Nonparametric Spherical Topic Modeling with Word Embeddings
Traditional topic models do not account for semantic regularities in language. Recent distributional representations of words exhibit semantic consistency over directional metrics such as cosine similarity. However, neither categorical nor Gaussian o…
Authors: Kayhan Batmanghelich, Ardavan Saeedi, Karthik Narasimhan
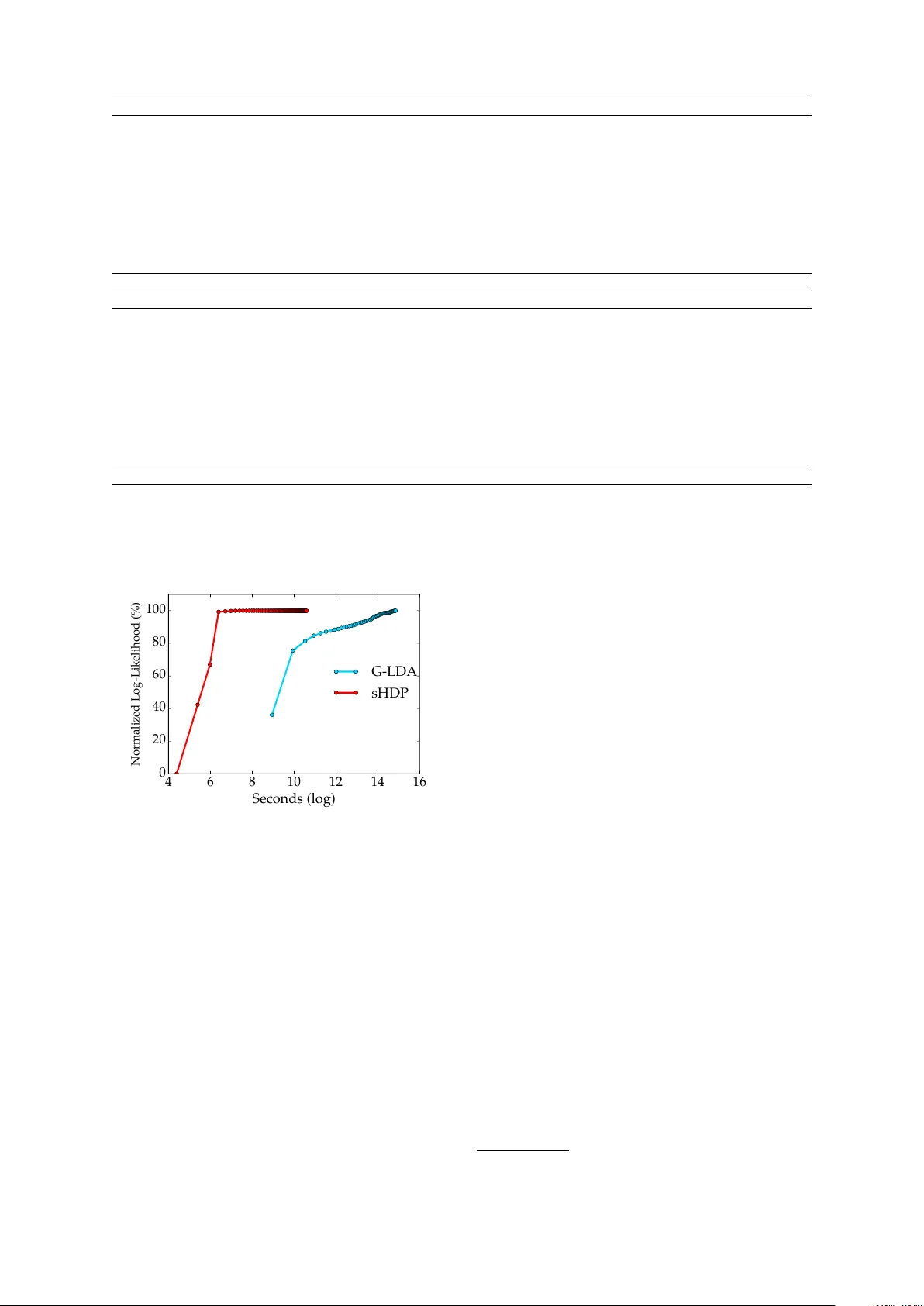
Nonparametric Spherical T opic Modeling with W ord Embeddings Kayhan Batmanghelich ∗ CSAIL, MIT kayhan@mit.edu Arda van Saeedi * CSAIL, MIT ardavans@mit.edu Karthik Narasimhan CSAIL, MIT karthikn@mit.edu Sam Gershman Harv ard Uni versity gershman@fas.harvard.edu Abstract T raditional topic models do not account for semantic regularities in language. Recent distributional representations of words e xhibit semantic consistency ov er directional metrics such as cosine simi- larity . Ho wev er , neither categorical nor Gaussian observational distributions used in existing topic models are appropriate to le verage such correlations. In this paper , we propose to use the von Mises-Fisher distribution to model the density of words ov er a unit sphere. Such a representation is well-suited for directional data. W e use a Hierarchical Dirichlet Process for our base topic model and propose an ef ficient infer - ence algorithm based on Stochastic V ari- ational Inference. This model enables us to naturally exploit the semantic structures of word embeddings while fle xibly discov- ering the number of topics. Experiments demonstrate that our method outperforms competiti ve approaches in terms of topic coherence on two different text corpora while of fering efficient inference. 1 Introduction Prior work on topic modeling has mostly in volved the use of categorical lik elihoods (Blei et al., 2003; Blei and Laf ferty , 2006; Rosen-Zvi et al., 2004). Applications of topic models in the tex- tual domain treat words as discrete observations, ignoring the semantics of the language. Recent de velopments in distributional representations of words (Mikolov et al., 2013; Pennington et al., 2014) hav e succeeded in capturing certain seman- tic regularities, but have not been explored exten- ∗ Authors contributed equally and listed alphabetically . si vely in the conte xt of topic modeling. In this pa- per , we propose a probabilistic topic model with a nov el observ ational distribution that inte grates well with directional similarity metrics. One way to employ semantic similarity is to use the Euclidean distance between word vectors, which reduces to a Gaussian observational distri- bution for topic modeling (Das et al., 2015). The cosine distance between word embeddings is an- other popular choice and has been shown to be a good measure of semantic relatedness (Mikolov et al., 2013; Pennington et al., 2014). The von Mises-Fisher (vMF) distribution is well-suited to model such directional data (Dhillon and Sra, 2003; Banerjee et al., 2005) but has not been pre- viously applied to topic models. In this work, we use vMF as the observational distribution. Each word can be vie wed as a point on a unit sphere with topics being canonical di- rections. More specifically , we use a Hierarchi- cal Dirichlet Process (HDP) (T eh et al., 2006), a Bayesian nonparametric variant of Latent Dirich- let Allocation (LD A), to automatically infer the number of topics. W e implement an efficient infer - ence scheme based on Stochastic V ariational Infer- ence (SVI) (Hof fman et al., 2013). W e perform experiments on two dif ferent English text corpora: 2 0 N E W S G RO U P S and N I P S and compare against two baselines - HDP and Gaussian LD A. Our model, spherical HDP (sHDP), outperforms all three systems on the mea- sure of topic coher ence . For instance, sHDP ob- tains gains ov er Gaussian LD A of 97.5% on the N I P S dataset and 65.5% on the 2 0 N E W S G RO U P S dataset. Qualitativ e inspection rev eals consistent topics produced by sHDP . W e also empirically demonstrate that employing SVI leads to ef ficient topic inference. 2 Related W ork T opic modeling and word embeddings Das et al. (2015) proposed a topic model which uses a Gaussian distribution over word embeddings. By performing inference o ver the vector representa- tions of the words, their model is encouraged to group words that are semantically similar , lead- ing to more coherent topics. In contrast, we pro- pose to utilize von Mises-Fisher (vMF) distribu- tions which rely on the cosine similarity between the word v ectors instead of euclidean distance. vMF in topic models The vMF distribution has been used to model directional data by plac- ing points on a unit sphere (Dhillon and Sra, 2003). Reisinger et al. (2010) propose an admix- ture model that uses vMF to model documents rep- resented as vector of normalized word frequen- cies. This does not account for word lev el seman- tic similarities. Unlike their method, we use vMF ov er word embeddings. In addition, our model is nonparametric. Nonparametric topic models HDP and its v ari- ants hav e been successfully applied to topic mod- eling (Paisle y et al., 2015; Blei, 2012; He et al., 2013); ho we ver , all these models assume a cate- gorical likelihood in which the words are encoded as one-hot representation. 3 Model In this section, we describe the generative process for documents. Rather than one-hot representa- tion of w ords, we employ normalized word em- beddings (Mikolo v et al., 2013) to capture seman- tic meanings of associated words. W ord n from document d is represented by a normalized M - dimensional vector x dn and the similarity between words is quantified by the cosine of angle between the corresponding word v ectors. Our model is based on the Hierarchical Dirich- let Process (HDP). The model assumes a collec- tion of “topics” that are shared across documents in the corpus. The topics are represented by the topic centers µ k ∈ R M . Since word vectors are normalized, the µ k can be vie wed as a direction on unit sphere. V on Mises − Fisher (vMF) is a distri- bution that is commonly used to model directional data. The likelihood of the topic k for word x dn is: f ( x dn ; µ k ; κ k ) = exp κ k µ T k x dn C M ( κ k ) D x dn z dn ⇡ d µ k , k 1 ⇤ ↵ ' dn k , k ✓ d N d ( µ 0 ,C 0 ) ( m, ) Figure 1: Graphical representation of our spheri- cal HDP (sHDP) model. The symbol next to each random variable denotes the parameter of its vari- ational distribution. W e assume D documents in the corpus, each document contains N d words and there are countably infinite topics represented by ( µ k , κ k ) . where κ k is the concentration of the topic k , the C M ( κ k ) := κ M / 2 − 1 k / (2 π ) M / 2 I M / 2 − 1 ( κ k ) is the normalization constant, and I ν ( · ) is the mod- ified Bessel function of the first kind at order ν . Interestingly , the log-likelihood of the vMF is pro- portional to µ T k x dn (up to a constant), which is equal to the cosine distance between two vectors. This distance metric is also used in Mikolov et al. (2013) to measure semantic proximity . When sampling a new document, a subset of topics determine the distribution ov er words. W e let z dn denote the topic selected for the word n of document d . Hence, z dn is drawn from a categori- cal distribution: z dn ∼ Mult ( π d ) , where π d is the proportion of topics for document d . W e draw π d from a Dirichlet Process which enables us to esti- mate the the number of topics from the data. The generati ve process for the generation of new doc- ument is as follo ws: β ∼ GEM ( γ ) π d ∼ DP ( α, β ) κ k ∼ log-Normal ( m, σ 2 ) µ k ∼ vMF ( µ 0 , C 0 ) z dn ∼ Mult ( π d ) x dn ∼ vMF ( µ k , κ k ) where GEM ( γ ) is the stick-breaking distribution with concentration parameter γ , DP ( α, β ) is a Dirichlet process with concentration parameter α and stick proportions β (T eh et al., 2012). W e use log-normal and vMF as hyper-prior distributions for the concentrations ( κ k ) and centers of the top- ics ( µ k ) respecti vely . Figure 1 provides a graphical illustration of the model. Stochastic variational inference In the rest of the paper , we use bold symbols to denote the v ari- ables of the same kind ( e.g., x d = { x dn } n , z := { z dn } d,n ). W e employ stochastic variational mean-field inference (SVI) (Hoffman et al., 2013) to estimate the posterior distributions of the latent v ariables. SVI enables us to sequentially process batches of documents which makes it appropriate in large-scale settings. T o approximate the posterior distribution of the latent variables, the mean-field approach finds the optimal parameters of the fully factorizable q ( i.e ., q ( z , β , π , µ , κ ) := q ( z ) q ( β ) q ( π ) q ( µ ) q ( κ ) ) by maximizing the Evidence Lo wer Bound (ELBO), L ( q ) = E q [log p ( X , z , β , π , µ , κ )] − E q [log q ] where E q [ · ] is expectation with respect to q , p ( X , z , β , π , µ , κ ) is the joint likelihood of the model specified by the HDP model. The v ariational distributions for z , π , µ hav e the follo wing parametric forms, q ( z ) = Mult ( z | ϕ ) q ( π ) = Dir ( π | θ ) q ( µ ) = vMF ( µ | ψ , λ ) , where Dir denotes the Dirichlet distribution and ϕ , θ , ψ and λ are the parameters we need to op- timize the ELBO. Similar to (Bryant and Sud- derth, 2012), we vie w β as a parameter; hence, q ( β ) = δ β ∗ ( β ) . The prior distribution κ does not follo w a conjugate distrib ution; hence, its poste- rior does not have a closed-form. Since κ is only one dimensional v ariable, we use importance sam- pling to approximate its posterior . For a batch size of one ( i.e., processing one document at time), the update equations for the parameters are: ϕ dwk ∝ exp { E q [log vMF ( x dw | ψ k , λ k )] + E q [log π dk ] } θ dk ← (1 − ρ ) θ dk + ρ ( α β k + D W X n =1 ω wj ϕ dwk ) t ← (1 − ρ ) t + ρs ( x d , ϕ dk ) ψ ← t/ k t k 2 , λ ← k t k 2 where D , ω wj , W , ρ are the total number of docu- ments, number of word w in document j , the total number of words in the dictionary , and the step size, respecti vely . t is a natural parameter for vMF and s ( x d , ϕ dk ) is a function computing the suffi- cient statistics of vMF distribution of the topic k . Model T opic Coherence 2 0 N E W S N I P S HDP 0.037 0.270 G-LD A (k=20) -0.017 0.215 G-LD A (k=40) 0.052 0.248 G-LD A (k=60) 0.082 0.137 G-LD A (k=100) -0.032 0.267 sHDP 0.162 0.442 T able 2: A verage topic coherence for various base- lines (HDP , Gaussian LD A (G-LD A)) and sHDP . k =number of topics. Best scores are sho wn in bold. W e use numerical gradient ascent to optimize for β ∗ (see Gopal and Y ang (2014) for exact forms of E q log[ vMF ( x dw | ψ k , λ k )] and E q [log π dk ] ). 4 Experiments Setup W e perform experiments on two dif ferent text corpora: 11266 documents from 2 0 N E W S - G RO U P S 1 and 1566 documents from the N I P S cor- pus 2 . W e utilize 50-dimensional word embeddings trained on text from W ikipedia using wor d2vec 3 . The vectors are post-processed to have unit ` 2 - norm. W e e v aluate our model using the mea- sure of topic coherence (Newman et al., 2010), which has been shown to effecti vely correlate with human judgement (Lau et al., 2014). For this, we compute the Pointwise Mutual Information (PMI) using a reference corpus of 300k documents from Wikipedia. The PMI is calculated using co- occurence statistics ov er pairs of words ( u i , u j ) in 20-word sliding windo ws: PMI ( u i , u j ) = log p ( u i , u j ) p ( u i ) · p ( u j ) W e compare our model with two baselines: HDP and the Gaussian LD A model . W e ran G-LD A with v arious number of topics ( k ). Results T able 2 details the topic coherence av- eraged over all topics produced by each model. W e observe that our sHDP model outperforms G- LD A by 0.08 points on 2 0 N E W S G R O U P S and by 0.17 points on the N I P S dataset. W e can also see that the indi vidual topics inferred by sHDP 1 http://qwone.com/ ˜ jason/20Newsgroups/ 2 http://www.cs.nyu.edu/ ˜ roweis/data. html 3 https://code.google.com/p/word2vec/ Gaussian LD A vector shows network hidden performance net figure size image feature learning term work references shown av erage gaussian show model rule press introduction neurons present equation motion neural w ord tion statistical point family generalization action input means ing related lar ge versus images spike data words eq comparison neuron spread gradient series function approximate performed source small median theory final time derived em statistics fig physiology dimensional robot set describe vol free cells children 1.16 0.4 0.35 0.29 0.25 0.25 0.21 0.2 Spherical HDP neural function analysis press pattern problem noise algorithm layer linear theory cambridge fig process gradient error neurons functions computational journal temporal method propagation parameters neuron vector statistical vol shape optimal signals computation activ ation random field eds smooth solution frequency algorithms brain probability simulations trans surf ace complexity feedback compute cells parameter simulation springer horizontal estimation electrical binary cell dimensional nonlinear volume v ertical prediction filter mapping synaptic equation dynamics revie w posterior solve detection optimization 1.87 1.73 1.51 1.44 1.41 1.19 1.12 1.03 T able 1: Examples of top words for the most coherent topics (column-wise) inferred on the N I P S dataset by Gaussian LD A (k=40) and Spherical HDP . The last row for each model is the topic coherence (PMI) computed using W ikipedia documents as reference. 4 6 8 10 12 14 16 Seconds (log) 0 20 40 60 80 100 Normalized Log-Likelihood (%) G-LDA sHDP Figure 2: Normalized log-likelihood (in percent- age) o ver a training set of size 1566 documents from the NIPS corpus. Since the log-likelihood v alues are not comparable for the Gaussian LD A and the sHDP , we normalize them to demon- strate the con v ergence speed of the two inference schemes for these models. make sense qualitati vely and ha ve higher coher - ence scores than G-LD A (T able 1). This supports our hypothesis that using the vMF likelihood helps in producing more coherent topics. sHDP pro- duces 16 topics for the 2 0 N E W S G R O U P S and 92 topics on the N I P S dataset. Figure 2 shows a plot of normalized log- likelihood against the runtime of sHDP and G- LD A. 4 W e calculate the normalized value of log- likelihood by subtracting the minimum v alue from it and dividing it by the dif ference of maximum and minimum values. W e can see that sHDP con- ver ges faster than G-LD A, requiring only around fi ve iterations while G-LDA takes longer to con- ver ge. 5 Conclusion Classical topic models do not account for semantic regularities in language. Recently , distributional representations of words have emerged that exhibit semantic consistency ov er directional metrics like cosine similarity . Neither categorical nor Gaussian observ ational distributions used in existing topic models are appropriate to lev erage such correla- tions. In this work, we demonstrate the use of the von Mises-Fisher distribution to model words as points o ver a unit sphere. W e use HDP as the base topic model and propose an ef ficient algorithm based on Stochastic V ariational Inference. Our model naturally exploits the semantic structures of word embeddings while fle xibly inferring the number of topics. W e sho w that our method out- performs three competitiv e approaches in terms of topic coherence on two dif ferent datasets. 4 Our sHDP implementation is in Python and the G-LDA code is in Jav a. References [Banerjee et al.2005] Arindam Banerjee, Inderjit S Dhillon, Joydeep Ghosh, and Suvrit Sra. 2005. Clustering on the unit hypersphere using v on mises- fisher distrib utions. In Journal of Machine Learning Resear ch , pages 1345–1382. [Blei and Lafferty2006] David M Blei and John D Laf- ferty . 2006. Dynamic topic models. In Proceed- ings of the 23rd international confer ence on Ma- chine learning , pages 113–120. A CM. [Blei et al.2003] Da vid M Blei, Andrew Y Ng, and Michael I Jordan. 2003. Latent dirichlet allocation. the Journal of machine Learning r esear ch , 3:993– 1022. [Blei2012] Da vid M Blei. 2012. Probabilistic topic models. Communications of the A CM , 55(4):77–84. [Bryant and Sudderth2012] Michael Bryant and Erik B Sudderth. 2012. Truly nonparametric online varia- tional inference for hierarchical dirichlet processes. In Advances in Neural Information Pr ocessing Sys- tems , pages 2699–2707. [Das et al.2015] Rajarshi Das, Manzil Zaheer, and Chris Dyer . 2015. Gaussian LDA for topic mod- els with word embeddings. In Pr oceedings of the 53nd Annual Meeting of the Association for Compu- tational Linguistics . [Dhillon and Sra2003] Inderjit S Dhillon and Suvrit Sra. 2003. Modeling data using directional dis- tributions. T echnical report, T echnical Report TR- 03-06, Department of Computer Sciences, The Uni- versity of T exas at Austin. URL ftp://ftp. cs. utexas. edu/pub/techreports/tr03-06. ps. gz. [Gopal and Y ang2014] Siddarth Gopal and Y iming Y ang. 2014. V on mises-fisher clustering models. [He et al.2013] Y ulan He, Chenghua Lin, W ei Gao, and Kam-Fai W ong. 2013. Dynamic joint sentiment- topic model. A CM T ransactions on Intelligent Sys- tems and T echnology (TIST) , 5(1):6. [Hoffman et al.2013] Matthew D Hof fman, David M Blei, Chong W ang, and John Paisley . 2013. Stochastic v ariational inference. The Journal of Ma- chine Learning Resear ch , 14(1):1303–1347. [Lau et al.2014] Jey Han Lau, David Newman, and T imothy Baldwin. 2014. Machine reading tea leav es: Automatically ev aluating topic coherence and topic model quality . In EACL , pages 530–539. [Mikolov et al.2013] T omas Mikolo v , Ilya Sutske v er , Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality . In Advances in neural information pr ocessing systems , pages 3111–3119. [Newman et al.2010] David Newman, Jey Han Lau, Karl Grieser , and T imothy Baldwin. 2010. Auto- matic e valuation of topic coherence. In Human Lan- guage T echnologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics , pages 100–108. As- sociation for Computational Linguistics. [Paisle y et al.2015] John Paisle y , Chingyue W ang, David M Blei, and Michael I Jordan. 2015. Nested hierarchical dirichlet processes. P attern Analysis and Machine Intelligence, IEEE T r ansactions on , 37(2):256–270. [Pennington et al.2014] Jef frey Pennington, Richard Socher , and Christopher D. Manning. 2014. Glo ve: Global vectors for word representation. In Em- pirical Methods in Natural Language Pr ocessing (EMNLP) , pages 1532–1543. [Reisinger et al.2010] Joseph Reisinger , Austin W aters, Bryan Silverthorn, and Raymond J Mooney . 2010. Spherical topic models. In Pr oceedings of the 27th International Confer ence on Machine Learning (ICML-10) , pages 903–910. [Rosen-Zvi et al.2004] Michal Rosen-Zvi, Thomas Griffiths, Mark Steyvers, and Padhraic Smyth. 2004. The author-topic model for authors and documents. In Pr oceedings of the 20th confer ence on Uncertainty in artificial intelligence , pages 487–494. A UAI Press. [T eh et al.2006] Y ee Whye T eh, Michael I Jordan, Matthew J Beal, and David M Blei. 2006. Hierar - chical dirichlet processes. Journal of the American Statistical Association , 101:1566–1581. [T eh et al.2012] Y ee Whye T eh, Michael I Jordan, Matthew J Beal, and David M Blei. 2012. Hierar - chical dirichlet processes. J ournal of the american statistical association .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment