A Minimalistic Approach to Sum-Product Network Learning for Real Applications
Sum-Product Networks (SPNs) are a class of expressive yet tractable hierarchical graphical models. LearnSPN is a structure learning algorithm for SPNs that uses hierarchical co-clustering to simultaneously identifying similar entities and similar fea…
Authors: Viktoriya Krakovna, Moshe Looks
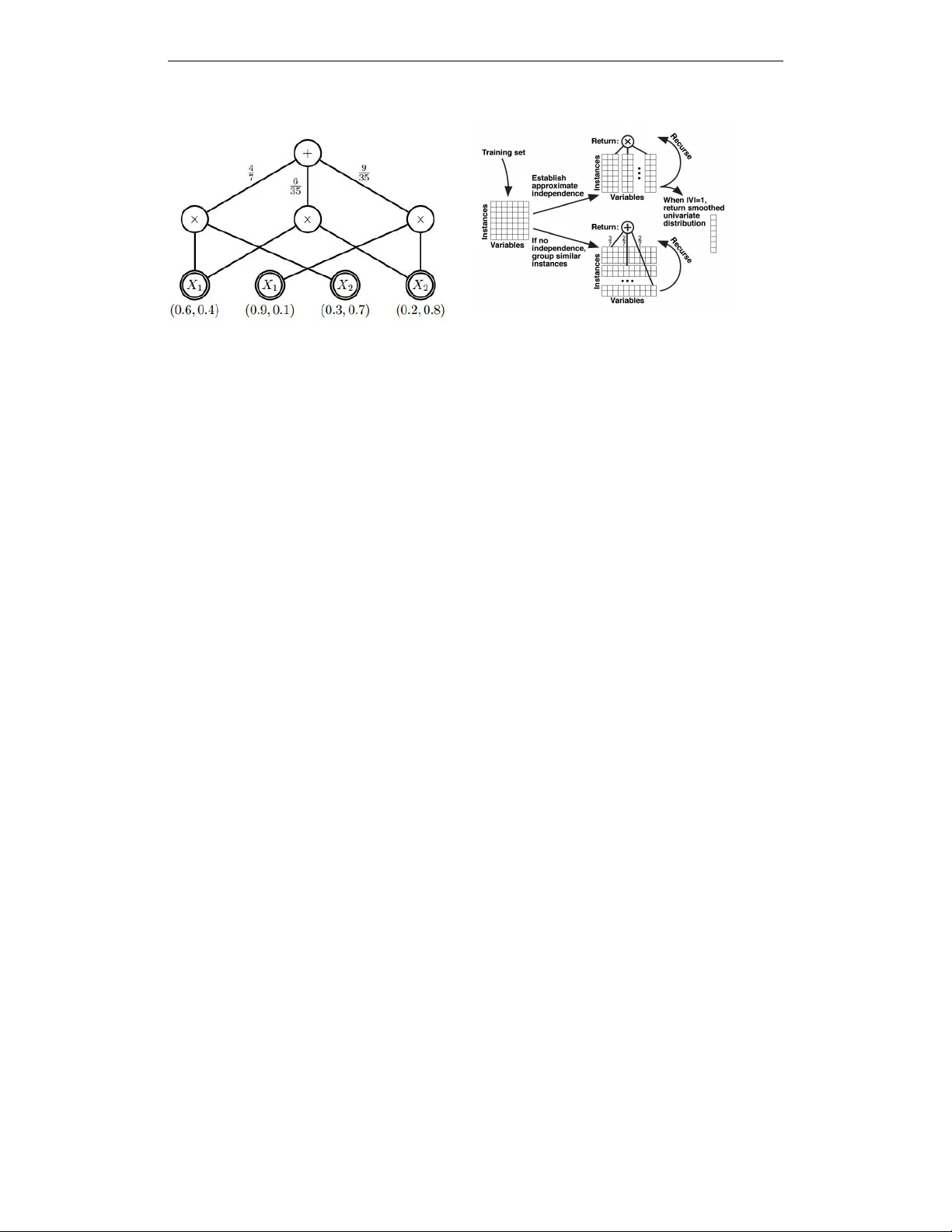
W orkshop track - ICLR 2016 A M I N I M A L I S T I C A P P R O A C H T O S U M - P RO D U C T N E T - W O R K L E A R N I N G F O R R E A L A P P L I C A T I O N S V iktoriya Krakovna Department of Statistics, Harvard Uni v ersity vkrakovna@fas.harvard.edu Moshe Looks Google madscience@google.com A B S T R AC T Sum-Product Networks (SPNs) are a class of expressi ve yet tractable hierarchical graphical models. LearnSPN is a structure learning algorithm for SPNs that uses hierarchical co-clustering to simultaneously identifying similar entities and simi- lar features. The original LearnSPN algorithm assumes that all the variables are discrete and there is no missing data. W e introduce a practical, simplified version of LearnSPN, MiniSPN, that runs faster and can handle missing data and hetero- geneous features common in real applications. W e demonstrate the performance of MiniSPN on standard benchmark datasets and on two datasets from Google’ s Knowledge Graph exhibiting high missingness rates and a mix of discrete and continuous features. 1 I N T RO D U C T I O N The Sum-Product Netw ork (SPN) [Poon & Domingos, 2011] is a tractable and interpretable deep model. An advantage of SPNs over other graphical models such as Bayesian Networks is that they allow ef ficient exact inference in linear time with network size. An SPN represents a multiv ari- ate probability distribution with a directed acyclic graph consisting of sum nodes (clusters over instances), product nodes (partitions over features), and leaf nodes (univ ariate distributions over features), as shown in Figure 1. The standard algorithms for learning SPN structure assume discrete data with no missingness, and mostly test on the same set of benchmark data sets that satisfy these criteria [Rooshenas & Lowd, 2014]. This is not a reasonable assumption when dealing with messy data sets in real applications. The Google Kno wledge Graph (KG) is a semantic network of facts, based on Freebase [Bollacker et al., 2008], used to generate Knowledge Panels in Google Search. KG data is quite heterogeneous, with a lot of it missing, since much more is kno wn about some entities in the graph than others. High missingness rates can also w orsen the impact of discretizing continuous v ariables before doing structure learning, which results in losing more of the already scarce cov ariance information. Applications like the KG are common, and there is a need for an SPN learning algorithm that can handle this kind of data. In this paper , we present MiniSPN, a simplification of a state-of-the-art SPN learning algorithm that improves its applicability , performance and speed. W e demonstrate the performance of MiniSPN on KG data and on standard benchmark data sets. 2 V A R I A T I O N O N T H E L E A R N S P N A L G O R I T H M LearnSPN [Gens & Domingos, 2013] is a greedy algorithm that performs co-clustering by recur- siv ely partitioning variables into approximately independent sets and partitioning the training data into clusters of similar instances, as sho wn in Figure 2. The variable and instance partitioning steps are applied to data slices (subsets of instances and v ariables) produced by previous steps. The variable partition step uses pairwise independence tests on the variables, and the approximately independent sets are the connected components in the resulting dependency graph. The instance clustering step uses a nai ve Bayes mixture model for the clusters, where the v ariables in each cluster are assumed independent. The clusters are learned using hard EM with restarts, av oiding o verfitting using an exponential prior on the number of clusters. The splitting process continues until the data 1 W orkshop track - ICLR 2016 Figure 1: Example of an SPN structure (figure from Zhao et al. [2015]) Figure 2: Recursiv e partitioning process in the LearnSPN algorithm (figure from Gens & Domingos [2013]) slice has too fe w instances to test for independence, at which point all the v ariables in that slice are considered independent. The end result is a tree-structured SPN. The standard LearnSPN algorithm assumes that all the variables are discrete and there is no missing data. Hyperparameter values for the cluster penalty and the independence test critical value are determined using grid search. The clustering step seems unnecessarily comple x, in v olving a penalty prior , EM restarts, and h yperparameter tuning. It is by far the most complicated part of the algorithm in a way that seems dif ficult to justify , and lik ely the most time-consuming due to the restarts and hyperparameter tuning. W e propose a v ariation on LearnSPN called MiniSPN that handles missing data, performs lazy discretization of continuous data in variable partition step, simplifies the model in the instance clustering step, and does not require hyperparameter search. W e simplify the nai ve Bayes mixture model in the instance clustering step by attempting a split into two clusters at any gi ven point, and eliminating the cluster penalty prior , which results in a more greedy approach than in LearnSPN that does not require restarts or hyperparameter tuning. This seems like a natural choice of simplification - an extension of the greedy approach used at the top lev el of the LearnSPN algorithm. W e compare a partition into univ ariate leav es to a mixture of two partitions into uni variate lea ves (generated using hard EM), and the split succeeds if the tw o-cluster version has higher validation set likelihood. If the split succeeds, we apply it to each of the two resulting data slices, and only mov e on to a variable partition step after the clustering step fails. The greedy approach is similar to the one used in the SPN-B method [V ergari et al., 2015], which howe v er alternates between variable and instance splits by default, thus building e ven deeper SPNs. In the variable partition step, we perform an independence test using the subset of rows where both variables are not missing, and conclude independence if the number of such ro ws is belo w threshold. W e apply binary binning to each continuous variable, using its median in the data slice as a cutof f. W e compare to the “P areto” algorithm, pre viously used for learning SPN models in KG, inspired by the work of Grosse et al. [2012]. It produces a Pareto-optimal set of models, trading of f between degrees of freedom and v alidation set log likelihood score. At each iteration, production rules are randomly applied to add partition and mixture splits to the models in the current model set, and the ne w models are added to the model set. If a model in the model set has both lo wer degrees of freedom and higher log likelihood score than another model, the inferior model is remov ed from the set. The algorithm returns the model from the P areto model set with the highest v alidation log likelihood. W e also compare to a hybrid method, with the Pareto algorithm initialized by MiniSPN. 3 S U M M A RY O F E X P E R I M E N T S W e use two data sets from the Knowledge Graph People collection. In the KG Professions data set, most of the variables are boolean indicators of whether each person belongs to a particular profession. There are 83 boolean v ariables and 4 continuous variables. In the KG Dates data set, there are 14 continuous v ariables representing dates of life e vents for each person and their spouse(s), 2 W orkshop track - ICLR 2016 T able 1: A verage log lik elihood and runtime comparison on KG data sets (best performing methods are shown in bold). T est set log likelihood Runtime (seconds) Data set Pareto Hybrid MiniSPN Pareto Hybrid MiniSPN Professions-10K -10.2 -6.2 -6.09 5.3 3.7 0.4 Professions-100K -6.61 -6.53 -6.44 72 131 7.2 Dates-10K -8.66 -8.53 -8.68 1.7 2.4 0.26 Dates-100K -17.1 -16.7 -16.5 29 566 5.4 T able 2: A verage log likelihood and runtime comparison on literature data sets (best performing methods are shown in bold). T est set log likelihood Runtime (seconds) Data set Pareto Hybrid MiniSPN LearnSPN Pareto Hybrid MiniSPN LearnSPN NL TCS -6.33 -6.03 -6.12 -6.1 4.8 35 1.4 60 MSNBC -6.54 -6.4 -6.61 -6.11 61 212 5.6 2400 KDDCup -2.17 -2.13 -2.14 -2.21 152 2080 23 400 Plants -17.3 -13.1 -13.2 -13 28 780 11 160 Audio -41.9 -39.9 -40 -40.5 28 556 12 955 Jester -54.6 -52.9 -53 -53.4 13 193 6.7 1190 Netflix -59.5 -56.7 -56.8 -57.3 27 766 14 1230 Accidents -40.4 -32.5 -32.6 -30.3 31 1140 18 330 Retail -11.1 -11 -11.1 -11.09 25 63 7.3 100 Pumsb-star -40.8 -28.4 -28.3 -25 47 1100 22 350 DN A -98.1 -91.5 -93.9 -89 6.3 45 3 300 K osarek -11.2 -10.8 -10.9 -11 90 537 22 200 MSW eb -10.7 -9.94 -10.1 -10.26 75 572 34 260 Book -35.1 -34.7 -34.7 -36.4 83 181 32 350 EachMovie -55 -52.3 -52.2 -52.5 62 218 22 220 W ebKB -161 -155 -155 -162 37 169 38 900 Reuters-52 -92 -85.2 -84.7 -86.5 76 656 95 2900 Newsgroup -156 -152 -152 -160.5 181 1190 139 28000 BBC -258 -250 -249 -250 33 123 42 900 Ad -52.3 -49.5 -49.2 -22 58 92 50 300 with around 95% of the data missing. W e use subsets of 10000 and 100000 instances from each of these data sets, and randomly split the data sets into a training and test set. On the KG data sets, we compare MiniSPN, Pareto and Hybrid algorithms. W e were not able to apply the standard LearnSPN algorithm on these data sets, since they contain missing data. T able 1 shows log likelihood performance on the test set and runtime performance. MiniSPN does better than Pareto, both in terms of log likelihood and runtime. Hybrid performs comparably to MiniSPN, but is usually the slo west of the three. W e use 20 benchmark data sets from the literature (exactly the same ones used in the LearnSPN paper [Gens & Domingos, 2013]) to compare the performance of MiniSPN with the standard Learn- SPN algorithm. W e are particularly interested in the ef fect of MiniSPN’ s simple two-cluster instance split relati ve to the more complex instance split with the exponential prior and EM restarts used in the standard LearnSPN. T able 2 sho ws log likelihood performance on the test set and runtime per- formance. Like on the KG data, we find that MiniSPN uniformly outperforms Pareto, and performs similarly to Hybrid and LearnSPN but runs much faster (on the most time-intensi ve data set, Ne ws- group, MiniSPN takes 2 minutes while LearnSPN takes 8 hours). 4 C O N C L U S I O N Sum-product networks hav e been receiving increasing attention from researchers due to their expres- siv eness, ef ficient inference and interpretability , and many learning algorithms hav e been de veloped in the past few years. While recent developments have mostly focused on improving performance on benchmark data sets, our v ariation on a classical learning algorithm is simple yet has a large impact on usability , by improving speed and making it possible to apply to messy real data sets. 3 W orkshop track - ICLR 2016 R E F E R E N C E S Kurt Bollack er , Colin Evans, Pra veen P aritosh, Tim Sturge, and Jamie T aylor . Freebase: a collab- orativ ely created graph database for structuring human kno wledge. In Pr oceedings of the 2008 A CM SIGMOD international confer ence on Management of data , pp. 1247–1250. A CM, 2008. Robert Gens and Pedro M. Domingos. Learning the Structure of Sum-Product Networks. In Pr o- ceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16-21 J une 2013 , pp. 873–880, 2013. Roger B. Grosse, Ruslan Salakhutdinov , W illiam. T . Freeman, and Joshua B. T enenbaum. Exploit- ing compositionality to explore a large space of model structures. In Proceedings of the 28th Confer ence on Uncertainty in AI (U AI) , 2012. Hoifung Poon and Pedro M. Domingos. Sum-Product Netw orks: A Ne w Deep Architecture. In U AI 2011, Pr oceedings of the T wenty-Se venth Confer ence on Uncertainty in Artificial Intelligence, Bar celona, Spain, J uly 14-17, 2011 , pp. 337–346, 2011. Amirmohammad Rooshenas and Daniel Lowd. Learning Sum-Product Netw orks with Direct and Indirect V ariable Interactions. In T ony Jebara and Eric P . Xing (eds.), Pr oceedings of the 31st International Confer ence on Machine Learning (ICML-14) , pp. 710–718. JMLR W orkshop and Conference Proceedings, 2014. Antonio V ergari, Nicola Di Mauro, and Floriana Esposito. Simplifying, Regularizing and Strength- ening Sum-Product Network Structure Learning. In Machine Learning and Knowledge Discov- ery in Databases - Eur opean Conference , ECML PKDD 2015, P orto, P ortugal, September 7-11, 2015, Pr oceedings, P art II , pp. 343–358, 2015. Han Zhao, Mazen Melibari, and Pascal Poupart. On the Relationship between Sum-Product Net- works and Bayesian Networks. In Pr oceedings of the 32nd International Confer ence on Machine Learning, ICML 2015, Lille, F rance, 6-11 J uly 2015 , pp. 116–124, 2015. 4
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment