megaman: Manifold Learning with Millions of points
Manifold Learning is a class of algorithms seeking a low-dimensional non-linear representation of high-dimensional data. Thus manifold learning algorithms are, at least in theory, most applicable to high-dimensional data and sample sizes to enable ac…
Authors: James McQueen, Marina Meila, Jacob V
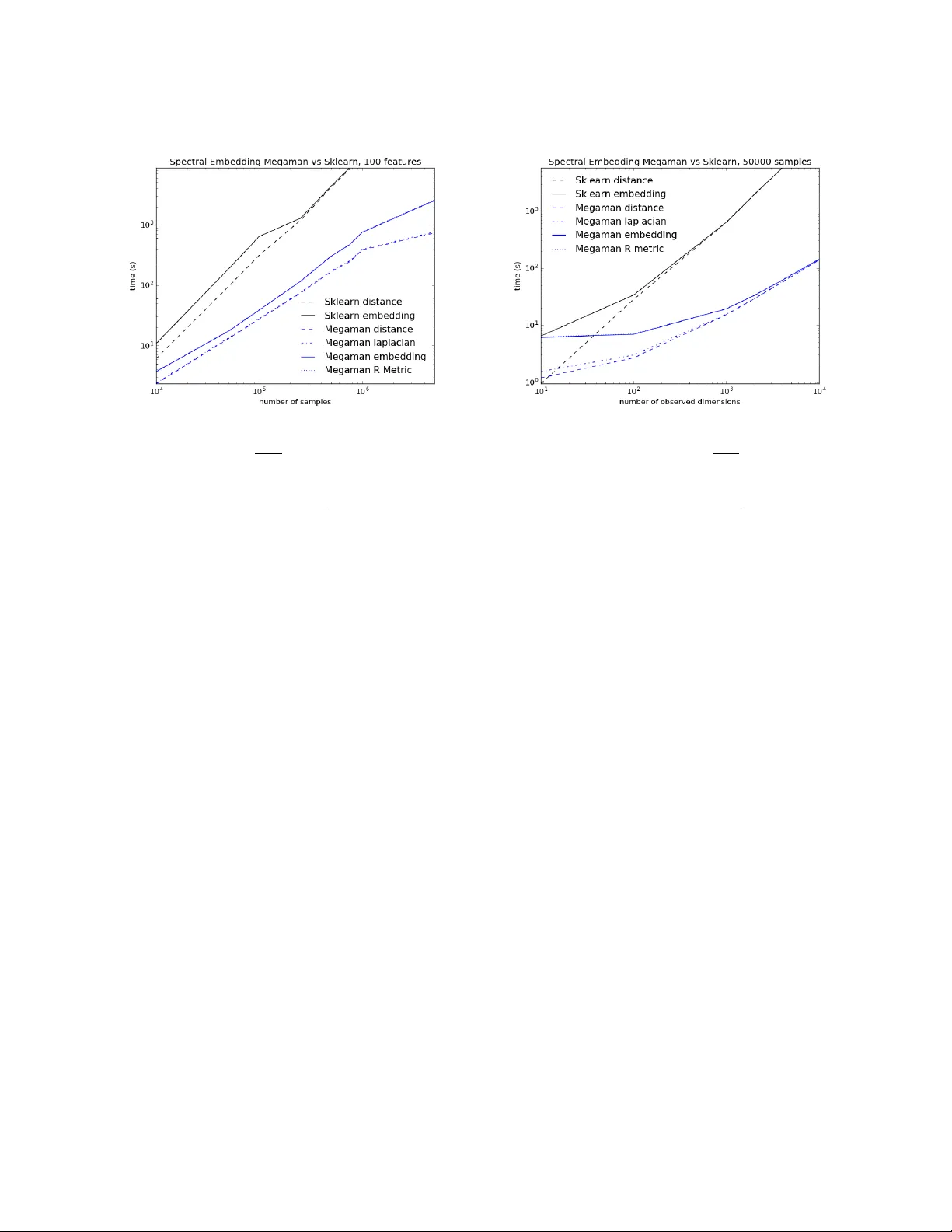
megaman: Manifold Learning with Millions of points megaman: Manifold Learning with Millions of p oin ts James McQueen jmcq@uw.edu Dep artment of Statistics University of Washington Se attle, W A 98195-4322, USA Marina Meil˘ a mmp@st a t.w ashington.edu Dep artment of Statistics University of Washington Se attle, W A 98195-4322, USA Jacob V anderPlas jakevdp@uw.edu e-Scienc e Institute University of Washington Se attle, W A 98195-4322, USA Zhongyue Zhang zhangz6@cs.w ashington.edu Dep artment of Computer Scienc e and Engine ering University of Washington Se attle, W A 98195-4322, USA Editor: Abstract Manifold L e arning (ML) is a class of algorithms seeking a lo w-dimensional non-linear rep- resen tation of high-dimensional data. Th us ML algorithms are, at least in theory , most applicable to high-dimensional data and sample sizes to enable accurate estimation of the manifold. Despite this, most existing manifold learning implementations are not particu- larly scalable. Here w e present a Python pack age that implements a v ariety of manifold learning algorithms in a modular and scalable fashion, using fast appro ximate neighbors searc hes and fast sparse eigendecomp ositions. The pack age incorp orates theoretical ad- v ances in manifold learning, such as the unbiased Laplacian estimator in tro duced by Coif- man and Lafon (2006) and the estimation of the embedding distortion by the Riemannian metric method introduced by P erraul-Joncas and Meila (2013). In benchmarks, ev en on a single-core desktop computer, our code em b eds millions of data points in min utes, and tak es just 200 min utes to embed the main sample of galaxy sp ectra from the Sloan Digital Sky Survey — consisting of 0.6 million samples in 3750-dimensions — a task which has not previously b een p ossible. Keyw ords: Manifold Learning, Dimension Reduction, Riemannian metric, Graph Em- b edding, Scalable Metho ds, Python 1. Motiv ation Manifold L e arning (ML) algorithms lik e Diffusion Maps or Isomap find a non-linear repre- sen tation of high-dimensional data with a small n umber of dimensions. Research in ML is 1 McQueen, Meil ˘ a, V anderPlas and Zhang making steady progress, yet there is curren tly no ML soft ware library efficien t enough to b e used in realistic research and application of ML. The first comprehensiv e attempt to bring several manifold learning algorithms under the same umbrella is the mani Matlab pack age authored by Wittman (2010). This pack age w as instrumen tal in illustrating the behavior of the existing ML algorithms of a v ariety of syn thetic to y data sets. More recen tly , a new Matlab toolb o x drtoolbox 1 w as released, that implemen ts o ver thirty dimension reduction metho ds, and works well with sample sizes in the thousands. P erhaps the b est kno wn op en implemen tation of common manifold learning algorithms is the manifold sub-mo dule of the Python pac k age scikit-learn 2 (P edregosa et al., 2011). This softw are b enefits from the in tegration with scikit-learn , meets its standards and philosoph y , comes with excellent do cumen tation and examples, and is written in a widely supp orted op en language. The scikit-learn pack age strives primarily for usability rather than scalability . While the pack age do es feature some algorithms designed with scalability in mind, the manifold metho ds are not among