조건부 제한 볼츠만 머신을 활용한 콜드 스타트 추천 혁신
조건부 제한 볼츠만 머신(CRBM)을 도입해 아이템의 메타데이터(배우, 장르 등)를 활용함으로써 기존 협업 필터링이 어려웠던 신규 아이템(콜드 스타트) 추천 문제를 효과적으로 해결한다. 실험 결과, CRBM은 행렬 분해 기반 모델과 경쟁력 있는 성능을 보이며, 학습된 은닉 특징이 해석하기 쉬운 장점을 가진다.
저자: Jiankou Li, Wei Zhang
본 논문은 콜드 스타트 상황, 즉 평점 데이터가 전혀 없는 신규 아이템에 대한 추천을 다루기 위해 조건부 제한 볼츠만 머신(Conditional Restricted Boltzmann Machine, 이하 CRBM)을 제안한다. 기존 협업 필터링(CF) 기반 모델은 사용자‑아이템 평점 행렬에 의존하기 때문에 신규 아이템이 등장하면 해당 아이템에 대한 은닉 특성을 추정할 입력이 없어 예측이 불가능하다. 반면, 콘텐츠 기반 방법은 아이템의 메타데이터(배우, 장르 등)를 이용해 추천이 가능하지만, 순수 콘텐츠 기반은 사용자 선호와의 다양성을 충분히 반영하지 못한다. 따라서 두 접근법을 결합한 하이브리드 모델이 필요하다.
논문은 먼저 제한 볼츠만 머신(RBM)의 구조와 학습 방식을 소개한다. RBM은 가시층(사용자)과 은닉층(아이템 특성) 사이에 완전 연결된 이중층 무향 그래프이며, 에너지 함수 E(v,h)=‑∑a_mv_m‑∑b_nh_n‑∑v_mh_nW_mn 로 정의된다. 가시층과 은닉층은 각각 이진 변수이며, 조건부 확률은 로지스틱 함수 σ를 통해 계산된다. 학습은 대조 발산(Contrastive Divergence, CD) 알고리즘을 사용해 데이터 분포와 모델 분포 사이의 KL 발산을 최소화한다. 그러나 신규 아이템은 v가 전혀 없으므로 은닉층이 활성화되지 않는다.
이를 해결하기 위해 저자들은 아이템 메타데이터를 이진 벡터 f로 표현하고, f와 은닉층 사이에 추가적인 가중치 행렬 U를 도입한다. 수정된 에너지 함수는 E(v,h,f)=‑∑a_mv_m‑∑b_nh_n‑∑v_mh_nW_mn‑∑f_kh_nU_kn 이다. 이때 은닉 유닛의 활성화 확률은 p(h_n|v,f)=σ(b_n+∑v_mW_mn+∑f_kU_kn) 로, 메타데이터 f가 은닉 유닛을 직접 자극한다. 따라서 평점이 없는 신규 아이템이라도 f가 존재하면 은닉층이 활성화되고, 이를 통해 가시층(사용자)에 대한 재구성 확률을 얻어 추천 순위를 산출할 수 있다. 학습 과정에서 U 역시 CD를 이용해 업데이트되며, 과적합 방지를 위해 L2 정규화(가중치 감쇠) λU를 적용한다.
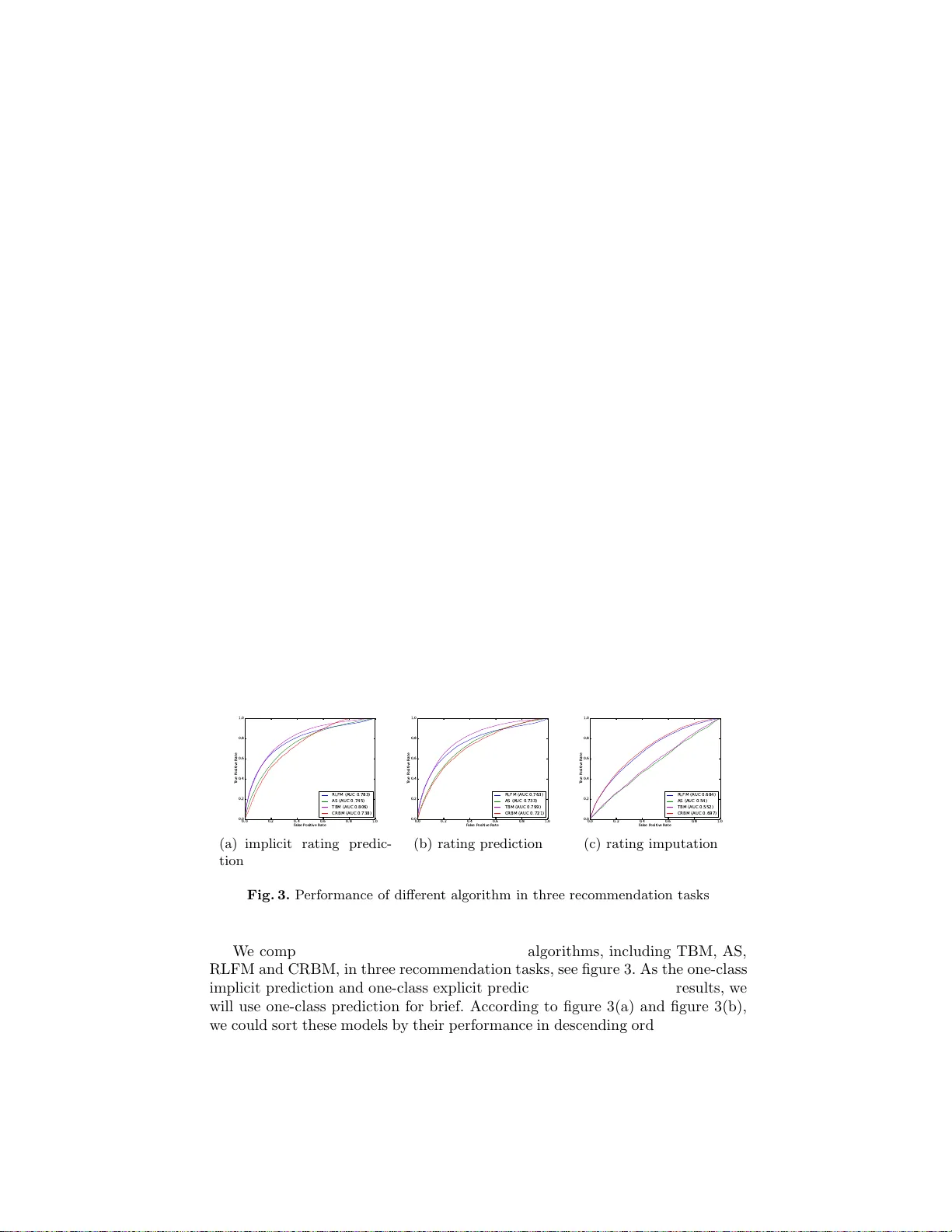
실험은 MovieLens‑100K 데이터셋(943명 사용자, 1682개 영화, 100,000개 평점)을 사용한다. 아이템을 무작위로 333개는 테스트 셋(콜드 스타트)으로, 나머지는 학습 셋으로 구분하였다. 아이템 메타데이터는 IMDb에서 수집한 배우와 장르 정보를 이진 벡터로 변환했다. 평가 과제는 세 가지로 나뉜다. (1) 일‑클래스 명시적 예측: 3점 초과 평점을 1, 그 이하와 결측을 0으로 변환해 긍정/부정을 예측한다. (2) 일‑클래스 암시적 예측: 모든 관측 평점을 1, 결측을 0으로 두고 사용자가 아이템을 평가할 확률을 예측한다. (3) 평점 예측(회귀): 관측된 평점만을 사용해 실제 평점을 예측한다. 첫 두 과제는 결측값을 0으로 처리해 데이터가 밀집(dense)해지는 반면, 평점 예측은 결측값을 무시해 희소(sparse)한 행렬을 유지한다.
베이스라인 모델로는 (a) Aspect Model(AS) – 토픽 기반 혼합 모델, (b) Tied Boltzmann Machine(TBM) – 아이템 간 쌍방향 상호작용을 모델링하는 무향 그래프, (c) Regression‑based Latent Factor Model(RLFM) – 메타데이터와 잠재 요인을 동시에 학습하는 행렬 분해 기반 모델을 선택했다. 평가 지표는 ROC 곡선 아래 면적(AUC)이며, 이는 클래스 불균형에 강인한 특성을 가진다.
결과는 다음과 같다. 암시적/명시적 예측에서는 TBM이 AUC 0.806으로 가장 높은 성능을 보였으며, RLFM(0.783), AS(0.745), CRBM(0.738) 순이었다. 반면 평점 예측에서는 CRBM이 AUC 0.697으로 최고였으며, TBM(0.552), RLFM(0.684), AS(0.54)보다 월등히 우수했다. 이는 결측값을 0으로 채우는 일‑클래스 과제와 결측값을 무시하는 회귀 과제 사이의 데이터 처리 차이가 모델 성능에 큰 영향을 미친다는 점을 시사한다. 특히 CRBM은 메타데이터 f가 은닉 유닛을 직접 활성화함으로써 콜드 스타트 아이템에 대한 잠재 특성을 효과적으로 추정한다. 또한, 가중치 감쇠를 적용한 U 행렬은 비교적 작은 값으로 수렴해 해석이 용이하며, 특정 배우·장르가 어떤 은닉 특성에 기여하는지 직관적으로 파악할 수 있다.
논문은 CRBM이 기존 행렬 분해 기반 모델과 비교해 다음과 같은 장점을 가진다고 주장한다. 첫째, 콘텐츠와 협업 정보를 하나의 확률 모델 안에서 자연스럽게 결합한다. 둘째, 추가적인 파라미터가 적고 학습 복잡도가 크게 증가하지 않는다. 셋째, 학습된 은닉‑메타데이터 연결 가중치가 작아 해석 가능성이 높다. 마지막으로, 콜드 스타트 상황에서도 평점 예측 성능이 기존 모델을 능가한다는 실험적 증거를 제공한다. 향후 연구에서는 더 풍부한 메타데이터(텍스트, 이미지 등)와 심층 구조를 결합해 성능을 더욱 향상시키는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기