In Defense of MinHash Over SimHash
MinHash and SimHash are the two widely adopted Locality Sensitive Hashing (LSH) algorithms for large-scale data processing applications. Deciding which LSH to use for a particular problem at hand is an important question, which has no clear answer in…
Authors: Anshumali Shrivastava, Ping Li
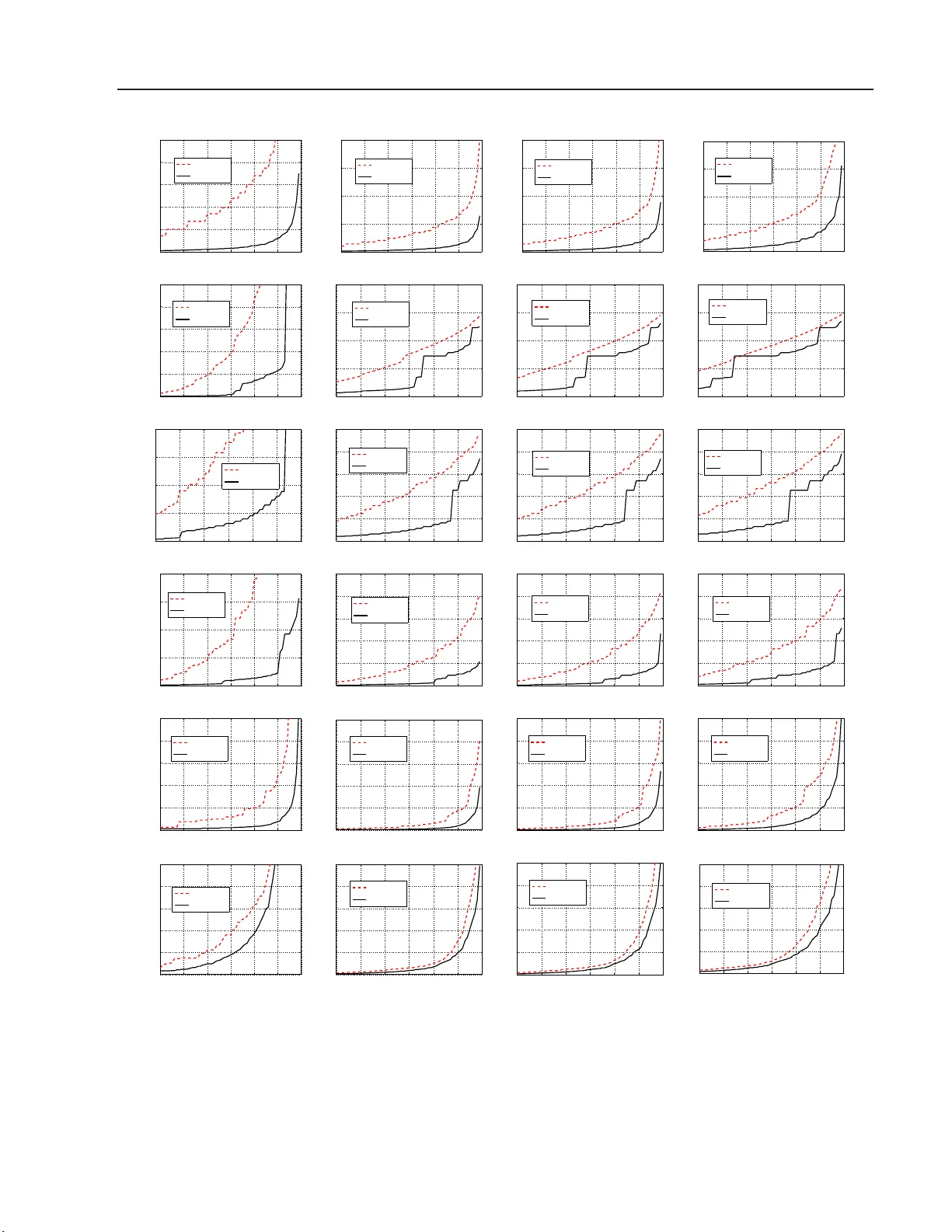
In Defense of MinHash Ov er SimHash Ansh umali Shriv asta v a Ping Li Department of Computer Science Computing and Information Science Cornell Univ er sity , Ithac a , NY, USA Department of Statistics and Biostatistics Department of Computer Science Rutgers Univ er sity , P iscataw ay , NJ, USA Abstract MinHash and SimHash are the tw o widely adopted Lo cality Sensitiv e Hashing (LSH) a l- gorithms for large- scale data pro cessing ap- plications. Deciding whic h LSH to use for a particular problem at hand is an imp or- tant question, which has no clear answer in the existing literature. In this study , we pro- vide a theoretical answer (v alida ted b y exp er- imen ts) that MinHash v ir tually a lways out- per forms SimHash when the data are binar y , as common in pr actice suc h as search. The collision probability of MinHash is a function o f r esemblanc e simila rity ( R ), while the collision proba bilit y of SimHash is a func- tion of c osine similarity ( S ). T o pr ovide a common basis for co mpa rison, we ev aluate retriev al results in terms o f S for b oth Min- Hash and SimHas h. This ev aluation is v alid as w e can pro ve that MinHash is a v alid LSH with resp ect to S , by using a g eneral inequa l- it y S 2 ≤ R ≤ S 2 −S . O ur worst case analysis can show that MinHash significantly outp er- forms SimHash in high simi larit y regio n. Int er e stingly , o ur intensive exper imen ts re- veal that MinHash is also substan tially better than SimHash even in datas ets whe r e most of the da ta p o ints are not to o similar to each other. This is pa rtly because , in pra c tical data, often R ≥ S z −S holds wher e z is only slightly la rger than 2 (e.g., z ≤ 2 . 1 ). Our re- stricted worst case analysis by a ssuming S z −S ≤ R ≤ S 2 −S shows that MinHash in- deed sig nifica ntly outp erforms SimHash e ven in lo w s i milarity reg io n. W e b elieve the results in this pap er will pro- vide v aluable guidelines for search in pr actice, esp ecially when the data a re sparse. 1 In tro du ct ion The adven t of the Internet has le d to genera tion o f massive and inherently high dimensional da ta . In many industria l applica tions, the size of the datasets has long e x ceeded the memor y capacity of a single machine. In w eb domains, it is not difficult to find datasets with the num b er of insta nces and the n um- ber of dimensio ns going in to billions [1, 6, 28]. The reality tha t web data are typically sparse and high dimensional is due to the wide adoption of the “Bag of W ords” (Bo W) repre sentations for do c umen ts and images. In BoW representations, it is k nown that the word frequency within a do cument follows p ower law. Most of the words o ccur rarely in a do cumen t and most of the higher o rder shingles in the do cument occur only once. It is o ften the case that just the presence or absence infor mation suffices in practice [7, 14, 1 7, 23]. Leading search companies routinely use sparse binary representations in their large data systems [6 ]. Lo calit y sensitive hashing (LSH) [16] is a gen- eral framework of indexing tec hnique, devised for effi- ciently s olving the approximate near neighbo r s earch problem [11]. The p erforma nc e o f LSH larg ely de- pends on the under lying par ticular hashing metho ds. Two p opular hashing algorithms a re MinHash [3 ] and SimHash (sign normal random pro jections) [8]. MinHash is an LSH for resemblance simil arit y which is defined ov er binary vectors, while SimHash is an LSH for cosine sim ilarity which works for ge n- eral real-v alued data. With the abundance o f binary data o ver the web, it has b ecome a practica lly im- po rtant questio n: which LSH should b e pr eferr e d in binary data? . This ques tion has not b een adequately answered in exis ting literature. There were pr ior at- tempts to a ddress this problem from v arious asp ects. F or example, the pap er on Conditio nal Ra ndom S am- pling ( CR S ) [19] show ed that random pro jections can be very inaccura te esp ecially in binary data, for the task of inner pro duct estimation (which is not the s ame as near neigh b or search). A more recen t paper [26] em- pirically demonstrated that b -bit minwise has hing [2 2] outp e rformed SimHash and s pec tral hashing [30]. In De fense of MinHash Over SimHash Our contr ib uti on : Our pap er provides an essent ially conclusive a nswer that MinHash sho uld b e used for near neighbor sea r ch in bina ry data, b oth theore tica lly and empirically . T o fav or SimHash, our theoretical analysis a nd exp e r iments ev aluate the retriev al r esults of MinHas h in terms of cosine similar it y (instead of resemblance). This is po ssible b ecause we are able to show that MinHash can b e prov ed to b e a n LSH for cosine simila rity by establis hing an inequality which bo unds resemblance by purely functions of cosine. Because we ev aluate MinHash (which was designed for resemblance) in terms of cosine, we will first illustra te the close connection betw een these tw o s imilarities. 2 Cosine V ersus Resem blance W e fo cus on binar y data, which can be viewed as sets (lo cations of nonze r os). Co nsider tw o sets W 1 , W 2 ⊆ Ω = { 1 , 2 , ..., D } . The cosine similarity ( S ) is S = a √ f 1 f 2 , where (1) f 1 = | W 1 | , f 2 = | W 2 | , a = | W 1 ∩ W 2 | (2) The resemblance similarity , denoted b y R , is R = R ( W 1 , W 2 ) = | W 1 ∩ W 2 | | W 1 ∪ W 2 | = a f 1 + f 2 − a (3) Clearly these tw o similarities are closely related. T o better illustrate the connection, we re-write R a s R = a/ √ f 1 f 2 p f 1 /f 2 + p f 2 /f 1 − a/ √ f 1 f 2 = S z − S (4) z = z ( r ) = √ r + 1 √ r ≥ 2 (5) r = f 2 f 1 = f 1 f 2 f 2 1 ≤ f 1 f 2 a 2 = 1 S 2 (6) There are tw o degrees of fr eedom: f 2 /f 1 , a/f 2 , which make it inconv enient for analysis. F o rtunately , in The- orem 1, w e can bound R by pur ely functions o f S . Theorem 1 S 2 ≤ R ≤ S 2 − S (7) Tightness Without making assumptions on the data, neither t he lower b ound S 2 or t he u pp er b ound S 2 −S c an b e impr ove d in the domain of c ontinuous fu n ctions. Data dep endent b ound If the data satisfy z ≤ z ∗ , wher e z is define d in (5), then S z ∗ − S ≤ R ≤ S 2 − S (8) Pr o of: Se e App endix A. Figure 1 illustrates that in high similarity region, the upper a nd lo wer b ounds essentially o verlap. Note that, in or der to obtain S ≈ 1, we need f 1 ≈ f 2 (i.e., z ≈ 2 ). 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 S S 2 S 2 − S Figure 1: Upp er (in red) and low er (in blue) b ounds in Theorem 1, which ov erlap in high s imilarity reg ion. While the high similarity re g ion is often of interest, we m ust also handle data in the low similarity regio n, bec ause in a realistic datas e t, the ma jorit y o f the pa irs are usually not similar. Interestingly , we observe that for the six da tasets in T able 1 , we o ften have R = S z −S with z only being slightly larger than 2; see Fig ure 2. T a ble 1: Datasets Dataset # Query # T rain # Dim MNIST 10,000 60,000 784 NEWS20 2,000 18,000 1,355,1 91 NYTIMES 5,000 100,000 102,660 RCV1 5,000 100,000 47,236 URL 5,000 90,000 3,231,9 58 WEBSP AM 5,000 100,000 16,6 09,143 2 2.1 2.2 2.3 2.4 2.5 0 0.2 0.4 0.6 0.8 z Frequency MNIST 2 2.1 2.2 2.3 2.4 2.5 0 0.1 0.2 0.3 0.4 z Frequency NEWS20 2 2.1 2.2 2.3 2.4 2.5 0 0.1 0.2 0.3 0.4 0.5 z Frequency NYTIMES 2 2.1 2.2 2.3 2.4 2.5 0 0.1 0.2 0.3 0.4 z Frequency RCV1 2 2.1 2.2 2.3 2.4 2.5 0 0.2 0.4 0.6 0.8 1 z Frequency URL 2 2.1 2.2 2.3 2.4 2.5 0 0.1 0.2 0.3 0.4 z Frequency WEBSPAM Figure 2: F requencies of the z v alues for all six datasets in T able 1, where z is defined in (5). W e compute z for every q uery-train pair of data p o in ts. Anshumali Shriv astav a, Ping Li 10 0 10 1 10 2 10 3 0.5 0.6 0.7 0.8 0.9 1 Top Location Similarity MNIST Resemblance Cosine 10 0 10 1 10 2 10 3 0.6 0.7 0.8 0.9 1 Top Location Resemblance of Rankings MNIST 10 0 10 1 10 2 10 3 0 0.1 0.2 0.3 0.4 0.5 Top Location Similarity NEWS20 Resemblance Cosine 10 0 10 1 10 2 10 3 0.6 0.7 0.8 0.9 1 Top Location Resemblance of Rankings NEWS20 10 0 10 1 10 2 10 3 0 0.1 0.2 0.3 Top Location Similarity NYTIMES Resemblance Cosine 10 0 10 1 10 2 10 3 0.6 0.7 0.8 0.9 1 Top Location Resemblance of Rankings NYTIMES 10 0 10 1 10 2 10 3 0 0.1 0.2 0.3 0.4 0.5 Top Location Similarity RCV1 Resemblance Cosine 10 0 10 1 10 2 10 3 0.6 0.7 0.8 0.9 1 Top Location Resemblance of Rankings RCV1 10 0 10 1 10 2 10 3 0.6 0.7 0.8 0.9 1 Top Location Similarity URL Resemblance Cosine 10 0 10 1 10 2 10 3 0.6 0.7 0.8 0.9 1 Top Location Resemblance of Rankings URL 10 0 10 1 10 2 10 3 0.4 0.5 0.6 0.7 0.8 0.9 1 Top Location Similarity WEBSPAM Resemblance Cosine 10 0 10 1 10 2 10 3 0.6 0.7 0.8 0.9 1 Top Location Resemblance of Rankings WEBSPAM Figure 3: Left panels : F or each query p oint, we rank its similarities to all training po ints in descend- ing order. F or every top lo cation, we plo t the median (among all q uery p oints) of the similarities, separa tely for cosine (dashed) and resemblance (so lid), together with the low er and upp e r b ounds o f R (dot-dashed). Right Panels : F or ev er y query po int, we rank the training p oints in des cending order o f s imilarities, sep- arately for cosine and resemblance. W e plot the resem- blance of t wo ra nked lists a t top- T ( T = 1 to 1000 ). F or each da taset, we compute b oth cosine and rese m- blance for every query- tr ain pair (e.g., 1000 0 × 60000 pairs for MNIST dataset). F or ea ch q ue r y p oint, we rank its s imilarities to all tra ining p oints in descending order. W e examine the top-10 00 lo ca tio ns a s in Fig - ure 3. In the left panels , for every top loca tion, we plot the median (among all quer y p oints) of the simila r i- ties, separately for cos ine (dashed) and resemblance (solid), together with the low er and upp er bounds of R (dot-dashed). W e ca n see for NEWS20, NYTIMES, and RCV1, the data are not to o similar. Interestingly , for all six datase ts, R matches fairly well with the up- per b ound S 2 −S . In other words, the lower b ound S 2 can b e very cons e rv a tive even in low simila r ity r e gion. The r ight panels of Figure 3 present the compar isons of the or derings of similar ities in an interesting wa y . F or every query p oint, we rank the training points in descending order of similar ities, separ ately for co sine and resemblance. This wa y , for every q uery p oint we hav e t wo lists of num ber s (o f the data p oints). W e truncate the lists at top- T and compute the rese m- blance b etw een the t wo lists. By v a rying T from 1 to 1000, we obtain a cur ve which roughly measures the “similarity” of cosine and rese mblance. W e prese n t the av erag e d curve over a ll query p oints. Clearly Figure 3 shows there is a strong corr elation b etw een the tw o measures in all data sets, as o ne would exp ect. 3 Lo calit y Sensitive Hashing (LSH) A common forma lism for approximate nea r neighbor problem is the c -approximate ne a r neighbor o r c -NN. Definition : ( c -Approximate Near Neighbor or c -NN). Given a set of po ints in a d -dimensio nal s pa ce R d , and parameters S 0 > 0, δ > 0 , c onstruct a data structure which, given any quer y point q , do es the following with probability 1 − δ : if there exist an S 0 -near neighbor of q in P , it rep o rts some cS 0 -near neigh b or of q in P . The usual notion of S 0 -near neig hbor is in terms of the distance function. Since we ar e dealing with similar- ities, we can e quiv a lent ly define S 0 -near neighbor of po int q as a p o int p with S im ( q , p ) ≥ S 0 , where S im is the simila rity function of int er est. A popular technique f o r c - NN, uses the under lying the- ory o f L o c ality S en sitive Hashing (LSH) [16]. LSH is a family of functions, with the prop erty tha t simila r input ob jects in the do main of these functions have a higher pr obability of colliding in the ra nge space tha n non-similar ones. In fo r mal terms, consider H a fa mily of hash functions mapping R D to s ome set S . Definition: Lo calit y Sensitive Hashing A fam- ily H is called ( S 0 , cS 0 , p 1 , p 2 )-sensitive if for any t wo po int s x, y ∈ R d and h chosen uniformly from H sat- isfies the follo wing: In De fense of MinHash Over SimHash • if S im ( x, y ) ≥ S 0 then P r H ( h ( x ) = h ( y )) ≥ p 1 • if S im ( x, y ) ≤ cS 0 then P r H ( h ( x ) = h ( y )) ≤ p 2 F or approximate near est neighbo r search typically , p 1 > p 2 and c < 1 is needed. Since we are defining neighbors in terms of similarity we have c < 1. T o get distance analogy we can us e the tra nsformation D ( x, y ) = 1 − S im ( x, y ) with a requirement of c > 1. The definitio n of LSH family H is tightly linked with the similar it y function of interest S im . An LSH a llows us to co nstruct data structur es that give prov ably ef- ficient query time algor ithms for c -NN problem. F act : Given a family of ( S 0 , cS 0 , p 1 , p 2 ) -sensitive has h functions, one can construct a da ta structure for c -NN with O ( n ρ log 1 /p 2 n ) query time, where ρ = log p 1 log p 2 . The quantit y ρ < 1 measures the efficiency of a given LSH, the smaller the b etter. In theory , in the worst case, the num ber of points sca nned by a given LSH to find a c -approximate near neighbor is O ( n ρ ) [16], which is dep endent on ρ . Th us given tw o LSHs, for the same c -NN problem, the LSH with smaller v alue of ρ will achiev e the same appr oximation guar antee and at the same time will have faster quer y time. LSH with low er v alue of ρ will rep ort fewer p oints fro m the da ta base as the p otential near neig hbors. Thes e rep orted po int s need additional re-ranking to find the true c -a pproximate near neighbor , whic h is a costly step. It should be noted that the efficiency of an LSH scheme, the ρ v alue, is dep endent on many things. It depe nds on the s imilarity threshold S 0 and the v alue of c which is the appr oximation parameter. 3.1 R esemblance Sim ilarit y and Min H ash Min wise has hing [4 ] is the LSH for r esemblance simi- larity . The min wise hashing family a pplies a r a ndom per mut atio n π : Ω → Ω, on the given set W , and stores only the minimum v alue after the p ermutation mapping. F orma lly MinHash is defined as: h min π ( W ) = min( π ( W )) . (9) Given sets W 1 and W 2 , it ca n b e shown by elementary probability ar g ument that P r ( h min π ( W 1 ) = h min π ( W 2 )) = | W 1 ∩ W 2 | | W 1 ∪ W 2 | = R . (10) It follo ws from (10) that minwise hashing is ( R 0 , c R 0 , R 0 , c R 0 ) sens itive family of ha s h function when the similarity function of interest is res emblance i.e R . It has efficiency ρ = log R 0 log c R 0 for approximate resemblance based search. 3.2 Si mHash and Cosi ne Si milarity SimHash is another p opular LSH for the cosine sim- ilarity mea sure, which o riginates from the co ncept of sign r andom pr oje ctions ( S RP) [8]. Giv en a vector x , SRP utilizes a ra ndom vector w with each comp onent generated from i.i.d. nor mal, i.e., w i ∼ N (0 , 1), and only stores the sign of the pro jected da ta . F or mally , SimHash is giv en by h sim w ( x ) = sig n ( w T x ) (11) It was shown in [12] that the collision under SRP sat- isfies the follo wing equation: P r ( h sim w ( x ) = h sim w ( y )) = 1 − θ π , (12) where θ = cos − 1 x T y || x || 2 || y || 2 . The term x T y || x || 2 || y || 2 , is the cosine similarity for data vectors x and y , which bec omes S = a √ f 1 f 2 when the data a re binary . Since 1 − θ π is monotonic with r esp ect to cosine sim- ilarity S . Eq. (12) implies that SimHash is a S 0 , c S 0 , 1 − cos − 1 ( S 0 ) π , 1 − cos − 1 ( c S 0 ) π sensitive hash function with efficiency ρ = log 1 − cos − 1 ( S 0 ) π log 1 − cos − 1 ( c S 0 ) π . 4 Theoretical Comparisons W e would like to highlight her e that the ρ v alues fo r MinHash and SimHash, shown in the pr evious sectio n, are no t direc tly comparable b ecause they are in the context of diff er ent similarit y measures. Consequently , it w as not clear , b efore our work, if there is any theo- retical way of finding conditions under which MinHash is pre ferable ov er SimHash and vic e versa. It turns o ut that the tw o sided b ounds in Theor em 1 allow us to prov e MinHas h is a lso an LSH for cosine similarity . 4.1 M inHash as an LSH fo r Cosi ne Sim ilarit y W e fix our go ld standard s imilarity measur e to be the cosine s imila rity S im = S . Theorem 1 leads to tw o simple corolla ries: Corollary 1 If S ( x, y ) ≥ S 0 , then we have P r ( h min π ( x ) = h min π ( y )) = R ( x, y ) ≥ S 2 0 Corollary 2 If S ( x, y ) ≤ cS 0 , then we have P r ( h min π ( x ) = h min π ( y )) = R ( x, y ) ≤ cS 0 2 − cS 0 Immediate conseq uence of these tw o cor ollaries com- bined with the definitio n o f LSH is the following: Theorem 2 F or binary data, MinHash is ( S 0 , cS 0 , S 2 0 , cS 0 2 − cS 0 ) sens itive family of hash func- tion for c osine similarity with ρ = log S 2 0 log cS 0 2 − cS 0 . 4.2 1 -bit M in wis e Hashing SimHash gene r ates a single bit output (only the signs) whereas MinHash genera tes an in teger v alue. Recently Anshumali Shriv astav a, Ping Li prop osed b -bit minwise hashing [22] provides simple strategy to generate a n informa tive s ingle bit output from MinHas h, by using the par ity of MinHa sh v alues: h min, 1 bit π ( W 1 ) = ( 1 if h min π ( W 1 ) is o dd 0 otherw ise (13) F or 1- bit MinHash and very spa rse da ta (i.e., f 1 D → 0, f 2 D → 0), w e hav e the fo llowing collisio n probability P r ( h min, 1 bit π ( W 1 ) = h min, 1 bit π ( W 2 )) = R + 1 2 (14) The ana lysis pres ent ed in pr evious sectio ns allows us to theor etically ana lyze this new scheme. The inequal- it y in Theore m 1 can b e mo dified for R +1 2 and using similar arguments as for MinHash w e obtain Theorem 3 F or binary data, 1-bit MH (minwise hashing) is ( S 0 , cS 0 , S 2 0 +1 2 , 1 2 − cS 0 ) sensitive family of hash function for c osine similarity with ρ = log 2 S 2 0 +1 log (2 − cS 0 ) . 4.3 W orst Case Gap Analysis W e will compare the gap ( ρ ) v alues of the three hashing metho ds we hav e studied: SimHash: ρ = log 1 − cos − 1 ( S 0 ) π log 1 − cos − 1 ( c S 0 ) π (15) MinHash: ρ = log S 2 0 log cS 0 2 − cS 0 (16) 1-bit MH: ρ = log 2 S 2 0 +1 log (2 − cS 0 ) (17) This is a worst ca se a nalysis. W e know the lo wer b o und S 2 ≤ R is usually very conserv ative in real data when the simila rity level is low. Nevertheless, for high simi- larity regio n, the comparis ons of the ρ v a lues indica te that MinHash s ig nificantly outper forms SimHash as shown in Figure 4, at leas t for S 0 ≥ 0 . 8. 4.4 R estricted W orst Case Gap Analysis The worst case analysis do es not make an y as sumption on the data. It is obviously to o c onserv ative when the data a re not to o similar . Figure 2 has demonstra ted that in real data, we can fairly safely r eplace the low er bo und S 2 with S z −S for so me z which, defined in (5), is very close to 2 (for ex ample, 2.1). If we are willing to make this as sumption, then we can go through the same analy sis for MinHash as an LSH for co sine and compute the corresp onding ρ v alues: MinHash: ρ = log S 0 z −S 0 log c S 0 2 − c S 0 (18) 1-bit MH: ρ = log 2( z −S 0 ) z log (2 − c S 0 ) (19) 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Worst Case S 0 = 0.95 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Worst Case S 0 = 0.9 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Worst Case S 0 = 0.8 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Worst Case S 0 = 0.7 SimHash MinHash 1−bit MH Figure 4: W orst ca se g ap ( ρ ) analysis, i.e., (1 5) (16 ) (17), for hig h similarity regio n; low er is b etter. Note that this is still a w or st case analy s is (and hence can still be very co nserv ative). Figure 5 presents the ρ v alues for this restric ted worst case gap analy sis, for t wo v alues of z (2.1 and 2.3) and S 0 as small as 0.2. The results confirms that MinHash still significantly outp e rforms SimHash e ven in low similarity reg ion. 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.7, z = 2.1 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.7, z = 2.3 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.5, z = 2.1 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.5, z = 2.3 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.3, z = 2.1 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.3, z = 2.3 SimHash MinHash 1−bit MH Figure 5: Restricted worst case gap ( ρ ) analysis by assuming the data satisfy S z − S ≤ R ≤ S 2 − S , where z is defined in (5). The ρ v alues for MinHa s h and 1-bit MinHash are expressed in (18) a nd (19 ), resp ectively . Both Figure 4 and Figure 5 show that 1-bit MinHash In De fense of MinHash Over SimHash can b e less c o mpe titiv e when the similar ity is not high. This is ex pec ted a s ana lyzed in the or iginal pap er of b -bit minwise hashing [2 0]. The r emedy is to use more bits. As s hown in Figure 6, o nce we us e b = 8 (or even b = 4) bits, the p erfor mance of b -bit minwise hashing is no t m uch different fr om MinHa s h. 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.5, z = 2.1 b=1 2 4 b=8 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.5, z = 2.3 b=1 2 4 b=8 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.3, z = 2.1 b=1 2 4 b=8 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Restricted Worst S 0 = 0.3, z = 2.3 b=1 2 4 b=8 Figure 6 : Restricted worst case gap ( ρ ) analys is for b -bit min wise hashing for b = 1, 2, 4, 8. 4.5 Ide al i zed Case Gap Analysi s The restricted worst ca se analysis can still be very co n- serv ative and may not fully expla in the stunning p er- formance of MinHash in our exp er imen ts on da tasets of low simila r ities. Here, w e also pr ovide a n ana lysis based on fixed z v a lue. That is, we only a nalyze the gap ρ by assuming R = S z −S for a fixed z . W e call this idealized gap analys is . Not sur prisingly , Figure 7 confirms that, with this as s umption, MinHash s ignif- icantly outper form SimHash even for e x tremely lo w similarity . W e should keep in mind that this idealized gap analys is ca n b e somew ha t optimistic and should only be used as some side information. 5 Exp erimen ts W e ev aluate b oth MinHash and SimHash in the actual task of retrieving top- k nea r neigh b or s. W e imple- men ted the standar d ( K, L ) parameter ized LSH [16] algorithms with b oth MinHash and SimHas h. That is, we concatena te K ha sh functions to form a new hash function for each table, a nd we gener ate L such tables (see [2] for more details ab out the implemen- tation). W e us ed a ll the six bina rized datasets with the query and training par titions a s shown in T able 1. F or each dataset, elements from training partition were used for constructing hash ta bles, while the e le men ts of the quer y partition were used as quer y for top- k neighbor sear ch. F or every query , we compute the gold sta nda rd top- k near neig hbors us ing the cosine similarity as the underlying similarity measure. In standard ( K, L ) para meterized buc keting sc heme 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Idealized Case S 0 = 0.3, z = 2 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Idealized Case S 0 = 0.3, z = 2.5 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Idealized Case S 0 = 0.1, z = 2 SimHash MinHash 1−bit MH 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0 0.2 0.4 0.6 0.8 1 ρ c Idealized Case S 0 = 0.1, z = 2.5 SimHash MinHash 1−bit MH Figure 7: Idealized case gap ( ρ ) a nalysis by a ssuming R = S z −S for a fixed z ( z = 2 a nd z = 2 . 5 in the plots). the choice of K and L is depe ndent on the similar it y thresholds and the hash function under considera tio n. In the task of top- k near neighbor retriev al, the sim- ilarity thresholds v ary with the datasets. Hence, the actual choice of ideal K and L is difficult to deter- mine. T o ensure that this choice do es not a ffect our ev a luations, w e implemented all the combinations of K ∈ { 1 , 2 , ..., 30 } and L ∈ { 1 , 2 , ..., 20 0 } . These com- binations include the reaso nable choices for bo th the hash function and differen t threshold levels. F or each co mb inatio n of ( K , L ) and for b oth o f the hash functions, w e computed the mean rec a ll of the top- k gold standard neig h b or s a long with the av erag e nu mber o f p oints rep or ted per query . W e then com- pute the least num ber of po in ts needed, by each of the t wo hash functions, to achieve a given p ercentage of recall of the gold standar d top- k , where the least was computed over the choices of K and L . W e are there- fore ensuring the bes t ov er all the choices of K a nd L for ea ch hash function independently . This elimi- nates the effect o f K and L , if an y , in the ev alua tio ns. The plots of the fr a ction of p oints retrieved at different recall levels, for k = 1 , 10 , 20 , 1 00, are in Figur e 8. A go o d hash function, a t a given r ecall should retrieve less num b er of p oints. MinHash needs to ev aluate significantly less fraction of the tota l data points to achiev e a given recall co mpared to SimHash. MinHash is consisten tly better than SimHash, in most cases very significantly , ir resp ective of the choices o f datas et and k . It should b e noted that our g old standard mea- sure for computing top- k neig hbo rs is cosine similar- it y . This should fav or SimHash b ecause it was the o nly known LSH for cosine s imilarity . Despite this “ disad- v a ntage”, MinHash still outp erforms SimHash in top near neigh b or sea rch with cosine similarit y . This nicely confirms our theoretical g ap analysis. Anshumali Shriv astav a, Ping Li 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.01 0.02 0.03 0.04 0.05 Recall Fraction Retrieved MNIST: Top 1 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.05 0.1 0.15 0.2 Recall Fraction Retrieved MNIST: Top 10 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.05 0.1 0.15 0.2 Recall Fraction Retrieved MNIST: Top 20 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.05 0.1 0.15 0.2 Recall Fraction Retrieved MNIST: Top 100 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.02 0.04 0.06 0.08 0.1 Recall Fraction Retrieved NEWS20: Top 1 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 Recall Fraction Retrieved NEWS20: Top 10 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 Recall Fraction Retrieved NEWS20: Top 20 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 Recall Fraction Retrieved NEWS20: Top 100 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 Recall Fraction Retrieved NYTIMES: Top 1 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved NYTIMES: Top 10 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved NYTIMES: Top 20 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved NYTIMES: Top 100 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.05 0.1 0.15 0.2 Recall Fraction Retrieved RCV1: Top 1 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved RCV1: Top 10 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved RCV1: Top 20 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved RCV1: Top 100 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.01 0.02 0.03 0.04 0.05 Recall Fraction Retrieved URL: Top 1 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 Recall Fraction Retrieved URL: Top 10 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 Recall Fraction Retrieved URL: Top 20 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 Recall Fraction Retrieved URL: Top 100 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.01 0.02 0.03 0.04 0.05 Recall Fraction Retrieved WEBSPAM: Top 1 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 Recall Fraction Retrieved WEBSPAM: Top 10 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 Recall Fraction Retrieved Webspam: Top 20 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 Recall Fraction Retrieved WEBSPAM: Top 100 SimHash MinHash Figure 8: F r action of data po int s r etrieved (y-axis ) in or der to achiev e a spec ifie d r ecall (x-axis), for compa r ing SimHash with MinHash. Low er is b etter. W e use top- k (cosine similarities) as the gold sta ndard for k = 1, 10, 2 0, 10 0. F or all 6 binarized datas ets, MinHash significantly outper forms SimHash. F or example, to achiev e a 90% re call for top-1 on MNIST, MinHash needs to scan, on av er a ge, 0 . 6% of the data po ints while SimHash has to sca n 5%. F o r fair co mpa risons, we present the optimum o utcomes (i.e., smallest fraction of data p oints) separately for MinHash and SimHash, b y sea rching a wide range of par ameters ( K, L ), where K ∈ { 1 , 2 , ..., 30 } is the num b er of hash functions per table and L ∈ { 1 , 2 , ..., 2 00 } is the nu mber of tables. In De fense of MinHash Over SimHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.01 0.02 0.03 0.04 0.05 Recall Fraction Retrieved MNIST (Real): Top 1 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.05 0.1 0.15 0.2 Recall Fraction Retrieved MNIST (Real): Top 10 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.05 0.1 0.15 0.2 Recall Fraction Retrieved MNIST (Real): Top 20 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.05 0.1 0.15 0.2 Recall Fraction Retrieved MNIST (Real): Top 100 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.05 0.1 0.15 0.2 Recall Fraction Retrieved RCV1 (Real): Top 1 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved RCV1 (Real): Top 10 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved RCV1 (Real): Top 20 SimHash MinHash 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 Recall Fraction Retrieved RCV1 (Real): Top 100 SimHash MinHash Figure 9: Retriev al exp eriments o n the orig inal r eal- v a lue d data. W e apply SimHas h on the origina l data and MinHash o n the bina rized da ta , and we ev a luate the retriev al results based on the cosine similar it y of the original data. MinHash still o utper forms SimHash. T o co nclude this section, we a lso add a set of exp eri- men ts using the original (real-v alued) data, for MNIST and RCV1. W e apply SimHash on the original da ta and MinHash on the binarized data. W e a lso ev aluate the r e triev a l results based on the cos ine similarities of the original data. This set-up places MinHash in a v ery disadv ant ag eous pla ce compar e d to SimHas h. Never- theless, we can see from Figure 9 that MinHash still no- ticeably outp erfo rms SimHash, although the improv e- men ts are not as s ig nificant, compa red to the ex p er i- men ts on binarized data (Figure 8). 6 Conclusion Min wise hashing (MinHash), originally designed fo r detecting duplicate web pa ges [3, 10, 15], has b een widely adopted in the s earch industry , with numerous applications, for example, large -sale ma chine lea rning systems [2 3, 21], W eb spam [29, 18], c o nten t match- ing for online advertising [25], compressing so c ial net- works [9], advertising diversification [1 3], graph sam- pling [24 ], W eb gra ph compression [5 ], etc. F ur ther- more, the re cent development of one p ermutation hash- ing [21, 27] has substantially reduced the prepro cessing costs of MinHash, making the metho d mo re practical. In machine le arning research literature, how ever, it ap- pea rs that SimHas h is more p opular for approximate near neighbor search. W e b elieve par t of the reason is that researchers tend to use the c o sine s imilarity , for which SimHash can be directly a pplied. It is usually taken for granted that MinHash and SimHash are theoretica lly incomparable and the c hoice betw een them is decided based on whether the desired notion of similar it y is co sine simila rity or resemblance. This pap er has shown that MinHas h is prov a bly a b et- ter LSH than SimHash even for co sine similar ity . Our analysis provides a first prov able w ay o f comparing t wo LSHs devised for different similarity meas ur es. Theo- retical and e x per imental evidence indicates significant computational adv antage of us ing MinHas h in pla ce o f SimHash. Since LSH is a concept studied b y a wide v a- riety of resear chers and practitioner s, we believe tha t the results shown in this pap er will b e useful from b oth theoretical as well as practical p oint of view. Ac kno wledge men ts : Anshum ali Shriv astav a is a Ph.D. student supp or ted by NSF (DMS08 08864 , SES1131 848, I I I124 9316 ) and ONR (N00014 -13-1 - 0764). Ping Li is pa r tially supp orted by AF OSR (F A9550-13 -1-01 37), ONR (N00014 -13-1 -0764 ), and NSF (II I136 0971, BI GDA T A1419 2 10). A Pro of of Theorem 1 The only les s obvious step is the Pro of of tigh tness : Let a c ontin uous function f ( S ) be a sharp er upper bo und i.e., R ≤ f ( S ) ≤ S 2 −S . F or any r ational S = p q , with p, q ∈ N and p ≤ q , choos e f 1 = f 2 = q a nd a = p . Note that f 1 , f 2 and a a re p ositive integers. This c hoice lea ds to S 2 −S = R = p 2 q − p . Thus, the upp er bo und is a chiev able for all rational S . Hence, it must be the case that f ( S ) = S 2 −S = R for a ll ra tional v alues of S . F or a ny rea l num ber c ∈ [0 , 1], there exists a Cauch y sequence of ra tio nal num ber s { r 1 , r 2 , ...r n , ... } such that r n ∈ Q and lim n →∞ r n = c . Since all r n ’s are rational, f ( r n ) = r n 2 − r n . F ro m the contin uity of b oth f a nd S 2 −S , we hav e f (lim n →∞ r n ) = lim n →∞ r n 2 − r n which implies f ( c ) = c 2 − c implying ∀ c ∈ [0 , 1 ]. F or tightn ess of S 2 , let S = q p q , choos ing f 2 = a = p and f 1 = q gives an infinite set o f po int s having R = S 2 . W e now use simila r a rguments in the pro of tightn ess of upp er b ound. All we need is the existence of a Cauch y sequence of squar e ro o t of rationa l num- ber s conv erging to any r eal c . Anshumali Shriv astav a, Ping Li References [1] Alekh A garw al, Olivier C hap elle, Mirosla v Dudik, and John Langford. A reliable effective terascale linear learning system. T ec hn ical rep ort, arXiv:1110.41 98 , 2011. [2] Alexandr Andoni and Piotr I ndyk. E2lsh: Exact eu - clidean locality sensitive hashing. T echnical rep ort, 2004. [3] Andrei Z. Bro der. On the resemblance and contain- ment of documents. I n the Compr ession and Complex- ity of Se quenc es , p ages 21–29, Positano, Italy , 1997. [4] Andrei Z. Brod er, Moses Charik ar, Alan M. F rieze, and Mic hael Mitzenmacher. Min-wise indep endent p ermutatio ns. I n STOC , pages 327–3 36, Dallas, TX, 1998. [5] Gregory Bu eh rer and Kumar Chellapilla. A scalable pattern mining approac h to w eb graph compression with communities. In WSDM , pages 95 –106, Stanford, CA, 2008. [6] T ushar Chandra, Eugene Ie, Kenn eth Goldman, T omas Lloret Llinares, Jim McF add en, F ernando P ereira, Joshua Redstone, T al Shaked, and Y oram Singer. Sibyl: a system for large scale machine learn- ing. T echnical report, 2010. [7] Olivier Chap elle, Patric k H affner, and Vladimir N. V apnik. S upp ort vector mac hines for histogram-based image classification. 10(5):1055–1064 , 1999. [8] Moses S . Charik ar. Similarit y estimation tec hn iques from rounding algorithms. In STOC , pages 380–388, Mon treal, Queb ec, Canada, 2002. [9] Flavio Chieric hetti, Ravi Kumar, Silvio Lattanzi, Mic hael Mitzenmac her, Alessandro Panconesi, and Prabhak ar Ragha v an. On compressing so cial net- w orks. In KDD , p ages 219–228, Pa ris, F rance, 2009. [10] Dennis F ett erly , Mark Manasse, Marc N a jork, and Janet L. Wiener. A large-scale stud y of the evolution of w eb pages. In WWW , pages 669–678, Budap est, Hungary , 2003. [11] Jerome H. F riedman, F. Baske tt, and L. S hustek. An algorithm for find ing nearest neighbors. IEEE T r ans- actions on Computers , 24:100 0–1006, 1975. [12] Mic hel X. Go emans and David P . Williamson. Im- prov ed approximation algorithms for maxim um cut and satisfiabilit y problems using semidefinite pro- gramming. Journal of ACM , 42(6):1115–1145 , 1995. [13] Sreeniv as Gollapudi and Aneesh Sharma. A n ax- iomatic approach for result diversification. I n WWW , pages 381–390 , Madrid, Spain, 2009. [14] Matthias H ein and O livier Bousqu et. Hilbertian met- rics and p ositive definite kernels on probability mea- sures. In AI ST A TS , pages 136–143, Barbados, 2005. [15] Monik a Rauch Hen zin ger. Finding near-d uplicate w eb pages: a large-scale ev aluation of algorithms. In SI- GIR , pages 284–291, 2006. [16] Piotr Ind y k and R a jeev Mot wani. App ro ximate near- est neighbors: T o wards remo v in g the curse of dimen- sionalit y . In STO C , pages 604–613, Dallas, TX, 1998. [17] Y ugang Jiang, Chongwah N go, and Jun Y ang. T o- w ards optimal bag-of-features for ob je ct categoriza- tion and semantic video retriev al. In CIVR , p ages 494–501 , A msterdam, Netherlands, 2007. [18] Nitin Jindal and Bing Liu. O pinion spam and analysis . In WSDM , pages 219–2 30, Palo Alto, California, U SA, 2008. [19] Ping Li, Ken neth W. Churc h, and T revor J. H astie. Conditional random sampling: A sketc h-based sam- pling technique for sparse d ata. In NIPS , pages 873– 880, V ancouver, BC, Canada, 2006. [20] Ping Li and Arnd Christian K¨ onig. b-bit minw ise hashing. In Pr o c e e dings of the 19th International C on- fer enc e on World Wi de Web , pages 671–680, Raleigh, NC, 2010. [21] Ping Li, Art B Ow en, and Cun- Hui Zhang. O ne p er- mutatio n hashing. In NIPS , Lake T aho e, NV, 2012. [22] Ping Li, Anshumali Shriva stav a, an d Arnd Christian K¨ onig. b-bit min wise hashing in practice. In Internet- war e , Changsha, China, 2013. [23] Ping Li, A n shumali Shriv astav a, Josh ua Mo ore, and Arnd Christian K¨ onig. Hashing algorithms for large- scale learning. In NIPS , Granada, Spain, 2011. [24] Marc Na jork, Sreeniv as Gollapudi, and Rina P ani- grah y . Less is more: sampling the neigh b orho od graph makes salsa better and faster. In W SDM , pages 242– 251, Barcelona, Sp ain, 2009. [25] Sandeep Pandey , Andrei Brod er, Flavio Chieric hetti, V anja Josifo vski, Ravi Kumar, an d Sergei V assilvit- skii. Nearest-neighbor cac hing for content-matc h ap- plications. In WWW , pages 441– 450, Madrid, Spain, 2009. [26] Anshumali Shriva stav a and Ping Li. F ast near neigh- b or s earch in high-dimensional binary data. In ECML , Bristol, UK, 2012. [27] Anshumali S hriv asta v a and Ping Li. D ensifying one p ermutatio n hashing via rotation for fast near neigh- b or searc h. In I CML , 2014. [28] Simon T ong. Lessons learned develo pin g a practical large scale machine learning system. http://g o ogleresearc h.blogsp ot.com/2010/04/lessons-learned-devel o p i n g - p r a c t i c a l . h 2008. [29] T anguy U rvo y , Emmanuel Chauveau, P ascal Filoche, and Thomas Lav ergne. T racking web sp am with html style similarities. ACM T r ans. Web , 2(1):1–28, 2008. [30] Y air W eiss, Antonio T orralba, and Rob ert F ergus. Sp ectral hashing. In NIPS , 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment