문서 공동군집을 위한 퍼지 삼중 유사도와 병렬 처리 아키텍처
** 본 논문은 문서‑문장‑단어 3‑파트ite 그래프에서 퍼지 집합을 이용해 유사도를 반복적으로 계산하는 FT‑Sim 모델을 제안하고, 대규모·다중 출처 데이터에 대해 순차, 병합, 분할 방식의 세 가지 병렬 아키텍처를 설계하여 시간·공간 복잡도를 낮추는 방법을 제시한다. **
저자: Sonia Alouane-Ksouri, Minyar Sassi-Hidri, Kamel Barkaoui
**
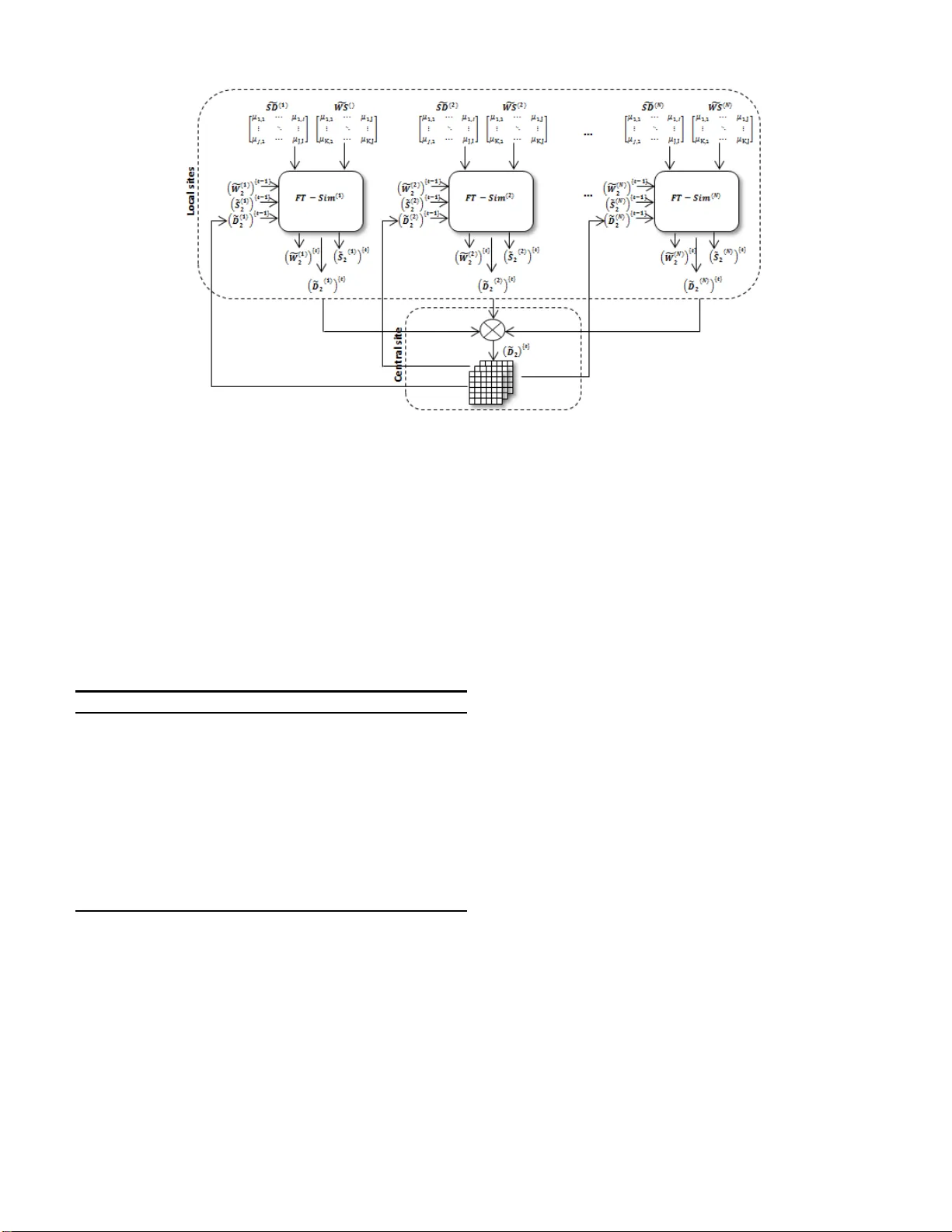
본 논문은 급증하는 웹 텍스트 데이터와 다중 출처 문서 집합을 효과적으로 군집화하기 위해, 기존의 2‑파트ite 기반 유사도 측정 방식인 X‑Sim을 확장한 퍼지 트라이디크 유사도(FT‑Sim) 모델과 이를 병렬화할 수 있는 세 가지 아키텍처를 제안한다.
먼저, 저자들은 문서‑문장‑단어라는 삼중 관계를 3‑파트ite 그래프로 모델링한다. 각 관계는 두 개의 행렬 \(S_D\) (문서‑문장)와 \(W_S\) (문장‑단어)로 표현되며, 초기값은 0/1 크리프 행렬이다. 이후, 선형(삼각형·사다리꼴) 멤버십 함수를 적용해 퍼지화함으로써 \(L_i\) 와 \(U_i\) 사이 값을
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기