신경망 기계 번역 특성 분석 인코더 디코더 접근법
본 논문은 RNN 기반 인코더‑디코더와 새롭게 제안된 게이트형 재귀 컨볼루션 신경망(grConv)을 이용한 프랑스어‑영어 번역 성능을 분석한다. 짧은 문장과 어휘가 충분히 알려진 경우에는 양 모델이 좋은 BLEU 점수를 보이지만, 문장이 길어지거나 미지의 단어가 늘어날수록 성능이 급격히 저하된다. 또한 grConv는 입력 문장의 구문 구조를 자동으로 학습하는 특징을 보인다.
저자: Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau
본 논문은 신경망 기반 기계 번역(Neural Machine Translation, NMT)의 특성을 두 가지 인코더‑디코더 모델을 통해 체계적으로 분석한다. 첫 번째 모델은 기존 연구에서 제안된 RNN Encoder‑Decoder(Cho et al., 2014)이며, 두 번째 모델은 저자들이 새롭게 고안한 게이트형 재귀 컨볼루션 신경망(gated recursive convolutional neural network, grConv)이다. 두 모델 모두 프랑스어‑영어 번역 작업에 적용되었으며, 각각의 구조적 차이와 번역 품질에 미치는 영향을 정량적인 BLEU 점수와 정성적인 사례 분석을 통해 평가한다.
1. **배경 및 동기**
NMT는 전통적인 통계적 기계 번역(SMT)과 달리 전체 시스템을 하나의 신경망으로 학습한다는 점에서 메모리 효율성과 공동 최적화라는 장점을 가진다. 그러나 아직까지 NMT가 어떤 종류의 문장에 강하고, 어떤 상황에서 약한지에 대한 체계적인 연구는 부족하다. 특히, 문장 길이와 어휘 범위가 번역 성능에 미치는 영향을 명확히 규명하고자 한다.
2. **모델 설계**
- **RNN Encoder‑Decoder**: 입력 문장을 순차적으로 처리하는 GRU 기반 인코더가 고정 길이 벡터 z를 생성하고, 동일한 GRU 구조를 가진 디코더가 z를 초기 상태로 삼아 목표 언어 문장을 생성한다. GRU는 reset와 update 게이트를 통해 장기 의존성을 관리한다.
- **gated recursive convolutional neural network (grConv)**: 입력 시퀀스를 재귀적으로 합치는 1‑D 컨볼루션 레이어를 사용한다. 각 레이어는 세 개의 게이트(중심 ω_c, 좌 ω_l, 우 ω_r)를 통해 현재 노드가 새로운 합성 결과, 왼쪽 자식, 오른쪽 자식 중 어느 것을 선택할지 결정한다. 이 메커니즘은 입력에 따라 동적으로 트리 구조를 형성하게 하며, 사실상 비지도 파싱 효과를 제공한다. 디코더는 RNNenc와 동일한 GRU를 사용한다.
3. **데이터 및 실험 설정**
- **코퍼스**: Europarl, 뉴스 코멘터리, UN 등 다양한 출처를 합쳐 3억 48백만 문장을 구축했으며, 학습 시에는 양쪽 문장이 30단어 이하인 쌍만 사용하였다. 어휘는 각각 상위 30,000개 단어로 제한하고, 나머지는 UNK 토큰으로 대체하였다.
- **학습**: 두 모델 모두 620차원 임베딩을 사용했으며, RNNenc는 1,000개의 은닉 유닛, grConv는 2,000개의 은닉 유닛을 배치했다. 최적화는 AdaDelta를 적용했으며, 전체 학습 시간은 약 110시간(수십만 배치)이다.
- **디코딩**: 빔 서치(빔 폭 10)를 이용해 가장 높은 로그 확률을 갖는 번역을 선택했으며, UNK 토큰이 포함된 후보는 배제하였다.
4. **결과**
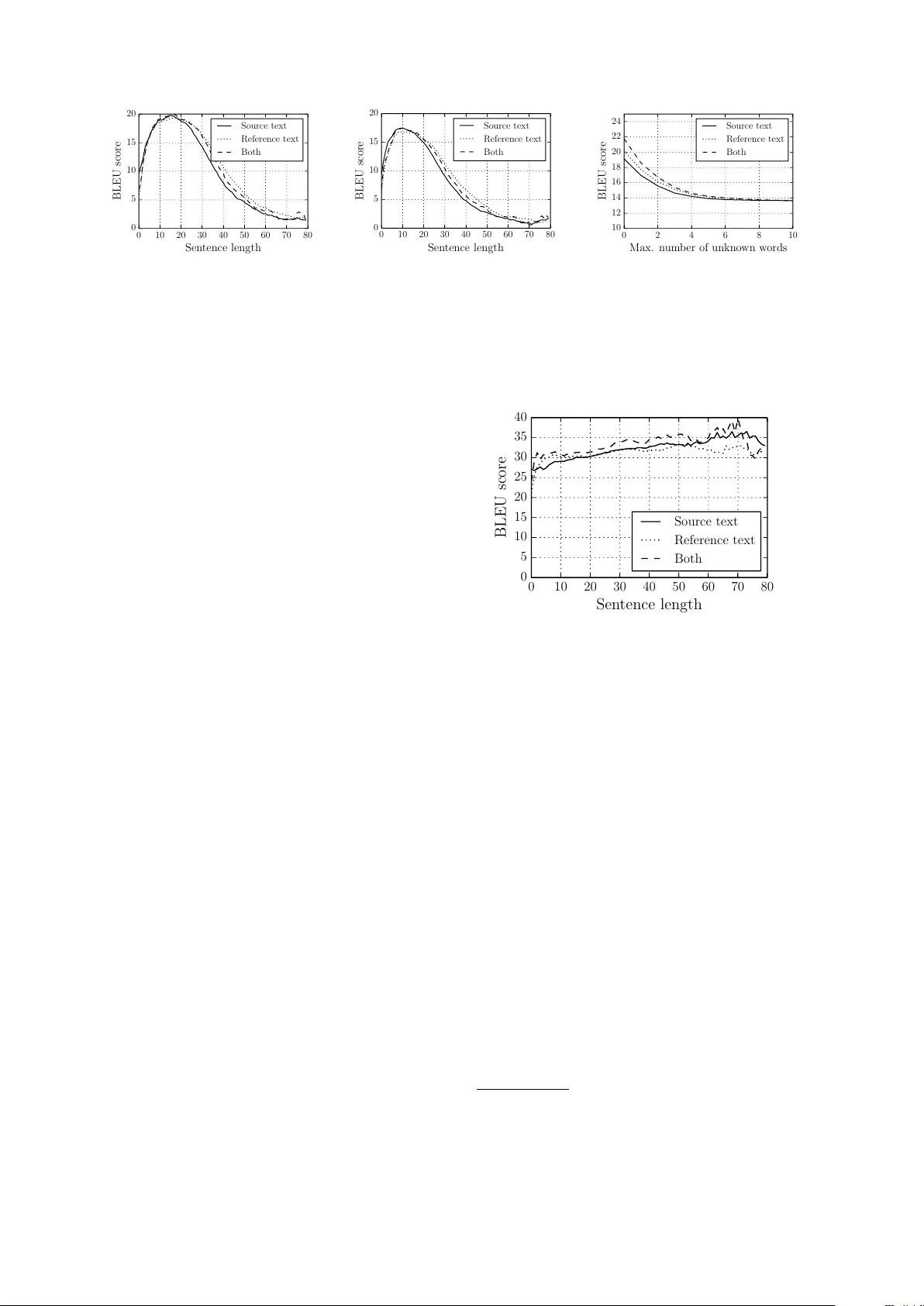
- **BLEU 점수**: 전체 테스트 셋에서 RNNenc는 13~20점, grConv는 10~18점을 기록했으며, 전통적인 SMT 시스템(Moses)은 30점대의 BLEU를 유지했다. 특히 UNK 토큰이 전혀 없는 경우, RNNenc는 21~24점, grConv는 17~22점을 달성해 격차가 크게 줄어들었다.
- **문장 길이 영향**: 짧은 문장(10~20단어)에서는 두 모델 모두 비교적 높은 점수를 보였지만, 길이가 30단어에 가까워질수록 BLEU가 급격히 하락했다. 이는 고정 길이 벡터 z가 긴 문장의 모든 정보를 충분히 압축하지 못한다는 가설을 뒷받침한다.
- **UNK 토큰 영향**: UNK 토큰 수가 증가할수록 성능이 급격히 저하되었다. 어휘 규모 확대가 향후 NMT 성능 향상의 핵심 과제로 부각된다.
- **구조 학습**: grConv는 학습 과정에서 입력 문장의 구문 트리를 자동으로 형성한다는 정성적 관찰이 있었다. 이는 컨볼루션 기반 인코더가 순환 구조보다 문법적 정보를 더 효과적으로 포착할 가능성을 시사한다.
5. **논의 및 향후 연구**
현재의 인코더‑디코더 구조는 고정 길이 표현에 의존하기 때문에 장문과 복잡한 구문을 처리하는 데 한계가 있다. 이를 극복하기 위한 방안으로는 (1) 어텐션 메커니즘을 도입해 가변 길이 컨텍스트를 제공, (2) 어휘 집합을 확대하거나 서브워드 단위 모델링을 적용, (3) grConv와 같은 재귀적 구조를 더욱 깊게 설계해 명시적인 트리 구조를 학습하는 방법 등이 제시된다. 또한, NMT와 기존 SMT를 결합하는 하이브리드 접근법이 BLEU 점수 향상에 기여할 수 있음을 실험적으로 확인하였다.
결론적으로, 본 연구는 NMT가 짧고 어휘가 충분히 커버된 문장에서는 경쟁력 있는 성능을 보이지만, 문장 길이와 어휘 부족에 취약함을 명확히 규명하였다. 향후 연구는 구조적 인코더 설계와 어휘 확장, 그리고 어텐션 기반 모델을 통해 이러한 약점을 보완함으로써 NMT가 기존 SMT를 넘어서는 번역 품질을 달성할 수 있는 길을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기