Deep Reinforcement Learning in Large Discrete Action Spaces
Being able to reason in an environment with a large number of discrete actions is essential to bringing reinforcement learning to a larger class of problems. Recommender systems, industrial plants and language models are only some of the many real-wo…
Authors: Gabriel Dulac-Arnold, Richard Evans, Hado van Hasselt
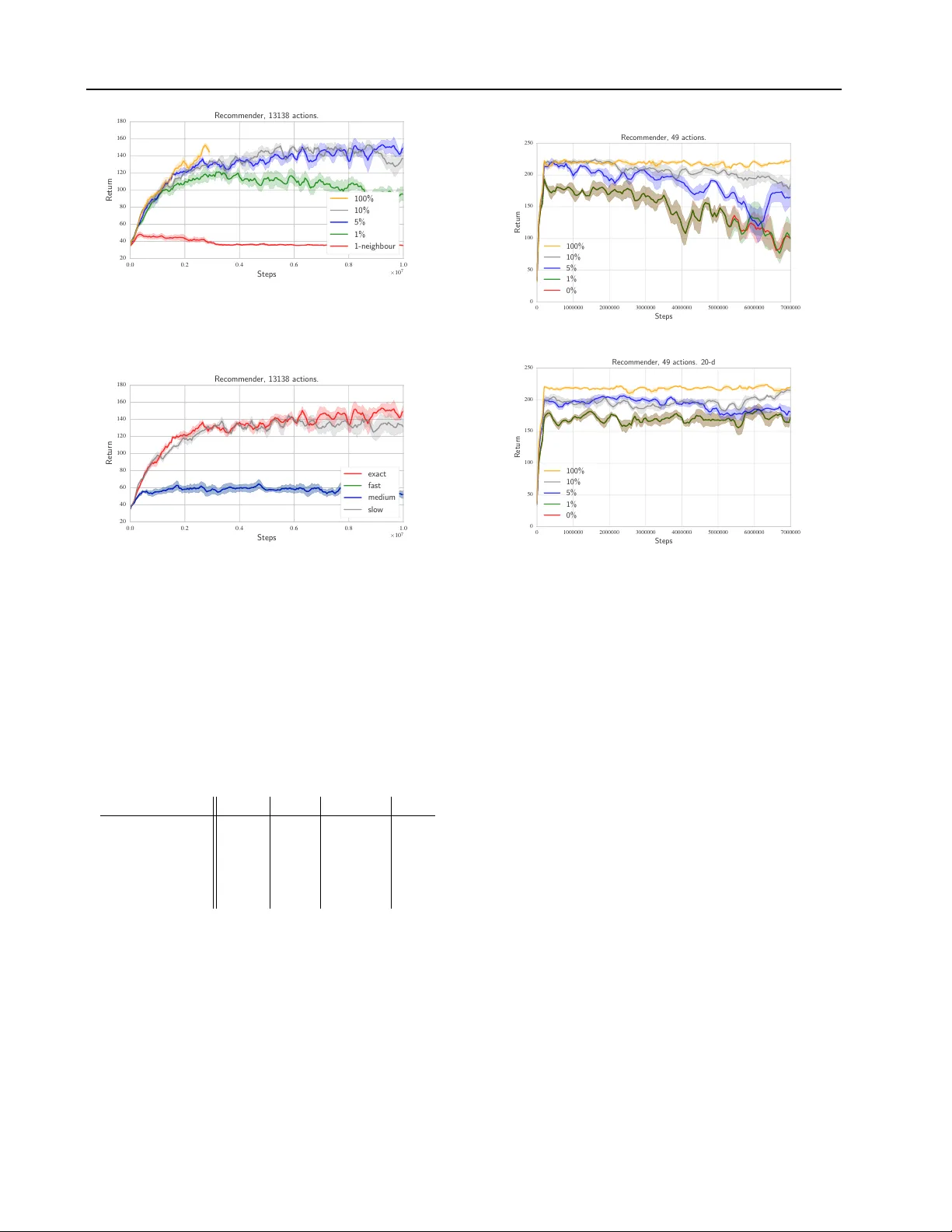
Deep Reinf or cement Learning in Lar ge Discrete Action Spaces Gabriel Dulac-Arnold*, Richard Evans*, Hado van Hasselt, Peter Sunehag, Timoth y Lillicrap, Jonathan Hunt, Timoth y Mann, Theophane W eber , Thomas Degris, Ben Coppin D U L AC A R N O L D @ G O O G L E . C O M Google DeepMind Abstract Being able to reason in an en vironment with a large number of discrete actions is essential to bringing reinforcement learning to a larger class of problems. Recommender systems, industrial plants and language models are only some of the many real-world tasks in volving large numbers of discrete actions for which current methods are difficult or e ven often impossible to apply . An ability to generalize ov er the set of actions as well as sub-linear complexity relative to the size of the set are both necessary to handle such tasks. Current approaches are not able to provide both of these, which motiv ates the work in this paper . Our proposed approach leverages prior information about the actions to embed them in a continuous space upon which it can general- ize. Additionally , approximate nearest-neighbor methods allo w for logarithmic-time lookup com- plexity relativ e to the number of actions, which is necessary for time-wise tractable training. This combined approach allows reinforcement learn- ing methods to be applied to large-scale learn- ing problems previously intractable with current methods. W e demonstrate our algorithm’ s abili- ties on a series of tasks having up to one million actions. 1. Introduction Advanced AI systems will likely need to reason with a large number of possible actions at every step. Recommender systems used in large systems such as Y ouT ube and Ama- zon must reason about hundreds of millions of items every second, and control systems for large industrial processes may hav e millions of possible actions that can be applied at e very time step. All of these systems are fundamentally *Equal contribution. reinforcement learning ( Sutton & Barto , 1998 ) problems, but current algorithms are dif ficult or impossible to apply . In this paper , we present a ne w policy architecture which operates efficiently with a large number of actions. W e achiev e this by leveraging prior information about the ac- tions to embed them in a continuous space upon which the actor can generalize. This embedding also allows the pol- icy’ s complexity to be decoupled from the cardinality of our action set. Our policy produces a continuous action within this space, and then uses an approximate nearest- neighbor search to find the set of closest discrete actions in logarithmic time. W e can either apply the closest ac- tion in this set directly to the en vironment, or fine-tune this selection by selecting the highest valued action in this set relativ e to a cost function. This approach allows for gen- eralization ov er the action set in logarithmic time, which is necessary for making both learning and acting tractable in time. W e begin by describing our problem space and then detail our policy architecture, demonstrating how we can train it using policy gradient methods in an actor-critic framew ork. W e demonstrate the effecti veness of our policy on various tasks with up to one million actions, but with the intent that our approach could scale well beyond millions of actions. 2. Definitions W e consider a Markov Decision Process (MDP) where A is the set of discrete actions, S is the set of discrete states, P : S × A × S → R is the transition probability distrib ution, R : S × A → R is the re ward function, and γ ∈ [0 , 1] is a discount factor for future rew ards. Each action a ∈ A corresponds to an n -dimensional vector , such that a ∈ R n . This vector provides information related to the action. In the same manner , each state s ∈ S is a vector s ∈ R m . The return of an episode in the MDP is the discounted sum of rewards received by the agent during that episode: R t = P T i = t γ i − t r ( s i , a i ) . The goal of RL is to learn a policy π : S → A which maximizes the expected return ov er all episodes, E [ R 1 ] . The state-action value function Q π ( s , a ) = E [ R 1 | s 1 = s , a 1 = a , π ] is the expected re- Deep Reinfor cement Learning in Large Discrete Action Spaces turn starting from a given state s and taking an action a , following π thereafter . Q π can be expressed in a recursiv e manner using the Bellman equation: Q π ( s , a ) = r ( s , a ) + γ X s 0 P ( s 0 | s , a ) Q π ( s 0 , π ( s 0 )) . In this paper, both Q and π are approximated by parametrized functions. 3. Problem Description There are two primary families of policies often used in RL systems: value-based, and actor-based policies. For value-based policies, the policy’ s decisions are directly conditioned on the v alue function. One of the more com- mon examples is a polic y that is greedy relati ve to the value function: π Q ( s ) = arg max a ∈A Q ( s , a ) . (1) In the common case that the value function is a parame- terized function which takes both state and action as input, | A | e valuations are necessary to choose an action. This quickly becomes intractable, especially if the parameter- ized function is costly to ev aluate, as is the case with deep neural networks. This approach does, howe ver , hav e the desirable property of being capable of generalizing over actions when using a smooth function approximator . If a i and a j are similar , learning about a i will also inform us about a j . Not only does this make learning more efficient, it also allo ws v alue-based policies to use the action features to reason about previously unseen actions. Unfortunately , ex ecution complexity gro ws linearly with | A | which ren- ders this approach intractable when the number of actions grows significantly . In a standard actor -critic approach, the policy is explicitly defined by a parameterized actor function: π θ : S → A . In practice π θ is often a classifier-lik e function approxima- tor , which scale linearly in relation to the number of ac- tions. Howe ver , actor-based architectures avoid the com- putational cost of ev aluating a likely costly Q-function on ev ery action in the arg max in Equation ( 1 ). Nev ertheless, actor-based approaches do not generalize over the action space as naturally as v alue-based approaches, and cannot extend to pre viously unseen actions. Sub-linear comple xity relati ve to the action space and an ability to generalize over actions are both necessary to handle the tasks we interest ourselves with. Current ap- proaches are not able to provide both of these, which moti- vates the approach described in this paper . STATE A C T O R C R I T I C PROTO ACTION ARGMAX ACTION EMBEDDING K-NN ACTION Figure 1. W olpertinger Architecture 4. Proposed A pproach W e propose a ne w policy architecture which we call the W olpertinger architecture. This architecture av oids the heavy cost of ev aluating all actions while retaining general- ization ov er actions. This policy builds upon the actor-critic ( Sutton & Barto , 1998 ) framework. W e define both an ef fi- cient action-generating actor, and utilize the critic to refine our actor’ s choices for the full policy . W e use multi-layer neural networks as function approximators for both our ac- tor and critic functions. W e train this policy using Deep Deterministic Policy Gradient ( Lillicrap et al. , 2015 ). The W olpertinger policy’ s algorithm is described fully in Algorithm 1 and illustrated in Figure 1 . W e will detail these in the following sections. Algorithm 1 W olpertinger Policy State s pre viously receiv ed from environment. ˆ a = f θ π ( s ) { Recei ve proto-action from actor . } A k = g k ( ˆ a ) { Retrieve k approximately closest actions. } a = arg max a j ∈A k Q θ Q ( s , a j ) Apply a to en vironment; receiv e r, s 0 . 4.1. Action Generation Our architecture reasons over actions within a continuous space R n , and then maps this output to the discrete action Deep Reinfor cement Learning in Large Discrete Action Spaces set A . W e will first define: f θ π : S → R n f θ π ( s ) = ˆ a . f θ π is a function parametrized by θ π , mapping from the state representation space R m to the action representation space R n . This function provides a proto-action in R n for a given state, which will likely not be a valid action, i.e. it is likely that ˆ a / ∈ A . Therefore, we need to be able to map from ˆ a to an element in A . W e can do this with: g : R n → A g k ( ˆ a ) = k arg min a ∈A | a − ˆ a | 2 . g k is a k -nearest-neighbor mapping from a continuous space to a discrete set 1 . It returns the k actions in A that are closest to ˆ a by L 2 distance. In the exact case, this lookup is of the same complexity as the arg max in the value-function deriv ed policies described in Section 3 , but each step of e valuation is an L 2 distance instead of a full value-function ev aluation. This task has been extensiv ely studied in the approximate nearest neighbor literature, and the lookup can be performed in an approximate manner in logarithmic time ( Muja & Lo we , 2014 ). This step is de- scribed by the bottom half of Figure 1 , where we can see the actor network producing a proto-action, and the k -nearest neighbors being chosen from the action embedding. 4.2. Action Refinement Depending on how well the action representation is struc- tured, actions with a low Q -value may occasionally sit clos- est to ˆ a ev en in a part of the space where most actions ha ve a high Q -value. Additionally , certain actions may be near each other in the action embedding space, but in certain states they must be distinguished as one has a particularly low long-term value relati ve to its neighbors. In both of these cases, simply selecting the closest element to ˆ a from the set of actions generated previously is not ideal. T o av oid picking these outlier actions, and to generally im- prov e the finally emitted action, the second phase of the algorithm, which is described by the top part of Figure 1 , refines the choice of action by selecting the highest-scoring action according to Q θ Q : π θ ( s ) = arg max a ∈ g k ◦ f θ π ( s ) Q θ Q ( s , a ) . (2) This equation is described more explicitly in Algorithm 1 . It introduces π θ which is the full W olpertinger policy . The parameter θ represents both the parameters of the action generation element in θ π and of the critic in θ Q . 1 For k = 1 this is a simple nearest neighbor lookup. As we demonstrate in Section 7 , this second pass makes our algorithm significantly more rob ust to imperfections in the choice of action representation, and is essential in mak- ing our system learn in certain domains. The size of the generated action set, k , is task specific, and allo ws for an explicit trade-of f between policy quality and speed. 4.3. T raining with Policy Gradient Although the architecture of our policy is not fully differ - entiable, we argue that we can nevertheless train our polic y by following the policy gradient of f θ π . W e will first con- sider the training of a simpler policy , one defined only as ˜ π θ = g ◦ f θ π . In this initial case we can consider that the policy is f θ π and that the ef fects of g are a deterministic aspect of the en vironment. This allows us to maintain a standard polic y gradient approach to train f θ π on its output ˆ a , ef fectively interpreting the effects of g as en vironmen- tal dynamics. Similarly , the arg max operation in Equation ( 2 ) can be seen as introducing a non-stationary aspect to the en vironmental dynamics. 4.4. W olpertinger T raining The training algorithm’ s goal is to find a parameterized policy π θ ∗ which maximizes its expected return ov er the episode’ s length. T o do this, we find a parametrization θ ∗ of our policy which maximizes its expected return over an episode: θ ∗ = arg max θ E [ R 1 | π θ ] . W e perform this optimization using Deep Deterministic Policy Gradient (DDPG) ( Lillicrap et al. , 2015 ) to train both f θ π and Q θ Q . DDPG draws from two stability- inducing aspects of Deep Q-Networks ( Mnih et al. , 2015 ) to extend Deterministic Policy Gradient ( Silver et al. , 2014 ) to neural network function approximators by introducing a replay b uffer ( Lin , 1992 ) and target networks. DPG is sim- ilar to work introduced by NFQCA ( Hafner & Riedmiller , 2011 ) and leverages the gradient-update originally intro- duced by ADHDP ( Prokhorov et al. , 1997 ). The goal of these algorithms is to perform policy iteration by alternativ ely performing policy ev aluation on the cur- rent polic y with Q-learning, and then improving upon the current policy by follo wing the policy gradient. The critic is trained from samples stored in a replay buf fer ( Mnih et al. , 2015 ). Actions stored in the replay buffer are generated by π θ π , but the policy gradient ∇ a Q θ Q ( s , a ) is taken at ˆ a = f θ π ( s ) . This allows the learning algorithm to lev erage the otherwise ignored information of which action was actually executed for training the critic, while taking the policy gradient at the actual output of f θ π . The target action in the Q-update is generated by the full policy π θ and not simply f θ π . A detailed description of the algorithm is a vailable in the Deep Reinfor cement Learning in Large Discrete Action Spaces supplementary material. 5. Analysis T ime-complexity of the abov e algorithm scales linearly in the number of selected actions, k . W e will see that in prac- tice though, increasing k beyond a certain limit does not provide increased performance. There is a diminishing re- turns aspect to our approach that provides significant per- formance gains for the initial increases in k , but quickly renders additional performance gains marginal. Consider the following simplified scenario. For a random proto-action ˆ a , each nearby action has a probability p of being a bad or broken action with a low value of Q ( s, ˆ a ) − c . The values of the remaining actions are uniformly drawn from the interval [ Q ( s, ˆ a ) − b, Q ( s, ˆ a ) + b ] , where b ≤ c . The probability distrib ution for the value of a chosen action is therefore the mixture of these two distrib utions. Lemma 1. Denote the closest k actions as inte gers { 1 , . . . , k } . Then in the scenario as described above, the expected value of the maximum of the k closest actions is E max i ∈{ 1 ,...k } Q ( s, i ) | s, ˆ a = Q ( s, a ) + b − p k ( c − b ) − 2 b k + 1 1 − p k +1 1 − p The highest value an action can ha ve is Q ( s, ˆ a ) + b . The best action within the k -sized set is thus, in expectation, p k ( c − b ) + 2 b k +1 1 − p k +1 1 − p smaller than this value. The first term is in O ( p k ) and decreases exponentially with k . The second term is in O ( 1 k +1 ) . Both terms decrease a relativ ely lar ge amount for each additional action while k is small, b ut the marginal returns quickly diminish as k gro ws larger . This property is also observ able in experiments in Section 7 , notably in Figures 6 & 7 . Using 5% or 10% of the maximal number of actions the performance is similar to when the full action set is used. Using the remaining ac- tions would result in relati vely small performance benefits while increasing computational time by an order of magni- tude. The proof to Lemma 1 is av ailable in the supplementary material. 6. Related W ork There has been limited attention in the literature with re- gards to large discrete action spaces within RL. Most prior work has been concentrated on factorizing the action space into binary subspaces. Generalized value functions were proposed in the form of H-value functions ( Pazis & Parr , 2011 ), which allow for a policy to e valuate log ( | A | ) bi- nary decisions to act. This learns a factorized value func- tion from which a greedy policy can be deriv ed for each subspace. This amounts to performing log( | A | ) binary op- erations on each action-selection step. A similar approach was proposed which leverages Error- Correcting Output Code classifiers (ECOCs) ( Dietterich & Bakiri , 1995 ) to factorize the policy’ s action space and al- low for parallel training of a sub-policy for each action sub- space ( Dulac-Arnold et al. , 2012 ) . In the ECOC-based ap- proach case, a policy is learned through Rollouts Classifi- cation Policy Iteration ( Lagoudakis & Parr , 2003 ), and the policy is defined as a multi-class ECOC classifier . Thus, the policy directly predicts a binary action code, and then a nearest-neighbor lookup is performed according to Ham- ming distance. Both these approaches effecti vely factorize the action space into log( | A | ) binary subspaces, and then reason about these subspaces independently . These approaches can scale to very large action spaces, howe ver , they require a binary code representation of each action, which is difficult to de- sign properly . Additionally , the generalized value-function approach uses a Linear Program and explicitly stores the value function per state, which prev ents it from generaliz- ing ov er a continuous state space. The ECOC-based ap- proach only defines an action producing policy and does not allow for refinement with a Q -function. These approaches cannot naturally deal with discrete ac- tions that have associated continuous representations. The closest approach in the literature uses a continuous-action policy gradient method to learn a policy in a continuous action space, and then apply the nearest discrete action ( V an Hasselt et al. , 2009 ). This is in principle similar to our approach, but was only tested on small problems with a uni-dimensional continuous action space (at most 21 dis- crete actions) and a low-dimensional observ ation space. In such small discrete action spaces, selecting the nearest dis- crete action may be sufficient, but we show in Section 7 that a more comple x action-selection scheme is necessary to scale to larger domains. Recent work extends Deep Q-Networks to ‘unbounded’ ac- tion spaces ( He et al. , 2015 ), effecti vely generating action representations for an y action the en vironment provides, and picking the action that provides the highest Q. Ho w- ev er, in this setup, the environment only ev er provides a small (2-4) number of actions that need to be ev aluated, hence they do not have to explicitly pick an action from a large set. This policy architecture has also been leveraged by the au- thors for learning to attend to actions in MDPs which take in multiple actions at each state (Slate MDPs) ( Sunehag et al. , 2015 ). Deep Reinfor cement Learning in Large Discrete Action Spaces 7. Experiments W e ev aluate the W olpertinger agent on three en vironment classes: Discretized Continuous Control, Multi-Step Plan- ning, and Recommender Systems. These are outlined be- low: 7.1. Discretized Continuous En vironments T o ev aluate how the agent’ s performance and learning speed relate to the number of discrete actions we use the MuJoCo ( T odorov et al. , 2012 ) physics simulator to simu- late the classic continuous control tasks cart-pole (). Each dimension d in the original continuous control action space is discretized into i equally spaced values, yielding a dis- crete action space with | A | = i d actions. In cart-pole swing-up, the agent must balance a pole at- tached to a cart by applying force to the cart. The pole and cart start in a random downward position, and a reward of +1 is recei ved if the pole is within 5 degrees of vertical and the cart is in the middle 10% of the track, otherwise a re- ward of zero is received. The current state is the position and v elocity of the cart and pole as well as the length of the pole. The environment is reset after 500 steps. W e use this en vironment as a demonstration both that our agent is able to reason with both a small and large num- ber of actions efficiently , especially when the action repre- sentation is well-formed. In these tasks, actions are repre- sented by the force to be applied on each dimension. In the cart-pole case, this is along a single dimension, so actions are represented by a single number . 7.2. Multi-Step Plan En vironment Choosing amongst all possible n -step plans is a general large action problem. For example, if an en vironment has i actions av ailable at each time step and an agent needs to plan n time steps into the future then the number of actions i n is quickly intractable for arg max -based approaches. W e implement a version of this task on a puddle world en vi- ronment, which is a grid world with four cell types: empty , puddle, start or goal. The agent consistently starts in the start square, and a re ward of -1 is gi ven for visiting an empty square, a reward of -3 is giv en for visiting a puddle square, and a re ward of 250 is given and the episode ends if on a goal cell. The agent observes a fixed-size square window surrounding its current position. The goal of the agent is to find the shortest path to the goal that trades off the cost of puddles with distance traveled. The goal is always placed in the bottom right hand cor- ner of the en vironment and the base actions are restricted to moving right or down to guarantee goal discovery with random exploration. The action set is the set of all pos- sible n -length action sequences. W e hav e 2 base actions: { down , right } . This means that en vironments with a plan of length n hav e 2 n actions in total, for n = 20 we have 2 20 ≈ 1 e 6 actions. This environment demonstrates our agent’ s abilities with very large number of actions that are more difficult to dis- cern from their representation, and ha ve less ob vious con- tinuity with regards to their effect on the en vironment com- pared to the MuJoCo tasks. W e represent each action with the concatenation of each step of the plan. There are two possible steps which we represent as either { 0 , 1 } or { 1 , 0 } . This means that a full plan will be a v ector of concatenated steps, with a total length of 2 n . This representation was chosen arbitrarily , but we sho w that our algorithm is nev er- theless able to reason well with it. 7.3. Recommender En vironment T o demonstrate how the agent would perform on a real- world large action space problem we constructed a sim- ulated recommendation system utilizing data from a li ve large-scale recommendation engine. This en vironment is characterized by a set of items to recommend, which cor - respond to the action set A and a transition probability ma- trix W , such that W i,j defines the probability that a user will accept recommendation j giv en that the last item they accepted was item i . Each item also has a reward r asso- ciated with it if accepted by the user . The current state is the item the user is currently consuming, and the previously recommended items do not affect the current transition. At each time-step, the agent presents an item i to the user with action A i . The recommended item is then either ac- cepted by the user (according to the transition probability matrix) or the user selects a random item instead. If the presented item is accepted then the episode ends with prob- ability 0.1, if the item is not accepted then the episode ends with probability 0.2. This has the effect of simulating user patience - the user is more likely to finish their session if they have to search for an item rather than selecting a rec- ommendation. After each episode the en vironment is reset by selecting a random item as the initial en vironment state. 7.4. Evaluation For each environment, we vary the number of nearest neighbors k from k = 1 , which effecti vely ignores the re- ranking step described in Section 4.2 , to k = | A | , which effecti vely ignores the action generation step described in Section 4.1 . For k = 1 , we demonstrate the performance of the nearest-neighbor element of our policy g ◦ f θ π . This is the fastest policy configuration, but as we see in the sec- tion, is not always sufficiently expressi ve. For k = | A | , we demonstrate the performance of a policy that is greedy relativ e to Q , always choosing the true maximizing action Deep Reinfor cement Learning in Large Discrete Action Spaces from A . This gi ves us an upper bound on performance, b ut we will soon see that this approach is often computation- ally intractable. Intermediate v alues of k are ev aluated to demonstrate the performance gains of partial re-ranking. W e also ev aluate the performance in terms of training time and average re ward for full nearest-neighbor search, and three approximate nearest neighbor configurations. W e use FLANN ( Muja & Lo we , 2014 ) with three settings we refer to as ‘Slow’, ‘Medium’ and ‘Fast’. ‘Slow’ uses a hierarchi- cal k-means tree with a branching factor of 16, which corre- sponds to 99% retrieval accuracy on the recommender task. ‘Medium’ corresponds to a randomized K-d tree where 39 nearest neighbors at the leaf nodes are checked. This cor - responds to a 90% retriev al accuracy in the recommender task. ‘Fast’ corresponds to a randomized K-d tree with 1 nearest neighbor at the leaf node checked. This corre- sponds to a 70% retrie val accuracy in the recommender task. These settings were obtained with FLANN’ s auto- tune mechanism. 8. Results In this section we analyze results from our e xperiments with the en vironments described above. 8.1. Cart-Pole The cart-pole task was generated with a discretization of one million actions. On this task, our algorithm is able to find optimal policies. W e ha ve a video available of our final policy with one million actions, k = 1 , and ‘fast’ FLANN lookup here: http://goo.gl/3YFyAE . W e visualize performance of our agent on a one million action cart-pole task with k = 1 and k = 0 . 5% in Figure 2 , using an exact lookup. In the relati vely simple cart-pole task the k = 1 agent is able to conv erge to a good policy . Howe ver , for k = 0 . 5% , which equates to 5,000 actions, training has failed to attain more than 100,000 steps in the same amount of time. 0 500000 1000000 1500000 2000000 2500000 3000000 3500000 Steps − 1 . 2 − 1 . 1 − 1 . 0 − 0 . 9 − 0 . 8 − 0 . 7 − 0 . 6 − 0 . 5 − 0 . 4 Return Ca rtp ole, 1e6 actions, exact lo okup. k=1 k=0.5% Figure 2. Agent performance for various settings of k with exact lookup as a function of steps. W ith 0.5% of neighbors, training time is prohibitiv ely slow and con ver gence is not achiev ed. Figure 3 shows performance as a function of wall-time on the cart-pole task. It presents the performance of agents with v arying neighbor sizes and FLANN settings after the same number of seconds of training. Agents with k = 1 are able to achie ve con vergence after 150,000 seconds whereas k = 5 , 000 (0.5% of actions) trains much more slo wly . 0 50000 100000 150000 200000 250000 300000 350000 400000 W all Time (s) − 1 . 2 − 1 . 1 − 1 . 0 − 0 . 9 − 0 . 8 − 0 . 7 − 0 . 6 − 0 . 5 − 0 . 4 Return Ca rtp ole, 1e6 actions, va rying k and FLANN settings. fast-1 neighb our fast-0.5% neighb ours exact-1 neighb our exact-0.5% neighb ours Figure 3. Agent performance for various settings of k and FLANN as a function of wall-time on one million action cart- pole. W e can see that with 0.5% of neighbors, training time is prohibitiv ely slow . # Neighbors Exact Slow Medium F ast 1 18 2.4 8.5 23 0.5% – 5 , 000 0.6 0.6 0.7 0.7 T able 1. Median steps/second as a function of k & FLANN set- tings on cart-pole. T able 1 display the median steps per second for the train- ing algorithm. W e can see that FLANN is only helpful for k = 1 lookups. Once k = 5 , 000 , all the computation time is spent on e valuating Q instead of finding nearest neighbors. FLANN performance impacts nearest-neighbor lookup negati vely for all settings except ‘fast’ as we are looking for a nearest neighbor in a single dimension. W e will see in the next section that for more action dimensions this is no longer true. 8.2. Puddle W orld W e ran our system on a fixed Puddle W orld map of size 50 × 50 . In our setup the system dynamics are deterministic, our main goal being to show that our agent is able to find appropriate actions amongst a very large set (up to more than one million). T o begin with we note that in the simple case with two actions, n = 1 in Figure ( 4 ) it is difficult to find a stable policy . W e belie ve that this is due to a large number of states producing the same observ ation, which makes a high-frequency policy more dif ficult to learn. As the plans get longer, the policies get significantly better . The best possible score, without puddles, is 150 (50+50 steps of -1, and a final score of 250). Figure ( 5 ) demonstrates performance on a 20-step plan Deep Reinfor cement Learning in Large Discrete Action Spaces 0 500000 1000000 1500000 2000000 2500000 3000000 Step − 500 − 400 − 300 − 200 − 100 0 100 200 Return Puddle W o rld, k=1. n=1 n=3 n=10 n=15 n=20 Figure 4. Agent performance for v arious lengths of plan, a plan of n = 20 corresponds to 2 20 = 1 , 048 , 576 actions. The agent is able to learn faster with longer plan lengths. k = 1 and ‘slow’ FLANN settings are used. Puddle W orld with the number of neighbors k = 1 and k = 52428 , or 5% of actions. In this figure k = | A | is absent as it failed to arriv e to the first ev aluation step. W e can see that in this task we are finding a near optimal polic y while never using the arg max pass of the policy . W e see that ev en our most lossy FLANN setting with no re-ranking con verges to an optimal polic y in this task. As a large num- ber of actions are equiv alent in value, it is not surprising that e ven a very lossy approximate nearest neighbor search returns sufficiently pertinent actions for the task. Experi- ments on the recommender system in Section 8.3 show that this is not always this case. 0 500000 1000000 1500000 2000000 2500000 3000000 Steps 0 20 40 60 80 100 120 140 Return Puddle W o rld, n=20 0% 5% Figure 5. Agent performance for v arious percentages of k in a 20- step plan task in Puddle W orld with FLANN settings on ‘slow’. T able 3 describes the median steps per second during train- ing. In the case of Puddle W orld, we can see that we can get a speedup for equiv alent performance of up to 1,250 times. # Neighbors Exact Medium Fast 1 4.8 119 125 0.5% – 5,242 0.2 0.2 0.2 100% – 1 e 6 0.1 0.1 0.1 T able 2. Median steps/second as a function of k & FLANN set- tings. 8.3. Recommender T ask Experiments were run on 3 different recommender tasks in volving 49 elements, 835 elements, and 13,138 elements. These tasks’ dynamics are quite irregular , with certain ac- tions being good in many states, and certain states requiring a specific action rarely used elsewhere. This has the effect of rendering agents with k = 1 quite poor at this task. Ad- ditionally , although initial exploration methods were purely uniform random with an epsilon probability , to better simu- late the reality of the running system — where state transi- tions are also heavily guided by user choice — we restricted our epsilon e xploration to a likely subset of good actions provided to us by the simulator . This subset is only used to guide exploration; at each step the policy must still choose amongst the full set of actions if not exploring. Learning with uniform exploration conv erges, but in the larger tasks performance is typically 50% of that with guided explo- ration. 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Steps × 10 7 0 100 200 300 400 500 600 700 Return Recommender, 835 actions. 100% 10% 5% 1% 1-neighb our Figure 6. Performance on the 835-element recommender task for varying v alues of k , with exact nearest-neighbor lookup. Figure 6 shows performance on the 835-element task using exact lookup for varying v alues of k as a percentage of the total number of actions. W e can see a clear progression of performance as k is increased in this task. Although not displayed in the plot, these smaller action sizes have much less significant speedups, with k = | A | taking only twice as long as k = 83 (1%). Results on the 13 , 138 element task are visualized in Fig- ures ( 7 ) for varying values of k , and in Figure ( 8 ) with varying FLANN settings. Figure ( 7 ) shows performance for e xact nearest- neighbor lookup and v arying v alues of k . W e note that the agent using all actions (in yellow) does not train as many steps due to slo w training speed. It is training approximately 15 times slower in wall-time than the 1% agent. Figure ( 8 ) shows performance for v arying FLANN settings on this task with a fix ed k at 5% of actions. W e can quickly see both that lower -recall settings significantly impact the performance on this task. Results on the 49-element task with both a 200- Deep Reinfor cement Learning in Large Discrete Action Spaces 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Steps × 10 7 20 40 60 80 100 120 140 160 180 Return Recommender, 13138 actions. 100% 10% 5% 1% 1-neighb our Figure 7. Agent performance for v arious numbers of nearest neighbors on 13k recommender task. T raining with k = 1 failed to learn. 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Steps × 10 7 20 40 60 80 100 120 140 160 180 Return Recommender, 13138 actions. exact fast medium slo w Figure 8. Agent performance for v arious FLANN settings on nearest-neighbor lookups on the 13k recommender task. In this case, fast and medium FLANN settings are equi valent. k = 656 (5%). dimensional and a 20-dimensional representation are pre- sented in Figure 9 using a fixed ‘slow’ setting of FLANN and varying values of k . W e can observe that when using a small number of actions, a more compact representation of the action space can be beneficial for stabilizing con ver - gence. # Neighbors Exact Slow Medium F ast 1 31 50 69 68 1% – 131 23 37 37 37 5% – 656 10 13 12 14 10% – 1,313 7 7.5 7.5 7 100% – 13,138 1.5 1.6 1.5 1.4 T able 3. Median steps/second as a function of k & FLANN set- tings on the 13k recommender task. Results on this series of tasks suggests that our approach can scale to real-world MDPs with large number of actions, but e xploration will remain an issue if the agent needs to learn from scratch. Fortunately this is generally not the case, and either a domain-specific system provides a good starting state and action distribution, or the system’ s dy- namics constrain transitions to a reasonable subset of ac- tions for a giv en states. 0 1000000 2000000 3000000 4000000 5000000 6000000 7000000 Steps 0 50 100 150 200 250 Return Recommender, 49 actions. 100% 10% 5% 1% 0% 0 1000000 2000000 3000000 4000000 5000000 6000000 7000000 Steps 0 50 100 150 200 250 Return Recommender, 49 actions. 20-d 100% 10% 5% 1% 0% Figure 9. Recommender task with 49 actions using 200 dimen- sional action representation (left) and 20-dimensional action rep- resentations (right), for varying values of k and fixed FLANN setting of ‘slow’. The figure intends to sho w general behavior and not detailed values. 9. Conclusion In this paper we introduce a ne w policy architecture able to efficiently learn and act in large discrete action spaces. W e describe ho w this architecture can be trained using DDPG and demonstrate good performance on a series of tasks with a range from tens to one million discrete actions. Architectures of this type giv e the polic y the ability to gen- eralize over the set of actions with sub-linear complexity relativ e to the number of actions. W e demonstrate how con- sidering only a subset of the full set of actions is sufficient in man y tasks and provides significant speedups. Addition- ally , we demonstrate that an approximate approach to the nearest-neighbor lookup can be achie ved while often im- pacting performance only slightly . Future work in this direction would allow the action repre- sentations to be learned during training, thus allowing for actions poorly placed in the embedding space to be mov ed to more appropriate parts of the space. W e also intend to in- vestigate the application of these methods to a wider range of real-world control problems. Deep Reinfor cement Learning in Large Discrete Action Spaces References Dietterich, Thomas G. and Bakiri, Ghulum. Solving multiclass learning problems via error-correcting output codes. Journal of artificial intelligence r esear ch , pp. 263–286, 1995. Dulac-Arnold, Gabriel, Deno yer , Ludovic, Preux, Philippe, and Gallinari, Patrick. Fast reinforcement learning with large action sets using error-correcting output codes for mdp f actorization. In Machine Learning and Knowledge Discovery in Databases , pp. 180–194. Springer , 2012. Hafner , Roland and Riedmiller , Martin. Reinforcement learning in feedback control. Mac hine learning , 84(1- 2):137–169, 2011. He, Ji, Chen, Jianshu, He, Xiaodong, Gao, Jianfeng, Li, Lihong, Deng, Li, and Ostendorf, Mari. Deep reinforce- ment learning with an unbounded action space. arXiv pr eprint arXiv:1511.04636 , 2015. Lagoudakis, Michail and Parr , Ronald. Reinforcement learning as classification: Leveraging modern classifiers. In ICML , volume 3, pp. 424–431, 2003. Lillicrap, T imothy P , Hunt, Jonathan J, Pritzel, Alexander , Heess, Nicolas, Erez, T om, T assa, Y uv al, Silver , David, and Wierstra, Daan. Continuous control with deep re- inforcement learning. arXiv pr eprint arXiv:1509.02971 , 2015. Lin, Long-Ji. Self-improving reactive agents based on re- inforcement learning, planning and teaching. Mac hine learning , 8(3-4):293–321, 1992. Mnih, V olodymyr , Kavukcuoglu, Koray , Silver , David, Rusu, Andrei A, V eness, Joel, Bellemare, Marc G, Grav es, Alex, Riedmiller , Martin, Fidjeland, Andreas K, Ostrovski, Georg, et al. Human-level control through deep reinforcement learning. Natur e , 518(7540):529– 533, 2015. Muja, Marius and Lowe, David G. Scalable nearest neigh- bor algorithms for high dimensional data. P attern Analy- sis and Mac hine Intelligence, IEEE T ransactions on , 36, 2014. Pazis, Jason and Parr , Ron. Generalized value functions for large action sets. In Pr oceedings of the 28th Interna- tional Confer ence on Machine Learning (ICML-11) , pp. 1185–1192, 2011. Prokhorov , Danil V , W unsch, Donald C, et al. Adaptiv e critic designs. Neural Networks, IEEE T ransactions on , 8(5):997–1007, 1997. Silver , David, Lever , Guy , Heess, Nicolas, De gris, Thomas, W ierstra, Daan, and Riedmiller , Martin. Determinis- tic policy gradient algorithms. In Pr oceedings of The 31st International Confer ence on Machine Learning , pp. 387–395, 2014. Sunehag, Peter , Evans, Richard, Dulac-Arnold, Gabriel, Zwols, Y ori, V isentin, Daniel, and Coppin, Ben. Deep reinforcement learning with attention for slate marko v decision processes with high-dimensional states and ac- tions. arXiv pr eprint arXiv:1512.01124 , 2015. Sutton, Richard S and Barto, Andrew G. Reinfor cement learning: An intr oduction , v olume 1. MIT press Cam- bridge, 1998. T odorov , Emanuel, Erez, T om, and T assa, Y uval. Mujoco: A physics engine for model-based control. In Intelli- gent Robots and Systems (IROS), 2012 IEEE/RSJ Inter- national Confer ence on , pp. 5026–5033. IEEE, 2012. V an Hasselt, Hado, W iering, Marco, et al. Using continu- ous action spaces to solve discrete problems. In Neural Networks, 2009. IJCNN 2009. International Joint Con- fer ence on , pp. 1149–1156. IEEE, 2009. A ppendices A. Detailed W olpertinger Algorithm Algorithm 2 describes the full DDPG algorithm with the notation used in our paper, as well as the distinctions be- tween actions from A and prototype actions. The critic is trained from samples stored in a replay buf fer . These samples are generated on lines 9 and 10 of Algorithm 2 . The action a t is sampled from the full W olpertinger pol- icy π θ on line 9. This action is then applied on the en viron- ment on line 10 and the resulting re ward and subsequent state are stored along with the applied action in the replay buf fer on line 11. On line 12, a random transition is sampled from the replay buf fer, and line 13 performs Q-learning by applying a Bell- man backup on Q θ Q , using the tar get network’ s weights for the target Q. Note the target action is generated by the full policy π θ and not simply f θ π . The actor is then trained on line 15 by follo wing the policy gradient: ∇ θ f θ π ≈ E f 0 ∇ θ π Q θ Q ( s , ˆ a ) | ˆ a = f θ ( s ) = E f 0 [ ∇ ˆ a Q θ Q ( s , f θ ( s )) · ∇ θ π f θ π ( s ) | ] . Deep Reinfor cement Learning in Large Discrete Action Spaces Algorithm 2 W olpertinger Training with DDPG 1: Randomly initialize critic network Q θ Q and actor f θ π with weights θ Q and θ π . 2: Initialize target network Q θ Q and f θ π with weights θ Q 0 ← θ Q , θ π 0 ← θ π 3: Initialize g ’ s dictionary of actions with elements of A 4: Initialize replay buf fer B 5: for episode = 1, M do 6: Initialize a random process N for action e xploration 7: Receiv e initial observation state s 1 8: for t = 1, T do 9: Select action a t = π θ ( s t ) according to the current policy and e xploration method 10: Execute action a t and observe rew ard r t and new state s t +1 11: Store transition ( s t , a t , r t , s t +1 ) in B 12: Sample a random minibatch of N transitions ( s i , a i , r i , s i +1 ) from B 13: Set y i = r i + γ · Q θ Q 0 ( s i +1 , π θ 0 ( s i +1 )) 14: Update the critic by minimizing the loss: L ( θ Q ) = 1 N P i [ y i − Q θ Q ( s i , a i )] 2 15: Update the actor using the sampled gradient: ∇ θ π f θ π | s i ≈ 1 N X i ∇ a Q θ Q ( s , ˆ a ) | ˆ a = f θ π ( s i ) · ∇ θ π f θ π ( s ) | s i 16: Update the target netw orks: θ Q 0 ← τ θ Q + (1 − τ ) θ Q 0 θ π 0 ← τ θ π + (1 − τ ) θ π 0 17: end for 18: end for Actions stored in the replay buf fer are generated by π θ π , but the policy gradient ∇ ˆ a Q θ Q ( s , ˆ a ) is taken at ˆ a = f θ π ( s ) . This allows the learning algorithm to lev erage otherwise ignored information of which action was actually ex ecuted for training the critic, while taking the policy gradient at the actual output of f θ π . B. Proof of Lemma 1 Pr oof. W ithout loss of generality we can assume Q ( s, a ) = 1 2 , b = 1 2 and replace c with c 0 = c 2 b , result- ing in an affine transformation of the original setting. W e undo this transformation at the end of this proof to obtain the general result. There is a p probability that an action is ‘bad’ and has v alue − c 0 . If it is not bad, the distrib ution of the v alue of the action is uniform in [ Q ( s, a ) − b, Q 0 ( s, a ) + b ] = [0 , 1] . This implies that the cumulati ve distribution function (CDF) for the value of an action i ∈ { 1 , . . . k } is F ( x ; s, i ) = 0 for x < − c p for x ∈ [ − c, 0) p + (1 − p ) x for x = [0 , 1] 1 for x > 1 . If we select k such actions, the CDF of the maximum of these actions equals the product of the individual CDFs, because the probability that the maximum v alue is smaller that some giv en x is equal to the probability that all of the values is smaller than x , so that the cumulati ve distribution function for F max ( x ; s, a ) = P max i ∈{ 1 ,...k } Q ( s, i ) ≤ x = Y i ∈{ 1 ,...,k } P ( Q ( s, i ) ≤ x ) = Y i ∈{ 1 ,...,k } F ( x ; s, i ) = F ( x ; s, 1) k , where the last step is due to the assumption that the dis- tribution is equal for all k closest actions (it is straightfor - ward to extend this result by making other assumptions, e.g., about how the distribution depends on distance to the selected action). The CDF of the maximum is therefore giv en by F max ( x ; s, a ) = 0 for x < − c 0 p k for x ∈ [ − c 0 , 0) ( p + (1 − p ) x ) k for x ∈ [0 , 1] 1 for x > 1 . Now we can determine the desired e xpected value as E [ max i ∈{ 1 ,...,k } Q ( s, i )] = Z ∞ −∞ x d F max ( x ; s, a ) = p k 1 2 − c 0 + Z 1 0 x d F max ( x ; s, a ) = p k 1 2 − c 0 + [ xF max ( x ; s, a )] 1 0 − Z 1 0 F max ( x ; s, a ) d x = p k 1 2 − c 0 + 1 − Z 1 0 ( p + (1 − p ) x ) k d x = p k 1 2 − c 0 + 1 − 1 1 − p 1 k + 1 ( p + (1 − p ) x ) k +1 1 0 = p k 1 2 − c 0 + 1 − 1 1 − p 1 k + 1 − 1 1 − p 1 k + 1 p k +1 = 1 + p k 1 2 − c 0 − 1 k + 1 1 − p k +1 1 − p , Deep Reinfor cement Learning in Large Discrete Action Spaces where we hav e used R 1 0 x d µ ( x ) = R 1 0 1 − µ ( x ) d x , which can be prov ed by integration by parts. W e can scale back to the arbitrary original scale by subtracting 1 / 2 , multiplying by 2 b and then adding Q ( s, a ) back in, yielding E max i ∈{ 1 ,...,k } Q ( s, i ) = Q ( s, a ) + 2 b 1 + p k 1 2 − c 0 − 1 k + 1 1 − p k +1 1 − p − 1 2 = Q ( s, a ) + b + p k b − p k c − 2 b k + 1 1 − p k +1 1 − p = Q ( s, a ) + b − p k c − b 2 k + 1 1 − p k +1 1 − p − p k
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment