On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
Neural machine translation is a relatively new approach to statistical machine translation based purely on neural networks. The neural machine translation models often consist of an encoder and a decoder. The encoder extracts a fixed-length represent…
Authors: Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau
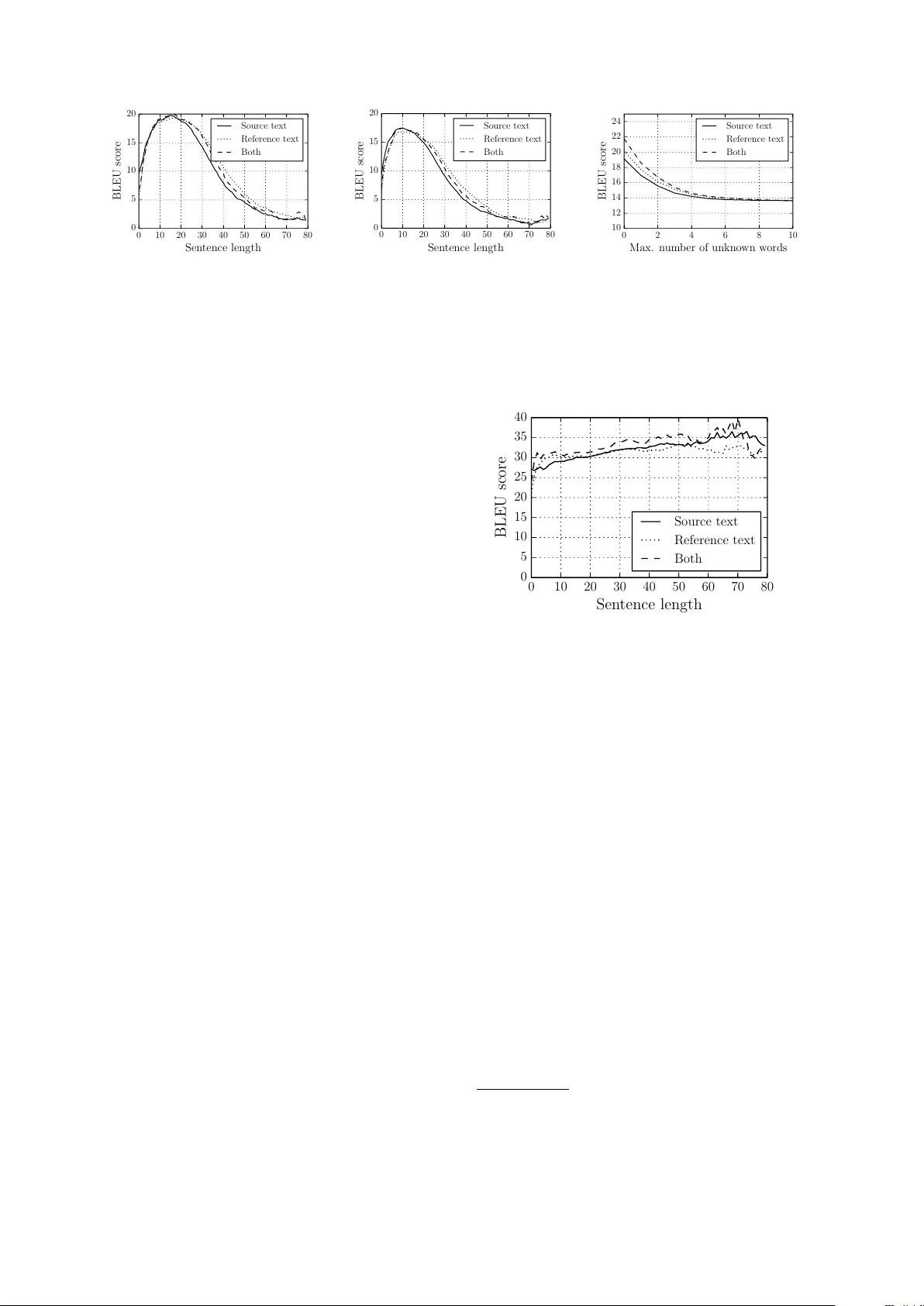
On the Pr operties of Neural Machine T ranslation: Encoder –Decoder A pproaches K yunghyun Cho Bart van Merri ¨ enboer Uni versit ´ e de Montr ´ eal Dzmitry Bahdanau ∗ Jacobs Uni versity , German y Y oshua Bengio Uni versit ´ e de Montr ´ eal, CIF AR Senior Fellow Abstract Neural machine translation is a relativ ely ne w approach to statistical machine trans- lation based purely on neural networks. The neural machine translation models of- ten consist of an encoder and a decoder . The encoder extracts a fix ed-length repre- sentation from a v ariable-length input sen- tence, and the decoder generates a correct translation from this representation. In this paper , we focus on analyzing the proper- ties of the neural machine translation us- ing two models; RNN Encoder–Decoder and a ne wly proposed gated recursi ve con- volutional neural network. W e sho w that the neural machine translation performs relati vely well on short sentences without unkno wn words, but its performance de- grades rapidly as the length of the sentence and the number of unkno wn words in- crease. Furthermore, we find that the pro- posed gated recursi ve con volutional net- work learns a grammatical structure of a sentence automatically . 1 Introduction A ne w approach for statistical machine transla- tion based purely on neural networks has recently been proposed (Kalchbrenner and Blunsom, 2013; Sutske ver et al., 2014). This ne w approach, which we refer to as neural machine translation , is in- spired by the recent trend of deep representational learning. All the neural network models used in (Kalchbrenner and Blunsom, 2013; Sutske ver et al., 2014; Cho et al., 2014) consist of an encoder and a decoder . The encoder extracts a fix ed-length vector representation from a variable-length input sentence, and from this representation the decoder ∗ Research done while visiting Univ ersit ´ e de Montr ´ eal generates a correct, v ariable-length target transla- tion. The emergence of the neural machine transla- tion is highly significant, both practically and the- oretically . Neural machine translation models re- quire only a fraction of the memory needed by traditional statistical machine translation (SMT) models. The models we trained for this paper require only 500MB of memory in total. This stands in stark contrast with existing SMT sys- tems, which often require tens of gigabytes of memory . This makes the neural machine trans- lation appealing in practice. Furthermore, un- like con ventional translation systems, each and ev- ery component of the neural translation model is trained jointly to maximize the translation perfor- mance. As this approach is relativ ely new , there has not been much work on analyzing the properties and behavior of these models. For instance: What are the properties of sentences on which this ap- proach performs better? Ho w does the choice of source/target vocab ulary af fect the performance? In which cases does the neural machine translation fail? It is crucial to understand the properties and be- havior of this new neural machine translation ap- proach in order to determine future research di- rections. Also, understanding the weaknesses and strengths of neural machine translation might lead to better ways of integrating SMT and neural ma- chine translation systems. In this paper , we analyze two neural machine translation models. One of them is the RNN Encoder–Decoder that was proposed recently in (Cho et al., 2014). The other model replaces the encoder in the RNN Encoder–Decoder model with a nov el neural network, which we call a gated r ecursive con volutional neural network (grCon v). W e e valuate these tw o models on the task of trans- lation from French to English. Our analysis shows that the performance of the neural machine translation model degrades quickly as the length of a source sentence in- creases. Furthermore, we find that the vocabulary size has a high impact on the translation perfor- mance. Nonetheless, qualitatively we find that the both models are able to generate correct transla- tions most of the time. Furthermore, the ne wly proposed grConv model is able to learn, without supervision, a kind of syntactic structure over the source language. 2 Neural Networks f or V ariable-Length Sequences In this section, we describe two types of neural networks that are able to process variable-length sequences. These are the recurrent neural net- work and the proposed gated recursiv e con volu- tional neural network. 2.1 Recurrent Neural Network with Gated Hidden Neur ons z r h h ~ x (a) (b) Figure 1: The graphical illustration of (a) the re- current neural netw ork and (b) the hidden unit that adapti vely for gets and remembers. A recurrent neural network (RNN, Fig. 1 (a)) works on a variable-length sequence x = ( x 1 , x 2 , · · · , x T ) by maintaining a hidden state h ov er time. At each timestep t , the hidden state h ( t ) is updated by h ( t ) = f h ( t − 1) , x t , where f is an acti v ation function. Often f is as simple as performing a linear transformation on the input vectors, summing them, and applying an element-wise logistic sigmoid function. An RNN can be used effecti vely to learn a dis- tribution o ver a variable-length sequence by learn- ing the distribution ov er the next input p ( x t +1 | x t , · · · , x 1 ) . For instance, in the case of a se- quence of 1 -of- K vectors, the distribution can be learned by an RNN which has as an output p ( x t,j = 1 | x t − 1 , . . . , x 1 ) = exp w j h h t i P K j 0 =1 exp w j 0 h h t i , for all possible symbols j = 1 , . . . , K , where w j are the ro ws of a weight matrix W . This results in the joint distribution p ( x ) = T Y t =1 p ( x t | x t − 1 , . . . , x 1 ) . Recently , in (Cho et al., 2014) a new activ ation function for RNNs was proposed. The ne w acti va- tion function augments the usual logistic sigmoid acti v ation function with tw o gating units called re- set, r , and update, z , gates. Each gate depends on the pre vious hidden state h ( t − 1) , and the current input x t controls the flow of information. This is reminiscent of long short-term memory (LSTM) units (Hochreiter and Schmidhuber , 1997). For details about this unit, we refer the reader to (Cho et al., 2014) and Fig. 1 (b). For the remainder of this paper , we alw ays use this ne w activ ation func- tion. 2.2 Gated Recursiv e Con volutional Neural Network Besides RNNs, another natural approach to deal- ing with v ariable-length sequences is to use a re- cursi ve con volutional neural network where the parameters at each le vel are shared through the whole network (see Fig. 2 (a)). In this section, we introduce a binary conv olutional neural network whose weights are recursi vely applied to the input sequence until it outputs a single fix ed-length vec- tor . In addition to a usual con volutional architec- ture, we propose to use the previously mentioned gating mechanism, which allows the recursi ve net- work to learn the structure of the source sentences on the fly . Let x = ( x 1 , x 2 , · · · , x T ) be an input sequence, where x t ∈ R d . The proposed gated recursive con volutional neural network (grCon v) consists of four weight matrices W l , W r , G l and G r . At each recursion lev el t ∈ [1 , T − 1] , the activ ation of the j -th hidden unit h ( t ) j is computed by h ( t ) j = ω c ˜ h ( t ) j + ω l h ( t − 1) j − 1 + ω r h ( t − 1) j , (1) where ω c , ω l and ω r are the values of a gater that sum to 1 . The hidden unit is initialized as h (0) j = Ux j , where U projects the input into a hidden space. ω h ~ (a) (b) (c) (d) Figure 2: The graphical illustration of (a) the recursiv e con volutional neural network and (b) the proposed gated unit for the recursiv e conv olutional neural network. (c–d) The example structures that may be learned with the proposed gated unit. The ne w acti vation ˜ h ( t ) j is computed as usual: ˜ h ( t ) j = φ W l h ( t ) j − 1 + W r h ( t ) j , where φ is an element-wise nonlinearity . The gating coef ficients ω ’ s are computed by ω c ω l ω r = 1 Z exp G l h ( t ) j − 1 + G r h ( t ) j , where G l , G r ∈ R 3 × d and Z = 3 X k =1 h exp G l h ( t ) j − 1 + G r h ( t ) j i k . According to this acti v ation, one can think of the activ ation of a single node at recursion level t as a choice between either a new activ ation com- puted from both left and right children, the acti- v ation from the left child, or the activ ation from the right child. This choice allows the ov erall structure of the recursi ve con volution to change adapti vely with respect to an input sample. See Fig. 2 (b) for an illustration. In this respect, we may ev en consider the pro- posed grCon v as doing a kind of unsupervised parsing. If we consider the case where the gat- ing unit makes a hard decision, i.e., ω follows an 1-of-K coding, it is easy to see that the network adapts to the input and forms a tree-like structure (See Fig. 2 (c–d)). Howe ver , we leave the further in vestigation of the structure learned by thi s model for future research. 3 Purely Neural Machine T ranslation 3.1 Encoder –Decoder Appr oach The task of translation can be understood from the perspecti ve of machine learning as learning the E c on o m i c gr owt h h a s s l owe d do w n in r e c e n t ye a r s . La c r o iss a n c e é c onom i qu e a r a l e n t i c e s de r n iè r e s a n n é e s . [z ,z , .. . ,z ] 1 2 d En c o d e Deco d e Figure 3: The encoder–decoder architecture conditional distribution p ( f | e ) of a target sen- tence (translation) f given a source sentence e . Once the conditional distribution is learned by a model, one can use the model to directly sample a target sentence giv en a source sentence, either by actual sampling or by using a (approximate) search algorithm to find the maximum of the dis- tribution. A number of recent papers ha ve proposed to use neural networks to directly learn the condi- tional distribution from a bilingual, parallel cor- pus (Kalchbrenner and Blunsom, 2013; Cho et al., 2014; Sutsk e ver et al., 2014). For instance, the au- thors of (Kalchbrenner and Blunsom, 2013) pro- posed an approach in volving a con volutional n - gram model to extract a fixed-length vector of a source sentence which is decoded with an inv erse con volutional n -gram model augmented with an RNN. In (Sutske ver et al., 2014), an RNN with LSTM units w as used to encode a source sentence and starting from the last hidden state, to decode a target sentence. Similarly , the authors of (Cho et al., 2014) proposed to use an RNN to encode and decode a pair of source and target phrases. At the core of all these recent works lies an encoder–decoder architecture (see Fig. 3). The encoder processes a variable-length input (source sentence) and builds a fixed-length vector repre- sentation (denoted as z in Fig. 3). Conditioned on the encoded representation, the decoder generates a v ariable-length sequence (target sentence). Before (Sutske ver et al., 2014) this encoder – decoder approach was used mainly as a part of the existing statistical machine translation (SMT) sys- tem. This approach was used to re-rank the n -best list generated by the SMT system in (Kalchbren- ner and Blunsom, 2013), and the authors of (Cho et al., 2014) used this approach to provide an ad- ditional score for the existing phrase table. In this paper , we concentrate on analyzing the direct translation performance, as in (Sutskev er et al., 2014), with two model configurations. In both models, we use an RNN with the gated hidden unit (Cho et al., 2014), as this is one of the only options that does not require a non-trivial way to determine the target length. The first model will use the same RNN with the gated hidden unit as an encoder , as in (Cho et al., 2014), and the second one will use the proposed gated recursiv e con vo- lutional neural network (grConv). W e aim to un- derstand the inductiv e bias of the encoder –decoder approach on the translation performance measured by BLEU. 4 Experiment Settings 4.1 Dataset W e ev aluate the encoder–decoder models on the task of English-to-French translation. W e use the bilingual, parallel corpus which is a set of 348M selected by the method in (Axelrod et al., 2011) from a combination of Europarl (61M words), ne ws commentary (5.5M), UN (421M) and two crawled corpora of 90M and 780M words respec- ti vely . 1 W e did not use separate monolingual data. The performance of the neural machien transla- tion models was measured on the news-test2012, ne ws-test2013 and news-test2014 sets ( 3000 lines each). When comparing to the SMT system, we use ne ws-test2012 and ne ws-test2013 as our de- velopment set for tuning the SMT system, and ne ws-test2014 as our test set. Among all the sentence pairs in the prepared parallel corpus, for reasons of computational ef- ficiency we only use the pairs where both English and French sentences are at most 30 words long to train neural networks. Furthermore, we use only the 30,000 most frequent words for both English 1 All the data can be downloaded from http: //www- lium.univ- lemans.fr/ ˜ schwenk/cslm_ joint_paper/ . and French. All the other rare words are consid- ered unknown and are mapped to a special token ( [ UNK ] ). 4.2 Models W e train two models: The RNN Encoder– Decoder (RNNenc)(Cho et al., 2014) and the ne wly proposed gated recursi ve con volutional neural network (grCon v). Note that both models use an RNN with gated hidden units as a decoder (see Sec. 2.1). W e use minibatch stochastic gradient descent with AdaDelta (Zeiler , 2012) to train our two mod- els. W e initialize the square weight matrix (transi- tion matrix) as an orthogonal matrix with its spec- tral radius set to 1 in the case of the RNNenc and 0 . 4 in the case of the grConv . tanh and a rectifier ( max(0 , x ) ) are used as the element-wise nonlin- ear functions for the RNNenc and grConv respec- ti vely . The grCon v has 2000 hidden neurons, whereas the RNNenc has 1000 hidden neurons. The word embeddings are 620-dimensional in both cases. 2 Both models were trained for approximately 110 hours, which is equiv alent to 296,144 updates and 846,322 updates for the grConv and RNNenc, re- specti vely . 3 4.2.1 T ranslation using Beam-Sear ch W e use a basic form of beam-search to find a trans- lation that maximizes the conditional probability gi ven by a specific model (in this case, either the RNNenc or the grCon v). At each time step of the decoder , we keep the s translation candidates with the highest log-probability , where s = 10 is the beam-width. During the beam-search, we exclude any hypothesis that includes an unknown word. For each end-of-sequence symbol that is se- lected among the highest scoring candidates the beam-width is reduced by one, until the beam- width reaches zero. The beam-search to (approximately) find a se- quence of maximum log-probability under RNN was proposed and used successfully in (Gra ves, 2012) and (Boulanger-Le wando wski et al., 2013). Recently , the authors of (Sutske ver et al., 2014) found this approach to be effecti ve in purely neu- ral machine translation based on LSTM units. 2 In all cases, we train the whole network including the word embedding matrix. 3 The code will be av ailable online, should the paper be accepted. Model De velopment T est All RNNenc 13.15 13.92 grCon v 9.97 9.97 Moses 30.64 33.30 Moses+RNNenc ? 31.48 34.64 Moses+LSTM ◦ 32 35.65 No UNK RNNenc 21.01 23.45 grCon v 17.19 18.22 Moses 32.77 35.63 Model De velopment T est All RNNenc 19.12 20.99 grCon v 16.60 17.50 Moses 28.92 32.00 No UNK RNNenc 24.73 27.03 grCon v 21.74 22.94 Moses 32.20 35.40 (a) All Lengths (b) 10–20 W ords T able 1: BLEU scores computed on the de velopment and test sets. The top three ro ws show the scores on all the sentences, and the bottom three rows on the sentences having no unknown words. ( ? ) The result reported in (Cho et al., 2014) where the RNNenc was used to score phrase pairs in the phrase table. ( ◦ ) The result reported in (Sutske ver et al., 2014) where an encoder–decoder with LSTM units was used to re-rank the n -best list generated by Moses. When we use the beam-search to find the k best translations, we do not use a usual log-probability but one normalized with respect to the length of the translation. This prev ents the RNN decoder from f avoring shorter translations, beha vior which was observ ed earlier in, e.g., (Grav es, 2013). 5 Results and Analysis 5.1 Quantitative Analysis In this paper , we are interested in the properties of the neural machine translation models. Specif- ically , the translation quality with respect to the length of source and/or target sentences and with respect to the number of words unknown to the model in each source/target sentence. First, we look at ho w the BLEU score, reflect- ing the translation performance, changes with re- spect to the length of the sentences (see Fig. 4 (a)– (b)). Clearly , both models perform relativ ely well on short sentences, but suffer significantly as the length of the sentences increases. W e observe a similar trend with the number of unkno wn words, in Fig. 4 (c). As expected, the performance degrades rapidly as the number of unkno wn words increases. This suggests that it will be an important challenge to increase the size of vocabularies used by the neural machine trans- lation system in the future. Although we only present the result with the RNNenc, we observed similar behavior for the grCon v as well. In T able 1 (a), we present the translation perfor - mances obtained using the two models along with the baseline phrase-based SMT system. 4 Clearly 4 W e used Moses as a baseline, trained with additional the phrase-based SMT system still shows the su- perior performance ov er the proposed purely neu- ral machine translation system, b ut we can see that under certain conditions (no unkno wn words in both source and reference sentences), the differ - ence diminishes quite significantly . Furthermore, if we consider only short sentences (10–20 words per sentence), the dif ference further decreases (see T able 1 (b). Furthermore, it is possible to use the neural ma- chine translation models together with the existing phrase-based system, which was found recently in (Cho et al., 2014; Sutske ver et al., 2014) to im- prov e the overall translation performance (see T a- ble 1 (a)). This analysis suggests that that the current neu- ral translation approach has its weakness in han- dling long sentences. The most obvious explana- tory hypothesis is that the fixed-length vector rep- resentation does not hav e enough capacity to en- code a long sentence with complicated structure and meaning. In order to encode a variable-length sequence, a neural network may “sacrifice” some of the important topics in the input sentence in or- der to remember others. This is in stark contrast to the con ventional phrase-based machine translation system (Koehn et al., 2003). As we can see from Fig. 5, the con ventional system trained on the same dataset (with additional monolingual data for the language model) tends to get a higher BLEU score on longer sentences. In fact, if we limit the lengths of both the source monolingual data for a 4-gram language model. Source She explained her new position of foreign affairs and security policy representative as a reply to a question: ”Who is the European Union? Which phone number should I call?”; i.e. as an important step to unification and better clarity of Union’ s policy to wards countries such as China or India. Reference Elle a e xpliqu ´ e le nouv eau poste de la Haute repr ´ esentante pour les aff aires ´ etrang ` eres et la politique de d ´ efense dans le cadre d’une r ´ eponse ` a la question: ”Qui est qui ` a l’Union europ ´ eenne?” ”A quel num ´ ero de t ´ el ´ ephone dois-je appeler?”, donc comme un pas important v ers l’unicit ´ e et une plus grande lisibilit ´ e de la politique de l’Union face aux ´ etats, comme est la Chine ou bien l’Inde. RNNEnc Elle a d ´ ecrit sa position en mati ` ere de politique ´ etrang ` ere et de s ´ ecurit ´ e ainsi que la politique de l’Union europ ´ eenne en mati ` ere de gouvernance et de d ´ emocratie . grCon v Elle a expliqu ´ e sa nouvelle politique ´ etrang ` ere et de s ´ ecurit ´ e en r ´ eponse ` a un certain nombre de questions : ”Qu’est-ce que l’Union europ ´ eenne ? ” . Moses Elle a expliqu ´ e son nouveau poste des aff aires ´ etrang ` eres et la politique de s ´ ecurit ´ e repr ´ esentant en r ´ eponse ` a une question: ”Qui est l’Union europ ´ eenne? Quel num ´ ero de t ´ el ´ ephone dois-je appeler?”; c’est comme une ´ etape importante de l’unification et une meilleure lisibilit ´ e de la politique de l’Union ` a des pays comme la Chine ou l’Inde . Source The inv estigation should be complete by the end of the year when the findings will be presented to Deutsche Bank’ s board of managing directors - with recommendations for action. Reference L ’examen doit ˆ etre termin ´ e d’ici la fin de l’ann ´ ee, ensuite les r ´ esultats du conseil d’administration de la Deutsche Bank doiv ent ˆ etre pr ´ esent ´ es - av ec recommandation, d’ habitude. RNNEnc L ’ ´ etude de vrait ˆ etre termin ´ ee ` a la fin de l’ ann ´ ee, lorsque les conclusions seront pr ´ esent ´ ees au conseil d’administration de la Deutsche Bank, conseil d’association av ec des mesures. grCon v L ’enqu ˆ ete devrait ˆ etre termin ´ ee ` a la fin de l’ann ´ ee o ` u les conclusions seront pr ´ esent ´ ees par le conseil d’administration de la BCE ` a la direction des recommandations. Moses L ’enqu ˆ ete de vrait ˆ etre termin ´ e d’ici la fin de l’ann ´ ee lorsque les r ´ esultats seront pr ´ esent ´ es ` a la Deutsche Bank conseil des directeurs g ´ en ´ eraux - av ec des recommandations . Source And there are thorny mechanical questions that must be resolved during that time, like how to bal- ance the state’ s mandate of ”adequate access” to licensed marijuana with its prohibitions on cannabis businesses within 1,000 feet of a school, park, playground or child care center . Reference Pendant ce temps, des questions pratiques restent en suspens: comment ´ equilibrer le mandat de l’ ´ etat qui garantit un acc ` es appropri ´ e ` a la marijuana agr ´ e ´ ee et interdit l’installation de commerces de vente de cannabis dans un rayon de 30 km autour d’une ´ ecole, d’un parc, d’un terrain de jeu ou d’une cr ` eche. RNNEnc Il y a des questions pr ´ eventi ves qui se posent quant ` a l’ ´ equilibre des droits de l’enfant dans les limites d’une entreprise de collecte de sang. grCon v De fac ¸ on g ´ en ´ erale, il y a des raisons de s ´ ecurit ´ e pour que les entreprises aient acc ` es ` a des milliers de centres de p ˆ eche, d’eau ou de recherche. Moses Et il y a des probl ` emes m ´ ecaniques complexes qui doivent ˆ etre r ´ esolues au cours de cette p ´ eriode, comme la mani ` ere d’ ´ equilibrer le mandat de ”l’acc ` es ad ´ equat” permis de marijuana avec l’interdiction du cannabis aux entreprises de 1000 pieds d’une ´ ecole de jeu ou de parc, le service de garde. (a) Long Sentences Source There is still no agreement as to which election rules to follow . Reference T outefois il n’existe toujours pas d’accord selon quel r ` eglement de vote il f aut proc ´ eder . RNNEnc Il n’y a pas encore d’accord sur les r ` egles ´ electorales. grCon v Il n’y a pas encore d’accord sur la question des ´ elections ` a suivre. Moses Il y a toujours pas d’accord sur l’ ´ election des r ` egles ` a suivre. Source Many of these ideas may ha ve been creativ e, but the y didn’t necessarily work. Reference Beaucoup de ces id ´ ees ´ etaient cr ´ eativ es mais elles n’ont pas forc ´ ement fonctionn ´ e. RNNEnc Bon nombre de ces id ´ ees ont peut- ˆ etre ´ et ´ e cr ´ eatrices, mais elles ne s’appliquaient pas n ´ ecessairement. grCon v Beaucoup de ces id ´ ees peuvent ˆ etre cr ´ eativ es, mais elles n’ont pas fonctionn ´ e. Moses Beaucoup de ces id ´ ees ont pu ˆ etre cr ´ eatif, mais ils n’ont pas n ´ ecessairement. Source There is a lot of consensus between the Left and the Right on this subject. Reference C’est qu’il y a sur ce sujet un assez large consensus entre gauche et droite. RNNEnc Il existe beaucoup de consensus entre la gauche et le droit ` a la question. grCon v Il y a un consensus entre la gauche et le droit sur cette question. Moses Il y a beaucoup de consensus entre la gauche et la droite sur ce sujet. Source According to them, one can find any weapon at a lo w price right now . Reference Selon eux, on peut trouver aujourd’hui ` a Moscou n’importe quelle arme pour un prix raisonnable. RNNEnc Selon eux, on peut se trouver de l’arme ` a un prix trop bas. grCon v En tout cas, ils peuvent trouver une arme ` a un prix tr ` es bas ` a la fois. Moses Selon eux, on trouve une arme ` a bas prix pour l’instant. (b) Short Sentences T able 2: The sample translations along with the source sentences and the reference translations. 0 10 20 30 40 50 60 70 80 Sen tence length 0 5 10 15 20 BLEU score Source text Reference text Both (a) RNNenc 0 10 20 30 40 50 60 70 80 Sen tence length 0 5 10 15 20 BLEU score Source text Reference text Both (b) grCon v 0 2 4 6 8 10 Max. n um b er of unkno wn w ords 10 12 14 16 18 20 22 24 BLEU score Source text Reference text Both (c) RNNenc Figure 4: The BLEU scores achie ved by (a) the RNNenc and (b) the grCon v for sentences of a given length. The plot is smoothed by taking a windo w of size 10. (c) The BLEU scores achie ved by the RNN model for sentences with less than a gi ven number of unkno wn words. sentence and the reference translation to be be- tween 10 and 20 w ords and use only the sentences with no unknown words, the BLEU scores on the test set are 27.81 and 33.08 for the RNNenc and Moses, respecti vely . Note that we observed a similar trend ev en when we used sentences of up to 50 w ords to train these models. 5.2 Qualitative Analysis Although BLEU score is used as a de-facto stan- dard metric for ev aluating the performance of a machine translation system, it is not the perfect metric (see, e.g., (Song et al., 2013; Liu et al., 2011)). Hence, here we present some of the ac- tual translations generated from the two models, RNNenc and grCon v . In T able. 2 (a)–(b), we show the translations of some randomly selected sentences from the de- velopment and test sets. W e chose the ones that hav e no unknown words. (a) lists long sentences (longer than 30 words), and (b) short sentences (shorter than 10 words). W e can see that, despite the difference in the BLEU scores, all three mod- els (RNNenc, grCon v and Moses) do a decent job at translating, especially , short sentences. When the source sentences are long, howe ver , we no- tice the performance degradation of the neural ma- chine translation models. Additionally , we present here what type of structure the proposed gated recursi ve con volu- tional network learns to represent. W ith a sample sentence “Obama is the President of the United States” , we present the parsing structure learned by the grConv encoder and the generated transla- tions, in Fig. 6. The figure suggests that the gr- Con v extracts the vector representation of the sen- 0 10 20 30 40 50 60 70 80 Sen tence length 0 5 10 15 20 25 30 35 40 BLEU score Source text Reference text Both Figure 5: The BLEU scores achiev ed by an SMT system for sentences of a giv en length. The plot is smoothed by taking a window of size 10. W e use the solid, dotted and dashed lines to show the ef fect of different lengths of source, reference or both of them, respecti vely . tence by first merging “of the United States” to- gether with “is the Pr esident of ” and finally com- bining this with “Obama is” and “. ” , which is well correlated with our intuition. Despite the lower performance the grCon v sho wed compared to the RNN Encoder–Decoder , 5 we find this property of the grCon v learning a grammar structure automatically interesting and belie ve further in vestigation is needed. 6 Conclusion and Discussion In this paper , we have in vestigated the property of a recently introduced family of machine trans- 5 Howe ver , it should be noted that the number of gradient updates used to train the grCon v was a third of that used to train the RNNenc. Longer training may change the result, but for a fair comparison we chose to compare models which were trained for an equal amount of time. Neither model was trained to con vergence. Obama is the President of the United States . + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + T ranslations Obama est le Pr ´ esident des ´ Etats-Unis . (2.06) Obama est le pr ´ esident des ´ Etats-Unis . (2.09) Obama est le pr ´ esident des Etats-Unis . (2.61) Obama est le Pr ´ esident des Etats-Unis . (3.33) Barack Obama est le pr ´ esident des ´ Etats-Unis . (4.41) Barack Obama est le Pr ´ esident des ´ Etats-Unis . (4.48) Barack Obama est le pr ´ esident des Etats-Unis . (4.54) L ’Obama est le Pr ´ esident des ´ Etats-Unis . (4.59) L ’Obama est le pr ´ esident des ´ Etats-Unis . (4.67) Obama est pr ´ esident du Congr ` es des ´ Etats-Unis .(5.09) (a) (b) Figure 6: (a) The visualization of the grCon v structure when the input is “Obama is the Pr esident of the United States. ” . Only edges with gating coefficient ω higher than 0 . 1 are shown. (b) The top- 10 translations generated by the grCon v . The numbers in parentheses are the neg ative log-probability of the translations. lation system based purely on neural networks. W e focused on e valuating an encoder–decoder ap- proach, proposed recently in (Kalchbrenner and Blunsom, 2013; Cho et al., 2014; Sutskev er et al., 2014), on the task of sentence-to-sentence trans- lation. Among many possible encoder–decoder models we specifically chose two models that dif- fer in the choice of the encoder; (1) RNN with gated hidden units and (2) the newly proposed gated recursi ve con volutional neural network. After training those two models on pairs of English and French sentences, we analyzed their performance using BLEU scores with respect to the lengths of sentences and the existence of un- kno wn/rare words in sentences. Our analysis re- vealed that the performance of the neural machine translation suffers significantly from the length of sentences. Ho we ver , qualitatively , we found that the both models are able to generate correct trans- lations very well. These analyses suggest a number of future re- search directions in machine translation purely based on neural networks. Firstly , it is important to find a way to scale up training a neural network both in terms of com- putation and memory so that much larger vocab u- laries for both source and target languages can be used. Especially , when it comes to languages with rich morphology , we may be required to come up with a radically dif ferent approach in dealing with words. Secondly , more research is needed to prev ent the neural machine translation system from under - performing with long sentences. Lastly , we need to explore different neural architectures, especially for the decoder . Despite the radical dif ference in the architecture between RNN and grCon v which were used as an encoder , both models suffer from the curse of sentence length . This suggests that it may be due to the lack of representational power in the decoder . Further inv estigation and research are required. In addition to the property of a general neural machine translation system, we observed one in- teresting property of the proposed gated recursiv e con volutional neural network (grCon v). The gr- Con v was found to mimic the grammatical struc- ture of an input sentence without any supervision on syntactic structure of language. W e belie ve this property mak es it appropriate for natural language processing applications other than machine trans- lation. Acknowledgments The authors would like to acknowledge the sup- port of the follo wing agencies for research funding and computing support: NSERC, Calcul Qu ´ ebec, Compute Canada, the Canada Research Chairs and CIF AR. References Amittai Axelrod, Xiaodong He, and Jianfeng Gao. 2011. Domain adaptation via pseudo in-domain data selection. In Pr oceedings of the A CL Conference on Empirical Methods in Natural Language Pr ocessing (EMNLP) , pages 355–362. Association for Compu- tational Linguistics. Nicolas Boulanger-Le wandowski, Y oshua Bengio, and Pascal V incent. 2013. Audio chord recognition with recurrent neural networks. In ISMIR . Kyungh yun Cho, Bart v an Merrienboer , Caglar Gul- cehre, Fethi Bougares, Holger Schwenk, and Y oshua Bengio. 2014. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In Pr oceedings of the Empiricial Methods in Natural Language Pr ocessing (EMNLP 2014) , October . to appear . Alex Grav es. 2012. Sequence transduction with re- current neural networks. In Proceedings of the 29th International Conference on Machine Learning (ICML 2012) . A. Grav es. 2013. Generating sequences with recurrent neural networks. arXiv: 1308.0850 [cs.NE] , August. S. Hochreiter and J. Schmidhuber . 1997. Long short- term memory . Neural Computation , 9(8):1735– 1780. Nal Kalchbrenner and Phil Blunsom. 2013. T wo re- current continuous translation models. In Pr oceed- ings of the ACL Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 1700–1709. Association for Computational Linguis- tics. Philipp Koehn, Franz Josef Och, and Daniel Marcu. 2003. Statistical phrase-based translation. In Pr o- ceedings of the 2003 Confer ence of the North Amer- ican Chapter of the Association for Computational Linguistics on Human Language T echnology - V ol- ume 1 , N AACL ’03, pages 48–54, Stroudsbur g, P A, USA. Association for Computational Linguistics. Chang Liu, Daniel Dahlmeier , and Hwee T ou Ng. 2011. Better ev aluation metrics lead to better ma- chine translation. In Pr oceedings of the Confer ence on Empirical Methods in Natural Language Pr o- cessing , pages 375–384. Association for Computa- tional Linguistics. Xingyi Song, Tre vor Cohn, and Lucia Specia. 2013. BLEU deconstructed: Designing a better MT ev al- uation metric. In Pr oceedings of the 14th Interna- tional Conference on Intelligent T ext Pr ocessing and Computational Linguistics (CICLING) , March. Ilya Sutskev er , Oriol V inyals, and Quoc Le. 2014. Se- quence to sequence learning with neural networks. In Advances in Neural Information Processing Sys- tems (NIPS 2014) , December . Matthew D. Zeiler . 2012. ADADEL T A: an adap- tiv e learning rate method. T echnical report, arXiv 1212.5701.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment