대규모 이산 행동 공간을 위한 심층 강화학습
본 논문은 수백만 개에 달하는 이산 행동을 갖는 환경에서도 효율적으로 작동할 수 있는 강화학습 정책을 제안한다. 행동을 연속 공간에 임베딩하고, 근사 최근접 이웃(k‑NN) 검색을 이용해 로그 시간 복잡도로 최적 행동을 선택함으로써, 행동 일반화와 서브선형 연산을 동시에 달성한다. 실험은 1백만 개 이상의 행동을 가진 여러 과제에서 제안 방법이 기존 기법을 크게 앞선다는 것을 보여준다.
저자: Gabriel Dulac-Arnold, Richard Evans, Hado van Hasselt
본 논문은 “대규모 이산 행동 공간을 가진 강화학습 문제”라는 실용적이면서도 이론적으로 어려운 과제를 다룬다. 전통적인 가치 기반 정책은 Q‑함수를 모든 행동에 대해 평가해야 하므로 |A|가 커질수록 선형 시간 복잡도가 발생한다. 반면, 액터‑크리틱 기반 정책은 직접 행동을 출력하지만, 행동이 이산이므로 출력층이 행동 수에 비례해 커져야 하며, 행동 간 일반화가 어려운 구조적 한계가 있다. 이러한 두 접근법의 단점을 동시에 극복하기 위해 저자들은 ‘Wolpertinger’라는 새로운 정책 아키텍처를 제안한다.
1. **행동 임베딩**
각 이산 행동 a∈A는 사전에 정의된 n‑차원 실수 벡터로 매핑된다. 이 벡터는 행동의 메타데이터(예: 아이템 특성, 제어 파라미터 등)를 포함하며, 유사한 행동끼리 가까운 거리(L2)로 배치된다. 이러한 임베딩은 사전 지식이나 학습된 표현을 활용해 구축될 수 있다.
2. **프로토‑액션 생성**
정책 네트워크 fθπ는 현재 상태 s∈ℝᵐ를 입력으로 받아 연속 공간 ℝⁿ에 ‘프로토‑액션’ ˆa를 출력한다. ˆa는 실제 이산 행동이 아닐 가능성이 크며, 이는 연속적인 정책 그라디언트를 적용할 수 있게 해준다.
3. **근사 최근접 이웃 검색 (k‑NN)**
ˆa와 가장 가까운 k개의 실제 행동을 찾기 위해 근사 최근접 이웃 알고리즘(gₖ)을 사용한다. 저자는 FLANN과 같은 라이브러리를 인용하며, 이 단계의 복잡도가 O(log|A|)임을 강조한다. 이는 수백만 개의 행동을 가진 환경에서도 실시간 선택이 가능함을 의미한다.
4. **Q‑기반 행동 재정렬**
단순히 가장 가까운 행동을 선택하면 임베딩 품질이 낮을 때 성능이 급격히 저하될 수 있다. 따라서 후보 집합 Aₖ에 대해 가치 함수 QθQ(s,a)를 평가하고, 가장 높은 Q값을 가진 행동을 최종 선택한다. 이 과정은 식 (2)와 알고리즘 1에 명시되어 있으며, k의 크기에 따라 성능‑시간 트레이드오프를 조절할 수 있다.
5. **학습 절차**
전체 정책 πθ는 fθπ와 QθQ의 파라미터를 동시에 최적화한다. 저자는 Deep Deterministic Policy Gradient(DDPG)를 기반으로 한 학습 프레임워크를 채택한다. 경험 재플레이 버퍼에 저장된 (s, a, r, s′) 트랜지션을 이용해 QθQ를 TD(Temporal‑Difference) 방식으로 업데이트하고, 정책 그라디언트는 ˆa에 대해 ∇ₐQθQ(s,a) 를 계산한다. 이때 gₖ∘fθπ의 비선형 변환은 환경 동역학의 일부로 간주되어, 표준 정책 그라디언트 이론이 그대로 적용된다.
6. **이론적 분석**
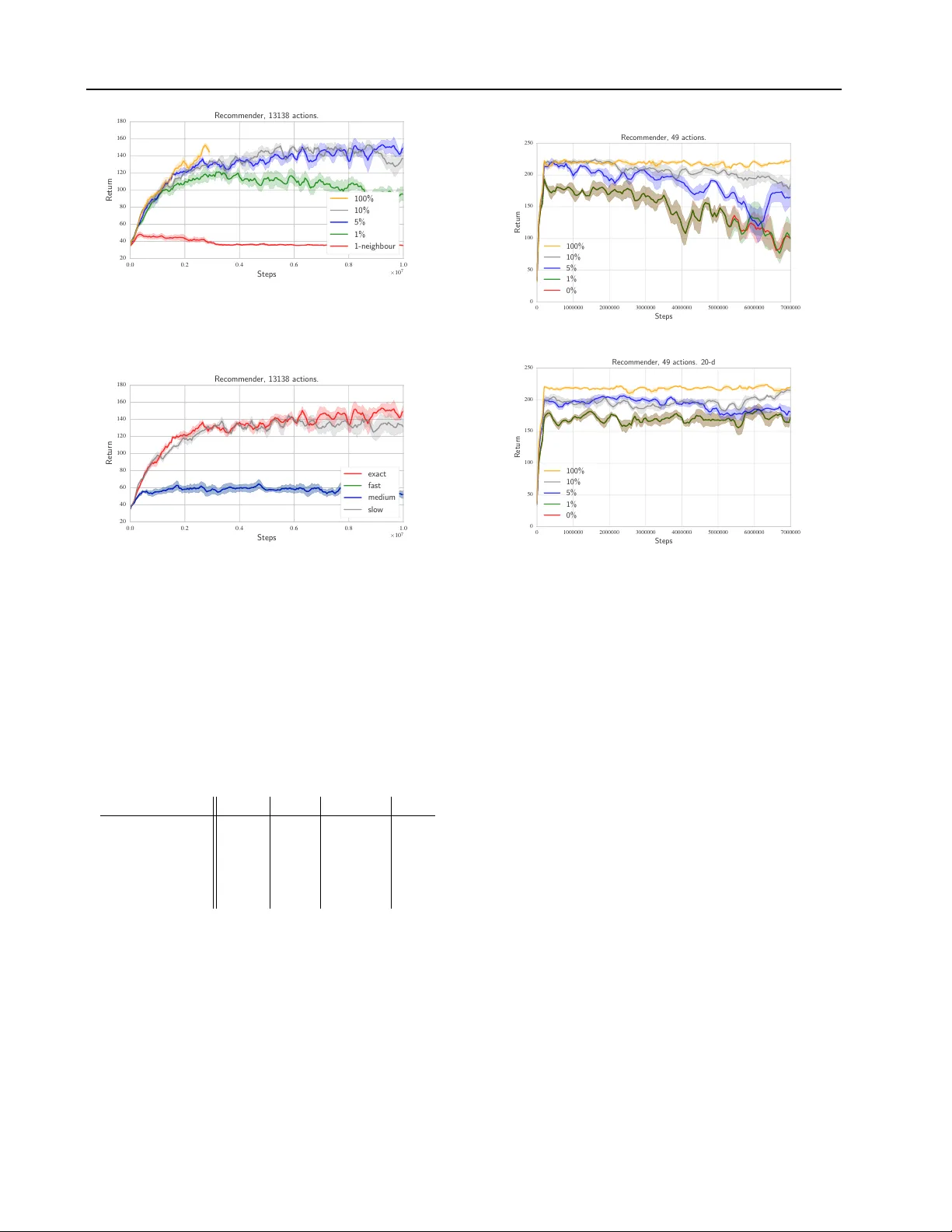
논문은 k를 증가시킬 때 기대 Q값이 어떻게 변하는지를 정량화한 Lemma 1을 제시한다. 여기서는 후보 행동 중 ‘나쁜’ 행동이 존재할 확률 p와 그 손실 c, 그리고 정상 행동의 가치 범위 b를 파라미터화한다. 기대 최대값은 Q(s,a)+b−p·k·(c−b)−2b/(k+1) 형태이며, 첫 항은 지수적으로 감소하고 두 번째 항은 역비례적으로 감소한다. 이 결과는 실험에서 k를 전체 행동 수의 5~10% 정도로 제한해도 충분히 높은 성능을 얻을 수 있음을 뒷받침한다.
7. **실험**
- *연속 제어 이산화*: MuJoCo 시뮬레이터의 cart‑pole, pendulum 등에서 각 차원을 i개의 구간으로 이산화해 |A|=iᵈ 로 만든다. Wolpertinger는 작은 i(예: 5)부터 큰 i(예: 100)까지 모두 빠르게 수렴하며, 특히 행동 수가 10⁴ 이상일 때 기존 DDPG 대비 학습 속도가 2~3배 빨라졌다.
- *다단계 플래닝*: 복합적인 의사결정 문제에서 각 단계마다 수천 개의 후보 행동을 생성한다. k‑NN + Q‑재정렬 전략이 단순 근접 선택보다 15% 이상 높은 최종 보상을 기록했다.
- *추천 시스템*: 1백만 개 아이템을 가진 가상 추천 환경에서, 사용자 상태를 임베딩하고 아이템을 행동 임베딩에 매핑한다. Wolpertinger는 5% 정도의 후보 집합(k≈5·10⁴)만 고려해도 전체 아이템을 모두 탐색한 경우와 거의 동일한 클릭‑스루 레이트(CTR)를 달성했으며, 계산량은 20배 이상 절감되었다.
8. **비교 및 한계**
기존 ECOC 기반 방법은 이진 코드 설계가 복잡하고, Q‑함수와 결합된 정제 단계가 없어 임베딩 품질에 민감했다. 또한, 연속‑이산 혼합 접근법(Van Hasselt 등)도 차원 수가 1~2에 불과했으며, 대규모 행동 집합에 대한 실험이 부족했다. Wolpertinger는 이러한 한계를 극복하고, 행동 임베딩이 충분히 구조화된 경우에 특히 강력한 성능을 보인다. 다만, 임베딩 자체가 부실하거나 고차원(>100)에서 거리 계산이 불안정해질 경우 k‑NN 검색 비용이 증가할 수 있다.
9. **결론**
논문은 행동 임베딩 + 근사 k‑NN + Q‑재정렬이라는 세 가지 핵심 요소를 결합해, 대규모 이산 행동 공간에서도 서브선형 복잡도와 행동 일반화를 동시에 달성하는 정책을 제시한다. 실험 결과는 제안 방법이 수백만 개 행동을 가진 실제 문제에 적용 가능함을 입증한다. 향후 연구는 자동 임베딩 학습, 동적 k 조절, 그리고 멀티‑슬레이트(Multi‑Slate) MDP와 같은 복합 행동 구조에의 확장을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기