Variation of word frequencies in Russian literary texts
We study the variation of word frequencies in Russian literary texts. Our findings indicate that the standard deviation of a word's frequency across texts depends on its average frequency according to a power law with exponent $0.62,$ showing that th…
Authors: Vladislav Kargin
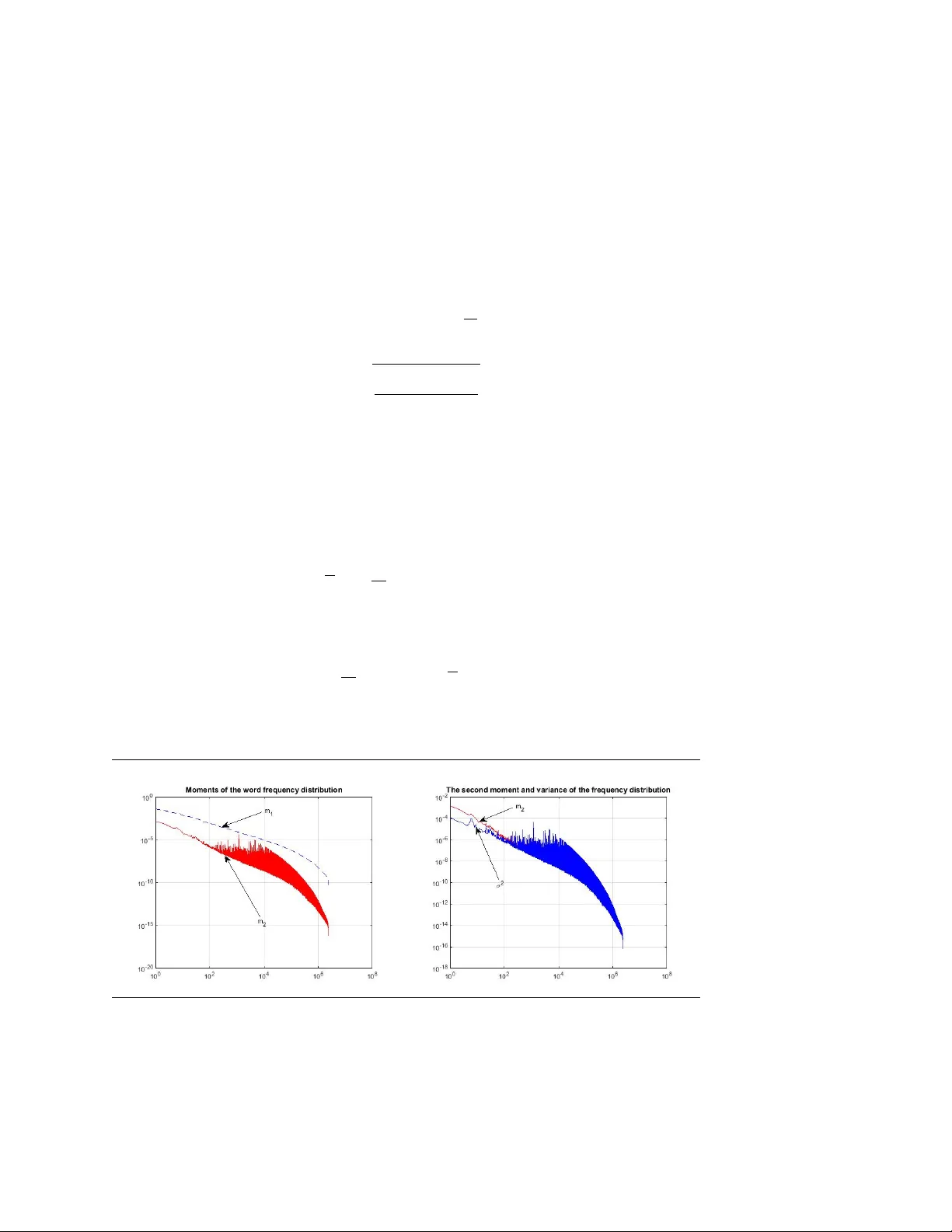
V ARIA TION OF W ORD FREQUENCIES IN R USSIAN LITERAR Y TEXTS VLADISLA V KAR GIN Abstract W e study the v ariation of w ord frequencies in Russian literary texts. Our findings indicate that the standard deviation of a w ord’s frequency across texts dep ends on its a v erage frequency according to a p o wer la w with exp o- nen t 0 . 62 , sho wing that the rarer w ords hav e a relatively larger degree of frequency v olatilit y (i.e., “burstiness”). Sev eral laten t factors models ha ve b een estimated to in v estigate the structure of the word frequency distribu- tion. The dep endence of a w ord’s frequency v olatility on its a v erage frequency can b e explained b y the asymmetry in the distribution of laten t factors. 1. In tro duction The study of w ord frequency v ariation in differen t texts arose first in the problem of author attribution ( Zipf 1932, Y ule 1944, Mosteller and W allace 1964). Recen tly , the explosive gro wth in the computing p o wer and in the text data v olume led to many new applications. F or example, the text indexing problem asks to asso ciate do cuments with queries for fast retriev al; the authorship profiling problem require to describ e features of the author (sex, age, religious and p olitical b eliefs, etc) based on texts that the author pro duced. In addition, the classic authorship attribution problem found new applications in securit y and forensics (see surv eys by Holmes 1998, Juola 2008, K opp el, Sc hler, and Argamon 2009 and Stamatatos 2009). F or all these applications, the fundamental statistical issue is the distribution of word frequencies 1 in differen t texts. F or example, if a Date: Ma y 2015. e-mail: vladisla v.k argin@gmail.com. 1 In this pap er we use the term “frequency” as usual in statistics, that is, the n umber of the w ord occurrences in a document divided by the document’s total n umber of words. 1 2 VLADISLA V KAR GIN w ord in a query has its frequency in a document higher than its av erage frequency , then this do cument can be regarded as more relev ant to the query . Some properties of the w ord frequency distribution w ere noticed a long time ago. F or example, Zipf ’s la w (Zipf 1932) describ es the distribution of w ord frequencies in a particular text, and Heaps’ law (p. 207 in Heaps 1978, p.75 in Herdan 1966) relates the num b er of distinct w ords in a text to its length. Some new researc h on these la ws w as done in F ont-Clos, Boleda, and Corral 2013, Gerlac h and Altmann 2013, Gerlac h and Altmann 2014, and Pian tadosi 2014. See also surv eys in Zanette 2014, Altmann and Gerlac h 2015. This pap er fo cuses on a differen t set of prop erties and in v estigates the v ariation of w ord frequencies across do cuments. One has to understand the structure of the w ord-do cumen t fre- quency matrix for applications in the information retriev al, in order to handle the problems of word synon ymit y and p olysemy . F or this purp ose, there ha v e been recently developed to ols suc h as LSA (“latent seman tic analysis”, Deerw ester et al. 1990), pLSA (“probabilistic latent seman tic analysis”, Hofmann 1999), and LD A (“latent Dirichlet allo- cation”, Blei, Ng, and Jordan 2003). The main idea of these metho ds is the dimension reduction. The v ariation of word frequencies across texts is assumed to stem mainly from the v ariation in relativ ely small amoun t of factors (or “topics”) across texts. The goal of this study is to establish basic facts about the fluctua- tions of word frequencies across do cuments such as the dep endence of the fluctuation size on the a verage word frequency . In order to clar- ify this dep endence, we will apply the latent factor tec hniques such as LSA, pLSA, and LDA. The data for this study come from a large online library of Russian literary texts. This collection is esp ecially appropriate for our study since it co vers a v ery large spectrum of texts from v arious authors, genres and ep o chs. The pap er is organized as follo ws. First, in Section 2 we describ e the data. Then, in Section 3 w e study how the size of frequency fluctuations across texts dep ends on the word’s a v erage frequency . Next, in Sections 4 and 5 w e apply factor mo dels to analyze the v ariation of v o cabulary across texts in more detail. Finally , Section 6 concludes. 2. A preliminary lo ok at the data W e use data from Flibusta, a Russian online library . It cov ers Rus- sian and translated fiction w orks from many historical p erio ds and V ARIA TION OF WORD FREQUENCIES IN RUSSIAN LITERAR Y TEXTS 3 literary genres. Curren tly , it has b etw een 200 , 000 and 300 , 000 texts b y ab out 85 , 000 authors, where the author is understo o d to include translators and sometimes organizations that published a particular text. Our analysis uses only a part of this dataset (around 25 , 000 b o oks). In particular, w e use only b o oks which are a v ailable in a text format (more precisely , in the “FB2” b o ok format) and we exclude the do cumen ts that are a v ailable only as p df, djvu, do c, and other binary formats. The library works using the wiki principle and the texts are uploaded b y users, therefore the n um b er of texts depends b oth on ho w man y texts w ere written b y the author and on ho w many of them w ere uploaded b y users. T able 8 in App endix shows authors with the largest num b er of texts. The top place belongs to “Unkno wn Author”, whic h can be asso ci- ated with texts suc h a “Bhagav ad Gita” or “Poetry of Mediev al F rance”. In the second place one sees a w eekly p olitical publication "T omorrow". The third and fourth places b elong to the American and Russian science fiction writers Ray Bradbury and Kir Bulychev, resp ectively . Man y of the other top authors are authors and translators of b o oks in p opular genres suc h as science fiction, m ystery , romance, action, historical fiction, sensational and ho w-to literature. The righ t p ortion of T able 8 in App endix shows the top 25 authors after we excluded the “unknown author”, w eekly publications, transla- tors, and the authors working in the genres asso ciated with p opular culture. The result is the list of well-kno wn authors, most of which are short story writers. F or these authors, the n um b er of texts in the online library ranges from 446 for An ton Chekhov to 144 for F ranz Kafk a. 3. V ariation of word frequencies across texts Supp ose that ξ ( t ) b,w is an indicator v ariable which equals 1 if the w ord at place t in b o ok b equals w . Then, the frequency of w ord w in b o ok b can b e written as x b,w = 1 T b T b X t =1 ξ ( t ) b,w , (1) where T b is the length of the b o ok b . First, let us take the h yp othesis that for a giv en w the v ariables ξ ( t ) b,w are indep enden t identically distributed random v ariables with the exp ectation parameter p w , whic h do es not dep end on b . Then E x b,w = p w , and V ( x b,w ) = p w (1 − p w ) T b . (2) 4 VLADISLA V KAR GIN Figure 1. Normalized v ariance vs av erage frequency . W e can use (2) to c heck ξ ( t ) b,w are i.i.d. v ariables. F or this purp ose, w e estimate p w b y using the whole sample: b p w := 1 T B X b =1 T b X t =1 ξ ( t ) b,w , (3) where T is the total num b er of w ords in the data and B is the n umber of texts, and then we compute the normalized v ariance of x b,w across b o oks. V w = 1 B B X b =1 √ T w ( x b,w − b p w ) p b p w (1 − b p w ) ! 2 . (4) This statistic should b e compared with 1 . The results are shown in Figure 1. They suggest that this mo del is not acceptable and that there is a significant degree of v ariation in the distribution of ξ b,w across texts. This v ariation in the w ord frequency distribution across texts is at the heart of most applications. Ho wev er, its first systematic study is relativ ely recent and w as done in Churc h and Gale 1995. The phe- nomenon is often called burstiness for a measure of w ord frequency v ariabilit y whic h w as used in Churc h and Gale. 2 One in teresting ob- serv ation of Ch urch and Gale is that the words with an un usually high 2 The name “burstiness” comes from the observ ation that if a rare w ord has o ccurred at least once in a do cumen t, then it is lik ely to occur more times in the same do cument than it is predicted by a Poisson distribution with the word’s a verage frequency . This observ ation can b e explained b y the v ariabilit y of the word frequencies across texts since the observ ation of a word in a do cument c hanges the p osterior b elief ab out the w ord frequency in this do cumen t. V ARIA TION OF WORD FREQUENCIES IN RUSSIAN LITERAR Y TEXTS 5 frequency v ariabilit y are often con ten t words: they hav e an additional linguistic load. No w, let the v ariables ξ ( t ) b,w b e indep enden t random v ariables, which are iden tically distributed conditional on b and w and hav e the exp ec- tation parameter p b,w . That is, the parameter is allo wed to c hange from text to text and w e are interested in learning how it is distributed across texts. The simplest estimate for p b,w is x b,w = 1 T b P T b t =1 ξ ( t ) b,w . It is reliable only if the standard deviation of the estimate is sufficien tly small: p b,w s p b,w (1 − p b,w ) T b , (5) or p b,w T − 1 b . In our database, the av erage text length is of the order of 3 × 10 4 w ords and therefore we can exp ect that x b,w reliably estimates p b,w only if p b,w ≥ 10 − 4 . Let us define the a verage w ord frequency: x w = 1 B B X b =1 x b,w , (6) and the cross-text v ariance: σ 2 w = 1 B B X b =1 ( x b,w − x w ) 2 . (7) In the next pictures w e order word types by their av erage frequency . Figure 2. The (estimated) exp ectation, second momen t, and v ariance of the w ord frequency distribution. 6 VLADISLA V KAR GIN The pictures in Figure 2 suggest that in general the v ariance decline together with the a v erage frequency , so e it is natural to ask ab out the la w of this dep endence. Figure 3. Normalized v ariance vs av erage frequency; 1000 of the most frequent w ords. In Figure 3, the vertical axis sho ws the v ariance normalized b y a p o wer of the av erage frequency: y w = σ 2 w x 1 . 25 w . (8) The exp onen t κ = 1 . 25 was chosen to fit the data. W e sh o w the results for 1 , 000 words with the largest frequency . These are the words for whic h w e can exp ect that the v ariance σ 2 w is reliably estimated. Figure 3 demonstrates that the v ariance follo ws the p o w er law: σ 2 ∼ ax 1 . 25 , (9) where a is a random v ariable whic h generally exceeds 4 × 10 − 3 . Or, in terms of the ratio of the standard deviation to the mean: σ x ∼ a 1 / 2 x − 0 . 375 . (10) That is, the ratio increases for rarer words. Figure 4 is similar except it also shows v ariances and a v erage fre- quencies for some of the less-frequent w ords. (W e simply use the first 2000 differen t w ords that app eared in the data.) The conclusion drawn from Figure 3 is not c hanged by Figure 4, although w e observ e some deviations b elo w the straight line for the normalized v ariance of less- frequen t w ords. V ARIA TION OF WORD FREQUENCIES IN RUSSIAN LITERAR Y TEXTS 7 Figure 4. Normalized v ariance vs av erage frequency; a sam- ple of 2000 w ords. In summary , these observ ations show that there is a p ow er dep en- dence b et w een the v ariance of do cument word frequencies and the a v- erage frequency . The frequen t words ha v e larger v ariation in frequency across texts. Ho w ev er, the ratio of the standard deviation to the av- erage frequency is increases as the av erage frequency b ecomes smaller. This dep endence follo ws a p o wer la w with an exp onen t of appro xi- mately − 0 . 