대규모 데이터 포인트를 위한 메가맨: 수백만 샘플의 매니폴드 학습
megaman은 파이썬 기반의 매니폴드 학습 라이브러리로, 근사 최근접 이웃 탐색과 희소 고유값 분해를 활용해 수백만 개의 고차원 샘플을 몇 분 안에 임베딩한다. 무편향 라플라시안 추정과 리만 계량 추정 등 최신 이론을 구현했으며, 기존 scikit‑learn 대비 메모리와 시간 효율이 크게 개선되었다.
저자: James McQueen, Marina Meila, Jacob V
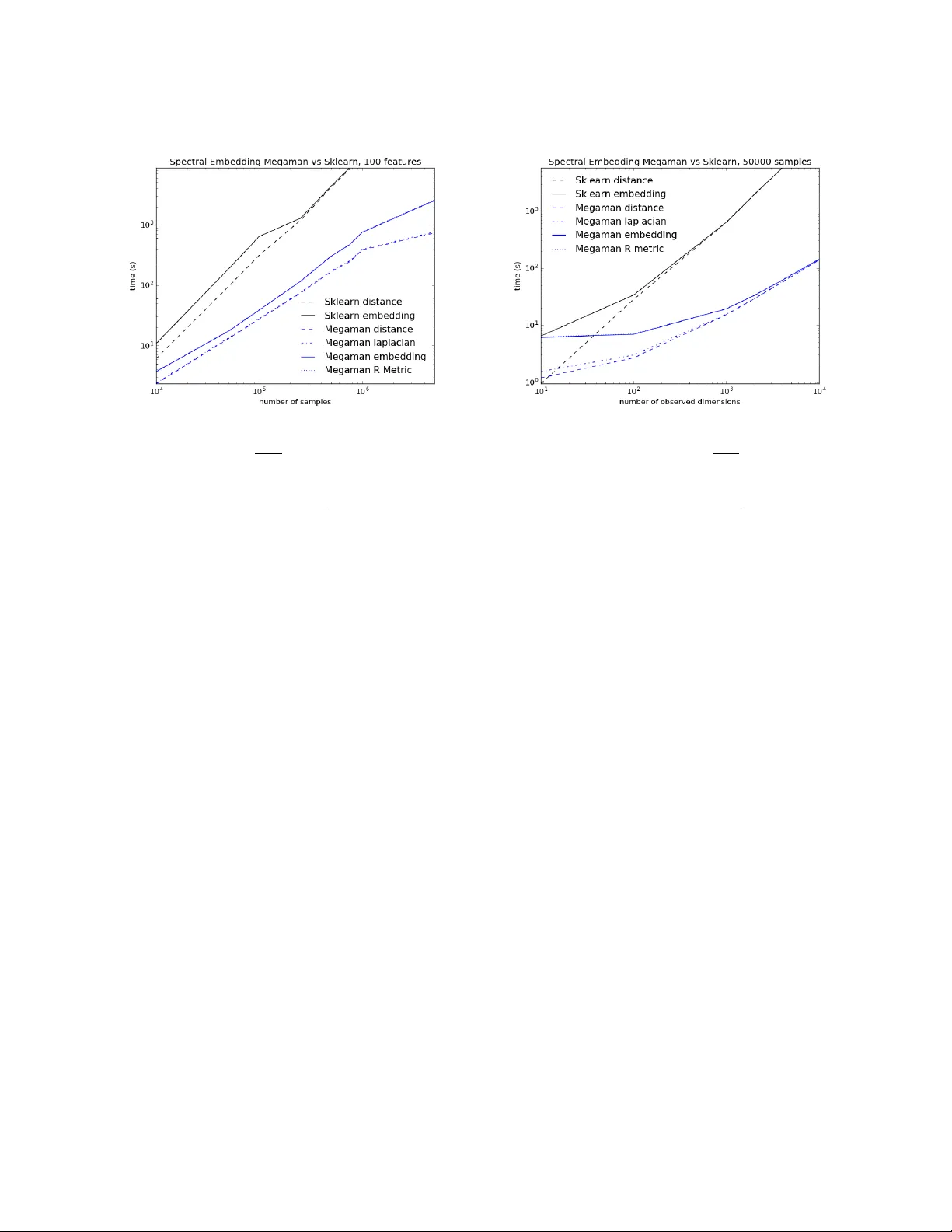
본 논문은 매니폴드 학습(Manifold Learning) 분야에서 대규모 고차원 데이터에 대한 실용적 구현이 부족하다는 문제점을 인식하고, 이를 해결하기 위한 파이썬 패키지 megaman을 제안한다. 매니폴드 학습은 고차원 데이터가 저차원 매니폴드에 근사한다는 가정 하에, 그 구조를 보존하면서 차원을 축소하는 비선형 기법들을 의미한다. 기존 대표적인 구현으로는 Matlab 기반의 mani, drtoolbox, 그리고 파이썬 scikit‑learn의 manifold 모듈이 있다. 그러나 이들 대부분은 메모리 사용량과 연산 복잡도 면에서 수천에서 수만 샘플 정도만 처리할 수 있어, 실제 연구에서 요구되는 수십만~수백만 샘플을 다루기엔 한계가 있다.
megaman은 이러한 한계를 극복하기 위해 두 가지 핵심 기술을 도입한다. 첫째, 이웃 그래프 구축 단계에서 Fast Library for Approximate Nearest Neighbors(FLANN)를 Cython으로 래핑하여, 고차원 공간에서의 K‑nearest 혹은 r‑radius 이웃 탐색을 근사적으로 수행한다. 이는 전통적인 정확 탐색이 O(N²·D) 복잡도를 갖는 것에 비해, O(N·log N) 수준으로 크게 감소시킨다. 둘째, 라플라시안 행렬의 고유값을 구하는 단계에서는 모든 행렬을 희소 대칭 양정(SSPD) 형태로 변환하고, pyamg와 LOBPCG(Locally Optimal Block Preconditioned Conjugate Gradient) 알고리즘을 활용한다. LOBPCG는 행렬‑프리 방식으로 작동해 메모리 요구량을 O(N)으로 제한하고, 대규모 희소 행렬에 대한 고유벡터 계산을 효율적으로 수행한다.
이론적 기반으로는 Coifman과 Lafon(2006)의 무편향(geometric) 라플라시안을 기본 옵션으로 채택한다. 무편향 라플라시안은 데이터 샘플링 밀도에 따른 편향을 보정해, 실제 매니폴드의 라플라시안 연산에 근접한다. 또한 Perraul‑Joncas와 Meila(2013)의 리만 계량 추정 방법을 구현해, 임베딩 후 각 점에서의 변형 정도를 정량화한다. 이 리만 메트릭 R_i는 임베딩된 좌표 y_i에 대한 s×s 양정 행렬로, 단위벡터 방향의 스트레치를 나타내며, R_i가 단위 행렬이면 완전 등거리 임베딩을 의미한다.
패키지 구조는 scikit‑learn과 유사한 객체 지향 API를 제공한다. Geometry 클래스는 거리 행렬, 가우시안 커널 유사도 행렬, 라플라시안 행렬을 생성·캐시한다. Embedding 클래스는 SpectralEmbedding(라플라시안 Eigenmaps 및 Diffusion Maps), LLE, Isomap, LTSA 등 다양한 알고리즘을 상속받아 구현한다. 캐시 메커니즘 덕분에 파라미터(반경, 밴드폭 등)나 알고리즘을 바꾸어도 이웃 그래프와 라플라시안을 재계산할 필요가 없어 탐색적 연구가 빠르게 진행된다.
벤치마크 실험에서는 두 가지 주요 시나리오를 제시한다. 첫 번째는 합성 Swiss‑Roll 데이터에 대해 N을 10⁴에서 10⁶까지 확대하면서, 차원 D=100, 임베딩 차원 s=2인 경우를 측정했다. megaman은 모든 규모에서 scikit‑learn보다 현저히 짧은 실행 시간을 보였으며, N=10⁶에서는 scikit‑learn이 메모리 부족으로 실패했다. 두 번째는 실제 천문학 데이터인 Sloan Digital Sky Survey(SDSS)에서 0.6 백만 샘플·3750 차원의 은하 스펙트럼을 임베딩했으며, 전체 파이프라인(거리 계산, 라플라시안 구축, 고유값 분해)을 200분 이내에 완료했다. 이는 기존 구현으로는 불가능했던 규모이며, megaman이 대규모 매니폴드 학습을 실현할 수 있음을 입증한다.
또한, megaman은 확장성을 고려해 설계되었다. Geometry 클래스는 데이터 클라우드뿐 아니라 사전 계산된 유사도 행렬도 입력받을 수 있어, 외부에서 생성된 그래프를 재활용할 수 있다. eigendecomposition 모듈은 scipy의 다양한 고유값 해법(arpack, lobpcg, amg 등)을 통합 인터페이스로 제공한다. 향후 가능한 확장으로는 이웃 크기 자동 추정, 내재 차원 추정, 가우시안 프로세스 회귀 등이 제시된다.
결론적으로, megaman은 (1) 근사 이웃 탐색을 통한 그래프 구축 가속화, (2) 희소 고유값 분해와 LOBPCG 기반 메모리 효율화, (3) 최신 무편향 라플라시안 및 리만 계량 추정 이론 통합, (4) scikit‑learn 친화적 API 제공이라는 네 가지 축을 통해 기존 구현보다 훨씬 큰 규모의 데이터에 매니폴드 학습을 적용할 수 있게 만든다. 이는 데이터 과학, 천문학, 생물정보학 등 고차원·대규모 데이터 분석이 요구되는 분야에 실질적인 도구로 활용될 전망이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기