them. F or example, in scikit-learn it is difficult for different metho ds to share intermediate results, such as eigenv ector computations, whic h can lead to inefficiency in data exploration. The scikit-learn manifold metho ds cannot handle out- of-core data, whic h leads to difficulties in scaling. Moreov er, though scikit-learn accepts sparse inputs and uses sparse data structures internally , the current implemen tation do es not alwa ys fully exploit the data sparsit y . T o address these c hallenges, w e prop ose megaman , a new Python pack age for scalable manifold learning. This pack age is designed for p erformance, while adopting the lo ok and feel of the scikit-learn pack age, and inheriting the functionalit y of scikit-learn ’s w ell- designed API (Buitinck et al., 2013). 2. Bac kground on non-linear dimension reduction and manifold learning This section pro vides a brief description of non-linear dimension reduction via manifold learning, outlining the tasks performed by a generic manifold learning algorithm. The reader can find more information on this topic in Perraul-Joncas and Meila (2013), as w ell as on the scikit-learn w eb site 3 . W e assume that a set of N vectors x 1 , . . . x N in D dimensions is giv en (for instance, for the data in Figure 5, N = 3 × 10 6 , D = 300). It is assumed that these data are sampled from (or appro ximately from) a lo wer dimensional space (i.e. a manifold ) of intrinsic dimension d . The goal of manifold learning is to map the v ectors x 1 , . . . x N to s -dimensional v ectors y 1 , . . . y N , where y i is called the emb e dding of x i and s D , s ≥ d is called the emb e dding dimension . The mapping should preserve the neigh b orho od relations of the original data p oin ts, and as m uc h as possible of their lo cal geometric relations. F rom the p oin t of view of a ML algorithm (also called an emb e dding algorithm ), non- linear dimension reduction subsumes the follo wing stages. 1. https://lvdmaaten.github.io/drtoolbox/ 2. http://scikit-learn.org/stable/modules/manifold.html 3. http://scikit-learn.org/stable/auto examples/index.html 2 megaman: Manifold Learning with Millions of points Geometry FLANN Laplacian Em b edding R. metric eigendecomp. lop cg,arpac k Figure 1: megaman classes (gray , framed), pack ages (gra y , no frame) and external pac k ages (blue). The class structure reflects the relationships b et w een ML tasks. Constructing a neighb orho o d gr aph G , that connects all p oin t pairs x i , x j whic h are “neigh b ors”. The graph G is sparse when data can be represented in low dimensions. F rom this graph, a similarit y S ij ≥ 0 b et w een an y pair of p oin ts x i , x j is computed b y S ij = exp −|| x i − x j || 2 /σ 2 , where σ is a user-defined parameter controlling the neigh b orho od size. This leads to a N × N similarity matrix S , sparse. Constructing the neigh b orhoo d graph is common to most existing ML algorithms. F rom S a sp ecial N × N symmetric matrix called the L aplacian is derived. The Laplacian is directly used for em b edding in metho ds such as the Sp ectral Em b edding (also known as Laplacian Eigenmaps) of Belkin and Niyogi (2002) and Diffusion Maps of Nadler et al. (2006). The Laplacian is also used after em b edding, in the p ost-processing stage. Because these op erations are common to man y ML algorithms and capture the geometry of the high-dimensional data in the matrices S or L , we will generically call the softw are mo dules that implement them Ge ometry . The next stage, the Emb e dding proper, can b e p erformed b y different emb e dding algo- rithms . An embedding algorithm take as input a matrix, which can b e either the matrix of distances || x i − x j || or a matrix derived from it, such as S or L . W ell known algorithms im- plemen ted by megaman are Laplacian Eigenmaps (Belkin and Niyogi, 2002), Diffusion Maps (Nadler et al., 2006), Isomap (Bernstein et al., 2000), etc. The ouput of this step is the s -dimensional represen tation y i corresp onding to eac h data p oin t x i . Em b edding typically in volv es computing O ( d ) eigenv ectors of some N × N matrix. T o note that this matrix has the same sparsity pattern as the neighborho od graph G . Finally , for a given em b edding y 1 , . . . y n , one ma y wish to estimate the distortion incurred w.r.t the original data. This can b e done via the metho d of Perraul-Joncas and Meila (2013), b y calculating for each p oin t y i a metric 4 R i ; R i is an s × s symmetric, p ositiv e definite matrix. Practically , the v alue u T R i u , with u a unit vector, is the “stretc h” at y i in direction u of the em b edding { y 1 , . . . , y N } w.r.t the original data { x 1 , . . . x N } . In particular, for an embedding with no stretc h 5 , R i should b e equal to the unit matrix. The metric given b y R 1 , . . . R N can b e used to calculate distances, areas and v olumes using the embedded data, whic h approximate w ell their respective v alues on the original high-dimensional data. Therefore, obtaining R 1: N along with the embedding co ordinates y 1: N pro vides a geometry-preserving (lossy) compression of the original x 1: N . 4. Mathematically speaking R i represen ts the inv erse of the push-forw ard Riemannian metric in the em- b edding space (Perraul-Joncas and Meila, 2013). 5. That is, for an isometric embedding. 3 McQueen, Meil ˘ a, V anderPlas and Zhang Figure 2: The circle on the left hand plot represen ts the original data with D = 2. The ellipse in the righ t hand plot is an “embedding” of these data into s = 2 dimensions, which deforms the circle in to an ellipse. The blue ov als plotted at selected p oin ts represent the (dual) Riemannian Metric at that p oin t. The long axes of the ellipses represent the lo cal unit of length along the ellipse ; the units are smaller left and righ t, where the length of the original curv e w as compressed, and larger in the middle where the circle was stretc hed. The logical structure of these tasks is sho wn in Figure 1, along with some of the classes and softw are pac k ages used to implemen t them. 3. Soft w are design 3.1 F unctionalit y W e provide classes that implement the abov e tasks, along with p ost-pro cessing and visual- ization to ols. The pac k age implemen ts recent adv ances in the statistical understanding of manifold learning such as: • It has b een shown decisively by Hein et al. (2007) and Ting et al. (2010) that the construction of the neighborho od graph can influence the resulting embedding. In particular, the k -nearest neigh b or graph construction introduces biases that can b e a voided by the use of the -radius graphs. Therefore, the default graph construction metho d is radius neighbors . • A v ariet y of graph Laplacians ( unnormalized, normalized, random walk (v on Luxburg, 2007), renormalized and geometric (Coifman and Lafon, 2006)) are a v ailable. The default c hoice is the geometric Laplacian in tro duced by (Coifman and Lafon, 2006) who show ed that this choice eliminates the biases due v ariation in the density of the samples. 6 6. T echnically sp eaking, this is a t yp e of renormalized Laplacian, whic h con verges to the Laplace-Beltrami op erator if the data is sampled from a manifold. 4 megaman: Manifold Learning with Millions of points • Embedding metric estimation following Perraul-Joncas and Meila (2013). The (dual) Riemannian metric measures the “stretch” in tro duced by the embedding algorithm with resp ect to the original data; Figure 2 illustrates this. 3.2 Designed for p erformance The megaman pack age is designed to b e simple to use with an in terface that is similar to the p opular scikit-learn p ython pac k age. Additionally , megaman is designed with exp erimen tal and exploratory researc h in mind. 3.2.1 Comput a tional challenges The ML pipeline described abov e and in Figure 1 comprises tw o significant computational b ottlenec ks. Computing the neighborho o d graph inv olv es finding the K -nearest neighbors, or the r -nearest neighbors (i.e all neighbors within radius r ) in D dimensions, for N data p oin ts. This leads to sparse graph G and sparse N × N matrix S with O ( d ) neigh b ors p er no de, resp ectiv ely en tries p er row. All N × N matrices in subsequent steps will hav e the same sparsit y pattern as S . Naiv ely implemen ted, this computation requires O ( N 2 ( D + log N )) op erations. Eigendecomp osition A large num b er of em b edding algorithms (effectiv ely all algo- rithms implemen ted in megaman ) in volv e computing O ( s ) principal eigen v ectors of an N × N symmetric, semi-p ositiv e definite matrix. This computation scales like O ( N 2 s ) for dense matrices. In addition, if the working matrices were stored in dense form, the memory re- quiremen ts would scale lik e N 2 , and elementary linear algebra operations like matrix-v ector m ultiplications would scale likewise. 3.2.2 Main design fea tures W e made sev eral design and implemen tation choices in supp ort of scalabilit y . • Sparse representation are used as default for optimal storage and computations. • W e incorporated state of the art Fast Library Approximate Nearest Neigh b or search algorithm b y Muja and Lo we (2014) (can handle Billions of data points) with a cython in terface to Python allo wing for rapid neigh b ors computation. • Intermediate data structures (such as data set index, distances, affinity matrices, Laplacian) are cac hed allowing for testing alternate parameters and methods without redundan t computations. • By con verting matrices to sparse symmetric p ositiv e definite (SSPD) in all cases, megaman takes adv antage of pyamg and of the Lo cally Optimal Block Preconditioned Conjugate Gradien t (LOBPCG) pack age as a matrix-free metho d (Kn y azev, 2001) for solving generalized eigenv alue problem for SSPD matrices. Conv erting to symmetric matrices also improv es the numerical stabilit y of the algorithms. 5 McQueen, Meil ˘ a, V anderPlas and Zhang With these, megaman runs in reasonable time on data sets in the millions. The design also supp orts w ell the exploratory t yp e of work in which a user exp eriments with different pa- rameters (e.g. radius or bandwidth parameters) as w ell as differen t embedding pro cedures; megaman caches an y re-usable information in both the Geometry and embedding classes. 3.3 Designed for extensions megaman ’s interface is similar to that of the scikit-learn pac k age, in order to facilitation easy transition for the users of scikit-learn . megaman is ob ject-orien ted and mo dular. F or example, the Geometry class pro vides user access to geometric computational pro cedures (e.g. fast appro ximate radius neigh- b ors, sparse affinity and Laplacian construction) as an indep endent mo dule, whether the user intends to use embedding metho ds or not. megaman also offers the unified inter- face eigendecomposition to a handful of differen t eigendecomposition procedures (dense, arpack , lobpcg , amg ). Consequently , the megaman pack age can b e used for access to these (fast) to ols without using the other classes. F or example, megaman metho ds can b e used to perform the Laplacian computation and embedding steps of sp ectral clustering. Finally , Geometry accepts input in a v ariet y of forms, from data cloud to similarity matrix, allowing a user to optionally input a precomputed similarity . This design facilitates easy extension of megaman ’s functionality . In particular, new em- b edding algorithms and new metho ds for distance computation can b e added seamlessly . More ambitious p ossible extensions are: neigh b orhoo d size estimation, dimension estima- tion, Gaussian pro cess regression. Finally , the megaman pac k age also has a comprehensive do cumentation with examples and unit tests that can b e run with nosetests to ensure v alidit y . T o allo w future extensions megaman also uses T ra vis Contin uous Integration 7 . 4. Do wnloading and installation megaman is publically a v ailable at: https://github.com/mmp2/megaman . megaman ’s re- quired dep endencies are numpy , scipy , and scikit-learn , but for optimal p erformance FLANN, cython , pyamg and a c compiler gcc are also required. F or unit tests and inte- gration megaman dep ends on nose . The most recen t megaman release can b e installed along with its dep endencies using the cross-platform conda 8 pac k age manager: $ c o n d a i n s t a l l - c h t t p s : / / c o n d a . a n a c o n d a . o r g / j a k e v d p m e g a m a n Alternativ ely , the megaman can be installed from source b y downloading the source rep osi- tory and running: $ p y t h o n s e t u p . p y i n s t a l l With nosetests installed, unit tests can b e run with: $ m a k e t e s t 7. https://tra vis-ci.org/ 8. http://conda.p ydata.org/miniconda.html 6 megaman: Manifold Learning with Millions of points 5. Quic k start F or full documentation see the megaman w ebsite at: http://mmp2.github.io/megaman/ f r o m m e g a m a n . g e o m e t r y i m p o r t G e o m e t r y f r o m m e g a m a n . e m b e d d i n g i m p o r t S p e c t r a l E m b e d d i n g f r o m s k l e a r n . d a t a s e t s i m p o r t m a k e _ s w i s s _ r o l l n = 1 0 0 0 0 X , t = m a k e _ s w i s s _ r o l l ( n ) n _ c o m p o n e n t s = 2 r a d i u s = 1 . 1 g e o m = G e o m e t r y ( a d j a c e n c y _ m e t h o d = ’ c y f l a n n ’ , a d j a c e n c y _ k w d s = { ’ r a d i u s ’ : r a d i u s } , a f f i n i t y _ m e t h o d = ’ g a u s s i a n ’ , a f f i n i t y _ k w d s = { ’ r a d i u s ’ : r a d i u s } , l a p l a c i a n _ m e t h o d = ’ g e o m e t r i c ’ , l a p l a c i a n _ k w d s = { ’ s c a l i n g _ e p p s ’ : r a d i u s } ) S E = S p e c t r a l E m b e d d i n g ( n _ c o m p o n e n t s = n _ c o m p o n e n t s , e i g e n _ s o l v e r = ’ a m g ’ , g e o m = g e o m ) e m b e d _ s p e c t r a l = S E . f i t _ t r a n s f o r m ( X ) 6. Classes ov erview The follo wing is an o verview of the classes and other tools provided in the megaman pack age: Geometry This is the primary non-em b edding class of the pac k age. It contains functions to compute the pairwise distance matrix (in terfacing with the distance module), the Gaus- sian kernel similarity matrix S and the Laplacian matrix L . A Geometry ob ject is what is passed or created inside the em b edding classes. RiemannianMetric This class pro duces the estimated Riemannian metric R i at each p oin t i given an embedding y 1: N and the estimated Laplacian from the original data. embeddings The manifold learning algorithms are implemented in their own classes inheriting from a base class. Included are: • SpectralEmbedding implemen ts L aplacian Eigenmaps (Belkin and Niyogi, 2002) and Diffusion Maps (Nadler et al., 2006): These methods use the eigendecomposition of the Laplacian. • LTSA implements the L o c al T angent Sp ac e A lignment metho d (Zhang and Zha, 2004): This metho d aligns estimates of local tangen t spaces. • LocallyLinearEmbedding (LLE) (Ro weis and Saul, 2000): This metho d finds em- b eddings that preserv e local reconstruction w eigh ts • Isomap (Bernstein et al., 2000): This metho d uses Multidimensional Scaling to pre- serv e shortest-path distances along a neighborho o d-based graph. 7 McQueen, Meil ˘ a, V anderPlas and Zhang Figure 3: Run time vs. data set size N for fixed D = 100 and = 5 N 1 / 8 + D 1 / 4 − 2. The data is from a Swiss Roll (in 3 dimensions) with an additional 97 noise dimensions, embedded into s = 2 dimensions by the spectral embedding al- gorithm. By N = 1 , 000 , 000 scikit-learn was unable to compute an embedding due to insuffi- cien t memory . All megaman run times (including time betw een distance and embedding) are faster than scikit-learn . Figure 4: Run time vs. data set dimension D for fixed N = 50 , 000 and = 5 N 1 / 8 + D 1 / 4 − 2. The data is from a Swiss Roll (in 3 dimensions) with additional noise dimensions, embedded into s = 2 dimensions by the spectral embedding algorithm. By D = 10 , 000 scikit-learn was unable to compute an embedding due to insuffi- cien t memory . All megaman run times (including time betw een distance and embedding) are faster than scikit-learn . eigendecomposition Not implemented as a class, this mo dule pro vides a unified (function) in terface to the differen t eigendecomp osition metho ds pro vided in scipy . It also pro vides a null space function (used by LLE and L TSA). 7. Benc hmarks The one other p opular comparable implementation of manifold learning algorithms is the scikit-learn pack age. T o mak e the comparison as fair as possible, we choose the Spectral Embedding metho d for the comparison, because b oth scikit-learn and megaman allo w for similar settings: • Both are able to use radius-based neighborho o ds • Both are able to use the same fast eigensolver, a L o c al ly-Optimize d Blo ck-Pr e c onditione d Conjugate Gr adient (lobp c g) using the algebraic multigrid solv ers in pyamg . Inciden tally , Sp ectral Em b edding is empirically the fastest of the usual manifold learn- ing metho ds, and the b est understoo d theoretically . Note that with the default settings, scikit-learn would perform slo w er than in our exp erimen ts. W e displa y total embedding time (including time to compute the graph G , the Laplacian matrix and the embedding) for megaman versus scikit-learn , as the num b er of samples N v aries (Figure 3) or the data dimension D v aries (Figure 4). All b enc hmark computations w ere p erformed on a single desktop computer running Lin ux with 24.68GB RAM and a 8 megaman: Manifold Learning with Millions of points Figure 5: 3,000,000 words and phrases mapped b y word2vec in to 300 dimensions were embed- ded into 2 dimensions using Sp ectral Em b edding. The plot sho ws a sample of 10,000 p oin ts display- ing the ov erall shap e of the embedding as well as the estimated “stretch” (i.e. dual push-forward Riemannian metric) at v arious lo cations in the em b edding. Figure 6: A three-dimensional embedding of the main sample of galaxy spectra from the Sloan Digital Sky Survey (appro ximately 675,000 sp ec- tra observed in 3750 dimensions). Colors in the ab o v e figure indicate the strength of Hydrogen alpha emission, a very nonlinear feature which requires dozens of dimensions to b e captured in a linear embedding (Yip et al., 2004). A nonlinear em b edding such as the one sho wn here is able to capture that information m uch more succinctly (V anderplas and Connolly, 2009). (Figure b y O. Grace T elford.) Quad-Core 3.07GHz In tel Xeon CPU. W e use a relatively w eak machine to demonstrate that our pack age can be reasonably used without high p erformance hardware. The experiments show that megaman scales considerably b etter than scikit-learn , ev en in the most fav orable conditions for the latter; the memory fo otprin t of megaman is smaller, even when scikit-learn uses sparse matrices internally . The adv antages gro w as the data size gro ws, whether it is w.r.t D or to N . The t wo earlier identified b ottlenec ks, distance computation and eigendecomp osition, dominate the compute time. By comparison, the other steps of the pip e-line, such as Lapla- cian and Riemannian metric computation are negligible. When D is large, the distance computation dominates, while for N D , the eigendecomp osition takes a time compara- tiv ely equal to the distance computation. W e rep ort run times on t wo other real w orld data sets, where the em b edding were done solely with megaman . The first is the word2vec data set 9 whic h con tains feature v ectors in 300 dimensions for ab out 3 million w ords and phrases, extracted from Go ogle News. The v ector represen tation was obtained via a m ultilay er neural net work b y Mik olo v et al. (2013). The second data set contains galaxy sp ectra from the Sloan Digital Sky Survey 10 (Abaza- jian et al., 2009). W e extracted a subset of galaxy sp ectra whose SNR w as sufficiently high, kno wn as the main sample . This set contains fluxes from 675,000 galaxies obse rv ed in 3750 sp ectral bins, prepro cessed as describ ed in T elford et al. (2016). Previous manifold learning 9. Downloaded from GoogleNews-vectors-negative300.bin.gz . 10. www.sdss.org 9 McQueen, Meil ˘ a, V anderPlas and Zhang studies of this data op erated on carefully selected subsets of the data in order to circumv en t computational difficulties of ML (e.g. V anderplas and Connolly, 2009). Here for the first time we present a manifold embedding from the entir e sample. Run time [min] Dataset Size N Dimensions D Distances Em b edding R. metric T otal Sp ectral 0.7M 3750 190.5 8.9 0.1 199.5 W ord2V ec 3M 300 107.9 44.8 0.6 153.3 8. Conclusion megaman puts in the hands of scien tists and metho dologists alik e to ols that enable them to apply state of the art manifold learning methods to data sets of realistic size. The pac k age is easy to use for all scikit-learn users, it is extensible and mo dular. W e hop e that by pro viding this pac k age, non-linear dimension reduction will b e b enefit those who most need it: the practitioners exploring large scien tific data sets. Ac kno wledgments W e w ould lik e to ackno wledge supp ort for this pro ject from the National Science F oundation (NSF grant I IS-9988642), the Multidisciplinary Researc h Program of the Department of Defense (MURI N00014-00-1-0637), the Department of Defense (62-7760 “DOD Unclassified Math”), and the Moore/Sloan Data Science En vironment grant. W e are grateful to Grace T elford for creating F igure 6. This pro ject grew from the Data Science Incubator program 11 at the Universit y of W ashington eScience Institute. References K. N. Abaza jian, J. K. Adelman-McCarthy, M. A. Ag ¨ ueros, S. S. Allam, C. Allende Prieto, D. An, K. S. J. Anderson, S. F. Anderson, J. Annis, N. A. Bahcall, and et al. The Sev en th Data Release of the Sloan Digital Sky Survey. Astr ophysic al Journal Supplement Series , 182:543-558, June 2009. doi: 10.1088/0067- 0049/182/2/543. M. Belkin and P . Niy ogi. Laplacian eigenmaps and sp ectral tec hniques for em b edding and clustering. In T. G. Dietterich, S. Beck er, and Z. Ghahramani, editors, A dvanc es in Neur al Information Pr o c essing Systems 14 , Cambridge, MA, 2002. MIT Press. Mira Bernstein, Vin de Silv a, John C. Langford, and Josh T ennen- baum. Graph appro ximations to geo desics on em b edded manifolds. http://web.mit.edu/cocosci/isomap/BdSLT.pdf , December 2000. Lars Buitinc k, Gilles Louppe, Mathieu Blondel, F abian P edregosa, Andreas Mueller, Olivier Grisel, Vlad Niculae, P eter Prettenhofer, Alexandre Gramfort, Jaques Grobler, et al. API design for machine learning softw are: exp eriences from the scikit-learn pro ject. arXiv pr eprint arXiv:1309.0238 , 2013. 11. http://data.uw.edu/incubator/ 10 megaman: Manifold Learning with Millions of points R. R. Coifman and S. Lafon. Diffusion maps. Applie d and Computational Harmonic A nal- ysis , 30(1):5–30, 2006. Matthias Hein, Jean-Yv es Audib ert, and Ulrik e von Luxburg. Graph laplacians and their con vergence on random neigh b orhoo d graphs. Journal of Machine L e arning R ese ar ch , 8: 1325–1368, 2007. URL http://dl.acm.org/citation.cfm?id=1314544 . Andrew V. Kn y azev. T ow ard the optimal preconditioned eigensolv er: Lo cally optimal block preconditioned conjugate gradient metho d. SIAM Journal on Scientific Computing , 23 (2):517–541, 2001. doi: 10.1137/S1064827500366124. URL http://dx.doi.org/10. 1137/S1064827500366124 . T omas Mik olov, Ilya Sutsk ever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed represen tations of w ords and phrases and their comp ositionalit y . In A dvanc es in Neur al Information Pr o c essing Systems 26 , 2013. Marius Muja and Da vid G. Lo we. Scalable nearest neigh bor algorithms for high dimensional data. Pattern A nalysis and Machine Intel ligenc e, IEEE T r ansactions on , 36, 2014. Boaz Nadler, Stephane Lafon, Ronald Coifman, and Ioannis Kevrekidis. Diffusion maps, sp ectral clustering and eigenfunctions of F okk er-Planck op erators. In Y. W eiss, B. Sc h¨ olkopf, and J. Platt, editors, A dvanc es in Neur al Information Pr o c essing Systems 18 , pages 955–962, Cam bridge, MA, 2006. MIT Press. F abian Pedregosa, Ga¨ el V aro quaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron W eiss, Vincen t Dub ourg, et al. Scikit-learn: Mac hine learning in Python. The Journal of Machine L e arning R ese ar ch , 12:2825–2830, 2011. D. Perraul-Joncas and M. Meila. Non-linear dimensionalit y reduction: Riemannian metric estimation and the problem of geometric discov ery. ArXiv e-prints , Ma y 2013. Sam Ro weis and Lawrence Saul. Nonlinear dimensionality reduction b y lo cally linear em- b edding. Scienc e , 290(5500):2323–2326, December 2000. O. Grace T elford, Jacob V anderplas, James McQueen, and Marina Meila. Metric em bedding of Sloan galaxy spectra. (in pr ep ar ation) , 2016. Daniel Ting, Ling Huang, and Mic hael I. Jordan. An analysis of the con vergence of graph laplacians. In Pr o c e e dings of the 27th International Confer enc e on Machine L e arning (ICML-10), June 21-24, 2010, Haifa, Isr ael , pages 1079–1086, 2010. URL http://www. icml2010.org/papers/554.pdf . J. V anderplas and A. Connolly. Reducing the Dimensionalit y of Data: Lo cally Linear Em b edding of Sloan Galaxy Sp ectra. Astr onomic al Journal , 138:1365–1379, No vem b er 2009. doi: 10.1088/0004- 6256/138/5/1365. Ulrik e von Luxburg. A tutorial on sp ectral clustering. Statistics and Computing , 17(4): 395–416, 2007. 11 McQueen, Meil ˘ a, V anderPlas and Zhang T. Wittman. Manifold learning matlab demo. h ttp://www.math.umn.edu/˜wittman/mani/, retriev ed 07/2010, 2010. C. W. Yip, A. J. Connolly, A. S. Szala y, T. Buda v´ ari, M. SubbaRao, J. A. F rieman, R. C. Nic hol, A. M. Hopkins, D. G. Y ork, S. Ok am ura, J. Brinkmann, I. Csabai, A. R. Thak ar, M. F ukugita, and ˇ Z. Ivezi ´ c. Distributions of Galaxy Spectral T yp es in the Sloan Digital Sky Survey. Astr onomic al Journal , 128:585–609, August 2004. doi: 10.1086/422429. Zhen yue Zhang and Hongyuan Zha. Principal manifolds and nonlinear dimensionalit y re- duction via tangen t space alignmen t. SIAM J. Scientific Computing , 26(1):313–338, 2004. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment