarily contigu- ous. Aligned chunks are further classified using T ype classifier and Score classifier . T ype pr edic- tion module identifies a pair of aligned chunks ( concat ( S 1 ) , concat ( s 2 )) ) with a relation type like EQUI (equiv alent), OPPO (opposite) etc. Scor e classifier module assigns a similarity score ranging between 0-5 for a pair of chunks. For the system chunks track, the chunking module , conv erts sen- tences S ent 1 , S ent 2 to sentence chunks C 1 , C 2 . 2.1 iMA TCH: ILP based Monolingual Aligner f or Multiple-Alignment at the Chunk Lev el W e approach the problem of multiple alignment (permitting non-contiguous chunk combinations) by formulating it as an Integer Linear Programming (ILP) optimization problem. W e construct the ob- jecti ve function as the sum of all Z S 1 ,S 2 , ∀ S 1 , S 2 weighed by the similarity between concat ( S 1 ) and concat ( S 2 ) , subject to constraints to ensure that each chunk is aligned only a single time with any other chunk. This leads to the following optimiza- tion problem based on Integer linear programming (Nemhauser and W olsey , 1988): max Z Σ S 1 ∈S 1 ,S 2 ∈S 2 Z S 1 ,S 2 α ( S 1 , S 2 ) S im ( S 1 , S 2 ) S.T Σ ¯ S 1 = { S : c 1 ∈ S,S ∈ S 1 } ,S 2 ∈ S 2 Z S 1 ,S 2 ≤ 1 , ∀ 1 ≤ c 1 ≤ M Σ S 1 ∈ S 1 , ¯ S 2 = { S : c 2 ∈ S,S ∈ S 2 } Z S 1 ,S 2 ≤ 1 , ∀ 1 ≤ c 2 ≤ N Z S 1 ,S 2 ∈ { 0 , 1 } , ∀ S 1 ∈ S 1 , S 2 ∈ S 2 Optimization constraints ensure that a particular chunk c appears in an alignment a single time with any subset of chunks in the other sentence. There- fore, one chunk can be part of alignment only once. W e note that all possible multiple alignments are e x- plored by this optimization problem when S 1 = P ow erS et ( C 1 ) − φ and S 2 = P ow er S et ( C 2 ) − φ . Ho wev er , this leads to a very high number of deci- sion variables Z S 1 ,S 2 , not suitable for realistic use. Hence we consider a restricted usecase S 1 = { C 1 1 } , . . . , { C 1 M } ∪ {{ C 1 i , C 1 j } : 1 ≤ i < j ≤ M } S 2 = { C 2 1 } , . . . , { C 2 N } ∪ {{ C 2 i , C 2 j } : 1 ≤ i < j ≤ N } This leads to many-to-many alignment where at most two chunks are combined to align with two other chunks. For iSTS task submission, we restrict our experiments to this setting (since this worked well for the iSTS task), but can relax sets S 1 and S 2 to cover combinations of 3 or more chunks. For ef- ficiency , it should be possible to consider a subset of chunks based on adjacency information, existence of a dependenc y using dependenc y parsing techniques. S im ( S 1 , S 2 ) , the similarity score, that measures de- sirability of aligning concat ( S 1 ) with concat ( S 2 ) , plays an important role in finding the optimal solu- tion for the monolingual alignment task. W e com- pute this similarity score by taking the maximum of similarity scores obtained from a subset of features F1, F2, F3, F8, F10 and F11 gi ven in T able 1 as follo ws: max ( F 1 , F 2 , F 3 , F 8 , F 10 , F 11) . During implementation, the weighting term, α ( S 1 , S 2 ) is set as a function of the cardinality of S 1 and cardinality of S 2 to ensure aligning fewer individual chunks (for instance, single alignment tends to increase objec- ti ve function value more due to more aligned pairs, since similarity scores are normalized to lie between -1 and 1) does not get an undue advantage over mul- tiple alignment. This is a hyper-parameter whose v alue is set using simple grid search. W e solve the actual ILP optimization problem using PuLP (Mitchell et al., 2011), a python toolkit for linear programming. Our system achiev ed the best align- ment score for headlines datasets in the gold chunks track. 2.2 T ype Prediction Module W e use a supervised approach for multiclass classi- fication based on the training data of 2016 and that of previous years (for some submitted runs) to learn the similarity type between aligned pair of chunks based on v arious features deriv ed from the chunk text. W e train a one-vs-rest random forest classi- fier (Pedregosa et al., 2011) with various features mentioned in T able 1. W e perform normalization on the input phrases as a preprocessing step before extracting features for classification. Normalisation step includes v arious heuristic steps to conv ert simi- lar words to the same form, for example ‘USA ’ and ‘US’ were mapped to ‘U.S.A ’. Empirical results sug- gested that features F1, F2, F3, F5, F7, F8, F9, F12 along with unigram and bigram features gi ve good accuracy with decision tree classifier . Feature vec- tor normalisation is done before training and pre- diction. W e note that our type classification mod- ule performed well for the answer-students dataset, while it did not generalize as well for the headlines and images. W e are exploring other features to im- prov e performance on these datasets as future work. 2.3 Score Prediction Module Similar to type classifier , we designed the Score classifier to do multiclass classification using one- vs-rest random forest classifier (Pedregosa et al., 2011). Each score 1-5 is considered as a class. ‘0’ score is assigned by default for ‘not-aligned’ chunks. W ord normalization (US, USA, U.S.A are mapped to U.S.A string) is performed as a prepro- cessing step. Features F1, F2, F3, F5, F7, F8, F9, F12 along with unigram and bigram features (refer T able 1) were used in training the multi-class clas- sifier . Feature normalization was performed to im- prov e results. Our score classifier works well on all datasets. The system achiev ed highest score on the gold-chunks track for answer-students dataset and T able 1: Feature Extraction as used in v arious modules of iSTS system No. Featur e Name Description F1 Common W ord Count v 1 wor ds = { words1 from sentence 1 } v 2 wor ds = { words2 from sentence 2 } feature value = {| v 1 w ords ∩ v 2 wor ds |} 0 . 5 ∗ ( sentence 1 leng th + sentence 2 length ) F2 W ordnet Synonym Count v 1 = { words1 } ∪ { wordnet synsets, similar tos, hypernms and hyponyms of w ords in sentence 1 } v 2 = { words2 } ∪ { wordnet synsets, similar tos, hypernms and hyponyms of w ords in sentence 2 } feature value = | v 1 ∩ v 2 | 0 . 5 ∗ ( sentence 1 leng th + sentence 2 length ) F3 W ordnet Antonym Count v 1 wor ds = { words1 } , v 1 anto = { wordnet antonyms of words in sentence 1 } v 2 wor ds = { words2 } , v 2 anto = { wordnet antonyms of words in sentence 2 } feature value = {| v 1 w ords ∩ v 2 anto |} + {| v 2 − wor ds ∩ v 1 anto |} 0 . 5 ∗ ( sentence 1 leng th + sentence 2 length ) F4 W ordnet IsHyponym & IsHypernym v 1 syn = { synonyms of words in sentence 1 } , v 1 hyp = { hypo { /hyper } nyms of words in v1 syn } v 2 syn = { synonyms of words in sentence 2 } , v 2 hyp = { hypo { /hyper } nyms of words in v2 syn } feature value = 1 if | v 1 sy n ∩ v 2 hyp | ≥ 1 F5 W ordnet Path Similarity v 1 syn = { synonyms of words in sentence 1 } v 2 syn = { synonyms of words in sentence 2 } feature value = { P w 1 .path similar ity ( w 2) } ( sentence 1 leng th + sentence 2 length ) , w 1 ∈ v 1 syn, w 2 ∈ v 2 syn F6 Has Number feature value = 1 if phrase contains a number F7 Is Negation feature value = 1 if one phrase contains a ’not’ or ’n’ t’ or ’nev er’ and other phrase does not contain those terms. F8 Edit Score v 1 = words in sentence 1 v 2 = words in sentence 2 value = P [max(1 − E ditDistance ( w 1 ,w 2) ( max ( len ( sentence 1) ,len ( sentence 2)) ) , ∀ w 2 ∈ v 2] ∀ w 1 ∈ v 1 . feature value = value sentence 1 leng th For phrasal score, sum editscore of sentence 1 words with the closest sentence 2 w ords. Compute the av erage over scores for words in source. F9 PPDB Similarity v 1 = words in sentence 1 v 2 = words in sentence 2 feature value = P [ ppdb similarity { w 1 , w 2 } ] , w 1 ∈ v 1 , w 2 ∈ v 2 F10 W2V Similarity v 1 = words in sentence 1, v 1 vec = P word2vec embedding { w1 } , w1 ∈ v1 v 2 = words in sentence 2, v 2 vec = P word2vec embedding { w2 } , w2 ∈ v2 feature value = cosine distance ( v 1 v ec, v 2 v ec ) F11 Bigram Similarity v 1 = bigrams in sentence 1, v 2 = bigrams in sentence 2, feature value = cosine distance ( v 1 , v 2) F12 Length Difference feature value = len ( sentence 1) − len ( sentence 2) headlines dataset and is within 2% of the top score for all other datasets. 2.4 System Chunks T rack: Chunking Module When gold chunks are not given, we perform an additional chunking step. W e use two methods for chunking: (1) With OpenNLP Chunker(Apache, 2010) (2) With stanford-core-nlp (Manning et al., 2014) API for generating parse trees and using the chunklink (Buchholz, 2000) tool for chunking based on the parse trees. For chunking, we do preprocessing to remov e punctuations unless the punctuation is space sepa- rated (therefore constitutes an independent word). W e also con vert unicode characters to ascii charac- ters. Output of chunker is further post-processed to combine each single preposition phrase with the pre- ceding phrase. W e noted that the OpenNLP chun- ker ignored last word of a sentence, in which case, we concatenated the last word as a separate chunk. In the case of chunking based on stanford-core-nlp parser , we noted that in sev eral instances, particu- larly in the student answer dataset, a conjunction such as ‘and’ was consistently being separated into an independent chunk in most cases, and therefore improv ed chunking can be realized by potentially combining chunks around a conjunction. These pro- cessing heuristics are based on observ ations from gold chunks data. W e observ e that quality of chunk- ing has a huge impact on the o verall score in system chunks track. As future work, we are exploring ways to improv e the chunking with custom algorithms. 3 Experimental Results In this section, we present our results, in both the gold standard and the system chunks tracks. W e sub- mitted 3 runs for each track. In gold chunks trac k , T able 2: Gold Chunks Images RunName Align T ype Score T+S Rank IIScNLP R2 0.8929 0.5247 0.8231 0.5088 15 IIScNLP R3 0.8929 0.505 0.8264 0.4915 17 IIScNLP R1 0.8929 0.5015 0.8285 0.4845 19 UWB R3 0.8922 0.6867 0.8408 0.6708 1 UWB R1 0.8937 0.6829 0.8397 0.6672 2 T able 3: Gold Chunks headlines RunName Align T ype Score T+S Rank IIScNLP R2 0.9134 0.5755 0.829 0.5555 16 IIScNLP R1 0.9144 0.5734 0.82 0.5509 18 IIScNLP R3 0.9144 0.567 0.8206 0.5405 19 Inspire R1 0.8194 0.7031 0.7865 0.696 1 T able 4: Gold Chunks Answer Students RunName Align T ype Score T+S Rank IIScNLP R1 0.8684 0.6511 0.8245 0.6385 1 IIScNLP R2 0.8684 0.627 0.8263 0.6167 4 IIScNLP R3 0.8684 0.6511 0.8245 0.6385 2 V -Rep R2 0.8785 0.5823 0.7916 0.5799 8 T able 5: Gold Chunks Ov erall RunName Images Headline Answer Mean Rank Student IISCNLP r2 0.5088 0.5555 0.6167 0.560 13 IIScNLP R1 0.4845 0.5509 0.6385 0.558 14 IIScNLP R3 0.4915 0.5405 0.6385 0.557 15 UWB R1 0.6672 0.6212 0.6248 0.637 1 T able 6: System Chunks Images RunName Align T ype Score T+S Rank IIScNLP R2 0.8459 0.4993 0.777 0.4872 9 IIScNLP R3 0.8335 0.4862 0.7654 0.4744 11 IIScNLP R1 0.8335 0.4862 0.7654 0.4744 10 DTSim R3 0.8429 0.6276 0.7813 0.6095 1 Fbk-Hlt-Nlp R1 0.8427 0.5655 0.7862 0.5475 5 T able 7: System Chunks Headlines RunName Alignment T ype Score T+S Rank IIScNLP R2 0.821 0.508 0.7401 0.4919 9 IIScNLP R1 0.8105 0.4888 0.723 0.4686 10 IIScNLP R3 0.8105 0.4944 0.721 0.4685 11 DTSim R2 0.8366 0.5605 0.7595 0.5467 1 DTSim R3 0.8376 0.5595 0.7586 0.5446 2 T able 8: System Chunks Answer Students RunName Align T ype Score T+S Rank IIScNLP R3 0.7563 0.5604 0.71 0.5451 2 IIScNLP R1 0.756 0.5525 0.71 0.5397 5 IIScNLP R2 0.7449 0.5317 0.6995 0.5198 6 Fbk-Hlt-Nlp R3 0.8166 0.5613 0.7574 0.5547 1 Fbk-Hlt-Nlp R1 0.8162 0.5479 0.7589 0.542 3 T able 9: System Chunks Ov erall RunName Image Headline Answer Mean Rank Student IISCNLP-R2 0.4872 0.4919 0.5198 0.499 8 IISCNLP-R3 0.4744 0.4685 0.5451 0.496 9 IISCNLP-R1 0.4744 0.4686 0.5397 0.494 10 DTSim R3 0.6095 0.5446 0.5029 0.552 1 all three runs used the same algorithm, with different training data for the supervised prediction of type and score. While, in system chunks track, we sub- mitted different algorithm and data combination for v arious runs. Detailed run information follows: – Gold Chunks - Run 1 uses training data from 2015+2016 for the headlines and images dataset and 2016 data for answer-students dataset. – Gold Chunks - Run 2 uses training data of all datasets combined from 2015 and 2016 for headlines and images and 2016 data for answer-students. – Gold Chunks - Run 3 uses 2016 training data alone for each dataset. – System Chunks - Run 1 uses OpenNLP chunker with supervised training of type and score with data of all datasets combined for years 2015,2016. – System Chunks - Run 2 we use chunker based on stanford nlp parser and chunklink with training data of all datasets combined for years 2015,2016. – System Chunks - Run 3 , we use the OpenNLP chunker , with training data of 2016 alone. Results of our system compared to the best per- forming systems in each track are listed in T a- bles 2-9. In both gold and system chunks track, run2 performs best o wing to more data during train- ing. Our system performed well for the answer - students dataset owing to our edit-distance feature that enables handling noisy data without any pre- processing for spelling correction. Our alignment score is best or close to the best in the gold chunks track, thus validating that our nov el and simple ap- proach based on ILP can be used for high qual- ity monolingual multiple alignment at the chunk le vel. Our system took only 5.2 minutes for a sin- gle threaded ex ecution on a Xeon 2420, 6 core sys- tem for the headlines dataset. Therefore, our tech- nique is fast to execute. W e observe that the qual- ity of chunking has a huge impact on alignment and thereby the final score. W e are actively ex- ploring other chunking strategies that could improv e results. Code for our alignment module is a vail- able at https://github.com/lavanyats/ iMATCH.git 4 Conclusion and Future W e have proposed a system for Interpretable Se- mantic T extual Similarity (task 2- Semev al 2016) (Agirre et al., 2016). W e introduce a novel mono- lingual alignment algorithm iMA TCH for multiple- alignment at the chunk le vel based on Integer Lin- ear Programming(ILP) that leads to the best align- ment score in sev eral cases. Our system uses nov el features to capture dataset properties. For example, we designed edit distance based feature for answer- students dataset which had considerable number of spelling mistakes. This feature helped our system perform well on the noisy data of test set without any preprocessing in the form of spelling-correction. As future work, we are acti vely exploring features to improve our classification accuracy for type clas- sification, which could help us improve out mean score. Some exploration in the techniques for simul- taneous alignment and chunking could significantly boost the performance in sys-chunk track. Acknowledgment W e thank Prof. Partha Pratim T alukdar, IISc for guidance during this research. References [Agirre et al.2015] Eneko Agirre, Aitor Gonzalez-Agirre, Inigo Lopez-Gazpio, Montse Maritxalar , German Rigau, and Larraitz Uria. 2015. Ubc: Cubes for english semantic textual similarity and supervised ap- proaches for interpretable sts. In Pr oceedings of the 9th International W orkshop on Semantic Evaluation (SemEval 2015) , pages 178–183, Denv er , Colorado, June. Association for Computational Linguistics. [Agirre et al.2016] Eneko Agirre, Aitor Gonzalez-Agirre, Inigo Lopez-Gazpio, Montse Maritxalar , German Rigau, and Larraitz Uria. 2016. Seme val-2016 task 2: Interpretable semantic textual similarity . In Pro- ceedings of the 10th International W orkshop on Se- mantic Evaluation (SemEval 2016) , San Diego, Cal- ifornia, June. [Apache2010] Apache. 2010. Opennlp. [Banjade et al.2015] Rajendra Banjade, Nobal Bikram Niraula, Nabin Maharjan, V asile Rus, Dan Stefanescu, Mihai Lintean, and Dipesh Gautam. 2015. Nerosim: A system for measuring and interpreting semantic tex- tual similarity . In Pr oceedings of the 9th International W orkshop on Semantic Evaluation (SemEval 2015) , pages 164–171, Den ver , Colorado, June. Association for Computational Linguistics. [Bodrumlu et al.2009] T ugba Bodrumlu, Ke vin Knight, and Sujith Ra vi. 2009. A ne w objectiv e function for word alignment. In Pr oceedings of the W orkshop on Inte ger Linear Pr ogramming for Natur al Langaug e Pr ocessing , ILP ’09, pages 28–35, Stroudsbur g, P A, USA. Association for Computational Linguistics. [Buchholz2000] Sabine Buchholz. 2000. Chunklink perl script. http://ilk.uvt.nl/team/sabine/chunklink/README.html. [H ¨ anig et al.2015] Christian H ¨ anig, Robert Remus, and Xose de la Puente. 2015. Exb themis: Extensi ve feature extraction from word alignments for seman- tic textual similarity . In Pr oceedings of the 9th Inter- national W orkshop on Semantic Evaluation (SemEval 2015) , pages 264–268, Den ver , Colorado, June. Asso- ciation for Computational Linguistics. [Kuhn and Y aw1955] H. W . Kuhn and Bryn Y aw . 1955. The Hungarian method for the assignment pr ob- lem . Nav al Research Logistics Quarterly 2: 8397. doi:10.1002/nav .3800020109. [lien Maxe Anne V ilnat2011] Houda Bouamor Aur lien Maxe Anne V ilnat. 2011. Monolingual Alignment by Edit Rate Computation on Sentential P araphrase P airs . A CL. [Manning et al.2014] Christopher D. Manning, Mihai Surdeanu, John Bauer, Jenn y Finkel, Steven J. Bethard, and David McClosky . 2014. The Stanford CoreNLP natural language processing toolkit. In As- sociation for Computational Linguistics (A CL) System Demonstrations , pages 55–60. [Md Arafat Sultan and Summer2014] Stev en Bethard Md Arafat Sultan and T amara Summer . 2014. Back to basics for Monolingual Alignment, Exploiting wor d Similarity and Contextual Evidence . A CL. [Md Arafat Sultan and Summer2015] Stev en Bethard Md Arafat Sultan and T amara Summer . 2015. F eatur e-Rich T wo-Stage Logistic Re gr ession for Monolingual Alignment . EMNLP . [Mitchell et al.2011] Mitchell, Stuart Michael OSulliv an, and Iain Dunning. 2011. Pulp: a linear programming toolkit for python. The Uni versity of Auckland, Auck- land, New Zealand, http://www . optimization-online. org/DB-FILE/2011/09/3178. [Nemhauser and W olsey1988] Geor ge L. Nemhauser and Laurence A. W olsey . 1988. Integ er and combinatorial optimization . W iley . ISBN 978-0-471-82819-8. [Pedregosa et al.2011] F . Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. W eiss, V . Dubour g, J. V anderplas, A. P assos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay . 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Resear ch , 12:2825–2830. [Snov er et al.2009] Matthew G. Snov er , Nitin Madnani, Bonnie Dorr , and Richard Schw artz. 2009. TER- Plus: paraphr ase, semantic, and alignment enhance- ments to T ranslation Edit Rate. Machine T ranslation 23.2-3 (2009): 117-127. [Y ao and Durme2015] X Y ao and B V an Durme. 2015. A Lightweight and High P erformance Monolingual W ord Aligner: J acana based on CRF Semi-Markov Phrase- based Monolingual Alignment . EMNLP .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment