Conditional Restricted Boltzmann Machines for Cold Start Recommendations
Restricted Boltzman Machines (RBMs) have been successfully used in recommender systems. However, as with most of other collaborative filtering techniques, it cannot solve cold start problems for there is no rating for a new item. In this paper, we fi…
Authors: Jiankou Li, Wei Zhang
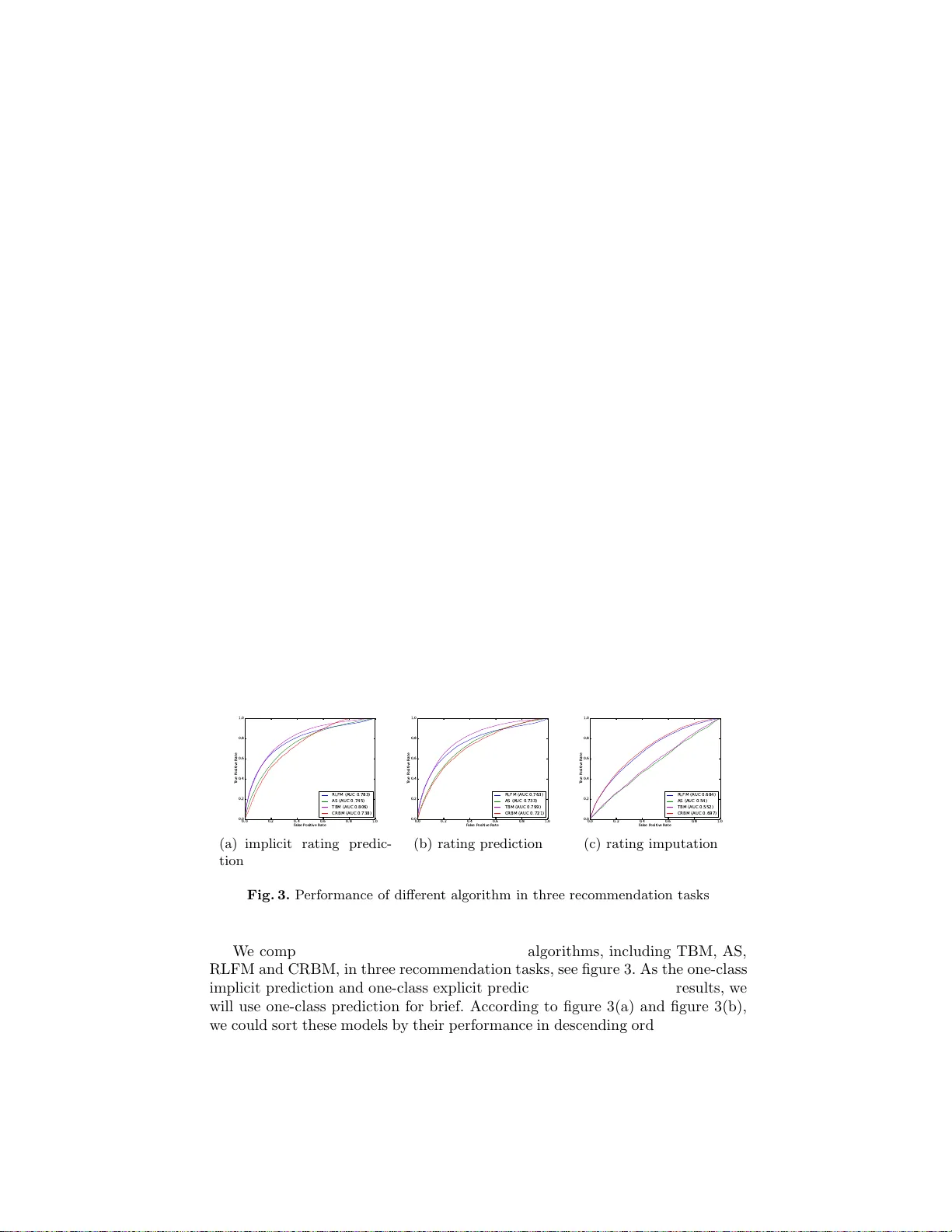
Conditional Restricted Boltzmann Mac hines for Cold Start Re commendations Jiankou Li 1 , 2 and W ei Zhang 1 , 2 1 State Key Lab oratory of Computer Science, I n stitute of Soft ware, Chinese Academy of Sciences, P .O. Bo x 8718, Beijing, 100190, P .R.China 2 School of Information Science and Engineering, Universit y of Chinese Academ y of Sciences, P .R.China Abstract. Restricted Boltzman Mac hines (RBMs) hav e b een success- fully used in recommender systems. Ho wev er, as with most of other c ol- laborative filtering tec hniques, it cannot sol ve cold start p roblems f or there is no rating for a new item. In this p aper, we first apply condi- tional RBM (CRBM) which could take ex tra information into account and sho w that CRBM could solve cold start problem very well, esp e- cially for rating prediction task. CRBM naturally com bine th e conten t and colla b orativ e data under a single framewo rk which could b e fi t ted effectivel y . Exp erimen ts sho w that CRBM can b e compared fav ourably with matrix factori zation mo dels, while hidden features learned from the former mo dels are more easy to b e in terpreted. Keywords: cold start, conditional RBM, rating p rediction 1 In tro duction The cold start problem g enerally means making reco mmendations for new items or new users. It has attracted attentions of many researchers for its impor tance. Collab orative filtering(CF) techniques make prediction of unknown preference by known preferences of a group of users [22]. Pre fer ences her e ma ybe explicit movie rating or implicit item buying in the online s e rvices. Though CF tec hnique has b een successfully used in r ecommender system, when there is no rating fo r new items or new user s suc h metho ds b ecome inv alid. So pure CF could no t solve cold start problems. Different fr om CF, conten t-based tec hniques do no t suffer from the cold start problem, as they make recommendations based on co n ten t of items, e.g. actor s, genres of a mo vie is usua lly used. Ho w ever, a pur e conten t-based tec hniques only recommends items that a re similar to users’ previously consumed items and so its result lack diversit y [16]. A key step fo r so lving the co ld start problem is how to combine the col- lab orative information and conten t information. Hybrid tech niques reta in the adv antages of CF a s well as no t suffer from the cold s tart problem [1], [4], [6], [14], [1 9]. In the pape r, we firstly use condition r e stricted Boltzmann machines that co uld combine the collab orative infor mation and co n ten t informa tion na t- urally to s o lv e co ld start problem. RBMs are p ow erful undirected graphica l mo dels for rating pre dic tio n [1 8]. Different fro m dir ected graphica l models [1], [4], [6], [14], [19], whose exa ct in- ference is usually ha rd, inferring latent feature of RBMs is exac t and efficien t. An imp o rtant fea tur e of undirected g raphical model is that they do no t suffer the ’explaining-aw ay’ pro blem o f directed g raphical models [21]. What’s more impo rtan t is that RBMs co uld be efficiently trained using Contrastiv e Div er- gence [7], [8]. Bas ed on RBM, CRBM takes the extr a information in to account [24], [2 5]. The items conten t feature lik e acto rs, genres etc could be added into CRBM naturally , with little more extra fitting pro cedure. The remainder of this pap er is org anized a s follows. Section 2 is devoted to r elated work. Section 3 in tro duces the models w e used including RBM and CRBM. In section 4 w e show the results of our e x periments. Finally w e conclude the pape r with a summary and discuss the w ork in the future in section 5. 2 Related W ork Cold start problems hav e attracted lots of rese archers. The key step for solving cold sta rt problem is combining conten t feature with c o llabo rative filtering tec h- niques. On one hand, topic models could mo del con ten t information w ell. On the other ha nd, ma trix factoriza tio n is one of the mos t s uccessful techniques for collab orative. So most previous works for solving cold start problem are based on these two techn iques. Previous w ork [19] uses a probabilistic topic mo de l to solve the c o ld start problem in three step. Firstly , they map users into a latent space by features of their related items. Every user c ould b e repres en ted by some topics o f features . Then a ’folding-in’ algorithm is used to fold new items into a user-feature a spect mo del. Fina lly , the probabilit y of a user g iv en a new mo vie ( could be seen as some similarity measure) was calculated in o rder to make re c ommendation. Gantner et a ll pro pose a high-lev el framework for solving cold star t problem. They train a factorization model to learn the latent factors and then learn the mapping function fr om features of entities to their la ten t features [4]. This kind of mo del use the conten t featur e while r etain the adv a n tages of matrix factorizatio n [12], [15], [17] and could generalize well to other laten t factor models a nd mapping functions. Another matrix factorization base d mo del is the reg ression-base d laten t fac- tor mo del (RLFM). RLFM simultaneously incorp orate user features, item fea- tures, in to a single mo deling fr amew ork. Diff erent from [4], where the latent fac- tors’ lear ning phase and mapping phase a re sepa rated, a Gaussian prio r with a feature-base r egression was added to the latent factor s for r egularization. RLFM provided a mo deling framework thro ugh hierarchical mo dels which add mor e flexibility to the factorization methods. In [26], the co llabor ative filtering and probabilistic topic modeling were com- bined through laten t factor s. Making recommendatio ns is a pr oce s s o f balancing the influence of the conten t of articles and the librar ies o f the other users. T ec h- niques used for solving cold start proble m falling into the dire c ted graphica l mo dels include latent Dir ic hlet a lloca tion [2], [14], probabilistic latent s eman tic indexing [10] etc. Other technique for solving cold start problem include semi- sup e rvised [2 8], decisio n trees [23] etc. Besides directed graphical models , undirected graphical models a lso found application in recommender systems. A tied Boltzma nn machin e in [6] ca ptures the pairwise interactions b etw een items by features of items. Then a probability of new items could be giv en to users in order to be ranked. A more p o w erful model of undirected graphica l mo del is Restricted Boltzmann Machines which has found wide application. RBM was fir st introduced in [20] named as har monium. In [13], the Discriminative RBM w as successfully used for character re cognition and text classification. The most imp ortant s uc c ess o f RBMs are as initial training phase for deep neural netw orks [9] and as feature extra ctors for text and imag e [5]. [1 8] firstly in tro duce the RBM for colla bor ativ e filtering. In this pap er we will show its go o d p erformance for so lving cold start problem. 3 The Mo dels 3.1 Restricted Boltzmann Mac hines Fig. 1. I llustration of a restricted Boltzmann mac hine with b inary hidd en un its and binary visual units. In t his pap er, eac h RBM represen t s an mo vie, eac h visual u nit represents a user that has rated the item and eac h hidden un it represen ts a feature of mo vies. RBM is a tw o- la yer undirected gra phical mo del, see figure 1. It defines a join t distribution over visible v ariables v and a hidden v ariable h . In the cold sta rt situation, w e consider the ca s e where b oth v and h are bina ry vectors. RBM is a n energy- based mo del, whos e energ y function is given by E ( v , h ) = − M X m =1 a m v m − N X n =1 b n h n − M X m =1 N X n =1 v m h n W mn (1) where M is the nu mber of visual units, N is the num b er of hidden units, v m , h n are the binar y states of visible unit m and hidden unit n, a m , b n are their biases and W mn is the weight betw een v and h . Every joint configur a tion ( v , h ) has probability of the for m: p ( v , h ) = 1 Z e − E ( v ,h ) (2) where Z is the partition function given b y summing over all p ossible config- uration of ( v , h ): Z = X v, h e − E ( v ,h ) (3) F or a given visible vector v , the marginal pr obability of p ( v ) is given by p ( v ) = 1 Z X h e − E ( v ,h ) (4) The condition distribution of a visible unit given all the hidden units and the condition distribution of a hidden unit given all the visible units are as follows: p ( v m | h ) = σ ( a m + M X n =1 h n W mn ) (5) p ( h n | v ) = σ ( b n + N X m =1 v m W mn ) (6) where σ ( x ) = 1 / (1 + e − x ) is the logistic function. In this pap er, ea c h RBM represents a movie, each visua l unit represents a user tha t has rated the movie. This differs fr o m [18] where ea c h RBM r epresents a user and ea ch visua l unit r epresents a movie. All RBMs hav e the same n umber of hidden units and different num ber of visible units b ecause different movies are rated by differen t users. The corresp onding w eights a nd biases are tied together in all RBMS. So if tw o movies are rated b y the sa me p eople, then these t w o RBM hav e the same w eight s a nd biases . In other w ords, w e co uld say a ll movies use the same RBM while the missing v alue of user s that do no t rating a specific mo vie are igno red. This idea is similar to the matrix factorization based tec hnique [1 1], [15] that only mo del the obser v ing ratings and ignore the missing v a lues. 3.2 Learning RBM W e need learn the mo del by adjusting the w eights and bia ses to low er the energy of the item w hile in the same time arise the ener gy of other configuratio n. This could b e done by p erforming the gradient ascent in the log-likelihoo d of eq. 4, T X t =1 ln p ( v t | θ ) (7) where T is the num b er of movies, θ = { w, a, b } is the parameter of RBM. The gradient is as follows, ∂ l og p ( v ) ∂ a m = h v m i data − h v m i model (8) ∂ l og p ( v ) ∂ b n = h h n i data − h h n i model (9) ∂ l og p ( v ) ∂ W mn = h v m h n i data − h v m h n i model (10) where hi represents the exp ectations under the distribution of data and mo del resp ectively . hi data is generally easy to get, while hi model cannot b e computed in less tha n exp onent ial time. So we use the Contrastive Divergence (CD) algorithm which is muc h faster [8]. Instead of hi model , the CD algor ithm use hi r econ , the ’reconstructio n’ pro duced by se tting each v m to 1 with proba bility in equation 5. Indeed, maximizing the log likelihoo d of the data is equiv alent to minimizing the Kullback-Liebler div ergence b et ween the data distribution and the mo del distribution. CD o nly minimizing the data distribution a nd the reconstruction distribution, and usually the o ne step reconstruction w orks w ell [18]. The up date rule is as fo llows. a τ +1 m = a τ m + ǫ ( h v m i data − h v m i T 1 ) (11) b τ +1 n = a τ m + ǫ ( h h n i data − h h n i T 1 ) (12) W τ +1 mn = W τ mn + ǫ ( h v m h n i data − h v m h n i T 1 ) (13) where T 1 represent the one step r econstruction, ǫ is the learning rate. 3.3 Conditional Restricted Boltzmann Mac hines (CRBMs ) The ab ov e mo del could b e used in co llabor ative filtering as in [18]. But it b ecomes inv a lid for new items as there ar e no rating and the corresp ond hidden units could not b e activ ated. W e m ust add ex tra informatio n to this model for solving cold start pr oblem. Conditional RBM (CRBM) c o uld ea sily take these ex tra information int o a ccount [24], [2 5]. F or ea ch movie we use a bina ry vector f to deno te its feature and then add directed connection from f to its hidden factors h . So the joint distr ibutio n over ( v , h ) co nditio na l on f is defined, see figur e 2. The ener gy function b ecomes the following form. E ( v , h, f ) = − M X m =1 a m v m − N X n =1 b n h n − M X m =1 N X n =1 v m h n W mn − K X k =1 N X n =1 f k h n U kn (14) Fig. 2. Illustration of a conditional restricted Boltzmann machine with binary hidden units and binary visual un its The conditional distinction of v m given hidden units is just the sa me as eq.5. The conditional distribution of h n bec omes the following form. E ( h n | f , v ) = σ ( b n + M X m =1 v m w mn + K X k =1 f k U kn ) (15) In CRBM, the hidden states ar e affected b y the feature vector f . When we hav e new items, there ar e no rating by users, but the hidden state could still b e activ ated by f , then the visible unit could b e reconstr uc ted as the usual RB M. What’s more, this do es not add muc h extra computation. Learning the weigh t matrix U is just like lea rning the bias of hidden unit. In our exper imen ts, w e a dd an r e gularization term to the normal gra die nt known as w eig h t-decay [7]. W e used the ’ L 2 ’ p enalty function to avoid large weight s. The upda te r ule b ecomes follows. U τ +1 kn = U τ kn + ǫ (( h h n i data − h h n i T 1 ) f k + λU kn ) (16) W eight-decay fo r U brings so me a dv antages. On one hand, it improv es the per formance of CRBM by avoid ov er fitting in the train process . On the other hand, small weight can b e mo r e interpretable than very large v alues whic h will be s ho wn in section 4. More reasons for w eight-deca y could be found in [7]. 4 Exp erimen t 4.1 DataSet W e illustr ate the results on b enchmark data sets (Mo vieLens-100 K ). In this datas et, there are 1 00K ratings betw een 943 users and 1,6 82 mo vies. As we mainly foc us on the new item cold star t pr oblem, we use the items fea tures only (a ctors a nd genres). W e r a ndomly split the items into t wo sets . In the test set there a re 333 movies which do not app e ar in the train set to use d for cold start. The data s et set co mes from the Gr oupLens pro ject and the items’ feature are downloaded from the Internet Movie Database (http://www.imdb.com). 4.2 Recommendation T ask In this section, we ma k e a dis ting uish among different recommendation tas k in real world applications . There ar e mainly three recommendation tasks dep ending on the data w e have. They are one-clas s explicit prediction, one- class implicit prediction, and rating pr e diction. 1. One - class explicit prediction This task is usually aris ed wher e w e ha ve data that o nly con tains explict po ssitive feedback. Our goal is to predict whether a user likes an item or not. In this paper , we conv ert the o riginal integer rating v alues from 1 to 5 int o bina ry state 0 and 1 . Concretely , if a rating is bigger than 3, we take it as 1, otherwis e we take it a s 0 . As a result, all the ra ting not bigger than 3 or missing rating are taken to b e 0. 2. One - class implicit pre dic tio n Implicit rating means s o me feedback o f a user which do es not g iv e explic it preference, e.g. the purchase histor y , watc hing habits and browsing activity etc. In this ta sk w e would pr edict probability tha t a use r will rate a g iv en movie. In this pap er, all the observed ra ting s are tak en to b e 1 and all the missing rating are taken to b e 0. 3. Rating prediction Rating imputation is to predict whether a user will like an item or not condition on his implicit rating. Usually this could be used to ev aluate an algorithm’s p erformance by holding out some rating from training da ta and then predicting their ratings. In the tra in phase, all missing v alue are ignored and only the observed v alue ar e used. In the test phase, only the obser v ed v alue in the test set are ev aluated. This is very differ e n t from the former t wo taskes where all missing v alue are taken to be 0 . In the firs t tw o recommenda tion taskes all the missing v alues are taken to b e zeros. As a r esult, the rating matr ix bec o mes dense. While in the rating pr edic- tion task , rating ma trix could r emain spar s e. [19] also give three recommendation task which ar e similar to o urs. It’s important to make such a distinction as mo d- els can giv e notable differen t performanc e in difference task. In this paper we compare a lgorithms on these tasks and analy s is their p erformance. 4.3 Ev aluation Metrics Precisio n- recall cur v e and roo t mean sq uare erro r (RMSE) are tw o p opular ev al- uation metrics. But both of them may b e pitfall when the data class has skew distribution. As we k no w, the rating data is usua lly sparse and each user only rates a very s ma ll fraction of all the items. A trivial idea is that we take all the pair a s 0, then we will get a not v ery bad res ult accor ding RMSE or precis ion- recall curve. Besides they also suffer from the problem of zero rating’s uncertain. Zero rating’s uncertain here mea ns that a miss ing rating ma y either indicate the user do es not like the item or that the user doe s not know the item at all. In this paper, we use receiver o pera ting characteristics (R O C) graph to ev al- uate the per formance of different mo dels. ROC graphs hav e long b een used for organizing classifiers and visualizing their p erformance . One attractive proper ty of ROC cur v e is that they are insensitive to c hanges in class distribution. W e could also reduce R OC per formance to a sing le scala r v alue to compare cla ssi- fiers, that is the ar ea under the ROC curve (AUC) [3]. 4.4 Baselines In this pap er, we mainly fo cus on the cold start pr oblem. As there are so many techn iques for reco mmender systems, w e select three typical mo dels as our base- lines. They are asp ect mo del (AS)[19], tied Boltzmann machine (TBM)[6] and regres s ion-based latent factor mo del (RLFM) [1 ]. W e select these three mo dels bec ause they b elong to disc r ete latent factor mo del, contin uous latent factor mo del and undirected graphical mo dels resp ectiv ely . They repre s en t three direc- tions fo r sovling cold star t problems. The former tw o mo dels b oth of which ar e latent fa ctor mo dels b elong to the directed gra phical mo dels. Their difference mainly lie in the type of latent factors. I n the as pect mo del, the latent factor is discrete, so asp ect mo del is a mixture model indeed. RLFM is strongly cor r elated with SVD style matrix factorization metho ds whe r e the latent fac to rs are contin uous. TBM is another t yp e of mo del b elonging to the undirected gra phical mo del which dir ectly mo dels the relationship be tween items. 4.5 Result 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 F a lse P osi tiv e R ate 0 .0 0 .2 0 .4 0 .6 0 .8 1.0 T ru e P ositive R a te R L F M (A U C 0 . 783 ) A S (A U C 0. 745) T B M (A U C 0. 806 ) CR B M (A U C 0. 738) (a) implicit rating predic- tion 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 F a lse P ositive R a te 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 T ru e P ositive R a te R L FM (A U C 0. 763) A S (A U C 0. 733) T B M (A U C 0. 799) C R B M (A U C 0. 7 21) (b) rating prediction 0 .0 0 .2 0 .4 0 .6 0.8 1 .0 F a lse P ositive R a te 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 T ru e P ositive R a te R L FM (A U C 0. 684) A S (A U C 0. 54) T B M (A U C 0. 552) C R B M (A U C 0. 6 97) (c) rating imputation Fig. 3. Performance of different alg orithm in t hree recommendation tasks W e compare the p erformance of thes e four algor ithms, including TBM, AS, RLFM and CRBM, in three recommendatio n task s , see figure 3. As the o ne - class implicit predictio n and one-class explicit prediction give v ery similar results, we will us e one-cla ss prediction for br ief. Acco rding to figure 3 (a) and figure 3(b), we could sor t these mo dels by their p erformance in descending or der and ge t the result (TBM, RLFM, AS, C RB M). Ho w ev er, w e get almost an opp osite result when conside r ing figure 3(c). In the following, we discuss how the differenc e arise. A key difference betw een one- class pr e diction and rating prediction is ho w to deal with the missing v a lue. On one hand, all user -item pair s have a certain v alue in the one-class predic- tion task. All missing v alue b e t w een users and items take v alue 0 when we tr ain mo dels, see section 4.2. When predicting for cold start items, all user will b e con- sidered. The ROC curve is plotted using all pairs b etw een users and new items. On the other hand, we remain the missing state of the corresp onding user -item pair. When predicting for new items we only test users that hav e rated them. The ROC curve is plotted only using user-item pairs in the test set. Concretely , in one-cla ss predictio n there a re t wo states for eac h user-item pair 0 a nd 1 , the rating matrix is a dense. While in rating prediction, the rating matrix is sparse. This difference is of significance and pla y an imp o rtant role for ev aluate the per - formance of mo dels. In the f ormer cas e we need to predic t ratings betw een all user-item pairs. P roblems ar ise when w e fill 0 v alue to the missing pairs which will be illustr ated by the following example. Suppo se there ar e 1000 users and 1 000 movies in our data set. Without lo ss of generality , s uppose a user in the test set lik es 20 movies. Now w e nee d ev a luate an alg orithm using this da ta set. In the one-class prediction task a p erfect model should put these 20 mo vies o n the top of the pr ediction rank list, whic h means we assume this user lik e these 20 mo vies b etter than other movies. This assumption do es not see m ra tional. It’s very lik ely that the user likes the other movie better than these 20 ones. Putting these 2 0 ones in the top r ank list is not what we really wan t to do. W e want to know the correct rank of all 1 000 mo v ies, but this is impossible generally a s the other 900 mo vies rating ar e missing. So the problem of rating pre dic tio n we caus ed by its filling missing v alue. When comes to the r ating prediction, the situation is difference. W e only need predict whether a user will like or not for each of the test movie whic h a re all giv en in the test set. In other words, we just to give a ra nk list of the test se t but not the who le movie set. When w e do not kno w the correc t the answer, it’s b etter to ignore them tha n to take them as 0. In the ab ov e, we analy s is the main problem of rating prediction. W e must rea lize tha t w e could not ignore the missing in one-class prediction task just as in rating prediction. Rating prediction could not replace one-class prediction completely because the later is suitable when there are only p o sititv e feedbac k and no neg ativ e feedback. Collab orative filtering techn iques, such as use-based CF, item-ba s ed CF or matrix factorizatio n, b ecome inv a lid in such situation. These tech niques alwa ys give some trivial re s ult, all user liking all items. It’s easy for us to understand the p erformance of t hese four models as w e know ab out the differ ence and characteristic abo ut the recommendation task. Our data s e t contains b o th p ossitive feedback and neg ativ e feedback. So we should use the rating prediction task to e v aluate the p erforma nce. Thoug h AS mo del and TBM gives p erfect resutls in one-class prediction, they pr edict r atings in the dense way . They use miss ing v alues whic h includes uncertaint y . RFLM and CRBM could deal with the or ig in sparse raing matrix. If w e also sample some negative feedback from the missing pair, they co uld give go o d p erformance in the one-class pr ediction. In our exp erimen t we sample the negative feedback ab out 10 times the pos sitiv e sapmle. In the one-class prediction, we igno re the negative feedba ck and use fewer information bo th in t rain and test phase. RFLM and CRBM could deal with this situatio n. But in the opp osite, AS and TBM co uld only dea l with one-c lass problem, when we ignore the negative feedba c k in the train phase and pre dic t more informativ e result, they become inv a lid, just as the per formance o f AS and TBM in ra ting predictio n. 4.6 In terpretation In this sectio n, we will show the matrix U we have learned indeed make sense. The matrix U g iv es us more in tuition. Every row of U could b e seen as a feature of movies. A movie has a feature if the feature’s co rresp onding state is active. Every co lumn could b e seen as the corresp ondence v alue of actor or genre. So every mo vie has a repres e n tation b y actors. If tw o actors a r e similar (similar means user has similar r ating for movies of these actors), then the v alue of the distance of cor resp o nd column should b e small. So we could cluster the actors by U. In this paper w e use the k-mean algor ithm to cluster the ac tors. T able 1 illustra tes 8 clusters from our ex p eriment. In ea ch cluster, w e sho w 4 actors or genre s . we co uld see who and who are more s imilary with ea c h other and in which t ype of movie one actor is usually app ear. F or example, we se e Brad P itt and Kevin Ba con ar e more lik ely appear in the s ame type movie. Also, the main movie types comedy , crime , w ar etc. are partitioned into different clusters . T able 1. Cluster actors and genres based on U T opic N um b er Actors and Genres 1 Rance How ard,Park er Po sey ,James Earl Jones,John Cusac k 2 Children’s, Brad Pitt, K evin Bacon, W estern 3 Comedy , P aul Herman, Mic hael Rapap ort, John Diehl 4 R. Lee Ermey , Tim Roth, Dermot Mulroney , W ar 5 W allace Shaw n, James Gandolfini, Crime, Sci-Fi 6 Action, Bruce Willis, S igourney W eav er, Xander Berkel ey 7 Adven ture, Drama, John T ra volta, Da vid Pa ymer 8 Thriller, Paul Calderon, Gene Hackman, St eve Buscemi 5 Conclusion and F uture work In this paper, we a pply CRB M to solve the new items cold-start problem. In fact, it could be eas ily extended for new us er situation. W e compare CRBM with other three typical techniques and sho w that in the implicit ra ting prediction a nd rating prediction task, CRBM gives c omparable perfor mance, w hile in the r ating imputation task CRBM gives the best res ult. Acco rding our analysis, the rating imputation task is mor e coincidence with the real situation. So CRBM sho ws its super iority to other mo dels. Such results give us more indication for future resear ches. Firstly , RBM-based models are go o d at extra ct features , so we could give more easy explainable r esult. Secondly , this k inds of mo del are eas ily to b e applied for online application. When there are new items, we just need update the parameters by the r econstruction. Thirdly , RBM- ba sed mo del co uld be eas ily combined with deep models to extract more feature for recommendation [21]. Just a s [27], we do not wan t to show CRBM mo dels are mor e sup erior than the directed gra phical mo dels. But the ener gy-based model give us some more information in different application. In the future w e will use deep mo dels to solve the c old s tart pro blem. References 1. Deepak Agarw al and Bee-Chung Chen. Regression-based latent factor models. In Pr o c e e dings of the 15th ACM SIGKDD International Confer enc e on Know l e dge Disc overy and Data Mining , pages 19–28. ACM, 2009 . 2. Da vid M Blei, An drew Y Ng, and Mic hael I Jordan. Latent dirichlet allocation. the Journal of Machine L e arning R ese ar ch , 3:993–1022, 2003. 3. T om F aw cett. An in troduction to roc analysis. Pattern r e c o gnition l ette rs , 27(8):861– 874, 2006. 4. Zeno Gantner, Lucas Dru m on d , Christoph F reudenthaler, Steffen Rend le, and Lars Schmidt-Thieme. Learning attribu te-to-feature mappings for cold-start recommen- dations. In Intern ational Confer enc e on Data Mining , pages 176–185. IEEE, 2010. 5. P eter V Gehler, A lex D Holub, and Max W elling. The rate adapting p oisson mod el for information retriev al and ob ject recognition. In Pr o c e e dings of the 23r d International Conf er enc e on Machine le arning , p ages 337–34 4. ACM, 2006. 6. Asela Gu n a w ardana and Christopher Meek. Tied boltzmann mac hines for cold start recommendations. In Pr o c e e dings of the 2008 ACM c onfer enc e on R e c om- mender Systems , pages 19–26. ACM, 2008. 7. Geoffrey Hinton. A practical guide to training restricted b oltzmann machines. Momentum , 9(1):926, 2010. 8. Geoffrey E Hinton. T raining prod ucts of exp erts b y minimizing contra stive div er- gence. Neur al Computation , 14(8):1771–1 800, 2002. 9. Geoffrey E Hinton. T o recognize shap es, fi rst learn to generate images. Pr o gr ess in br ain r ese ar ch , 165:535–54 7, 2007. 10. Thomas Hofmann. Probabili stic latent semantic indexing. In Pr o c e e dings of the 22nd annual Internat ional A CM SIGIR Confer enc e on R ese ar ch and Development in I nformation R etrieval , pages 50–57. ACM, 1999 . 11. Y eh uda Koren. F actorizatio n meets the neighborho od : a m ultifaceted collab orativ e filtering mod el. In Pr o c e e dings of the 14th ACM SIGKDD international c onfer enc e on Know l e dge disc overy and data mini ng , pages 426–434. AC M, 2008. 12. Y eh uda K oren, Robert Bell, and Chris V olinsky . Matrix factorization techniques for recommender systems. Computer , 42(8):30– 37, 2009. 13. Hugo Laro chell e and Y oshua Bengio. C lassification using d iscriminativ e restricted b oltzmann mac h ines. In Pr o c e e dings of the 25th International Confer enc e on Ma- chine le arning , pages 536–543. ACM, 2008. 14. Jo vian Lin, Kazun ari Su giy ama, Min-Y en Kan, and T at-S en g Chua. Addressing cold-start in app recommendation: latent u ser models constructed from twi tter follo wers. In Pr o c e e dings of the 36th international ACM SIGIR Confer enc e on R ese ar ch and Development in Inf ormation R etrieval , pages 283–292 . ACM, 2013. 15. Andriy Mnih and Ruslan Salakhutdinov. Pro babilistic matrix factorization. I n A dvanc es in Neur al I nformation Pr o c essing Syst ems , p ages 125 7–1264, 2007. 16. Seung-T aek P ark and W ei Ch u. Pairw ise preference regress ion for cold-start recom- mendation. In Pr o c e e dings of the thir d A CM Confer enc e on R e c ommender Systems , pages 21–28. ACM, 2009. 17. Ruslan Salakhutdinov and Andriy Mnih. Bay esian probabilistic matrix factoriza- tion using marko v chain monte ca rlo. In Pr o c e e dings of the 25th International Confer enc e on Machine le arning , pages 880–887 . ACM, 2008. 18. Ruslan Salakhutdino v, Andriy Mnih, and Geoffrey H in ton. Restricted b oltzmann mac hines for collaborative filtering. In Pr o c e e dings of the 24th I nternational Con- fer enc e on Machine le arning , pages 791–798 . ACM, 20 07. 19. Andrew I S c hein, Alexandrin Popescul, Lyle H U ngar, and David M Pennock. Method s and metrics for cold-start recommendations. In Pr o c e e dings of t he 25th annual International ACM SIGIR Confer enc e on R ese ar ch and Development i n Information Re trieval , pages 253–260. ACM, 2002. 20. P aul Smolensky . Information pro cessing in dynamical systems: F oundations of harmony th eory . 1986. 21. Nitish Sriva sta v a, Ruslan R Salakhutdino v, and Geoffrey E Hinton. Modeling docu men ts with deep b oltzmann mac h ines. arXiv pr eprint arXiv:1309.6865 , 2013. 22. Xiao yuan Su and T aghi M Khoshgoftaar. A survey of collab orativ e fi ltering tech- niques. A dvanc es in Art ificial Intel l igenc e , page 4, 2009. 23. Mingxuan S un, F uxin Li, Joonseok Lee, Ke Zh ou, Guy Lebanon, and Hongyu an Zha. Learning multiple-question decision trees for cold-start recommendation. In Pr o c e e dings of the Sixth A CM International Confer enc e on Web Se ar ch and Data Mining , WSDM ’13, pages 445–454, New Y ork, NY, USA , 2013. ACM. 24. Ilya Sutskev er and Geoffrey E Hinton. Learning multilev el distributed represen- tations for high- d imensional sequences. In Internat ional Confer enc e on Artificial Intel ligenc e and Statistics , pages 548–555, 2007. 25. Graham W T a ylor, Geoffrey E Hinton, and Sam T R o w eis. Mo deling human m otion using binary laten t v ariable s. A dvanc es i n Neur al Information Pr o c essing Systems , 19:1345 , 2007. 26. Chong W ang and D a vid M Blei. Collaborative topic mod eling for recommending scien tific articles. In Pr o c e e dings of the 17th ACM SIGKDD Intern ational Confer- enc e on Know le dge Disc overy and Data Mini ng , p ages 448–456. AC M, 2011. 27. Max W elling, Michal Rosen-Zvi, and Geoffrey E Hinton. Exp onenti al family har- moniums with an application t o information retriev al. In A dvanc es in Neur al Information Pr o c essing Systems , volume 17, p ages 1481–1 488, 2004. 28. Mi Zh ang, Jie T ang, Xu c hen Zhang, and Xiangya ng Xue. Addressing cold start in recommender systems: A semi-sup erv ised co-training algorithm. I n Pr o c e e d- ings of the 30th Annual Interna tional A CM SIGIR Confer enc e on R ese ar ch and Development in I nf ormation R etrieval , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment