실제 응용을 위한 미니멀리즘 SPN 학습 접근법
MiniSPN은 기존 LearnSPN 알고리즘을 단순화하여 결측치와 연속형 변수를 동시에 처리할 수 있게 만든 구조 학습 방법이다. 빠른 실행 속도와 높은 로그가능도 성능을 보이며, 구글 지식 그래프(KG)와 여러 벤치마크 데이터셋에서 기존 방법들을 능가한다.
저자: Viktoriya Krakovna, Moshe Looks
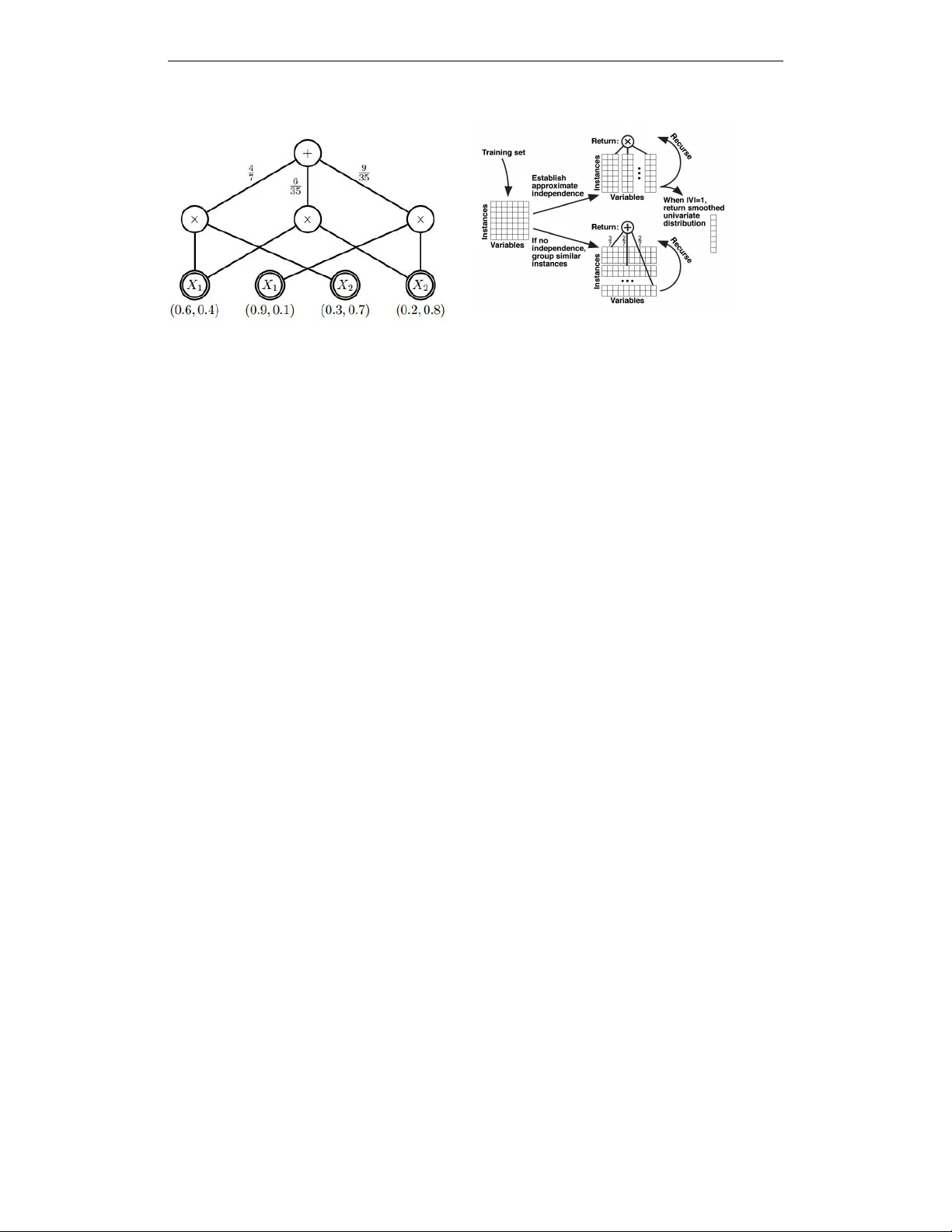
본 논문은 Sum‑Product Network(SPN)의 구조 학습을 위한 기존 대표 알고리즘인 LearnSPN의 한계를 짚고, 실제 응용 환경에서 마주치는 데이터 특성을 반영한 간소화 버전인 MiniSPN을 제안한다. SPN은 합과 곱 노드, 그리고 변수별 단변량 분포를 갖는 리프 노드로 구성된 DAG 형태의 확률 모델로, 트리 구조라면 선형 시간에 정확한 추론이 가능하다는 장점이 있다. 그러나 기존 LearnSPN은 (1) 모든 변수가 이산형이라는 가정, (2) 결측치가 없다는 전제, (3) 인스턴스 클러스터링 단계에서 복잡한 베이즈 혼합 모델과 EM 재시작, 그리고 클러스터 수에 대한 지수형 페널티와 하이퍼파라미터 튜닝을 필요로 한다는 제약이 있다. 이러한 제약은 실제 산업 데이터, 특히 구글 지식 그래프(KG)와 같이 높은 결측률과 연속·이산 혼합 특성을 가진 데이터에 적용하기 어렵게 만든다.
MiniSPN은 세 가지 주요 개선점을 통해 이러한 제약을 해소한다. 첫째, 변수 파티션 단계에서 결측치를 가진 행을 제외하고 쌍별 독립성 검정을 수행한다. 두 변수 사이에 동시에 관측된 샘플 수가 사전에 정의된 임계값 이하이면 두 변수를 독립으로 간주한다. 이는 결측치가 많아도 신뢰할 수 있는 독립성 판단을 가능하게 한다. 둘째, 연속형 변수는 각 데이터 슬라이스마다 중앙값을 기준으로 이진 구간화(바이너리 빈)하여 이산형처럼 다룬다. 이렇게 “lazy discretization”을 적용하면 별도의 전처리 없이 연속형 변수를 SPN 구조에 포함시킬 수 있다. 셋째, 인스턴스 클러스터링을 두 클러스터 분할에 한정하고, 클러스터 수에 대한 사전 페널티를 완전히 제거한다. 구체적으로 현재 슬라이스에 대해 하드 EM을 이용해 두 개의 베이즈 혼합 모델을 학습하고, 검증 데이터 로그가능도가 향상되면 분할을 확정한다. 이 greedy 전략은 EM 재시작과 하이퍼파라미터 탐색을 없애며, LearnSPN이 사용하는 복잡한 지수형 페널티와 비교해 구현이 단순하고 실행 속도가 빠르다.
알고리즘 흐름은 다음과 같다. (1) 전체 데이터에서 변수 독립성 그래프를 만든 뒤, 연결 요소를 찾아 변수 파티션을 수행한다. (2) 각 변수 파티션에 대해 두 클러스터 인스턴스 분할을 시도한다. (3) 분할이 성공하면 두 슬라이스 각각에 대해 다시 변수 파티션을 재귀적으로 적용한다. 슬라이스가 충분히 작아 독립성 검정이 불가능하거나 두 클러스터 분할이 로그가능도 향상을 보이지 않을 때 재귀를 멈춘다.
실험은 두 개의 KG 데이터셋(Professions와 Dates)과 20개의 공개 벤치마크 데이터셋을 대상으로 수행되었다. KG Professions 데이터는 83개의 이진 변수와 4개의 연속 변수, Dates 데이터는 14개의 연속 변수와 약 95% 결측률을 가지고 있다. MiniSPN은 이들 데이터에 대해 Pareto 기반 알고리즘보다 로그가능도가 높고 실행 시간이 현저히 짧았다. 특히 Professions‑100K에서는 MiniSPN이 7.2초에 학습을 마친 반면 Pareto는 72초, Hybrid는 131초가 소요되었다.
벤치마크 실험에서는 MiniSPN이 LearnSPN과 거의 동일한 테스트 로그가능도를 기록했으며, 가장 큰 NewsGroup 데이터셋에서는 MiniSPN이 2분 내에 학습을 마친 반면 LearnSPN은 8시간이 걸렸다. 이는 MiniSPN이 복잡한 두‑클러스터 혼합 모델 대신 단순한 greedy 분할을 사용해도 충분히 좋은 근사 해를 제공한다는 것을 보여준다. 또한 하이퍼파라미터 탐색이 필요 없으므로 실무에서 바로 적용하기 용이하다.
결론적으로 MiniSPN은 (1) 결측치와 연속형 변수를 자연스럽게 처리하고, (2) 구조 학습 과정을 크게 단순화하며, (3) 실행 속도를 크게 개선함으로써 실제 대규모, 잡다한 데이터에 SPN을 적용하려는 연구자와 엔지니어에게 실용적인 솔루션을 제공한다. 향후 연구에서는 더 정교한 연속형 변수 이산화 방법이나, 다중 클러스터 분할을 선택적으로 도입하는 방안을 탐색함으로써 MiniSPN의 표현력을 더욱 향상시킬 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기