러시아 문학 텍스트에서 단어 빈도 변동성의 파워법칙
본 연구는 러시아 온라인 문학 데이터베이스(≈25 000권)에서 단어 빈도의 평균값과 텍스트 간 변동성 사이에 전형적인 파워법칙이 존재함을 밝혀냈다. 평균 빈도가 낮은 희귀 단어일수록 표준편차가 평균 대비 크게 증가하며, 이는 “버스티니스(burstiness)” 현상의 정량적 근거가 된다. 또한 LSA·pLSA·LDA 등 잠재 요인 모델을 적용해 변동성을 설명하는 주요 요인이 10여 개 정도이며, 가장 큰 고유값은 전체 단어 분포의 평균 형태를…
저자: Vladislav Kargin
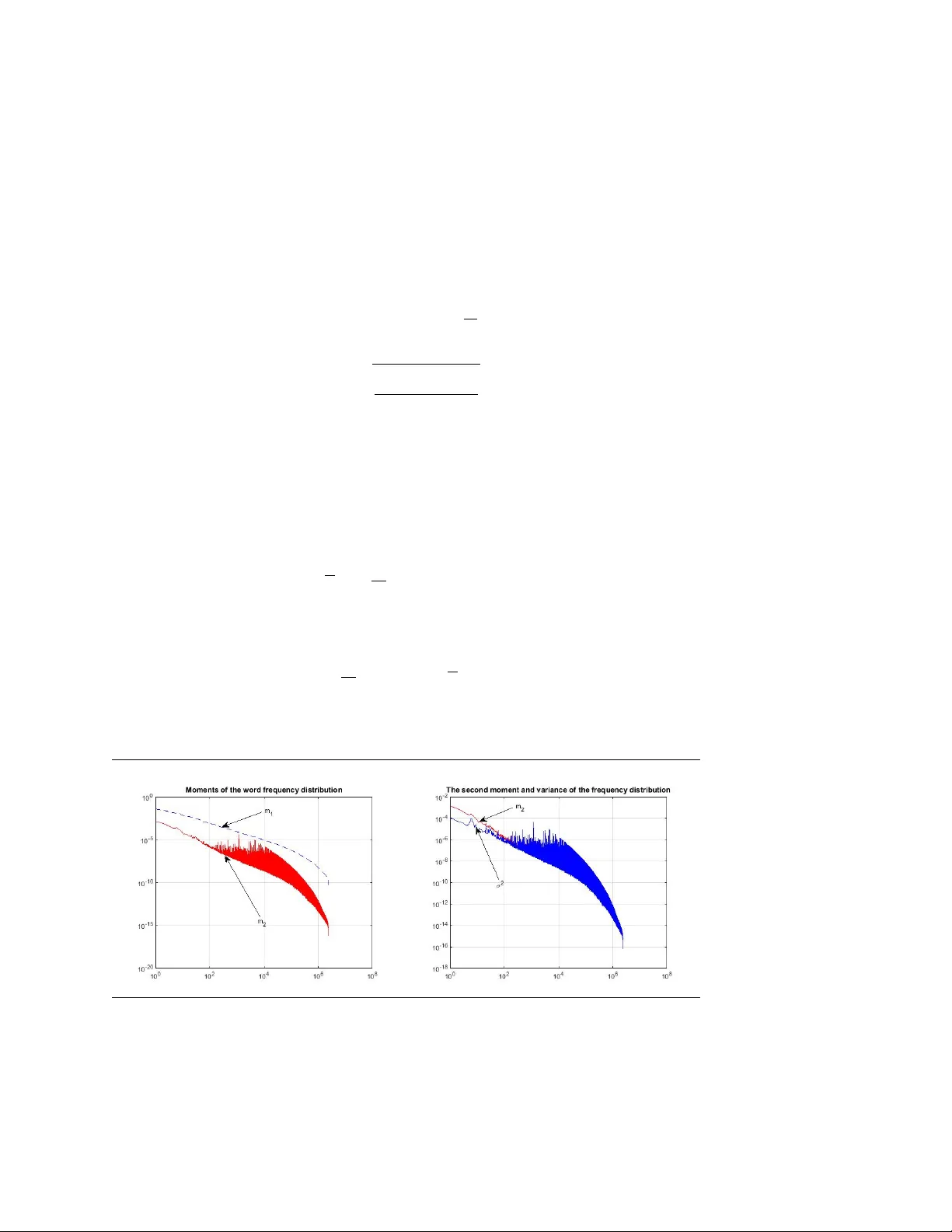
본 연구는 러시아 온라인 문학 도서관(Flibusta)에서 수집한 약 25 000권의 텍스트를 대상으로, 단어 빈도의 평균값과 텍스트 간 변동성 사이의 관계를 정량적으로 분석하였다. 먼저, 각 텍스트 b 에서 단어 w 의 등장 여부를 ξ(t)ᵇʷ 로 정의하고, 전체 단어 수 Tᵇ 로 정규화한 빈도 xᵇ,ʷ 를 구했다. 전통적인 i.i.d. 가정에 따르면 분산은 pʷ(1‑pʷ)/Tᵇ 로 예측되지만, 실제 데이터에서 정규화된 분산 Vʷ 를 계산하면 1보다 크게 벗어나며, 이는 텍스트마다 단어 발생 확률이 다름을 의미한다.
다음 단계에서는 전체 코퍼스에서 각 단어의 평균 빈도 xʷ 와 텍스트 간 분산 σ²ʷ 를 추정하였다. 1 000개의 가장 빈번한 단어에 대해 σ²ʷ 를 평균 빈도의 1.25제곱(x¹·²⁵) 으로 나눈 정규화 지표 yʷ 를 도출했으며, yʷ 가 거의 직선 형태를 보였다. 이는 σ²ʷ ≈ a·x¹·²⁵ (a≈4·10⁻³) 라는 파워법칙을 만족함을 보여준다. 따라서 표준편차 σ는 평균 빈도 x에 대해 σ ∝ x⁰·⁶² 로 감소하고, 상대적인 변동성 σ/x ∝ x⁻⁰·³⁷⁵ 가 희귀 단어일수록 크게 증가한다. 이 현상은 “버스티니스(burstiness)”라 불리며, 단어가 한 번 등장하면 같은 문서 내에서 추가 등장 확률이 평균보다 높아지는 현상을 설명한다.
버스티니스를 구조적으로 설명하기 위해 저자는 잠재 요인 모델을 적용했다. LSA 기반 선형 요인 모델 X = Σₖ θₖ fₖ vₖᵀ + Z 를 제시하고, 500개의 가장 빈번한 단어에 대해 SVD 를 수행했다. 가장 큰 특이값 91.6 은 전체 단어 분포의 평균 형태를 나타내며, 나머지 특이값(3.15, 1.76, 1.52 등)은 주제·저자·시대별 변동을 설명한다. 대규모 랜덤 행렬 이론에 따르면, 특이값 중 10개 정도가 “아웃라이어” 로 구분되어 실제 의미 있는 요인으로 해석될 수 있다.
확률적 접근으로는 pLSA와 LDA를 사용했다. pLSA는 각 텍스트가 토픽 z 를 선택하고, 토픽별 단어 분포 P(w|z) 로 단어를 생성한다는 혼합 모델이며, EM 알고리즘으로 파라미터를 추정한다. 실험에서는 수렴이 느리고 지역 최적화 문제를 겪었다. LDA는 토픽 비율 θᵇ 를 Dirichlet 사전으로 모델링함으로써 텍스트 간 토픽 분포의 변동성을 정규화하고, 베이지안 추론을 통해 보다 견고한 추정치를 제공한다.
전체적으로, 텍스트 간 단어 빈도 변동성은 소수(≈10)의 잠재 요인으로 충분히 설명 가능하며, 가장 큰 요인은 전체 코퍼스의 평균 빈도 패턴을, 나머지는 특정 장르·시대·저자에 특화된 편차를 반영한다. 변동성‑빈도 파워법칙(σ/x ∝ x⁻⁰·³⁷⁵)은 버스티니스 현상을 정량화하는 핵심 지표이며, 정보 검색, 저자 식별, 텍스트 분류 등 다양한 NLP 응용에서 단어 가중치를 설계할 때 빈도에 따라 정규화하는 것이 필요함을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기