Parallel architectures for fuzzy triadic similarity learning
In a context of document co-clustering, we define a new similarity measure which iteratively computes similarity while combining fuzzy sets in a three-partite graph. The fuzzy triadic similarity (FT-Sim) model can deal with uncertainty offers by the …
Authors: Sonia Alouane-Ksouri, Minyar Sassi-Hidri, Kamel Barkaoui
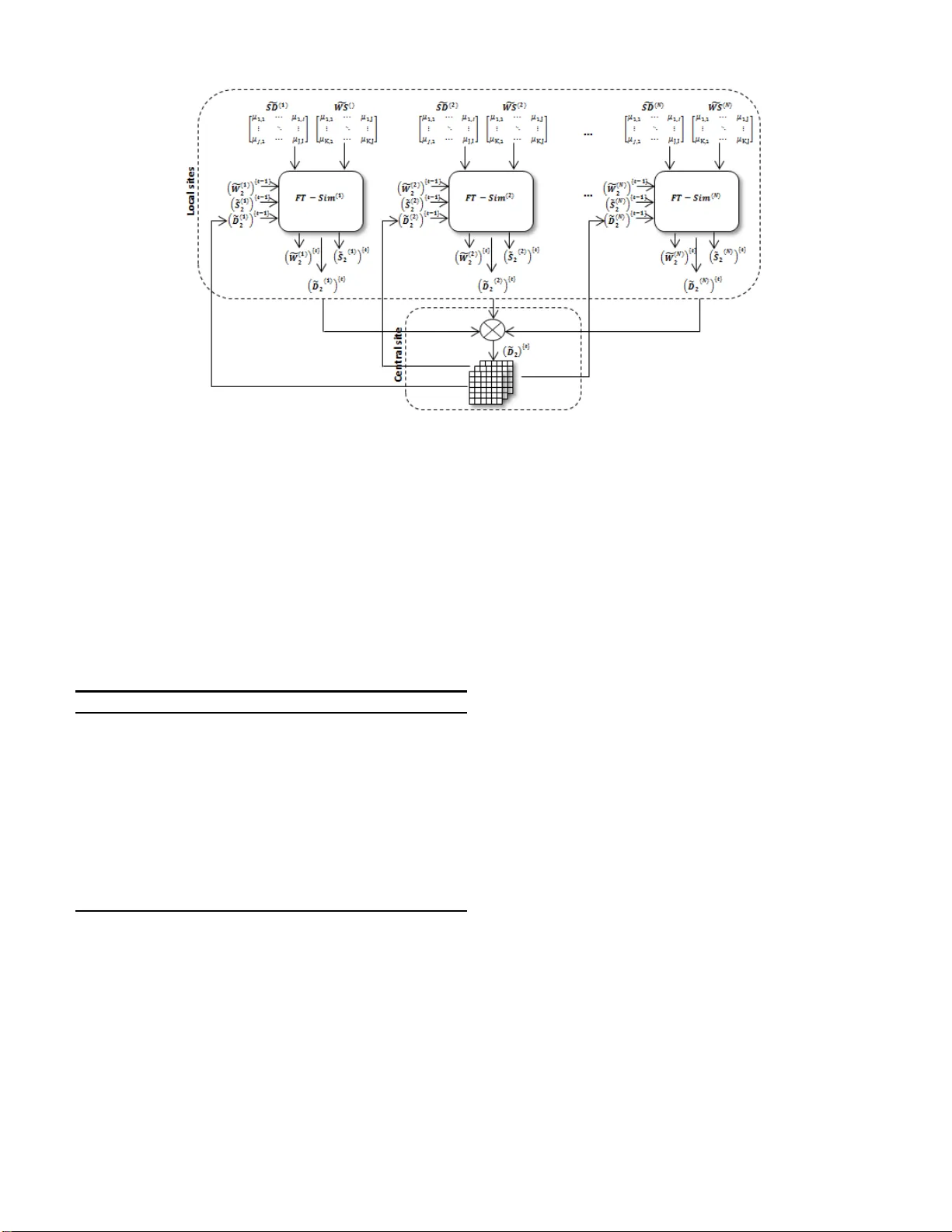
P aralle l archite ctures for fuzz y tria dic similarit y learning Sonia Alouane Ksouri 1 , Minyar Sassi Hidri 2 , Kamel Barkaoui 3 1 , 2 Universit ´ e T unis El Manar 1 , 2 Ecole Nationale d ’Ing ´ enieurs de T unis Laborato ire Signal, Image et T echnolo gies de l’Information BP . 37 , Le Belv ` ed ` ere 1002, T unis, T unisia 3 CEDRIC-CN AM Rue Saint-Ma rtin P aris 75 003, France { 1 , 2 sonia.aloun ae,minyar .sassi } @enit.rnu .tn, 3 kamel.bar kaoui@cnam.f r Abstract —In a context of document co-clustering, we defi ne a new similarity measure which iteratively computes similarity while combining fuzzy sets in a th ree -partite graph. The fuzzy triadic similarity (FT -Sim) model can deal with uncertainty offers by the fuzzy sets. Moreo ver , with the development of the W eb and the h igh av ail ability of storage spaces, more and mor e documents become accessible. Documents c an be provided from mu ltiple sites and make similarity comput ation an expensiv e processing . This problem motivated us to use parallel computing. In this paper , we introduce parallel architectures which are able to treat large and multi-source d ata sets by a sequential, a merg ing or a splittin g-based process . T hen, we proceed to a local and a central (or global) computing using the basic FT -Sim measure. The idea behind these architectures is to reduce b oth time and space complexities thanks to parallel computation. K eywords: Document co-clustering, Three-partite graph, Fuzzy sets, Parallel computing. I . I N T RO D U C T I O N Now adays inform ation on the intern et is explo ding expo - nentially through time, and approximately 80% are stored in the fo rm of text. So text minin g h as b een a very hot top ic. One p articular research area is doc ument clustering, which is a majo r top ic in the Infor mation Retriev a l comm unity . I t allows to efficiently cap ture h igh-order similarities between objects describe d by rows and colu mns of a data matr ix. In the dom ain of text clustering, a d ocument is described as a set of words. The relationship b etween d ocuments and words allo ws for exploitation of th e relationship between groups of words th at occur mostly in a group of do cuments. In [1], a co -similarity measu re has b een pro posed, called X-Sim [1] wh ich b uilds on th e idea of iteratively generating the similarity matrices between docu ments and words, each of them b uilt on the b asis of the other . T his m easure works well for unsu pervised doc ument clu stering. Howe ver, in recent researche s, th e sentence has been con- sidered as a more informativ e featur e term for improving the effecti vene ss of do cument clustering [2]. While considering three lev els Documen ts × Sentences × W o rds to represen t the data set, we are able to deal with a depen dency b etween Documen ts-Sentences, as also between Sen tences-W ords and, by dedu ction, between Do cuments-W ords. Another important aspect in co-clustering is the weight computin g. A weig hted value may b e a ssigned as a link f rom a doc ument to a word (or sen tence) indicating the presence of the word (senten ce) in th at docum ent. T he 0 /1 encod ing denotes th e presence o r absence of an o bject in a given docume nt. Different weighting schemes such as th e tf-idf [3] may be incorpo rated to better rep resent the imp ortance of word s in the corpus, but it has spawned th e view that classical probab ility theory is u nable to de al with unc ertainties in natura l lan guage and mach ine learnin g. So, we pr oceed to a fuzz ification con trol p rocess wh ich conv erts crisp similarities to f uzzy on es. The conversion to fuzzy values is represented by th e member ship f unctions [4]. They allow a grap hical represen tation of a f uzzy set [5 ]. These fuzzy similarity matrices are used to calculate fuzzy similarity between documents, sentences and words in a triadic computin g called FT -Sim (Fuz zy Triadic Similarity). Moreover , with the d e velopment of the W eb an d the hig h av ailab ility of the storage spaces, more and more documen ts become accessible. Data can be p rovided f rom multiple sites and can be seen as a co llection of m atrices. By sep arately processing th ese matrices, we get a hu ge loss of in formation. Sev eral extensions to the co- clustering me thods hav e been propo sed to deal w ith such multi-view data. Some works aim at combining multiple similar ity ma trices to p erform a given learning task [ 6], [7 ]. T he id ea being to build clu sters f rom multiple similarity ma trices co mputed along different views. Multi-view co-clusterin g such as MV -Sim [8] ar chitecture, based on X-Sim measur e [1] d eals with th e pro blem of learning co-similar ities from a collectio n o f matrices describ- ing inter related ty pes of ob jects. It was pr oved that this architecture p rovides some in teresting prop erties both in terms of con vergence a nd scalab ility a nd it a llo ws an efficient parallelization of the process. For this, we provid e par allel a rchitectures for FT -Sim to tackle the pro blem of learning similarities f rom a collection of m atrices. For multi- source or large matrices, we pr opose different parallel architectures in which each FT -Sim is the basic com ponent or node we will use to deal with multiple matrices. Thus, we co nsider a model in wh ich data sets are distributed into N sites (or r elation matrices). They describ e th e conn ec- tions betwe en docu ments fo r each local data set. Our goal is then to c ompute a fuzzy Documents × Docu- ments matrix e D ( i ) 2 for each site i ( i = 1 ..N ) trying to take into accou nt all the rep resentati ve information expressed in the relations. T o co mbine multiple occurren ces of FT -Sim, we pro pose sequential, merging and splitting based pa rallel ar chitectures. The rest of th e paper is organized a s f ollo ws: in section 2 we hig hlights backgr ounds related to similar ity measures in a multi-view d ata sets. In sectio n 3 we provid e our fu zzy triad ic similarity measur e. I n section 4 w e present the th ree prop osed architecture s allowing p arallel computin g for co -clustering. Section 5 concludes the p aper and gives indic ations o f some future work. I I . D E A L I N G W I T H M U LT I - V I E W D AT A S E T S Most of the e xisting clustering methods focus on data sets described by a unique data matrix, which can either be a matrix which describes objects by their characteristics, or a relation matrix that describes the intensity of the relation between instances of two types of objects, such as a Documen ts × W ords matrix . In the latter ca se, bo th ty pes of ob jects can b e clustered ; metho ds dealing with this task ar e ref erred to as co-clustering app roaches and h a ve been extensively studied . Howe ver, in many applications, data sets inv o lving mor e than two type s of interacting obje cts, or simp ly re lated, are also fre quent. A simple way to rep resent such data sets is to use as many ma trices as there ar e relation s b etween the objects. Then , one could use classical co- clustering methods to separa tely cluster the objects oc curring in the different matrices but, in this way , inter actions between objects are not taken into acco unt, thu s leading to a loss o f infor mation. Therefo re, handlin g the views together, referenced as the multi-view clustering task, is an interesting challeng e in th e learning dom ain to resolve lim its of classical clu stering. Many extensions to the clustering m ethods have been pro- posed to deal with multi-view data. In [ 9], they describe an extension of k- means (MVKM) and of EM algor ithms usin g multi-view model. In [6] an d [7], th e auth ors build c lusters from multiple similarity matrices co mputed alon g d if ferent views. I n [10], a co -clustering system called MVSC has bee n propo sed. It p ermits a m ulti-view spectral clustering while using the co- training th at has been widely used in semi- supervised learning pro blems. The gener al idea is to lear n the clustering in o ne view and use it to label the data in an oth er view so as to modify the graph struc ture (similarity matrix). Closer to our app roach, some works aim at comb ining multiple sim ilarity matrices to perfo rm a giv en learnin g task. The MVSim architecture [8] which is an extension o f the X- Sim algo rithm [1], ad apts the previous algorithm to the multi- view context. It compu tes simultaneo usly th e co-similarity matrix for each of N d if ferent kinds of objects T i described by M relatio n m atrices. The basic idea is to create a learning network isomo rphic to these data sets structures. It was shown that it is possible to use this a rchitecture to efficiently comp ute co-similarities on large data sets by splitting a data matrix in to smaller ones. I I I . F T- S I M : F U Z Z Y T R I A D I C S I M I L A R I T Y Sentence-b ased analysis mean s th at the similarity between docume nts should be based on m atching sentences rath er th an on matchin g single word s only . Senten ces con tain m ore in- formation th an single word s (in formation regard ing pr oximity and o rder of w ords) and have a h igher descriptive power[11] [12][13]. Thus a documen t must be broken into a set o f sentences, and a senten ce is bro ken into a set of words. W e focus o n how to combine the advantages of two r epresentation models in do cument c o-clustering. T o represent our textual data set, two representation s h a ve been pr oposed: the collection o f matrices and the k -partite graph [14]. I n the first, each matrix de scribes a view on the data. In the secon d, a graph is said to b e k-partite when the nodes are p artitioned into k subsets with th e conditio n than no two nodes of the same sub set are ad jacent. Th us in th e k- partite g raph para digm [14], a given subset of no des contain s the instances of one type of objects, a nd a link between two nodes of different s ubsets rep resents the relation between these two nodes. T o explain ou r mod el we consider m atrices to represen t th e data sets and we use a th ree-partite g raph r epresentation of the da ta matric es with three r elations linking to explain our model. From a function al point o f view , th e pro posed FT -Sim model can be represente d in the following way as sho wn in figure 1, wh ere S D and W S are two data matric es representin g a corp us and describing the connectio n b etween Documen ts/Sentences an d Sentences/W or ds, bro ught by the three-par tite graph [15]. Fig. 1. Functio nal diagram of FT -Sim. After the generation of S D and W S matr ices, we proceed to a fu zzification process. It co n verts cr isp values to f uzzy ones. The conversion to f uzzy values is repre sented b y the memb er - ship fu nctions [4]. They allow a graphica l rep resentation of a fuzzy set [ 5]. There are various metho ds to assign memb ership values or the m embership functions to fuzzy variables. W e mention essentially th e trian gular and trapezo idal ones. The second fo rm is the mo st suitable on e for mo deling fuzzy Sentences × Documen ts and W or ds × Sentence s similarities. For each do cument, we define a f uzzy m embership functio n throug h a linear transforma tion between the lower bound v alue L i , a mem bership of 0 , to the uppe r bound v alue U i , which is assign ed a membership of 1 . T his functio n is used because smaller values linear ly in crease in membersh ip to the larger values for a positi ve slope and op posite fo r a negati ve slop e. The following form ulas show the f uzzy linear membership function s for g S D i and g W S j . f S D i = [ µ ] ji = ( 1 , if S D ji ≥ L i S D ji − U i U i − L i , if L i < S D ji < U i 0 , if S D ji ≤ L i (1) and f W S j = [ µ ] kj = ( 1 , if W S kj ≥ L i W S kj − U i U i − L i , if L i < W S kj < U i 0 , if W S kj ≤ L i (2) Before pro ceeding to fuzz y triadic com puting, we must initialize Documents × Doc uments, Sentences × Sentences and W ord s × W ords fuzzy matrices with th e identity ones denoted as ˜ D (0) 2 , ˜ S (0) 2 and ˜ W (0) 2 . The similarity between the same docum ents (resp. sen tences and word s) have the value equal to 1. All o thers values ar e initialized with zero . ˜ D ( t ) 2 is as follows: ˜ D ( t ) 2 = [ µ ] ( t ) lm = D 1 . . . D m 1 . . . µ ( t ) 1 m D 1 . . . . . . . . . µ ( t ) l 1 . . . 1 D l (3) where µ ( t ) lm ( l = 1 ..I , m = 1 ..I is the membersh ip degree of th e l th docume nt acco rding the m th one. Similarly , we determine the ˜ S ( t ) 2 and ˜ W ( t ) 2 . After initializin g ˜ D ( t ) 2 , we calculate th e new m atrix ˜ D ( t ) 2 which r epresents fuzzy similar ities between d ocuments while using ˜ S ( t − 1) 2 and g S D . Usually , th e similarity measur e between two do cuments D l and D m is defined as a fun ction that is the sum of the similarities between sh ared sentences. Our idea is to generalize this functio n in order to take into accou nt the intersection b etween all the p ossible pairs of sentences occu rring in documen ts D l and D m . In this way , not only can we capture the f uzzy similar ity o f th eir common sentences but also the f uzzy o nes co ming fro m sentences that are not dire ctly co mmon in the do cuments but are shared with some o ther do cuments.For each pair of sentences not directly shared by the doc uments, we need to take into acco unt the fuzzy similarity b etween them as provided by ˜ S ( t − 1) 2 . Since we work with fuzzy ma trices fo rmed by membersh ip degrees, we shou ld certainly b e applied in accordan ce with the opera tors for fuzzy sets, especially th e intersection an d union. T hus, µ ( t ) l,m , except the case l = m , c an b e formu lated as follows: µ ( t ) l,m = J X i =1 J X j =1 min( µ il , µ jm ) ∗ µ ˜ S 2 ( t − 1) ij (4) As we have sh o wn for ˜ D ( t ) 2 computin g, we gener alize fuzzy similarities in o rder to take into a ccount the intersectio n between all the p ossible pairs o f words occurr ing in sentence s S l and S m . I n this way , n ot on ly do we capture the fuzzy similarity of their comm on words but also the fuzzy o nes coming fro m words th at are not directly com mon in th e sentences but ar e shared with som e other sentences. For ea ch pair of words not dire ctly sha red b y th e sen tences, we need to take into account the fuzzy similarity between them as provided by ˜ W ( t − 1) 2 . The overall fuzzy similarity between docume nts S l and S m is defined in the f ollowing equation : µ ( t ) l,m = M in [ I X i =1 I X j =1 min( µ il , µ jm ) ∗ µ ˜ D 2 ( t − 1) ij , (5) P K i =1 P K j =1 min( µ il , µ jm ) ∗ µ ˜ W 2 ( t − 1) ij ] Similarly , for each pair of words not directly shared by the sentences, we need to take into accou nt the fu zzy similarity between th em as pr ovided by f W ( t − 1) 2 . Th e overall fuzzy similarity b etween do cuments W l and W m is d efined in the following equ ation: µ ( t ) l,m = J X i =1 J X j =1 min( µ il , µ jm ) ∗ µ ˜ S 2 ( t − 1) ij (6) I V . P A R A L L E L F T - S I M For mu lti-source or large d ata sets, we propo se different parallel architectures in which each FT -Sim is the basic compon ent or site we will u se to deal with m ultiple matrices. Thus, we co nsider a mode l in wh ich the data sets are co m- posed of N relatio n matrices g S D ( i ) and g W S ( i ) ( i = 1 ..N ) . They describe the connection s between do cuments fo r each local d ata set. O ur go al is then to comp ute a fu zzy matrix e D ( i ) 2 for each data set tryin g to take in to account all the inform ation expressed in the r elations. T o comb ine multiple occurr ences of FT -Sim, we can adopt three different architecture s: a sequential, a m erging or a splitting based on e. A. Seque ntial-based parallel a r chitectur e In this first model, an instance of F T − S i m ( i ) is as- sociated to each local site i . Each site is represented by the relatio n matrice corresp onding to th e similarity b etween sentences/docu ments g S D ( i ) and words/sentenc es g W S ( i ) for ( i = 1 ..N ) . N being the numb er of data sources. This instance is d enoted F T − S im ( i ) . Figure 2 shows the sequ ential-based parallel architec ture. As sh o wn in figure 2, we assum e a link b etween each F T − S im ( i ) and the following o ne. Th en it compu tes the similarity matrices from the data matrices of the first data set g S D (1) and g W S (1) , and uses the resulting document similarity matrix to initialize the n ext site. The d ocument similarity issue of the 1 ( st ) data-set e D (1) 2 is used to in itialize the next docum ent similarity denoted by ( e D (2) 2 ) { 0 } (the secon d d ocument similar ity m atrice at iteration Fig. 2. Sequenti al-based parall el architec ture. 0 ). The initializatio n fun ction p resented in algorith m 1 is the n run with a second g S D (2) and g W S (2) matrices etc. Algorithm 1 Initialization fun ction Requir e: e D ( i ) 2 Ensure: ˜ D 2 1: I ← Compute the number of documents in e D ( i ) 2 and ( e D ( i +1) 2 ) { 0 } 2: Let ˜ D 2 = [ µ l,m ] ( l = 1 ..I and m = 1 .. I ) 3: ˜ D 2 ← I dentity 4: for l = 1 ..I ( i ) do 5: f or m = 1 ..I ( i ) do 6: µ l,m ← µ ( i ) l,m 7: end f or 8: end for The natur al qu estion th at arises is: how to in itialise ( e D ( i +1) 2 ) { 0 } with e D ( i ) 2 ? In th e beginning, ( e D ( i +1) 2 ) { 0 } must co ntain all do cuments existing in the i th and th e ( i + 1) th data sets. Th ey are initialized as an identity matrix denoted by I de ntity . After th at, the o btained ( e D ( i +1) 2 ) { 0 } is upda ted with th e similarities in e D ( i ) 2 . The different steps for the s equen tial-based parallel pro cess are pr esented in algorith me 2. Algorithm 2 Sequential- based algorithm Requir e: e D (0) 2 , N Ensure: ˜ D 2 1: Execute F T − S im (1) with ˜ D (0) 2 2: for i = 1 ..N do 3: Initia lizing with e D ( i ) 2 4: Execut e F T − S im ( i +1) with e D ( i ) 2 5: end for Each F T − S im ( i ) is connected to the inputs of th e following one wh ich creates a ch ain. In th at way , th e instances are sequentially r un in a static o r dyna mic or der and the similarity matrices e D ( i ) 2 are pr ogressiv ely upd ated. The pro blem with this mo del is that the ord er m atters. How do we cho ose the o rder of th e m atrices? H o w m any iterations do we p erform fo r ea ch lo cal F T − S im ( i ) ? Thus, witho ut any prio r knowledge abou t th e re lati ve in ter - est of the relation matric es and the nu mber of itera tions for each local computing, this model seems dif ficu lt to optimize. B. Mer g ing-based parallel ar chitectu r e In th e second model, we p ropose to compu te the similarity matrices from several sites and merge them befor e perfo rming the co-clustering algor ithm on it. Fig ure 3 shows the merging- based parallel ar chitecture. In this top ology , all local F T − S im ( i ) instances ( i = 1 ..N ) are run in para llel, th en the similarity matrices e D ( i ) 2 are simultaneou sly updated with an aggregation fu nction. This policy offers the ben efit that all the in stances of F T − S im ( i ) have the same in fluence. The aggregation function takes N matrices ( e D (1) 2 ) { t } , ( e D (2) 2 ) { t } ,.., ( e D ( N ) 2 ) { t } issue f rom each data sou rce i for a giv en iteration t . T wo rules are ado pted: Rule 1: If a given docum ent do es no t ap pear in a single site then we assign its correspo nding similarity measures directly in ˜ D 2 . Rule 2: If a particu lar d ocument ap pears in several d if ferent sites, we assign the minimu m of all similarity me asures relev a nt to this doc ument to ˜ D 2 without takin g into accoun t the value o f 0 . The d if ferent step s of aggr egation compu ting are p resented in algorithm 3. Algorithm 3 Mergin g Functio n Requir e: Collecti on of N matrices { ( e D (1) 2 ) { t } , ( e D (2) 2 ) { t } , . ., ( e D ( N ) 2 ) { t } } Ensure: e D 2 1: I ← Number of documents in { ( e D (1) 2 ) { t } , ( e D (2) 2 ) { t } , .., ( e D ( N ) 2 ) { t } } 2: Let e D 2 = [ µ l,m ] ( l = 1 .. I and m = 1 ..I ) 3: e D 2 ← I dentity 4: for Each document D l of e D 2 do 5: if D l Appear in only one data set s then 6: µ l, ∗ ← µ ( s ) l, ∗ 7: else 8: µ l, ∗ ← min( All µ ( i ) l, ∗ ) i ∈ { sites where D l appear } with µ ( i ) l, ∗ 6 = 0 9: end if 10: end fo r So, for a giv en iteration t , each instance F T − S i m ( i ) pro- duces its own similar ity m atrix ( e D ( i ) 2 ) { t } . W e th us get a set of output similarity matrices { ( e D (1) 2 ) { t } , ( e D (2) 2 ) { t } ,.., ( e D ( N ) 2 ) { t } } the cardinal of which being equ al to the number o f data-sets related to N . Fig. 3. Merg ing-based parallel architecture . Therefo re, we use the aggr egation fun ction denoted by N and d e veloped in the m erging based function to comp ute a consensus similarity matrix m erging all of the { ( e D (1) 2 ) { t } , ( e D (2) 2 ) { t } ,.., ( e D ( N ) 2 ) { t } } with the current matrix e D { t } 2 . In turn, th is resulting con sensus m atrix is connected to the inputs of all the F T − S im ( i ) instances, to b e taken in to account in the t + 1 th iteration, thus creatin g feedb ack lo ops allowing the system to spread the k nowledge pr ovided by each ( e D ( i ) 2 ) { t } within the network. The d if ferent steps for th e merging-b ased parallel p rocess are presented in algorith me 4. Algorithm 4 Parallel m erging-based Algorith m Requir e: collect ion of matrices f S D ( i ) , g W S ( i ) ( i = 1 ..N ) , T Ensure: e D 2 1: for all i do 2: ( e D ( i ) 2 ) { 0 } ← I dentity 3: ( e S ( i ) 2 ) { 0 } ← I dentity 4: ( e W ( i ) 2 ) { 0 } ← I dentity 5: f or i = 1 ..T do 6: Execut e ev ery F T − S im ( i ) with f S D ( i ) , g W S ( i ) and t = 1 7: ( e D 2 ) { t } ← Merging with all ( e D [ i ) 2 ) { t } 8: Update each ( e D [ i ) 2 ) { t } 9: end f or 10: end for The complexity of th is architecture is obviously related to that of the F T − S im ( i ) algorithm . In the p arallel merging- based ar chitecture, as eac h instance of F T − S im ( i ) can run on an indepen dent core, the meth od can easily be parallelized, thus keeping th e global complexity unchang ed (considerin g th e number of iterations as a constant factor). So, the comp lexity of the merging f unction can be igno red. C. Splitting -based parallel ar chitectur e In this sectio n we presen t a genera ted model that can u se previous arch itectures to efficiently co mpute FT -Sim o n large data sets by splitting a data matrix into smaller ones. Figure 4 shows th e splitting -based p arallel ar chitecture. In o rder to reduce the co mplexity of a problem of treating huge data sets, it is possible to sp lit a given data matr ix into a collection of smaller on es, each sub-m atrix becom ing a compon ent of our n etwork and processed as a separa te view . W e have to evaluate th e splitting approache s with the aim of finding the one m ost suitable with our solu tion. Here, our goal is to cluster th e documen ts and to explore the behavior of the pr oposed architecture when varying the number of H splits, obtain ing H sub- matrices. Then we adop t a random split sentence method. For each S D ( i ) matrix, the sentences are divided into H sub- sets th ereby forming H sub-m atrices S D ( i ) . So, The nu mber of F T − S im ( i ) instances in th e propo sed n etwork is equal to the number of splits H . For example, let us con sider a pro blem with one [docu - ments/sentences] matrix of size I by J in which we ju st want to cluster th e do cuments. we can divide the pro blem into a collection o f h ma trices of size n by m/H . Th us, by using a distributed version of F T − S im ( i ) on h cores, we will gain both in time and space complexity . By sp litting a matrix, we lost some info rmation. Th e so- lution does not compute the co-similar ities be tween all pairs of sentences but on ly be tween th e words occu rring in each g S D ( i ) . Thanks to the fee dback loop s of this arc hitecture and to the presenc e of the co mmon similarity ma trix ˜ D 2 , we will be able to spread the inform ation thro ugh the network and alleviate the problem of inter -matrice compa risons. Thus, b y using a par allel versio n of F T − S im ( i ) on H co res, we will g ain bo th in tim e and space complexity: indeed,th e time complexity d ecreases, lead ing to an overall gain of 1 /H 2 [16]. In the same way , the memory needed to store the similarity matrices between word s will d ecrease b y a 1 /H factor . Fig. 4. Splitt ing-based parallel architectu re. V . C O N C L U S I O N In th is paper, a fuzzy triadic similarity model, called FT - Sim, for the co -clustering task has b een pro posed. It takes, iterativ ely , into acco unt three abstra ction comp uting levels Documen t × Sentences × W ord s. T he sentences con sisting o f one or more words are used to designate th e fuzzy similar ity of two do cuments. W e are able to cluster togeth er d ocuments that have similar concepts based o n their shared ( or similar) sentences an d in the sam e way to cluster toge ther sentences based on words. This also allows us to use any classical clustering algo rithm such as Fu zzy-C-Means (FCM) [1 7] o r other fu zzy partitio ned-based clu stering app roaches [ 18]. Our p roposition has been extended to suit with multi-v ie w models. Because the domain of text cluster ing focu ses on docume nts an d their similarities, in our pr oposition we spread informa tions ab out document similarities. W e ha ve p resented three parallel architectur es that combin e FT -Sim instances to compute similarities f rom different sources. Actually , we need to further analyze the theoretical points of view and the b ehavior o f the th ree arch itectures in a multi- threading pr ogramming . R E F E R E N C E S [1] F . Hussain, X-Sim: A New Cosimilarity Measure : Applicati on to T ext Mining and Bioinformatics , Phd Thesis, 2010. [2] H. Chim and X. Deng, E f ficient Phrase-Based Document Similarit y for Clusterin g , Knowle dge and Dat a Engineeri ng, IEEE T ransactions, vol . 20, pp. 1217-1229, 2008. [3] G. Salton and C. Buckley , T erm-weighing appr oache s in automatic text re triev al , In Information Processing and Management, vol. 34, pp. 513- 523, 1988. [4] S. Kund u, Min-tr ansitivi ty of f uzzy lef tness relat ionship and its appl ication to decision making , Fuzzy Sets and Systems, vol. 93, pp. 357-367, 1997. [5] L.A. Zadeh, F uzzy sets , Information and Control 8, pp. 338-353, 1965. [6] W . T ang a nd Z. Lu an d I.S. Dhillon, Clustering with multi ple grap hs , proceed ings of the 9 th IEEE Internati onal Conference on Data Mining, pp. 1016-1021, 2009. [7] F . de Carvalh o and Y . Lechev allier and F . M. de Melo, P artitionin g hard clusteri ng algorithms based on multiple dissimilarity matrices , P attern Recogni tion 45, pp. 447-464, 2012. [8] G. Bisson and C. Grimal, Co-clustering of Multi-V iew Datasets: a P aralle lizable A ppr oach , IEEE Internation al Conferen ce on Data Mining , pp. 828-833, 2012. [9] I. Drost and S . Bickel and T . Scheer , Discovering communities in link ed data by multi-v iew clustering , proceed ings of the 29 th Annual Conferen ce of the German Classicatio n Society , Studies in Classica tion, Data Analysis, and Knowle dge Organizat ion, pp. 342-349, 2005. [10] A. Kumar and H. Da ume, A co-traini ng appr oach for multi-vie w spectr al clusteri ng , proceed ings of the 28 th Interna tional Conferen ce on Machi ne Learning, pp. 393-400, 2011. [11] H. Chim and X. Deng, Efficient Phrase-Based Document Similari ty for Clusterin g , Knowle dge and Dat a Engine ering, IEEE T ransactions, vol . 20, pp. 1217-1229, 2008. [12] J.M. T orres-Moreno and P .V elzquez -Morales and J. -G. Meunier , Corte x: Un algorithme pour la condensat ion automatique de textes , Colloque Interdisc iplinai re en Science s Cogniti ves, 2001. [13] M. Sven and L. Jorg and N. Hermann, Algorithms for bigram and trigram word clustering , Speech Communicatio n, vol . 24, pp. 19-37, 1998. [14] B. Long and X. Wu and Z.M. Zhang and S.Y . Philip, Unsupervised learning on k-partite gr aphs , proceedings of the 12 th A CM SIGKDD interna tional confe rence on Knowle dge di scov ery and data m inin g, pp. 317-326, 2006. [15] S. Alouane, M. Sassi Hidri and K. Barkaoui, Fuzzy Tri adic Similarity for T ext Cate gorization: T owards P arall el Computing , Internati onal Con- ference on W eb and Information T echnologies, pp. 265-274, 2013. [16] G. Bisson and C. Grimal, An Arc hitect ure to Efficient ly Learn Co- Similarit ies from Multi-V iew Datasets , Int ernation al Conference on Neural Information Processing, pp. 184-193, 2012. [17] J.C. Bezd ek, FCM: The Fuzzy C -Means cluste ring algorithm , Computers et Geosciences, vol. 10(2-3), pp. 191-203, 1984. [18] J.B. MacQueen, Some methods for classifica tion and analysis of mul- tivaria te observation , proc eedings of the 5 th Berk eley Symposium on Mathemat ical Statistics and Probabilit y , pp. 281-297, 1967.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment