단어 임베딩을 활용한 비모수 구형 토픽 모델링
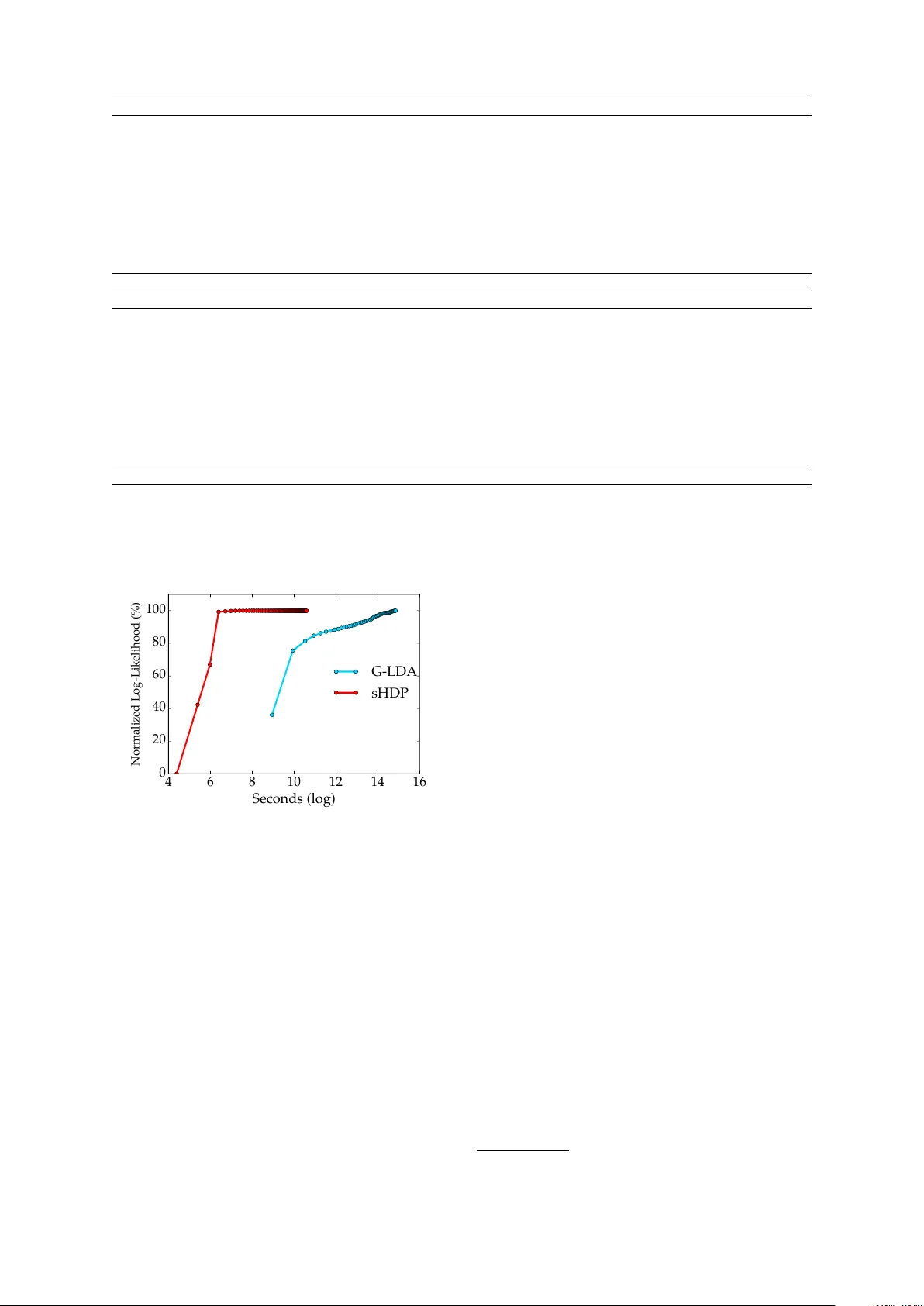
본 논문은 단어 임베딩을 단위 구면 위의 방향 데이터로 간주하고, von Mises‑Fisher(vMF) 분포를 관측 모델로 채택한 비모수 토픽 모델(sHDP)을 제안한다. 계층적 디리클레 프로세스(HDP)를 기반으로 하여 토픽 수를 자동 추정하고, 스토캐스틱 변분 추론(SVI)으로 효율적인 학습을 수행한다. 20 Newsgroups와 NIPS 데이터셋에서 토픽 일관성(PMI) 기준으로 기존 HDP와 Gaussian LDA를 크게 능가함을 실험…
저자: Kayhan Batmanghelich, Ardavan Saeedi, Karthik Narasimhan
**1. 서론**
전통적인 토픽 모델(LDA, HDP 등)은 단어를 이산형 원‑핫 벡터로 취급해 의미적 유사성을 무시한다. 최근 워드투벡·GloVe와 같은 분산 표현은 코사인 유사도를 통해 단어 간 의미적 일관성을 포착하지만, 기존 모델은 카테고리컬 혹은 가우시안 관측 분포를 사용해 이러한 정보를 활용하지 못한다. 저자들은 단어 임베딩을 단위 구면 위의 방향 데이터로 보고, 방향 데이터에 특화된 von Mises‑Fisher(vMF) 분포를 관측 모델로 도입한다.
**2. 관련 연구**
Das et al.(2015)는 임베딩에 가우시안 관측 모델을 적용했으며, Reisinger et al.(2010)는 문서 자체를 정규화된 단어 빈도 벡터로 모델링해 vMF를 사용했다. 그러나 전자는 유클리드 거리 기반이며, 후자는 단어 수준의 의미를 반영하지 않는다. 비모수 토픽 모델(HDP)은 토픽 수를 자동 추정하지만, 관측 모델이 여전히 카테고리컬이다.
**3. 모델 설계**
- **데이터 표현**: 각 단어 w는 M‑차원 정규화 임베딩 x_{dn} ∈ ℝ^M, ‖x‖=1 로 표현한다.
- **토픽 파라미터**: 토픽 k는 방향 µ_k ∈ ℝ^M (단위 벡터)와 농도 κ_k>0 로 정의된다. 관측 확률은 vMF:
f(x|µ_k,κ_k)=C_M(κ_k)·exp(κ_k µ_kᵀx).
- **비모수 구조**: 전역 토픽 비중 β ∼ GEM(γ) (stick‑breaking), 문서별 비중 π_d ∼ DP(α,β). 토픽 할당 z_{dn} ∼ Mult(π_d).
- **사전**: µ_k ∼ vMF(µ_0, C_0), κ_k ∼ LogNormal(m,σ²).
**4. 추론 방법**
스토캐스틱 변분 추론(SVI)을 적용한다. 변분 분포를 완전 독립 형태로 가정하고, ELBO를 최대화한다. 주요 파라미터 업데이트는 다음과 같다:
- 토픽 할당 ϕ_{dwk} ∝ exp{E_q
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기