Large-Scale Paralleled Sparse Principal Component Analysis
Principal component analysis (PCA) is a statistical technique commonly used in multivariate data analysis. However, PCA can be difficult to interpret and explain since the principal components (PCs) are linear combinations of the original variables. …
Authors: W. Liu, H. Zhang, D. Tao
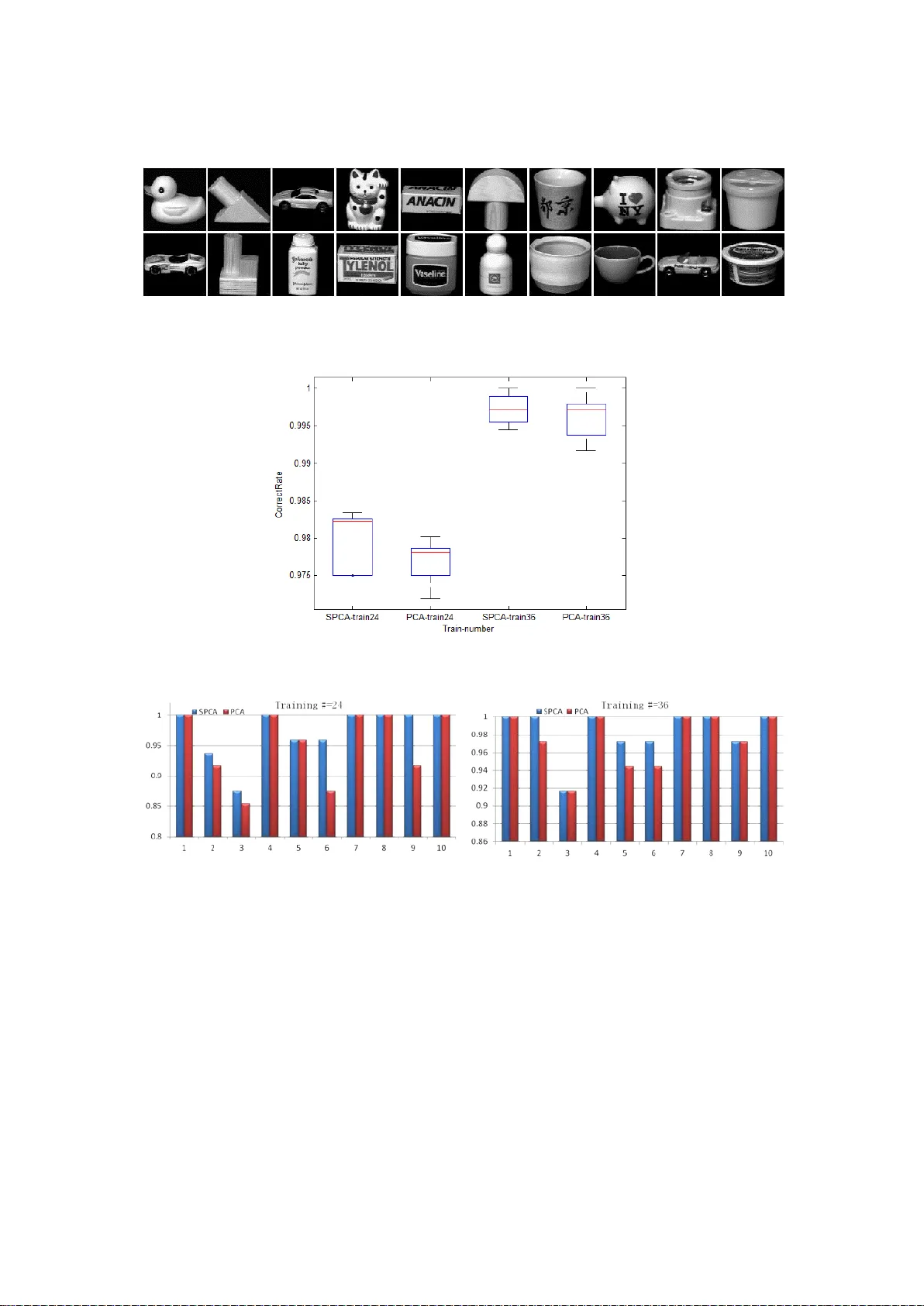
Large- Scale Paralleled Sparse Principal Com ponent Analysis W. L i u 1 , H. Zhang 1 , D. T ao 1* , Y . W ang 1 , K. Lu 1 1 China University of Petroleum (dtao.scut@gmail.com) Abstract Principal component analysis (PCA) is a statistical te chnique commonly used in multivariat e data analys is. However , PCA ca n be dif ficult to interpret and explain since the principal components ( PCs) are linear combinations of the original variables. Sparse PCA (SPCA) aims to balance statisti cal fidelity and interpretab ility by approximating sparse PCs whose projections capture the maximal variance of ori ginal data. In this paper we present an ef f icient and parallel ed method of SPCA using graphics proc essing units (GPUs) , which can process lar ge blocks of data in parallel . Specifically , we construct pa rallel im plementations of the four optimization formulations of the generalized power method of SPCA ( GP - SPCA) , one of the most ef ficient and ef fective SPCA approaches , on a GPU . T he parallel GPU implement ation of GP - SPCA (using CUBL AS) is up to eleven times fast er than the corresponding CPU implementation (using CBLAS ), and up to 107 times faster than a MatLab implementatio n. E xtensive comparative experiments in several r eal -world datasets confirm that SPCA offers a pract ical advantage . Keywords - Sparse principal component analysis, power method, GPU, lar ge - scale, parallel method 1. Introduction Principal component analysis (PCA) [1] is a well - established t ool used for data analysis and dimensionality reduction. The goal of PC A is to find a sequence of orthogonal factors that represent the direct ions of lar gest variance. PCA is used in many applications, incl uding machine learning, image processing, n eurocomputing , engineering, and computer networks , especially for large da tasets . However , despite its power and popularity , a ma jor limitation o f PCA is that the deriv ed principa l components (PCs) are dif ficult to i nterpret and explain because they tend to be linear combinations of all the origin al variabl es . Over the past ten years, sparse principal component an alysis (SPCA) has been used t o improve the interpretability of PCs . SPCA ai ms to find a reasonable balance be tween statistical f idelity and interpreta bility by approxim ating sparse PCs . Briefly , SPCA methods can be divided into two groups: (1) ad hoc methods [2] [3] and (2) sparsity penalization methods [4] [5] [6] [ 7] [8] [9] . Ad hoc methods post - process the components obtained from classical PCA ; f or example, Jolliffe [2] uses rota tion techniques in the standard PCA subspace to find sparse loa ding vectors , while Cadi ma and Jol lif fe [3] si mply set the PCA loadings w ith small absolute values to zero . Sparsity penalization methods usually form ulate the SPCA probl em as an optimization program by adding a sparsity - penalized term into the PCA framework. For example, Jolliffe et al. [4] maxi mi z e the Rayleigh quotient of the dat a covariance matrix under the L1 - norm penalty in the SCoTLASS algorithm . Zou et al. [5 ] formulate sparse PCA as a regression - type opt imization problem by i mposing the LASSO penalty on the r egression coef ficients. In the DSPCA algorithm, d’Aspremont et al. [6] solve a convex relaxation of the spar se PCA , while Moghaddam et al. [8] and d’ Aspremont et al. [7] go on to use greedy methods in order to solve the combinatorial problems encountered in sparse P CA. Finally , Journée et al. [9] propose the generalized power method for sparse PCA (GP - SPCA) , in which sparse PCA is formulated as two single - unit and two block optimization problems . GP - SPCA has optimal convergence properties when either the objective function , or the feasible set , are strongly convex [9] . There is ever growing collection, sharing, combination , and use of massive amounts of data. The analysis of such “ big data ” has become essential in many com mercial and scientific applications, from image analysis to genom e sequencing. P arallel computing algorithms are essential for large - scale, high - dimensional data. Fortunately , modern graphics processing units (GPUs) have a highly paral lel structure that makes the m ideally suited to pr ocessing big dat a algor ithms as well as graphics [10] . In this stud y w e consider how to build compact, unsupervised representations of la rge - scale, high - dimensional data using sparse PCA schemes , with an emphasis on executing the algorithm in t he GPU environment. T he work can be regarded as a set of parallel optim ization procedur e s for SPCA; specifically , we construct parallel implementations of the four optimization formulations used in GP - SPCA. T o the best of our knowledge, GP - SPCA has not previ ously been implemented using GPU s. We compare the GPU implem entation ( on an NVIDIA T esla C2050) with the corresponding CPU implementation (on a six - core 3.33 GHz high - performance cluster) and s how that the para llel GPU im plementation of GP - SPCA is up to 1 1 times faster than the corresponding CPU implementation , and up to 107 times faster than the corresponding MatLab implementation . W e also conduct extensive compar ativ e experiments of S PCA an d PCA on several benchmark dataset s, which provide further evidence that SPCA out performs PCA in the majority of cases. T he remainder of this pape r is organ ized as follows. GP - SPCA is briefly introduced in Section 2 . T he implementation of GP - SPCA on GPU s usi ng CUBLAS is described in Section 3, and the experiments are presented in Section 4. W e conclude in S ection 5. 2. Gene ralized power method of SPCA Let × be a matrix encoding p samples of n variables. SPCA ai ms to find principal components that are both sparse and explain as m uch of the variance in th e data as possible , and in doing so find s a reasonable tra de - of f between statis tical fidelity and int erpretabili ty . GP - SPCA considers two single - unit and two block formulations of SPCA, in order to extract m sparse principal components, with = 1 for two sin gle - unit formulations of SPCA and 1 for the two block formulations of SPCA. GP - SPCA maximizes a convex function on the unit Euclidean sphere in ( for = 1 ) or on the Stiefel manifold in × (for > 1 ). Depending on the type of penalt y (either or ) used to enforce spa rsity , there are four formulations of SPCA, namely single- unit SPCA via the -penalty (GP - SPCA - SL1), single - unit SPCA via the - penalty (GP - SPCA - SL0), block SPCA via the - penalty (GP - SPCA - BL1), and block SPCA via the - penalty (GP - SPCA - BL0). Denote the unit Euclidean ball (resp. sphere) in by = { | 1 } (resp. = { | = 1 } ). Denote the space of × matrice s with unit- norm columns by [ ] = { × | ( ) = } , where ( ) is the dia gonal matrix , by extracting the diagonal of the argument. Denote the Stiefel manifold by = { × | = } , a nd write ( ) for the sign of the argum ent and = { 0, } . The characteristic s of the four varian ts are summarized in T able 1 . T able 1. The four variant f ormulations of GP - SPCA. Original form of SPCA Reformulation GP - SPCA -SL1 ( ) max ( ) max [ | | ] GP - SPCA -SL0 ( ) max ( ) max [( ) ] GP - SPCA -BL1 , ( ) max [ ] ( ) , ( ) max [ ] GP - SPCA -BL0 , ( ) max [ ] ( ( ) ) , ( ) max [( ) ] GP - SPCA has optimal convergence propert ies when either the objective functions, or the feasible set , are strongly convex, which is the case with the single - unit formulations and can be enforced in the block case s [9] . 3. GPU implementa tion of GP - SPCA GPUs are typically u sed for computer graphics processing in general -purpose computing . The re is a discrepancy between the floating - point capability of the C PU and GPU because the GPU is specialized for intensiv e, highly - parallel computation , and is theref ore specifically designed to devote more transisto rs to data pr ocessing rather than data caching and flow control , as shown in Figure 1 [10] . Figure 1. The dif ference be tween GPU and CPU [10] CUDA TM is a general - purpose parallel computing architecture designed by NVIDIA, which has a paral lel p rogramm ing model and instruc tion set archite cture. CUD A guides the programm er to partition a problem into a sub- problem that can be solved as independent parallel blocks of threads in a thread hierarchy ; Figure 2 illustrates the hierarchy of threads, blocks, and grids used in CUDA. As well as the CUDA programming environment , NVIDIA also supplies toolkits f or the progr ammer: CUBLAS [1 1] is one such library that implements Basic Linear Algebra Subprograms (BLAS). Figure 2. Grids of thread blocks [10] Here w e implement all f ormulations of GP - S P C A on the GPU using CUBLAS. The data space is allocat ed both on the host memory (CPU) and on the device memory (GPU) . D ata are initialized on the host m emory before being transferred to the device memor y , after which par allel computation is performed on the device memory . The results are then transferred back to the host memory when computation is complete. 4. Experiments I n this section, we conduct compar ative experiments to evaluate the ef ficiency of GPU computing and the eff ectiveness of GP - SPCA. 4.1 Efficiency of GPU compu ting In order t o compare the eff iciency of GPU and CPU co mputing , we first conduct the CPU impl e ment ation of GP - SPC A using G S L CBL AS [12] , whic h is a highl y ef ficient implementation of BLAS. W e also compare the implem entation with the MatLab application p resented in [9] . A six - core 3.33 GHz hig h performance cluster w as used for the CPU implem entation , and a n NVIDIA T esla C2050 for the GPU implementation. Tw e nt y test instances were generated for each input m atrix × ( [5.0 × 10 , 3.2 × 10 ] , = / 10 ). H ere , = 5 is t he number of sparse PCs, and { 0. 01 ,0. 05 } is the aforementioned parameter that balance s the sparsity and variance of the PCs. Figure 3 show s the average running time of dif ferent inpu t matri c es using different parameters . T he x - ax i s indicates the size of the input matrix and the y - axi s denotes computation time. The difference in processing time ( be tween CPU and GPU ) increases with increasing size of the input matrix , with up to eleven times improvement in speed over the corresponding CBLAS implement ation , and up to 107- times over the MatLab implementation. a. GP - SPCA - SL0, = 5 , = 0. 01 b. GP- SPCA -BL0, = 5 , = 0. 01 c. GP - SPCA - SL1, = 5 , = 0. 05 d. GP- SPCA -BL1, = 5 , = 0. 05 Figure 3. A comparison of GP - S P C A performed on a GPU (T esla C2050) and a CPU 4.2 Effectiveness of GP - SPCA T o evaluate the effectiveness of GP - SPCA in practice , we ne xt conduct ed GP - SPCA and PCA experi ments on several benchm ark datasets , including the USPS database [13] , the COIL20 database [14] , and t he Isolet spoken letter recognition database [15] . F or each experiment, we use d GP - SPCA a nd P CA to learn the project functions using training samples, before mapping all the samples (both training and test samples ) into the lower dimensional subspace where recognition is performed using a nearest neighbor classifier . Figure 4. E xamples of handwriting in the USPS database USPS database: The USPS database [13] is a handwritten digit database contain ing 9298 16 × 16 pixel handwritten di git images in total ( Figure 4 ). T he database was split int o 7291 training images and 2007 test images as in [16] [17] , with the parameter set to 0.1. T he results of SPCA and PCA in recognizing the ten handwritten dig its are shown in Figure 5, f rom which we can see that SPCA outperforms PCA in most cases. Figure 5. Recognition of SPCA and PCA on USPS COIL20 database: The COIL20 database [14] contains 1440 images of 20 objects (for examples, see Figure 6) . The images of each object are taken five degrees apart as the object is rotated on a turntable , and as a result each object is represented by 72 32 × 32 pixel images. W e randomly select ed two groups of 24 and 36 examples of each object as training sets, and used the remaining images for the test set s. T he parameter wa s set to 0.3 for 24 - example group, and 0.1 for t he 36- example group. All the experiments we re repeated five times. Figure 7 shows that SPCA outperforms PCA in both cases. Figure 8, which shows the recognition rate of selected objects, dem onstrates that S P C A out performs PCA in most cases . Figure 6. COIL20 examples Figure 7. The average recognition rates of SPCA and PCA on COIL20 data Figure 8. The recognition results of selected objects Isolet spoken letter r ecognition database: The Isolet spoken lette r recognition database [15] contains 150 subjects, each of who m speaks each letter of the alphabet twice . The speakers we re grouped into five sets of 30 speakers ; th ree wer e used for training and two for testing in the first experiment and four groups for training the other for testing in the second experiment (to evaluate robustness) . T he parameter wa s set to 10 for the first exp eriment and 0.02 for the second, and each experiment was repeated five times. Figure 9. The average recognition rates of SPCA and PCA on Isolet data Figure 10. Recognition rates for each character Figures 9 and 10 show the average recognition rates and recognition of each character , respectively . SPCA is superi or to PCA in the majority of cases . 5. Conclusion Sparse PCA is a re asonable method for balancing statistica l fidelity and interpretabi lity . In this paper , we present a parallel ed method of GP - SPCA , one of the most ef ficient SPCA approaches, using a GP U . Specifically , we construct parallel implementations of the four optimization formulations for the GPU , and compare this with a CPU implementation usi ng CBLAS. Using real - world data, we experimentall y validate the ef fectiveness of GP - SPCA and demonstrate that the parallel G PU implement ation of GP - S PCA can significantly improve performance . This work has several potential applic ations in l arg e - scale , hi gh- dimension reduction problems such as video indexing [18] [21] and web image annotation [19] [20] , which will be the subject of future study . Refer ence s [1] I.T . Jolliffe, Principal component analysis. Springer V erlag, New Y ork , 1986. [2] I.T . Jollif fe , Rotation of principal components: choice of normalization constraints. Journal of Appli ed Stati sti cs, 22:29-35, 1995. [3] J. Cadima and I.T . Jolliff e, Loadings and correlations in the interpretation of principal components. Journal of applied Statistics, 22:203-214, 1995. [4] I.T . Jolliff e, N.T . T rendafilov , and M. Uddin, A modified principal component technique based on the LASSO. Journal of Computational and Graphical Statistics, 12 (3):531 -547, 2003. [5] H. Zou, T . Hastie, and R. T ibs hirani, Sparse principal component analysis. Journal of Computational and Gra phical Statis tics, 15(2):265 -286, 2006. [6] A. d ’ Aspremont, L.El Ghaoui, M.I. Jordan, and G.R.G. Lanckriet, A direct formulation for sparse P CA using semidefinite program ming. Siam Review , 49:434- 448, 2007. [7] A. d ’ Aspremont, F .R. Bach, and L.El Ghaoui, Optimal solutions for sparse principal component analysis. Journal of Machine Learning Research, 9:1269-1294, 2008 [8] B. Moghaddam, Y . W ei ss, and S. A vidan, Spectral bounds for sparse PCA: Exact and greedy algorithms. Advances in Neural Information Processing systems 18:915-922, MIT Press, C ambridge, MA, 2006 [9] Michel Journée, Y urii Nesterov , Peter Richtárik, and Rodolphe Sepulchre. Generalize power method for sparse principal com ponent analysis. Journal of Machine Learning Research, 1 1:517-553, 2010 [10] NVIDIA, CUDA C Pr ogr amming Guide (version 4.0), 201 1 [11] NVIDIA, CUBLA S Library , 2011 [12] Mark Galassi, Jim D avies, James Theiler , Brian Gough, et al. GNU Scientific Library , 2003 [13] J. J. Hull , A database for handwritten text recognition research. IEEE T ra nsactions on Pattern Analysis and Machine Intelligence, 16(5):550 - 554, May 1994. [14] S. A. Nene, S. K. Nayar and H. Murase, Columbia Object Im age Library (COIL -20). T echnical Re port CUCS -005-96, February 1996. [15] K. Bache and M. Lichman , UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science , 2013 [16] Deng Cai, Xiaofei He, Jiawei Han, Thomas Huang, Graph Regularized Non - negative Matrix Factorization f or Data Representation . IEEE T - PA M I 33 (8) : 1548-1560, 201 1 [17] Den g Cai, Xiaofei He, Jiawei Han, Speed Up Kernel Discriminant Analysis . The VLDB Journal, 20(1), 21-33, 201 1. [18] Zheng- Jun Zha, Meng W ang, Y an - T ao Zheng, Y i Y ang, Richang Hong, Ta t - Seng Chua: Interactive V ideo Indexing W ith Statistical Active Learning. IEEE T ransactions on Multim edia 14(1): 17 -27, 2012 [19] Zheng- Jun Zha, Xian - Sheng Hua, T ao Mei, Jingdong W a ng, Guo - Jun Qi, Zengfu W an g: Joint multi - label multi - ins tance le arning f or image classification. CVPR 2008 [20] Ya n - T ao Zheng, Zheng - Jun Zha, T at - Seng Chua: Research and applications on georeferenced multimedia: a survey . Multimedia T ools Appl. 51(1): 77 -98 (201 1) [21] Cheng- Chieh Chiang, Huei - Fang Y ang, Quick browsing and retr i eval for surveillance videos. Multimedia T ools and Applications. 2013, DOI: 10.1007/s1 1042-013-1750-z [22] Y outian Du, Feng Chen, W enli Xu and Xueming Qian , V ideo content categorization using the double decomposition. Multimedia T ools and Applications. 2013, DO I: 10.1007/s1 1042-012-1213-y
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment