ILP 기반 다중 청크 정렬로 해석 가능한 의미 유사도 구현
본 논문은 인터프리터블 의미 텍스트 유사도(iSTS) 과제에서 청크 수준의 정렬과 유사도 유형·점수 예측을 수행하는 시스템을 제안한다. 핵심은 정수선형계획법(ILP)으로 다중(비연속) 청크 정렬을 찾는 iMATCH 알고리즘이며, 유형·점수 예측은 랜덤 포레스트 기반 다중 클래스 분류기로 구현한다. 실험 결과 iMATCH는 정렬 정확도에서 대부분의 경쟁 시스템을 앞서며, 실행 시간도 매우 짧다.
저자: Lavanya Sita Tekumalla, Sharmistha
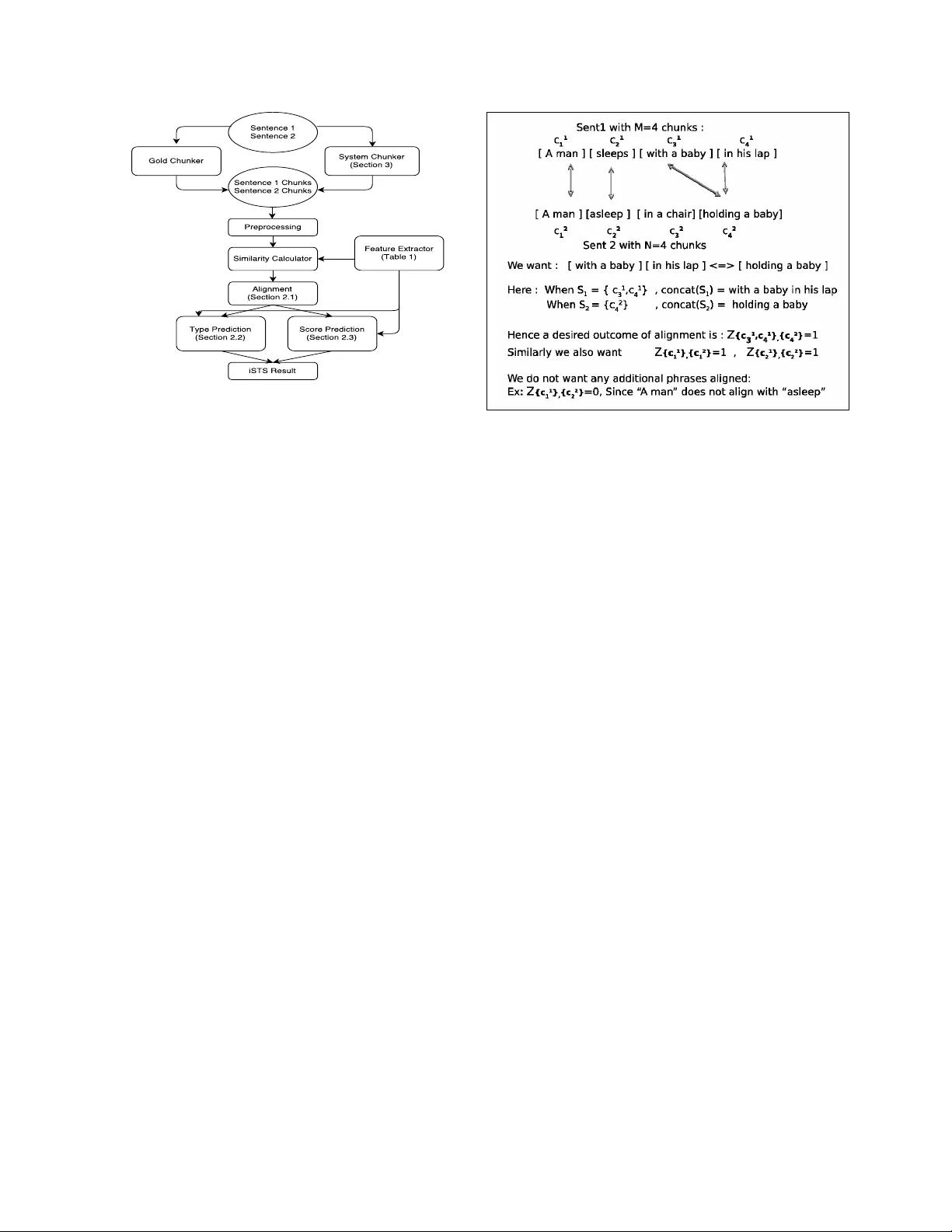
이 논문은 인터프리터블 의미 텍스트 유사도(iSTS) 과제에서 청크 수준의 정렬과 그에 따른 유사도 유형·점수 예측을 수행하는 전체 시스템을 제안한다. iSTS는 기존 STS와 달리 텍스트를 의미 단위인 청크로 분할하고, 각 청크 쌍에 대해 의미적 유사도와 관계 유형을 제공함으로써 결과를 해석 가능하게 만든다.
시스템은 크게 세 부분으로 구성된다. 첫 번째는 “iMATCH”라는 ILP 기반 청크 정렬 모듈이다. 입력 문장은 각각 M, N개의 청크(C₁, C₂)로 나뉘며, 각 청크는 1‑청크 혹은 2‑청크 조합으로 묶일 수 있다. 모든 가능한 비어 있지 않은 청크 부분집합 S₁⊆C₁, S₂⊆C₂에 대해 이진 변수 Z_{S₁,S₂} 를 정의하고, 목표 함수는 Z에 각 청크 쌍의 유사도 Sim(S₁,S₂)와 가중치 α(S₁,S₂)를 곱한 값을 합산한다. 제약식은 한 청크가 여러 정렬에 동시에 포함되지 않도록 Σ Z ≤ 1 로 제한한다. 이때 Sim은 12개의 특징(F1~F12) 중 의미적 연관성을 가장 잘 나타내는 F1, F2, F3, F8, F10, F11의 최대값을 사용한다. α는 정렬된 청크 수에 따라 조정되는 하이퍼파라미터이며, 변수 수를 현실적으로 관리하기 위해 두 청크까지의 조합만 허용한다. ILP는 파이썬 PuLP 라이브러리를 이용해 최적화한다.
두 번째는 유형 예측 모듈이다. 정렬된 청크 쌍에 대해 EQUI(동등), OPPO(반대) 등 6가지 관계 유형을 다중 클래스 문제로 정의하고, 랜덤 포레스트(one‑vs‑rest) 분류기를 학습한다. 특징으로는 단어 공통 수(F1), WordNet 기반 동의어·반의어(F2, F3), 경로 유사도(F5), 부정 여부(F7), 편집 거리(F8), PPDB·Word2Vec·빅그램 유사도(F9~F11) 등을 사용한다. 전처리 단계에서 “USA”와 “U.S.A.” 같은 표기를 통일해 노이즈를 감소시켰다.
세 번째는 점수 예측 모듈이다. 0~5 점을 클래스라 보고 동일한 랜덤 포레스트 구조와 특징을 적용한다. ‘0’ 점은 정렬되지 않은 청크에 자동 부여한다.
골드 청크 트랙에서는 이미 제공된 청크를 그대로 사용했으며, 시스템 청크 트랙에서는 청크 추출을 위해 OpenNLP와 Stanford CoreNLP 기반 두 파이프라인을 적용했다. OpenNLP는 전치사 구문을 앞 청크와 결합하고, Stanford 파서는 구문 트리에서 chunklink를 이용해 청크를 생성한다. 두 파이프라인 모두 구두점 제거, 유니코드→ASCII 변환, 전치사·접속사 처리 등 휴리스틱을 적용해 청크 품질을 높였다.
실험 결과, iMATCH는 정렬 점수에서 대부분의 경쟁 시스템을 앞섰다. 골드 청크 트랙에서 헤드라인 데이터는 정렬 점수 0.9134, 전체 점수 0.829를 기록했으며, 답변‑학생 데이터에서는 전체 점수 0.8245로 1위를 차지했다. 시스템 청크 트랙에서도 iMATCH 기반 런2가 평균 점수 0.560 ~ 0.545 수준으로 상위권에 위치했다. 특히 답변‑학생 데이터는 철자 오류가 많았음에도 편집 거리 기반 특징(F8) 덕분에 별도 교정 없이 높은 점수를 얻었다.
시간 효율성도 뛰어나 헤드라인 데이터 한 세트를 5.2분(6코어 Xeon 2420)만에 처리했으며, 이는 실시간 혹은 대규모 적용 가능성을 시사한다. 코드가 공개된 점은 재현성과 확장성을 크게 향상시킨다.
향후 연구 방향으로는 (1) 청크 조합을 3개 이상으로 확장해 보다 복잡한 의미 관계를 포착, (2) 의존 구문 정보를 활용해 변수 수를 동적으로 감소시키는 효율적인 ILP 모델 설계, (3) 유형·점수 예측에 더 풍부한 신경망 기반 특징을 도입해 일반화 성능을 향상시키는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기