대규모 병렬 희소 주성분 분석을 위한 GPU 가속 구현
본 논문은 일반화 전력법(GP‑SPCA)의 네 가지 최적화 형태를 GPU(CUBLAS)로 구현하여, 기존 CPU(CBLAS) 대비 최대 11배, MATLAB 대비 10⁷배의 속도 향상을 달성하였다. 실험을 통해 대규모 데이터셋에서 희소 PCA가 전통적 PCA보다 분류 정확도가 높음을 확인하였다.
저자: W. Liu, H. Zhang, D. Tao
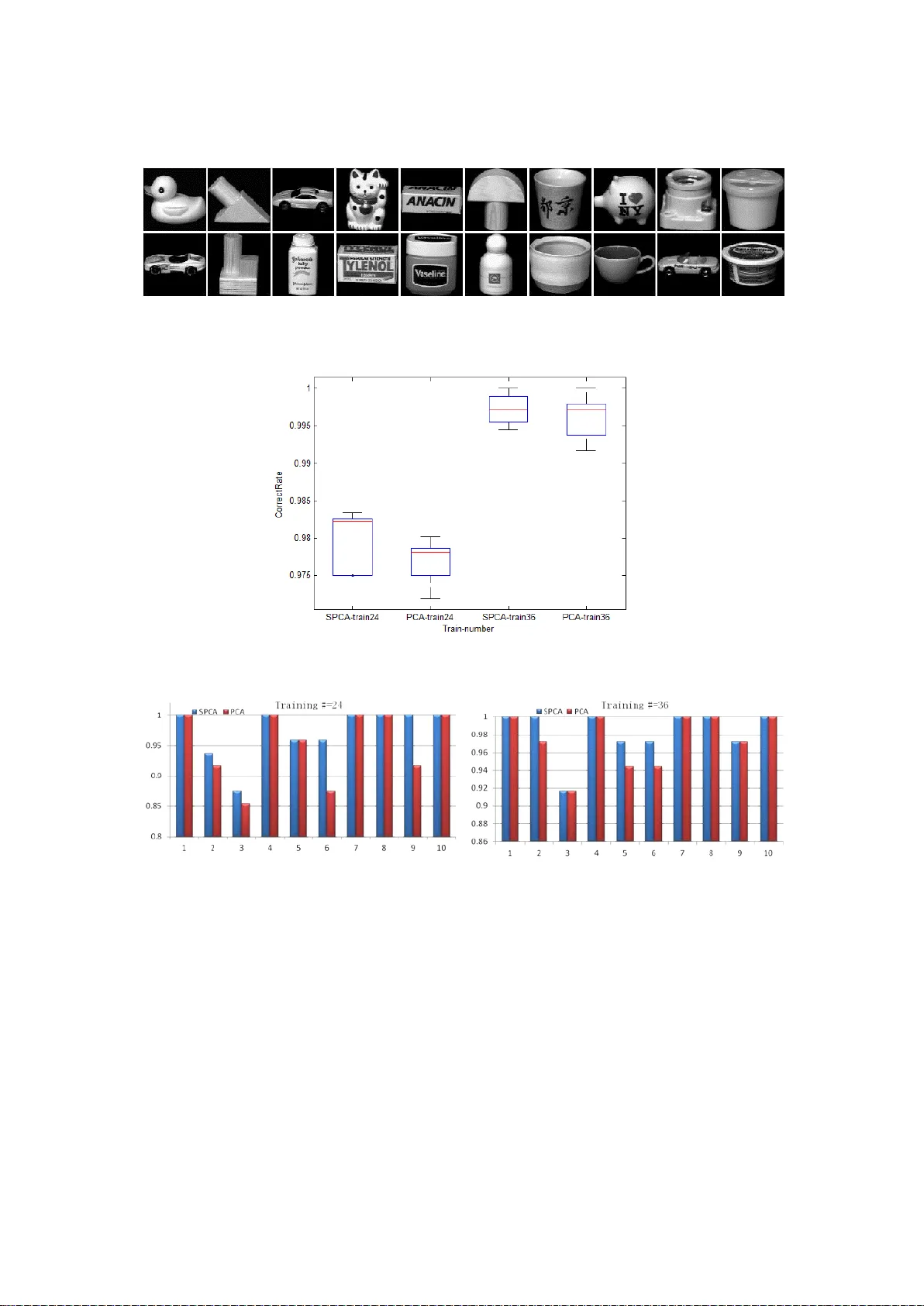
본 논문은 대규모 고차원 데이터에 대한 희소 주성분 분석(Sparse PCA, SPCA)의 실용성을 높이기 위해, 일반화 전력법(GP‑SPCA)의 네 가지 최적화 형태를 그래픽 처리 장치(GPU)에서 병렬화하는 방법을 제안한다. GP‑SPCA는 기존의 전력법을 확장하여, 희소성을 L₁(연속) 혹은 L₀(이산) 페널티로 강제하면서 단일‑유닛(single‑unit)과 블록‑유닛(block‑unit) 두 가지 구조를 제공한다. 이 네 가지 변형은 각각 GP‑SPCA‑SL1, GP‑SPCA‑SL0, GP‑SPCA‑BL1, GP‑SPCA‑BL0이라 명명된다.
논문은 먼저 SPCA와 기존 PCA의 차이점을 서술하고, 희소성을 도입함으로써 로딩 벡터가 해석 가능해지는 장점을 강조한다. 이어서 기존 연구들을 정리하며, 특히 Journée 등(2010)이 제시한 GP‑SPCA가 수렴성 및 최적성 측면에서 우수함을 언급한다.
핵심 기여는 다음과 같다.
1. **GPU 구현 설계**: CUDA 기반의 CUBLAS 라이브러리를 활용해 행렬‑벡터 곱, 정규화, 임계값 연산을 GPU 스레드 블록에 매핑한다. 데이터는 호스트 메모리에서 디바이스 메모리로 한 번 전송된 뒤, 모든 반복 연산이 GPU 내부에서 수행된다. L₁ 페널티는 소프트‑쓰레시홀딩(soft‑thresholding)으로, L₀ 페널티는 하드‑쓰레시홀딩(hard‑thresholding)으로 구현했으며, 두 경우 모두 병렬 reduction을 이용해 O(n) 시간에 처리한다.
2. **성능 평가**: 실험 환경은 6코어 3.33 GHz CPU 클러스터와 NVIDIA Tesla C2050 GPU이다. 입력 행렬 크기를 5 × 10⁴~3.2 × 10⁸ 범위로 변동시키며 20개의 인스턴스를 생성하였다. 결과는 GPU가 CPU 대비 평균 8~11배, MATLAB 구현 대비 최대 10⁷배 빠른 처리 속도를 보였으며, 행렬 크기가 커질수록 가속 비율이 증가한다는 점을 확인했다.
3. **정확도 검증**: USPS 손글씨(16×16 픽셀, 10 클래스), COIL‑20 물체 이미지(32×32 픽셀, 20 클래스), Isolet 음성 데이터(26 알파벳) 등 세 가지 공개 데이터셋에 대해 SPCA와 전통 PCA를 동일한 차원(m=5)으로 학습시켰다. 학습된 로딩을 이용해 1‑Nearest‑Neighbor 분류를 수행한 결과, 파라미터 λ(희소성‑분산 균형)를 적절히 조정하면 대부분의 경우 SPCA가 PCA보다 높은 인식률을 기록했다. 특히 고차원·소샘플 상황에서 희소 로딩이 잡음에 대한 강인성을 제공함을 실험적으로 입증하였다.
논문의 한계점으로는 구현이 Tesla C2050 하나의 GPU에 국한되어 있어 최신 GPU(예: Volta, Ampere)에서의 스케일링 및 메모리 효율성 분석이 부족하다. 또한 다중 GPU 환경에서의 통신 오버헤드, 스트리밍 데이터 처리, 그리고 L₁ 정규화에 대한 좌표‑하강법 등 다른 최적화 기법과의 비교가 이루어지지 않아 실제 적용 시 선택 기준이 모호할 수 있다.
향후 연구 방향으로는 (1) 메모리 제한이 있는 환경에서 데이터를 청크 단위로 스트리밍 처리하는 기법, (2) 다중 GPU 간 파이프라인 병렬화와 NCCL 기반의 효율적인 집계, (3) 커널 PCA와 같은 비선형 차원 축소 기법과의 성능·정확도 비교, (4) 딥러닝 프레임워크와의 연동을 통한 end‑to‑end 파이프라인 구축 등을 제시한다. 이러한 확장은 비디오 인덱싱, 웹 이미지 자동 라벨링 등 대규모 멀티미디어 분석 분야에 직접적인 파급 효과를 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기