375 . This relation can b e seen as a quan tification of the burstiness phe- nomenon. In particular, it sho ws that burstiness is in general more pronounced for rarer w ords. Hence, if v olatility of a w ord’s frequency (i.e., its burstiness) is used to ev aluate the amount of con ten t asso ciated with the w ord, then the volatilit y should b e normalized b y a function of its frequency . In the next section, we will try to unco v er the structure in the v ari- ation of do cument w ord frequencies using a factor mo del, which is a v arian t of the LSA mo del. 4. A factor mo del for the v o cabulary size v ariation In a factor mo del, exp ected w ord frequencies are allo w ed to c hange from text to text, as in the general random effects mo del. How ev er, it is p ostulated that these changes can b e explained b y a relatively small n um b er of factors. This approac h is esp ecially conv enient for v ery large collections of data, when w e are interested in reducing the complexity of the data, or, in other words, in “reducing the dimensionality” of an observ ed phenomenon. 8 VLADISLA V KAR GIN Let the empirical frequency distribution of w ord t yp es in a b o ok b is denoted x b . If the n um b er of w ord t yp es is N , then x b is an N - v ector. Eac h entry ( x b ) w is the frequency of w ord t yp e w in b o ok b . In particular, k x b k 1 = 1 . The simplest factor model, whic h is a v arian t of the LSA mo del, assumes that x b has a part whic h can b e explained by a small num b er of factors and a part which is an unexplained noise. Hence the mo del is X = s X k =1 θ k f k v ∗ k + Z, (11) where X is an N -b y- B matrix whose columns are x b , the empirical frequency distributions of word types, and where Z is a noise matrix. 3 W e assume that { f k } is an orthonormal system of N -v ectors, and { v k } is an orthonormal system of B -v ectors. Ev ery b o ok b can b e c haracterized by vector ω b = (( v 1 ) b , . . . , ( v s ) b ) , and b o oks with the same vector ω are exp ected to hav e the same w ord frequency distribution up to noise. The simplest metho d is to estimate θ k , f k , and v k is by computing the SVD (“Singular V alue Decomp osition”) of the matrix X and to use only that part of the decomp osition that corresp onds to large singular v alues. There are several b enefits of this model. First, it has a straight- forw ard in terpretation: the frequency matrix is approximated b y a small-rank matrix. Hence, w e fit a parsimonious mo del to the data and ha v e a clear trade-off b et w een the qualit y of the appro ximation and the complexity of the mo del. Second, the mo del can b e estimated with efficien t and fast SVD algorithms. Finally , the statistical litera- ture ab out factor mo dels is ric h and may pro vide some guidance ab out the c hoice of the n umber of factors. There are also significan t deficiencies. The most imp ortant is that the mo del ignores the fact that x b are the empirical frequency distri- butions. This is esp ecially troublesome for less-frequent w ords, when most of the entries in x b are zeros. 3 The difference from the original LSA mo del is that here the decomposition is applied to the frequency matrix X rather than to the matrix of word coun ts in each do cumen t. In addition, the more recen t implemen tations of the LSA metho d usually use “tf-idf ” (term frequency , inv erse document frequency) instead of raw counts. This correction often improv es p erformance of the LSA in do cument indexing tasks. W e will not use this modification in our version since it essen tially remo ves the frequen t words (like “the” and “in”) from consideration, and these words were found imp ortan t in other tasks such as authorship attribution. V ARIA TION OF WORD FREQUENCIES IN RUSSIAN LITERAR Y TEXTS 9 The second deficiency is that most of the results ab out the num b er of factors are derived under the assumption that Z has i.i.d Gaussian en tries. In our situation, this assumption do es not hold. F rom the computational prosp ectiv e, matrix X is very large (of or- der 10 4 b y 10 6 ), and it is computationally difficult to estimate its sp ec- tral parameters. There are tw o alternativ e approac hes to handle this difficult y . First, one can tak e a sample of texts and analyze the sp ectral data using this sample. Second, the text-w ord matrix can b e restricted to the part that contain only the most frequent word types. In this paper, we c ho ose the second metho d that uses the most frequen t w ords. In particular, we computed eigen v alues θ k and eigenv ectors f k for 500 most frequent w ords. F or the applications, one also need to know v k , the eigen v ectors of a large B -by- B matrix X ∗ X . F ortunately , they can b e easily computed: v k = 1 θ k X ∗ f k . (12) The four largest eigen v alues w ere found equal to : 91 . 6 , 3 . 15 , 1 . 76 , and 1 . 52 . The first eigen v alue is m uc h larger than the other ones and corresp onds to an eigenv ector with p ositiv e entries. This eigenv ector can b e in terpreted as the av erage frequency distribution and all other eigen v ectors as “corrections”. In order to estimate the num b er of factors, we note some stylized facts from the theory of large random matrices (Baik and Silverstein 2006, Paul 2007, Benayc h-Georges and Nadakuditi 2012). If a large random matrix Z deformed b y a low-rank matrix, then the resulting matrix X has the “bulk” sp ectrum that corresp ond to singular v alues of Z and outlier singular v alues whic h corresp ond to the singular v alues of the low-rank p erturbations. The plots for the eigenv alues and their spacings suggest that there are at least 10 outliers that can b e interpreted as detectable factors. The plot of eigenv ectors f k suggest that the eigevectors are concen- trated on less than 100 of the most frequent w ords. 5. pLSA and LDA mo dels In the pLSA (“probabilistic latent semantic analysis”) approac h, the true word frequencies in a do cumen t are mo deled as a mixture of a few probabilit y distrib utions, whic h are in terpreted as word distributions b elonging to a factor (or a “topic” in the terminology of text indexing 10 VLADISLA V KAR GIN Figure 5. Distribution of eigen v alues of X X ∗ . (The largest eigen v alue is excluded.) Figure 6. The eigen vectors f k for the first three largest eigen- v alues of X X ∗ . literature). P ( w | b ) = s X z =1 P ( w | z ) P ( z | b ) (13) The interpretation is that for each w ord in a b o ok b w e randomly select a topic z and then select the probability of a w ord w on the basis of this topic. In other w ords, given topic z , the probability of a w ord w is indep enden t of the b o ok b . The mo del resembles the factor mo del (11). How ev er, its strong adv an tage is that this mo del treats the w ord frequencies as a probability distribution in a true probability mo del. Assuming further the indep endence of w ord frequencies in a do cu- men t, the mo del can b e estimated by the log-likelihoo d maximization with the following log-likelihoo d function: L = X b,w n w,b log P ( w | b ) , (14) V ARIA TION OF WORD FREQUENCIES IN RUSSIAN LITERAR Y TEXTS 11 where n b,w is the num b er of o ccurences of the w ord w in a b o ok b . The maximization can b e p erformed by the EM metho d, although as usual, there is a problem of lo cal maxima. In addition, in our exp erience the con v ergence rate was rather slow. 4 The LD A (“latent Dirichlet allo cation”) mo del is similar to the pLSA in that it is assumed that the distribution of w ords in a text is con trolled b y an s -by- N matrix β whic h is a matrix of cond itional probabilit y of a w ord given a topic, β z w = P ( w | z ) . Ev ery do cument is asso ciated with a probability distribution ov er topics θ b whic h is an s -vector of conditional probabilities ( θ b ) z = P ( z | b ) . The nov el idea is to treat the v ector θ b as a random v ariable drawn from a Dirichlet distribution with an s -v ector parameter α . The idea to treat conditional probabilities as random v ariables is the key idea of the hierarchical Bay esian mo deling. In this particular con text, its main in tention is to use the information ab out the distri- bution of θ b o v er all texts b in order to mak e more precise estimates of a particular θ b . T o restate, the joint distribution of the mixture θ , and sequences of w ords { w i } and topics { z i } in a text b is P ( θ, { w i } , { z i }| α, β ) = P ( θ | α ) N b X i =1 P ( w i | z i , β ) P ( z i | θ ) , (15) where P ( θ | α ) is the Dirichlet distribution with parameter α . The main task is to estimate the parameters α and β and compute the p osterior distribution P ( θ |{ w i } ) . This is a non-trivial computa- tional problem. Sev eral appro ximation algorithms are a v ailable. F or details, see pap er by Blei, Ng, and Jordan 2003. In our exp erimen ts we used the co de developed in V erb eek 2006. The ev aluations of practical b enefits of LDA ov er pLSA differ. While Blei, Ng, and Jordan 2003 found some b enefits of the LD A ov er pLSA in the context of collab orative filtering, Masada, Kiyasu, and Miy ahara 2008 found no adv an tage of LDA ov er pLSA in classification of Japanese and K orean webpages. The adv an tage of the LD A mo del for our purp oses is that it can b e used to inv estigate the burstiness phenomenon. (F or a related model, 4 In the mo del with 10 factors, 100 frequen t words and approximately 27,000 b ooks, the conv ergence from a random starting guess to the 6th digit to ok several min utes and to the 9th digit to ok sev eral hours, with some evidence that each new digit of precision tak es progressively more time. The code was implemen ted in Matlab on a PC machine. W e ha ve also used the pLSA co de from V erb eek 2006 for comparison. It yielded similar results. 12 VLADISLA V KAR GIN the Dirichlet comp ound m ultinomial mo del, the burstiness was inv es- tigated in Madsen, Kauchak, and Elk an 2005.) In particular, w e will use the LDA mo del to clarify results found in Section 3. First, note that the probability of w ord w in a b o ok b equals ( θ β ) bz = P s z =1 θ bz β z w . Here θ b is a realization of a random vector θ distributed according to the Diric hlet distribution with parameter α . The join t moments of the Diric hlet distribution are well-kno wn: E s Y z =1 θ k i i ! = Γ ( P i α i ) Γ ( P i ( α i + k i )) × Y i Γ ( α i + k i ) Γ ( α i ) , and therefore one can easily compute the momen ts of the linear com- binations of θ i . Consider, for simplicity , the case with only tw o factors and the sym- metric Dirichlet distribution. So, let s = 2 and α 1 = α 2 = α . Then the probability that a particular w ord in a b ook is a w ord w has a distribution with the exp ectation: E ( p w ) = 1 2 ( β 1 w + β 2 w ) and the v ariance can b e computed as V ( p w ) = 1 4 1 2 α + 1 ( β 1 w − β 2 w ) 2 . If ξ w = | β 2 w − β 1 w | / 2 , then we could recov er the findings in Section 3 provided that ξ w ∼ ( E p w ) κ/ 2 with κ = 1 . 25 . The problem with this in terpretation, is that this relation is imp ossible for small E p w . Indeed, the p ositivity of β 1 w and β 2 w implies that ξ w ≤ E p w and this contradicts the previous relation for small E p w . This can also b e seen from the fact that V ( p w ) ≤ ( E p w ) 2 in this mo del. This can b e rectified by using an asymmetric mo del. T ak e for ex- ample s = 2 , α 1 = 1 and α 2 = α . In this case, E ( p w ) = 1 1 + α β 1 w + α 1 + α β 2 w , V ( p w ) = α (2 + α )(1 + α ) 2 ( β 1 w − β 2 w ) 2 . Let α 1 , β 1 w = γ w α β 2 w . Then, [ E ( p w )] 2 ∼ ( γ w + β 2 w ) 2 α 2 , and V ( p w ) ∼ β 2 2 w 2 α. V ARIA TION OF WORD FREQUENCIES IN RUSSIAN LITERAR Y TEXTS 13 Hence, V ( p w ) [ E ( p w )] 2 pro vided that γ w is not to o large relative to β 2 w . In tuitiv ely , the second topic o ccurs very rarely ( α 1 ). How ev er, it is asso ciated with muc h larger conditional probabilit y to observ e the w ord w : β 2 w β 1 w . This leads to a relativ ely large v ariance of the frequency distribution for the word w . In other w ords, the high burstiness of the word w is due to its b eing a marker of a rare topic. Next, we observe that when α is small and fixed, the p o w er relation V ( p w ) = [ E ( p w )] 1 . 25 is p ossible but only if γ w β 2 w . Since γ w = β 1 w /α , it follo ws that the relationship can o ccur in a limited range when β 1 w β 2 w β 1 w /α. This range is wide only if α is small Figure 7. The estimated parameters of the LD A mo del with 50 topics and 1000 most frequent words. In summary , the p o w er relation observed in Section 3 app ears to b e due to the asymmetry in the distribution of topics v ector θ , and, in particular, it is due to the existence of rare topics that are asso ciated with some sp ecific words (“topic mark ers”). In order to demonstrate the asymmetry in the distribution of topics in the data, w e show the estimates of the parameter α whic h is the Diric hlet parameter for topics, and the parameter β z = p ( w | z ) for one of the rare topics z . The left plot in Figure 7 sho ws the distribution of α , which ranges from 0 . 04 to 0 . 45 . The righ t plot sho ws that a rare topic is indeed asso ciated with mark er w ords. In this example, for the topic with α = 0 . 04 , there are three relatively infrequent words with β > 0 . 03 . They are “всё” (“all”), “ещё” (“y et”), and “её” (“her”). Their a v erage frequencies are 3 . 8 × 10 − 4 , 2 × 10 − 4 , and 1 . 9 × 10 − 4 , resp ectiv ely . The common feature of these words is the presence of the letter “ё”. This 14 VLADISLA V KAR GIN letter is often substituted by the letter “е” to economize on typography costs, and its presence indicates that either the b o ok is in tended for c hildren or it has b een published recently with the help of computerized t yp ograph y . 6. Conclusion In this pap er w e studied the v ariation in the vocabulary of Russian literary texts from a large online database. First, we detected a significant v ariation in the distribution of word frequencies across texts, and found that the v ariance of this distribution is in general larger for words with higher frequency . W e found that the dep endence of the word frequency v olatilit y on its mean has a form of p ow er law with the exp onent 0 . 625 , which quan tify the observ ation that rarer words has greater degree of “burstiness”. In order to study the v ariation in word frequencies across texts, we applied sev eral v ariants of the factor analysis metho d. W e found that most of the v ariation is concentrated in approximately 100 functional w ords and a significant p ortion of this v ariation can b e explained by ab out 10 factors. An analysis of the LDA mo del suggests that the p ow er dep endence of the frequency volatilit y on its mean can b e explained b y an asymmetry in the prior distribution of topics. References [1] Eduardo G. Altmann and Martin Gerlach. “ Statistical la ws in linguistics”. Pro ceedings of the Flo w Mac hines W orkshop: Cre- ativit y and Universalit y in Language, Paris, June 18 to 20, 2014; a v ailable at arxiv:1502.03296. 2015. [2] J. Baik and J. W. Silverstein. “ Eigen v alues of large sample co- v ariance matrices of spik ed p opulation mo dels”. In: Journal of Multiv ariate Analysis 97 (2006), pp. 1382–1408. [3] Florent Benayc h-Georges and Ra j Rao Nadakuditi. “ The Singular V alues and V ectors of Lo w Rank P erturbations of Large Rectan- gular Random Matrices”. In: Journal of Multiv ariate Analysis 111 (2012). arxiv:1103.2221, pp. 120–135. [4] David M. Blei, Andrew Y. Ng, and Mic hael I. Jordan. “ Latent Diric hlet Allocation”. In: Journal of Mac hine Learning Researc h 3 (2003), pp. 993–1022. [5] Kenneth W. Ch urc h and William A. Gale. “ P oisson Mixtures”. In: Natural Language Engineering 1 (1995), pp. 163–190. REFERENCES 15 [6] Scott Deerwester et al. “ Indexing b y Laten t Seman tic Analysis”. In: Journal of the American So ciet y for Information Science 41 (1990), pp. 391–407. [7] F rancesc F ont-Clos, Gemma Boleda, and Alv aro Corral. “ A scal- ing law b eyond Zipf ’s law and its relation to Heaps’ law”. In: New Journal of Physics 15 (2013), p. 093033. [8] Martin Gerlach and Eduardo G. Altmann. “ Scaling laws and fluc- tuations in the statistics of w ord frequencies”. In: New Journal of Ph ysics 16 (2014), p. 113010. [9] Martin Gerlac h and Eduardo G. Altmann. “ Sto c hastic Mo del for the V o cabulary Growth in Natural Languages”. In: Ph ysical Re- view X 3 (2013), p. 021006. [10] H. S. Heaps. Information Retriev al: Computational and Theoret- ical Asp ects. Academic Press, New Y ork, 1978. [11] G. Herdan. A dv anced Theory of Language as Choice and Chance. Springer-V erlag, New Y ork, 1966. [12] T. Hofmann. “ Probabilistic Latent Semantic Indexing”. In: Pro- ceedings of the T w en t y-Second An n ual International SIGIR Con- ference. 1999. [13] D. I. Holmes. “ The ev olution of stylometry in humanities sc holar- ship”. In: Literary and Linguistic Computing 13 (1998), 111–117. [14] Patric k Juola. Authorship A ttribution. F oundations and T rends(r) in Information Retriev al. Now Publishers Inc, 2008. [15] Moshe Koppel, Jonathan Schler, and Shlomo Argamon. “ Compu- tational Methods in Authorship A ttribution”. In: Journal of the Asso ciation for Information Science and T echnology 60 (2009), pp. 9–26. [16] Rasmus E. Madsen, Da vid Kauc hak, and Charles Elk an. “ Mo d- eling W ord Burstiness Using the Dirichlet Distribution”. In: Pro- ceedings of the 22Nd International Conference on Machine Learn- ing. ICML ’05. New Y ork, NY, USA: A CM, 2005, pp. 545–552. isbn: 1-59593-180-5. [17] T omonari Masada, Seny a Kiyasu, and Sueharu Miy ahara. “ Com- paring LDA with pLSI as a Dimensionalit y Reduction Metho d in Document Clustering”. In: Large-Scale Kno wledge Resources. Construction and Application. Ed. b y T ak enobu T okunaga and An tonio Ortega. V ol. 4938. Lecture Notes in Computer Science. Springer Berlin Heidelb erg, 2008, pp. 13–26. isbn: 978-3-540-78158- 5. [18] F rederick Mosteller and Da vid L. W allace. Inference and Disputed Authorship: The F ederalist. A ddison-W esley Publishing Compan y , Inc., 1964. 16 REFERENCES [19] Debashis Paul. “ Asymptotics of sample eigenstructure for a large dimensional spik ed co v ariance model”. In: Statistica Sinica 17 (2007), pp. 1617–1642. [20] Steven T. Piantadosi. “ Zipf ’s word frequency law in natural lan- guage: a critical review and future directions”. In: Psyc honomic Bulletin and Review 21 (2014), pp. 1112–1130. [21] Efstathios Stamatatos. “ A survey of mo dern authorship attribu- tion metho ds”. In: Journal of the American So ciet y for informa- tion science and technology 60 (2009), 538–556. [22] Jacob V erb eek. Laten t Diric hlet Allo cation / Probabilisic Latent Seman tic Analysis. http : / / lear . inrialp es . fr / ~verbeek / soft w are . php. 2006. [23] G. U. Y ule. The statistical study of literary v o cabulary . Cam- bridge Univ ersit y Press, 1944. [24] Damian H. Zanette. “ Statistical patterns in written language”. a v ailable at arxiv:1412.3336. 2014. [25] G. K. Zipf. Selected studies of the principle of relative frequency in language. Cambridge, MA: Harv ard Univ ersity Press, 1932. REFERENCES 17 App endix A. T ables T able 8. Authors with largest num b er ot texts All authors Authors of classic prose Author N. of texts Comment Author N. of texts Unkno wn Author 2442 Chekho v 446 «T omorro w» 597 A weekly publication Maupassan t 390 Bradbury 550 Gorky 379 Bulyc hev 540 Russian sci-fi writer T olstoi 311 Asimo v 508 Grin 295 Marina Sero v a 464 A group of m ystery fic- tion writers P . Neruda 245 An ton Chekho v 446 E. A. Poe 237 «CompuT erra» 437 A weekly publication Nab ok ov 227 Agatha Christie 433 Borges 224 Stephen King 392 O. Henry 217 Guy de Maupassant 390 Lesk o v 215 Maxim Gorky 379 Mark T wain 212 Arth ur Conan Doyle 378 Dumas 185 Victor W eb er 371 T ranslator Kuprin 183 Barbara Cartland 356 Kipling 179 Rob ert Shec kley 356 Bunin 171 Irina Guro v a 353 T ranslator Bulgak o v 165 F edor Razzak o v 348 A biographer of Russian media stars. Solzhenitsyn 164 Stanis ł a w Lem 341 L. Andreev 153 Leo T olstoi 311 P etrushevsk a ya 152 Alexander Grin 295 Romantic no v els set in a fan tasy land Pushkin 151 Vladimir Goldic h 291 T ranslator Balzak 150 Roger Zelazn y 291 Hasek 147 Rob ert E. How ard 286 Sh ukshin 146 T atiana P ertsev a 275 T ranslator Kafk a 144
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment