Anytime Belief Propagation Using Sparse Domains
Belief Propagation has been widely used for marginal inference, however it is slow on problems with large-domain variables and high-order factors. Previous work provides useful approximations to facilitate inference on such models, but lacks importan…
Authors: Sameer Singh, Sebastian Riedel, Andrew McCallum
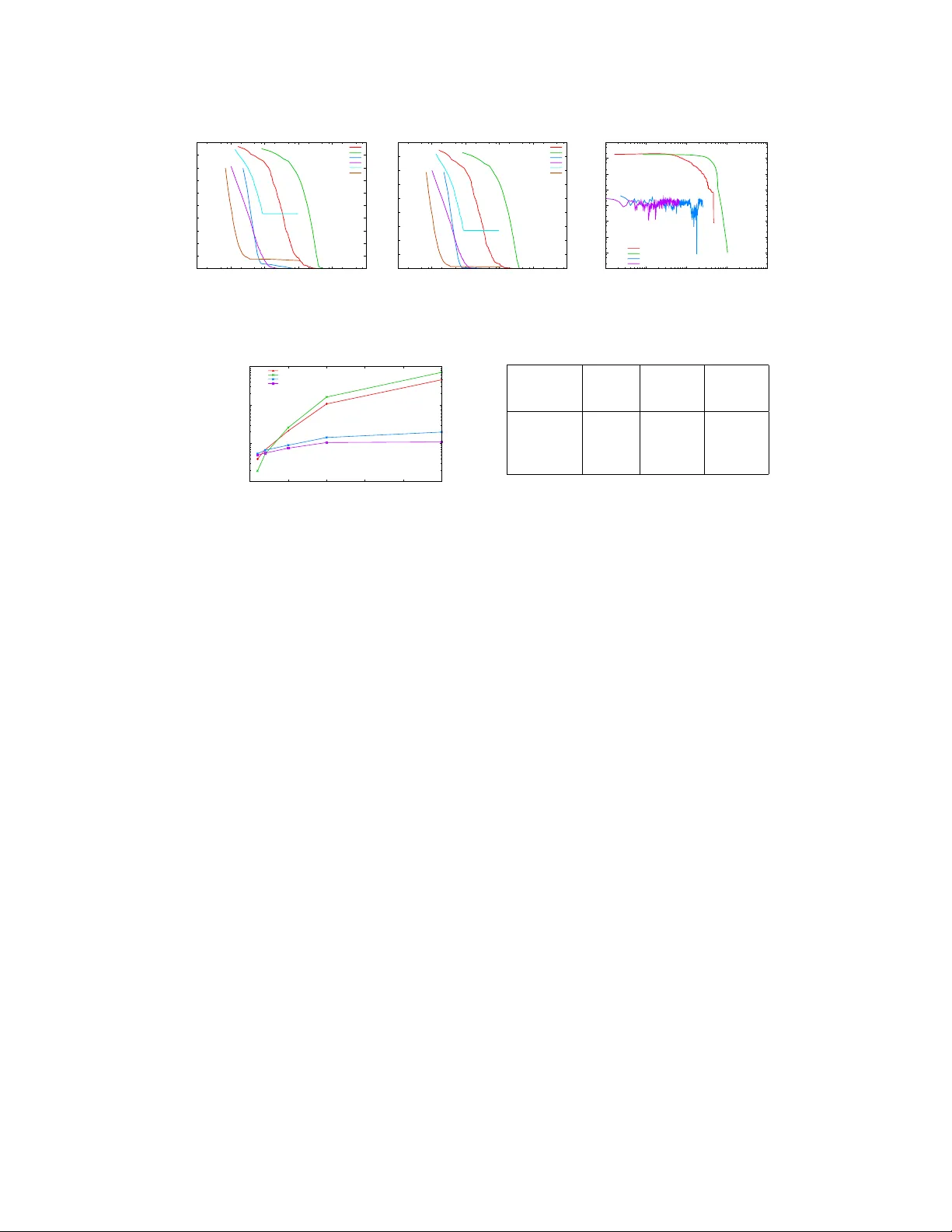
Anytime Belief Pr opagation Using Sparse Domains Sameer Singh Univ ersity of Massachusetts Amherst MA 01003 sameer@cs.umass.edu Sebastian Riedel Univ ersity College London London UK s.riedel@cs.ucl.ac.uk Andrew McCallum Univ ersity of Massachusetts Amherst MA 01003 mccallum@cs.umass.edu For marginal inference on graphical models, belief propagation (BP) has been the algorithm of choice due to impressiv e empirical results on many models. These models often contain many variables and factors, howe v er the domain of each variable (the set of values that the variable can take) and the neighborhood of the factors is usually small. When faced with models that contain v ariables with large domains and higher-order factors, BP is often intractable. The primary reason BP is unsuitable for large domains is the cost of message computations and representation, which is in the order of the cross-product of the neighbors’ domains. Existing extensions to BP that address this concern [ 1 , 2 , 4 , 8 , 9 , 10 , 13 ] use parameters that define the desired lev el of approximation, and return the approximate marginals at con v ergence. This results in poor anytime behavior . Since these algorithms try to directly achiev e the desired approximation, the mar ginals during inference cannot be characterized, and are often inconsistent with each other . Further , the relationship of the parameter that controls the approximation to the quality of the intermediate mar ginals is often unclear . As a result, these approaches are not suitable for applications that require consistent, anytime mar ginals but are willing to trade-of f error for speed, for e xample applications that in volv e real-time tracking or user interactions. There is a need for an an ytime algorithm that can be interrupted to obtain consistent marginals corresponding to fixed points of a well-defined objecti ve, and can impro ve the quality of the marginals o ver the e xecution period, e ventually obtaining the BP mar ginals. In this work we propose a novel class of message passing algorithms that compute accurate, anytime- consistent marginals. Initialized with a sparse domain for each variable, the approach alternates between two phases: (1) augmenting v alues to sparse variable domains, and (2) con ver ging to a fixed point of the approximate mar ginal inference objectiv e as defined by these sparse domains. W e tighten our approximate marginal inference objecti ve by selecting the value to add to the sparse domains by estimating the impact of adding the value to the v ariational objectiv e; this is an accurate prioritization scheme that depends on the instantiated domains and requires runtime computation. W e also provide an alternate prioritization scheme based on the gradient of the primal objectiv e that can be computed a priori, and provides constant time selection of the v alue to add. T o con verge to a fixed point of the approximate mar ginal objectiv e, we perform message passing on the sparse domains. Since naiv e schedules that update messages in a round robin or random fashion are wasteful, we use residual-based dynamic prioritization [ 3 ]. Inference can be interrupted to obtain consistent marginals at a fixed point defined o ver the instantiated domains, and longer e xecution results in more accurate marginals, e v entually optimizing the BP objectiv e. 1 Marginal Infer ence for Undir ected Graphical Models Let x be a random vector where each x i ∈ x takes a v alue v i from domain D . An assignment to a subset of variables x c ⊆ x is represented by v c ∈ D | x c | . A factor graph [ 6 ] is defined by a bipartite graph ov er the variables x and a set of factors f ∈ F (with neighborhood x f ≡ N ( f ) ). Each f actor f 1 defines a scalar function φ f ov er the assignments v f of its neighbors x f , defining the distribution: p ( v ) , 1 Z exp X f ∈ F φ f ( v f ) , where Z , X v 0 ∈ D n exp X f ∈ F φ f ( v 0 f ) . Inference is used to compute the variable mar ginals p ( v i ) = P v /x i p ( v ) and the factor marginals p ( v f ) = P v / x f p ( v ) . When performing approximate v ariational inference, we represent the approximate mar ginals µ ≡ ( µ X , µ F ) that contain elements for e very assignment to the variables µ X ≡ µ i ( v i ) , ∀ x i , v i ∈ D and factors µ F ≡ µ f ( v f ) , ∀ f , v f ∈ D | x f | . Minimizing the KL di ver gence between the desired and approximate marginals results in: max µ ∈ M X f ∈ F X v f µ f ( v f ) φ f ( v f ) + H ( µ ) , where M is the set of realizable mean vectors µ , and H ( µ ) is the entropy of the distrib ution that yields µ . Both the polytope M and the entropy H need to be approximated in order to ef ficiently solve the maximization. Belief propagation (BP) approximates M using the local polytope : L , µ ≥ 0 , ∀ f ∈ F : P v f µ f ( v f ) = 1 , ∀ f, i ∈ N ( f ) , v s : P v 0 f ,v 0 i = v s µ f v 0 f = µ i ( v s ) and entropy using Bethe approximation: H B ( µ ) , P f H µ f − P i ( d i − 1) H ( µ i ) , leading to: max µ ∈ L X f ∈ F X v f µ f ( v f ) φ f ( v f ) + H B ( µ ) (1) The Lagrangian relaxation of this optimization is: L BP ( µ , λ ) , X f ∈ F X v f µ f ( v f ) φ f ( v f ) + H B ( µ ) + X f λ f C f ( µ ) + X f X i ∈ N ( f ) X v i λ v i f i C f ,i,v i ( µ ) (2) where C f ,i,v i = µ i ( v i ) − P v f /x i µ f ( v f ) and C f = 1 − P v f µ f ( v f ) are the constraints that correspond to the local polytope L . BP messages correspond to the dual v ariables, i.e. m f i ( v i ) ∝ exp λ v i f i . If the messages con ver ge, Y edidia et al. [12] show that the marginals correspond to a µ ∗ and λ ∗ at a saddle point of L BP , i.e. ∇ µ L BP ( µ ∗ , λ ∗ ) = 0 and ∇ λ L BP ( µ ∗ , λ ∗ ) = 0 . In other words: at con ver gence BP marginals are locally consistent and locally optimal. BP is not guaranteed to con ver ge, or to find the global optimum if it does, howe ver it often con verges and produces accurate marginals in practice [7]. 2 Anytime Belief Propagation Graphical models are often defined over v ariables with large domains and factors that neighbor many variables. Message passing algorithms perform poorly for such models since the complexity of message computation for a factor is O | D | | N f | where D is the domain of the v ariables. Further , if inference is interrupted, the resulting marginals are not locally consistent, nor do the y correspond to any fix ed point of a well-defined objectiv e. Here, we describe an algorithm that meets the following desiderata: (1) anytime property that results in consistent marginals, (2) more iterations improv e the accuracy of mar ginals, and (3) con v ergence to BP mar ginals (as obtained at a fixed point of BP). Instead of directly performing inference on the complete model, our approach maintains partial domains for each v ariable. Message passing on these sparse domains con ver ges to a fixed point of a well-defined objecti ve (Section 2.1). This is followed by incrementally gr owing the domains (Section 2.2), and resuming message passing on the ne w set of domains till conv ergence. At an y point, the marginals are close to a fixed point of the sparse BP objecti ve, and we tighten this objecti ve ov er time by growing the domains. If the algorithm is not interrupted, entire domains are instantiated, and the marginals con verge to a fix ed point of the complete BP objectiv e. 2.1 Belief Propagation with Sparse Domains First we study the propagation of messages when the domains of each v ariables hav e been partially instantiated (and are assumed to be fixed here). Let S i ⊆ D, | S i | ≥ 1 be the set of v alues associated with the instantiated domain for variable x i . During message passing, we fix the marginals corre- sponding to the non-instantiated domain to be zero, i.e. ∀ v i ∈ D − S i , µ i ( v i ) = 0 . By setting these values in the BP dual objecti ve (2) , we obtain the optimization defined only over the sparse domains: L SBP ( µ , λ , S ) , X f X v f ∈ S f µ f ( v f ) φ f ( v f ) + H B ( µ ) + X f λ f C f ( µ ) + X f X i ∈ N ( f ) X v i ∈ S i λ v i f i C f ,i,v i ( µ ) (3) 2 Note that L SBP ( µ , λ , D n ) = L BP ( µ , λ ) . Message computations for this approximate objectiv e, including the summations in the updates, are defined sparsely over the instantiated domains. In general, for a f actor f , the computation of its outgoing messages requires O Q x i ∈ N f | S i | operations, as opposed to O | D | | N f | for whole domains. V ariables for which | S i | = 1 are treated as observed . 2.2 Gr owing the Domains As expected, BP on sparse domains is much faster than on whole domains, howe ver it is optimizing a different, approximate objecti v e. The approximation can be tightened by growing the instantiated domains, that is, as the sparsity constraints of µ i ( v i ) = 0 are remov ed, we obtain more accurate marginals when message passing for ne wly instantiated domain con v erges. Identifying which v alues to add is crucial for good anytime performance, and we propose two approaches here based on the gradient of the variational and the primal objecti v es. Dynamic V alue Prioritization: When inference with sparse domains con ver ges, we obtain marginals that are locally consistent, and define a saddle point of Eq (3) . W e would like to add the value v i to S i for which removing the constraint µ i ( v i ) = 0 will have the most impact on the approximate objectiv e L SBP . In other words, we select v i for which the gradient ∂ L SBP ∂ µ i ( v i ) | µ i ( v i )=0 is largest. From (3) we derive ∂ L S B P ∂ µ i ( v i ) = ( d i − 1)(1 + log µ i ( v i )) + P f ∈ N ( x i ) λ v i f i . Although log µ i ( v i ) → −∞ when µ i ( v i ) → 0 , we ignore the term as it appears for all i and v i 1 . The rest of the gradient is the priority: π i ( v i ) = d i + X f ∈ N ( x i ) λ v i f i . Since λ v i f i is undefined for v i / ∈ S i , we estimate it by performing a single round of message update o ver the sparse domains. T o compute priority of all values for a v ariable x i , this computation requires an efficient O | D || S | N f − 1 . Since we need to identify the value with the highest priority , we can improve this search by sorting factor scores φ , and further , we only update the priorities for the v ariables that hav e participated in message passing. Precomputed Priorities of V alues: Although the dynamic strategy selects the v alue that improv es the approximation the most, it also spends time on computations that may not result in a corresponding benefit. As an alternativ e, we propose a prioritization that precomputes the order of the values to add; even though this does not take the current beliefs into account, the resulting savings in speed may compensate. Intuitiv ely , we want to add values to the domain that hav e the highest marginals in the final solution. Although the final mar ginals cannot be computed directly , we estimate them by enforcing a single constraint µ i ( v i ) = P v f /x i µ f ( v f ) and performing greedy coordinate ascent for each f on the primal objective in (1) . W e set the gradient w .r .t. µ f ( v f ) to zero to obtain: π i ( v i ) = ˆ µ i ( v i ) = X v 0 f ,v 0 i = v s ˆ µ f v 0 f = X f ∈ N ( x i ) log X v f ∈ D f x i exp φ f ( v f ) . This priority can be precomputed and identifies the next v alue to add in constant time. 2.3 Dynamic Message Scheduling After the selected v alue has been added to its respecti ve domain, we perform message passing as described in Section 2.1 to con v erge to a fixed point of the ne w objecti ve. T o focus message updates in the areas affected by the modified domains, we use dynamic prioritization amongst messages [ 3 , 11 ] with the dynamic range of the change in the messages ( residual ) as the choice of the message norm [ 5 ]. Formally: π ( f ) = max x i ∈ N f max v i ,v j ∈ S i log e ( v i ) e ( v j ) , e = m f i m 0 f i . As shown by Elidan et al. [3] , residuals of this form bound the reduction in distance between the factor’ s messages and their fixed point, allowing their use in two ways: first, we pick the highest priority message since it indicates the part of the graph that is least locally consistent. Second, the maximum priority is an indication of con ver gence and consistency; a low max-residual implies a low bound on the distance to con vergence. 1 Alternativ ely , approximation to L SBP that replaces the variable entrop y − P p p log p with its second order T aylor approximation P p p (1 − p ) . The gradient at µ i ( v i ) = 0 of the approximation is d i + P f ∈ N ( x i ) λ v i f i . 3 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 10 100 1000 10000 100000 1e+06 Total variation Time (ms) Total variation vs Time (ms) BP RBP Dynamic Fixed TruncBP Random (a) T otal V ariation Distance 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10 100 1000 10000 100000 1e+06 L2 Error Time (ms) L2 Error vs Time (ms) BP RBP Dynamic Fixed TruncBP Random (b) L2 Error 1e-07 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 10 100 1000 10000 100000 1e+06 Average Residual Time (ms) Max Residual vs Time (ms) BP RBP Dynamic Fixed (c) A verage Residual in Messages Figure 1: Runtime Analysis: for 10 × 10 grid with domain size of 100 , av eraged ov er 10 runs. 100 1000 10000 100000 0 50 100 150 200 250 Time to Converge (ms) Complete Domain Size BP RBP Dynamic Fixed Figure 2: Con vergence time for different do- mains: to L 2 < 10 − 4 ov er 10 runs of 5 × 5 grids. # Entities 4 6 8 # V ars 16 36 64 # Factors 28 66 120 BP 41,193 91,396 198,374 RBP 54,577 117,850 241,870 Fixed 24,099 26,981 49,227 Dynamic 24,931 36,432 41,371 Figure 3: Joint Information Extraction: A vg time taken (ms) to L 2 < 0 . 001 3 Experiments Our primary baseline is Belief Pr opagation ( BP ) using random scheduling. W e also e valuate Residual BP ( RBP ) that uses dynamic message scheduling. Our first baseline that uses sparsity , T runcated Domain ( T runcBP ), is initialized with domains that contain a fix ed fraction of values ( 0 . 25 ) selected according to precomputed priorities (Section 2.2) and are not modified during inference. W e ev aluate three variations of our frame work. Random Instantiation ( Random ) is the baseline that the value to be added at random, follo wed by priority based message passing. Our approach that estimates the gradient of the dual objectiv e is Dynamic , while the approach that precomputes priorities is Fixed . Grids: Our first testbed for ev aluation consists of 5 × 5 and 10 × 10 grid models (with domain size of L = 10 , 20 , 50 , 100 , 250 ), consisting of synthetically generated unary and pairwise factors. The runtime error for our approaches compared against the marginals obtained by BP at con ver gence (Figure 1) is significantly better than BP; up to 12 times faster to obtain L 2 error of 10 − 7 . TruncBP is efficient, ho we ver con verges to an inaccurate solution, suggesting that prefix ed sparsity in domains is not desirable. Similarly , Random is initially fast, since adding any value has a significant impact, ho wev er as the selections become crucial, the rate of con v ergence slows down considerably . Although both Fixed and Dynamic provide desirable trajectories, Fixed is much faster initially due to constant time growth of domains. Howe v er as messages and marginals become accurate, the dynamic prioritization that utilizes them e ventually ov ertakes the Fixed approach. T o e xamine the anytime local consistency , we examine the average residuals in Figure 1c since lo w residuals imply a consistent set of marginals for the objecti v e defined ov er the instantiated domain. Our approaches demonstrate lo w residuals throughout, while the residuals for e xisting techniques remain significantly higher (note the log-scale), lowering only near con vergence. When the total domain size is varied in Figure 2, we observe that although our proposed approaches are slower on problems with small domains, the y obtain significantly higher speedups on larger domains ( 25 − 40 times on 250 labels). Joint Information Extraction: W e also ev aluate on the real-world task of joint entity type prediction and relation extraction for the entities that appear in a sentence. The domain sizes for entity types and relations is 42 and 24 respectiv ely , resulting in 42 , 336 neighbor assignments for joint factors (details omitted due to space). Figure 3 sho ws the con ver gence time averaged over 5 runs. For smaller sentences, sparsity does not help much since BP con verges in a fe w iterations. Howe v er , for longer sentences containing many more entities, we observ e a significant speedup (up to 6 times). 4 4 Conclusions In this paper , we describe a no vel family of anytime message passing algorithms designed for marginal inference on problems with large domains. The approaches maintain sparse domains, and ef ficiently compute updates that quickly reach the fixed point of an approximate objectiv e by using dynamic message scheduling. Further, by gro wing domains based on the gradient of the objecti ve, we impro ve the approximation iterativ ely , ev entually obtaining the BP mar ginals. References [1] James Coughlan and Huiying Shen. Dynamic quantization for belief propagation in sparse spaces. Computer V ision and Image Understanding , 106:47–58, April 2007. ISSN 1077-3142. [2] James M. Coughlan and Sabino J. Ferreira. Finding deformable shapes using loopy belief propagation. In Eur opean Confer ence on Computer V ision (ECCV) , pages 453–468, 2002. [3] G. Elidan, I. McGra w , and D. K oller . Residual belief propagation: Informed scheduling for asynchronous message passing. In Uncertainty in Artificial Intelligence (U AI) , 2006. [4] Alexander Ihler and Da vid McAllester . Particle belief propagation. In International Confer ence on Artificial Intelligence and Statistics (AIST ATS) , pages 256–263, 2009. [5] Alexander Ihler , John W . Fisher III, Alan S. W illsky , and Maxwell Chickering. Loopy belief propagation: Con v ergence and ef fects of message errors. J ournal of Machine Learning Researc h , 6:905–936, 2005. [6] Frank R. Kschischang, Brendan J. Frey , and Hans Andrea Loeliger . Factor graphs and the sum-product algorithm. IEEE T ransactions of Information Theory , 47(2):498–519, Feb 2001. [7] Ke vin P . Murphy , Y air W eiss, and Michael I. Jordan. Loopy belief propagation for approximate inference: An empirical study . In Uncertainty in Artificial Intelligence , pages 467–475, 1999. [8] Nima Noorshams and Martin J. W ainwright. Stochastic belief propagation: Low-comple xity message-passing with guarantees. In Communication, Contr ol, and Computing (Allerton) , 2011. [9] Libin Shen, Giorgio Satta, and Aravind Joshi. Guided learning for bidirectional sequence classification. In Association for Computational Linguistics (A CL) , 2007. [10] E. B. Sudderth, A. T . Ihler , W . T . Freeman, and A. S. W illsky . Nonparametric belief propagation. In Computer V ision and P attern Recognition (CVPR) , 2003. [11] Charles Sutton and Andrew McCallum. Improv ed dynamic schedules for belief propagation. In Uncertainty in Artificial Intelligence (U AI) , 2007. [12] J.S. Y edidia, W .T . Freeman, and Y . W eiss. Generalized belief propagation. In Neural Information Pr ocessing Systems (NIPS) , number 13, pages 689–695, December 2000. [13] T ianli Y u, Ruei-Sung Lin, B. Super, and Bei T ang. Efficient message representations for belief propagation. In International Confer ence on Computer V ision (ICCV) , pages 1 –8, 2007. 5 A Algorithm The proposed approach is outlined in Algorithm 1. W e initialize the sparse domains using a single value for each variable with the highest priority . The domain priority queue ( Q d ) contains the priorities for the rest of the v alues of the v ariables, which remain fixed or are updated depending on the prioritization scheme of choice (Section 2.2). Message passing uses dynamic message prioritization maintained in the message queue Q m . Once message passing has con ver ged to obtain locally-consistent marginals (according to some small ), we select another value to add to the domains using one of the value priority schemes, and continue till all the domains are fully-instantiated. If the algorithm is interrupted at any point, we return either the current marginals, or the last conv erged, locally-consistent marginals. W e use a heap-based priority queue for both messages and domain values, in which update and deletion take O (log n ) , where n is often smaller than the number of factors and total possible v alues. Algorithm 1 Anytime Belief Propagation 1: ∀ x i , S i ← { v i } where v i = arg max v s π i ( v s ) 2: Q d ⊕ h ( i, v i ) , π i ( v i ) i ∀ x i , v i ∈ D i − S i 3: Q m = {} 4: while | Q d | > 0 do Domains are still partial 5: G R O W D O M A I N ( S , Q d ) Add a value to a domain, Algorithm 2 6: C O N V E R G E U S I N G B P ( S , Q m ) Con ver ge to a fix ed point, Algorithm 3 7: end while Con ver ged on full domains Algorithm 2 Growing by a single v alue (Section 2.2) 1: procedure G R OW D O M A I N ( S , Q d ) 2: ( i, v p ) ← Q d .pop Select value to add 3: S i ← S i ∪ { v p } Add value to domain 4: for f ← N ( x i ) do 5: Q m ⊕ h f , π ( f ) i Update msg priority 6: end for 7: end procedure Algorithm 3 BP on Sparse Domains (Sect. 2.1, 2.3) 1: procedure C O N V E R G E U S I N G B P ( S , Q m ) 2: while max ( Q m ) > do 3: f ← Q m .pop Factor with max priority 4: Pass messages from f 5: for x j ← N f ; f 0 ← N ( x j ) do 6: Q m ⊕ h f 0 , π ( f 0 ) i Update msg priorities 7: Q d ⊕ h ( k , v q ) , π k ( v k ) i ∀ x k ∈ N f 0 , ∀ v k 8: end for 9: end while Con ver ged on sparse domains 10: end procedure 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment